

Edition 1.5
1801 Varsity Drive
Raleigh, NC 27606-2072 USA
Phone: +1 919 754 3700
Phone: 888 733 4281
Fax: +1 919 754 3701
Mono-spaced Bold
To see the contents of the filemy_next_bestselling_novelin your current working directory, enter thecat my_next_bestselling_novelcommand at the shell prompt and press Enter to execute the command.
Press Enter to execute the command.Press Ctrl+Alt+F2 to switch to the first virtual terminal. Press Ctrl+Alt+F1 to return to your X-Windows session.
mono-spaced bold. For example:
File-related classes includefilesystemfor file systems,filefor files, anddirfor directories. Each class has its own associated set of permissions.
Choose → → from the main menu bar to launch Mouse Preferences. In the Buttons tab, click the Left-handed mouse check box and click to switch the primary mouse button from the left to the right (making the mouse suitable for use in the left hand).To insert a special character into a gedit file, choose → → from the main menu bar. Next, choose → from the Character Map menu bar, type the name of the character in the Search field and click . The character you sought will be highlighted in the Character Table. Double-click this highlighted character to place it in the Text to copy field and then click the button. Now switch back to your document and choose → from the gedit menu bar.
Mono-spaced Bold ItalicProportional Bold Italic
To connect to a remote machine using ssh, typesshat a shell prompt. If the remote machine isusername@domain.nameexample.comand your username on that machine is john, typessh [email protected].Themount -o remountcommand remounts the named file system. For example, to remount thefile-system/homefile system, the command ismount -o remount /home.To see the version of a currently installed package, use therpm -qcommand. It will return a result as follows:package.package-version-release
Publican is a DocBook publishing system.
mono-spaced roman and presented thus:
books Desktop documentation drafts mss photos stuff svn books_tests Desktop1 downloads images notes scripts svgs
mono-spaced roman but add syntax highlighting as follows:
package org.jboss.book.jca.ex1; import javax.naming.InitialContext; public class ExClient { public static void main(String args[]) throws Exception { InitialContext iniCtx = new InitialContext(); Object ref = iniCtx.lookup("EchoBean"); EchoHome home = (EchoHome) ref; Echo echo = home.create(); System.out.println("Created Echo"); System.out.println("Echo.echo('Hello') = " + echo.echo("Hello")); } }
6.
/lib directory. When using 64-bit systems, some of the files mentioned may instead be located in /lib64.
nmap command followed by the hostname or IP address of the machine to scan.
nmap foo.example.comInteresting ports on foo.example.com: Not shown: 1710 filtered ports PORT STATE SERVICE 22/tcp open ssh 53/tcp open domain 80/tcp open http 113/tcp closed auth
| Exploit | Description | Notes | |||
|---|---|---|---|---|---|
| Null or Default Passwords | Leaving administrative passwords blank or using a default password set by the product vendor. This is most common in hardware such as routers and firewalls, though some services that run on Linux can contain default administrator passwords (though Red Hat Enterprise Linux does not ship with them). |
| |||
| Default Shared Keys | Secure services sometimes package default security keys for development or evaluation testing purposes. If these keys are left unchanged and are placed in a production environment on the Internet, all users with the same default keys have access to that shared-key resource, and any sensitive information that it contains. |
| |||
| IP Spoofing | A remote machine acts as a node on your local network, finds vulnerabilities with your servers, and installs a backdoor program or trojan horse to gain control over your network resources. |
| |||
| Eavesdropping | Collecting data that passes between two active nodes on a network by eavesdropping on the connection between the two nodes. |
| |||
| Service Vulnerabilities | An attacker finds a flaw or loophole in a service run over the Internet; through this vulnerability, the attacker compromises the entire system and any data that it may hold, and could possibly compromise other systems on the network. |
| |||
| Application Vulnerabilities | Attackers find faults in desktop and workstation applications (such as e-mail clients) and execute arbitrary code, implant trojan horses for future compromise, or crash systems. Further exploitation can occur if the compromised workstation has administrative privileges on the rest of the network. |
| |||
| Denial of Service (DoS) Attacks | Attacker or group of attackers coordinate against an organization's network or server resources by sending unauthorized packets to the target host (either server, router, or workstation). This forces the resource to become unavailable to legitimate users. |
|
/mnt/cdrom, use the following command to import it into the keyring (a database of trusted keys on the system):
rpm --import /mnt/cdrom/RPM-GPG-KEYrpm -qa gpg-pubkey*gpg-pubkey-db42a60e-37ea5438rpm -qi command followed by the output from the previous command, as in this example:
rpm -qi gpg-pubkey-db42a60e-37ea5438rpm -K /tmp/updates/*.rpmgpg OK. If it doesn't, make sure you are using the correct Red Hat public key, as well as verifying the source of the content. Packages that do not pass GPG verifications should not be installed, as they may have been altered by a third party.
rpm -Uvh /tmp/updates/*.rpmrpm -ivh /tmp/updates/<kernel-package><kernel-package> in the previous example with the name of the kernel RPM.
rpm -e <old-kernel-package><old-kernel-package> in the previous example with the name of the older kernel RPM.
glibc, which are used by a number of applications and services. Applications utilizing a shared library typically load the shared code when the application is initialized, so any applications using the updated library must be halted and relaunched.
lsof command as in the following example:
lsof /lib/libwrap.so*tcp_wrappers package is updated.
sshd, vsftpd, and xinetd.
/sbin/service command as in the following example:
/sbin/service <service-name> restart<service-name> with the name of the service, such as sshd.
xinetd Servicesxinetd super service only run when a there is an active connection. Examples of services controlled by xinetd include Telnet, IMAP, and POP3.
xinetd each time a new request is received, connections that occur after an upgrade are handled by the updated software. However, if there are active connections at the time the xinetd controlled service is upgraded, they are serviced by the older version of the software.
xinetd controlled service, upgrade the package for the service then halt all processes currently running. To determine if the process is running, use the ps command and then use the kill or killall command to halt current instances of the service.
imap packages are released, upgrade the packages, then type the following command as root into a shell prompt:
ps aux | grep imapkill <PID>kill -9 <PID><PID> with the process identification number (found in the second column of the ps command) for an IMAP session.
killall imapd[1] http://law.jrank.org/pages/3791/Kevin-Mitnick-Case-1999.html
[2] http://www.livinginternet.com/i/ia_hackers_levin.htm
[3] http://www.theregister.co.uk/2007/05/04/txj_nonfeasance/
[4] http://www.fudzilla.com/content/view/7847/1/
[5] http://www.internetworldstats.com/stats.htm
[6] http://www.cert.org
[7] http://www.cert.org/stats/cert_stats.html
[8] http://news.cnet.com/Computer-crime-costs-67-billion,-FBI-says/2100-7349_3-6028946.html
[9] http://www.cio.com/article/504837/Why_Security_Matters_Now
[10] http://www.sans.org/resources/errors.php
cat command.
/sbin/grub-md5-crypt/boot/grub/grub.conf. Open the file and below the timeout line in the main section of the document, add the following line:
password --md5 <password-hash>/boot/grub/grub.conf file must be edited.
title line of the operating system that you want to secure, and add a line with the lock directive immediately beneath it.
title DOS lockpassword line must be present in the main section of the /boot/grub/grub.conf file for this method to work properly. Otherwise, an attacker can access the GRUB editor interface and remove the lock line.
lock line to the stanza, followed by a password line.
title DOS lock password --md5 <password-hash>/etc/passwd file, which makes the system vulnerable to offline password cracking attacks. If an intruder can gain access to the machine as a regular user, he can copy the /etc/passwd file to his own machine and run any number of password cracking programs against it. If there is an insecure password in the file, it is only a matter of time before the password cracker discovers it.
/etc/shadow, which is readable only by the root user.
otrattw,tghwg.
7 for t and the at symbol (@) for a:
o7r@77w,7ghwg.
H.
o7r@77w,7gHwg.
passwd, which is Pluggable Authentication Modules (PAM) aware and therefore checks to see if the password is too short or otherwise easy to crack. This check is performed using the pam_cracklib.so PAM module. Since PAM is customizable, it is possible to add more password integrity checkers, such as pam_passwdqc (available from http://www.openwall.com/passwdqc/) or to write a new module. For a list of available PAM modules, refer to http://www.kernel.org/pub/linux/libs/pam/modules.html. For more information about PAM, refer to Managing Single Sign-On and Smart Cards.
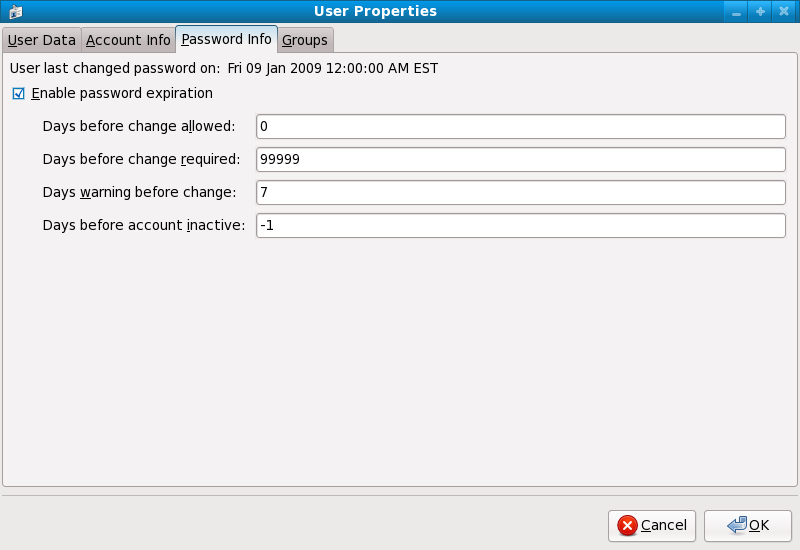
chage command or the graphical User Manager (system-config-users) application.
-M option of the chage command specifies the maximum number of days the password is valid. For example, to set a user's password to expire in 90 days, use the following command:
chage -M 90 <username><username> with the name of the user. To disable password expiration, it is traditional to use a value of 99999 after the -M option (this equates to a little over 273 years).
chage command in interactive mode to modify multiple password aging and account details. Use the following command to enter interactive mode:
chage <username>[root@myServer ~]# chage davido Changing the aging information for davido Enter the new value, or press ENTER for the default Minimum Password Age [0]: 10 Maximum Password Age [99999]: 90 Last Password Change (YYYY-MM-DD) [2006-08-18]: Password Expiration Warning [7]: Password Inactive [-1]: Account Expiration Date (YYYY-MM-DD) [1969-12-31]: [root@myServer ~]#
system-config-users at a shell prompt.
sudo or su. A setuid program is one that operates with the user ID (UID) of the program's owner rather than the user operating the program. Such programs are denoted by an s in the owner section of a long format listing, as in the following example:
-rwsr-xr-x 1 root root 47324 May 1 08:09 /bin/sus may be upper case or lower case. If it appears as upper case, it means that the underlying permission bit has not been set.
pam_console.so, some activities normally reserved only for the root user, such as rebooting and mounting removable media are allowed for the first user that logs in at the physical console (refer to Managing Single Sign-On and Smart Cards for more information about the pam_console.so module.) However, other important system administration tasks, such as altering network settings, configuring a new mouse, or mounting network devices, are not possible without administrative privileges. As a result, system administrators must decide how much access the users on their network should receive.
| Method | Description | Effects | Does Not Affect | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Changing the root shell. |
Edit the /etc/passwd file and change the shell from /bin/bash to /sbin/nologin.
|
|
| |||||||||||||||
| Disabling root access via any console device (tty). |
An empty /etc/securetty file prevents root login on any devices attached to the computer.
|
|
| |||||||||||||||
| Disabling root SSH logins. |
Edit the /etc/ssh/sshd_config file and set the PermitRootLogin parameter to no.
|
|
| |||||||||||||||
| Use PAM to limit root access to services. |
Edit the file for the target service in the /etc/pam.d/ directory. Make sure the pam_listfile.so is required for authentication.[a]
|
|
| |||||||||||||||
[a] Refer to Section 2.1.4.2.4, “Disabling Root Using PAM” for details. | ||||||||||||||||||
/sbin/nologin in the /etc/passwd file. This prevents access to the root account through commands that require a shell, such as the su and the ssh commands.
sudo command, can still access the root account.
/etc/securetty file. This file lists all devices the root user is allowed to log into. If the file does not exist at all, the root user can log in through any communication device on the system, whether via the console or a raw network interface. This is dangerous, because a user can log in to his machine as root via Telnet, which transmits the password in plain text over the network. By default, Red Hat Enterprise Linux's /etc/securetty file only allows the root user to log in at the console physically attached to the machine. To prevent root from logging in, remove the contents of this file by typing the following command:
echo > /etc/securetty/etc/securetty file does not prevent the root user from logging in remotely using the OpenSSH suite of tools because the console is not opened until after authentication.
/etc/ssh/sshd_config). Change the line that reads:
PermitRootLogin yesPermitRootLogin nokill -HUP `cat /var/run/sshd.pid`/lib/security/pam_listfile.so module, allows great flexibility in denying specific accounts. The administrator can use this module to reference a list of users who are not allowed to log in. Below is an example of how the module is used for the vsftpd FTP server in the /etc/pam.d/vsftpd PAM configuration file (the \ character at the end of the first line in the following example is not necessary if the directive is on one line):
auth required /lib/security/pam_listfile.so item=user \ sense=deny file=/etc/vsftpd.ftpusers onerr=succeed
/etc/vsftpd.ftpusers file and deny access to the service for any listed user. The administrator can change the name of this file, and can keep separate lists for each service or use one central list to deny access to multiple services.
/etc/pam.d/pop and /etc/pam.d/imap for mail clients, or /etc/pam.d/ssh for SSH clients.
su or sudo.
su Commandsu command, they are prompted for the root password and, after authentication, is given a root shell prompt.
su command, the user is the root user and has absolute administrative access to the system[13]. In addition, once a user has become root, it is possible for them to use the su command to change to any other user on the system without being prompted for a password.
usermod -G wheel <username><username> with the username you want to add to the wheel group.
system-config-users at a shell prompt.
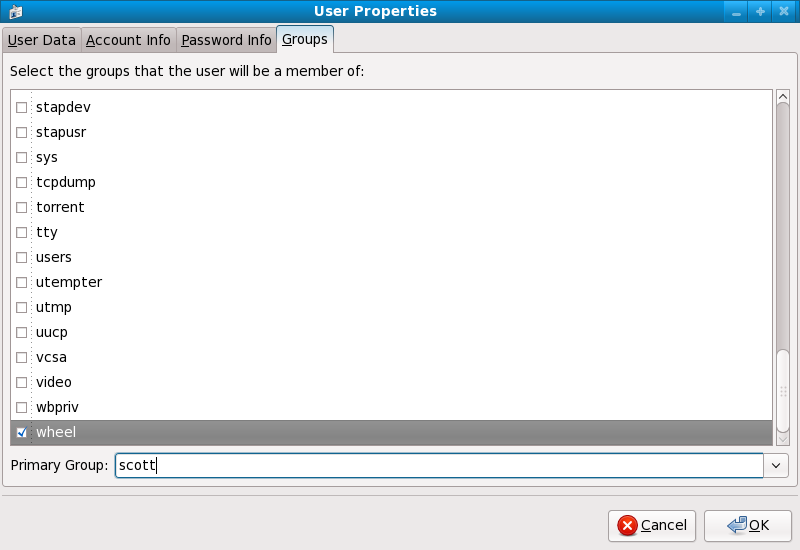
su (/etc/pam.d/su) in a text editor and remove the comment # from the following line:
auth required /lib/security/$ISA/pam_wheel.so use_uid
wheel can use this program.
wheel group by default.
sudo Commandsudo command offers another approach to giving users administrative access. When trusted users precede an administrative command with sudo, they are prompted for their own password. Then, when they have been authenticated and assuming that the command is permitted, the administrative command is executed as if they were the root user.
sudo command is as follows:
sudo <command><command> would be replaced by a command normally reserved for the root user, such as mount.
sudo command should take extra care to log out before walking away from their machines since sudoers can use the command again without being asked for a password within a five minute period. This setting can be altered via the configuration file, /etc/sudoers.
sudo command allows for a high degree of flexibility. For instance, only users listed in the /etc/sudoers configuration file are allowed to use the sudo command and the command is executed in the user's shell, not a root shell. This means the root shell can be completely disabled, as shown in Section 2.1.4.2.1, “Disabling the Root Shell”.
sudo command also provides a comprehensive audit trail. Each successful authentication is logged to the file /var/log/messages and the command issued along with the issuer's user name is logged to the file /var/log/secure.
sudo command is that an administrator can allow different users access to specific commands based on their needs.
sudo configuration file, /etc/sudoers, should use the visudo command.
visudo and add a line similar to the following in the user privilege specification section:
juan ALL=(ALL) ALLjuan, can use sudo from any host and execute any command.
sudo:
%users localhost=/sbin/shutdown -h now/sbin/shutdown -h now as long as it is issued from the console.
sudoers has a detailed listing of options for this file.
cupsd — The default print server for Red Hat Enterprise Linux.
lpd — An alternative print server.
xinetd — A super server that controls connections to a range of subordinate servers, such as gssftp and telnet.
sendmail — The Sendmail Mail Transport Agent (MTA) is enabled by default, but only listens for connections from the localhost.
sshd — The OpenSSH server, which is a secure replacement for Telnet.
cupsd running. The same is true for portmap. If you do not mount NFSv3 volumes or use NIS (the ypbind service), then portmap should be disabled.
netdump, transmit the contents of memory over the network unencrypted. Memory dumps can contain passwords or, even worse, database entries and other sensitive information.
finger and rwhod reveal information about users of the system.
rlogin, rsh, telnet, and vsftpd.
rlogin, rsh, and telnet) should be avoided in favor of SSH. Refer to Section 2.1.7, “Security Enhanced Communication Tools” for more information about sshd.
finger
authd (this was called identd in previous Red Hat Enterprise Linux releases.)
netdump
netdump-server
nfs
rwhod
sendmail
smb (Samba)
yppasswdd
ypserv
ypxfrd
system-config-firewall). This tool creates broad iptables rules for a general-purpose firewall using a control panel interface.
iptables is probably a better option. Refer to Section 2.5, “Firewalls” for more information. Refer to Section 2.6, “IPTables” for a comprehensive guide to the iptables command.
telnet and rsh. OpenSSH includes a network service called sshd and three command line client applications:
ssh — A secure remote console access client.
scp — A secure remote copy command.
sftp — A secure pseudo-ftp client that allows interactive file transfer sessions.
sshd service is inherently secure, the service must be kept up-to-date to prevent security threats. Refer to Section 1.5, “Security Updates” for more information.
xinetd, a super server that provides additional access, logging, binding, redirection, and resource utilization control.
xinetd to create redundancy within service access controls. Refer to Section 2.5, “Firewalls” for more information about implementing firewalls with iptables commands.
hosts_options man page for information about the TCP Wrapper functionality and control language. Refer to the xinetd.conf man page available online at http://linux.die.net/man/5/xinetd.conf for available flags, which act as options you can apply to a service.
banner option.
vsftpd. To begin, create a banner file. It can be anywhere on the system, but it must have same name as the daemon. For this example, the file is called /etc/banners/vsftpd and contains the following line:
220-Hello, %c 220-All activity on ftp.example.com is logged. 220-Inappropriate use will result in your access privileges being removed.
%c token supplies a variety of client information, such as the username and hostname, or the username and IP address to make the connection even more intimidating.
/etc/hosts.allow file:
vsftpd : ALL : banners /etc/banners/ spawn directive.
/etc/hosts.deny file to deny any connection attempts from that network, and to log the attempts to a special file:
ALL : 206.182.68.0 : spawn /bin/echo `date` %c %d >> /var/log/intruder_alert %d token supplies the name of the service that the attacker was trying to access.
spawn directive in the /etc/hosts.allow file.
spawn directive executes any shell command, it is a good idea to create a special script to notify the administrator or execute a chain of commands in the event that a particular client attempts to connect to the server.
severity option.
emerg flag in the log files instead of the default flag, info, and deny the connection.
/etc/hosts.deny:
in.telnetd : ALL : severity emerg authpriv logging facility, but elevates the priority from the default value of info to emerg, which posts log messages directly to the console.
xinetd to set a trap service and using it to control resource levels available to any given xinetd service. Setting resource limits for services can help thwart Denial of Service (DoS) attacks. Refer to the man pages for xinetd and xinetd.conf for a list of available options.
xinetd is its ability to add hosts to a global no_access list. Hosts on this list are denied subsequent connections to services managed by xinetd for a specified period or until xinetd is restarted. You can do this using the SENSOR attribute. This is an easy way to block hosts attempting to scan the ports on the server.
SENSOR is to choose a service you do not plan on using. For this example, Telnet is used.
/etc/xinetd.d/telnet and change the flags line to read:
flags = SENSOR
deny_time = 30
deny_time attribute are FOREVER, which keeps the ban in effect until xinetd is restarted, and NEVER, which allows the connection and logs it.
disable = no
SENSOR is a good way to detect and stop connections from undesirable hosts, it has two drawbacks:
SENSOR is running can mount a Denial of Service attack against particular hosts by forging their IP addresses and connecting to the forbidden port.
xinetd is its ability to set resource limits for services under its control.
cps = <number_of_connections> <wait_period> — Limits the rate of incoming connections. This directive takes two arguments:
<number_of_connections> — The number of connections per second to handle. If the rate of incoming connections is higher than this, the service is temporarily disabled. The default value is fifty (50).
<wait_period> — The number of seconds to wait before re-enabling the service after it has been disabled. The default interval is ten (10) seconds.
instances = <number_of_connections> — Specifies the total number of connections allowed to a service. This directive accepts either an integer value or UNLIMITED.
per_source = <number_of_connections> — Specifies the number of connections allowed to a service by each host. This directive accepts either an integer value or UNLIMITED.
rlimit_as = <number[K|M]> — Specifies the amount of memory address space the service can occupy in kilobytes or megabytes. This directive accepts either an integer value or UNLIMITED.
rlimit_cpu = <number_of_seconds> — Specifies the amount of time in seconds that a service may occupy the CPU. This directive accepts either an integer value or UNLIMITED.
xinetd service from overwhelming the system, resulting in a denial of service.
portmap service is a dynamic port assignment daemon for RPC services such as NIS and NFS. It has weak authentication mechanisms and has the ability to assign a wide range of ports for the services it controls. For these reasons, it is difficult to secure.
portmap only affects NFSv2 and NFSv3 implementations, since NFSv4 no longer requires it. If you plan to implement an NFSv2 or NFSv3 server, then portmap is required, and the following section applies.
portmap service since it has no built-in form of authentication.
portmap service, it is a good idea to add iptables rules to the server and restrict access to specific networks.
portmap service) from the 192.168.0.0/24 network. The second allows TCP connections to the same port from the localhost. This is necessary for the sgi_fam service used by Nautilus. All other packets are dropped.
iptables -A INPUT -p tcp ! -s 192.168.0.0/24 --dport 111 -j DROP iptables -A INPUT -p tcp -s 127.0.0.1 --dport 111 -j ACCEPT
iptables -A INPUT -p udp ! -s 192.168.0.0/24 --dport 111 -j DROP
ypserv, which is used in conjunction with portmap and other related services to distribute maps of usernames, passwords, and other sensitive information to any computer claiming to be within its domain.
/usr/sbin/rpc.yppasswdd — Also called the yppasswdd service, this daemon allows users to change their NIS passwords.
/usr/sbin/rpc.ypxfrd — Also called the ypxfrd service, this daemon is responsible for NIS map transfers over the network.
/usr/sbin/yppush — This application propagates changed NIS databases to multiple NIS servers.
/usr/sbin/ypserv — This is the NIS server daemon.
portmap service as outlined in Section 2.2.2, “Securing Portmap”, then address the following issues, such as network planning.
/etc/passwd map:
ypcat -d<NIS_domain>-h<DNS_hostname>passwd
/etc/shadow file by typing the following command:
ypcat -d<NIS_domain>-h<DNS_hostname>shadow
/etc/shadow file is not stored within an NIS map.
o7hfawtgmhwg.domain.com. Similarly, create a different randomized NIS domain name. This makes it much more difficult for an attacker to access the NIS server.
/var/yp/securenets File/var/yp/securenets file is blank or does not exist (as is the case after a default installation), NIS listens to all networks. One of the first things to do is to put netmask/network pairs in the file so that ypserv only responds to requests from the appropriate network.
/var/yp/securenets file:
255.255.255.0 192.168.0.0
/var/yp/securenets file.
rpc.yppasswdd — the daemon that allows users to change their login passwords. Assigning ports to the other two NIS server daemons, rpc.ypxfrd and ypserv, allows for the creation of firewall rules to further protect the NIS server daemons from intruders.
/etc/sysconfig/network:
YPSERV_ARGS="-p 834" YPXFRD_ARGS="-p 835"
iptables -A INPUT -p ALL ! -s 192.168.0.0/24 --dport 834 -j DROP iptables -A INPUT -p ALL ! -s 192.168.0.0/24 --dport 835 -j DROP
/etc/shadow map is sent over the network. If an intruder gains access to an NIS domain and sniffs network traffic, they can collect usernames and password hashes. With enough time, a password cracking program can guess weak passwords, and an attacker can gain access to a valid account on the network.
portmap service as outlined in Section 2.2.2, “Securing Portmap”. NFS traffic now utilizes TCP in all versions, rather than UDP, and requires it when using NFSv4. NFSv4 now includes Kerberos user and group authentication, as part of the RPCSEC_GSS kernel module. Information on portmap is still included, since Red Hat Enterprise Linux 6 supports NFSv2 and NFSv3, both of which utilize portmap.
/etc/exports file. Be careful not to add extraneous spaces when editing this file.
/etc/exports file shares the directory /tmp/nfs/ to the host bob.example.com with read/write permissions.
/tmp/nfs/ bob.example.com(rw)
/etc/exports file, on the other hand, shares the same directory to the host bob.example.com with read-only permissions and shares it to the world with read/write permissions due to a single space character after the hostname.
/tmp/nfs/ bob.example.com (rw)
showmount command to verify what is being shared:
showmount -e <hostname>no_root_squash Optionnfsnobody user, an unprivileged user account. This changes the owner of all root-created files to nfsnobody, which prevents uploading of programs with the setuid bit set.
no_root_squash is used, remote root users are able to change any file on the shared file system and leave applications infected by trojans for other users to inadvertently execute.
MOUNTD_PORT — TCP and UDP port for mountd (rpc.mountd)
STATD_PORT — TCP and UDP port for status (rpc.statd)
LOCKD_TCPPORT — TCP port for nlockmgr (rpc.lockd)
LOCKD_UDPPORT — UDP port nlockmgr (rpc.lockd)
rpcinfo -p command on the NFS server to see which ports and RPC programs are being used.
chown root <directory_name>chmod 755 <directory_name>/etc/httpd/conf/httpd.conf):
FollowSymLinks/.
IndexesUserDirUserDir directive is disabled by default because it can confirm the presence of a user account on the system. To enable user directory browsing on the server, use the following directives:
UserDir enabled UserDir disabled root
/root/. To add users to the list of disabled accounts, add a space-delimited list of users on the UserDir disabled line.
IncludesNoExec directive. By default, the Server-Side Includes (SSI) module cannot execute commands. It is recommended that you do not change this setting unless absolutely necessary, as it could, potentially, enable an attacker to execute commands on the system.
gssftpd — A Kerberos-aware xinetd-based FTP daemon that does not transmit authentication information over the network.
tux) — A kernel-space Web server with FTP capabilities.
vsftpd — A standalone, security oriented implementation of the FTP service.
vsftpd FTP service.
vsftpd, add the following directive to the /etc/vsftpd/vsftpd.conf file:
ftpd_banner=<insert_greeting_here><insert_greeting_here> in the above directive with the text of the greeting message.
/etc/banners/. The banner file for FTP connections in this example is /etc/banners/ftp.msg. Below is an example of what such a file may look like:
######### # Hello, all activity on ftp.example.com is logged. #########
220 as specified in Section 2.2.1.1.1, “TCP Wrappers and Connection Banners”.
vsftpd, add the following directive to the /etc/vsftpd/vsftpd.conf file:
banner_file=/etc/banners/ftp.msg
/var/ftp/ directory activates the anonymous account.
vsftpd package. This package establishes a directory tree for anonymous users and configures the permissions on directories to read-only for anonymous users.
/var/ftp/pub/.
mkdir /var/ftp/pub/upload
chmod 730 /var/ftp/pub/upload
drwx-wx--- 2 root ftp 4096 Feb 13 20:05 upload
vsftpd, add the following line to the /etc/vsftpd/vsftpd.conf file:
anon_upload_enable=YES
vsftpd, add the following directive to /etc/vsftpd/vsftpd.conf:
local_enable=NO
sudo privileges, the easiest way is to use a PAM list file as described in Section 2.1.4.2.4, “Disabling Root Using PAM”. The PAM configuration file for vsftpd is /etc/pam.d/vsftpd.
vsftpd, add the username to /etc/vsftpd/ftpusers
/etc/mail/sendmail.mc, the effectiveness of such attacks is limited.
confCONNECTION_RATE_THROTTLE — The number of connections the server can receive per second. By default, Sendmail does not limit the number of connections. If a limit is set and reached, further connections are delayed.
confMAX_DAEMON_CHILDREN — The maximum number of child processes that can be spawned by the server. By default, Sendmail does not assign a limit to the number of child processes. If a limit is set and reached, further connections are delayed.
confMIN_FREE_BLOCKS — The minimum number of free blocks which must be available for the server to accept mail. The default is 100 blocks.
confMAX_HEADERS_LENGTH — The maximum acceptable size (in bytes) for a message header.
confMAX_MESSAGE_SIZE — The maximum acceptable size (in bytes) for a single message.
/var/spool/mail/, on an NFS shared volume.
SECRPC_GSS kernel module does not utilize UID-based authentication. However, it is still considered good practice not to put the mail spool directory on NFS shared volumes.
/etc/passwd file should be set to /sbin/nologin (with the possible exception of the root user).
netstat -an or lsof -i. This method is less reliable since these programs do not connect to the machine from the network, but rather check to see what is running on the system. For this reason, these applications are frequent targets for replacement by attackers. Crackers attempt to cover their tracks if they open unauthorized network ports by replacing netstat and lsof with their own, modified versions.
nmap.
nmap -sT -O localhost
Starting Nmap 4.68 ( http://nmap.org ) at 2009-03-06 12:08 EST Interesting ports on localhost.localdomain (127.0.0.1): Not shown: 1711 closed ports PORT STATE SERVICE 22/tcp open ssh 25/tcp open smtp 111/tcp open rpcbind 113/tcp open auth 631/tcp open ipp 834/tcp open unknown 2601/tcp open zebra 32774/tcp open sometimes-rpc11 Device type: general purpose Running: Linux 2.6.X OS details: Linux 2.6.17 - 2.6.24 Uptime: 4.122 days (since Mon Mar 2 09:12:31 2009) Network Distance: 0 hops OS detection performed. Please report any incorrect results at http://nmap.org/submit/ . Nmap done: 1 IP address (1 host up) scanned in 1.420 seconds
portmap due to the presence of the sunrpc service. However, there is also a mystery service on port 834. To check if the port is associated with the official list of known services, type:
cat /etc/services | grep 834
netstat or lsof. To check for port 834 using netstat, use the following command:
netstat -anp | grep 834
tcp 0 0 0.0.0.0:834 0.0.0.0:* LISTEN 653/ypbind
netstat is reassuring because a cracker opening a port surreptitiously on a hacked system is not likely to allow it to be revealed through this command. Also, the [p] option reveals the process ID (PID) of the service that opened the port. In this case, the open port belongs to ypbind (NIS), which is an RPC service handled in conjunction with the portmap service.
lsof command reveals similar information to netstat since it is also capable of linking open ports to services:
lsof -i | grep 834
ypbind 653 0 7u IPv4 1319 TCP *:834 (LISTEN) ypbind 655 0 7u IPv4 1319 TCP *:834 (LISTEN) ypbind 656 0 7u IPv4 1319 TCP *:834 (LISTEN) ypbind 657 0 7u IPv4 1319 TCP *:834 (LISTEN)
lsof, netstat, nmap, and services for more information.
iptables-based firewall filters out unwelcome network packets within the kernel's network stack. For network services that utilize it, TCP Wrappers add an additional layer of protection by defining which hosts are or are not allowed to connect to "wrapped" network services. One such wrapped network service is the xinetd super server. This service is called a super server because it controls connections to a subset of network services and further refines access control.
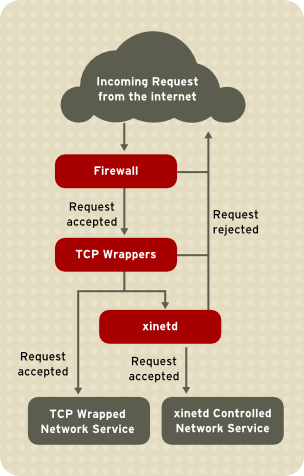
xinetd in controlling access to network services and reviews how these tools can be used to enhance both logging and utilization management. Refer to Section 2.6, “IPTables” for information about using firewalls with iptables.
tcp_wrappers and tcp_wrappers-libs) are installed by default and provide host-based access control to network services. The most important component within the package is the /lib/libwrap.a or /lib64/libwrap.a library. In general terms, a TCP-wrapped service is one that has been compiled against the libwrap.a library.
/etc/hosts.allow and /etc/hosts.deny) to determine whether or not the client is allowed to connect. In most cases, it then uses the syslog daemon (syslogd) to write the name of the requesting client and the requested service to /var/log/secure or /var/log/messages.
libwrap.a library. Some such applications include /usr/sbin/sshd, /usr/sbin/sendmail, and /usr/sbin/xinetd.
libwrap.a, type the following command as the root user:
ldd <binary-name> | grep libwrap
<binary-name> with the name of the network service binary.
libwrap.a.
/usr/sbin/sshd is linked to libwrap.a:
[root@myServer ~]# ldd /usr/sbin/sshd | grep libwrap
libwrap.so.0 => /lib/libwrap.so.0 (0x00655000)
[root@myServer ~]#/etc/hosts.allow
/etc/hosts.deny
/etc/hosts.allow — The TCP-wrapped service sequentially parses the /etc/hosts.allow file and applies the first rule specified for that service. If it finds a matching rule, it allows the connection. If not, it moves on to the next step.
/etc/hosts.deny — The TCP-wrapped service sequentially parses the /etc/hosts.deny file. If it finds a matching rule, it denies the connection. If not, it grants access to the service.
hosts.allow are applied first, they take precedence over rules specified in hosts.deny. Therefore, if access to a service is allowed in hosts.allow, a rule denying access to that same service in hosts.deny is ignored.
hosts.allow or hosts.deny take effect immediately, without restarting network services.
/var/log/messages or /var/log/secure. This is also the case for a rule that spans multiple lines without using the backslash character. The following example illustrates the relevant portion of a log message for a rule failure due to either of these circumstances:
warning: /etc/hosts.allow, line 20: missing newline or line too long
/etc/hosts.allow and /etc/hosts.deny is identical. Each rule must be on its own line. Blank lines or lines that start with a hash (#) are ignored.
<daemon list>:<client list>[:<option>:<option>: ...]
<daemon list> — A comma-separated list of process names (not service names) or the ALL wildcard. The daemon list also accepts operators (refer to Section 2.3.2.1.4, “Operators”) to allow greater flexibility.
<client list> — A comma-separated list of hostnames, host IP addresses, special patterns, or wildcards which identify the hosts affected by the rule. The client list also accepts operators listed in Section 2.3.2.1.4, “Operators” to allow greater flexibility.
<option> — An optional action or colon-separated list of actions performed when the rule is triggered. Option fields support expansions, launch shell commands, allow or deny access, and alter logging behavior.
vsftpd : .example.com
vsftpd) from any host in the example.com domain. If this rule appears in hosts.allow, the connection is accepted. If this rule appears in hosts.deny, the connection is rejected.
sshd : .example.com \ : spawn /bin/echo `/bin/date` access denied>>/var/log/sshd.log \ : deny
sshd) is attempted from a host in the example.com domain, execute the echo command to append the attempt to a special log file, and deny the connection. Because the optional deny directive is used, this line denies access even if it appears in the hosts.allow file. Refer to Section 2.3.2.2, “Option Fields” for a more detailed look at available options.
ALL — Matches everything. It can be used for both the daemon list and the client list.
LOCAL — Matches any host that does not contain a period (.), such as localhost.
KNOWN — Matches any host where the hostname and host address are known or where the user is known.
UNKNOWN — Matches any host where the hostname or host address are unknown or where the user is unknown.
PARANOID — Matches any host where the hostname does not match the host address.
KNOWN, UNKNOWN, and PARANOID wildcards should be used with care, because they rely on a functioning DNS server for correct operation. Any disruption to name resolution may prevent legitimate users from gaining access to a service.
example.com domain:
ALL : .example.com
192.168.x.x network:
ALL : 192.168.
192.168.0.0 through 192.168.1.255:
ALL : 192.168.0.0/255.255.254.0
3ffe:505:2:1:: through 3ffe:505:2:1:ffff:ffff:ffff:ffff:
ALL : [3ffe:505:2:1::]/64
example.com domain:
ALL : *.example.com
/etc/telnet.hosts file for all Telnet connections:
in.telnetd : /etc/telnet.hosts
hosts_access man 5 page for more information.
Portmap's implementation of TCP Wrappers does not support host look-ups, which means portmap can not use hostnames to identify hosts. Consequently, access control rules for portmap in hosts.allow or hosts.deny must use IP addresses, or the keyword ALL, for specifying hosts.
portmap access control rules may not take effect immediately. You may need to restart the portmap service.
portmap to operate, so be aware of these limitations.
EXCEPT. It can be used in both the daemon list and the client list of a rule.
EXCEPT operator allows specific exceptions to broader matches within the same rule.
hosts.allow file, all example.com hosts are allowed to connect to all services except cracker.example.com:
ALL: .example.com EXCEPT cracker.example.com
hosts.allow file, clients from the 192.168.0.x network can use all services except for FTP:
ALL EXCEPT vsftpd: 192.168.0.
EXCEPT operators. This allows other administrators to quickly scan the appropriate files to see what hosts are allowed or denied access to services, without having to sort through EXCEPT operators.
severity directive.
example.com domain are logged to the default authpriv syslog facility (because no facility value is specified) with a priority of emerg:
sshd : .example.com : severity emerg
severity option. The following example logs any SSH connection attempts by hosts from the example.com domain to the local0 facility with a priority of alert:
sshd : .example.com : severity local0.alert
syslogd) is configured to log to the local0 facility. Refer to the syslog.conf man page for information about configuring custom log facilities.
allow or deny directive as the final option.
client-1.example.com, but deny connections from client-2.example.com:
sshd : client-1.example.com : allow sshd : client-2.example.com : deny
hosts.allow or hosts.deny. Some administrators consider this an easier way of organizing access rules.
spawn — Launches a shell command as a child process. This directive can perform tasks like using /usr/sbin/safe_finger to get more information about the requesting client or create special log files using the echo command.
example.com domain are quietly logged to a special file:
in.telnetd : .example.com \ : spawn /bin/echo `/bin/date` from %h>>/var/log/telnet.log \ : allow
twist — Replaces the requested service with the specified command. This directive is often used to set up traps for intruders (also called "honey pots"). It can also be used to send messages to connecting clients. The twist directive must occur at the end of the rule line.
example.com domain are sent a message using the echo command:
vsftpd : .example.com \ : twist /bin/echo "421 This domain has been black-listed. Access denied!"
hosts_options man page.
spawn and twist directives, provide information about the client, server, and processes involved.
%a — Returns the client's IP address.
%A — Returns the server's IP address.
%c — Returns a variety of client information, such as the username and hostname, or the username and IP address.
%d — Returns the daemon process name.
%h — Returns the client's hostname (or IP address, if the hostname is unavailable).
%H — Returns the server's hostname (or IP address, if the hostname is unavailable).
%n — Returns the client's hostname. If unavailable, unknown is printed. If the client's hostname and host address do not match, paranoid is printed.
%N — Returns the server's hostname. If unavailable, unknown is printed. If the server's hostname and host address do not match, paranoid is printed.
%p — Returns the daemon's process ID.
%s —Returns various types of server information, such as the daemon process and the host or IP address of the server.
%u — Returns the client's username. If unavailable, unknown is printed.
spawn command to identify the client host in a customized log file.
sshd) are attempted from a host in the example.com domain, execute the echo command to log the attempt, including the client hostname (by using the %h expansion), to a special file:
sshd : .example.com \ : spawn /bin/echo `/bin/date` access denied to %h>>/var/log/sshd.log \ : deny
example.com domain are informed that they have been banned from the server:
vsftpd : .example.com \ : twist /bin/echo "421 %h has been banned from this server!"
hosts_access (man 5 hosts_access) and the man page for hosts_options.
xinetd daemon is a TCP-wrapped super service which controls access to a subset of popular network services, including FTP, IMAP, and Telnet. It also provides service-specific configuration options for access control, enhanced logging, binding, redirection, and resource utilization control.
xinetd, the super service receives the request and checks for any TCP Wrappers access control rules.
xinetd verifies that the connection is allowed under its own access rules for that service. It also checks that the service is able to have more resources assigned to it and that it is not in breach of any defined rules.
xinetd then starts an instance of the requested service and passes control of the connection to it. After the connection has been established, xinetd takes no further part in the communication between the client and the server.
xinetd are as follows:
/etc/xinetd.conf — The global xinetd configuration file.
/etc/xinetd.d/ — The directory containing all service-specific files.
/etc/xinetd.conf file contains general configuration settings which affect every service under xinetd's control. It is read when the xinetd service is first started, so for configuration changes to take effect, you need to restart the xinetd service. The following is a sample /etc/xinetd.conf file:
defaults
{
instances = 60
log_type = SYSLOG authpriv
log_on_success = HOST PID
log_on_failure = HOST
cps = 25 30
}
includedir /etc/xinetd.dxinetd:
instances — Specifies the maximum number of simultaneous requests that xinetd can process.
log_type — Configures xinetd to use the authpriv log facility, which writes log entries to the /var/log/secure file. Adding a directive such as FILE /var/log/xinetdlog would create a custom log file called xinetdlog in the /var/log/ directory.
log_on_success — Configures xinetd to log successful connection attempts. By default, the remote host's IP address and the process ID of the server processing the request are recorded.
log_on_failure — Configures xinetd to log failed connection attempts or if the connection was denied.
cps — Configures xinetd to allow no more than 25 connections per second to any given service. If this limit is exceeded, the service is retired for 30 seconds.
includedir /etc/xinetd.d/ — Includes options declared in the service-specific configuration files located in the /etc/xinetd.d/ directory. Refer to Section 2.3.4.2, “The /etc/xinetd.d/ Directory” for more information.
log_on_success and log_on_failure settings in /etc/xinetd.conf are further modified in the service-specific configuration files. More information may therefore appear in a given service's log file than the /etc/xinetd.conf file may indicate. Refer to Section 2.3.4.3.1, “Logging Options” for further information.
/etc/xinetd.d/ directory contains the configuration files for each service managed by xinetd and the names of the files are correlated to the service. As with xinetd.conf, this directory is read only when the xinetd service is started. For any changes to take effect, the administrator must restart the xinetd service.
/etc/xinetd.d/ directory use the same conventions as /etc/xinetd.conf. The primary reason the configuration for each service is stored in a separate file is to make customization easier and less likely to affect other services.
/etc/xinetd.d/krb5-telnet file:
service telnet
{
flags = REUSE
socket_type = stream
wait = no
user = root
server = /usr/kerberos/sbin/telnetd
log_on_failure += USERID
disable = yes
}telnet service:
service — Specifies the service name, usually one of those listed in the /etc/services file.
flags — Sets any of a number of attributes for the connection. REUSE instructs xinetd to reuse the socket for a Telnet connection.
REUSE flag is deprecated. All services now implicitly use the REUSE flag.
socket_type — Sets the network socket type to stream.
wait — Specifies whether the service is single-threaded (yes) or multi-threaded (no).
user — Specifies which user ID the process runs under.
server — Specifies which binary executable to launch.
log_on_failure — Specifies logging parameters for log_on_failure in addition to those already defined in xinetd.conf.
disable — Specifies whether the service is disabled (yes) or enabled (no).
xinetd.conf man page for more information about these options and their usage.
xinetd. This section highlights some of the more commonly used options.
/etc/xinetd.conf and the service-specific configuration files within the /etc/xinetd.d/ directory.
ATTEMPT — Logs the fact that a failed attempt was made (log_on_failure).
DURATION — Logs the length of time the service is used by a remote system (log_on_success).
EXIT — Logs the exit status or termination signal of the service (log_on_success).
HOST — Logs the remote host's IP address (log_on_failure and log_on_success).
PID — Logs the process ID of the server receiving the request (log_on_success).
USERID — Logs the remote user using the method defined in RFC 1413 for all multi-threaded stream services (log_on_failure andlog_on_success).
xinetd.conf man page.
xinetd services can choose to use the TCP Wrappers hosts access rules, provide access control via the xinetd configuration files, or a mixture of both. Refer to Section 2.3.2, “TCP Wrappers Configuration Files” for more information about TCP Wrappers hosts access control files.
xinetd to control access to services.
xinetd administrator restarts the xinetd service.
xinetd only affects services controlled by xinetd.
xinetd hosts access control differs from the method used by TCP Wrappers. While TCP Wrappers places all of the access configuration within two files, /etc/hosts.allow and /etc/hosts.deny, xinetd's access control is found in each service's configuration file in the /etc/xinetd.d/ directory.
xinetd:
only_from — Allows only the specified hosts to use the service.
no_access — Blocks listed hosts from using the service.
access_times — Specifies the time range when a particular service may be used. The time range must be stated in 24-hour format notation, HH:MM-HH:MM.
only_from and no_access options can use a list of IP addresses or host names, or can specify an entire network. Like TCP Wrappers, combining xinetd access control with the enhanced logging configuration can increase security by blocking requests from banned hosts while verbosely recording each connection attempt.
/etc/xinetd.d/telnet file can be used to block Telnet access from a particular network group and restrict the overall time range that even allowed users can log in:
service telnet
{
disable = no
flags = REUSE
socket_type = stream
wait = no
user = root
server = /usr/kerberos/sbin/telnetd
log_on_failure += USERID
no_access = 172.16.45.0/24
log_on_success += PID HOST EXIT
access_times = 09:45-16:15
}172.16.45.0/24 network, such as 172.16.45.2, tries to access the Telnet service, it receives the following message:
Connection closed by foreign host.
/var/log/messages as follows:
Sep 7 14:58:33 localhost xinetd[5285]: FAIL: telnet address from=172.16.45.107 Sep 7 14:58:33 localhost xinetd[5283]: START: telnet pid=5285 from=172.16.45.107 Sep 7 14:58:33 localhost xinetd[5283]: EXIT: telnet status=0 pid=5285 duration=0(sec)
xinetd access controls, it is important to understand the relationship between the two access control mechanisms.
xinetd when a client requests a connection:
xinetd daemon accesses the TCP Wrappers hosts access rules using a libwrap.a library call. If a deny rule matches the client, the connection is dropped. If an allow rule matches the client, the connection is passed to xinetd.
xinetd daemon checks its own access control rules both for the xinetd service and the requested service. If a deny rule matches the client, the connection is dropped. Otherwise, xinetd starts an instance of the requested service and passes control of the connection to that service.
xinetd access controls. Misconfiguration can cause undesirable effects.
xinetd support binding the service to an IP address and redirecting incoming requests for that service to another IP address, hostname, or port.
bind option in the service-specific configuration files and links the service to one IP address on the system. When this is configured, the bind option only allows requests to the correct IP address to access the service. You can use this method to bind different services to different network interfaces based on requirements.
redirect option accepts an IP address or hostname followed by a port number. It configures the service to redirect any requests for this service to the specified host and port number. This feature can be used to point to another port number on the same system, redirect the request to a different IP address on the same machine, shift the request to a totally different system and port number, or any combination of these options. A user connecting to a certain service on a system may therefore be rerouted to another system without disruption.
xinetd daemon is able to accomplish this redirection by spawning a process that stays alive for the duration of the connection between the requesting client machine and the host actually providing the service, transferring data between the two systems.
bind and redirect options are most clearly evident when they are used together. By binding a service to a particular IP address on a system and then redirecting requests for this service to a second machine that only the first machine can see, an internal system can be used to provide services for a totally different network. Alternatively, these options can be used to limit the exposure of a particular service on a multi-homed machine to a known IP address, as well as redirect any requests for that service to another machine especially configured for that purpose.
service telnet
{
socket_type = stream
wait = no
server = /usr/kerberos/sbin/telnetd
log_on_success += DURATION USERID
log_on_failure += USERID
bind = 123.123.123.123
redirect = 10.0.1.13 23
}bind and redirect options in this file ensure that the Telnet service on the machine is bound to the external IP address (123.123.123.123), the one facing the Internet. In addition, any requests for Telnet service sent to 123.123.123.123 are redirected via a second network adapter to an internal IP address (10.0.1.13) that only the firewall and internal systems can access. The firewall then sends the communication between the two systems, and the connecting system thinks it is connected to 123.123.123.123 when it is actually connected to a different machine.
xinetd are configured with the bind and redirect options, the gateway machine can act as a proxy between outside systems and a particular internal machine configured to provide the service. In addition, the various xinetd access control and logging options are also available for additional protection.
xinetd daemon can add a basic level of protection from Denial of Service (DoS) attacks. The following is a list of directives which can aid in limiting the effectiveness of such attacks:
per_source — Defines the maximum number of instances for a service per source IP address. It accepts only integers as an argument and can be used in both xinetd.conf and in the service-specific configuration files in the xinetd.d/ directory.
cps — Defines the maximum number of connections per second. This directive takes two integer arguments separated by white space. The first argument is the maximum number of connections allowed to the service per second. The second argument is the number of seconds that xinetd must wait before re-enabling the service. It accepts only integers as arguments and can be used in either the xinetd.conf file or the service-specific configuration files in the xinetd.d/ directory.
max_load — Defines the CPU usage or load average threshold for a service. It accepts a floating point number argument.
uptime, who, and procinfo commands for more information about load average.
xinetd. Refer to the xinetd.conf man page for more information.
xinetd is available from system documentation and on the Internet.
xinetd, and access control.
/usr/share/doc/tcp_wrappers-<version>/ — This directory contains a README file that discusses how TCP Wrappers work and the various hostname and host address spoofing risks that exist.
/usr/share/doc/xinetd-<version>/ — This directory contains a README file that discusses aspects of access control and a sample.conf file with various ideas for modifying service-specific configuration files in the /etc/xinetd.d/ directory.
xinetd-related man pages — A number of man pages exist for the various applications and configuration files involved with TCP Wrappers and xinetd. The following are some of the more important man pages:
man xinetd — The man page for xinetd.
man 5 hosts_access — The man page for the TCP Wrappers hosts access control files.
man hosts_options — The man page for the TCP Wrappers options fields.
man xinetd.conf — The man page listing xinetd configuration options.
xinetd configuration files to meet specific security goals.
xinetd.
ip xfrm commands, however this is not recommended.
yum install openswan command to install Openswan.
/etc/ipsec.d - main directory. Stores Openswan related files.
/etc/ipsec.conf - master configuration file. Further *.conf configuration files can be created in /etc/ipsec.d for individual configurations.
/etc/ipsec.secrets - master secrets file. Further *.secrets files can be created in /etc/ipsec.d for individual configurations.
/etc/ipsec.d/cert*.db - Certificate database files. The old default NSS database file is cert8.db. From Red Hat Enterprise Linux 6 onwards, NSS sqlite databases are used in the cert9.db file.
/etc/ipsec.d/key*.db - Key database files. The old default NSS database file is key3.db. From Red Hat Enterprise Linux 6 onwards, NSS sqlite databases are used in the key4.db file.
/etc/ipsec.d/cacerts - Location for Certificate Authority (CA) certificates.
/etc/ipsec.d/certs - Location for user certificates. Not needed when using NSS.
/etc/ipsec.d/policies - Groups policies. Policies can be defined as block, clear, clear-or-private, private, private-or-clear.
/etc/ipsec.d/nsspassword - NSS password file. This file does not exist by default, and is required if the NSS database in use is created with a password.
/etc/ipsec.conf.
protostack - defines which protocol stack is used. The default option in Red Hat Enterprise Linux 6 is netkey. Other valid values are auto, klips and mast.
nat_traversal - defines if NAT workaround for connections is accepted. Default is no.
dumpdir - defines the location for core dump files.
nhelpers - When using NSS, defines the number of threads used for cryptographic operations. When not using NSS, defines the number of processes used for cryptographic operations.
virtual_private - subnets allowed for the client connection. Ranges that may exist behind a NAT router through which a client connects.
plutorestartoncrash - set to yes by default.
plutostderr - path for pluto error log. Points to syslog location by default.
connaddrfamily - can be set to either ipv4 or ipv6.
ipsec.conf(5) manual page.
service ipsec start/stop is the recommended method of changing the state of the ipsec service. This is also the recommended technique for starting and stopping all other services in Red Hat Enterprise Linux 6.
ipsec setup start/stop
service ipsec start/stop
ipsec auto --add/delete <connection name>
ipsec auto --up/down <connection-name>
ipsec newhostkey --configdir /etc/ipsec.d --password password --output /etc/ipsec.d/<name-of-file>
ip xfrm policy
ip xfrm state
certutil -S -k rsa -n <ca-cert-nickname> -s "CN=ca-cert-common-name" -w 12 -t "C,C,C" -x -d /etc/ipsec.d
certutil -S -k rsa -c <ca-cert-nickname> -n <user-cert-nickname> -s "CN=user-cert-common-name" -w 12 -t "u,u,u" -d /etc/ipsec.d
| Method | Description | Advantages | Disadvantages | ||||||
|---|---|---|---|---|---|---|---|---|---|
| NAT | Network Address Translation (NAT) places private IP subnetworks behind one or a small pool of public IP addresses, masquerading all requests to one source rather than several. The Linux kernel has built-in NAT functionality through the Netfilter kernel subsystem. |
|
| ||||||
| Packet Filter | A packet filtering firewall reads each data packet that passes through a LAN. It can read and process packets by header information and filters the packet based on sets of programmable rules implemented by the firewall administrator. The Linux kernel has built-in packet filtering functionality through the Netfilter kernel subsystem. |
|
| ||||||
| Proxy | Proxy firewalls filter all requests of a certain protocol or type from LAN clients to a proxy machine, which then makes those requests to the Internet on behalf of the local client. A proxy machine acts as a buffer between malicious remote users and the internal network client machines. |
|
|
iptables tool.
iptables administration tool, a command line tool similar in syntax to its predecessor, ipchains, which Netfilter/iptables replaced in the Linux kernel 2.4 and above.
iptables uses the Netfilter subsystem to enhance network connection, inspection, and processing. iptables features advanced logging, pre- and post-routing actions, network address translation, and port forwarding, all in one command line interface.
iptables. For more detailed information, refer to Section 2.6, “IPTables”.
[root@myServer ~] # system-config-firewall
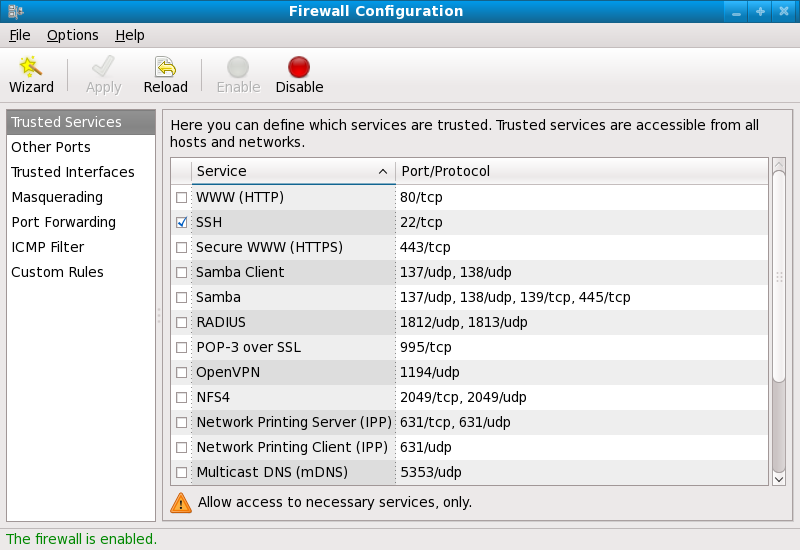
iptables rules.
/etc/sysconfig/iptables file. If you choose Disabled and click , these configurations and firewall rules will be lost.
httpd package be installed.
vsftpd package be installed.
openssh-server package be installed.
telnet-server package be installed.
fetchmail. To allow delivery of mail to your machine, select this check box. Note that an improperly configured SMTP server can allow remote machines to use your server to send spam.
iptables. For example, to allow IRC and Internet printing protocol (IPP) to pass through the firewall, add the following to the Other ports section:
194:tcp,631:tcp
iptables commands and written to the /etc/sysconfig/iptables file. The iptables service is also started so that the firewall is activated immediately after saving the selected options. If Disable firewall was selected, the /etc/sysconfig/iptables file is removed and the iptables service is stopped immediately.
/etc/sysconfig/system-config-firewall file so that the settings can be restored the next time the application is started. Do not edit this file by hand.
iptables service is not configured to start automatically at boot time. Refer to Section 2.5.2.6, “Activating the IPTables Service” for more information.
iptables service is running. To manually start the service, use the following command:
[root@myServer ~] # service iptables restart
iptables starts when the system is booted, use the following command:
[root@myServer ~] # chkconfig --level 345 iptables on
iptables is to start the iptables service. Use the following command to start the iptables service:
[root@myServer ~] # service iptables start
ip6tables service can be turned off if you intend to use the iptables service only. If you deactivate the ip6tables service, remember to deactivate the IPv6 network also. Never leave a network device active without the matching firewall.
iptables to start by default when the system is booted, use the following command:
[root@myServer ~] # chkconfig --level 345 iptables on
iptables to start whenever the system is booted into runlevel 3, 4, or 5.
iptables command illustrates the basic command syntax:
[root@myServer ~ ] # iptables -A<chain>-j<target>
-A option specifies that the rule be appended to <chain>. Each chain is comprised of one or more rules, and is therefore also known as a ruleset.
-j <target> option specifies the target of the rule; i.e., what to do if the packet matches the rule. Examples of built-in targets are ACCEPT, DROP, and REJECT.
iptables man page for more information on the available chains, options, and targets.
iptables chain is comprised of a default policy, and zero or more rules which work in concert with the default policy to define the overall ruleset for the firewall.
[root@myServer ~ ] # iptables -P INPUT DROP [root@myServer ~ ] # iptables -P OUTPUT DROP
[root@myServer ~ ] # iptables -P FORWARD DROP
iptables are transitory; if the system is rebooted or if the iptables service is restarted, the rules are automatically flushed and reset. To save the rules so that they are loaded when the iptables service is started, use the following command:
[root@myServer ~ ] # service iptables save
/etc/sysconfig/iptables and are applied whenever the service is started or the machine is rebooted.
[root@myServer ~ ] # iptables -A INPUT -p tcp -m tcp --dport 80 -j ACCEPT
[root@myServer ~ ] # iptables -A INPUT -p tcp -m tcp --dport 443 -j ACCEPT
iptables ruleset, order is important.
-I option. For example:
[root@myServer ~ ] # iptables -I INPUT 1 -i lo -p all -j ACCEPT
iptables to accept connections from remote SSH clients. For example, the following rules allow remote SSH access:
[root@myServer ~ ] # iptables -A INPUT -p tcp --dport 22 -j ACCEPT [root@myServer ~ ] # iptables -A OUTPUT -p tcp --sport 22 -j ACCEPT
iptables filtering rules.
FORWARD and NAT Rulesiptables provides routing and forwarding policies that can be implemented to prevent abnormal usage of network resources.
FORWARD chain allows an administrator to control where packets can be routed within a LAN. For example, to allow forwarding for the entire LAN (assuming the firewall/gateway is assigned an internal IP address on eth1), use the following rules:
[root@myServer ~ ] # iptables -A FORWARD -i eth1 -j ACCEPT [root@myServer ~ ] # iptables -A FORWARD -o eth1 -j ACCEPT
eth1 device.
[root@myServer ~ ] # sysctl -w net.ipv4.ip_forward=1
/etc/sysctl.conf file as follows:
net.ipv4.ip_forward = 0
net.ipv4.ip_forward = 1
sysctl.conf file:
[root@myServer ~ ] # sysctl -p /etc/sysctl.conf
[root@myServer ~ ] # iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
-t nat) and specifies the built-in POSTROUTING chain for NAT (-A POSTROUTING) on the firewall's external networking device (-o eth0).
-j MASQUERADE target is specified to mask the private IP address of a node with the external IP address of the firewall/gateway.
-j DNAT target of the PREROUTING chain in NAT to specify a destination IP address and port where incoming packets requesting a connection to your internal service can be forwarded.
[root@myServer ~ ] # iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 80 -j DNAT --to 172.31.0.23:80
[root@myServer ~ ] # iptables -A FORWARD -i eth0 -p tcp --dport 80 -d 172.31.0.23 -j ACCEPT
iptables rules to route traffic to certain machines, such as a dedicated HTTP or FTP server, in a demilitarized zone (DMZ). A DMZ is a special local subnetwork dedicated to providing services on a public carrier, such as the Internet.
PREROUTING table to forward the packets to the appropriate destination:
[root@myServer ~ ] # iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 80 -j DNAT --to-destination 10.0.4.2:80
[root@myServer ~ ] # iptables -A OUTPUT -o eth0 -p tcp --dport 31337 --sport 31337 -j DROP [root@myServer ~ ] # iptables -A FORWARD -o eth0 -p tcp --dport 31337 --sport 31337 -j DROP
[root@myServer ~ ] # iptables -A FORWARD -s 192.168.1.0/24 -i eth0 -j DROP
DROP and REJECT targets when dealing with appended rules.
REJECT target denies access and returns a connection refused error to users who attempt to connect to the service. The DROP target, as the name implies, drops the packet without any warning.
REJECT target is recommended.
iptables uses a method called connection tracking to store information about incoming connections. You can allow or deny access based on the following connection states:
NEW — A packet requesting a new connection, such as an HTTP request.
ESTABLISHED — A packet that is part of an existing connection.
RELATED — A packet that is requesting a new connection but is part of an existing connection. For example, FTP uses port 21 to establish a connection, but data is transferred on a different port (typically port 20).
INVALID — A packet that is not part of any connections in the connection tracking table.
iptables connection tracking with any network protocol, even if the protocol itself is stateless (such as UDP). The following example shows a rule that uses connection tracking to forward only the packets that are associated with an established connection:
[root@myServer ~ ] # iptables -A FORWARD -m state --state ESTABLISHED,RELATED -j ACCEPT
ip6tables command. In Red Hat Enterprise Linux 6, both IPv4 and IPv6 services are enabled by default.
ip6tables command syntax is identical to iptables in every aspect except that it supports 128-bit addresses. For example, use the following command to enable SSH connections on an IPv6-aware network server:
[root@myServer ~ ] # ip6tables -A INPUT -i eth0 -p tcp -s 3ffe:ffff:100::1/128 --dport 22 -j ACCEPT
iptables command, including definitions for many command options.
iptables man page contains a brief summary of the various options.
iptables project.
iptables. It includes topics that cover analyzing firewall logs, developing firewall rules, and customizing your firewall using various graphical tools.
ipchains as well as Netfilter and iptables. Additional security topics such as remote access issues and intrusion detection systems are also covered.
ipchains for packet filtering and used lists of rules applied to packets at each step of the filtering process. The 2.4 kernel introduced iptables (also called netfilter), which is similar to ipchains but greatly expands the scope and control available for filtering network packets.
iptables commands, and explains how filtering rules can be preserved between system reboots.
iptables rules and setting up a firewall based on these rules.
iptables, but iptables cannot be used if ipchains is already running. If ipchains is present at boot time, the kernel issues an error and fails to start iptables.
ipchains is not affected by these errors.
filter — The default table for handling network packets.
nat — Used to alter packets that create a new connection and used for Network Address Translation (NAT).
mangle — Used for specific types of packet alteration.
netfilter.
filter table are as follows:
nat table are as follows:
mangle table are as follows:

/etc/sysconfig/iptables or /etc/sysconfig/ip6tables files.
iptables service starts before any DNS-related services when a Linux system is booted. This means that firewall rules can only reference numeric IP addresses (for example, 192.168.0.1). Domain names (for example, host.example.com) in such rules produce errors.
ACCEPT target for a matching packet, the packet skips the rest of the rule checks and is allowed to continue to its destination. If a rule specifies a DROP target, that packet is refused access to the system and nothing is sent back to the host that sent the packet. If a rule specifies a QUEUE target, the packet is passed to user-space. If a rule specifies the optional REJECT target, the packet is dropped, but an error packet is sent to the packet's originator.
ACCEPT, DROP, REJECT, or QUEUE. If none of the rules in the chain apply to the packet, then the packet is dealt with in accordance with the default policy.
iptables command configures these tables, as well as sets up new tables if necessary.
iptables command. The following aspects of the packet are most often used as criteria:
iptables rules must be grouped logically, based on the purpose and conditions of the overall rule, for the rule to be valid. The remainder of this section explains commonly-used options for the iptables command.
iptables commands have the following structure:
iptables [-t <table-name>] <command> <chain-name> \ <parameter-1> <option-1> \ <parameter-n> <option-n><table-name> — Specifies which table the rule applies to. If omitted, the filter table is used.
<command> — Specifies the action to perform, such as appending or deleting a rule.
<chain-name> — Specifies the chain to edit, create, or delete.
<parameter>-<option> pairs — Parameters and associated options that specify how to process a packet that matches the rule.
iptables command can change significantly, based on its purpose.
iptables -D <chain-name> <line-number>
iptables commands, it is important to remember that some parameters and options require further parameters and options to construct a valid rule. This can produce a cascading effect, with the further parameters requiring yet more parameters. Until every parameter and option that requires another set of options is satisfied, the rule is not valid.
iptables -h to view a comprehensive list of iptables command structures.
iptables to perform a specific action. Only one command option is allowed per iptables command. With the exception of the help command, all commands are written in upper-case characters.
iptables commands are as follows:
-A — Appends the rule to the end of the specified chain. Unlike the -I option described below, it does not take an integer argument. It always appends the rule to the end of the specified chain.
-D <integer> | <rule> — Deletes a rule in a particular chain by number (such as 5 for the fifth rule in a chain), or by rule specification. The rule specification must exactly match an existing rule.
-E — Renames a user-defined chain. A user-defined chain is any chain other than the default, pre-existing chains. (Refer to the -N option, below, for information on creating user-defined chains.) This is a cosmetic change and does not affect the structure of the table.
Match not found error. You cannot rename the default chains.
-F — Flushes the selected chain, which effectively deletes every rule in the chain. If no chain is specified, this command flushes every rule from every chain.
-h — Provides a list of command structures, as well as a quick summary of command parameters and options.
-I [<integer>] — Inserts the rule in the specified chain at a point specified by a user-defined integer argument. If no argument is specified, the rule is inserted at the top of the chain.
-A or -I option.
-I with an integer argument. If you specify an existing number when adding a rule to a chain, iptables adds the new rule before (or above) the existing rule.
-L — Lists all of the rules in the chain specified after the command. To list all rules in all chains in the default filter table, do not specify a chain or table. Otherwise, the following syntax should be used to list the rules in a specific chain in a particular table:
iptables -L <chain-name> -t <table-name>-L command option, which provide rule numbers and allow more verbose rule descriptions, are described in Section 2.6.2.6, “Listing Options”.
-N — Creates a new chain with a user-specified name. The chain name must be unique, otherwise an error message is displayed.
-P — Sets the default policy for the specified chain, so that when packets traverse an entire chain without matching a rule, they are sent to the specified target, such as ACCEPT or DROP.
-R — Replaces a rule in the specified chain. The rule's number must be specified after the chain's name. The first rule in a chain corresponds to rule number one.
-X — Deletes a user-specified chain. You cannot delete a built-in chain.
-Z — Sets the byte and packet counters in all chains for a table to zero.
iptables commands, including those used to add, append, delete, insert, or replace rules within a particular chain, require various parameters to construct a packet filtering rule.
-c — Resets the counters for a particular rule. This parameter accepts the PKTS and BYTES options to specify which counter to reset.
-d — Sets the destination hostname, IP address, or network of a packet that matches the rule. When matching a network, the following IP address/netmask formats are supported:
N.N.N.N/M.M.M.MN.N.N.N is the IP address range and M.M.M.M is the netmask.
N.N.N.N/MN.N.N.N is the IP address range and M is the bitmask.
-f — Applies this rule only to fragmented packets.
!) option before this parameter to specify that only unfragmented packets are matched.
-i — Sets the incoming network interface, such as eth0 or ppp0. With iptables, this optional parameter may only be used with the INPUT and FORWARD chains when used with the filter table and the PREROUTING chain with the nat and mangle tables.
!) — Reverses the directive, meaning any specified interfaces are excluded from this rule.
+) — A wildcard character used to match all interfaces that match the specified string. For example, the parameter -i eth+ would apply this rule to any Ethernet interfaces but exclude any other interfaces, such as ppp0.
-i parameter is used but no interface is specified, then every interface is affected by the rule.
-j — Jumps to the specified target when a packet matches a particular rule.
ACCEPT, DROP, QUEUE, and RETURN.
iptables RPM package. Valid targets in these modules include LOG, MARK, and REJECT, among others. Refer to the iptables man page for more information about these and other targets.
-o — Sets the outgoing network interface for a rule. This option is only valid for the OUTPUT and FORWARD chains in the filter table, and the POSTROUTING chain in the nat and mangle tables. This parameter accepts the same options as the incoming network interface parameter (-i).
-p <protocol> — Sets the IP protocol affected by the rule. This can be either icmp, tcp, udp, or all, or it can be a numeric value, representing one of these or a different protocol. You can also use any protocols listed in the /etc/protocols file.
all" protocol means the rule applies to every supported protocol. If no protocol is listed with this rule, it defaults to "all".
-s — Sets the source for a particular packet using the same syntax as the destination (-d) parameter.
iptables command. For example, -p <protocol-name> enables options for the specified protocol. Note that you can also use the protocol ID, instead of the protocol name. Refer to the following examples, each of which have the same effect:
iptables -A INPUT -p icmp --icmp-type any -j ACCEPT iptables -A INPUT -p 5813 --icmp-type any -j ACCEPT /etc/services file. For readability, it is recommended that you use the service names rather than the port numbers.
/etc/services file to prevent unauthorized editing. If this file is editable, crackers can use it to enable ports on your machine you have otherwise closed. To secure this file, type the following commands as root:
[root@myServer ~]# chown root.root /etc/services [root@myServer ~]# chmod 0644 /etc/services [root@myServer ~]# chattr +i /etc/services
-p tcp):
--dport — Sets the destination port for the packet.
:). For example: -p tcp --dport 3000:3200. The largest acceptable valid range is 0:65535.
!) before the --dport option to match all packets that do not use that network service or port.
/etc/services file.
--destination-port match option is synonymous with --dport.
--sport — Sets the source port of the packet using the same options as --dport. The --source-port match option is synonymous with --sport.
--syn — Applies to all TCP packets designed to initiate communication, commonly called SYN packets. Any packets that carry a data payload are not touched.
!) before the --syn option to match all non-SYN packets.
--tcp-flags <tested flag list> <set flag list> — Allows TCP packets that have specific bits (flags) set, to match a rule.
--tcp-flags match option accepts two parameters. The first parameter is the mask; a comma-separated list of flags to be examined in the packet. The second parameter is a comma-separated list of flags that must be set for the rule to match.
ACK
FIN
PSH
RST
SYN
URG
ALL
NONE
iptables rule that contains the following specification only matches TCP packets that have the SYN flag set and the ACK and FIN flags not set:
--tcp-flags ACK,FIN,SYN SYN
!) before the --tcp-flags to reverse the effect of the match option.
--tcp-option — Attempts to match with TCP-specific options that can be set within a particular packet. This match option can also be reversed with the exclamation point character (!).
-p udp):
--dport — Specifies the destination port of the UDP packet, using the service name, port number, or range of port numbers. The --destination-port match option is synonymous with --dport.
--sport — Specifies the source port of the UDP packet, using the service name, port number, or range of port numbers. The --source-port match option is synonymous with --sport.
--dport and --sport options, to specify a range of port numbers, separate the two numbers with a colon (:). For example: -p tcp --dport 3000:3200. The largest acceptable valid range is 0:65535.
-p icmp):
--icmp-type — Sets the name or number of the ICMP type to match with the rule. A list of valid ICMP names can be retrieved by typing the iptables -p icmp -h command.
iptables command.
-m <module-name>, where <module-name> is the name of the module.
limit module — Places limits on how many packets are matched to a particular rule.
LOG target, the limit module can prevent a flood of matching packets from filling up the system log with repetitive messages or using up system resources.
LOG target.
limit module enables the following options:
--limit — Sets the maximum number of matches for a particular time period, specified as a <value>/<period>--limit 5/hour allows five rule matches per hour.
3/hour is assumed.
--limit-burst — Sets a limit on the number of packets able to match a rule at one time.
--limit option.
state module — Enables state matching.
state module enables the following options:
--state — match a packet with the following connection states:
ESTABLISHED — The matching packet is associated with other packets in an established connection. You need to accept this state if you want to maintain a connection between a client and a server.
INVALID — The matching packet cannot be tied to a known connection.
NEW — The matching packet is either creating a new connection or is part of a two-way connection not previously seen. You need to accept this state if you want to allow new connections to a service.
RELATED — The matching packet is starting a new connection related in some way to an existing connection. An example of this is FTP, which uses one connection for control traffic (port 21), and a separate connection for data transfer (port 20).
-m state --state INVALID,NEW.
mac module — Enables hardware MAC address matching.
mac module enables the following option:
--mac-source — Matches a MAC address of the network interface card that sent the packet. To exclude a MAC address from a rule, place an exclamation point character (!) before the --mac-source match option.
iptables man page for more match options available through modules.
<user-defined-chain>ACCEPT — Allows the packet through to its destination or to another chain.
DROP — Drops the packet without responding to the requester. The system that sent the packet is not notified of the failure.
QUEUE — The packet is queued for handling by a user-space application.
RETURN — Stops checking the packet against rules in the current chain. If the packet with a RETURN target matches a rule in a chain called from another chain, the packet is returned to the first chain to resume rule checking where it left off. If the RETURN rule is used on a built-in chain and the packet cannot move up to its previous chain, the default target for the current chain is used.
LOG — Logs all packets that match this rule. Because the packets are logged by the kernel, the /etc/syslog.conf file determines where these log entries are written. By default, they are placed in the /var/log/messages file.
LOG target to specify the way in which logging occurs:
--log-level — Sets the priority level of a logging event. Refer to the syslog.conf man page for a list of priority levels.
--log-ip-options — Logs any options set in the header of an IP packet.
--log-prefix — Places a string of up to 29 characters before the log line when it is written. This is useful for writing syslog filters for use in conjunction with packet logging.
log-prefix value.
--log-tcp-options — Logs any options set in the header of a TCP packet.
--log-tcp-sequence — Writes the TCP sequence number for the packet in the log.
REJECT — Sends an error packet back to the remote system and drops the packet.
REJECT target accepts --reject-with <type> (where <type> is the rejection type) allowing more detailed information to be returned with the error packet. The message port-unreachable is the default error type given if no other option is used. Refer to the iptables man page for a full list of <type>nat table, or with packet alteration using the mangle table, can be found in the iptables man page.
iptables -L [<chain-name>], provides a very basic overview of the default filter table's current chains. Additional options provide more information:
-v — Displays verbose output, such as the number of packets and bytes each chain has processed, the number of packets and bytes each rule has matched, and which interfaces apply to a particular rule.
-x — Expands numbers into their exact values. On a busy system, the number of packets and bytes processed by a particular chain or rule may be abbreviated to Kilobytes, Megabytes (Megabytes) or Gigabytes. This option forces the full number to be displayed.
-n — Displays IP addresses and port numbers in numeric format, rather than the default hostname and network service format.
--line-numbers — Lists rules in each chain next to their numeric order in the chain. This option is useful when attempting to delete the specific rule in a chain or to locate where to insert a rule within a chain.
-t <table-name> — Specifies a table name. If omitted, defaults to the filter table.
iptables command are stored in memory. If the system is restarted before saving the iptables rule set, all rules are lost. For netfilter rules to persist through a system reboot, they need to be saved. To save netfilter rules, type the following command as root:
/sbin/service iptables save iptables init script, which runs the /sbin/iptables-save program and writes the current iptables configuration to /etc/sysconfig/iptables. The existing /etc/sysconfig/iptables file is saved as /etc/sysconfig/iptables.save.
iptables init script reapplies the rules saved in /etc/sysconfig/iptables by using the /sbin/iptables-restore command.
iptables rule before committing it to the /etc/sysconfig/iptables file, it is possible to copy iptables rules into this file from another system's version of this file. This provides a quick way to distribute sets of iptables rules to multiple machines.
[root@myServer ~]# iptables-save >where<filename><filename>is a user-defined name for your ruleset.
/etc/sysconfig/iptables file to other machines, type /sbin/service iptables restart for the new rules to take effect.
iptables command (/sbin/iptables), which is used to manipulate the tables and chains that constitute the iptables functionality, and the iptables service (/sbin/service iptables), which is used to enable and disable the iptables service itself.
iptables in Red Hat Enterprise Linux:
system-config-firewall) — A graphical interface for creating, activating, and saving basic firewall rules. Refer to Section 2.5.2, “Basic Firewall Configuration” for more information.
/sbin/service iptables <option> — Used to manipulate various functions of iptables using its initscript. The following options are available:
start — If a firewall is configured (that is, /etc/sysconfig/iptables exists), all running iptables are stopped completely and then started using the /sbin/iptables-restore command. This option only works if the ipchains kernel module is not loaded. To check if this module is loaded, type the following command as root:
[root@MyServer ~]# lsmod | grep ipchains /sbin/rmmod command to remove the module.
stop — If a firewall is running, the firewall rules in memory are flushed, and all iptables modules and helpers are unloaded.
IPTABLES_SAVE_ON_STOP directive in the /etc/sysconfig/iptables-config configuration file is changed from its default value to yes, current rules are saved to /etc/sysconfig/iptables and any existing rules are moved to the file /etc/sysconfig/iptables.save.
iptables-config file.
restart — If a firewall is running, the firewall rules in memory are flushed, and the firewall is started again if it is configured in /etc/sysconfig/iptables. This option only works if the ipchains kernel module is not loaded.
IPTABLES_SAVE_ON_RESTART directive in the /etc/sysconfig/iptables-config configuration file is changed from its default value to yes, current rules are saved to /etc/sysconfig/iptables and any existing rules are moved to the file /etc/sysconfig/iptables.save.
iptables-config file.
status — Displays the status of the firewall and lists all active rules.
/etc/sysconfig/iptables-config file and change the value of IPTABLES_STATUS_NUMERIC to no. Refer to Section 2.6.4.1, “IPTables Control Scripts Configuration File” for more information about the iptables-config file.
panic — Flushes all firewall rules. The policy of all configured tables is set to DROP.
save — Saves firewall rules to /etc/sysconfig/iptables using iptables-save. Refer to Section 2.6.3, “Saving IPTables Rules” for more information.
ip6tables for iptables in the /sbin/service commands listed in this section. For more information about IPv6 and netfilter, refer to Section 2.6.5, “IPTables and IPv6”.
iptables initscripts is controlled by the /etc/sysconfig/iptables-config configuration file. The following is a list of directives contained in this file:
IPTABLES_MODULES — Specifies a space-separated list of additional iptables modules to load when a firewall is activated. These can include connection tracking and NAT helpers.
IPTABLES_MODULES_UNLOAD — Unloads modules on restart and stop. This directive accepts the following values:
yes — The default value. This option must be set to achieve a correct state for a firewall restart or stop.
no — This option should only be set if there are problems unloading the netfilter modules.
IPTABLES_SAVE_ON_STOP — Saves current firewall rules to /etc/sysconfig/iptables when the firewall is stopped. This directive accepts the following values:
yes — Saves existing rules to /etc/sysconfig/iptables when the firewall is stopped, moving the previous version to the /etc/sysconfig/iptables.save file.
no — The default value. Does not save existing rules when the firewall is stopped.
IPTABLES_SAVE_ON_RESTART — Saves current firewall rules when the firewall is restarted. This directive accepts the following values:
yes — Saves existing rules to /etc/sysconfig/iptables when the firewall is restarted, moving the previous version to the /etc/sysconfig/iptables.save file.
no — The default value. Does not save existing rules when the firewall is restarted.
IPTABLES_SAVE_COUNTER — Saves and restores all packet and byte counters in all chains and rules. This directive accepts the following values:
yes — Saves the counter values.
no — The default value. Does not save the counter values.
IPTABLES_STATUS_NUMERIC — Outputs IP addresses in numeric form instead of domain or hostnames. This directive accepts the following values:
yes — The default value. Returns only IP addresses within a status output.
no — Returns domain or hostnames within a status output.
iptables-ipv6 package is installed, netfilter in Red Hat Enterprise Linux can filter the next-generation IPv6 Internet protocol. The command used to manipulate the IPv6 netfilter is ip6tables.
iptables, except the nat table is not yet supported. This means that it is not yet possible to perform IPv6 network address translation tasks, such as masquerading and port forwarding.
ip6tables are saved in the /etc/sysconfig/ip6tables file. Previous rules saved by the ip6tables initscripts are saved in the /etc/sysconfig/ip6tables.save file.
ip6tables init script are stored in /etc/sysconfig/ip6tables-config, and the names for each directive vary slightly from their iptables counterparts.
iptables-config directive IPTABLES_MODULES:the equivalent in the ip6tables-config file is IP6TABLES_MODULES.
iptables.
man iptables — Contains a description of iptables as well as a comprehensive list of targets, options, and match extensions.
iptables, including a FAQ addressing specific problems and various helpful guides by Rusty Russell, the Linux IP firewall maintainer. The HOWTO documents on the site cover subjects such as basic networking concepts, kernel packet filtering, and NAT configurations.
iptables commands.
[11] Since system BIOSes differ between manufacturers, some may not support password protection of either type, while others may support one type but not the other.
[12] GRUB also accepts unencrypted passwords, but it is recommended that an MD5 hash be used for added security.
[13] This access is still subject to the restrictions imposed by SELinux, if it is enabled.
/etc/pki/tls/openssl.cnf and add the following at the beginning of the file:
openssl_conf = openssl_init
[openssl_init] engines = openssl_engines [openssl_engines] padlock = padlock_engine [padlock_engine] default_algorithms = ALL dynamic_path = /usr/lib/openssl/engines/libpadlock.so init = 1
dynamic_path = /usr/lib64/openssl/engines/libpadlock.so.
# openssl engine -c -tt
# openssl speed aes-128-cbc
# dd if=/dev/zero count=100 bs=1M | ssh -c aes128-cbc localhost "cat >/dev/null"
telinit 1
umount /home
fuser to find and kill processes hogging /home: fuser -mvk /home
cat /proc/mounts | grep home
dd if=/dev/urandom of=/dev/VG00/LV_home This process takes many hours to complete.
cryptsetup --verbose --verify-passphrase luksFormat /dev/VG00/LV_home
cryptsetup luksOpen /dev/VG00/LV_home home
ls -l /dev/mapper | grep home
mkfs.ext3 /dev/mapper/home
mount /dev/mapper/home /home
df -h | grep home
home /dev/VG00/LV_home none
/dev/mapper/home /home ext3 defaults 1 2
/sbin/restorecon -v -R /home
shutdown -r now
luks passphrase on boot
System > Administration > Add/Remove Software and wait for PackageKit to start. Enter Seahorse into the text box and select the Find. Select the checkbox next to the ''seahorse'' package and select ''Apply'' to add the software. You can also install Seahorse at the command line with the command su -c "yum install seahorse".
Seahorse. From the ''File'' menu select ''New'' then ''PGP Key''. Then click ''Continue''. Type your full name, email address, and an optional comment describing who are you (e.g.: John C. Smith, [email protected], The Man). Click ''Create''. A dialog is displayed asking for a passphrase for the key. Choose a strong passphrase but also easy to remember. Click ''OK'' and the key is created.
KGpg window.
gpg --gen-key
Enter key to assign a default value if desired. The first prompt asks you to select what kind of key you prefer:
1y, for example, makes the key valid for one year. (You may change this expiration date after the key is generated, if you change your mind.)
gpg program asks for signature information, the following prompt appears: Is this correct (y/n)? Enter y to finish the process.
gpg program asks you to enter your passphrase twice to ensure you made no typing errors.
gpg generates random data to make your key as unique as possible. Move your mouse, type random keys, or perform other tasks on the system during this step to speed up the process. Once this step is finished, your keys are complete and ready to use:
pub 1024D/1B2AFA1C 2005-03-31 John Q. Doe <[email protected]> Key fingerprint = 117C FE83 22EA B843 3E86 6486 4320 545E 1B2A FA1C sub 1024g/CEA4B22E 2005-03-31 [expires: 2006-03-31]
gpg --fingerprint [email protected]
/var/log/secure and /var/log/audit/audit.log. Note: sending logs to a dedicated log server helps prevent attackers from easily modifying local logs to avoid detection.
sudo to execute commands as root when required. Users capable of running sudo are specified in /etc/sudoers. Use the visudo utility to edit /etc/sudoers.
System -> Preferences -> Software Updates. In KDE it is located at: Applications -> Settings -> Software Updates.
[14] "Advanced Encryption Standard." Wikipedia. 14 November 2009 http://en.wikipedia.org/wiki/Advanced_Encryption_Standard
[15] "Advanced Encryption Standard." Wikipedia. 14 November 2009 http://en.wikipedia.org/wiki/Advanced_Encryption_Standard
[16] "Advanced Encryption Standard." Wikipedia. 14 November 2009 http://en.wikipedia.org/wiki/Advanced_Encryption_Standard
[17] "Data Encryption Standard." Wikipedia. 14 November 2009 http://en.wikipedia.org/wiki/Data_Encryption_Standard
[18] "Data Encryption Standard." Wikipedia. 14 November 2009 http://en.wikipedia.org/wiki/Data_Encryption_Standard
[19] "Data Encryption Standard." Wikipedia. 14 November 2009 http://en.wikipedia.org/wiki/Data_Encryption_Standard
[20] "Public-key Encryption." Wikipedia. 14 November 2009 http://en.wikipedia.org/wiki/Public-key_cryptography
[21] "Public-key Encryption." Wikipedia. 14 November 2009 http://en.wikipedia.org/wiki/Public-key_cryptography
[22] "Public-key Encryption." Wikipedia. 14 November 2009 http://en.wikipedia.org/wiki/Public-key_cryptography
[23] "Public-key Encryption." Wikipedia. 14 November 2009 http://en.wikipedia.org/wiki/Public-key_cryptography
[24] "Public-key Encryption." Wikipedia. 14 November 2009 http://en.wikipedia.org/wiki/Public-key_cryptography
[25] "Diffie-Hellman." Wikipedia. 14 November 2009 http://en.wikipedia.org/wiki/Diffie-Hellman
[26] "Diffie-Hellman." Wikipedia. 14 November 2009 http://en.wikipedia.org/wiki/Diffie-Hellman
[27] "Diffie-Hellman." Wikipedia. 14 November 2009 http://en.wikipedia.org/wiki/Diffie-Hellman
[28] "Diffie-Hellman." Wikipedia. 14 November 2009 http://en.wikipedia.org/wiki/Diffie-Hellman
[29] "DSA." Wikipedia. 24 February 2010 http://en.wikipedia.org/wiki/Digital_Signature_Algorithm
[30] "TLS/SSl." Wikipedia. 24 February 2010 http://en.wikipedia.org/wiki/Transport_Layer_Security
[31] "Cramer-Shoup cryptosystem." Wikipedia. 24 February 2010 http://en.wikipedia.org/wiki/Cramer–Shoup_cryptosystem
[32] "ElGamal encryption" Wikipedia. 24 February 2010 http://en.wikipedia.org/wiki/ElGamal_encryption
| Revision History | |||
|---|---|---|---|
| Revision 1.5 | Apr 19 2010 | ||
| |||
| Revision 1.4.1 | Mar 5 2010 | ||
| |||
| Revision 1.3 | Feb 19 2010 | ||
| |||