Chapter 6
Designing the Replication Process
Replicating your directory contents increases the availability and performance of your directory. In chapter 4 and chapter 5, you made decisions about the design of your directory tree and your directory topology. This chapter addresses the physical and geographical location of your data and, specifically, how to use replication to ensure your data is available when and where you need it.
This chapter discusses uses for replication and offers advice on designing a replication strategy for your directory environment. It contains the following sections:
- Introduction to Replication (page 109)
- Common Replication Scenarios (page 114)
- Defining a Replication Strategy (page 123)
- Using Replication with Other Directory Features (page 133)
Introduction to Replication
Replication is the mechanism that automatically copies directory data from one Red Hat Directory Server (Directory Server) to another. Using replication, you can copy any directory tree or subtree (stored in its own database) between servers. The Directory Server that holds the master copy of the information will automatically copy any updates to all replicas.
Replication enables you to provide a highly available directory service and to distribute your data geographically. In practical terms, replication brings the following benefits:
- Fault tolerance/Failover - By replicating directory trees to multiple servers, you can ensure your directory is available even if some hardware, software, or network problem prevents your directory client applications from accessing a particular Directory Server. Your clients are referred to another Directory Server for read and write operations. To support write failover, you must have a multi-master replication environment.
- Load balancing - By replicating your directory tree across servers, you can reduce the access load on any given machine, thereby improving server response time.
- Higher performance and reduced response times - By replicating directory entries to a location close to your users, you can vastly improve directory response times.
- Local data management - Replication allows you to own and manage data locally while sharing it with other Directory Servers across your enterprise.
Before defining a replication strategy for your directory information, you should understand how replication works. This section describes:
Replication Concepts
When you consider replication, you always start by making the following fundamental decisions:
- What information you want to replicate.
- Which server (or servers) holds the master copy, or read-write replica, of that information.
- Which server (or servers) holds the read-only copy, or read-only replica, of the information.
- What should happen when a read-only replica receives an update request; that is, to which server should it refer the request.
These decisions cannot be made effectively without an understanding of how the Directory Server handles these concepts. For example, when you decide what information you want to replicate, you need to know what is the smallest replication unit that the Directory Server can handle. The following sections contain definitions of concepts used by the Directory Server. This provides a framework for thinking about the global decisions you need to make.
Unit of Replication
The smallest unit of replication is a database. This means that you can replicate an entire database but not a subtree within a database. Therefore, when you create your directory tree, you must take your replication plans into consideration. For more information on how to set up your directory tree, refer to chapter 4, "Designing the Directory Tree."
The replication mechanism also requires that one database correspond to one suffix. This means that you cannot replicate a suffix (or namespace) that is distributed over two or more databases.
Read-Write Replica/Read-Only Replica
A database that participates in replication is defined as a replica. There are two kinds of replicas: read-write or read-only. The read-write replicas contain master copies of directory information and can be updated. Read-only replicas refer all update operations to read-write replicas.
Supplier/Consumer
A server that holds a replica that is copied to a replica on a different server is called a supplier for that replica. A server that holds a replica that is copied from a different server is called a consumer for that replica. Generally, the replica on the supplier server is a read-write replica, and the one on the consumer server is a read-only replica. There are exceptions to this statement:
- In the case of cascading replication, the hub supplier holds a read-only replica that it supplies to consumers. For more information, refer to "Cascading Replication," on page 119.
- In the case of multi-master replication, the suppliers are suppliers and consumers for the same read-write replica. For more information, refer to "Multi-Master Replication," on page 115.
For any particular replica, the supplier server must:
- Respond to read requests and update requests from directory clients.
- Maintain state information and a changelog for the replica.
- Initiate replication to consumer servers.
The supplier server is always responsible for recording the changes made to the read-write replicas that it manages, so the supplier server makes sure that any changes are replicated to consumer servers.
Any time a request to add, delete, or change an entry is received by a consumer server, the request is referred to a supplier for the replica. The supplier server performs the request, then replicates the change.
In the special case of cascading replication, the hub supplier must:
- Respond to read requests.
- Refer update requests to a supplier server for the replica.
- Initiate replication to consumer servers.
For more information on cascading replication, refer to "Cascading Replication," on page 119.
Changelog
Every supplier server maintains a changelog. A changelog is a record that describes the modifications that have occurred on a replica. The supplier server then replays these modifications on the replicas stored on consumer servers or on other suppliers in the case of multi-master replication.
When an entry is modified, a change record describing the LDAP operation that was performed is recorded in the changelog.
Replication Agreement
Directory Servers use replication agreements to define replication. A replication agreement describes replication between one supplier and one consumer. The agreement is configured on the supplier server. It identifies:
- The database to replicate.
- The consumer server to which the data is pushed.
- The times that replication can occur.
- The DN that the supplier server must use to bind (called the supplier bind DN).
- How the connection is secured (SSL, client authentication, or no SSL).
- Any attributes that will not be replicated (see "Fractional Replication," on page 125).
Data Consistency
Consistency refers to how closely the contents of replicated databases match each other at a given point in time. When you set up replication between two servers, part of the configuration is to schedule updates. The supplier server always determines when consumer servers need to be updated and initiates replication.
Directory Server offers the option of keeping replicas always synchronized or of scheduling updates for a particular time of day or day in the week. The advantage of keeping replicas always in sync is obviously that it provides better data consistency. The cost is the network traffic resulting from the frequent update operations. This solution is the best in cases where:
- You have a reliable high-speed connection between servers.
- The client requests serviced by your directory are mainly search, read, and compare operations, with relatively few update operations.
In cases where you can afford to have looser consistency in data, you can choose the frequency of updates that best suits your needs or lowers the affect on network traffic. This solution is the best in cases where:
- You have unreliable or intermittently available network connections (such as a dial-up connection to synchronize replicas).
- The client requests serviced by your directory are mainly update operations.
- You need to reduce the communication costs.
In the case of multi-master replication, the replicas on each supplier are said to be loosely consistent because at any given time, there can be differences in the data stored on each supplier. This is true, even when you have selected to always keep replicas in sync, for two reasons:
- There is a latency in the propagation of update operations between suppliers.
- The supplier that serviced the update operation does not wait for the second supplier to validate it before returning an "operation successful" message to the client.
Common Replication Scenarios
You need to decide how the updates flow from server to server and how the servers interact when propagating updates. There are four basic scenarios:
The following sections describe these methods and provide strategies for deciding the method appropriate for your environment. You can also combine these basic scenarios to build the replication topology that best suits your needs.
Single-Master Replication
In the most basic replication configuration, a supplier server copies a replica directly to one or more consumer servers. In this configuration, all directory modifications occur on the read-write replica on the supplier server, and the consumer servers contain read-only replicas of the data.
The supplier server must perform all modifications to the read-write replicas stored on the consumer servers. Figure 6-1, on page 115, shows this simple configuration.
Figure 6-1 Single-Master Replication

|
The supplier server can replicate a read-write replica to several consumer servers. The total number of consumer servers that a single supplier server can manage depends on the speed of your networks and the total number of entries that are modified on a daily basis. However, you can reasonably expect a supplier server to maintain several consumer servers.
Multi-Master Replication
In a multi-master replication environment, master copies of the same information can exist on multiple servers. This means that data can be updated simultaneously in different locations. The changes that occur on each server are replicated to the others. This means that each server plays both roles of supplier and consumer.
When the same data is modified on multiple servers, there is a conflict resolution procedure to determine which change is kept. The Directory Server considers the valid change to be the most recent one.
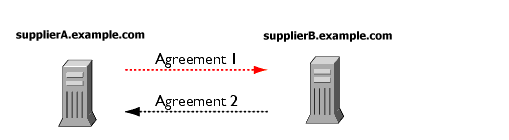
Multiple servers can have master copies of the same data, but, within the scope of a single replication agreement, there is only one supplier server and one consumer. That means that to create a multi-master environment between two supplier servers that share responsibility for the same data, you need to create more than one replication agreement. Figure 6-2 shows the configuration for a two-way multi-master replication.
Figure 6-2 Multi-Master Replication Configuration (Two Suppliers)
|
In the above illustration, supplier A and supplier B each hold a read-write replica of the same data.
To create a multi-master environment between four supplier servers that share responsibility for the same data, you need to create more than four replication agreements. Figure 6-3 and Figure 6-4 illustrate two sample configurations of four-way multi-master replication agreements. Keep in mind that the four suppliers can be configured in different topologies and that there are many parameters that have direct impact on the topology selection.
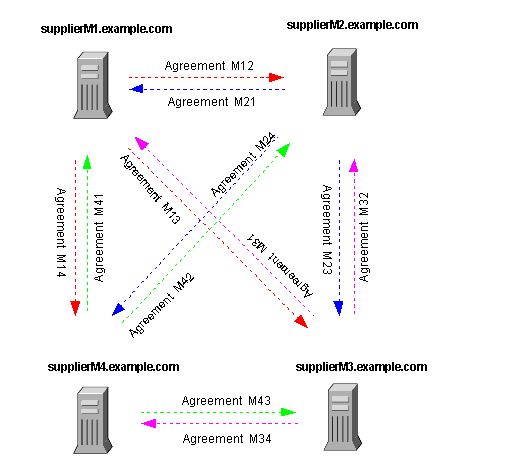
Figure 6-3 illustrates a fully connected mesh topology where all four supplier servers feed data to the other three supplier servers (and to the consumer servers). There are a total of twelve replication agreements among the four supplier servers. This topology provides high server failure tolerance at the expense of high fan-out for every supplier.
Figure 6-3 Multi-Master Replication Configuration (Four Suppliers)
|
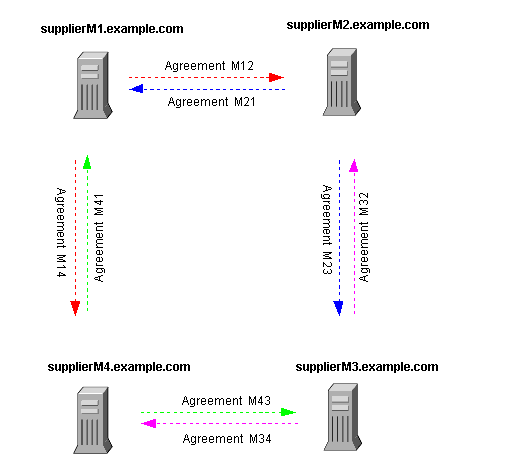
Figure 6-4 illustrates a topology where each supplier server feeds data to two other supplier servers (and to the consumer servers). There are only eight replication agreements among the four supplier servers, as opposed to the twelve agreements shown for the topology in Figure 6-3. The topology shown in Figure 6-4 is beneficial in situations where the possibility of two or more servers failing at the same time is negligible. Because each supplier has only two fan-outs, such a configuration is useful in reducing the network traffic and making the servers less busy.
Figure 6-4 Multi-Master Replication Configuration (Four Suppliers)
|
The total number of supplier servers you can have in any replication environment is limited to four. However, the number of consumer servers that hold the read-only replicas is not limited.
Directory Server supports four-way multi-master replication; that is, replication topologies comprising four supplier servers. |
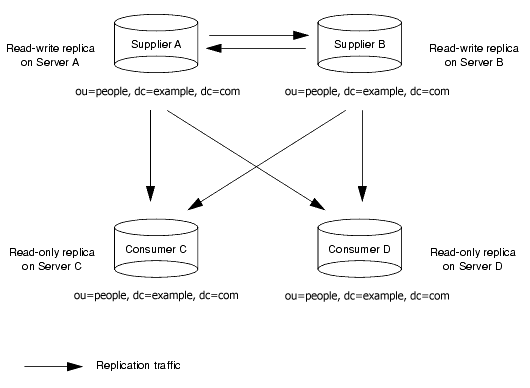
Figure 6-5 shows the replication traffic in an environment with two suppliers (read-write replicas in the illustration), and two consumers (read-only replicas in the illustration). This figure shows that the consumers can be updated by both suppliers. The supplier servers ensure that the changes do not collide.
Figure 6-5 Replication Traffic in a Multi-Master Environment
|
Cascading Replication
In a cascading replication scenario, a hub supplier receives updates from a supplier server and replays those updates on consumer servers. The hub supplier is a hybrid: it holds a read-only replica, like a typical consumer server, and it maintains a changelog like a typical supplier server.
Hub suppliers pass the master data on as they receive them from the original suppliers. For the same reason, when a hub supplier receives an update request from a directory client, it refers the client to the supplier server.
Cascading replication is useful, for example, if some network connections between various locations in your organization are better than others. For example, suppose the master copy of your directory data is in Minneapolis, and you have consumer servers in Saint Cloud as well as Duluth. Suppose your network connection between Minneapolis and Saint Cloud is very good, but your network connection between Minneapolis and Duluth is poor. Then, if your network between Saint Cloud and Duluth is fair, you can use cascaded replication to move directory data from Minneapolis to Saint Cloud to Duluth.
This cascading replication scenario is illustrated in Figure 6-6.
Figure 6-6 Cascading Replication Scenario
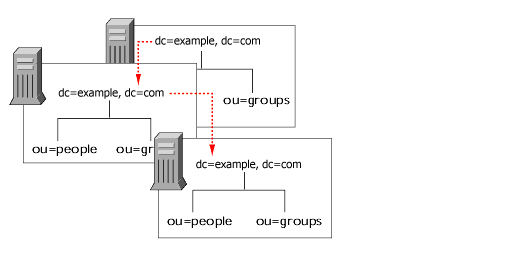
|
The same scenario is illustrated from a different perspective in Figure 6-7, below. It shows how the replicas are configured on each server (read-write or read-only) and which servers maintain a changelog.
Figure 6-7 Replication Traffic and Changelogs in Cascading Replication
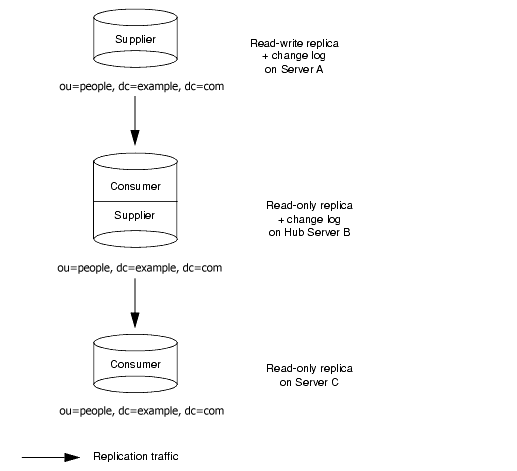
|
Mixed Environments
You can combine any of the scenarios outlined in the previous sections to best fit your needs. For example, you could combine a multi-master configuration with a cascading configuration to produce something similar to the scenario illustrated in Figure 6-8.
Figure 6-8 Combined Multi-Master and Cascading Replication
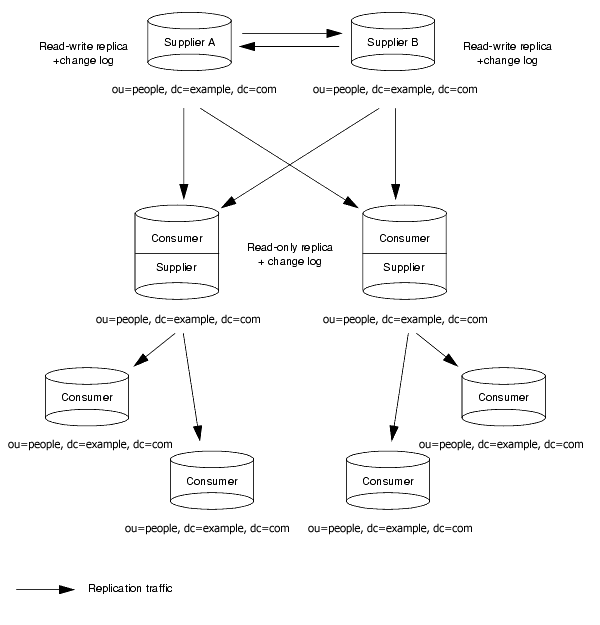
|
Defining a Replication Strategy
The replication strategy that you define is determined by the service you want to provide.
- If you have multiple consumers for different locations or sections of your company or if you have some servers that are insecure, then you should use fractional replication to exclude sensitive or seldom-modified information to maintain data integrity without compromising sensitive information. Fractional replication is described in "Fractional Replication," on page 125.
- If your network is stretched across a wide geographical area, then you will have multiple Directory Servers at multiple sites, with local data masters connected by multi-master replication. The required resources and configuration for wide-area replication are described in "Replication across a Wide-Area Network," on page 126.
- If high availability is your primary concern, you should create a data center with multiple Directory Servers on a single site. You can use single-master replication to provide read-failover and multi-master replication to provide write-failover. How to configure replication for high availability is described in "Using Replication for High Availability," on page 127.
- If local availability is your primary concern, you should use replication to distribute data geographically to Directory Servers in local offices around the world. You can decide to hold a master copy of all information in a single location, such as the company headquarters, or to let local sites manage the parts of the DIT that are relevant for them. The type of replication configuration to set up is described in "Using Replication for Local Availability," on page 128.
- In all cases, you probably want to balance the load of requests serviced by your Directory Servers and avoid network congestion. Strategies for load balancing your Directory Servers and your network are provided in "Using Replication for Load Balancing," on page 128.
To determine your replication strategy, start by performing a survey of your network, your users, your applications, and how they use the directory service you can provide. For guidelines on performing this survey, refer to the following section, "Replication Survey."
Once you understand your replication strategy, you can start deploying your directory. This is a case where deploying your service in stages will pay large dividends. By placing your directory into production in stages, you can get a better sense of the loads that your enterprise places on your directory. Unless you can base your load analysis on an already operating directory, be prepared to alter your directory as you develop a better understanding on how your directory is used.
The following sections describe in more detail the factors affecting your replication strategy:
- Replication Survey
- Replication Resource Requirements
- Fractional Replication
- Replication across a Wide-Area Network
- Using Replication for High Availability
- Using Replication for Local Availability
- Using Replication for Load Balancing
- Example Replication Strategy for a Small Site
- Example Replication Strategy for a Large Site
Replication Survey
The type of information you need to gather from your survey to help you define your replication strategy includes:
- Quality of the LANs and WANs connecting different buildings or remote sites and the amount of available bandwidth.
- Physical location of users, how many users are at each site, and what is their activity.
- The number of applications that access the directory and relative percentage of read/search/compare operations to write operations.
- If your messaging server uses the directory, you need to know how many operations it performs for each email message it handles. Other products that rely on the directory are typically products such as authentication applications or meta-directory applications. For each one, you must find out the type and frequency of operations that are performed in the directory.
- A site that manages human resource databases or financial information is likely to put a heavier load on your directory than a site containing engineering staff that uses the directory for simple telephone book purposes.
Replication Resource Requirements
Using replication requires more resources. Consider the following resource requirements when defining your replication strategy:
- Disk usage - On supplier servers, the changelog is written after each update operation. Supplier servers receiving many update operations may see higher disk usage.
- In addition, as there is a single changelog on every supplier server. If a supplier contains multiple replicated databases, the changelog will be used more frequently, and the disk usage will be even higher.
- Server threads - Each replication agreement consumes one server thread. So, the number of threads available to client applications is reduced, possibly affecting the server performance for the client applications.
- File descriptors - The number of file descriptors available to the server is reduced by the changelog (one file descriptor) and each replication agreement (one file descriptor per agreement).
Fractional Replication
Fractional replication allows the administrator to choose a set of attributes that will not be transmitted from a supplier to the consumer. This means administrators can replicate a database without replicating all the information in it.
Fractional replication is enabled and configured per replication agreement. The exclusion of attributes is applied equally to all entries. As far as the consumer server is concerned, the excluded attributes always have no value. Therefore, a client performing a search against the consumer server will never see the excluded attributes returned. Similarly, should it perform a search that specifies those attributes in its filter, no entries will match.
Fractional replication is particularly useful in these situations:
- Where the consumer server is connected via a slow network, excluding infrequently changed attributes or larger attributes such as jpegPhoto results in less network traffic.
- Where the consumer server is placed on an untrusted network such as the public Internet, excluding sensitive attributes such as telephone numbers provides an extra level of protection that guarantees no access to those attributes even if the server's access control measures are defeated or the machine is compromised by an attacker.
Fractional replication can only be done where the consumer is a read-only replica (dedicated consumer). This condition is enforced at the time the supplier server initiates a replication connection to the consumer, not at the time the agreement is created. Therefore, be aware that it is possible to create a fractional replication agreement on a supplier that will fail later when the supplier actually attempts to contact the consumer. This failure will be logged in the supplier's error log.
Replication across a Wide-Area Network
Directory Server version 7.1 and later support efficient replication when a supplier and consumer are connected via a wide-area network. Wide-area networks typically have higher latency, higher bandwidth delay product, and lower speeds than local area networks.
In previous versions of Directory Server, the replication protocols used to transmit entries and updates between suppliers and consumers were highly latency-sensitive because the supplier would send only one update operation and then wait for a response from the consumer. This led to reduced throughput with higher latencies. For example, on a typical USA coast-to-coast connection with 100ms round trip time, replication updates would be sent no faster than 10 per second.
Now, the supplier sends many updates and entries to the consumer without waiting for a response. Thus, on a network with high latency, many replication operations can be in transit on the network, and replication throughput is similar to that which can be achieved on a local area network.
When a current Directory Server supplier detects that it is connected to another supplier running an older release, it falls back to the old replication mechanism for compatibility. Thus, it is necessary to have both your supplier and consumer servers running version 7.1 or later in order to achieve the benefits of the new latency-insensitive replication.
There are performance issues to consider for both the Directory Server and the efficiency of the network connection:
- Where replication is performed across a public network such as the Internet, the use of SSL is highly recommended. This will guard against eavesdropping of the replication traffic.
- You should use a T-1 or faster Internet connection for your network.
- When creating agreements for replication over a wide-area network, it is recommended that you do not keep your servers always in sync. Replication traffic could consume a large portion of your bandwidth and slow down your overall network and Internet connections.
- When initializing consumers, do not to initialize the consumer immediately; instead, utilize filesystem replica initialization, which is much faster than online initialization or initializing from file. See the Red Hat Directory Server Administrator's Guide for information on using filesystem replica initialization.
Using Replication for High Availability
Use replication to prevent the loss of a single server from causing your directory to become unavailable. At a minimum, you should replicate the local directory tree to at least one backup server.
Some directory architects argue that you should replicate three times per physical location for maximum data reliability. How much you use replication for fault tolerance is up to you, but you should base this decision on the quality of the hardware and networks used by your directory. Unreliable hardware needs more backup servers.
You should not use replication as a replacement for a regular data backup policy. For information on backing up your directory data, refer to the Red Hat Directory Server Administrator's Guide. |
If you need to guarantee write-failover for all you directory clients, you should use a multi-master replication scenario. If read-failover is sufficient, you can use single-master replication.
LDAP client applications can usually be configured to search only one LDAP server. Unless you have written a custom client application to rotate through LDAP servers located at different DNS hostnames, you can only configure your LDAP client application to look at a single DNS hostname for a Directory Server. Therefore, you will probably need to use either DNS round-robins or network sorts to provide failover to your backup Directory Servers. For information on setting up and using DNS round robins or network sorts, see your DNS documentation.
Using Replication for Local Availability
Your need to replicate for local availability is determined by the quality of your network as well as the activities of your site. In addition, you should carefully consider the nature of the data contained in your directory and the consequences to your enterprise in the event that the data becomes temporarily unavailable. The more mission-critical the data, the less tolerant you can be of outages caused by poor network connections.
You should use replication for local availability for the following reasons:
- This is an important strategy for large, multinational enterprises that need to maintain directory information of interest only to the employees in a specific country. Having a local master copy of the data is also important to any enterprise where interoffice politics dictate that data be controlled at a divisional or organizational level.
- Intermittent network connections can occur if you are using unreliable WANs, as often occurs in international networks.
- Your networks periodically experience extremely heavy loads that may cause the performance of your directory to be severely reduced.
- Among other reasons, performance is affected in enterprises with aging networks, which may experience these conditions during normal business hours.
Using Replication for Load Balancing
Replication can balance the load on your Directory Servers in several ways:
- By spreading your user's search activities across several servers.
- By dedicating servers to read-only activities (writes occur only on the supplier server).
- By dedicating special servers to specific tasks, such as supporting mail server activities.
One of the more important reasons to replicate directory data is to balance the workload of your network. When possible, you should move data to servers that can be accessed using a reasonably fast and reliable network connection. The most important considerations are the speed and reliability of the network connection between your server and your directory users.
Directory entries generally average around one Kbyte in size. Therefore, every directory lookup adds about one Kbyte to your network load. If your directory users perform around ten directory lookups per day, then, for every directory user, you will see an increased network load of around 10,000 bytes per day. Given a slow, heavily loaded, or unreliable WAN, you may need to replicate your directory tree to a local server.
You must carefully consider whether the benefit of locally available data is worth the cost of the increased network load because of replication. If you are replicating an entire directory tree to a remote site, for instance, you are potentially adding a large strain on your network in comparison to the traffic caused by your users' directory lookups. This is especially true if your directory tree is changing frequently, yet you have only a few users at the remote site performing a few directory lookups per day.
If your directory tree on average includes in excess of 1,000,000 entries, and it is not unusual for about ten percent of those entries to change every day, then if your average directory entry is only one Kbyte in size, you could increase your network load by 100Mbyte per day. However, if your remote site has only a few employees, say 100, and they are performing an average of ten directory lookups a day, then the network load caused by their directory access is only one Mbyte per day.
Given the difference in loads caused by replication versus that caused by normal directory usage, you may decide that replication for network load-balancing purposes is not desirable. On the other hand, you may find that the benefits of locally available directory data far outweigh any considerations you may have regarding network loads.
A good compromise between making data available to local sites and overloading the network is to use scheduled replication. For more information on data consistency and replication schedules, refer to "Data Consistency," on page 113.
Example of Network Load Balancing
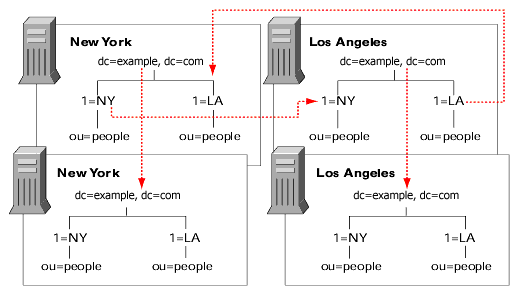
Suppose your enterprise has offices in New York and Los Angeles. Each office has specific subtrees that they manage, shown in the figure.
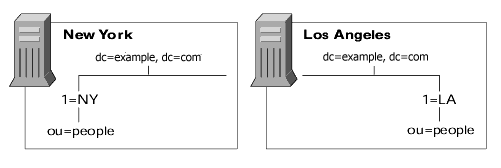
Each office contains a high-speed network, but you are using a dial-up connection to network between the two cities. To balance your network load:
- Replicate locally managed data from that server to the corresponding supplier server in the remote office.
- Replicate the directory tree on each supplier server (including data supplied from the remote office) to at least one local Directory Server to ensure availability of the directory data. You can use multi-master replication for the suffix managed locally and cascading replication for the suffix that receives a master copy of the data from a remote server.
Example of Load Balancing for Improved Performance
Suppose that your directory must include 1,500,000 entries in support of 1,000,000 users, and each user performs ten directory lookups a day. Also assume that you are using a messaging server that handles 25,000,000 mail messages a day and that performs five directory lookups for every mail message that it handles. Therefore, you can expect 125,000,000 directory lookups per day just as a result of mail. Your total combined traffic is, therefore, 135,000,000 directory lookups per day.
Assuming an eight-hour business day, and that your 1,000,000 directory users are clustered in four time zones, your business day (or peak usage) across four time zones is 12 hours long. Therefore you must support 135,000,000 directory lookups in a 12-hour day. This equates to 3,125 lookups per second (135,000,000 / (60*60*12)). That is:
Now, assume that you are using a combination of CPU and RAM with your Directory Servers that allows you to support 500 reads per second. Simple division indicates that you need at least six or seven Directory Servers to support this load. However, for enterprises with 1,000,000 directory users, you should add more Directory Servers for local availability purposes.
One method of replication is to:
- Place two Directory Servers in a multi-master configuration in one city to handle all write traffic.
- This configuration assumes that you want a single point of control for all directory data.
- The read, search, and compare requests serviced by your directory should be targeted at the consumer servers, thereby freeing the supplier servers to handle write requests. For a definition of a hub supplier, refer to "Cascading Replication," on page 119.
- Replicating to local sites helps balance the workload of your servers and your WANs, as well as ensuring high availability of directory data. Assume that you want to replicate to four sites around the country. You then have four consumers of each hub supplier.
- Use DNS sort to ensure that local users always find a local Directory Server they can use for directory lookups.
Example Replication Strategy for a Small Site
Suppose your entire enterprise is contained within a single building. This building has a very fast (100 MB per second) and lightly used network. The network is very stable, and you are reasonably confident of the reliability of your server hardware and OS platforms. Also, you are sure that a single server's performance will easily handle your site's load.
In this case, you should replicate at least once to ensure availability in the event your primary server is shut down for maintenance or hardware upgrades. Also, set up a DNS round-robin to improve LDAP connection performance in the event that one of your Directory Servers becomes unavailable.
Example Replication Strategy for a Large Site
Suppose your entire enterprise is contained within two buildings. Each building has a very fast (100 MB per second) and lightly used network. The network is very stable and you are reasonably confident of the reliability of your server hardware and OS platforms. Also, you are sure that a single server's performance will easily handle the load placed on a server within each building.
Also assume that you have slow (ISDN) connections between the buildings, and that this connection is very busy during normal business hours.
Your replication strategy follows:
- This server should be placed in the building that contains the largest number of people responsible for the master copy of the directory data. Call this Building A.
- Use a multi-master replication configuration if you need to ensure write-failover.
- Create two replicas in the second building (Building B).
- If there is no need for close consistency between the supplier and consumer server, schedule replication so that it occurs only during off peak hours.
Using Replication with Other Directory Features
Replication interacts with other Directory Server features to provide advanced replication features. The following sections describe feature interactions to help you better design your replication strategy.
Replication and Access Control
The directory stores ACIs as attributes of entries. This means that the ACI is replicated along with other directory content. This is important because Directory Server evaluates ACIs locally.
For more information about designing access control for your directory, refer to chapter 7, "Designing a Secure Directory.
Replication and Directory Server Plug-ins
You can use replication with most of the plug-ins delivered with Directory Server. There are some exceptions and limitations in the case of multi-master replication with the following plug-ins:
- You cannot use multi-master replication with the attribute uniqueness plug-in at all because this plug-in can validate only attribute values on the same server, not on multiple servers in the multi-master set.
- You can use the referential integrity plug-in with multi-master replication, providing that this plug-in is enabled on just one supplier in the multi-master set. This ensures that referential integrity updates are made on just one of the supplier servers and propagated to the others.
By default, these plug-ins are disabled. You need to use the Directory Server Console or the command-line to enable them. |
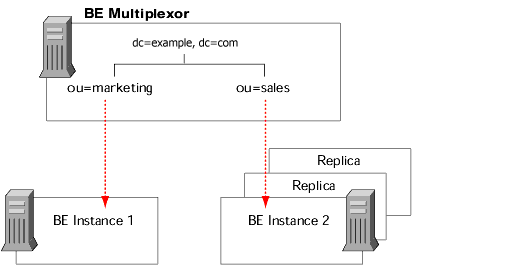
Replication and Database Links
When you distribute entries using chaining, the server containing the database link points to a remote server that contains the actual data. In this environment, you cannot replicate the database link itself. You can, however, replicate the database that contains the actual data on the remote server.
You must not use the replication process as a backup for database links. You must backup database links manually. For more information about chaining and entry distribution, refer to chapter 5, "Designing the Directory Topology.
Figure 6-9 Replicating Chained Databases
|
Schema Replication
In all replication scenarios, before pushing data to consumer servers, the supplier server checks whether its own version of the schema is in sync with the version of the schema held on consumer servers.
If the schema entries on both supplier and consumers are the same, the replication operation proceeds.
If the version of the schema on the supplier server is more recent than the version stored on the consumer, the supplier server replicates its schema to the consumer before proceeding with the data replication.
If the version of the schema on the supplier server is older than the version stored on the consumer, you will probably witness a lot of errors during replication because the schema on the consumer cannot support the new data.
A consumer might contain replicated data from two suppliers, each with different schema. Whichever supplier was updated last will "win," and its schema will be propagated to the consumer.
You must never update the schema on a consumer server because the supplier server is unable to resolve the conflicts that will occur, and replication will fail. Schema should be maintained on a supplier server in a replicated topology. If using the standard 99user.ldif file, these changes will be replicated to all consumers. When using custom schema files, ensure that these files are copied to all servers after making changes on the supplier. After copying files, the server must be restarted. Refer to "Creating Custom Schema Files," on page 53, for more information. |
The same Directory Server can hold read-write replicas for which it acts as a supplier and read-only replicas for which it acts as a consumer. Therefore, you should always identify the server that will act as a supplier for the schema and set up replication agreements between this supplier and all other servers in your replication environment which should act as consumers for the schema information..
Special replication agreements are not required to replicate the schema. If replication has been configured between a supplier and a consumer, schema replication will happen by default. |
Changes made to custom schema files are only replicated if the schema is updated using LDAP or the Directory Server Console. These custom schema files should be copied to each server in order to maintain the information in the same schema file on all servers. For more information, refer to "Creating Custom Schema Files," on page 53.
For more information on schema design, refer to chapter 3, "How to Design the Schema.
Replication and Synchronization
In order to propagate synchronized Windows entries throughout the Directory Server, use synchronization within a multi-master environment. Sync agreement should be kept to the lowest amount possible, preferably one per deployment. Multi-master replication allows the Windows information to be available through the network while limiting the data access point to a single Directory Server.