| Prev | Part IV. Programming With High Level APIs Chapter 14. The Calcium Skeleton Framework |
 |
Next |
Calcium is part of the ProActive Grid Middleware for programming structured parallel and distributed applications. The framework provides a basic set of structured patterns (skeletons) that can be nested to represents more complex patterns. Skeletons are considered a high level programming model because all the parallelisms details are hidden from the programmer. In Calcium, distributed programming is achieved by using ProActive deployment framework and active object model.
The Calcium implementation can be found in the following package of the ProActive Middleware distribution:
package org.objectweb.proactive.extensions.calcium;
The following steps must be performed for programming with the framework.
Define the skeleton structure.
Implement the missing classes of the structure (the muscle codes).
Create a new Calcium instance.
Provide a inputs of the problems to be solved by the framework.
Collect the results.
View the performance statistics.
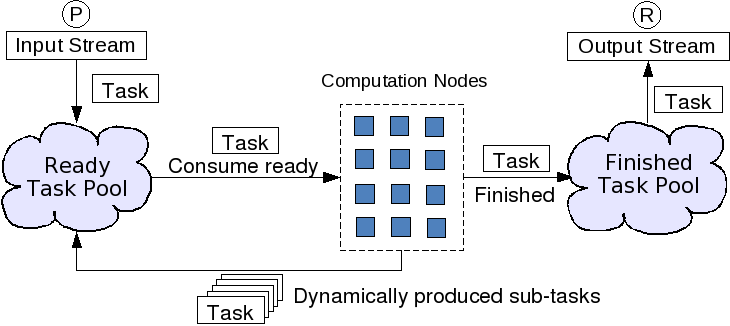
Problems inputed into the framework are treated as tasks. The tasks are interpreted by the remote skeleton interpreters as shown in the following Figure:
All the generation, distribution of tasks and their resource is completely hidden from the programmer. In fact, the task concept is never used when programming in Calcium.
In this example we implement a skeleton program that finds prime numbers between an interval using a brute force (naive) approach.
The approach consists of dividing the original search space into several smaller search spaces, and computing each sub search space in parallel. Therefore, the most suitable pattern corresponds to Divide and Conquer.
//DaC(<Divide>,<Condition>,<Skeleton>,<Conquer>) Skeleton<Interval, Primes> root = new DaC<Interval, Primes>( new IntervalDivide(), new IntervalDivideCondition(), new SearchInterval(), new JoinPrimes() );
We will call the problem an Interval and we will represent it using the following class.
class Interval implements Serializable { public int min,max; public int solvableSize; /** * Creates a new interval to search for primes. * @param min Beginning of interval * @param max End of interval * @param solvableSize Acceptable size of search interval */ public Interval(int min, int max, int solvableSize) { this.min = min; this.max = max; this.solvableSize = solvableSize; } }
The primes that are found will be stored in a Primes class.
public class Primes implements Serializable { public Vector<Integer> list; public Primes(){ primes=new Vector<Integer>(); } }
The divition of an Interval into smaller intervals is handled by an IntervalDivide class:
public class IntervalDivide implements Divide<Interval, Interval>{ public Interval[] divide(Interval param, SkeletonSystem system) { int middle = param.min+(param.max-param.min)/2; Interval ttUp = new Interval(middle + 1,param.max,param.solvableSize); Interval ttDown = new Interval(param.min, middle, param.solvableSize); return new Interval[] {ttDown, ttUP}; } }
The class IntervalDivideCondition is used to determine if an Interval must be subdivided or not.
public class IntervalDivideCondition implements Condition<Interval>{ public boolean condition(Interval params, SkeletonSystem system) { return params.max-params.min > params.solvableSize; } }
The SearchInterval class performes the actual findinf of primes. This class wil recieve an Interval object and return a Primes object
public class SearchInterval implements Execute<Interval, Primes> { public Primes execute(Interval param, SkeletonSystem system) { Primes primes = new Primes(); for (int i = param.min; i <= param.max; i++) { if (isPrime(i)) { primes.list.add(new Integer(i)); } } return primes; } //... }
The JoinPrimes class consolidates the result of the sub intervals into a single result.
public class JoinPrimes implements Conquer<Primes, Primes> { public Primes conquer(Primes[] p, SkeletonSystem system) { Primes conquered = new Primes(); for (Primes param : p) { conquered.list.addAll(param.primes); } Collections.sort(conquered.primes); return conquered; } }
The instantiation of the framework is performed in the following way
Skeleton<Interval,Primes> root = ...; //Step 1 EnvironmentFactory enviroment = new MultiThreadedEnvironment(2); Calcium calcium = new Calcium(enviroment); Stream<Interval, Primes> stream = calcium.newStream(root);
Vector<CalFuture<Primes>> futures = new Vector<Future<Primes>>(); futures.add(stream.input(new Interval(1,6400,300))); futures.add(stream.input(new Interval(1,100,20))); futures.add(stream.input(new Interval(1,640,64))); calcium.boot(); //begin the evaluation
for(CalFuture<Primes> future:futures){ Primes res=future.get(); System.out.print(res.list); } calcium.shutdown(); //release the resources
Skeletons can be composed in the following way:
S :=
farm(S)|pipe(S1,S2)|if(cond,S1,S2)|while(cond,S)|for(i,S)|dac(cond,div,S,conq)|map(div,
S, conq)|fork(div, S1...SN, conq)|seq(f)
Each skeleton represents a different parallelism described as follows:
Farm , also known as Master-Slave , corresponds to the task replication pattern where a specific function must be executed over a set of slaves.
Pipe corresponds to computation divided in stages were the stage n+1 is always executed after the n-th stage.
If corresponds to a decision pattern, were a choice must be made between executing two functions.
While corresponds to a pattern were a function is executed while a condition is met.
For corresponds to a pattern were a function is executed a specific number of times.
Divide and Conquer corresponds to a pattern were a problem is divided into several smaller problems while a condition is met. The tasks are solved and then solutions are then conquered into a single final solution for the original problem.
Map corresponds to a pattern were the same function is applied to several parts of a problem: single instruction multiple data.
Fork is like map, but models multiple data multiple instruction.
Seq is used to wrap muscle functions into terminal skeletons.
The Skeleton's API is the following:
class Farm<P,R> implements Skeleton<P,R> { public Farm(Skeleton<P,R> child); } class Pipe<P,R> implements Skeleton<P,R> { <X> Pipe(Skeleton<P,X> s1, Skeleton<X,R> s2); } class If<P,R> implements Skeleton<P,R> { public If(Condition<P> cond, Skeleton<P,R> ifsub, Skeleton<P,R> elsesub); } class While<P> implements Skeleton,P> { public While(Condition<P> cond, Skeleton<P,P> child); } class For<P> implements Skeleton<P,P> { public For(int times, Skeleton,P> sub); } class Map<P,R> implements Skeleton<P,R> { public <X,Y> Map(Divide<P,X> div, Skeleton<X,Y> sub, Conquer<Y,R> conq); } class Fork<P,R> implements Skeleton<P,R> { public <X,Y> Fork(Divide<P,X> div, Skeleton<X,Y>... args, Conquer<Y,R> conq); } class DaC<P,R> implements Skeleton<P,R> { public DaC(Divide<P,P> div, Condition<P> cond, Skeleton<P,R> sub, Conquer<R,R> conq); } class Seq<P,R> implements Skeleton<P,R> { public Seq(Execute<P,R> secCode); }
Where the muscle functions are user provided, and must implement the following interfaces:
interface Execute<P,R> extends Muscle<P,R> { public R exec(P param); } interface Condition<P> extends Muscle<P,Boolean> { public boolean evalCondition(P param); } interface Divide<P,X> extends Muscle<P,X[]> { public List<X> divide(P param); } interface Conquer<Y,R> extends Muscle<Y[],R> { public R conquer(Y[] param); }
Calcium can be used with different execution evironments. This means, that an application implemented in one environment is capable of running on a different one. There are currently 3 supported environments: MultiThreadedEnvironment (stable), ProActiveEnvironment (stable), ProActiveSchedulerEnvironment (beta).
The MultithreadEnvironment is the simplest execution environment. It uses threads to execute tasks, and can thus be used efficiently on multiprocessor machines. It is also an easier environment to debug applications, before submitting them to a distributed environment.
Environment environment = new EnvironmentFactory.newMultiThreadedEnvironment(2); //Number of threads to use.
The ProActiveEnvironment is the current stable way of executing a skeleton program on a distributed, but controlled, execution environment. It is mostly suitable for short lived distributed applications, as it does not yet support a suitable fault-tolerance mechanism. The ProActiveEnvironment uses ProActive Deployment Descriptos to acquire computation nodes, and active object to communicate and distribute the program to the computation nodes.
String descriptorPath = "/home/user/descriptor.xml"; Environment environment = EnvironmentFactory.newProActiveEnvironment(descriptor);
To instantiate the environment, a descriptor deployment's path must be specified. The ProActiveEnvironment requires that the descriptor file provides the following contractual variables:
<variables> <descriptorVariable name="SKELETON_FRAMEWORK_VN" value="framework" /> <descriptorVariable name="INTERPRETERS_VN" value="interpreters" /> <programDefaultVariable name="MAX_CINTERPRETERS" value="3"/> </variables>
Where the variables represent:
SKELETON_FRAMEWORK_VN The virtual-node pointing to the node where the service active object will be placed. This node should be stable and underloadad, since it will hold important objects like the TaskPool and the FileServer.
INTERPRETERS_VN The virtual-node pointing to the nodes that will be used for computation. It is important that this nodes can communicate with the nodes identified in SKELETON_FRAMEWORK_VN.
MAX_CINTERPRETERS Is an optional variable, and represents the number of maximum tasks that can be queued on an interpreter. By default this value is 3 , but can be overriden using this variable.
The new GCM Deployment mechanism is also supported through the following factory mechanism:
String descriptorPath = "/home/user/GCMApplication.xml"; Environment environment = EnvironmentFactory.newProActiveEnviromentWithGCMDeployment(descriptor);
The ProActiveSchedulerEnvironment is suitable for executing long running applications, and uses the ProActive Scheduler at the lower level to handle the distribution and execution of tasks. Currently, tasks requiring file access and transfer are not supported using this environment, but will be supported in future releases.
Environment environment = ProActiveSchedulerEnvironment.factory("schedulerURL","user", "password");
To use the scheduler, a URL with its location, a username and a password must be provided.
The ProActiveSchedulerEnvironment is currently under development and as such represents an unstable version of the framework, thus it is located in the following package of the ProActive distribution:
package org.objectweb.proactive.extra.calcium.environment.proactivescheduler;
Calcium provides a transparent support for file data access, based on the Proxy Pattern. The BLAST example is implemented using this support in:
package org.objectweb.proactive.extensions.calcium.examples.blast;
The goal of the file transfer support is to minimize the intrusion of non-functional code inside muscle functions, such as code for moving downloading, uploading or moving data.
The workspace is an abstraction that can be used to create File s from inside muscle functions. The framework guarantees that: 1. Any File created in the workspace will have read/write permissions; 2. if a File is passed as parameter to other muscle functions, the File will be locally available when another muscle function access it. Where File corresponds to the standard java type java.io.File .
/** * This method is used to get a reference on a file inside the workspace. * * Note that this is only a reference, and can point to an unexistent File. * ie. no File is actually created by invoking this method. * * @param path The path to look inside the workspace. * @return A reference to the path inside the workspace. */ public File newFile(String name); /** * Copies a File into the workspace, and returns * a reference on the new File. * * @param src The original location of the file. * @return A reference to the file inside the workspace. * @throws IOException */ public File copyInto(File src) throws IOException; /** * Downloads the file specified by the URL and places a copy inside * the workspace. * * @param src The location of the original file * @return A reference to the file inside the workspace. * @throws IOException */ public File copyInto(URL src) throws IOException; /** * This method returns true if a file with this name exists in the work space. * * @return true if the file exists, false otherwise. */ public boolean exists(File path); /** * This method returns a list of the files currently available on the root * of the workspace. * * @return The list of files that are currently held in the workspace. */ public File[] listFiles();
File s are treated in a deep-copy fashion, analogous with parameters/results of muscle functions. That is to say, when a File reference is passed from one muscle function to the next, the File 's data is copied. From this point modifications made on on the File by different muscle functions are made on copies of the File 's data.
Muscle functions can be annotated to improve the file transfer performance. By annotating a muscle function, the Calcium framework will try to pre-fetch files matching the annotation, and passed as parameters to the function in advance, before the function is executed. The current supported annotation can fetch a file based on its name, and size:
public @interface PrefetchFilesMatching { String name() default "[unassigned]"; long sizeSmallerThan() default Long.MIN_VALUE; long sizeBiggerThan() default Long.MAX_VALUE; }
It is important to note that annotations only represent an optimization, and are not required for the File support to work.
The following example is taken from the BLAST skeleton program. The muscle function presented here conquers the results of several parallel BLASTs into a single file. First, the annotation is used to try and pre-fetch files that begging with the prefix "merged". Then, a new File is created in the workspace to hold the merged files. Then a mergeFiles function is called to merge the results, and is not detailed here since it is specific to BLAST. Finally the new File holding the merged results is returned.
@PrefetchFilesMatching(name = "merged.*") public class ConquerResults implements Conquer<File, File> { public File conquer(File[] param, SkeletonSystem system) throws Exception { WSpace wspace = system.getWorkingSpace(); //Create a reference on the result merged file File merged = wspace.newFile("merged.result" + ProActiveRandom.nextPosInt()); //Merge the files mergeFiles(merged, param); //Return the result return merged; } //... mergeFiles(File, File[]) is not shown in this example }
The input and output is transparent as long as the File type class is used to reference Files. All File type referenced from inside the input parameter, are imported into the Calcium framework when submitting the parameter into the stream.
Stream<File, File> stream = ...; CalFuture<File> future = stream.input(new File("/home/user/input.data")); //input.data is copied and imported into the framework. ... File result = future.get(); //The data referenced by result is downloaded into the local machine before result is returned.
Then when the result is available, all File typed referenced in the result object are copied into the local machine, before the result is returned to the user.
There are two types of performance statistics.
These statistics refer to the global state of the framework by providing state information. The tasks can be in three different states: ready for execution, processing , waiting for other tasks to finish, and finished (ready to be collected by the user). The statistics corresponding to these states are:
Number of tasks on each state.
Average time spent by the tasks on each state.
Statistics for a specific moment can be directly retrieved from the Calcium instance:
StatsGlobal statsGlobal = calcium.getStatsGlobal()
An alternative is to create a monitor that can be performe functions based on the statistics. In the following example we activate a simple logger monitor that prints the statistics every 5 seconds.
Monitor monitor= new SimpleLogMonitor(calcium, 5);
monitor.start();
...
monitor.stop();
This statistics are specific for each result obtained from the framework. They provide information on how the result was obtained:
Execution time for each muscle of the skeleton.
Time spent by this task in the ready , processing , waiting and executing state. Also, the wallclock and computation time are provided.
Data parallelism achieved: tree size, tree depth, number of elements in the tree.
© 1997-2008 INRIA Sophia Antipolis All Rights Reserved