| Prev | Part II. Guided Tour and Tutorial Chapter 8. SPMD PROGRAMMING |  | Next |
The Jacobi example is made of two Java classes:
Jacobi.java: the main class
SubMatrix.java: the class implementing the SPMD code
Have a first quick look at the code, especially the Jacobi
class, looking for the strings "ProActive", "Nodes", "newSPMDGroup".
The last instruction of the class:
matrix.compute(); is an asynchronous group call. It
sends a request to all active objects in the SPMD group, triggering
computations in all the SubMatrix. We will get to the class
SubMatrix.java later on.
ProActive examples come with scripts to easily launch the execution under both Unix and Windows.For Jacobi, launch:
ProActive/scripts/unix/jacobi.sh
or
ProActive/scripts/windows/jacobi.bat
The computation stops after minimal difference is reached between two iterations (constant MINDIFF in class Jacobi.java), or after a fixed number of iteration (constant ITERATIONS in class Jacobi.java).
The provided script, using an XML descriptor, creates 4 JVMs on the current machine. The Jacobi class creates an SPMD group of 9 Active Objects; 2 or 3 AOs per JVM.
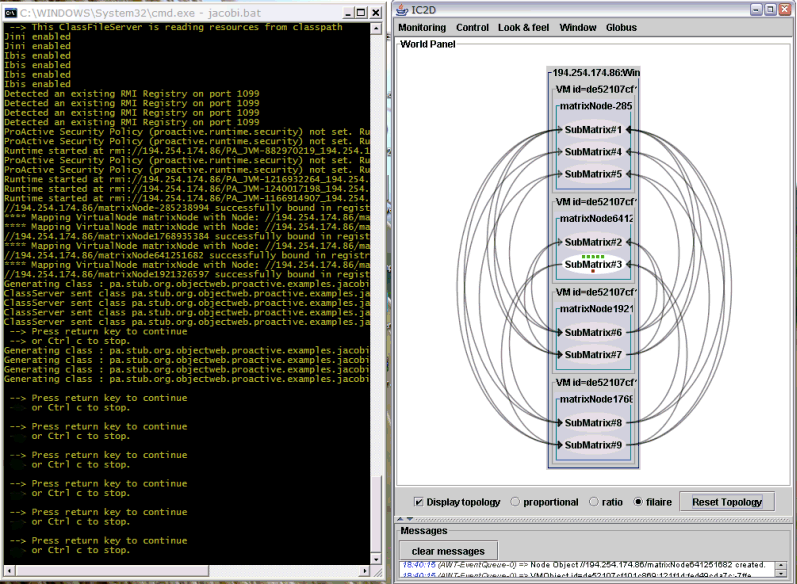
Look at the traces on the console upon starting the script; in the current case, remember that all JVMs and AOs send output to the same console. More specifically, understand the following:
Created a new registry on port 1099"
"Reading deployment descriptor ... Matrix.xml "
"created VirtualNode"
"**** Starting jvm on"
"ClassFileServer is reading resources from classpath"
"Detected an existing RMI Registry on port 1099""
"Generating class: ... jacobi.Stub_SubMatrix "
"ClassServer sent class ... jacobi.Stub_SubMatrix successfully"
You can start IC2D (script ic2d.sh or ic2d.bat) in order to visualize the JVMs and the Active Objects. Just activate the "Monitoring a new host" in the "Monitoring" menu at the top left. To stop the Jacobi computation and all the associated AOs, and JVMs, just ^C in the window where you started the Jacobi script.
Do a simple source modification, for instance changing the values of the constants MINDIFF (0.00000001 for ex) and ITERATIONS in class Jacobi.java.
Caveat: Be careful, due to a shortcoming of the Java make system (ant), make sure to also touch the class SubMatrix.java that uses the constants.
ProActive distribution comes with scripts to easily recompile the provided examples:
linux>ProActive/compile/build
or
windows>ProActive/compile/build.bat
Several targets are provided (start build without arguments to obtain them). In order to recompile the Jacobi, just start the target that recompile all the examples:
build examples
2 source files must appear as being recompiled.
Following the recompilation, rerun the examples as explained in section 1.2 above, and observe the differences.
Within the class SubMatrix.java the following methods correspond to a standard Jacobi implementation, and are not specific to ProActive:
internalCompute ()
borderCompute ()
exchange ()
buildFakeBorder (int size)
buildNorthBorder ()
buildSouthBorder ()
buildWestBorder ()
buildEastBorder ()
stop ()
The methods on which asynchronous remote method invocations take place are:
sendBordersToNeighbors ()
setNorthBorder (double[] border)
setSouthBorder (double[] border)
setWestBorder (double[] border)
setEastBorder (double[] border)
The first one sends to the appropriate neighbors the appropriate values, calling set*Border() methods asynchronously. Upon execution by the AO, the methods set*Border() memorize locally the values being received.
Notice that all those communication methods are made of purely functional Java code, without any code to the ProActive API.
On the contrary, the followings are ProActive related aspects:
buildNeighborhood ()
compute ()
loop ()
We will detail them in the next section.
Note: the classes managing topologies are still under development. In the next release, the repetitive and tedious topology related instructions (e.g. methods buildNeighborhood) won't have to be written explicitly by the user, whatever the topology (2D, 3D).
Let us describe the OO SPMD techniques which are used and the related ProActive methods.
First of all, look for the definition and use of the attribute "asyncRefToMe". Using the primitive "getStubOnThis()", it provides a reference to the current active object on which method calls are asynchronous. It permits the AO to send requests to itself.
For instance in
this.asyncRefToMe.loop();
Notice the absence of a classical loop. The method "loop()" is indeed asynchronously called from itself; it is not really recursive since it does not have the drawback of the stack growing. It features an important advantage: the AO will remain reactive to other calls being sent to it. Moreover, it eases reuse since it is not necessary to explicitly encode within the main SPMD loop all the messages that have to be taken into account. It also facilitates composition since services can be called by activities outside the SPMD group, they will be automatically executed by the FIFO service of the Active Object.
The method "buildNeighborhood ()" is called only once for initialization. Using a 2D topology (Plan), it constructs references to north, south, west, east neighbors -- attributes with respective names. It also construct dynamically the group of neighbors. Starting from an empty group of type SubMatrix
this.neighbors = (SubMatrix)
ProActiveGroup.newGroup
(SubMatrix.class.getName());
such typed view of the group is used to get the group view: Group neighborsGroup = ProActiveGroup.getGroup(this.neighbors); Then, the appropriate neighbors are added dynamically in the group, e.g.:
neighborsGroup.add(this.north);
Again, the topology management classes in a future release of ProActive will simplify this process.
Let's say we would like to control step by step the execution of the SPMD code. We will add a barrier in the SubMatrix.java, and control the barrier from input in the Jacobi.java class.
In class SubMatrix.java, add a method
barrier() of the form:
String[] st= new String[1]; st[0]="keepOnGoing"; ProSPMD.barrier(st);
Do not forget to define the keepOnGoing()
method that indeed can return void, and just be empty. Find the
appropriate place to call the barrier() method in
the loop() method.
In class Jacobi.java, just after the
compute() method, add an infinite loop that, upon a
user's return key pressed, calls the method
keepOnGoing() on the SPMD group "matrix". Here are
samples of the code:
while (true) { printMessageAndWait(); matrix.keepOnGoing(); } ... private static void printMessageAndWait() { java.io.BufferedReader d = new java.io.BufferedReader( new java.io.InputStreamReader(System.in)); System.out.println(" --> Press return key to continue"); System.out.println(" or Ctrl c to stop."); try { d.readLine(); } catch (Exception e) { e.printStackTrace(); }
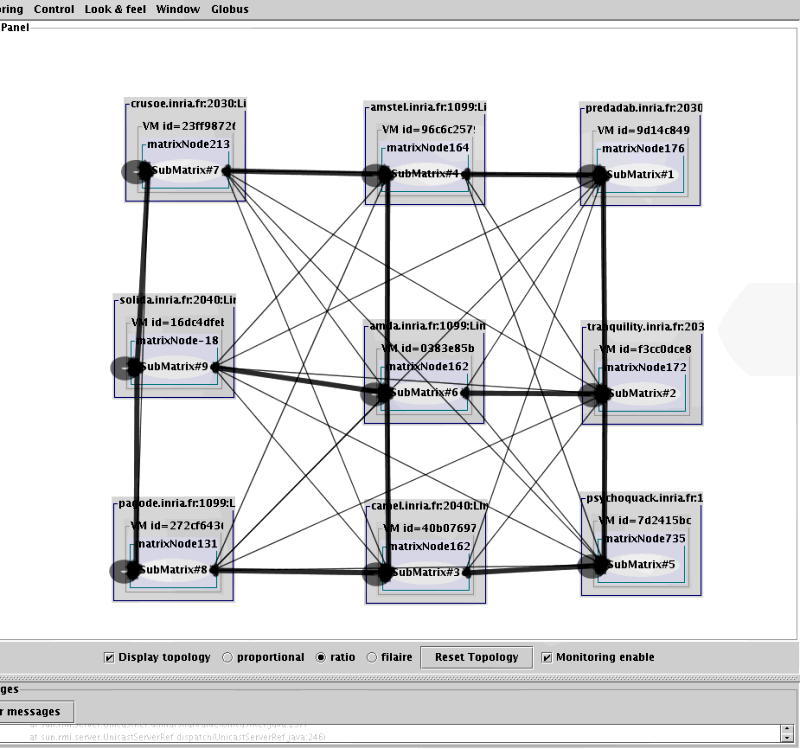
Recompile, and execute the code. Each iteration needs to be activated by hitting the return key in the shell window where Jacobi was launched. Start IC2D (./ic2d.sh or ic2d.bat), and visualize the communications as you control them. Use the "Reset Topology" button to clear communication arcs. The green and red dots indicate the pending requests.
You can try and test other modifications to the Jacobi code.
The group of neighbors built above is important wrt synchronization. Below in method "loop()", an efficient barrier is achieved only using the direct neighbors:
ProSPMD.barrier("SynchronizationWithNeighbors"+
this.iterationsToStop, this.neighbors);
This barrier takes as a parameter the group to synchronize with: it will be passed only when the 4 neighbors in the current 2D example have reached the same point. Adding the rank of the current iteration allows to have a unique identifier for each instance of the barrier.
Try to change the barrier instruction to a total barrier:
ProSPMD.barrier("SynchronizationWithNeighbors"+
this.iterationsToStop);
Then recompile and execute again. Using IC2D observe that many more communications are necessary.
In order to get details and documentation on Groups and OO SPMD, have a look at Chapter 14, Typed Group Communication and Chapter 15, OOSPMD.
Now, we will return to the source code of Jacobi.java to understand where and how the Virtual Nodes and Nodes are being used.
The XML descriptor being used is:
ProActive/descriptors/Matrix.xml
Look for and understand the following definitions:
- Virtual Node Definition
- Mapping of Virtual Nodes to JVM
- JVM Definition
- Process Definition
A detailed presentation of XML descriptors is available in Section 21.1, “Objectives”.
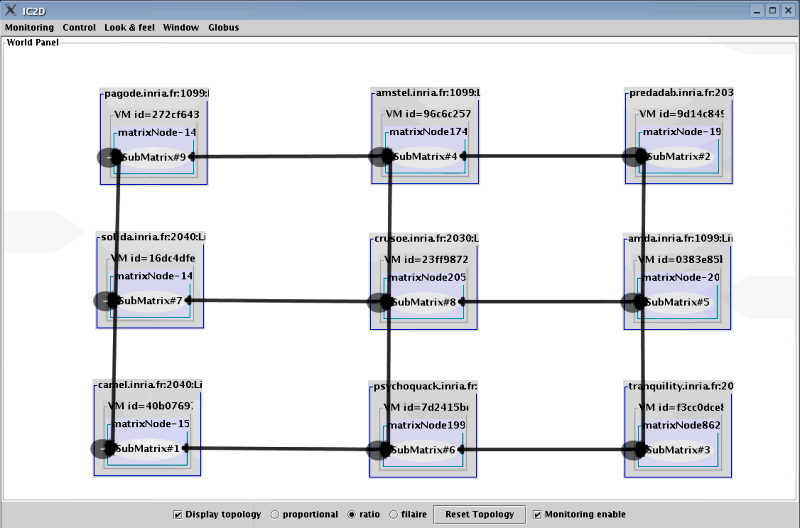
Edit the file Matrix.xml in order to change the number of JVMs being used. For instance, if your machine is powerful enough, start 9 JVMs, in order to have a single SubMatrix per JVM.
You do not need to recompile, just restart the execution. Use IC2D to visualize the differences in the configuration.
Explicit machine names
ProActive/examples/descriptors/Matrix.xml is the
XML deployment file used in this tutorial to start 4 jvms on the local
machine. This behavior is achieved by referencing in the creation tag
of Jvm1, Jvm2, Jvm3, Jvm4 a jvmProcess named with the id localProcess. To summarize briefly at least one
jvmProcess must be defined in an xml
deployment file. When this process is referenced directly in the
creation part of the jvm definition (like the example below), the jvm
will be created locally. On the other hand, if this process is
referenced by another process(rshProcess for instance, this is the case in
the next example), the jvm will be created remotely using the related
protocol (rsh in the next example).
Note that several jvmProcesses can be defined, for instance in order to specify different jvm configurations (e.g classpath, java path,...).
<ProActiveDescriptor xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation= "http://www-sop.inria.fr/oasis/proactive/schema/3.2/DescriptorSchema.xsd"> <componentDefinition> <virtualNodesDefinition> <virtualNode name="matrixNode" property="multiple"/> </virtualNodesDefinition> </componentDefinition> <deployment> <mapping> <map virtualNode="matrixNode"> <jvmSet> <vmName value="Jvm1"/> <vmName value="Jvm2"/> <vmName value="Jvm3"/> <vmName value="Jvm4"/> </jvmSet> </map> </mapping> <jvms> <jvm name="Jvm1"> <creation> <processReference refid="localProcess"/> </creation> </jvm> <jvm name="Jvm2"> <creation> <processReference refid="localProcess"/> </creation> </jvm> <jvm name="Jvm3"> <creation> <processReference refid="localProcess"/> </creation> </jvm> <jvm name="Jvm4"> <creation> <processReference refid="localProcess"/> </creation> </jvm> </jvms> </deployment> <infrastructure> <processes> <processDefinition id="localProcess"> <jvmProcess class="org.objectweb.proactive.core.process.JVMNodeProcess"/> </processDefinition> </processes> </infrastructure> </ProActiveDescriptor>
Modify your XML deployment file to use the current JVM (i.e the JVM reading the descriptor) and also to start 4 JVMs on remote machines using rsh protocol.
Use IC2D to visualize the machines ("titi", "toto", "tata" and "tutu" in this example) and the JVMs being launched on them.
<ProActiveDescriptor xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation= "http://www-sop.inria.fr/oasis/proactive/schema/3.2/DescriptorSchema.xsd"> <componentDefinition> <virtualNodesDefinition> <virtualNode name="matrixNode" property="multiple"/> </virtualNodesDefinition> </componentDefinition> <deployment> <mapping> </map> <map virtualNode="matrixNode"> <jvmSet> <currentJvm /> <vmName value="Jvm1"/> <vmName value="Jvm2"/> <vmName value="Jvm3"/> <vmName value="Jvm4"/> </jvmSet> </map> </mapping> <jvms> <jvm name="Jvm1"> <creation> <processReference refid="rsh_titi"/> </creation> </jvm> <jvm name="Jvm2"> <creation> <processReference refid="rsh_toto"/> </creation> </jvm> <jvm name="Jvm3"> <creation> <processReference refid="rsh_tata"/> </creation> </jvm> <jvm name="Jvm4"> <creation> <processReference refid="rsh_tutu"/> </creation> </jvm> </jvms> </deployment> <infrastructure> <processes> <processDefinition id="localProcess"> <jvmProcess class="org.objectweb.proactive.core.process.JVMNodeProcess"/> </processDefinition> <processDefinition id="rsh_titi"> <rshProcess class="org.objectweb.proactive.core.process.rsh.RSHProcess" hostname="titi"> <processReference refid="localProcess"/> /rshProcess> </processDefinition> <processDefinition id="rsh_toto"> <rshProcess class="org.objectweb.proactive.core.process.rsh.RSHProcess" hostname="toto"> <processReference refid="localProcess"/> /rshProcess> </processDefinition> <processDefinition id="rsh_tata"> <rshProcess class="org.objectweb.proactive.core.process.rsh.RSHProcess" hostname="tata"> <processReference refid="localProcess"/> /rshProcess> </processDefinition> <processDefinition id="rsh_tutu"> <rshProcess class="org.objectweb.proactive.core.process.rsh.RSHProcess" hostname="tutu"> <processReference refid="localProcess"/> /rshProcess> </processDefinition> </processes> </infrastructure> </ProActiveDescriptor>
Pay attention of what happened to your previous XML deployment file. First of all to use the current jvm the following line was added just under the jvmSet tag
<jvmSet> <currentJvm /> ... <jvmSet>
Then the jvms are not created directly using the localProcess, but instead using other processes named rsh_titi, rsh_toto, rsh_tata, rsh_tutu
<jvms> <jvm name="Jvm1"> <creation> <processReference refid="rsh_titi"/> </creation> </jvm> <jvm name="Jvm2"> <creation> <processReference refid="rsh_toto"/> </creation> </jvm> <jvm name="Jvm3"> <creation> <processReference refid="rsh_tata"/> </creation> </jvm> <jvm name="Jvm4"> <creation> <processReference refid="rsh_tutu"/> </creation> </jvm> </jvms>
Those processes as shown below are rsh processes. Note that it is mandatory for such processes to reference a jvmProcess, in this case named with the id localProcess, to create, at deployment time, a jvm on machines titi, toto, tata, tutu, once connected to those machines with rsh.
<processDefinition id="localProcess"> <jvmProcess class="org.objectweb.proactive.core.process.JVMNodeProcess"/> </processDefinition> <processDefinition id="rsh_titi"> <rshProcess class="org.objectweb.proactive.core.process.rsh.RSHProcess" hostname="titi"> <processReference refid="localProcess"/> /rshProcess> </processDefinition> <processDefinition id="rsh_toto"> <rshProcess class="org.objectweb.proactive.core.process.rsh.RSHProcess" hostname="toto"> <processReference refid="localProcess"/> /rshProcess> </processDefinition> <processDefinition id="rsh_tata"> <rshProcess class="org.objectweb.proactive.core.process.rsh.RSHProcess" hostname="tata"> <processReference refid="localProcess"/> /rshProcess> </processDefinition> <processDefinition id="rsh_tutu"> <rshProcess class="org.objectweb.proactive.core.process.rsh.RSHProcess" hostname="tutu"> <processReference refid="localProcess"/> /rshProcess> </processDefinition>
Using Lists of Processes
You can also use the notion of Process List, which leads to the same result but often simplifies the xml. Two tags are provided, the first is:
processListbyHost
This allows a single definition to list all hostnames on which the same JVM profile will be started.
<ProActiveDescriptor xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation= "http://www-sop.inria.fr/oasis/proactive/schema/3.2/DescriptorSchema.xsd"> <componentDefinition> <virtualNodesDefinition> <virtualNode name="matrixNode" property="multiple"/> </virtualNodesDefinition> </componentDefinition> <deployment> <mapping> </map> <map virtualNode="matrixNode"> <jvmSet> <currentJvm/> <vmName value="Jvm1"/> </jvmSet> </map> </mapping> <jvms> <jvm name="Jvm1"> <creation> <processReference refid="rsh_list_titi_toto_tutu_tata"/> </creation> </jvm> </jvms> </deployment> <infrastructure> <processes> <processDefinition id="localProcess"> <jvmProcess class="org.objectweb.proactive.core.process.JVMNodeProcess"/> </processDefinition> <processDefinition id="rsh_list_titi_toto_tutu_tata"> <processListbyHost class="org.objectweb.proactive.core.process.rsh.RSHProcessList" hostlist="titi toto tata tutu"> <processReference refid="localProcess"/> </processListbyHost> </processDefinition> </processes> </infrastructure> </ProActiveDescriptor>
The second is a shorthand for a set of numbered hosts with a common prefix:
processList
This is used when the machine names follow a list format, for instance titi1 titi2 titi3 ... titi100
<ProActiveDescriptor xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation= "http://www-sop.inria.fr/oasis/proactive/schema/3.2/DescriptorSchema.xsd"> <componentDefinition> <virtualNodesDefinition> <virtualNode name="matrixNode" property="multiple"/> </virtualNodesDefinition> </componentDefinition> <deployment> <mapping> </map> <map virtualNode="matrixNode"> <jvmSet> <currentJvm/> <vmName value="Jvm1"/> </jvmSet> </map> </mapping> <jvms> <jvm name="Jvm1"> <creation> <processReference refid="rsh_list_titi1_to_100"/> </creation> </jvm> </jvms> </deployment> <infrastructure> <processes> <processDefinition id="localProcess"> <jvmProcess class="org.objectweb.proactive.core.process.JVMNodeProcess"/> </processDefinition> <processDefinition id="rsh_list_titi1_to_100"> <processList class="org.objectweb.proactive.core.process.rsh.RSHProcessList" fixedName="titi" list="[1-100]" domain="titi_domain"> <processReference refid="localProcess"/> </processList> </processDefinition> </processes> </infrastructure> </ProActiveDescriptor>
If you have access to your own cluster, configure the XML descriptor to launch the Jacobi example on them, using the appropriate protocol:
ssh, LSF, PBS, Globus, etc.
Have a look at Section 21.1, “Objectives” to get the format of the XML descriptor for each of the supported protocols.
In this chapter we are going to see a simple example of an MPI written program ported to ProActive.
First let's introduce what we are going to compute.
This simple program approximates pi by computing :
pi = integral from 0 to 1 of 4/( 1+x*x ) dx
Which is approximated by :
sum from k=1 to N of 4 / ( ( 1 +( k-1/2 ) **2 )
The only input data required is N, the number of iterations.
Involved files :
ProActive/doc-src/mpi_files/int_pi2.c : the original MPI implementation
ProActive/trunk/src/org/objectweb/proactive/examples/integralpi/Launcher.java : the main class
ProActive/trunk/src/org/objectweb/proactive/examples/integralpi/Worker.java : the class implementing the SPMD code
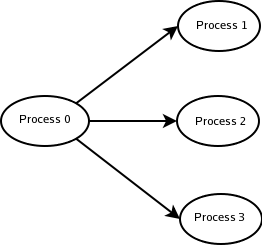
Some basic primitives are used, notice that MPI provides a rank to each process and the group size ( the number of involved processes ).
// All instances call startup routine to get their instance number (mynum) MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &mynum); MPI_Comm_size(MPI_COMM_WORLD, &nprocs); // Get a value for N solicit (&N, &nprocs, mynum);
First we need to create the group of workers (MPI processes represented by active objects). Notice that the creation of active objects is done in Launcher.java.
The group of active objects is created using specified parameters and the nodes specified in the deployement descriptor.
// Group creation Worker workers = (Worker) ProSPMD.newSPMDGroup( Worker.class.getName(), params, provideNodes(args[0])); // Once the group is created and the value for N is entered we can start the workers job // Workers starts their job and return a group of Futures DoubleWrapper results = workers.start( numOfIterations );
The ProSPMD layer provides similar to MPI initialization primitives. In Worker.java you can identify this initialization. Note that one-to-one communications will be done thanks to an array view on the created group.
// Worker initialization rank = ProSPMD.getMyRank(); groupSize = ProSPMD.getMySPMDGroupSize(); // Get all workers references workersArray = (Worker[]) ProActiveGroup.getGroup(ProSPMD.getSPMDGroup()).toArray(new Worker[0]);
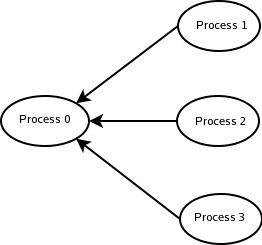
The communication pattern is very simple, it's done in 2 steps. First the process 0 Broadcasts N then waits for the result from each other process and sums the received values.
The MPI implementation involves 3 communication primitives :
MPI_Send ( Sends data to one process )
MPI_Recv ( Receives data from a sending process )
MPI_Bcast ( Broadcast a data to all processes )
Please note that MPI_Bcast, MPI_Send and MPI_Recv primitives are blocking.
// Get a value of N from stdin for the next run and Broadcast it MPI_Bcast(pN, 1, MPI_INT, source, MPI_COMM_WORLD); // LOCAL COMPUTATION LOOP // ... if ( mynum == 0 ) { // Check if i'm the leader process for (i=1; i<nprocs; i++) { source = i; info = MPI_Recv(&x, 1, MPI_FLOAT, source, type, MPI_COMM_WORLD, &status); // waits the value from source process sum=sum+x; // sum up the receive value } } else { info = MPI_Send(&sum, 1, MPI_FLOAT, dest, type, MPI_COMM_WORLD); // if i'm not the process 0 i send my sum }
The ProActive implementation is quite similar to MPI one. The fact is that all communications in ProActive are asynchronous ( non-blocking ) by default, therefore we need to specify explicitely to block until a specific request.
// The leader collects partial results. // Others just send their computed data to the rank 0. if ( rank==0 ) { // Check if i'm the leader worker for ( i=1; i<groupSize; i++ ) { body.serve(body.getRequestQueue().blockingRemoveOldest("updateX")); // block until an updateX call sum += x; } } else { workersArray[0].updateX(sum); }
The leader blocks his request queue until another worker will do a distant call on the leader's updateX method which is :
public void updateX(double value){ this.x = value; }
| MPI | ProActive |
|---|---|
| MPI_Init and MPI_Finalize | Activities creation |
| MPI_Comm_Size | ProSPMD.getMyGroupSize |
| MPI_Comm_Rank | ProSPMD.getMyRank |
| MPI_Send and MPI_Recv | Method call |
| MPI_Barrier | ProSPMD.barrier |
| MPI_Bcast | Method call on a group |
| MPI_Scatter | Method call with a scatter group as parameter |
| MPI_Gather | Result of a group communication |
| MPI_Reduce | Programmer's method |
Table 8.1. MPI to ProActive
ProActive distribution comes with scripts to easily recompile the provided examples:
linux>ProActive/compile/build
or
windows>ProActive/compile/build.bat
Use the build script to recompile the example
build examples
2 source files must appear as being recompiled.
In ProActive/scripts/unix or windows run integralpi.sh or .bat, you can specify the number of workers from the command line. Feel free to edit scripts to specify another deployement descriptor.
bash-3.00$ ./integralpi.sh
--- IntegralPi --------------------------------------------------
The number of workers is 4
--> This ClassFileServer is reading resources from classpath 2011
Created a new registry on port 1099
ProActive Security Policy (proactive.runtime.security) not set. Runtime Security disabled
************* Reading deployment descriptor: file:./../../descriptors/Matrix.xml ********************
created VirtualNode name=matrixNode
**** Starting jvm on amda.inria.fr
**** Starting jvm on amda.inria.fr
**** Starting jvm on amda.inria.fr
ProActive Security Policy (proactive.runtime.security) not set. Runtime Security disabled
--> This ClassFileServer is reading resources from classpath 2012
ProActive Security Policy (proactive.runtime.security) not set. Runtime Security disabled
ProActive Security Policy (proactive.runtime.security) not set. Runtime Security disabled
--> This ClassFileServer is reading resources from classpath 2013
--> This ClassFileServer is reading resources from classpath 2014
**** Starting jvm on amda.inria.fr
Detected an existing RMI Registry on port 1099
Detected an existing RMI Registry on port 1099
Detected an existing RMI Registry on port 1099
ProActive Security Policy (proactive.runtime.security) not set. Runtime Security disabled
--> This ClassFileServer is reading resources from classpath 2015
//amda.inria.fr/matrixNode2048238867 successfully bound in registry at //amda.inria.fr/matrixNode2048238867
**** Mapping VirtualNode matrixNode with Node: //amda.inria.fr/matrixNode2048238867 done
//amda.inria.fr/matrixNode690267632 successfully bound in registry at //amda.inria.fr/matrixNode690267632
**** Mapping VirtualNode matrixNode with Node: //amda.inria.fr/matrixNode690267632 done
//amda.inria.fr/matrixNode1157915128 successfully bound in registry at //amda.inria.fr/matrixNode1157915128
**** Mapping VirtualNode matrixNode with Node: //amda.inria.fr/matrixNode1157915128 done
Detected an existing RMI Registry on port 1099
//amda.inria.fr/matrixNode-814241328 successfully bound in registry at //amda.inria.fr/matrixNode-814241328
**** Mapping VirtualNode matrixNode with Node: //amda.inria.fr/matrixNode-814241328 done
4 nodes found
Generating class : pa.stub.org.objectweb.proactive.examples.integralpi.Stub_Worker
Enter the number of iterations (0 to exit) : 100000
Generating class : pa.stub.org.objectweb.proactive.examples.integralpi.Stub_Worker
Generating class : pa.stub.org.objectweb.proactive.examples.integralpi.Stub_Worker
Generating class : pa.stub.org.objectweb.proactive.examples.integralpi.Stub_Worker
Generating class : pa.stub.org.objectweb.proactive.examples.integralpi.Stub_Worker
Worker 2 Calculated x = 0.7853956634245252 in 43 ms
Worker 3 Calculated x = 0.7853906633745299 in 30 ms
Worker 1 Calculated x = 0.7854006634245316 in 99 ms
Worker 0 Calculated x = 3.141592653598117 in 12 ms
Calculated PI is 3.141592653598117 error is 8.324008149429574E-12
Enter the number of iterations (0 to exit) : © 2001-2007 INRIA Sophia Antipolis All Rights Reserved