

Edition 0
1801 Varsity Drive
Raleigh, NC 27606-2072 USA
Phone: +1 919 754 3700
Phone: 888 733 4281
Fax: +1 919 754 3701
Mono-spaced Bold
To see the contents of the filemy_next_bestselling_novelin your current working directory, enter thecat my_next_bestselling_novelcommand at the shell prompt and press Enter to execute the command.
Press Enter to execute the command.Press Ctrl+Alt+F2 to switch to the first virtual terminal. Press Ctrl+Alt+F1 to return to your X-Windows session.
mono-spaced bold. For example:
File-related classes includefilesystemfor file systems,filefor files, anddirfor directories. Each class has its own associated set of permissions.
Choose → → from the main menu bar to launch Mouse Preferences. In the Buttons tab, click the Left-handed mouse check box and click to switch the primary mouse button from the left to the right (making the mouse suitable for use in the left hand).To insert a special character into a gedit file, choose → → from the main menu bar. Next, choose → from the Character Map menu bar, type the name of the character in the Search field and click . The character you sought will be highlighted in the Character Table. Double-click this highlighted character to place it in the Text to copy field and then click the button. Now switch back to your document and choose → from the gedit menu bar.
Mono-spaced Bold ItalicProportional Bold Italic
To connect to a remote machine using ssh, typesshat a shell prompt. If the remote machine isusername@domain.nameexample.comand your username on that machine is john, typessh [email protected].Themount -o remountcommand remounts the named file system. For example, to remount thefile-system/homefile system, the command ismount -o remount /home.To see the version of a currently installed package, use therpm -qcommand. It will return a result as follows:package.package-version-release
Publican is a DocBook publishing system.
mono-spaced roman and presented thus:
books Desktop documentation drafts mss photos stuff svn books_tests Desktop1 downloads images notes scripts svgs
mono-spaced roman but add syntax highlighting as follows:
package org.jboss.book.jca.ex1; import javax.naming.InitialContext; public class ExClient { public static void main(String args[]) throws Exception { InitialContext iniCtx = new InitialContext(); Object ref = iniCtx.lookup("EchoBean"); EchoHome home = (EchoHome) ref; Echo echo = home.create(); System.out.println("Created Echo"); System.out.println("Echo.echo('Hello') = " + echo.echo("Hello")); } }
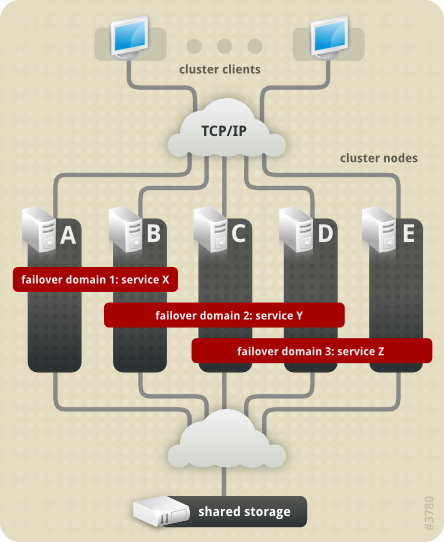
rgmanager.
rgmanager uses DLM to synchronize service states.
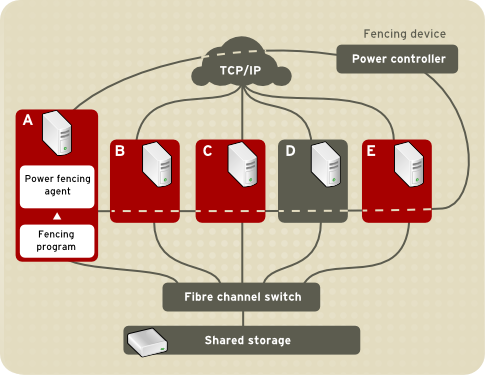
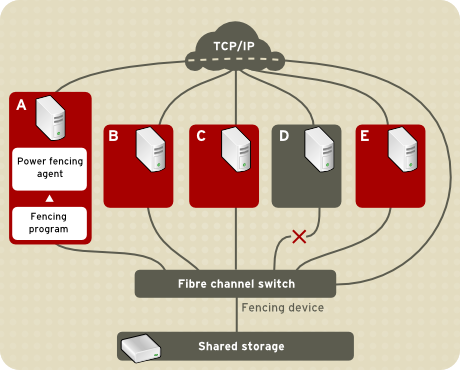
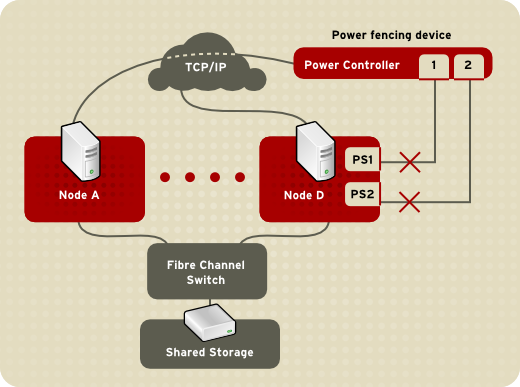
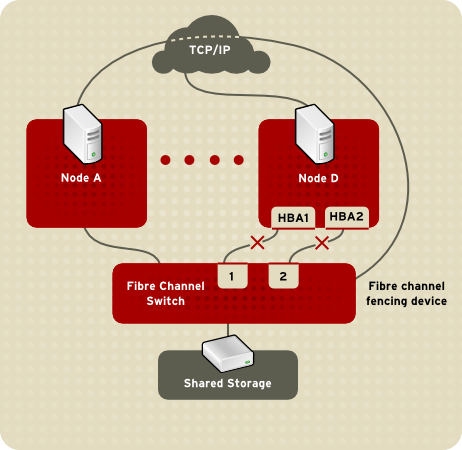
fenced.
fenced, when notified of the failure, fences the failed node. Other cluster-infrastructure components determine what actions to take — that is, they perform any recovery that needs to done. For example, DLM and GFS2, when notified of a node failure, suspend activity until they detect that fenced has completed fencing the failed node. Upon confirmation that the failed node is fenced, DLM and GFS2 perform recovery. DLM releases locks of the failed node; GFS2 recovers the journal of the failed node.
/etc/cluster/cluster.conf specifies the High Availability Add-On configuration.The configuration file is an XML file that describes the following cluster characteristics:
/usr/share/cluster/cluster.rng during startup time and when a configuration is reloaded. Also, you can validate a cluster configuration any time by using the ccs_config_validate command.
/usr/share/doc/cman-X.Y.ZZ/cluster_conf.html (for example /usr/share/doc/cman-3.0.12/cluster_conf.html).
rgmanager, implements cold failover for off-the-shelf applications. In the High Availability Add-On, an application is configured with other cluster resources to form a high-availability cluster service. A high-availability cluster service can fail over from one cluster node to another with no apparent interruption to cluster clients. Cluster-service failover can occur if a cluster node fails or if a cluster system administrator moves the service from one cluster node to another (for example, for a planned outage of a cluster node).
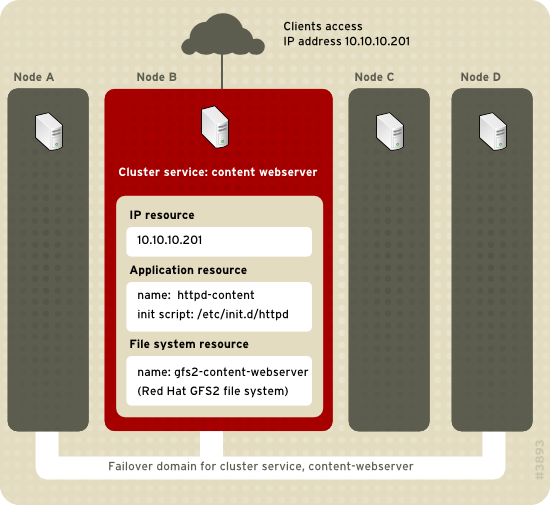
/etc/init.d/httpd (specifying httpd).
system-config-cluster is not available in RHEL 6.
| Revision History | |||
|---|---|---|---|
| Revision 1.0 | Wed Nov 10 2010 | ||
| |||