| Prev | Part IV. Programming With High Level APIs Chapter 13. Master-Worker API |
 |
Next |
Master-Worker computations are the most common case of distributed computations. They are suited well for embarrassingly parallel problems, in which the problem is easy to segment into a very large number of parallel tasks, and no essential dependency (or communication) between those parallel tasks are required.
The main goal of the ProActive Master-Worker API is to provide an easy to use framework for parallelizing embarrassingly parallel applications.
The main features are:
Automatic tasks scheduling for the Workers.
Automatic load-balancing between the Workers
Automatic fault-tolerance mechanism (i.e. when a Worker is missing, the task is rescheduled)
Very simple mechanism for solution gathering
All the internal concepts of ProActive are hidden from the user
Open and extensible API
The usage of the Master-Worker API is simple and consists of four steps:
Deployment of the Master-Worker framework.
Task definition and submission
Results gathering
Release of acquired resources
Before using the Master-Worker, launch the examples, or write your own code, it is very useful to enable the maximum logging information to have a deeper look at how the API works. In order to do that you'll need to add the following lines in the proactive-log4j file that you are using:
log4j.logger.proactive.masterworker = DEBUG log4j.additivity.proactive.masterworker = false
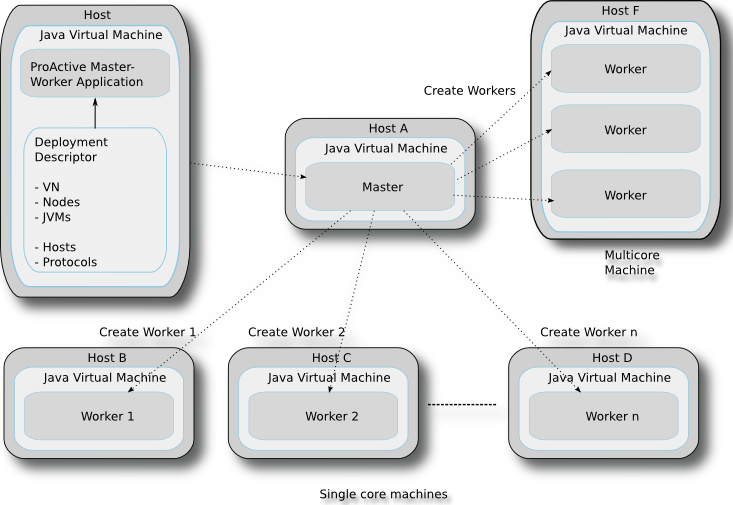
When creating the master the user application has the possibility to create either a local master (on the machine the user application is running on) or a remote master. Regardless of the way it is created the active object instantiation is transparent. The deployment process can be controlled by using the deployment descriptors.
The deployment of the Master-Worker framework relies on the ProActive deployment mechanism. In order to deploy a set of workers, the master needs either:
a ProActive deployment descriptor to be used by the master to deploy its resources
a set of already deployed ProActive resources like a VirtualNode object or a Collection of Node objects
For a full explanation of the ProActive deployment mechanism and of ProActive deployment descriptors, see Chapter 19, XML Deployment Descriptors .
The figure represents one case of deployment as it is possible to have several workers on a single core machine each running in its own independent thread, one worker in its own JVM on a multicore machine, or workers deployed on the machine running the master. The worker-JVM-machine mappings depend on the deployment descriptor. The only restriction is that each Worker is always started in its own Node. However, from the user application perspective, this is transparent as the Master performes communication and load balancing automatically. In the following figures we will show only the case of several single core machines as the same principles apply regardless of machine type.
In order to create a local master we use a constructor without parameters
master = new ProActiveMaster<A, Integer>();
Using this constructor, a master will be created in the current JVM, the master will share CPU
usage and memory with the user JVM. This master will compute tasks of type
A
and will produce
Integer
objects as a results.
In order to create a remote master the following constructors can be used:
/** * Creates a remote master that will be created on top of the given Node <br> * Resources can be added to the master afterwards * * @param remoteNodeToUse this Node will be used to create the remote master */ public ProActiveMaster(Node remoteNodeToUse)
/** * Creates an empty remote master that will be created on top of the given Node with an initial worker memory * * @param remoteNodeToUse this Node will be used to create the remote master * @param memoryFactory factory which will create memory for each new workers */ public ProActiveMaster(Node remoteNodeToUse, MemoryFactory memoryFactory)
Using either of these constructors, a master will be created in the specified remote resource(JVM), the master will share CPU usage and memory with existing running applications on the remote host. The mechanism in use to deploy the master remotely is the ProActive deployment mechanism (see Chapter 19, XML Deployment Descriptors for further details).
Now that the master has been created, resources (Workers) must be added to it. The following methods can be used for creating workers:
/** * Adds the given Collection of nodes to the master <br/> * @param nodes a collection of nodes */ void addResources(Collection<Node> nodes); /** * Adds the given descriptor to the master<br> * Every virtual nodes inside the given descriptor will be activated<br/> * @param descriptorURL URL of a deployment descriptor * @throws ProActiveException if a problem occurs while adding resources */ void addResources(URL descriptorURL) throws ProActiveException; /** * Adds the given descriptor to the master<br> * Only the specified virtual node inside the given descriptor will be activated <br/> * @param descriptorURL URL of a deployment descriptor * @param virtualNodeName name of the virtual node to activate * @throws ProActiveException if a problem occurs while adding resources */ void addResources(URL descriptorURL, String virtualNodeName) throws ProActiveException;
The first two methods will tell the master to create workers on already deployed ProActive resources. The last two methods will ask the master to deploy resources using a ProActive descriptor and to create workers on top of these resources. For a complete explanation of ProActive's deployment mechanism, please refer to Chapter 19, XML Deployment Descriptors .
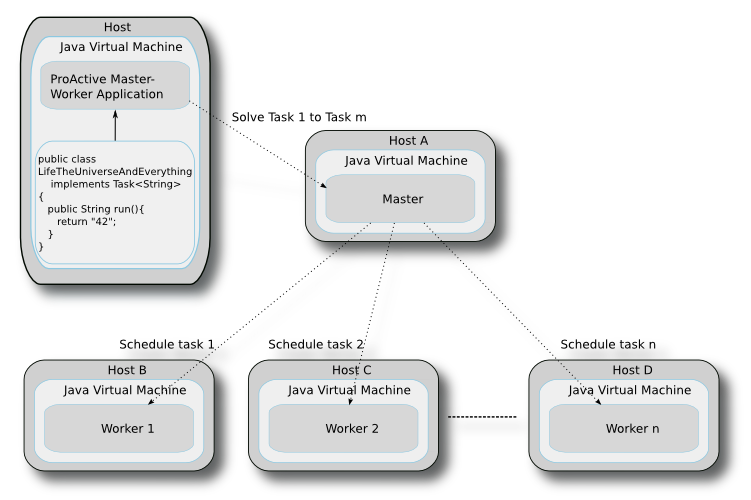
Tasks are submitted through classes that implement the
Task
interface. In this interface, the unique method
run
will contain the code to be executed remotely. After the tasks have been submitted to the master, the
master will dispatches them automatically to the workers.
![[Warning]](images/warning.png) |
Warning |
|---|---|
|
When a Java object implementing the Task interface (i.e. a user task) is submitted to the master, the object will be deep-copied to the master. In consequence, every referenced objects will also be copied. When tasks are submitted to the remote workers, the user task objects will be serialized and sent though the network. As a consequence, information which has only local meaning will be lost (database connections, references to etc.) |
The task interface is
org.objectweb.proactive.extensions.masterworker.interfaces.Task
/** * Definition of a Task (to be executed by the framework) <br/> * @author The ProActive Team * * @param <R> the result type of this task */ @PublicAPI public interface Task<R extends Serializable> extends Serializable { /** * A task to be executed<br/> * @param memory access to the worker memory * @return the result * @throws Exception any exception thrown by the task */ R run(WorkerMemory memory) throws Exception; }
Users need to implement the
Task
interface to define their tasks. The
WorkerMemory
parameter is explained in the
Advanced Usage
section.
The tasks are submitted to the master which in turn sends them to the workers. The following method submits the tasks:
/** * Adds a list of tasks to be solved by the master <br/> * <b>Warning</b>: the master keeps a track of task objects that have been submitted to it and which are currently computing.<br> * Submitting two times the same task object without waiting for the result of the first computation is not allowed. * @param tasks list of tasks */ void solve(List<T> tasks);
|
Warning |
|---|---|
|
The master keeps a track of task objects that have
been submitted to it and which are currently computing.
Submitting twice the same task object without
waiting for the result of the first computation will produce a
|
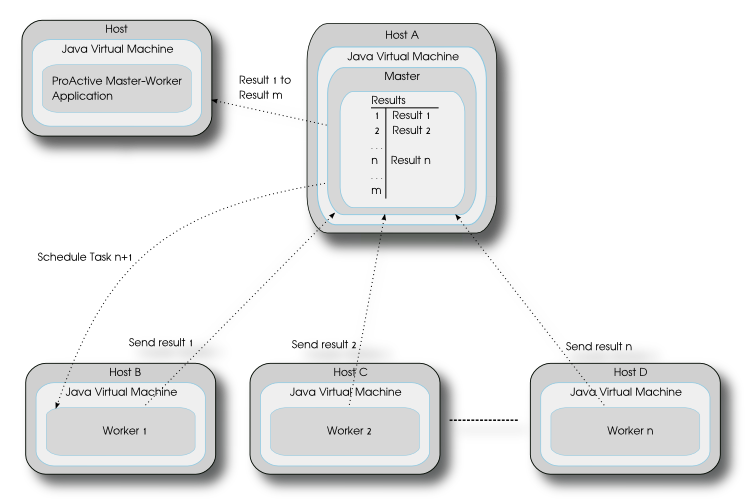
Results are collected by the master when the calculations are complete.
There are two ways of waiting for the results.The users application can either wait until one or every result is available (the thread blocks until the results are available) or ask the master for result availability and continue until the results are finally available. In the second case the application thread does not block while the results are computed.
The results can be received in two modes:
Completion order mode (default) : in this mode, user applications will receive the results in an unspecified order, depending on tasks completion order.
Submission order mode : in this mode, user applications will receive the results in the same order as the task submitted to the master.
Result reception order can be switched from Completion order to Submission order using the following method :
/** * Sets the current ordering mode <br/> * If reception mode is switched while computations are in progress,<br/> * then subsequent calls to waitResults methods will be done according to the new mode.<br/> * @param mode the new mode for result gathering */ void setResultReceptionOrder(OrderingMode mode);
The default mode of the Master-Worker API is Completion order. The mode can be switched dynamically, which means that subsequent calls to wait methods (see below), will be done according to the new mode.
Five methods can be used in order to collect results:
The first three methods will block the current thread until the corresponding results are available. If an exception occurs during the execution of one task, this exception will be thrown back to the user by the wait method.
The fourth method will give information on results availability but will not block the user thread.
The last method will tell when the user has received every result for the tasks previously submitted.
/** * Wait for all results, will block until all results are computed <br> * The ordering of the results depends on the result reception mode in use <br> * @return a collection of objects containing the result * @throws org.objectweb.proactive.extensions.masterworker.TaskException if a task threw an Exception */ List<R> waitAllResults() throws TaskException; /** * Wait for the first result available <br> * Will block until at least one Result is available. <br> * Note that in SubmittedOrder mode, the method will block until the next result in submission order is available<br> * @return an object containing the result * @throws TaskException if the task threw an Exception */ R waitOneResult() throws TaskException; /** * Wait for at least one result is available <br> * If there are more results availables at the time the request is executed, then every currently available results are returned * Note that in SubmittedOrder mode, the method will block until the next result in submission order is available and will return * as many successive results as possible<br> * @return a collection of objects containing the results * @throws TaskException if the task threw an Exception */ List<R> waitSomeResults() throws TaskException; /** * Wait for a number of results<br> * Will block until at least k results are available. <br> * The ordering of the results depends on the result reception mode in use <br> * @param k the number of results to wait for * @return a collection of objects containing the results * @throws TaskException if the task threw an Exception */ List<R> waitKResults(int k) throws TaskException; /** * Tells if the master is completely empty (i.e. has no result to provide and no tasks submitted) * @return the answer */ boolean isEmpty(); /** * Returns the number of available results <br/> * @return the answer */ int countAvailableResults();
/** * Terminates the worker manager and (eventually free every resources) <br/> * @param freeResources tells if the Worker Manager should as well free the node resources */ void terminate(boolean freeResources);
One single method is used to terminate the master. A boolean parameter tells the master to free resources or not (i.e. terminate remote JVMs).
At regular intervals, the Master sends a "ping" message to every Worker to check if they are reachable. The Ping period configuration parameter is the period in millisecond between two "ping" messages. The default value of this parameter is 10000 (which corresponds to 10 seconds).
In order to change this default value, the method described underneath can be called :
/** * Sets the period at which ping messages are sent to the workers <br/> * @param periodMillis the new ping period */ void setPingPeriod(long periodMillis);
If the Master does not receive an answer for the ping it will remove the Worker from its list and reassign the tasks the Worker has been assigned.
The Master-Worker API's internal scheduling mechanism is quite simple as it is based on a pulling strategy. When a worker has no more task to run, it asks the master for new tasks. The master usually gives a worker one task at a time, except the first time the worker asks for a task and each time the worker has no more tasks to compute. In this case, the master will do a flooding, by giving to worker as many tasks as the configurable parameter of the same name states. The default value of this parameter is 2, as it is expected to have at least twice as many tasks as workers. This mechanism is meant to avoid having idle workers waiting for new tasks all the time. The value of the flooding parameter should depend on how big your tasks are. A lot of small tasks should lead to a high flooding value (>10) where a small number of big tasks should lead to a small value (1-5).
Use the following method to change the flooding parameter :
/** * Sets the number of tasks initially sent to each worker * default is 2 tasks * @param number_of_tasks number of task to send */ void setInitialTaskFlooding(final int number_of_tasks);
The Worker Memory purpose is to allow users to store and retrieve data from a Worker's address space . The typical use case is the Master-Worker API computation if an iterative process. An iterative process consists generally of an initialization step 0, followed by n computation steps, where step n needs the results of step n-1. The initialization steps often requires that a large amount of information is "loaded" into the worker. Without the worker memory access, this information would be lost at each step of the iteration, which means that the initialization step 0 needs to be done at step 1,2, ... n, etc...
The Worker Memory lets you send some initial memory content when workers are initialized. Later on, when tasks are executed, workers can have access to their memory and save or load data from it. Please note that this memory is not at all what is called a "shared memory". A shared memory would mean that the same memory would be shared by all workers. Here, each worker has its own private memory, and if a worker modifies its memory, the memory of other workers will not be affected.
The Worker memory structure is very simple: it consists of <key, value> associations. A java object value is therefore saved in the memory with the given name, and this name will be needed to retrieve the value later on.
The Worker Memory API consists of three methods save , load , and erase . The interface to the worker memory is available when running a Task as a parameter of the run method. The user can use this interface to save, load or erase objects in the local worker's memory. Below is the detailed WorkerMemory interface:
/** * This interface gives access to the memory of a worker, a task can record data in this memory under a specific name. <br/> * This data could be loaded later on by another task <br/> * @author The ProActive Team * */ @PublicAPI public interface WorkerMemory { /** * Save data under a specific name * @param name name of the data * @param data data to be saved */ void save(String name, Object data); /** * Load some data previously saved * @param name the name under which the data was saved * @return the data */ Object load(String name); /** * Erase some data previously saved * @param name the name of the data which need to be erased */ void erase(String name); }
A user can store data in the Workers' memory either when :
Workers are created remotely
A task is run on the Worker.
Usage of the first mechanism is done by providing a list of <key, value> pairs (Map) to the constructors of the ProActiveMaster class. Every constructors detailed above have a version including this extra parameter. The given list will be the initial memory of every Workers created by the master.
Usage of the second mechanism is done by using the WorkerMemory parameter in the Task interface's run method. In contradiction with the first method, only the Worker currently running the Task will store the given data.
This very simple example computes PI using the Monte-Carlo method. The Monte-Carlo methods groups under
the same name method which solves a problem by generating random numbers and examining how a fraction of the
generated numbers follow certain patterns. The method can be used to obtain numerical results for problems
which would be hard to solve through analytical methods. The complete example is available, along with more
complex ones in the package
org.objectweb.proactive.examples.masterworker
The task randomly creates a set of points belonging to the [0, 1[x[0, 1[ interval and tests how many points are inside the unit circle. The number of points inside the unit circle allow us to calculate the value of PI with an arbitrary precision. The more points generated the better the accuracy for PI.
/** * Task which creates randomly a set of points belonging to the [0, 1[x[0, 1[ interval<br> * and tests how many points are inside the uniter circle. * @author The ProActive Team * */ public static class ComputePIMonteCarlo implements Task<Long> { /** * */ public ComputePIMonteCarlo() { } public Long run(WorkerMemory memory) throws Exception { long remaining = NUMBER_OF_EXPERIENCES; long successes = 0; while (remaining > 0) { remaining--; if (experience()) { successes++; } } return successes; } public boolean experience() { double x = Math.random(); double y = Math.random(); return Math.hypot(x, y) < 1; } }
In the main method the master is created and resources are added using a deployment descriptor .
// creation of the master ProActiveMaster<ComputePIMonteCarlo, Long> master = new ProActiveMaster<ComputePIMonteCarlo, Long>(); // adding resources master.addResources(PIExample.class.getResource("MWApplication.xml"));
After the master is created the tasks are created and submitted to the master.
// defining tasks Vector<ComputePIMonteCarlo> tasks = new Vector<ComputePIMonteCarlo>(); for (int i = 0; i < NUMBER_OF_TASKS; i++) { tasks.add(new ComputePIMonteCarlo()); } // adding tasks to the queue master.solve(tasks);
After the task submission the results are gathered and displayed.
// waiting for results List<Long> successesList = master.waitAllResults(); // computing PI using the results long sumSuccesses = 0; for (long successes : successesList) { sumSuccesses += successes; } double pi = (4 * sumSuccesses) / ((double) NUMBER_OF_EXPERIENCES * NUMBER_OF_TASKS); System.out.println("Computed PI by Monte-Carlo method : " + pi);
Finally, the master is terminated (all resources are freed) and the program exits.
master.terminate(true);
© 1997-2008 INRIA Sophia Antipolis All Rights Reserved