Potential project list¶
This is a list of projects that are interesting for potential contributors who are seriously interested in the PyPy project. They mostly share common patterns - they’re mid-to-large in size, they’re usually well defined as a standalone projects and they’re not being actively worked on. For small projects that you might want to work on, it’s much better to either look at the issue tracker, pop up on #pypy on irc.freenode.net or write to the mailing list. This is simply for the reason that small possible projects tend to change very rapidly.
This list is mostly for having an overview on potential projects. This list is by definition not exhaustive and we’re pleased if people come up with their own improvement ideas. In any case, if you feel like working on some of those projects, or anything else in PyPy, pop up on IRC or write to us on the mailing list.
Make bytearray type fast¶
PyPy’s bytearray type is very inefficient. It would be an interesting task to look into possible optimizations on this.
Implement copy-on-write list slicing¶
The idea is to have a special implementation of list objects which is used when doing myslice = mylist[a:b]: the new list is not constructed immediately, but only when (and if) myslice or mylist are mutated.
Numpy improvements¶
The numpy is rapidly progressing in pypy, so feel free to come to IRC and ask for proposed topic. A not necesarilly up-to-date list of topics is also available.
Improving the jitviewer¶
Analyzing performance of applications is always tricky. We have various tools, for example a jitviewer that help us analyze performance.
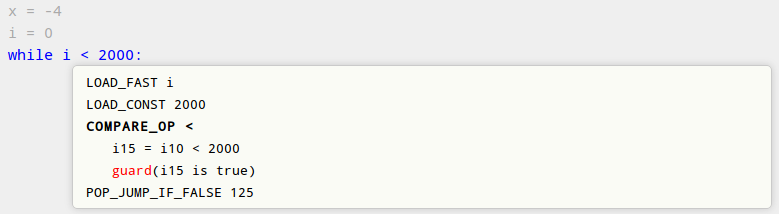
The jitviewer shows the code generated by the PyPy JIT in a hierarchical way, as shown by the screenshot below:
- at the bottom level, it shows the Python source code of the compiled loops
- for each source code line, it shows the corresponding Python bytecode
- for each opcode, it shows the corresponding jit operations, which are the ones actually sent to the backend for compiling (such as i15 = i10 < 2000 in the example)
The jitviewer is a web application based on flask and jinja2 (and jQuery on the client): if you have great web developing skills and want to help PyPy, this is an ideal task to get started, because it does not require any deep knowledge of the internals.
Optimized Unicode Representation¶
CPython 3.3 will use an optimized unicode representation which switches between different ways to represent a unicode string, depending on whether the string fits into ASCII, has only two-byte characters or needs four-byte characters.
The actual details would be rather different in PyPy, but we would like to have the same optimization implemented.
Or maybe not. We can also play around with the idea of using a single representation: as a byte string in utf-8. (This idea needs some extra logic for efficient indexing, like a cache.)
Translation Toolchain¶
- Incremental or distributed translation.
- Allow separate compilation of extension modules.
Various GCs¶
PyPy has pluggable garbage collection policy. This means that various garbage collectors can be written for specialized purposes, or even various experiments can be done for the general purpose. Examples:
- A garbage collector that compact memory better for mobile devices
- A concurrent garbage collector (a lot of work)
- A collector that keeps object flags in separate memory pages, to avoid un-sharing all pages between several fork()ed processes
STM (Software Transactional Memory)¶
This is work in progress. Besides the main development path, whose goal is to make a (relatively fast) version of pypy which includes STM, there are independent topics that can already be experimented with on the existing, JIT-less pypy-stm version:
- What kind of conflicts do we get in real use cases? And, sometimes, which data structures would be more appropriate? For example, a dict implemented as a hash table will suffer “stm collisions” in all threads whenever one thread writes anything to it; but there could be other implementations. Maybe alternate strategies can be implemented at the level of the Python interpreter (see list/dict strategies, pypy/objspace/std/{list,dict}object.py).
- More generally, there is the idea that we would need some kind of “debugger”-like tool to “debug” things that are not bugs, but stm conflicts. How would this tool look like to the end Python programmers? Like a profiler? Or like a debugger with breakpoints on aborted transactions? It would probably be all app-level, with a few hooks e.g. for transaction conflicts.
- Find good ways to have libraries using internally threads and atomics, but not exposing threads to the user. Right now there is a rough draft in lib_pypy/transaction.py, but much better is possible. For example we could probably have an iterator-like concept that allows each loop iteration to run in parallel.
Introduce new benchmarks¶
We’re usually happy to introduce new benchmarks. Please consult us before, but in general something that’s real-world python code and is not already represented is welcome. We need at least a standalone script that can run without parameters. Example ideas (benchmarks need to be got from them!):
- hg
Embedding PyPy and improving CFFI¶
PyPy has some basic embedding infrastructure. The idea would be to improve upon that with cffi hacks that can automatically generate embeddable .so/.dll library
Optimising cpyext (CPython C-API compatibility layer)¶
A lot of work has gone into PyPy’s implementation of CPython’s C-API over the last years to let it reach a practical level of compatibility, so that C extensions for CPython work on PyPy without major rewrites. However, there are still many edges and corner cases where it misbehaves, and it has not received any substantial optimisation so far.
The objective of this project is to fix bugs in cpyext and to optimise several performance critical parts of it, such as the reference counting support and other heavily used C-API functions. The net result would be to have CPython extensions run much faster on PyPy than they currently do, or to make them work at all if they currently don’t. A part of this work would be to get cpyext into a shape where it supports running Cython generated extensions.