| Prev | Part IV. Deploying Chapter 25. Fault-Tolerance |  | Next |
ProActive can provide fault-tolerance capabilities through two differents protocols: a Communication-Induced Checkpointing protocol (CIC) or a pessimistic message logging protocol (PML). Making a ProActive application fault-tolerant is fully transparent; active objects are turned fault-tolerant using Java properties that can be set in the deployment descriptor (see Chapter 21, XML Deployment Descriptors). The programmer can select at deployment time the most adapted protocol regarding the application and the execution environment.
Persistence of active objects is obtained through standard Java serialization; a checkpoint thus consists in an object containing a serialized copy of an active object and few informations related to the protocol. As a consequence, a fault-tolerant active object must be serializable.
Each active object in a CIC fault-tolerant application have to checkpoint at least every TTC (Time To Checkpoint) seconds. When all the active objects have taken a checkpoint, a global state is formed. If a failure occurs, the entire application must restarts from such a global state. The TTC value depends mainly on the assessed frequency of failures. A little TTC value leads to very frequent global state creation and thus to a little rollback in the execution in case of failure. But a little TTC value leads also to a bigger overhead between a non-fault-tolerant and a fault-tolerant execution. The TTC value can be set by the programmer in the deployment descriptor.
The failure-free overhead induced by the CIC protocol is usually low, and this overhead is quasi-independent from the message communication rate. The counterpart is that the recovery time could be long since all the application must restart after the failure of one or more active object.
Each active object in a PML fault-tolerant application have to checkpoint at least every TTC seconds and all the messages delivered to an active object are logged on a stable storage. There is no need for global synchronization as with CIC protocol, each checkpoint is independent: if a failure occurs, only the faulty process have to recover from its latest checkpoint. As for CIC protocol, the TTC value impact the global failure-free overhead, but the overhead is more linked to the communication rate of the application.
Regarding the CIC protocol, the PML protocol induces a higher overhead on failure-free execution, but the recovery time is lower as a single failure does not involve all the system.
Warning: For the version 3.0, those two protocols are not compatible: a fault-tolerance application can use only one of the two protocols. This compatibility will be provide in the next version.
To be able to recover a failed active object, the fault-tolerance system must have access to a resource server. A resource server is able to return a free node that can host the recovered active object.
A resource server is implemented in ProActive in
ft.servers.resource.ResourceServer. This server can
store free nodes by two differents way:
at deployment time: the user can specify in the deployment descriptor a resource virtual node. Each node mapped on this virtual node will automaticaly register itself as free node at the specified resource server.
at execution time: the resource server can use an underlying p2p network (see Chapter 35, ProActive Peer-to-Peer Infrastructure) to reclaim free nodes when a hosting node is needed.
Note that those two mechanisms can be combined. In that case, the resource server first provides node registered at deployment time, and when no more such nodes are available, the p2p network is used.
Fault-tolerance mechanism needs servers for the checkpoints
storage, the localization of the active objects, and the failure
detection. Those servers are implemented in the current version as a
unique server (ft.servers.FTServer), that implements
the interfaces of each server (ft.servers.*.*). This
global server also includes a resource server.
This server is a classfile server for recovered active objects. It must thus have access to all classes of the application, i.e. it must be started with all classes of the application in its classpath.
The global fault-tolerance server can be launched using the
ProActive/scripts/[unix|windows]/FT/startGlobalFTServer.[sh|bat]
script, with 5 optional parameters:
the protocol: -proto [cic|pml]. Default
value is cic.
the server name: -name <serverName>.
The default name is FTServer.
the port number: -port <portNumber>.
The default port number is 1100.
the fault detection period: -fdperiod
<periodInSec>. This value defines the time between
two consecutive fault detection scanning. The default value is 10
sec. Note that an active object is considered as faulty when it
becomes unreachable, i.e. when it becomes unable to receive a
message from another active object.
the URL of a p2p service (see Chapter 35, ProActive Peer-to-Peer Infrastructure) that can
be used by the resource server: -p2p <serviceURL>.
There is no default value for this
option.
The server can also be directly launched in the java source code,
using
org.objectweb.proactive.core.process.JVMProcessImpl
class:
GlobalFTServer server = new JVMProcessImpl(
new org.objectweb.proactive.core.process.AbstractExternalProcess.StandardOutputMessageLogger());
this.server.setClassname('org.objectweb.proactive.core.body.ft.servers.StartFTServer');
this.server.startProcess();Note that if one of the servers is unreachable when a fault-tolerant application is deploying, fault-tolerance is automatically and transparently disabled for all the application.
Fault-tolerance capabilities of a ProActive application are set in
the deployment descriptor, using the faultTolerance
service. This service is attached to a virtual
node: active objects that are deployed on this virtual node
are turned fault-tolerant. This service must first defines the protocol
that have to be used for this application. The user can select the
appropriate protocol with the entry <protocol
type='[cic|pml]'/> in the definition of the service.
The service also defines servers URLs:
<globalServer url='...'/> set the URL
of a global server, i.e. a server that
implements all needed methods for fault-tolerance mechanism (stable
storage, fault detection, localization). If this value is set, all
others URLs will be ignored.
<checkpointServer url='...'/> set the
URL of the checkpoint server, i.e. the server where checkpoints are
stored.
<locationServer url='...'/> set the
URL of the location server, i.e. the server responsible for giving
references on failed and recovered active objects.
<recoveryProcess url='...'/> set the
URL of the recovery process, i.e. the process responsible for
launching the recovery of the application after a failure.
<resourceServer url='...'/> set the
URL of the resource server, i.e. the server responsible for
providing free nodes that can host a recovered active object.
Finally, the TTC value is set in
fault-tolerance service, using <ttc
value='x'/>, where x is expressed in
seconds. If not, the default value (30 sec) is
used.
Here is an example of deployment descriptor that deploys 3 virtual
nodes: one for deploying fault-tolerant active objects, one for
deploying non-fault-tolerant active object (if needed), and one as
resource for recovery. The two fault-tolerance behaviors correspond to
two fault-tolerance services, appli and
resource. Note that non-fault-tolerant active objects
can communicate with fault-tolerant active objects as usual. Chosen
protocol is CIC and TTC is set to 5 sec for all the application.
<ProActiveDescriptor>
<componentDefinition>
<virtualNodesDefinition>
<virtualNode name='NonFT-Workers' property='multiple'/>
<virtualNode name='FT-Workers' property='multiple' ftServiceId='appli'/>
<virtualNode name='Failed' property='multiple' ftServiceId='resource'/>
</virtualNodesDefinition>
</componentDefinition>
<deployment>
<mapping>
<map virtualNode='NonFT-Workers'>
<jvmSet>
<vmName value='Jvm1'/>
</jvmSet>
</map>
<map virtualNode='FT-Workers'>
<jvmSet>
<vmName value='Jvm2'/>
</jvmSet>
</map>
<map virtualNode='Failed'>
<jvmSet>
<vmName value='JvmS1'/>
<vmName value='JvmS2'/>
</jvmSet>
</map>
</mapping>
<jvms>
<jvm name='Jvm1'>
<creation>
<processReference refid='linuxJVM'/>
</creation>
</jvm>
<jvm name='Jvm2'>
<creation>
<processReference refid='linuxJVM'/>
</creation>
</jvm>
<jvm name='JvmS1'>
<creation>
<processReference refid='linuxJVM'/>
</creation>
</jvm>
<jvm name='JvmS2'>
<creation>
<processReference refid='linuxJVM'/>
</creation>
</jvm>
</jvms>
</deployment>
<infrastructure>
<processes>
<processDefinition id='linuxJVM'>
<jvmProcess
class='org.objectweb.proactive.core.process.JVMNodeProcess'/>
</processDefinition>
</processes>
<services>
<serviceDefinition id='appli'>
<faultTolerance>
<protocol type='cic'></protocol>
<globalServer url='rmi://localhost:1100/FTServer'></globalServer>
<ttc value='5'></ttc>
</faultTolerance>
</serviceDefinition>
<serviceDefinition id='resource'>
<faultTolerance>
<protocol type='cic'></protocol>
<globalServer url='rmi://localhost:1100/FTServer'></globalServer>
<resourceServer url='rmi://localhost:1100/FTServer'></resourceServer>
<ttc value='5'></ttc>
</faultTolerance>
</serviceDefinition>
</services>
</infrastructure>
</ProActiveDescriptor>Persistence of active objects is obtained through standard Java serialization; a checkpoint thus consists in an object containing a serialized copy of an active object and a few informations related to the protocol. As a consequence, a fault-tolerant active object must be serializable. If a non serializable object is activated on a fault-tolerant virtual node, fault-tolerance is automatically and transparently disabled for this active object.
Standard Java thread, typically main method, cannot be turned fault-tolerant. As a consequence, if a standard main method interacts with active objects during the execution, consistency after a failure can no more be ensured: after a failure, all the active objects will roll back to the most recent global state but the main will not.
So as to avoid such inconsistency on recovery, the programmer must minimizes the use of standard main by, for example, delegating the initialization and launching procedure to an active object.
... public static void main(String[] args){ Initializer init = (Initializer)(ProActive.newActive('Initializer.getClas\ s.getName()', args); init.launchApplication(); System.out.println('End of main thread'); } ...
The object init is an active object, and as
such will be rolled back if a failure occurs: the application is kept
consistent.
To keep fault-tolerance fully transparent (see the technical report for more details), active objects can take a checkpoint before the service of a request. As a first consequence, if the service of a request is infinite, or at least much greater than TTC, the active object that serves such a request can no more take checkpoints. If a failure occurs during the execution, this object will force the entire application to rolls back to the beginning of the execution. The programmer must thus avoid infinite method such as
... public void infiniteMethod(){ while (true){ this.doStuff(); } } ...
The second consequence concerns the definition of the
runActivity() method (see runActive).
Let us consider the following example:
... public void runActivity(Body body) { org.objectweb.proactive.Service service = new org.objectweb.proactive.Se\ rvice(body); while (body.isActive()) { Request r = service.blockingRemoveOldest(); ... /* CODE A */ ... /* CHECKPOINT OCCURRENCE */ service.serve(r); } } ...
If a checkpoint is triggered before the service of
r, it characterizes the state of the active object at
the point /* CHECKPOINT OCCURRENCE */. If a failure
occurs, this active object is restarted by calling the
runActivity() method, from a state in which
the code /* CODE A */ has been already
executed. As a consequence, the execution looks like if
/* CODE A */ was executed two times.
The programmer should then avoid to alter the state of an active
object in the code preceding the call to
service.serve(r) when he redefines the
runActivity() method.
All the activities of a fault-tolerant application must be deterministic
(see [BCDH04]
for more details). The programmer must then avoid the use of non-deterministic
methods such as Math.random().
Fault-tolerance in ProActive is still not compliant with the following features:
active objects exposed as Web services (see Chapter 38, Exporting Active Objects and components as Web Services), or reachable using http protocol,
and security (see Chapter 37, ProActive Security Mechanism), as fault-tolerance servers are implemented using standard RMI.
You can find in
ProActive/scripts/[unix|windows]/ft/nbodyft.[sh|bat]
a script that starts a fault-tolerant version of the ProActive
NBody example. This script actually call the
ProActive/scripts/[unix|windows]/nbody.[sh|bat]
script with the option -displayft. The java source
code is the same as the standard version. The only difference is the
'Execution Control' panel added in the graphical interface, which allows
the user to remotely kill Java Virtual Machine so as to trigger a
failure by sending a killall java signal. Note that
this panel will not work with Windows operating system, since the
killall does not exist. But a failure can be
triggered for example by killing the JVM process on one of the
hosts.
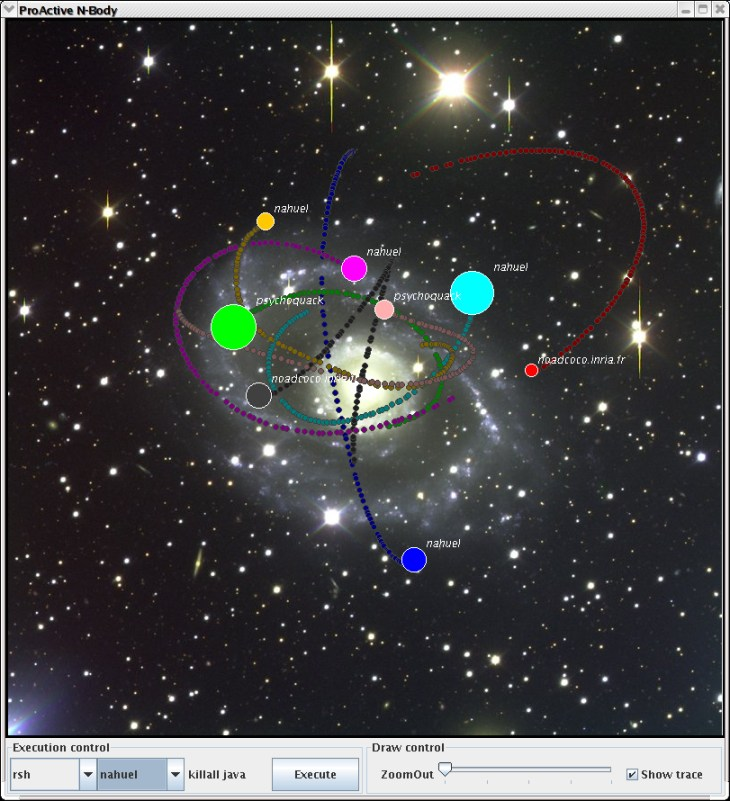
This snapshot shows a fault-tolerant execution with 8 bodies on 3 different hosts. Clicking on the 'Execute' button will trigger the failure of the host called Nahuel and the recovery of the 8 bodies. The checkbox Show trace is checked: the 100 latest positions of each body are drawn with darker points. These traces allow to verify that, after a failure, each body finally reach the position it had just before the failure.
Before starting the fault-tolerant body example, you have to edit
the ProActive/descriptors/FaultTolerantWorkers.xml
deployment descriptor so as to deploy on your own hosts (HOSTNAME), as follow:
...
<processDefinition id='jvmAppli1'>
<rshProcess
class='org.objectweb.proactive.core.process.rsh.RSHJVMProcess'
hostname='HOSTNAME'>
<processReference refid='jvmProcess'/>
</rshProcess>
</processDefinition>
...Of course, more than one host is needed to run this example, as failure are triggered by killing all Java processes on the selected host.
The deployment descriptor must also specify the GlobalFTServer
location as follow, assuming that the script
startGlobalFTServer.sh has been started on the host
SERVER_HOSTAME:
...
<services>
<serviceDefinition id='appli'>
<faultTolerance>
<protocol type='cic'></protocol>
<globalServer
url='rmi://SERVER_HOSTAME:1100/FTServer'></globalServer>
<ttc value='5'></ttc>
</faultTolerance>
</serviceDefinition>
<serviceDefinition id='ressource'>
<faultTolerance>
<protocol type='cic'></protocol>
<globalServer
url='rmi://SERVER_HOSTAME:1100/FTServer'></globalServer>
<resourceServer
url='rmi://SERVER_HOSTAME:1100/FTServer'></resourceServer>
<ttc value='5'></ttc>
</faultTolerance>
</serviceDefinition>
</services>
...Finally, you can start the fault-tolerant ProActive NBody and choose the version you want to run:
~/ProActive/scripts/unix/FT> ./nbodyFT.sh
Starting Fault-Tolerant version of ProActive NBody...
--- N-body with ProActive ---------------------------------
**WARNING**: $PROACTIVE/descriptors/FaultTolerantWorkers.xml MUST BE SET \
WITH EXISTING HOSTNAMES !
Running with options set to 4 bodies, 3000 iterations, display true
1: Simplest version, one-to-one communication and master
2: group communication and master
3: group communication, odd-even-synchronization
4: group communication, oospmd synchronization
5: Barnes-Hut, and oospmd
Choose which version you want to run [12345]:
4
Thank you!
--> This ClassFileServer is reading resources from classpath
Jini enabled
Ibis enabled
Created a new registry on port 1099
//tranquility.inria.fr/Node-157559959 successfully bound in registry at //t\
ranquility.inria.fr/Node-157559959
Generating class: pa.stub.org.objectweb.proactive.examples.nbody.common.St\
ub_Displayer
************* Reading deployment descriptor: file:./../../.././descriptors/\
FaultTolerantWorkers.xml ********************© 2001-2007 INRIA Sophia Antipolis All Rights Reserved