| Red Hat Docs > Manuals > Red Hat High Availability Server Manuals > |
| Red Hat Linux 6.2: The Official Red Hat High Availability Server Installation Guide | ||
|---|---|---|
| Prev | Introduction | Next |
While Red Hat High Availability Server can be configured in a variety of different ways, the configurations can be broken into two major categories:
Configurations based on FOS
Configurations based on LVS
The choice of FOS or LVS as the underlying technology for your Red Hat High Availability Server cluster has an impact on the hardware requirements and the service levels that can be supported. Let's take a look at some sample configurations, and discuss the implications of each.
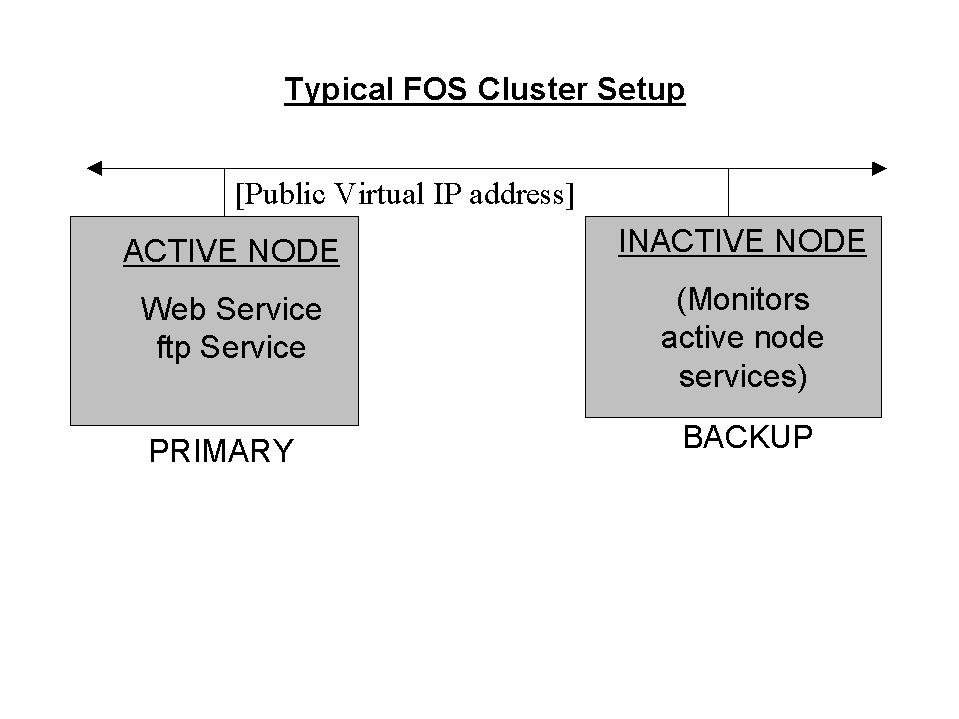
Red Hat High Availability Server clusters based on FOS consist of two Linux systems. Each system must be sized to support the full load anticipated for all services [1] . This is necessary, because at any given time only one system (the active node) provides the services to your customers.
During the initial configuration of an FOS cluster, one system is defined as the primary node, and the other as the backup node. This distinction is made to determine which system will be declared active should both systems find themselves in the active state at the same time. In such a case, the primary node will "win".
The active node responds to service requests through a virtual IP (or VIP) address. The VIP address is an IP address that is distinct from the active node's normal IP address.
The other system (the inactive node) does not actually run the services; instead it monitors the services on the active node, and makes sure the active node is still functional. If the inactive node detects a problem with either the active node or the services running on it, a failover will be initiated.
During a failover, the following steps are performed:
The active node is directed to shut down all services (if it is still running and has network connectivity)
The inactive node starts all services
The active node disables its use of the VIP address (if it is still running and has network connectivity)
The inactive node is now the active node, and enables its use of the VIP address
If it is still running and has network connectivity, the formerly-active node is now the inactive node, begins monitoring the services and general well-being of the active node
Let's take a look at the most basic of FOS configurations.
Figure 1 shows a Red Hat High Availability Server FOS cluster. In this case, the active node provides Web and FTP services, while the inactive node monitors the active node and its services.
While not shown in this diagram, it is possible for both the active and inactive nodes to be used for other, less critical, services while still performing their roles in an FOS cluster. For example, the inactive system could run inn to manage an NNTP newsfeed. However, care must be taken to either keep sufficient capacity free should a failover occur, or to select services that could be shut down (with little ill effect) in the event of a failover. Again, from a system administration standpoint, it may be desirable to dedicate the primary and backup nodes to cluster-related services, even if this does result in less then 100% utilization of system resources.
One aspect of an FOS cluster is that the capacity of the entire cluster is limited to the capacity of the currently-active node. This means that bringing additional capacity online will require upgrades (or replacements) for each system. While the FOS technology means that such upgrades can be done without impacting service availability, doing upgrades in such an environment means a greater exposure to possible service outages, should the active node fail while the inactive node is being upgraded or replaced.
It should also be noted that FOS is not a data-sharing technology. In other words, if a service reads and writes data on the active node, FOS includes no mechanism to replicate that data on the inactive node. This means data used by the services on an FOS cluster must fall into one or two categories:
The data does not change; it is read-only
The data is not read-only, but it is made available to both the active and inactive node equally.
While the sample configuration shown above might be appropriate for a Website containing static pages, it would not be appropriate for a busy FTP site, particularly one where new files are constantly uploaded by users of the FTP site. Let's look at one way an FOS cluster can use more dynamic data.
As noted above, some mechanism must be used to make read-write data available to both nodes in an FOS cluster. One such solution is to use NFS-accessible storage. By using this approach, failure of the active node will not result in the data being inaccessible from the inactive node.
However, care must be taken to prevent the NFS-accessible storage from becoming a single point of failure. Otherwise, the loss of this storage would result in a service outage, even if both the active and inactive nodes were otherwise healthy. The solution, as shown in Figure 2, is to use RAID and other technologies to implement a fault-resistant NFS server.
While it's certainly possible that various modifications to the basic FOS cluster configuration are possible, in general, the options are limited to one system providing all services, while a backup system monitors those services, and initiates a failover if and when required. For more flexibility and/or more capacity, an alternative is required. That alternative is LVS.
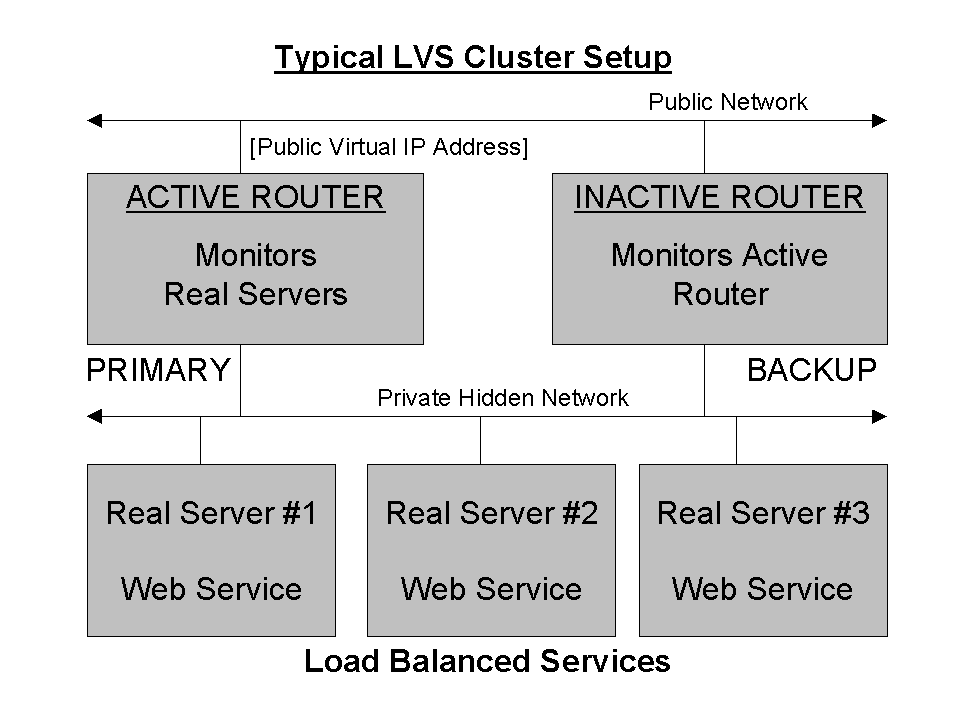
In many ways, an LVS cluster can be thought of as an FOS cluster with a single difference — instead of actually providing the services, the active node in an LVS cluster routes requests to one or more servers that actually provide the services. These additional servers (called real servers) are load-balanced by the active node (in LVS terms, the active router).
As in an FOS cluster, there are two systems that share the responsibility of ensuring that one of the two systems is active, while the other (the inactive router) stands by to initiate a failover should the need arise. However, that is where the similarities end.
Because the active router's main responsibility is to accept incoming service requests and direct them to the appropriate real server, it is necessary for the active router to keep track of the real servers' status, and to determine which real server should receive the next inbound service request. Therefore, the active router monitors every service on each real server. In the event of a service failure on a given real server, the active router will stop directing service requests to it until the service again becomes operative.
In addition, the active router can optionally use one of several scheduling metrics to determine which real server is most capable of handling the next service request. The available scheduling metrics are:
Round robin
Least connections
Weighted round robin
Weighted least connections
We'll go into more detail regarding scheduling in Chapter 8; however, for now the important thing to realize is that the active router can take into account the real servers' activity and (optionally) an arbitrarily-assigned weighting factor when routing service requests. This means that's it's possible to create a group of real servers using a variety of hardware configurations, and have the active router load each real server evenly.
Figure 3 shows a typical Red Hat High Availability Server LVS cluster with three real servers providing Web service. In this configuration, the real servers are connected to a dedicated private network segment. The routers have two network interfaces:
One interface on the public network
One interface on a private network
Service requests directed to the cluster's VIP address are received by the active router on one interface, and then passed to the most appropriate (as determined by the schedule/weighting algorithm in use) real server through the other interface. In this way, the routers are also able to act the part of firewalls; passing only valid service-related traffic to the real servers' private network.
An LVS cluster may use one of three different methods of routing traffic to the real servers:
Network Address Translation (NAT), which enables a private-LAN architecture
Direct routing, which enables LAN-based routing
Tunneling (IP encapsulation), which makes possible WAN-level distribution of real servers
In Figure 3, NAT routing is in use. While NAT-based routing makes it possible to operate the real servers in a more sheltered environment, it does exact additional overhead on the router, as it must translate the addresses of all traffic to and from each real server. In practice, this limits the size of a NAT-routed LVS cluster to approximately ten to twenty real servers [2] .
This overhead is not present when using tunneled or direct routing, because in these routing techniques the real servers respond directly to the requesting systems. With tunneling there is a bit more overhead than with direct routing, but it is minimal, especially when compared with NAT-based routing.
One interesting aspect of an LVS-based cluster is that the real servers do not have to run a particular operating system. Since the routing techniques used by LVS are all based on industry-standard TCP/IP features, any platform that supports a TCP/IP stack can conceivably be part of an LVS cluster [3] .
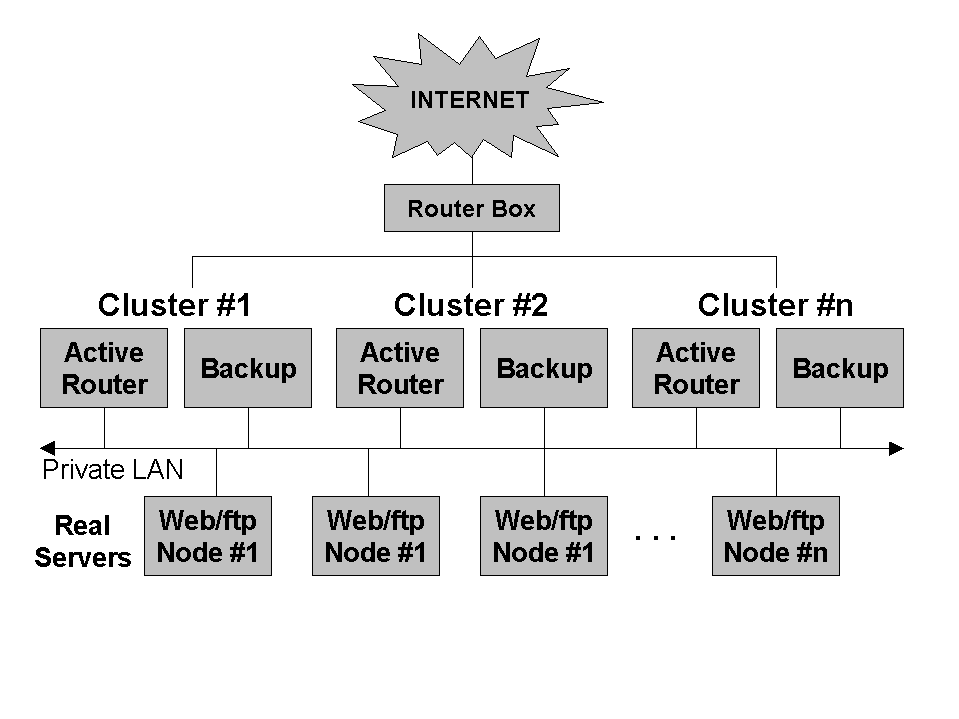
Figure 4 shows a more esoteric approach to deploying LVS. This configuration shows a possible approach for deploying clusters comprised of an extremely large number of systems. The approach taken by this configuration is to share a single pool of real servers between multiple routers (and their associated backup routers).
Because each active router is responsible for routing requests directed to a unique VIP address (or set of addresses), this configuration would normally present the appearance of multiple clusters. However, round-robin DNS can be used to resolve a single hostname to one of the VIP addresses managed by one of the active routers. Therefore, each service request will be directed to each active router in turn, effectively spreading the traffic across all active routers.
| [1] | Although there is no technological requirement that each system be identically configured (only that each system be capable of supporting all services), from a system administration perspective it makes a great deal of sense to configure each system identically. |
| [2] | It is possible to alleviate the impact of NAT-based routing by constructing more complex cluster configurations. For example, a two-level approach may be created where the active router load-balances between several real servers, each of which is itself an active router with its own group of real servers actually providing the service. |
| [3] | The scheduling options may be somewhat restricted if a real server's operating system does not support the uptime, ruptime, or rup commands. These commands are used to dynamically adjust the weights used in some of the scheduling methods. |