

Edition 0
1801 Varsity Drive
Raleigh, NC 27606-2072 USA
Phone: +1 919 754 3700
Phone: 888 733 4281
Fax: +1 919 754 3701
Mono-spaced Bold
To see the contents of the filemy_next_bestselling_novelin your current working directory, enter thecat my_next_bestselling_novelcommand at the shell prompt and press Enter to execute the command.
Press Enter to execute the command.Press Ctrl+Alt+F2 to switch to the first virtual terminal. Press Ctrl+Alt+F1 to return to your X-Windows session.
mono-spaced bold. For example:
File-related classes includefilesystemfor file systems,filefor files, anddirfor directories. Each class has its own associated set of permissions.
Choose → → from the main menu bar to launch Mouse Preferences. In the Buttons tab, click the Left-handed mouse check box and click to switch the primary mouse button from the left to the right (making the mouse suitable for use in the left hand).To insert a special character into a gedit file, choose → → from the main menu bar. Next, choose → from the Character Map menu bar, type the name of the character in the Search field and click . The character you sought will be highlighted in the Character Table. Double-click this highlighted character to place it in the Text to copy field and then click the button. Now switch back to your document and choose → from the gedit menu bar.
Mono-spaced Bold ItalicProportional Bold Italic
To connect to a remote machine using ssh, typesshat a shell prompt. If the remote machine isusername@domain.nameexample.comand your username on that machine is john, typessh [email protected].Themount -o remountcommand remounts the named file system. For example, to remount thefile-system/homefile system, the command ismount -o remount /home.To see the version of a currently installed package, use therpm -qcommand. It will return a result as follows:package.package-version-release
Publican is a DocBook publishing system.
mono-spaced roman and presented thus:
books Desktop documentation drafts mss photos stuff svn books_tests Desktop1 downloads images notes scripts svgs
mono-spaced roman but add syntax highlighting as follows:
package org.jboss.book.jca.ex1; import javax.naming.InitialContext; public class ExClient { public static void main(String args[]) throws Exception { InitialContext iniCtx = new InitialContext(); Object ref = iniCtx.lookup("EchoBean"); EchoHome home = (EchoHome) ref; Echo echo = home.create(); System.out.println("Created Echo"); System.out.println("Echo.echo('Hello') = " + echo.echo("Hello")); } }
[1] This feature is being provided in this release as a technology preview. Technology Preview features are currently not supported under Red Hat Enterprise Linux subscription services, may not be functionally complete, and are generally not suitable for production use. However, these features are included as a customer convenience and to provide the feature with wider exposure.
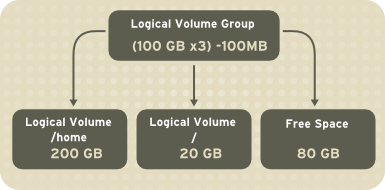
/home file system when 50GB or more is available for allocation of LVM physical volumes. The root file system (/) will be limited to a maximum of 50GB whe creating a separate /home logical volume, but the /home logical volume will grow to occupy all remaining space in the volume group.
| File System | Max Supported Size | Max File Size | Max Subdirectories (per directory) | Max Depth of Symbolic Links | ACL Support | Details |
|---|---|---|---|---|---|---|
| Ext2 | 8TB | 2TB | 32,000 | 8 | Yes | N/A |
| Ext3 | 16TB | 2TB | 32,000 | 8 | Yes | Chapter 6, The Ext3 File System |
| Ext4 | 16TB | 16TB | 65,000[a] | 8 | Yes | Chapter 7, The Ext4 File System |
| XFS | 100TB | 16TB | 65,000[a] | 8 | Yes | Chapter 9, The XFS File System |
[a] When the link count exceeds 65,000, it is reset to 1 and no longer increases. | ||||||
/home, /opt, and /usr/local on a separate device. This will allow you to reformat the devices/file systems containing the operating system while preserving your user and application data.
DASD= parameter at the boot command line or in a CMS configuration file.
FCP_x= lines on the boot command line (or in a CMS configuration file) allow you to specify this information for the installer.
dm-crypt will destroy any existing formatting on that device. As such, you should decide which devices to encrypt (if any) before the new system's storage configuration is activated as part of the installation process.
dmraid -r -E /device/
man dmraid and Chapter 13, Redundant Array of Independent Disks (RAID).
mmap(2)-based I/O will not work reliably, as there are no interlocks in the buffered write path to prevent buffered data from being overwritten after the DIF/DIX checksum has been calculated.
mmap(2) I/O, so it is not possible to work around these errors caused by overwrites.
O_DIRECT. Such applications should use the raw block device. Alternatively, it is also safe to use the XFS filesystem on a DIF/DIX enabled block device, as long as only O_DIRECT I/O is issued through the file system. XFS is the only filesystem that does not fall back to buffered IO when doing certain allocation operations.
O_DIRECT I/O and DIF/DIX hardware should use DIF/DIX.
/boot/ partition. The /boot/ partition cannot be on a logical volume group because the boot loader cannot read it. If the root (/) partition is on a logical volume, create a separate /boot/ partition which is not a part of a volume group.
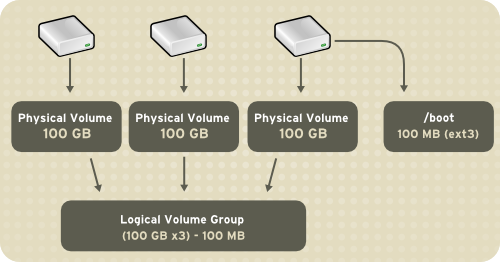
/home and / and file system types, such as ext2 or ext3. When "partitions" reach their full capacity, free space from the volume group can be added to the logical volume to increase the size of the partition. When a new hard drive is added to the system, it can be added to the volume group, and partitions that are logical volumes can be increased in size.
system-config-lvm. For comprehensive information on the creation and configuration of LVM partitions in clustered and non-clustered storage, please refer to the Logical Volume Manager Administration guide also provided by Red Hat.
system-config-lvmsystem-config-lvm from a terminal.
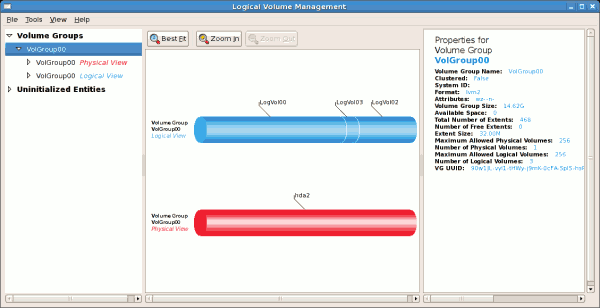
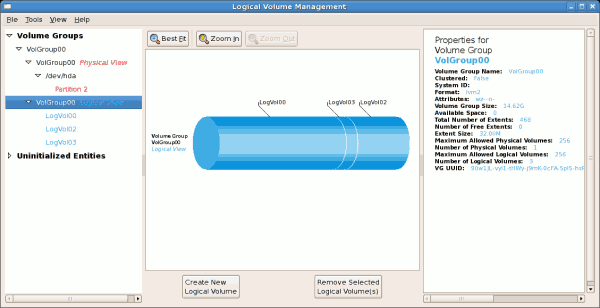
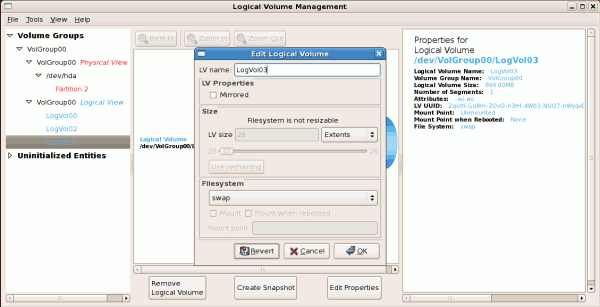
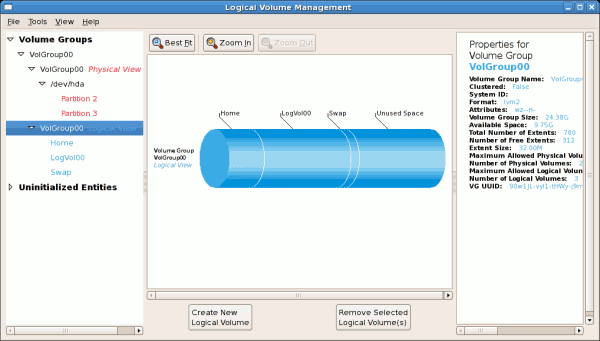
/boot - (Ext3) file system. Displayed under 'Uninitialized Entities'. (DO NOT initialize this partition). LogVol00 - (LVM) contains the (/) directory (312 extents). LogVol02 - (LVM) contains the (/home) directory (128 extents). LogVol03 - (LVM) swap (28 extents).
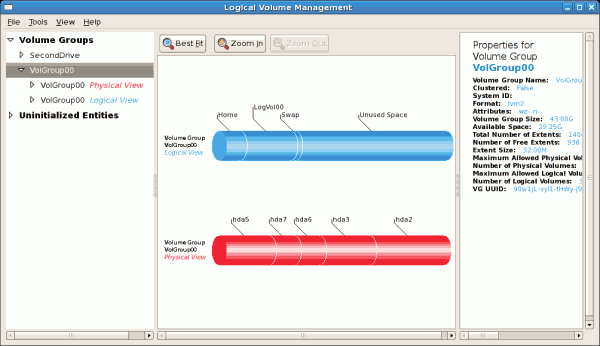
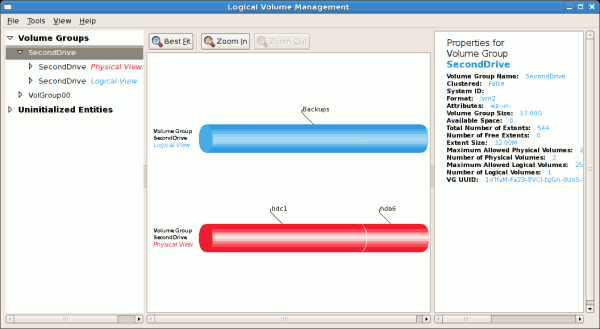
/dev/hda2 while /boot was created in /dev/hda1. The system also consists of 'Uninitialised Entities' which are illustrated in Figure 3.7, “Uninitialized Entities”. The figure below illustrates the main window in the LVM utility. The logical and the physical views of the above configuration are illustrated below. The three logical volumes exist on the same physical volume (hda2).
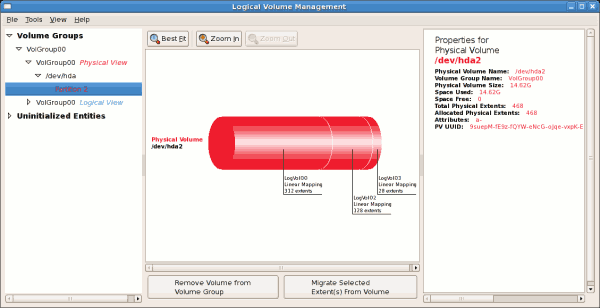
/ (root) directory, this task will not be successful as the volume cannot be unmounted.
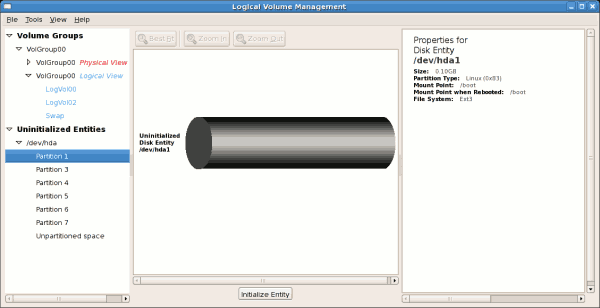
/boot. Uninitialized entities are illustrated below.
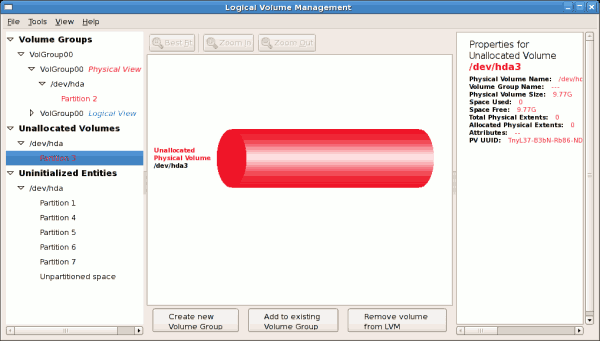
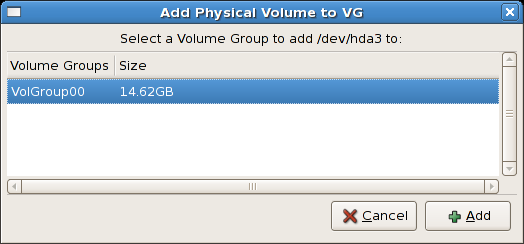
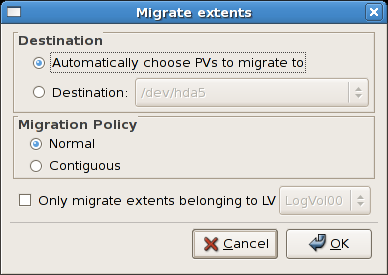
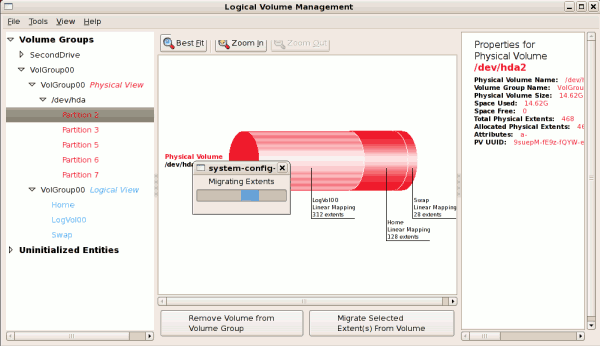
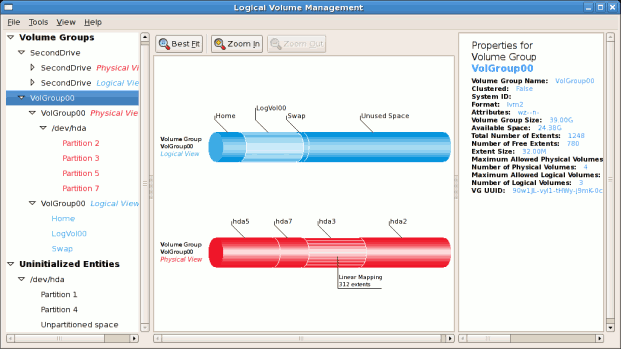
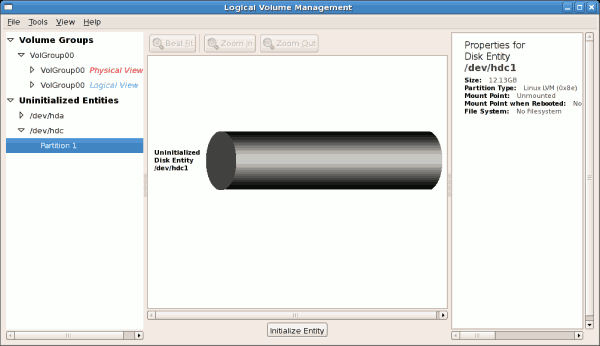
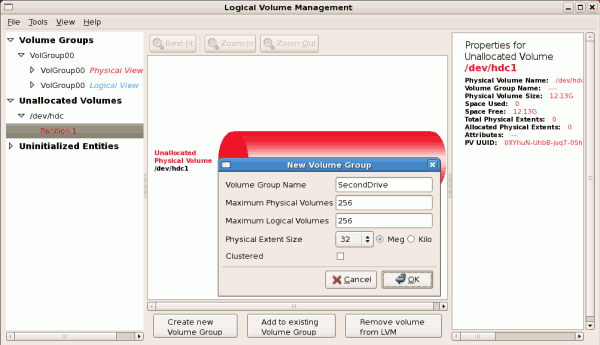
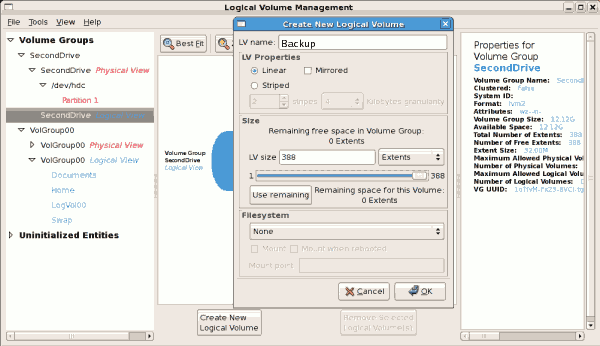
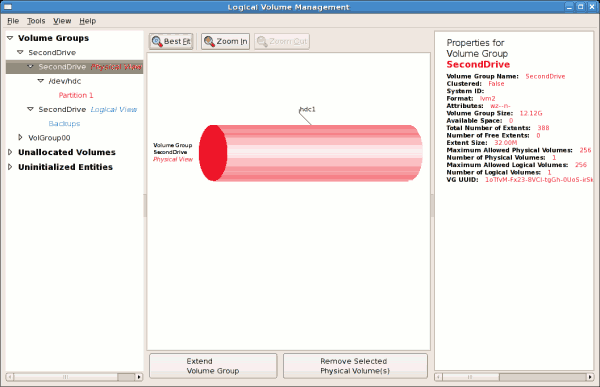
/dev/hda6 was selected as illustrated below.
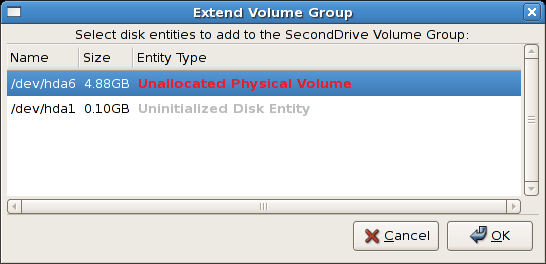
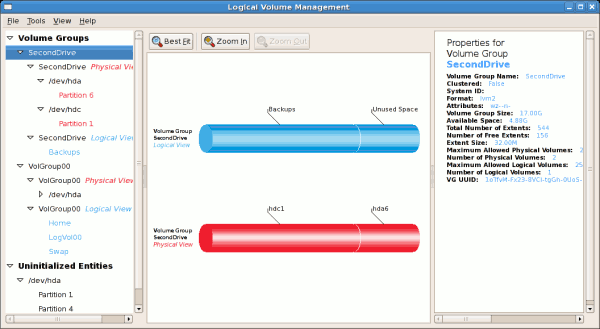
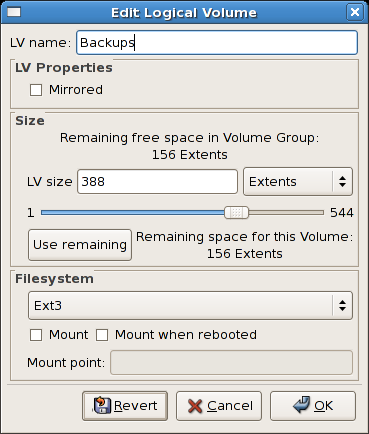
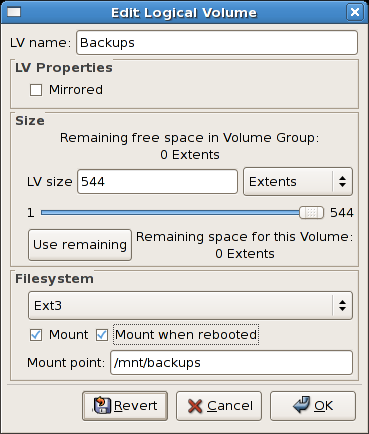
/mnt/backups. This is illustrated in the figure below.
rpm -qd lvm2 — This command shows all the documentation available from the lvm package, including man pages.
lvm help — This command shows all LVM commands available.
parted allows users to:
parted package is included when installing Red Hat Enterprise Linux. To start parted, log in as root and type the command parted /dev/sda at a shell prompt (where /dev/sdaumount command and turn off all the swap space on the hard drive with the swapoff command.
parted commands” contains a list of commonly used parted commands. The sections that follow explain some of these commands and arguments in more detail.
parted commands| Command | Description |
|---|---|
check
| Perform a simple check of the file system |
cp
|
Copy file system from one partition to another; from and to are the minor numbers of the partitions
|
help
| Display list of available commands |
mklabel
| Create a disk label for the partition table |
mkfs
|
Create a file system of type file-system-type
|
mkpart
| Make a partition without creating a new file system |
mkpartfs
| Make a partition and create the specified file system |
move
| Move the partition |
name
| Name the partition for Mac and PC98 disklabels only |
print
| Display the partition table |
quit
|
Quit parted
|
rescue start-mb end-mb
|
Rescue a lost partition from start-mb to end-mb
|
resize
|
Resize the partition from start-mb to end-mb
|
rm
| Remove the partition |
select
| Select a different device to configure |
set
|
Set the flag on a partition; state is either on or off
|
toggle [
|
Toggle the state of FLAG on partition NUMBER
|
unit
|
Set the default unit to UNIT
|
parted, use the command print to view the partition table. A table similar to the following appears:
Model: ATA ST3160812AS (scsi) Disk /dev/sda: 160GB Sector size (logical/physical): 512B/512B Partition Table: msdos Number Start End Size Type File system Flags 1 32.3kB 107MB 107MB primary ext3 boot 2 107MB 105GB 105GB primary ext3 3 105GB 107GB 2147MB primary linux-swap 4 107GB 160GB 52.9GB extended root 5 107GB 133GB 26.2GB logical ext3 6 133GB 133GB 107MB logical ext3 7 133GB 160GB 26.6GB logical lvm
number. For example, the partition with minor number 1 corresponds to /dev/sda1. The Start and End values are in megabytes. Valid Type are metadata, free, primary, extended, or logical. The Filesystem is the file system type, which can be any of the following:
Filesystem of a device shows no value, this means that its file system type is unknown.
parted, where /dev/sda is the device on which to create the partition:
parted /dev/sda
print
mkpart primary ext3 1024 2048
mkpartfs command instead, the file system is created after the partition is created. However, parted does not support creating an ext3 file system. Thus, if you wish to create an ext3 file system, use mkpart and create the file system with the mkfs command as described later.
print command to confirm that it is in the partition table with the correct partition type, file system type, and size. Also remember the minor number of the new partition so that you can label any file systems on it. You should also view the output of cat /proc/partitions to make sure the kernel recognizes the new partition.
/sbin/mkfs -t ext3 /dev/sda6
/dev/sda6 and you want to label it /work, use:
e2label /dev/sda6 /work
/work) as root.
/etc/fstab/etc/fstab file to include the new partition using the partition's UUID. Use the blkid -L label command to retrieve the partition's UUID. The new line should look similar to the following:
UUID=93a0429d-0318-45c0-8320-9676ebf1ca79 /work ext3 defaults 1 2
UUID= followed by the file system's UUID. The second column should contain the mount point for the new partition, and the next column should be the file system type (for example, ext3 or swap). If you need more information about the format, read the man page with the command man fstab.
defaults, the partition is mounted at boot time. To mount the partition without rebooting, as root, type the command:
mount /work
parted, where /dev/sda is the device on which to remove the partition:
parted /dev/sda
print
rm. For example, to remove the partition with minor number 3:
rm 3
print command to confirm that it is removed from the partition table. You should also view the output of
cat /proc/partitions
/etc/fstab file. Find the line that declares the removed partition, and remove it from the file.
parted, where /dev/sda is the device on which to resize the partition:
parted /dev/sda
print
resize command followed by the minor number for the partition, the starting place in megabytes, and the end place in megabytes. For example:
resize 3 1024 2048
print command to confirm that the partition has been resized correctly, is the correct partition type, and is the correct file system type.
df to make sure the partition was mounted and is recognized with the new size.
/usr/ partition as read-only. This is especially crucial, since /usr/ contains common executables and should not be changed by users. In addition, since /usr/ is mounted as read-only, it should be mountable from the CD-ROM drive or from another machine via a read-only NFS mount.
df command reports the system's disk space usage. Its output looks similar to the following:
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/VolGroup00-LogVol00
11675568 6272120 4810348 57% / /dev/sda1
100691 9281 86211 10% /boot
none 322856 0 322856 0% /dev/shm
df shows the partition size in 1 kilobyte blocks and the amount of used/available disk space in kilobytes. To view the information in megabytes and gigabytes, use the command df -h. The -h argument stands for "human-readable" format. The output for df -h looks similar to the following:
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup00-LogVol00
12G 6.0G 4.6G 57% / /dev/sda1
99M 9.1M 85M 10% /boot
none 316M 0 316M 0% /dev/shm
/dev/shm represents the system's virtual memory file system.
du command displays the estimated amount of space being used by files in a directory, displaying the disk usage of each subdirectory. The last line in the output of du shows the total disk usage of the directory; to see only the total disk usage of a directory in human-readable format, use du -hs. For more options, refer to man du.
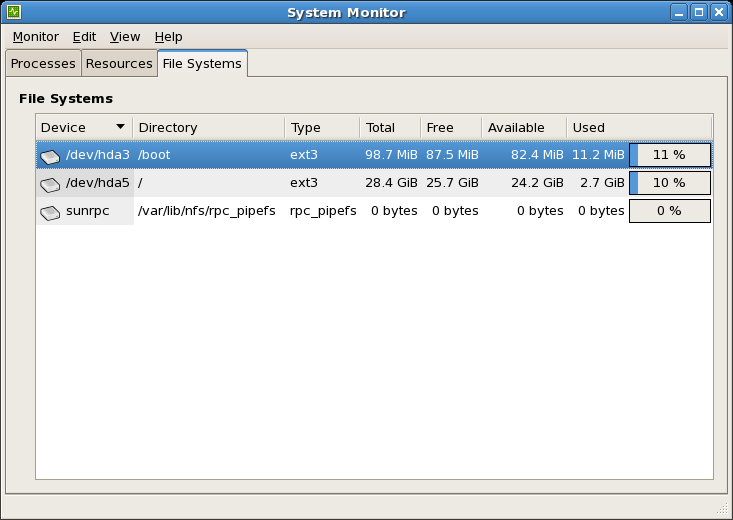
gnome-system-monitor. Select the File Systems tab to view the system's partitions. The figure below illustrates the File Systems tab.
/boot/ Directory/boot/ directory contains static files required to boot the system, e.g. the Linux kernel. These files are essential for the system to boot properly.
/boot/ directory. Doing so renders the system unbootable.
/dev/ Directory/dev/ directory contains device nodes that represent the following device types:
udevd daemon creates and removes device nodes in /dev/ as needed.
/dev/ directory and subdirectories are either character (providing only a serial stream of input/output, e.g. mouse or keyboard) or block (accessible randomly, e.g. hard drive, floppy drive). If you have GNOME or KDE installed, some storage devices are automatically detected when connected (e.g via USB) or inserted (e.g via CD or DVD drive), and a popup window displaying the contents appears.
/dev| File | Description |
|---|---|
| /dev/hda | The master device on primary IDE channel. |
| /dev/hdb | The slave device on primary IDE channel. |
| /dev/tty0 | The first virtual console. |
| /dev/tty1 | The second virtual console. |
| /dev/sda | The first device on primary SCSI or SATA channel. |
| /dev/lp0 | The first parallel port. |
/etc/ Directory/etc/ directory is reserved for configuration files that are local to the machine. It should contain no binaries; any binaries should be moved to /bin/ or /sbin/.
/etc/skel/ directory stores "skeleton" user files, which are used to populate a home directory when a user is first created. Applications also store their configuration files in this directory and may reference them when executed. The /etc/exports file controls which file systems to export to remote hosts.
/lib/ Directory/lib/ directory should only contain libraries needed to execute the binaries in /bin/ and /sbin/. These shared library images are used to boot the system or execute commands within the root file system.
/media/ Directory/media/ directory contains subdirectories used as mount points for removeable media such as USB storage media, DVDs, CD-ROMs, and Zip disks.
/mnt/ Directory/mnt/ directory is reserved for temporarily mounted file systems, such as NFS file system mounts. For all removeable storage media, use the /media/ directory. Automatically detected removeable media will be mounted in the /media directory.
/mnt directory must not be used by installation programs.
/opt/ Directory/opt/ directory is normally reserved for software and add-on packages that are not part of the default installation. A package that installs to /opt/ creates a directory bearing its name, e.g. /opt/packagename/. In most cases, such packages follow a predictable subdirectory structure; most store their binaries in /opt/packagename/bin/ and their man pages in /opt/packagename/man/, and so on.
/proc/ Directory/proc/ directory contains special files that either extract information from the kernel or send information to it. Examples of such information include system memory, cpu information, and hardware configuration. For more information about /proc/, refer to Section 5.4, “The /proc Virtual File System”.
/sbin/ Directory/sbin/ directory stores binaries essential for booting, restoring, recovering, or repairing the system. The binaries in /sbin/ require root privileges to use. In addition, /sbin/ contains binaries used by the system before the /usr/ directory is mounted; any system utilities used after /usr/ is mounted is typically placed in /usr/sbin/.
/sbin/:
arp
clock
halt
init
fsck.*
grub
ifconfig
mingetty
mkfs.*
mkswap
reboot
route
shutdown
swapoff
swapon
/srv/ Directory/srv/ directory contains site-specific data served by a Red Hat Enterprise Linux system. This directory gives users the location of data files for a particular service, such as FTP, WWW, or CVS. Data that only pertains to a specific user should go in the /home/ directory.
/sys/ Directory/sys/ directory utilizes the new sysfs virtual file system specific to the 2.6 kernel. With the increased support for hot plug hardware devices in the 2.6 kernel, the /sys/ directory contains information similar to that held by /proc/, but displays a hierarchical view device information specific to hot plug devices.
/usr/ Directory/usr/ directory is for files that can be shared across multiple machines. The /usr/ directory is often on its own partition and is mounted read-only. At a minimum, /usr/ should contain the following subdirectories:
/usr/bin, used for binaries
/usr/etc, used for system-wide configuration files
/usr/games
/usr/include, used for C header files
/usr/kerberos, used for Kerberos-related binaries and files
/usr/lib, used for object files and libraries that are not designed to be directly utilized by shell scripts or users
/usr/libexec, contains small helper programs called by other programs
/usr/sbin, stores system administration binaries that do not belong to /sbin/
/usr/share, stores files that are not architecture-specific
/usr/src, stores source code
/usr/tmp -> /var/tmp
/usr/ directory should also contain a /local/ subdirectory. As per the FHS, this subdirectory is used by the system administrator when installing software locally, and should be safe from being overwritten during system updates. The /usr/local directory has a structure similar to /usr/, and contains the following subdirectories:
/usr/local/bin
/usr/local/etc
/usr/local/games
/usr/local/include
/usr/local/lib
/usr/local/libexec
/usr/local/sbin
/usr/local/share
/usr/local/src
/usr/local/ differs slightly from the FHS. The FHS states that /usr/local/ should be used to store software that should remain safe from system software upgrades. Since the RPM Package Manager can perform software upgrades safely, it is not necessary to protect files by storing them in /usr/local/.
/usr/local/ for software local to the machine. For instance, if the /usr/ directory is mounted as a read-only NFS share from a remote host, it is still possible to install a package or program under the /usr/local/ directory.
/var/ Directory/usr/ as read-only, any programs that write log files or need spool/ or lock/ directories should write them to the /var/ directory. The FHS states /var/ is for variable data files, which include spool directories/files, logging data, transient/temporary files, and the like.
/var/ directory:
/var/account/
/var/arpwatch/
/var/cache/
/var/crash/
/var/db/
/var/empty/
/var/ftp/
/var/gdm/
/var/kerberos/
/var/lib/
/var/local/
/var/lock/
/var/log/
/var/mail -> /var/spool/mail/
/var/mailman/
/var/named/
/var/nis/
/var/opt/
/var/preserve/
/var/run/
/var/spool/
/var/tmp/
/var/tux/
/var/www/
/var/yp/
messages and lastlog, go in the /var/log/ directory. The /var/lib/rpm/ directory contains RPM system databases. Lock files go in the /var/lock/ directory, usually in directories for the program using the file. The /var/spool/ directory has subdirectories that store data files for some programs. These subdirectories include:
/var/spool/at/
/var/spool/clientmqueue/
/var/spool/cron/
/var/spool/cups/
/var/spool/exim/
/var/spool/lpd/
/var/spool/mail/
/var/spool/mailman/
/var/spool/mqueue/
/var/spool/news/
/var/spool/postfix/
/var/spool/repackage/
/var/spool/rwho/
/var/spool/samba/
/var/spool/squid/
/var/spool/squirrelmail/
/var/spool/up2date/
/var/spool/uucp
/var/spool/uucppublic/
/var/spool/vbox/
/var/lib/rpm/ directory. For more information on RPM, refer to man rpm.
/var/cache/yum/ directory contains files used by the Package Updater, including RPM header information for the system. This location may also be used to temporarily store RPMs downloaded while updating the system. For more information about Red Hat Network, refer to the documentation online at https://rhn.redhat.com/.
/etc/sysconfig/ directory. This directory stores a variety of configuration information. Many scripts that run at boot time use the files in this directory.
/proc contains neither text not binary files. Instead, it houses virtual files; hence, /proc is normally referred to as a virtual file system. These virtual files are typically zero bytes in size, even if they contain a large amount of information.
/proc file system is not used for storage per se. Its main purpose is to provide a file-based interface to hardware, memory, running processes, and other system components. You can retrieve real-time information on many system components by viewing the corresponding /proc file. Some of the files within /proc can also be manipulated (by both users and applications) to configure the kernel.
/proc files are relevant in managing and monitoring system storage:
/proc file system, refer to the Red Hat Enterprise Linux 6 Deployment Guide.
e2fsck program. This is a time-consuming process that can delay system boot time significantly, especially with large volumes containing a large number of files. During this time, any data on the volumes is unreachable.
data=ordered (default).
mke2fs -I option, or specified in /etc/mke2fs.conf to set system-wide defaults for mke2fs.
data_err=abort. This option instructs ext3 to abort the journal if an error occurs in a file data (as opposed to metadata) buffer in data=ordered mode. This option is disabled by default (i.e. set as data_err=ignore).
mkfs), mke2fs will attempt to "discard" or "trim" blocks not used by the file system metadata. This helps to optimize SSDs or thinly-provisioned storage. To suppress this behavior, use the mke2fs -K option.
mkfs.
e2label.
tune2fs allows you to convert an ext2 file system to ext3.
e2fsck utility to check your file system before and after using tune2fs. A default installation of Red Hat Enterprise Linux uses ext4 for all file systems. Before trying to convert, back up all your file systems in case any errors occur.
ext2 file system to ext3, log in as root and type the following command in a terminal:
tune2fs -j block_device
block_device contains the ext2 file system you wish to convert.
/dev/mapper/VolGroup00-LogVol02.
/dev/sdbX, where sdb is a storage device name and X is the partition number.
df command to display mounted file systems.
/dev/mapper/VolGroup00-LogVol02
umount /dev/mapper/VolGroup00-LogVol02
tune2fs -O ^has_journal /dev/mapper/VolGroup00-LogVol02
e2fsck -y /dev/mapper/VolGroup00-LogVol02
mount -t ext2 /dev/mapper/VolGroup00-LogVol02 /mount/point
/mount/point with the mount point of the partition.
.journal file exists at the root level of the partition, delete it.
/etc/fstab file.
fsync() call afterwards.
fsync(). This behavior hid bugs in programs that did not use fsync() to to ensure that written data was on-disk. The ext4 file system, on the other hand, often waits several seconds to write out changes to disk, allowing it to combine and reorder writes for better disk performance than ext3
fsync() to ensure that data is written to permanent storage.
xattr), which allows the system to associate several additional name/value pairs per file.
data=ordered (default).
mkfs.ext4 command. In general, the default options are optimal for most usage scenarios, as in:
mkfs.ext4 /dev/device
mke2fs 1.41.9 (22-Aug-2009) Filesystem label= OS type: Linux Block size=4096 (log=2) Fragment size=4096 (log=2) 1954064 inodes, 7813614 blocks 390680 blocks (5.00%) reserved for the super user First data block=0 Maximum filesystem blocks=4294967296 239 block groups 32768 blocks per group, 32768 fragments per group 8176 inodes per group Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000 Writing inode tables: done Creating journal (32768 blocks): done Writing superblocks and filesystem accounting information: done
mkfs.ext4 chooses an optimal geometry. This may also be true on some hardware RAIDs which export geometry information to the operating system.
-E option of mkfs.ext4 (i.e. extended file system options) with the following sub-options:
valuevaluevaluemkfs.ext4 -E stride=16,stripe-width=64 /dev/device
man mkfs.ext4.
tune2fs to enable some ext4 features on ext3 file systems, and to use the ext4 driver to mount an ext3 file system. These actions, however, are not supported in Red Hat Enterprise Linux 6, as they have not been fully tested. Because of this, Red Hat cannot guarantee consistent performance and predictable behavior for ext3 file systems converted or mounted thusly.
mount /dev/device /mount/point
acl parameter enables access control lists, while the user_xattr parameter enables user extended attributes. To enable both options, use their respective parameters with -o, as in:
mount -o acl,user_xattr /dev/device /mount/point
tune2fs utility also allows administrators to set default mount options in the file system superblock. For more information on this, refer to man tune2fs.
nobarrier option, as in:
mount -o nobarrier /dev/device /mount/point
resize2fs command, as in:
resize2fs /mount/point size
resize2fs command can also decrease the size of an unmounted ext4 file system, as in:
resize2fs /dev/device size
resize2fs utility reads the size in units of file system block size, unless a suffix indicating a specific unit is used. The following suffixes indicate specific units:
s — 512kb sectors
K — kilobytes
M — megabytes
G — gigabytes
man resize2fs.
quota, refer to man quota and Section 15.1, “Configuring Disk Quotas”.
tune2fs utility can also adjust configurable file system parameters for ext2, ext3, and ext4 file systems. In addition, the following tools are also useful in debugging and analyzing ext4 file systems:
man pages.
fsck command on a very large file system can take a long time and consume a large amount of memory. Additionally, in the event of a disk or disk-subsytem failure, recovery time is limited by the speed of your backup media.
clvmd, running in a Red Hat Cluster Suite cluster. The daemon makes it possible to use LVM2 to manage logical volumes across a cluster, allowing all nodes in the cluster to share the logical volumes. For information on the LVM volume manager, see Logical Volume Manager Administration.
gfs2.ko kernel module implements the GFS2 file system and is loaded on GFS2 cluster nodes.
fsync() call afterwards.
xattr), which allows the system to associate several additional name/value pairs per file.
mkfs.xfs /dev/device command. In general, the default options are optimal for common use.
mkfs.xfs on a block device containing an existing file system, use the -f option to force an overwrite of that file system.
mkfs.xfs command:
meta-data=/dev/device isize=256 agcount=4, agsize=3277258 blks
= sectsz=512 attr=2
data = bsize=4096 blocks=13109032, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0
log =internal log bsize=4096 blocks=6400, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0xfs_growfs command (refer to Section 9.4, “Increasing the Size of an XFS File System”).
mkfs.xfs chooses an optimal geometry. This may also be true on some hardware RAIDs which export geometry information to the operating system.
mkfs.xfs sub-options:
valuevaluek, m, or g suffix.
valuemkfs.xfs -d su=64k,sw=4 /dev/device
man mkfs.xfs.
mount /dev/device /mount/point
inode64 mount option. This option configures XFS to allocate inodes and data across the entire file system, which can improve performance:
mount -o inode64 /dev/device /mount/point
nobarrier option, as in:
mount -o nobarrier /dev/device /mount/point
noenforce; this will allow usage reporting without enforcing any limits. Valid quota mount options are:
uquota/uqnoenforce - User quotas
gquota/gqnoenforce - Group quotas
pquota/pqnoenforce - Project quota
xfs_quota tool can be used to set limits and report on disk usage. By default, xfs_quota is run interactively, and in basic mode. Basic mode sub-commands simply report usage, and are available to all users. Basic xfs_quota sub-commands include:
username/userIDusernameuserIDxfs_quota also has an expert mode. The sub-commands of this mode allow actual configuration of limits, and are available only to users with elevated privileges. To use expert mode sub-commands interactively, run xfs_quota -x. Expert mode sub-commands include:
/pathhelp.
-c option, with -x for expert sub-commands. For example, to display a sample quota report for /home (on /dev/blockdevice), use the command xfs_quota -cx 'report -h' /home. This will display output similar to the following:
User quota on /home (/dev/blockdevice)
Blocks
User ID Used Soft Hard Warn/Grace
---------- ---------------------------------
root 0 0 0 00 [------]
testuser 103.4G 0 0 00 [------]
...
john (whose home directory is /home/john), use the following command:
xfs_quota -x -c 'limit isoft=500 ihard=700 /home/john'
limit sub-command recognizes targets as users. When configuring the limits for a group, use the -g option (as in the previous example). Similarly, use -p for projects.
bsoft/bhard instead of isoft/ihard. For example, to set a soft and hard block limit of 1000m and 1200m, respectively, to group accounting on the /target/path file system, use the following command:
xfs_quota -x -c 'limit -g bsoft=1000m bhard=1200m accounting' /target/path
rtbhard/rtbsoft) are described in man xfs_quota as valid units when setting quotas, the real-time sub-volume is not enabled in this release. As such, the rtbhard and rtbsoft options are not applicable.
/etc/projects. Project names can be added to/etc/projectid to map project IDs to project names. Once a project is added to /etc/projects, initialize its project directory using the following command:
xfs_quota -c 'project -s projectname'
xfs_quota -x -c 'limit -p bsoft=1000m bhard=1200m projectname'
quota, repquota, edquota) may also be used to manipulate XFS quotas. However, these tools cannot be used with XFS project quotas.
man xfs_quota.
xfs_growfs command, as in:
xfs_growfs /mount/point -D size
-D size option grows the file system to the specified size-D size option, xfs_growfs will grow the file system to the maximum size supported by the device.
-D size, ensure that the underlying block device is of an appropriate size to hold the file system later. Use the appropriate resizing methods for the affected block device.
man xfs_growfs.
xfs_repair, as in:
xfs_repair /dev/device
xfs_repair utility is highly scalable, and is designed to repair even very large file systems with many inodes efficiently. Note that unlike other Linux file systems, xfs_repair does not run at boot time, even when an XFS file system was not cleanly unmounted. In the event of an unclean unmount, xfs_repair simply replays the log at mount time, ensuring a consistent file system.
xfs_repair utility cannot repair an XFS file system with a dirty log. To clear the log, mount and unmount the XFS file system. If the log is corrupt and cannot be replayed, use the -L option ("force log zeroing") to clear the log, i.e. xfs_repair -L /dev/device. Note, however, that this may result in further corruption or data loss.
man xfs_repair.
xfs_freeze. Suspending write activity allows hardware-based device snapshots to be used to capture the file system in a consistent state.
xfs_freeze utility is provided by the xfsprogs package, which is only available on x86_64.
xfs_freeze -f /mount/point
xfs_freeze -u /mount/point
xfs_freeze to suspend the file system first. Rather, the LVM management tools will automatically suspend the XFS file system before taking the snapshot.
xfs_freeze utility to freeze/unfreeze an ext3, ext4, GFS2, XFS, and BTRFS, file system. The syntax for doing so is also the same.
man xfs_freeze.
xfsdump and xfsrestore.
xfsdump utility. Red Hat Enterprise Linux 6 supports backups to tape drives or regular file images, and also allows multiple dumps to be written to the same tape. The xfsdump utility also allows a dump to span multiple tapes, although only one dump can be written to a regular file. In addition, xfsdump supports incremental backups, and can exclude files from a backup using size, subtree, or inode flags to filter them.
xfsdump uses dump levels to determine a base dump to which a specific dump is relative. The -l option specifies a dump level (0-9). To perform a full backup, perform a level 0 dump on the file system (i.e. /path/to/filesystemxfsdump -l 0 -f /dev/device /path/to/filesystem
-f option specifies a destination for a backup. For example, the /dev/st0 destination is normally used for tape drives. An xfsdump destination can be a tape drive, regular file, or remote tape device.
xfsdump -l 1 -f /dev/st0 /path/to/filesystem
xfsrestore utility restores file systems from dumps produced by xfsdump. The xfsrestore utility has two modes: a default simple mode, and a cumulative mode. Specific dumps are identified by session ID or session label. As such, restoring a dump requires its corresponding session ID or label. To display the session ID and labels of all dumps (both full and incremental), use the -I option, as in:
xfsrestore -I
file system 0: fs id: 45e9af35-efd2-4244-87bc-4762e476cbab session 0: mount point: bear-05:/mnt/test device: bear-05:/dev/sdb2 time: Fri Feb 26 16:55:21 2010 session label: "my_dump_session_label" session id: b74a3586-e52e-4a4a-8775-c3334fa8ea2c level: 0 resumed: NO subtree: NO streams: 1 stream 0: pathname: /mnt/test2/backup start: ino 0 offset 0 end: ino 1 offset 0 interrupted: NO media files: 1 media file 0: mfile index: 0 mfile type: data mfile size: 21016 mfile start: ino 0 offset 0 mfile end: ino 1 offset 0 media label: "my_dump_media_label" media id: 4a518062-2a8f-4f17-81fd-bb1eb2e3cb4f xfsrestore: Restore Status: SUCCESS
session-ID/path/to/destinationxfsrestore -f /dev/st0 -S session-ID /path/to/destination
-f option specifies the location of the dump, while the -S or -L option specifies which specific dump to restore. The -S option is used to specify a session ID, while the -L option is used for session labels. The -I option displays both session labels and IDs for each dump.
xfsrestore allows file system restoration from a specific incremental backup, i.e. level 1 to level 9. To restore a file system from an incremental backup, simply add the -r option, as in:
xfsrestore -f /dev/st0 -S session-ID -r /path/to/destination
xfsrestore utility also allows specific files from a dump to be extracted, added, or deleted. To use xfsrestore interactively, use the -i option, as in:
xfsrestore -f /dev/st0 -i
xfsrestore finishes reading the specified device. Available commands in this dialogue include cd, ls, add, delete, and extract; for a complete list of commands, use help.
man xfsdump and man xfsrestore.
xfs_fsr defragments all regular files in all mounted XFS file systems. This utility also allows users to suspend a defragmentation at a specified time and resume from where it left off later.
xfs_fsr also allows the defragmentation of only one file, as in xfs_fsr /path/to/file. Red Hat advises against periodically defragmenting an entire file system, as this is normally not warranted.
xfs_admin utility can only modify parameters of unmounted devices/file systems.
xfs_metadump utility should only be used to copy unmounted, read-only, or frozen/suspended file systems; otherwise, generated dumps could be corrupted or inconsistent.
xfs_metadump) to a file system image.
man pages.
rpcbind service, supports ACLs, and utilizes stateful operations. Red Hat Enterprise Linux supports NFSv2, NFSv3, and NFSv4 clients. When mounting a file system via NFS, Red Hat Enterprise Linux uses NFSv4 by default, if the server supports it.
rpcbind[2], rpc.lockd, and rpc.statd daemons. The rpc.mountd daemon is still required on the NFS server so set up the exports, but is not involved in any over-the-wire operations.
'-p' command line option that can set the port, making firewall configuration easier.
/etc/exports configuration file to determine whether the client is allowed to access any exported file systems. Once verified, all file and directory operations are available to the user.
rpc.nfsd process now allow binding to any specified port during system start up. However, this can be error-prone if the port is unavailable, or if it conflicts with another daemon.
rpcbind service. To share or mount NFS file systems, the following services work together, depending on which version of NFS is implemented:
portmap service was used to map RPC program numbers to IP address port number combinations in earlier versions of Red Hat Enterprise Linux. This service is now replaced by rpcbind in Red Hat Enterprise Linux 6 to enable IPv6 support. For more information about this change, refer to the following links:
service nfs start starts the NFS server and the appropriate RPC processes to service requests for shared NFS file systems.
service nfslock start activates a mandatory service that starts the appropriate RPC processes which allow NFS clients to lock files on the server.
rpcbind accepts port reservations from local RPC services. These ports are then made available (or advertised) so the corresponding remote RPC services can access them. rpcbind responds to requests for RPC services and sets up connections to the requested RPC service. This is not used with NFSv4.
nfs service and does not require user configuration.
rpc.nfsd allows explicit NFS versions and protocols the server advertises to be defined. It works with the Linux kernel to meet the dynamic demands of NFS clients, such as providing server threads each time an NFS client connects. This process corresponds to the nfs service.
rpc.lockd allows NFS clients to lock files on the server. If rpc.lockd is not started, file locking will fail. rpc.lockd implements the Network Lock Manager (NLM) protocol. This process corresponds to the nfslock service. This is not used with NFSv4.
rpc.statd is started automatically by the nfslock service, and does not require user configuration. This is not used with NFSv4.
rpc.rquotad is started automatically by the nfs service and does not require user configuration.
rpc.idmapd provides NFSv4 client and server upcalls, which map between on-the-wire NFSv4 names (which are strings in the form of user@domainidmapd to function with NFSv4, the /etc/idmapd.conf must be configured. This service is required for use with NFSv4, although not when all hosts share the same DNS domain name.
mount command mounts NFS shares on the client side. Its format is as follows:
mount -t nfs -o options host:/remote/export /local/directory
optionsserver/remote/exportserver, i.e. the directory you wish to mount
/local/directory/remote/export should be mounted
mount options nfsvers or vers. By default, mount will use NFSv4 with mount -t nfs. If the server does not support NFSv4, the client will automatically step down to a version supported by the server. If you use the nfsvers/vers option to pass a particular version not supported by the server, the mount will fail. The file system type nfs4 is also available for legacy reasons; this is equivalent to running mount -t nfs -o nfsvers=4 host:/remote/export /local/directory.
man mount for more details.
/etc/fstab file and the autofs service. Refer to Section 10.2.1, “Mounting NFS File Systems using /etc/fstab” and Section 10.3, “autofs” for more information.
/etc/fstab/etc/fstab file. The line must state the hostname of the NFS server, the directory on the server being exported, and the directory on the local machine where the NFS share is to be mounted. You must be root to modify the /etc/fstab file.
/etc/fstab is as follows:
server:/usr/local/pub /pub nfs rsize=8192,wsize=8192,timeo=14,intr
/pub must exist on the client machine before this command can be executed. After adding this line to /etc/fstab on the client system, use the command mount /pub, and the mount point /pub is mounted from the server.
/etc/fstab file is referenced by the netfs service at boot time, so lines referencing NFS shares have the same effect as manually typing the mount command during the boot process.
/etc/fstab entry to mount an NFS export should contain the following information:
server:/remote/export/local/directorynfsoptions0 0
server, /remote/export, /local/directory, and options are the same ones used when manually mounting an NFS share. Refer to Section 10.2, “NFS Client Configuration” for a definition of each variable.
/local/directory must exist on the client before /etc/fstab is read. Otherwise, the mount will fail.
/etc/fstab, refer to man fstab.
autofs/etc/fstab is that, regardless of how infrequently a user accesses the NFS mounted file system, the system must dedicate resources to keep the mounted file system in place. This is not a problem with one or two mounts, but when the system is maintaining mounts to many systems at one time, overall system performance can be affected. An alternative to /etc/fstab is to use the kernel-based automount utility. An automounter consists of two components:
automount utility can mount and unmount NFS file systems automatically (on-demand mounting), therefore saving system resources. It can be used to mount other file systems including AFS, SMBFS, CIFS, and local file systems.
autofs uses /etc/auto.master (master map) as its default primary configuration file. This can be changed to use another supported network source and name using the autofs configuration (in /etc/sysconfig/autofs) in conjunction with the Name Service Switch (NSS) mechanism. An instance of the autofs version 4 daemon was run for each mount point configured in the master map and so it could be run manually from the command line for any given mount point. This is not possible with autofs version 5, because it uses a single daemon to manage all configured mount points; as such, all automounts must be configured in the master map. This is in line with the usual requirements of other industry standard automounters. Mount point, hostname, exported directory, and options can all be specified in a set of files (or other supported network sources) rather than configuring them manually for each host.
autofs version 5 features the following enhancements over version 4:
autofs provide a mechanism to automatically mount file systems at arbitrary points in the file system hierarchy. A direct map is denoted by a mount point of /- in the master map. Entries in a direct map contain an absolute path name as a key (instead of the relative path names used in indirect maps).
-hosts map, commonly used for automounting all exports from a host under "/net/host" as a multi-mount map entry. When using the "-hosts" map, an 'ls' of "/net/host" will mount autofs trigger mounts for each export from host and mount and expire them as they are accessed. This can greatly reduce the number of active mounts needed when accessing a server with a large number of exports.
autofs version 5 has been enhanced in several ways with respect to autofs version 4. The autofs configuration file (/etc/sysconfig/autofs) provides a mechanism to specify the autofs schema that a site implements, thus precluding the need to determine this via trial and error in the application itself. In addition, authenticated binds to the LDAP server are now supported, using most mechanisms supported by the common LDAP server implementations. A new configuration file has been added for this support: /etc/autofs_ldap_auth.conf. The default configuration file is self-documenting, and uses an XML format.
nsswitch) configuration.man nsswitch.conf for more information on the supported syntax of this file. Please note that not all NSS databases are valid map sources and the parser will reject ones that are invalid. Valid sources are files, yp, nis, nisplus, ldap, and hesiod.
/-. The map keys for each entry are merged and behave as one map.
/- /tmp/auto_dcthon /- /tmp/auto_test3_direct /- /tmp/auto_test4_direct
autofs Configuration/etc/auto.master, also referred to as the master map which may be changed as described in the Section 10.3.1, “Improvements in autofs Version 5 over Version 4”. The master map lists autofs-controlled mount points on the system, and their corresponding configuration files or network sources known as automount maps. The format of the master map is as follows:
mount-point map-name optionsmount-pointautofs mount point e.g /home.
map-nameoptionsautofs version 4 where options where cumulative. This has been changed to implement mixed environment compatibility.
/etc/auto.master file (displayed with cat /etc/auto.master):
/home /etc/auto.misc
mount-point[options]location
mount-pointautofs mount point. This can be a single directory name for an indirect mount or the full path of the mount point for direct mounts. Each direct and indirect map entry key (mount-pointoptionslocation/etc/auto.misc):
payroll -fstype=nfs personnel:/dev/hda3 sales -fstype=ext3 :/dev/hda4
autofs mount point (sales and payroll from the server called personnel). The second column indicates the options for the autofs mount while the third column indicates the source of the mount. Following the above configuration, the autofs mount points will be /home/payroll and /home/sales. The -fstype= option is often omitted and is generally not needed for correct operation.
service autofs start
service autofs restart
autofs unmounted directory such as /home/payroll/2006/July.sxc, the automount daemon automatically mounts the directory. If a timeout is specified, the directory will automatically be unmounted if the directory is not accessed for the timeout period.
service autofs status
/etc/nsswitch.conf file has the following directive:
automount: files nis
auto.master file contains the following
+auto.master
auto.master map file contains the following:
/home auto.home
auto.home map contains the following:
beth fileserver.example.com:/export/home/beth joe fileserver.example.com:/export/home/joe * fileserver.example.com:/export/home/&
/etc/auto.home does not exist.
auto.home and mount home directories from a different server. In this case, the client will need to use the following /etc/auto.master map:
/home /etc/auto.home +auto.master
/etc/auto.home map contains the entry:
* labserver.example.com:/export/home/&
/home will contain the contents of /etc/auto.home instead of the NIS auto.home map.
auto.home map with a few entries, create a /etc/auto.home file map, and in it put your new entries and at the end, include the NIS auto.home map. Then the /etc/auto.home file map might look similar to:
mydir someserver:/export/mydir +auto.home
auto.home map listed above, ls /home would now output:
beth joe mydir
autofs knows not to include the contents of a file map of the same name as the one it is reading. As such, autofs moves on to the next map source in the nsswitch configuration.
openldap package should be installed automatically as a dependency of the automounter. To configure LDAP access, modify /etc/openldap/ldap.conf. Ensure that BASE, URI, and schema are set appropriately for your site.
rfc2307bis. To use this schema it is necessary to set it in the autofs configuration (/etc/sysconfig/autofs) by removing the comment characters from the schema definition. For example:
DEFAULT_MAP_OBJECT_CLASS="automountMap" DEFAULT_ENTRY_OBJECT_CLASS="automount" DEFAULT_MAP_ATTRIBUTE="automountMapName" DEFAULT_ENTRY_ATTRIBUTE="automountKey" DEFAULT_VALUE_ATTRIBUTE="automountInformation"
automountKey replaces the cn attribute in the rfc2307bis schema. An LDIF of a sample configuration is described below:
# extended LDIF # # LDAPv3 # base <> with scope subtree # filter: (&(objectclass=automountMap)(automountMapName=auto.master)) # requesting: ALL # # auto.master, example.com dn: automountMapName=auto.master,dc=example,dc=com objectClass: top objectClass: automountMap automountMapName: auto.master # extended LDIF # # LDAPv3 # base <automountMapName=auto.master,dc=example,dc=com> with scope subtree # filter: (objectclass=automount) # requesting: ALL # # /home, auto.master, example.com dn: automountMapName=auto.master,dc=example,dc=com objectClass: automount cn: /home automountKey: /home automountInformation: auto.home # extended LDIF # # LDAPv3 # base <> with scope subtree # filter: (&(objectclass=automountMap)(automountMapName=auto.home)) # requesting: ALL # # auto.home, example.com dn: automountMapName=auto.home,dc=example,dc=com objectClass: automountMap automountMapName: auto.home # extended LDIF # # LDAPv3 # base <automountMapName=auto.home,dc=example,dc=com> with scope subtree # filter: (objectclass=automount) # requesting: ALL # # foo, auto.home, example.com dn: automountKey=foo,automountMapName=auto.home,dc=example,dc=com objectClass: automount automountKey: foo automountInformation: filer.example.com:/export/foo # /, auto.home, example.com dn: automountKey=/,automountMapName=auto.home,dc=example,dc=com objectClass: automount automountKey: / automountInformation: filer.example.com:/export/&
mount commands, /etc/fstab settings, and autofs.
modemode are all, none, or pos/positive.
versionversion is 2, 3, or 4. This is useful for hosts that run multiple NFS servers. If no version is specified, NFS uses the highest version supported by the kernel and mount command.
vers is identical to nfsvers, and is included in this release for compatibility reasons.
set-user-identifier or set-group-identifier bits. This prevents remote users from gaining higher privileges by running a setuid program.
numport=num — Specifies the numeric value of the NFS server port. If num0 (the default), then mount queries the remote host's rpcbind service for the port number to use. If the remote host's NFS daemon is not registered with its rpcbind service, the standard NFS port number of TCP 2049 is used instead.
num and wsize=numrsize) and writes (wsize) by setting a larger data block size (num, in bytes), to be transferred at one time. Be careful when changing these values; some older Linux kernels and network cards do not work well with larger block sizes. For NFSv2 or NFSv3, the default values for both parameters is set to 8192. For NFSv4, the default values for both parameters is set to 32768.
modesec=sys, which uses local UNIX UIDs and GIDs by using AUTH_SYS to authenticate NFS operations.
sec=krb5 uses Kerberos V5 instead of local UNIX UIDs and GIDs to authenticate users.
sec=krb5i uses Kerberos V5 for user authentication and performs integrity checking of NFS operations using secure checksums to prevent data tampering.
sec=krb5p uses Kerberos V5 for user authentication, integrity checking, and encrypts NFS traffic to prevent traffic sniffing. This is the most secure setting, but it also involves the most performance overhead.
man mount and man nfs. For more information on using NFS via TCP or UDP protocols, refer to Section 10.9, “Using NFS over TCP”.
rpcbind[2] service must be running. To verify that rpcbind is active, use the following command:
service rpcbind status
service command to start, stop, or restart a daemon requires root privileges.
rpcbind service is running, then the nfs service can be started. To start an NFS server, use the following command as root:
service nfs start
nfslock must also be started for both the NFS client and server to function properly. To start NFS locking, use the following command:
service nfslock start
nfslock also starts by running chkconfig --list nfslock. If nfslock is not set to on, this implies that you will need to manually run the service nfslock start each time the computer starts. To set nfslock to automatically start on boot, use chkconfig nfslock on.
nfslock is only needed for NFSv2 and NFSv3.
service nfs stop
restart option is a shorthand way of stopping and then starting NFS. This is the most efficient way to make configuration changes take effect after editing the configuration file for NFS. To restart the server, as root, type:
service nfs restart
condrestart (conditional restart) option only starts nfs if it is currently running. This option is useful for scripts, because it does not start the daemon if it is not running. To conditionally restart the server, as root, type:
service nfs condrestart
service nfs reload
/etc/exports
exportfs
/etc/exports Configuration File/etc/exports file controls which file systems are exported to remote hosts and specifies options. It follows the following syntax rules:
#).
\).
exporthost(options)
exporthostoptionshost
exporthost1(options1)host2(options2)host3(options3)
/etc/exports file only specifies the exported directory and the hosts permitted to access it, as in the following example:
/exported/directory bob.example.com
bob.example.com can mount /exported/directory/ from the NFS server. Because no options are specified in this example, NFS will use default settings, which are:
rw option.
async.
no_wdelay; note that no_wdelay is only available if the default sync option is also specified.
nfsnobody. This effectively "squashes" the power of the remote root user to the lowest local user, preventing possible unauthorized writes on the remote server. To disable root squashing, specify no_root_squash.
all_squash. To specify the user and group IDs that the NFS server should assign to remote users from a particular host, use the anonuid and anongid options, respectively, as in:
exporthost(anonuid=uid,anongid=gid)
uid and gid are user ID number and group ID number, respectively. The anonuid and anongid options allow you to create a special user/group account for remote NFS users to share.
no_acl option when exporting the file system.
rw option is not specified, then the exported file system is shared as read-only. The following is a sample line from /etc/exports which overrides two default options:
/another/exported/directory 192.168.0.3(rw,async)
192.168.0.3 can mount /another/exported/directory/ read/write and all writes to disk are asynchronous. For more information on exporting options, refer to man exportfs.
man exports for details on these less-used options.
/etc/exports file is very precise, particularly in regards to use of the space character. Remember to always separate exported file systems from hosts and hosts from one another with a space character. However, there should be no other space characters in the file except on comment lines.
/home bob.example.com(rw) /home bob.example.com (rw)
bob.example.com read/write access to the /home directory. The second line allows users from bob.example.com to mount the directory as read-only (the default), while the rest of the world can mount it read/write.
exportfs Command/etc/exports file. When the nfs service starts, the /usr/sbin/exportfs command launches and reads this file, passes control to rpc.mountd (if NFSv2 or NFSv3) for the actual mounting process, then to rpc.nfsd where the file systems are then available to remote users.
/usr/sbin/exportfs command allows the root user to selectively export or unexport directories without restarting the NFS service. When given the proper options, the /usr/sbin/exportfs command writes the exported file systems to /var/lib/nfs/xtab. Since rpc.mountd refers to the xtab file when deciding access privileges to a file system, changes to the list of exported file systems take effect immediately.
/usr/sbin/exportfs:
/etc/exports to be exported by constructing a new export list in /etc/lib/nfs/xtab. This option effectively refreshes the export list with any changes made to /etc/exports.
/usr/sbin/exportfs. If no other options are specified, /usr/sbin/exportfs exports all file systems specified in /etc/exports.
file-systems/etc/exports. Replace file-systems with additional file systems to be exported. These file systems must be formatted in the same way they are specified in /etc/exports. Refer to Section 10.6.1, “
The /etc/exports Configuration File” for more information on /etc/exports syntax. This option is often used to test an exported file system before adding it permanently to the list of file systems to be exported.
/etc/exports; only options given from the command line are used to define exported file systems.
/usr/sbin/exportfs -ua suspends NFS file sharing while keeping all NFS daemons up. To re-enable NFS sharing, use exportfs -r.
exportfs command is executed.
exportfs command, it displays a list of currently exported file systems. For more information about the exportfs command, refer to man exportfs.
exportfs with NFSv4exportfs command is used to maintain the NFS table of exported file systems. When used with no arguments, exportfs shows all the exported directories.
MOUNT protocol, which was used with the NFSv2 and NFSv3 protocols, the mounting of file systems has changed.
fsid=0 option.
rpcbind, which dynamically assigns ports for RPC services and can cause problems for configuring firewall rules. To allow clients to access NFS shares behind a firewall, edit the /etc/sysconfig/nfs configuration file to control which ports the required RPC services run on.
/etc/sysconfig/nfs may not exist by default on all systems. If it does not exist, create it and add the following variables, replacing port with an unused port number (alternatively, if the file exists, un-comment and change the default entries as required):
MOUNTD_PORT=portmountd (rpc.mountd) uses.
STATD_PORT=portrpc.statd) uses.
LOCKD_TCPPORT=portnlockmgr (rpc.lockd) uses.
LOCKD_UDPPORT=portnlockmgr (rpc.lockd) uses.
/var/log/messages. Normally, NFS will fail to start if you specify a port number that is already in use. After editing /etc/sysconfig/nfs, restart the NFS service using service nfs restart. Run the rpcinfo -p command to confirm the changes.
rpcbind/sunrpc).
MOUNTD_PORT="port"
STATD_PORT="port"
LOCKD_TCPPORT="port"
LOCKD_UDPPORT="port"
* or ? character to specify a string match. Wildcards are not to be used with IP addresses; however, they may accidentally work if reverse DNS lookups fail. When specifying wildcards in fully qualified domain names, dots (.) are not included in the wildcard. For example, *.example.com includes one.example.com but does not include one.two.example.com.
a.b.c.d/z, where a.b.c.d is the network and z is the number of bits in the netmask (for example 192.168.0.0/24). Another acceptable format is a.b.c.d/netmask, where a.b.c.d is the network and netmask is the netmask (for example, 192.168.100.8/255.255.255.0).
group-name, where group-name is the NIS netgroup name.
rpcbind[2] service via TCP wrappers. Creating rules with iptables can also limit access to ports used by rpcbind, rpc.mountd, and rpc.nfsd.
rpcbind, refer to man iptables.
RPCSEC_GSS kernel module, the Kerberos version 5 GSS-API mechanism, SPKM-3, and LIPKEY. With NFSv4, the mandatory security mechanisms are oriented towards authenticating individual users, and not client machines as used in NFSv2 and NFSv3. As such, for security reasons, Red Hat recommends the use of NFSv4 over other versions whenever possible.
MOUNT protocol for mounting file systems. This protocol presented possible security holes because of the way that it processed file handles.
RPCSEC_GSS framework, including how rpc.svcgssd and rpc.gssd inter-operate, refer to http://www.citi.umich.edu/projects/nfsv4/gssd/.
su - command to access any files via the NFS share.
nobody. Root squashing is controlled by the default option root_squash; for more information about this option, refer to Section 10.6.1, “
The /etc/exports Configuration File”. If possible, never disable root squashing.
all_squash option. This option makes every user accessing the exported file system take the user ID of the nfsnobody user.
rpcbindrpcbind service for backward compatibility.
rpcbind[2] utility maps RPC services to the ports on which they listen. RPC processes notify rpcbind when they start, registering the ports they are listening on and the RPC program numbers they expect to serve. The client system then contacts rpcbind on the server with a particular RPC program number. The rpcbind service redirects the client to the proper port number so it can communicate with the requested service.
rpcbind to make all connections with incoming client requests, rpcbind must be available before any of these services start.
rpcbind service uses TCP wrappers for access control, and access control rules for rpcbind affect all RPC-based services. Alternatively, it is possible to specify access control rules for each of the NFS RPC daemons. The man pages for rpc.mountd and rpc.statd contain information regarding the precise syntax for these rules.
rpcbindrpcbind[2] provides coordination between RPC services and the port numbers used to communicate with them, it is useful to view the status of current RPC services using rpcbind when troubleshooting. The rpcinfo command shows each RPC-based service with port numbers, an RPC program number, a version number, and an IP protocol type (TCP or UDP).
rpcbind, issue the following command as root:
rpcinfo -p
program vers proto port 100021 1 udp 32774 nlockmgr 100021 3 udp 32774 nlockmgr 100021 4 udp 32774 nlockmgr 100021 1 tcp 34437 nlockmgr 100021 3 tcp 34437 nlockmgr 100021 4 tcp 34437 nlockmgr 100011 1 udp 819 rquotad 100011 2 udp 819 rquotad 100011 1 tcp 822 rquotad 100011 2 tcp 822 rquotad 100003 2 udp 2049 nfs 100003 3 udp 2049 nfs 100003 2 tcp 2049 nfs 100003 3 tcp 2049 nfs 100005 1 udp 836 mountd 100005 1 tcp 839 mountd 100005 2 udp 836 mountd 100005 2 tcp 839 mountd 100005 3 udp 836 mountd 100005 3 tcp 839 mountd
rpcbind will be unable to map RPC requests from clients for that service to the correct port. In many cases, if NFS is not present in rpcinfo output, restarting NFS causes the service to correctly register with rpcbind and begin working. For instructions on starting NFS, refer to Section 10.5, “Starting and Stopping NFS”.
rpcinfo, refer to its man page.
mount option -o udp when mounting the NFS-exported file system on the client system. Note that NFSv4 on UDP is not standards-compliant, since UDP does not feature congestion control; as such, NFSv4 on UDP is not supported.
/etc/fstab file (client side)
autofs configuration files, such as /etc/auto.master and /etc/auto.misc (server side with NIS)
mount -o udp shadowman.example.com:/misc/export /misc/local
/etc/fstab (client side):
server:/usr/local/pub /pub nfs rsize=8192,wsize=8192,timeo=14,intr,udp
autofs configuration file for a NIS server, available for NIS enabled workstations:
myproject -rw,soft,intr,rsize=8192,wsize=8192,udp penguin.example.net:/proj52
-o udp option is not specified, the NFS-exported file system is accessed via TCP.
/usr/share/doc/nfs-utils-version/ — This directory contains a wealth of information about the NFS implementation for Linux, including a look at various NFS configurations and their impact on file transfer performance.
man mount — Contains a comprehensive look at mount options for both NFS server and client configurations.
man fstab — Gives details for the format of the /etc/fstab file used to mount file systems at boot-time.
man nfs — Provides details on NFS-specific file system export and mount options.
man exports — Shows common options used in the /etc/exports file when exporting NFS file systems.
[2]
The rpcbind service replaces portmap, which was used in previous versions of Red Hat Enterprise Linux to map RPC program numbers to IP address port number combinations. For more information, refer to Section 10.1.1, “Required Services”.
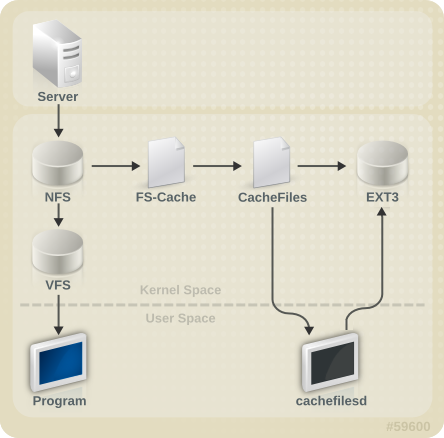
cachefs on Solaris, FS-Cache allows a file system on a server to interact directly with a client's local cache without creating an overmounted file system. With NFS, a mount option instructs the client to mount the NFS share with FS-cache enabled.
cachefiles). In this case, FS-Cache requires a mounted block-based file system that can supports bmap and extended attributes (e.g. ext3) as its cache back-end.
cachefiles caching back-end. The cachefilesd daemon initiates and manages cachefiles. The /etc/cachefilesd.conf file controls how cachefiles provides caching services. To configure a cache back-end of this type, the cachefilesd package must be installed.
dir /path/to/cache
/etc/cachefilesd.conf as /var/cache/fscache, as in:
dir /var/cache/fscache
/path/to/cache/) as the host file system, but for a desktop machine it would be more prudent to mount a disk partition specifically for the cache.
devicetune2fs -o user_xattr /dev/device
mount /dev/device /path/to/cache -o user_xattr
cachefilesd daemon:
service cachefilesd start
cachefilesd to start at boot time, execute the following command as root:
chkconfig cachefilesd on
-o fsc option to the mount command, as in:
mount nfs-share:/ /mount/point -o fsc
/mount/pointmount commands:
mount home0:/disk0/fred /home/fred -o fsc
mount home0:/disk0/jim /home/jim -o fsc
/home/fred and /home/jim will likely share the superblock as they have the same options, especially if they come from the same volume/partition on the NFS server (home0). Now, consider the next two subsequent mount commands:
mount home0:/disk0/fred /home/fred -o fsc,rsize=230
mount home0:/disk0/jim /home/jim -o fsc,rsize=231
/home/fred and /home/jim will not share the superblock as they have different network access parameters, which are part of the Level 2 key. The same goes for the following mount sequence:
mount home0:/disk0/fred /home/fred1 -o fsc,rsize=230
mount home0:/disk0/fred /home/fred2 -o fsc,rsize=231
/home/fred1 and /home/fred2) will be cached twice.
nosharecache parameter. Using the same example:
mount home0:/disk0/fred /home/fred -o nosharecache,fsc
mount home0:/disk0/jim /home/jim -o nosharecache,fsc
home0:/disk0/fred and home0:/disk0/jim. To address this, add a unique identifier on at least one of the mounts, i.e. fsc=unique-identifier. For example:
mount home0:/disk0/fred /home/fred -o nosharecache,fsc
mount home0:/disk0/jim /home/jim -o nosharecache,fsc=jim
jim will be added to the Level 2 key used in the cache for /home/jim.
cachefilesd daemon works by caching remote data from shared file systems to free space on the disk. This could potentially consume all available free space, which could be bad if the disk also housed the root partition. To control this, cachefilesd tries to maintain a certain amount of free space by discarding old objects (i.e. accessed less recently) from the cache. This behavior is known as cache culling.
/etc/cachefilesd.conf:
N%N% of total disk capacity, cachefilesd disables culling.
N%N% of total disk capacity, cachefilesd starts culling.
N%N%, cachefilesd will no longer allocate disk space until until culling raises the amount of free space above N%.
bcull or bstop. To address this, cachefilesd also tries to keep the number of files below a file system's limit. This behavior is controlled by the following settings:
N%N% of its maximum file limit, cachefilesd disables culling. For example, with frun 5%, cachefilesd will disable culling on an ext3 file system if it can accommodate more than 1,600 files, or if the number of files falls below 95% of its limit, i.e. 30,400 files.
N%N% of its maximum file limit, cachefilesd starts culling. For example, with fcull 5%, cachefilesd will start culling on an ext3 file system if it can only accommodate 1,600 more files, or if the number of files exceeds 95% of its limit, i.e. 30,400 files.
N%N% of its maximum file limit, cachefilesd will no longer allocate disk space until culling drops the number of files to below N% of the limit. For example, with fstop 5%, cachefilesd will no longer accommodate disk space until culling drops the number of files below 95% of its limit, i.e. 30,400 files.
N for each setting is as follows:
brun/frun — 10%
bcull/fcull — 7%
bstop/fstop — 3%
bstop < bcull < brun < 100
fstop < fcull < frun < 100
cat /proc/fs/fscache/stats
/usr/share/doc/kernel-doc-version/Documentation/filesystems/caching/fscache.txt
cachefilesd and how to configure it, refer to man cachefilesd and man cachefilesd.conf. The following kernel documents also provide additional information:
/usr/share/doc/cachefilesd-0.5/README
/usr/share/man/man5/cachefilesd.conf.5.gz
/usr/share/man/man8/cachefilesd.8.gz
/usr/share/doc/kernel-doc-version/Documentation/filesystems/caching/fscache.txt
mkfs. Instead, eCryptfs is initiated by issuing a special mount command. To manage file systems protected by eCryptfs, the ecryptfs-utils package must be installed first.
mount -t ecryptfs /source /destination
/source/destination/destination/source/source/source/destinationmount -t ecryptfs /home /home
/home pass through the eCryptfs layer.
mount will allow the following settings to be configured:
openssl, tspi, or passphrase. When choosing passphrase, mount will ask for one.
aes, blowfish, des3_ede, cast6, or cast5.
16, 32, 24
plaintext passthrough is enabled
filename encryption is enabled
mount will display all the selections made and perform the mount. This output consists of the command-line option equivalents of each chosen setting. For example, mounting /home with a key type of passphrase, aes cipher, key bytesize of 16 with both plaintext passthrough and filename encryption disabled, the output would be:
Attempting to mount with the following options: ecryptfs_unlink_sigs ecryptfs_key_bytes=16 ecryptfs_cipher=aes ecryptfs_sig=c7fed37c0a341e19 Mounted eCryptfs
-o option of mount. For example:
mount -t ecryptfs /home /home -o ecryptfs_unlink_sigs \ ecryptfs_key_bytes=16 ecryptfs_cipher=aes ecryptfs_sig=c7fed37c0a341e19[3]
man ecryptfs (provided by the ecryptfs-utils package). The following Kernel document (provided by the kernel-doc package) also provides additional information on eCryptfs:
/usr/share/doc/kernel-doc-version/Documentation/filesystems/ecryptfs.txt
[3] This is a single command split into multiple lines, to accommodate printed and PDF versions of this document. All concatenated lines — preceded by the backslash (\) — should be treated as one command, sans backslashes.
mdadm tool. For details on the options and their respective performance trade-offs, refer to man md.
mdraid subsystem was designed as a software RAID solution for Linux; it is also the preferred solution for software RAID under Linux. This subsystem uses its own metadata format, generally refered to as native mdraid metadata.
mdraid also supports other metadata formats, known as external metadata. Red Hat Enterprise Linux 6 uses mdraid with external metadata to access ISW / IMSM (Intel firmware RAID) sets. mdraid sets are configured and controlled through the mdadm utility.
dmraid refers to device-mapper kernel code that offers the mechanism to piece disks together into a RAID set. This same kernel code does not provide any RAID configuration mechanism.
dmraid is configured entirely in user-space, making it easy to support various on-disk metadata formats. As such, dmraid is used on a wide variety of firmware RAID implementations. dmraid also supports Intel firmware RAID, although Red Hat Enterprise Linux 6 uses mdraid to access Intel firmware RAID sets.
mdraid, and can recognize existing mdraid sets.
initrd which RAID set(s) to activate before searching for the root file system.
mdadm command-line tool is used to manage software RAID in Linux, i.e. mdraid. For information on the different mdadm modes and options, refer to man mdadm. The man page also contains useful examples for common operations like creating, monitoring, and assembling software RAID arrays.
dmraid is used to manage device-mapper RAID sets. The dmraid tool finds ATARAID devices using multiple metadata format handlers, each supporting various formats. For a complete list of supported formats, run dmraid -l.
dmraid tool cannot configure RAID sets after creation. For more information about using dmraid, refer to man dmraid.
/boot or root file system arrays on a complex RAID device; in such cases, you may need to use array options that are not supported by Anaconda. To work around this, perform the following procedure:
parted to create RAID partitions on the target hard drives. Then, use mdadm to manually create raid arrays from those partitions using any and all settings and options available. For more information on how to do these, refer to Chapter 4, Partitions, man parted, and man mdadm.
man pages. Both the man mdadm and man md contain useful information for creating custom RAID arrays, and may be needed throughout the workaround. As such, it can be helpful to either have access to a machine with these man pages present, or to print them out prior to booting into Rescue Mode and creating your custom arrays.
[4] A hot-swap chassis allows you to remove a hard drive without having to power-down your system.
[5] RAID level 1 comes at a high cost because you write the same information to all of the disks in the array, provides data reliability, but in a much less space-efficient manner than parity based RAID levels such as level 5. However, this space inefficiency comes with a performance benefit: parity-based RAID levels consume considerably more CPU power in order to generate the parity while RAID level 1 simply writes the same data more than once to the multiple RAID members with very little CPU overhead. As such, RAID level 1 can outperform the parity-based RAID levels on machines where software RAID is employed and CPU resources on the machine are consistently taxed with operations other than RAID activities.
[6] Parity information is calculated based on the contents of the rest of the member disks in the array. This information can then be used to reconstruct data when one disk in the array fails. The reconstructed data can then be used to satisfy I/O requests to the failed disk before it is replaced and to repopulate the failed disk after it has been replaced.
If M < 2 S = M *2 Else S = M + 2
free and cat /proc/swaps commands to verify how much and where swap is in use.
/dev/VolGroup00/LogVol01 is the volume you want to extend by 256MB):
swapoff -v /dev/VolGroup00/LogVol01
lvresize /dev/VolGroup00/LogVol01 -L +256M
mkswap /dev/VolGroup00/LogVol01
swapon -v /dev/VolGroup00/LogVol01
cat /proc/swaps or free to inspect the swap space.
/dev/VolGroup00/LogVol02 is the swap volume you want to add):
lvcreate VolGroup00 -n LogVol02 -L 256M
mkswap /dev/VolGroup00/LogVol02
/etc/fstab file:
/dev/VolGroup00/LogVol02 swap swap defaults 0 0
swapon -v /dev/VolGroup00/LogVol02
cat /proc/swaps or free to inspect the swap space.
count being equal to the desired block size:
dd if=/dev/zero of=/swapfile bs=1024 count=65536
mkswap /swapfile
swapon /swapfile
/etc/fstab to include the following entry:
/swapfile swap swap defaults 0 0
cat /proc/swaps or free to inspect the swap space.
/dev/VolGroup00/LogVol01 is the volume you want to reduce):
swapoff -v /dev/VolGroup00/LogVol01
lvreduce /dev/VolGroup00/LogVol01 -L -512M
mkswap /dev/VolGroup00/LogVol01
swapon -v /dev/VolGroup00/LogVol01
cat /proc/swaps or free to inspect the swap space.
/dev/VolGroup00/LogVol02 is the swap volume you want to remove):
swapoff -v /dev/VolGroup00/LogVol02
lvremove /dev/VolGroup00/LogVol02
/etc/fstab file:
/dev/VolGroup00/LogVol02 swap swap defaults 0 0
cat /proc/swaps or free to inspect the swap space.
quota RPM must be installed to implement disk quotas.
/etc/fstab file.
/etc/fstab file. Add the usrquota and/or grpquota options to the file systems that require quotas:
/dev/VolGroup00/LogVol00 / ext3 defaults 1 1 LABEL=/boot /boot ext3 defaults 1 2 none /dev/pts devpts gid=5,mode=620 0 0 none /dev/shm tmpfs defaults 0 0 none /proc proc defaults 0 0 none /sys sysfs defaults 0 0 /dev/VolGroup00/LogVol02 /home ext3 defaults,usrquota,grpquota 1 2 /dev/VolGroup00/LogVol01 swap swap defaults 0 0 . . .
/home file system has both user and group quotas enabled.
/home partition was created during the installation of Red Hat Enterprise Linux. The root (/) partition can be used for setting quota policies in the /etc/fstab file.
usrquota and/or grpquota options, remount each file system whose fstab entry has been modified. If the file system is not in use by any process, use one of the following methods:
umount command followed by the mount command to remount the file system. Refer to the man page for both umount and mount for the specific syntax for mounting and unmounting various file system types.
mount -o remount file-system command (where file-system/home file system, the command to issue is mount -o remount /home.
quotacheck command.
quotacheck command examines quota-enabled file systems and builds a table of the current disk usage per file system. The table is then used to update the operating system's copy of disk usage. In addition, the file system's disk quota files are updated.
aquota.user and aquota.group) on the file system, use the -c option of the quotacheck command. For example, if user and group quotas are enabled for the /home file system, create the files in the /home directory:
quotacheck -cug /home
-c option specifies that the quota files should be created for each file system with quotas enabled, the -u option specifies to check for user quotas, and the -g option specifies to check for group quotas.
-u or -g options are specified, only the user quota file is created. If only -g is specified, only the group quota file is created.
quotacheck -avug
quotacheck has finished running, the quota files corresponding to the enabled quotas (user and/or group) are populated with data for each quota-enabled locally-mounted file system such as /home.
edquota command.
edquota username
/etc/fstab for the /home partition (/dev/VolGroup00/LogVol02 in the example below) and the command edquota testuser is executed, the following is shown in the editor configured as the default for the system:
Disk quotas for user testuser (uid 501): Filesystem blocks soft hard inodes soft hard /dev/VolGroup00/LogVol02 440436 0 0 37418 0 0
EDITOR environment variable is used by edquota. To change the editor, set the EDITOR environment variable in your ~/.bash_profile file to the full path of the editor of your choice.
inodes column shows how many inodes the user is currently using. The last two columns are used to set the soft and hard inode limits for the user on the file system.
Disk quotas for user testuser (uid 501): Filesystem blocks soft hard inodes soft hard /dev/VolGroup00/LogVol02 440436 500000 550000 37418 0 0
quota testuser
devel group (the group must exist prior to setting the group quota), use the command:
edquota -g devel
Disk quotas for group devel (gid 505): Filesystem blocks soft hard inodes soft hard /dev/VolGroup00/LogVol02 440400 0 0 37418 0 0
quota -g devel
edquota -t
edquota commands operate on quotas for a particular user or group, the -t option operates on every file system with quotas enabled.
quotaoff -vaug
-u or -g options are specified, only the user quotas are disabled. If only -g is specified, only group quotas are disabled. The -v switch causes verbose status information to display as the command executes.
quotaon command with the same options.
quotaon -vaug
/home, use the following command:
quotaon -vug /home
-u or -g options are specified, only the user quotas are enabled. If only -g is specified, only group quotas are enabled.
repquota utility. For example, the command repquota /home produces this output:
*** Report for user quotas on device /dev/mapper/VolGroup00-LogVol02 Block grace time: 7days; Inode grace time: 7days Block limits File limits User used soft hard grace used soft hard grace ---------------------------------------------------------------------- root -- 36 0 0 4 0 0 kristin -- 540 0 0 125 0 0 testuser -- 440400 500000 550000 37418 0 0
-a) quota-enabled file systems, use the command:
repquota -a
-- displayed after each user is a quick way to determine whether the block or inode limits have been exceeded. If either soft limit is exceeded, a + appears in place of the corresponding -; the first - represents the block limit, and the second represents the inode limit.
grace columns are normally blank. If a soft limit has been exceeded, the column contains a time specification equal to the amount of time remaining on the grace period. If the grace period has expired, none appears in its place.
quotacheck. However, quotacheck can be run on a regular basis, even if the system has not crashed. Safe methods for periodically running quotacheck include:
/etc/cron.daily/ or /etc/cron.weekly/ directory—or schedule one using the crontab -e command—that contains the touch /forcequotacheck command. This creates an empty forcequotacheck file in the root directory, which the system init script looks for at boot time. If it is found, the init script runs quotacheck. Afterward, the init script removes the /forcequotacheck file; thus, scheduling this file to be created periodically with cron ensures that quotacheck is run during the next reboot.
cron, refer to man cron.
quotacheck is to (re-)boot the system into single-user mode to prevent the possibility of data corruption in quota files and run the following commands:
quotaoff -vaug /file_system
quotacheck -vaug /file_system
quotaon -vaug /file_system
quotacheck on a machine during a time when no users are logged in, and thus have no open files on the file system being checked. Run the command quotacheck -vaug file_system ; this command will fail if quotacheck cannot remount the given file_system as read-only. Note that, following the check, the file system will be remounted read-write.
quotacheck on a live file system mounted read-write is not recommended due to the possibility of quota file corruption.
man cron for more information about configuring cron.
acl package is required to implement ACLs. It contains the utilities used to add, modify, remove, and retrieve ACL information.
cp and mv commands copy or move any ACLs associated with files and directories.
mount -t ext3 -o acl device-name partition
mount -t ext3 -o acl /dev/VolGroup00/LogVol02 /work
/etc/fstab file, the entry for the partition can include the acl option:
LABEL=/work /work ext3 acl 1 2
--with-acl-support option. No special flags are required when accessing or mounting a Samba share.
no_acl option in the /etc/exports file. To disable ACLs on an NFS share when mounting it on a client, mount it with the no_acl option via the command line or the /etc/fstab file.
setfacl utility sets ACLs for files and directories. Use the -m option to add or modify the ACL of a file or directory:
setfacl -m rules files
rules) must be specified in the following formats. Multiple rules can be specified in the same command if they are separated by commas.
u:uid:permsg:gid:permsm:permso:permsperms) must be a combination of the characters r, w, and x for read, write, and execute.
setfacl command is used, the additional rules are added to the existing ACL or the existing rule is modified.
setfacl -m u:andrius:rw /project/somefile
-x option and do not specify any permissions:
setfacl -x rules files
setfacl -x u:500 /project/somefile
d: before the rule and specify a directory instead of a file name.
/share/ directory to read and execute for users not in the user group (an access ACL for an individual file can override it):
setfacl -m d:o:rx /share
getfacl command. In the example below, the getfacl is used to determine the existing ACLs for a file.
getfacl home/john/picture.png
# file: home/john/picture.png # owner: john # group: john user::rw- group::r-- other::r--
getfacl home/sales/ will display similar output:
# file: home/sales/ # owner: john # group: john user::rw- user:barryg:r-- group::r-- mask::r-- other::r-- default:user::rwx default:user:john:rwx default:group::r-x default:mask::rwx default:other::r-x
dump command now preserves ACLs during a backup operation. When archiving a file or file system with tar, use the --acls option to preserve ACLs. Similarly, when using cp to copy files with ACLs, include the --preserve=mode option to ensure that ACLs are copied across too. In addition, the -a option (equivalent to -dR --preserve=all) of cp also preserves ACLs during a backup along with other information such as timestamps, SELinux contexts, and the like. For more information about dump, tar, or cp, refer to their respective man pages.
star utility is similar to the tar utility in that it can be used to generate archives of files; however, some of its options are different. Refer to Table 16.1, “Command Line Options for star” for a listing of more commonly used options. For all available options, refer to man star. The star package is required to use this utility.
star| Option | Description |
|---|---|
-c
| Creates an archive file. |
-n
|
Do not extract the files; use in conjunction with -x to show what extracting the files does.
|
-r
| Replaces files in the archive. The files are written to the end of the archive file, replacing any files with the same path and file name. |
-t
| Displays the contents of the archive file. |
-u
| Updates the archive file. The files are written to the end of the archive if they do not exist in the archive, or if the files are newer than the files of the same name in the archive. This option only works if the archive is a file or an unblocked tape that may backspace. |
-x
|
Extracts the files from the archive. If used with -U and a file in the archive is older than the corresponding file on the file system, the file is not extracted.
|
-help
| Displays the most important options. |
-xhelp
| Displays the least important options. |
-/
| Do not strip leading slashes from file names when extracting the files from an archive. By default, they are stripped when files are extracted. |
-acl
| When creating or extracting, archives or restores any ACLs associated with the files and directories. |
ext_attr attribute. This attribute can be seen using the following command:
tune2fs -l filesystem-device
ext_attr attribute can be mounted with older kernels, but those kernels do not enforce any ACLs which have been set.
e2fsck utility included in version 1.22 and higher of the e2fsprogs package (including the versions in Red Hat Enterprise Linux 2.1 and 4) can check a file system with the ext_attr attribute. Older versions refuse to check it.
fsync() is persistent throughout a power loss.
fsync() heavily or create and delete many small files will likely run much slower.
fsync() call will also issue a storage cache flush. This guarantees that file data is persistent on disk even if power loss occurs shortly after fsync() returns.
-o nobarrier option for mount. However, some devices do not support write barriers; such devices will log an error message to /var/log/messages (refer to Table 17.1, “Write barrier error messages per file system”).
| File System | Error Message |
|---|---|
| ext3/ext4 |
JBD: barrier-based sync failed on
|
| XFS |
Filesystem
|
| btrfs |
btrfs: disabling barriers on dev
|
hdparm command, as in:
hdparm -W0 /device/
MegaCli64 tool to manage target drives. To show the state of all back-end drives for LSI Megaraid SAS, use:
MegaCli64 -LDGetProp -DskCache -LAll -aALL
MegaCli64 -LDSetProp -DisDskCache -Lall -aALL
parted, lvm, mkfs.*, and the like) to optimize data placement and access. If a legacy device does not export I/O alignment and size data, then storage management tools in Red Hat Enterprise Linux 6 will conservatively align I/O on a 4k (or larger power of 2) boundary. This will ensure that 4k-sector devices operate correctly even if they do not indicate any required/preferred I/O alignment and size.
physical_block_size internally but expose a more granular 512-byte logical_block_size to Linux. This discrepancy introduces potential for misaligned I/O. To address this, the Red Hat Enterprise Linux 6 I/O stack will attempt to start all data areas on a naturally-aligned boundary (physical_block_size) by making sure it accounts for any alignment_offset if the beginning of the block device is offset from the underlying physical alignment.
minimum_io_size) and streaming I/O (optimal_io_size) of a device. For example, minimum_io_size and optimal_io_size may correspond to a RAID device's chunk size and stripe size respectively.
logical_block_size boundary, and in multiples of the logical_block_size.
logical_block_size is 4K) it is now critical that applications perform direct I/O in multiples of the device's logical_block_size. This means that applications will fail with native 4k devices that perform 512-byte aligned I/O rather than 4k-aligned I/O.
sysfs and block device ioctl interfaces.
man libblkid. This man page is provided by the libblkid-devel package.
diskdiskpartitiondiskdiskdiskdisksysfs attributes for "legacy" devices that do not provide I/O parameters information, for example:
alignment_offset: 0 physical_block_size: 512 logical_block_size: 512 minimum_io_size: 512 optimal_io_size: 0
IDENTIFY DEVICE command. ATA devices only report I/O parameters for physical_block_size, logical_block_size, and alignment_offset. The additional I/O hints are outside the scope of the ATA Command Set.
BLOCK LIMITS VPD page) and READ CAPACITY(16) command to devices which claim compliance with SPC-3.
READ CAPACITY(16) command provides the block sizes and alignment offset:
LOGICAL BLOCK LENGTH IN BYTES is used to derive /sys/block/disk/queue/physical_block_size
LOGICAL BLOCKS PER PHYSICAL BLOCK EXPONENT is used to derive /sys/block/disk/queue/logical_block_size
LOWEST ALIGNED LOGICAL BLOCK ADDRESS is used to derive:
/sys/block/disk/alignment_offset
/sys/block/disk/partition/alignment_offset
BLOCK LIMITS VPD page (0xb0) provides the I/O hints. It also uses OPTIMAL TRANSFER LENGTH GRANULARITY and OPTIMAL TRANSFER LENGTH to derive:
/sys/block/disk/queue/minimum_io_size
/sys/block/disk/queue/optimal_io_size
sg3_utils package provides the sg_inq utility, which can be used to access the BLOCK LIMITS VPD page. To do so, run:
sg_inq -p 0xb0 disk
alignment_offset; once a layer adjusts accordingly, it will export a device with an alignment_offset of zero.
minimum_io_size and optimal_io_size relative to the stripe count (number of disks) and user-provided chunk size.
logical_block_size of 4K. File systems layered on such a hybrid device assume that 4K will be written atomically, but in reality it will span 8 logical block addresses when issued to the 512-byte device. Using a 4K logical_block_size for the higher-level DM device increases potential for a partial write to the 512-byte device if there is a system crash.
alignment_offset associated with any device managed by LVM. This means logical volumes will be properly aligned (alignment_offset=0).
alignment_offset, but this behavior can be disabled by setting data_alignment_offset_detection to 0 in /etc/lvm/lvm.conf. Disabling this is not recommended.
minimum_io_size or optimal_io_size exposed in sysfs. LVM will use the minimum_io_size if optimal_io_size is undefined (i.e. 0).
data_alignment_detection to 0 in /etc/lvm/lvm.conf. Disabling this is not recommended.
libblkid library provided with the util-linux-ng package includes a programmatic API to access a device's I/O parameters. libblkid allows applications, especially those that use Direct I/O, to properly size their I/O requests. The fdisk utility from util-linux-ng uses libblkid to determine the I/O parameters of a device for optimal placement of all partitions. The fdisk utility will align all partitions on a 1MB boundary.
libparted library from parted also uses the I/O parameters API of libblkid. The Red Hat Enterprise Linux 6 installer (Anaconda) uses libparted, which means that all partitions created by either the installer or parted will be properly aligned. For all partitions created on a device that does not appear to provide I/O parameters, the default alignment will be 1MB.
parted uses are as follows:
alignment_offset as the offset for the start of the first primary partition.
optimal_io_size is defined (i.e. not 0), align all partitions on an optimal_io_size boundary.
optimal_io_size is undefined (i.e. 0), alignment_offset is 0, and minimum_io_size is a power of 2, use a 1MB default alignment.
alignment_offset=0 and optimal_io_size=0. Such a device might be a single SAS 4K device; as such, at worst 1MB of space is lost at the start of the disk.
mkfs.filesystem utilities have also been enhanced to consume a device's I/O parameters. These utilities will not allow a file system to be formatted to use a block size smaller than the logical_block_size of the underlying storage device.
mkfs.gfs2, all other mkfs.filesystem utilities also use the I/O hints to layout on-disk data structure and data areas relative to the minimum_io_size and optimal_io_size of the underlying storage device. This allows file systems to be optimally formatted for various RAID (striped) layouts.
system-config-netboot) is no longer available in Red Hat Enterprise Linux 6. Deploying diskless systems is now possible in this release without the use of system-config-netboot.
tftp-server
xinetd
dhcp
syslinux
dracut-network
tftp service (provided by tftp-server) and a DHCP service (provided by dhcp). The tftp service is used to retrieve kernel image and initrd over the network via the PXE loader. Both tftp and DHCP services must be provided by the same host machine.
tftp service is disabled by default. To enable it and allow PXE booting via the network, set the Disabled option in /etc/xinetd.d/tftp to no. To configure tftp, perform the following steps:
tftp root directory (chroot) is located in /var/lib/tftpboot. Copy /usr/share/syslinux/pxelinux.0 to /var/lib/tftpboot/, as in:
cp /usr/share/syslinux/pxelinux.0 /var/lib/tftpboot/
pxelinux.cfg directory inside the tftp root directory:
mkdir -p /var/lib/tftpboot/pxelinux.cfg/
tftp traffic; as tftp supports TCP wrappers, you can configure host access to tftp via /etc/hosts.allow. For more information on configuring TCP wrappers and the /etc/hosts.allow configuration file, refer to the Red Hat Enterprise Linux 6 Security Guide; man hosts_access also provides information about /etc/hosts.allow.
tftp for diskless clients, configure DHCP, NFS, and the exported file system accordingly. Refer to Section 19.2, “Configuring DHCP for Diskless Clients” and Section 19.3, “Configuring an Exported File System for Diskless Clients” for instructions on how to do so.
tftp server, you need to set up a DHCP service on the same host machine. Refer to the Red Hat Enterprise Linux 6 Deployment Guide for instructions on how to set up a DHCP server. In addition, you should enable PXE booting on the DHCP server; to do this, add the following configuration to /etc/dhcp/dhcp.conf:
allow booting;
allow bootp;
class "pxeclients" {
match if substring(option vendor-class-identifier, 0, 9) = "PXEClient";
next-server server-ip;
filename "linux-install/pxelinux.0";
}server-iptftp and DHCP services reside. Now that tftp and DHCP are configured, all that remains is to configure NFS and the exported file system; refer to Section 19.3, “Configuring an Exported File System for Diskless Clients” for instructions.
/etc/exports. For instructions on how to do so, refer to Section 10.6.1, “
The /etc/exports Configuration File”.
rsync, as in:
rsync -a -e ssh --exclude='/proc/*' --exclude='/sys/*' hostname.com:/ /exported/root/directory
hostname.comrsync. The /exported/root/directoryyum with the --installroot option to install Red Hat Enterprise Linux to a specific location. For example:
/exported/root/directory
/etc/fstab to contain (at least) the following configuration:
none /tmp tmpfs defaults 0 0 tmpfs /dev/shm tmpfs defaults 0 0 sysfs /sys sysfs defaults 0 0 proc /proc proc defaults 0 0
vmlinuz-kernel-version) and copy it to the tftp boot directory:
cp /boot/vmlinuz-kernel-version /var/lib/tftpboot/
initrd (i.e. initramfs-kernel-version.img) with network support:
dracut initramfs-kernel-version.img vmlinuz-kernel-version
initramfs-kernel-version.img into the tftp boot directory as well.
initrd and kernel inside /var/lib/tftpboot. This configuration should instruct the diskless client's root to mount the exported file system (/exported/root/directory/var/lib/tftpboot/pxelinux.cfg/default with the following:
default rhel6 label rhel6 kernel vmlinuz-kernel-versionappend initrd=initramfs-kernel-version.img root=nfs:server-ip:/exported/root/directoryrw
server-iptftp and DHCP services reside.
TRIM. This command allows the file system to communicate to the underlying storage device that a given range of blocks is no longer in use. The SSD can use this information to free up space internally, using the freed blocks for wear-leveling.
TRIM support is most useful when there is available free space on the file system, but the file system has already written to most logical blocks on the underlying storage device. For more information about TRIM, refer to its Data Set Management T13 Specifications from the following link:
TRIM.
md targets do not support TRIM. As such, the default Red Hat Enterprise Linux 6 installation will not allow the use of the TRIM command, since this install uses DM-linear targets.
mdadm) write to all of the blocks on the storage device to ensure that checksums operate properly. This will cause the performance of the SSD to degrade quickly.
TRIM. To enable TRIM commands on a device, use the mount option discard. For example, to mount /dev/sda2 to /mnt with TRIM enabled, run:
mount -t ext4 -o discard /dev/sda2 /mnt
TRIM command. This is mostly to avoid problems on devices which may not properly implement the TRIM command. The Linux swap code will issue TRIM commands to TRIM-enabled devices, and there is no option to control this behaviour.
/usr/share/doc/kernel-version/Documentation/block/switching-sched.txt
vm_dirty_background_ratio and vm_dirty_ratio settings, as increased write-out activity should not negatively impact the latency of other operations on the disk. However, this can generate more overall I/O and so is not generally recommended without workload-specific testing.
sysfs objects. Red Hat advises that the sysfs object names and directory structure are subject to change in major Red Hat Enterprise Linux releases. This is because the upstream Linux kernel does not provide a stable internal API. For guidelines on how to reference sysfs objects in a transportable way, refer to the document /usr/share/doc/kernel-doc-version/Documentation/sysfs-rules.txt in the kernel source tree for guidelines.
/sys/class/ directories that contain files used to provide the userspace API. In each item, host numbers are designated by HBTLR/sys/class/fc_transport/targetH:B:T/port_id — 24-bit port ID/address
node_name — 64-bit node name
port_name — 64-bit port name
/sys/class/fc_remote_ports/rport-H:B-R/port_id
node_name
port_name
dev_loss_tmo — number of seconds to wait before marking a link as "bad". Once a link is marked bad, I/O running on its corresponding path (along with any new I/O on that path) will be failed.
dev_loss_tmo value varies, depending on which driver/device is used. If a Qlogic adapter is used, the default is 35 seconds, while if an Emulex adapter is used, it is 30 seconds. The dev_loss_tmo value can be changed via the scsi_transport_fc module parameter dev_loss_tmo, although the driver can override this timeout value.
dev_loss_tmo value is 600 seconds. If dev_loss_tmo is set to zero or any value greater than 600, the driver's internal timeouts will be used instead.
fast_io_fail_tmo — length of time to wait before failing I/O executed when a link problem is detected. I/O that reaches the driver will fail. If I/O is in a blocked queue, it will not be failed until dev_loss_tmo expires and the queue is unblocked.
/sys/class/fc_host/hostH/lpfc
qla2xxx
zfcp
mptfc
lpfc
|
qla2xxx
|
zfcp
|
mptfc
| |
|---|---|---|---|---|
Transport port_id
| X | X | X | X |
Transport node_name
| X | X | X | X |
Transport port_name
| X | X | X | X |
Remote Port dev_loss_tmo
| X | X | X | X |
Remote Port fast_io_fail_tmo
| X | X [a] | X [b] | |
Host port_id
| X | X | X | X |
Host issue_lip
| X | X | ||
[a] Supported as of Red Hat Enterprise Linux 5.4 [b] Supported as of Red Hat Enterprise Linux 6.0 | ||||
iscsiadm utility. Before using the iscsiadm utility, install the iscsi-initiator-utils package first; to do so, run yum install iscsi-initiator-utils.
service iscsi start
iscsiadm -m session -P 3
iscsiadm -m session -P 0
iscsiadm -m session
driver[sid]target_ip:port,target_portal_group_tag proper_target_name
iscsiadm -m session
tcp [2] 10.15.84.19:3260,2 iqn.1992-08.com.netapp:sn.33615311 tcp [3] 10.15.85.19:3260,3 iqn.1992-08.com.netapp:sn.33615311
/usr/share/doc/iscsi-initiator-utils-version/README.
/dev/sd name; another is the major:minor number. A third is a symlink maintained in the /dev/disk/by-path/ directory. This symlink maps from the path identifier to the current /dev/sd name. For example, for a Fibre Channel device, the PCI info and Host:BusTarget:LUNpci-0000:02:0e.0-scsi-0:0:0:0 -> ../../sda
by-path/ names map from the target name and portal information to the sd name.
0x83) or Unit Serial Number (page 0x80). The mappings from these WWIDs to the current /dev/sd names can be seen in the symlinks maintained in the /dev/disk/by-id/ directory.
0x83 identifier would have:
scsi-3600508b400105e210000900000490000 -> ../../sda
0x80 identifier would have:
scsi-SSEAGATE_ST373453LW_3HW1RHM6 -> ../../sda
/dev/sd name on that system. Applications can use the /dev/disk/by-id/ name to reference the data on the disk, even if the path to the device changes, and even when accessing the device from different systems.
/dev/mapper/wwid, such as /dev/mapper/3600508b400105df70000e00000ac0000.
multipath -l shows the mapping to the non-persistent identifiers: Host:Channel:Target:LUN/dev/sd name, and the major:minor number.
3600508b400105df70000e00000ac0000 dm-2 vendor,product [size=20G][features=1 queue_if_no_path][hwhandler=0][rw] \_ round-robin 0 [prio=0][active] \_ 5:0:1:1 sdc 8:32 [active][undef] \_ 6:0:1:1 sdg 8:96 [active][undef] \_ round-robin 0 [prio=0][enabled] \_ 5:0:0:1 sdb 8:16 [active][undef] \_ 6:0:0:1 sdf 8:80 [active][undef]
/dev/sd name on the system. These names are persistent across path changes, and they are consistent when accessing the device from different systems.
user_friendly_names feature (of device-mapper-multipath) is used, the WWID is mapped to a name of the form /dev/mapper/mpathn. By default, this mapping is maintained in the file /var/lib/multipath/bindings. These mpathn names are persistent as long as that file is maintained.
/var/lib/multipath/bindings) must be available at boot time. If /var is a separate file system from /, then you must change the default location of the file. For more information, refer to http://kbase.redhat.com/faq/docs/DOC-17650.
user_friendly_names, then additional steps are required to obtain consistent names in a cluster. Refer to the Consistent Multipath Device Names section in the Using Device-Mapper Multipath book.
udev rules to implement persistent names of your own, mapped to the WWID of the storage. For more information about this, refer to http://kbase.redhat.com/faq/docs/DOC-7319.
/dev/disk/by-label/ (e.g. boot -> ../../sda1 ) and /dev/disk/by-uuid/ (e.g. f8bf09e3-4c16-4d91-bd5e-6f62da165c08 -> ../../sda1) directories.
md and LVM write metadata on the storage device, and read that data when they scan devices. In each case, the metadata contains a UUID, so that the device can be identified regardless of the path (or system) used to access it. As a result, the device names presented by these facilities are persistent, as long as the metadata remains unchanged.
vmstat 1 100; device removal is not recommended if:
free can also be used to display the total memory).
si and so columns in the vmstat output).
umount to unmount any file systems that mounted the device.
md and LVM volume using it. If the device is a member of an LVM Volume group, then it may be necessary to move data off the device using the pvmove command, then use the vgreduce command to remove the physical volume, and (optionally) pvremove to remove the LVM metadata from the disk.
multipath -l and note all the paths to the device. Afterwards, remove the multipathed device using multipath -f device.
blockdev –flushbufs device to flush any outstanding I/O to all paths to the device. This is particularly important for raw devices, where there is no umount or vgreduce operation to cause an I/O flush.
/dev/sd, /dev/disk/by-path or the major:minor number, in applications, scripts, or utilities on the system. This is important in ensuring that different devices added in the future will not be mistaken for the current device.
echo 1 > /sys/block/device-name/device/delete where device-namesde, for example.
echo 1 > /sys/class/scsi_device/h:c:t:l/device/delete, where hctlecho "scsi remove-single-device 0 0 0 0" > /proc/scsi/scsi, is deprecated.
device-namelsscsi, scsi_id, multipath -l, and ls -l /dev/disk/by-*.
/dev/sd or /dev/disk/by-path or the major:minor number, in applications, scripts, or utilities on the system. This is important in ensuring that different devices added in the future will not be mistaken for the current device.
echo offline > /sys/block/sda/device/state.
echo 1 > /sys/block/device-name/device/delete where device-namesde, for example (as described in Procedure 21.1, “Ensuring a Clean Device Removal”).
/dev/sd name, major:minor number, and /dev/disk/by-path name, for example) the system assigns to the new device may have been previously in use by a device that has since been removed. As such, ensure that all old references to the path-based device name have been removed. Otherwise, the new device may be mistaken for the old device.
echo "c t l" > /sys/class/scsi_host/hosth/scan
hctlecho "scsi add-single-device 0 0 0 0" > /proc/scsi/scsi, is deprecated.
hctsysfs. For example, if the WWNN of the storage server is 0x5006016090203181, use:
grep 5006016090203181 /sys/class/fc_transport/*/node_name
/sys/class/fc_transport/target5:0:2/node_name:0x5006016090203181 /sys/class/fc_transport/target5:0:3/node_name:0x5006016090203181 /sys/class/fc_transport/target6:0:2/node_name:0x5006016090203181 /sys/class/fc_transport/target6:0:3/node_name:0x5006016090203181
56, then the following command will configure the first path:
echo "0 2 56" > /sys/class/scsi_host/host5/scan
sysfs.
lsscsi, scsi_id, multipath -l, and ls -l /dev/disk/by-*. This information, plus the LUN number of the new device, can be used as shown above to probe and configure that path to the new device.
multipath command, and check to see that the device has been properly configured. At this point, the device can be added to md, LVM, mkfs, or mount, for example.
fcoe-utils
lldpad
/etc/fcoe/cfg-eth0) to the name of the ethernet device that supports FCoE. This will provide you with a default file to configure. Given that the FCoE device is ethX, run:
cp /etc/fcoe/cfg-eth0 /etc/fcoe/cfg-ethX
ONBOOT=yes in the corresponding /etc/sysconfig/network-scripts/ifcfg-ethX file. For example, if the FCoE device is eth2, then edit /etc/sysconfig/network-scripts/ifcfg-eth2 accordingly.
dcbd) using the following command:
/etc/init.d/lldpad start
dcbtool sc ethX dcb on
dcbtool sc ethX app:fcoe e:1
dcbd settings for the ethernet interface were not changed.
ifconfig ethX up
/etc/init.d/fcoe start
fcoeadmin -i
lldpad to run at startup. To do so, use chkconfig, as in:
chkconfig lldpad on
chkconfig fcoe on
/usr/share/doc/fcoe-utils-version/README as of Red Hat Enterprise Linux 6.1. Please refer to that document for any possible changes throughout minor releases.
udev rules, autofs, and other similar methods. Sometimes, however, a specific service might require the FCoE disk to be mounted at boot-time. In such cases, the FCoE disk should be mounted as soon as the fcoe service runs and before the initiation of any service that requires the FCoE disk.
fcoe service. The fcoe startup script is /etc/init.d/fcoe.
/etc/fstab:
mount_fcoe_disks_from_fstab()
{
local timeout=20
local done=1
local fcoe_disks=($(egrep 'by-path\/fc-.*_netdev' /etc/fstab | cut -d ' ' -f1))
test -z $fcoe_disks && return 0
echo -n "Waiting for fcoe disks . "
while [ $timeout -gt 0 ]; do
for disk in ${fcoe_disks[*]}; do
if ! test -b $disk; then
done=0
break
fi
done
test $done -eq 1 && break;
sleep 1
echo -n ". "
done=1
let timeout--
done
if test $timeout -eq 0; then
echo "timeout!"
else
echo "done!"
fi
# mount any newly discovered disk
mount -a 2>/dev/null
}mount_fcoe_disks_from_fstab function should be invoked after the fcoe service script starts the fcoemon daemon. This will mount FCoE disks specified by the following paths in /etc/fstab:
/dev/disk/by-path/fc-0xXX:0xXX /mnt/fcoe-disk1 ext3 defaults,_netdev 0 0 /dev/disk/by-path/fc-0xYY:0xYY /mnt/fcoe-disk2 ext3 defaults,_netdev 0 0
fc- and _netdev sub-strings enable the mount_fcoe_disks_from_fstab function to identify FCoE disk mount entries. For more information on /etc/fstab entries, refer to man 5 fstab.
fcoe service does not implement a timeout for FCoE disk discovery. As such, the FCoE mounting code should implement its own timeout period.
vmstat 1 100; interconnect scanning is not recommended if free memory is less than 5% of the total memory in more than 10 samples per 100. It is also not recommended if swapping is active (non-zero si and so columns in the vmstat output). The command free can also display the total memory.
echo "1" > /sys/class/fc_host/host/issue_lipissue_lip is an asynchronous operation. The command may complete before the entire scan has completed. You must monitor /var/log/messages to determine when it is done.
lpfc and qla2xxx drivers support issue_lip. For more information about the API capabilities supported by each driver in Red Hat Enterprise Linux, refer to Table 21.1, “Fibre-Channel API Capabilities”.
/usr/bin/rescan-scsi-bus.shecho "- - -" > /sys/class/scsi_host/hosth/scanrmmod driver-name or modprobe driver-name/etc/iscsi/iscsid.conf. This file contains iSCSI settings used by iscsid and iscsiadm.
iscsiadm tool uses the settings in /etc/iscsi/iscsid.conf to create two types of records:
/var/lib/iscsi/nodesiscsiadm uses the settings in this file.
/var/lib/iscsi/discovery_typeiscsiadm uses the settings in this file.
/var/lib/iscsi/discovery_type) first. To do this, use the following command:
iscsiadm -m discovery -t discovery_type -p target_IP:port -o delete[7]
/etc/iscsi/iscsid.conf file directly prior to performing a discovery. Discovery settings use the prefix discovery; to view them, run:
iscsiadm -m discovery -t discovery_type -p target_IP:port
iscsiadm can also be used to directly change discovery record settings, as in:
iscsiadm -m discovery -t discovery_type -p target_IP:port -o update -n setting -v %value
man iscsiadm for more information on available settingvalueman pages of iscsiadm and iscsid. The /etc/iscsi/iscsid.conf file also contains examples on proper configuration syntax.
ping -I ethX target_IP[7]
ping fails, then you will not be able to bind a session to a NIC. If this is the case, check the network settings first.
scsi_tcp and ib_iser modules, this stack allocates an iSCSI host instance (i.e. scsi_host) per session, with a single connection per session. As a result, /sys/class_scsi_host and /proc/scsi will report a scsi_host for each connection/session you are logged into.
cxgb3i, Broadcom bnx2i and ServerEngines be2iscsi modules, this stack allocates a scsi_host for each PCI device. As such, each port on a host bus adapter will show up as a different PCI device, with a different scsi_host per HBA port.
iscsiadm uses the iface structure. With this structure, an iface configuration must be entered in /var/lib/iscsi/ifaces for each HBA port, software iSCSI, or network device (ethX) used to bind sessions.
iface configurations, run iscsiadm -m iface. This will display iface information in the following format:
iface_nametransport_name,hardware_address,ip_address,net_ifacename,initiator_name
| Setting | Description |
|---|---|
iface_name
|
iface configuration name.
|
transport_name
| Name of driver |
hardware_address
| MAC address |
ip_address
| IP address to use for this port |
net_iface_name
|
Name used for the vlan or alias binding of a software iSCSI session. For iSCSI offloads, net_iface_name will be <empty> because this value is not persistent across reboots.
|
initiator_name
|
This setting is used to override a default name for the initiator, which is defined in /etc/iscsi/initiatorname.iscsi
|
iscsiadm -m iface command:
iface0 qla4xxx,00:c0:dd:08:63:e8,20.15.0.7,default,iqn.2005-06.com.redhat:madmax iface1 qla4xxx,00:c0:dd:08:63:ea,20.15.0.9,default,iqn.2005-06.com.redhat:madmax
iface configuration must have a unique name (with less than 65 characters). The iface_name for network devices that support offloading appears in the format transport_name.hardware_nameiscsiadm -m iface on a system using a Chelsio network card might appear as:
default tcp,<empty>,<empty>,<empty>,<empty> iser iser,<empty>,<empty>,<empty>,<empty> cxgb3i.00:07:43:05:97:07 cxgb3i,00:07:43:05:97:07,<empty>,<empty>,<empty>
iface configuration in a more friendly way. To do so, use the option -I iface_name. This will display the settings in the following format:
iface.setting=value
iface settings of the same Chelsio video card (i.e. iscsiadm -m iface -I cxgb3i.00:07:43:05:97:07) would appear as:
# BEGIN RECORD 2.0-871 iface.iscsi_ifacename = cxgb3i.00:07:43:05:97:07 iface.net_ifacename = <empty> iface.ipaddress = <empty> iface.hwaddress = 00:07:43:05:97:07 iface.transport_name = cxgb3i iface.initiatorname = <empty> # END RECORD
iface configuration is required for each network object that will be used to bind a session.
iface configuration for software iSCSI, run the following command:
iscsiadm -m iface -I iface_name --op=new
iface configuration with a specified iface_nameiface configuration already has the same iface_nameiface configuration, use the following command:
iscsiadm -m iface -I iface_name --op=update -n iface.setting -v hw_address
hardware_address) of iface0 to 00:0F:1F:92:6B:BF, run:
iscsiadm -m iface -I iface0 - -op=update -n iface.hwaddress -v 00:0F:1F:92:6B:BF
default or iser as iface names. Both strings are special values used by iscsiadm for backward compatibility. Any manually-created iface configurations named default or iser will disable backwards compatibility.
iscsiadm will create an iface configuration for each Chelsio, Broadcom, and ServerEngines port. To view available iface configurations, use the same command for doing so in software iSCSI, i.e. iscsiadm -m iface.
iface of a network card for iSCSI offload, first set the IP address (target_IPbe2iscsi driver (i.e. ServerEngines iSCSI HBAs), the IP address is configured in the ServerEngines BIOS setup screen.
iface setting. So to configure the IP address of the iface, use:
iscsiadm -m iface -I iface_name -o update -n iface.ipaddress -v target_IP
iface IP address of a Chelsio card (with iface name cxgb3i.00:07:43:05:97:07) to 20.15.0.66, use:
iscsiadm -m iface -I cxgb3i.00:07:43:05:97:07 -o update -n iface.ipaddress -v 20.15.0.66
iscsiadm is used to scan for interconnects, it will first check the iface.transport settings of each iface configuration in /var/lib/iscsi/ifaces. The iscsiadm utility will then bind discovered portals to any iface whose iface.transport is tcp.
-I iface_name to specify which portal to bind to an iface, as in:
iscsiadm -m discovery -t st -p target_IP:port -I iface_name -P 1[7]
iscsiadm utility will not automatically bind any portals to iface configurations that use offloading. This is because such iface configurations will not have iface.transport set to tcp. As such, the iface configurations of Chelsio, Broadcom, and ServerEngines ports need to be manually bound to discovered portals.
iface. To do so, use default as the iface_nameiscsiadm -m discovery -t st -p IP:port -I default -P 1
iface, use:
iscsiadm -m node -targetname proper_target_name -I iface0 --op=delete[9]
iface, use:
iscsiadm -m node -I iface_name --op=delete
iscsiadm -m node -p IP:port -I iface_name --op=delete
iface configurations defined in /var/lib/iscsi/iface and the -I option is not used, iscsiadm will allow the network subsystem to decide which device a specific portal should use.
iscsiadm utility. Before doing so, however, you need to first retrieve the proper --targetname and the --portal values. If your device model supports only a single logical unit and portal per target, use iscsiadm to issue a sendtargets command to the host, as in:
iscsiadm -m discovery -t sendtargets -p target_IP:port[7]
target_IP:port,target_portal_group_tagproper_target_name
proper_target_nameiqn.1992-08.com.netapp:sn.33615311 and a target_IP:port10.15.85.19:3260, the output may appear as:
10.15.84.19:3260,2 iqn.1992-08.com.netapp:sn.33615311 10.15.85.19:3260,3 iqn.1992-08.com.netapp:sn.33615311
target_ip:port10.15.84.19:3260 and 10.15.85.19:3260.
iface configuration will be used for each session, add the -P 1 option. This option will print also session information in tree format, as in:
Target: proper_target_name
Portal: target_IP:port,target_portal_group_tag
Iface Name: iface_nameiscsiadm -m discovery -t sendtargets -p 10.15.85.19:3260 -P 1, the output may appear as:
Target: iqn.1992-08.com.netapp:sn.33615311
Portal: 10.15.84.19:3260,2
Iface Name: iface2
Portal: 10.15.85.19:3260,3
Iface Name: iface2
iqn.1992-08.com.netapp:sn.33615311 will use iface2 as its iface configuration.
sendtargets command to the host first to find new portals on the target. Then, rescan the existing sessions using:
iscsiadm -m session --rescan
SIDiscsiadm -m session -r SID --rescan[10]
sendtargets command to the hosts to find new portals for each target. Then, rescan existing sessions to discover new logical units on existing sessions (i.e. using the --rescan option).
sendtargets command used to retrieve --targetname and --portal values overwrites the contents of the /var/lib/iscsi/nodes database. This database will then be repopulated using the settings in /etc/iscsi/iscsid.conf. However, this will not occur if a session is currently logged in and in use.
-o new or -o delete options, respectively. For example, to add new targets/portals without overwriting /var/lib/iscsi/nodes, use the following command:
iscsiadm -m discovery -t st -p target_IP -o new
/var/lib/iscsi/nodes entries that the target did not display during discovery, use:
iscsiadm -m discovery -t st -p target_IP -o delete
iscsiadm -m discovery -t st -p target_IP -o delete -o new
sendtargets command will yield the following output:
ip:port,target_portal_group_tagproper_target_name
equallogic-iscsi1 as your target_name10.16.41.155:3260,0 iqn.2001-05.com.equallogic:6-8a0900-ac3fe0101-63aff113e344a4a2-dl585-03-1
proper_target_nameip:port,target_portal_group_tag--targetname and --portal values needed to manually scan for iSCSI devices. To do so, run the following command:
iscsiadm --mode node --targetname proper_target_name --portal ip:port,target_portal_group_tag \ --login [11]
proper_target_nameequallogic-iscsi1), the full command would be:
iscsiadm --mode node --targetname \ iqn.2001-05.com.equallogic:6-8a0900-ac3fe0101-63aff113e344a4a2-dl585-03-1 \ --portal 10.16.41.155:3260,0 --login[11]
service iscsi start
init scripts will automatically log into targets where the node.startup setting is configured as automatic. This is the default value of node.startup for all targets.
node.startup to manual. To do this, run the following command:
iscsiadm -m node --targetname proper_target_name -p target_IP:port -o update -n node.startup -v manual
iscsiadm -m node --targetname proper_target_name -p target_IP:port -o delete
/etc/fstab with the _netdev option. For example, to automatically mount the iSCSI device sdb to /mount/iscsi during startup, add the following line to /etc/fstab:
/dev/sdb /mnt/iscsi ext3 _netdev 0 0
iscsiadm -m node --targetname proper_target_name -p target_IP:port -l
proper_target_nametarget_IP:portecho 1 > /sys/block/sdX/device/rescan
sd1, sd2, and so on) that represents a path for the multipathed logical unit. To determine which devices are paths for a multipath logical unit, use multipath -ll; then, find the entry that matches the logical unit being resized. It is advisable that you refer to the WWID of each entry to make it easier to find which one matches the logical unit being resized.
iscsiadm -m node --targetname target_name -R[7]
target_nameiscsiadm -m node -R -I interface
interfaceiface0). This command performs two operations:
echo "- - -" > /sys/class/scsi_host/host/scan does (refer to Section 21.12, “
Scanning iSCSI Interconnects”).
echo 1 > /sys/block/sdX/device/rescan does. Note that this command is the same one used for re-scanning fibre-channel logical units.
multipathd. To do so, first ensure that multipathd is running using service multipathd status. Once you've verified that multipathd is operational, run the following command:
multipathd -k"resize map multipath_device"
multipath_device/dev/mapper. Depending on how multipathing is set up on your system, multipath_devicempathX, where Xmpath0)
3600508b400105e210000900000490000
multipath -ll. This displays a list of all existing multipath entries in the system, along with the major and minor numbers of their corresponding devices.
multipathd -k"resize map multipath_device" if there are any commands queued to multipath_deviceno_path_retry parameter (in /etc/multipath.conf) is set to "queue", and there are no active paths to the device.
multipathd daemon to recognize (and adjust to) the changes you made to the resized logical unit:
dmsetup table multipath_device
table_namedmsetup suspend multipath_device
table_namedmsetup reload multipath_device table_name
dmsetup resume multipath_device
sg3_utils package provides the rescan-scsi-bus.sh script, which can automatically update the logical unit configuration of the host as needed (after a device has been added to the system). The rescan-scsi-bus.sh script can also perform an issue_lip on supported devices. For more information about how to use this script, refer to rescan-scsi-bus.sh --help.
sg3_utils package, run yum install sg3_utils.
rescan-scsi-bus.sh script, take note of the following known issues:
rescan-scsi-bus.sh to work properly, LUN0 must be the first mapped logical unit. The rescan-scsi-bus.sh can only detect the first mapped logical unit if it is LUN0. The rescan-scsi-bus.sh will not be able to scan any other logical unit unless it detects the first mapped logical unit even if you use the --nooptscan option.
rescan-scsi-bus.sh be run twice if logical units are mapped for the first time. During the first scan, rescan-scsi-bus.sh only adds LUN0; all other logical units are added in the second scan.
rescan-scsi-bus.sh script incorrectly executes the functionality for recognizing a change in logical unit size when the --remove option is used.
rescan-scsi-bus.sh script does not recognize ISCSI logical unit removals.
dev_loss_tmo callback, access attempts to a device through a link will be blocked when a transport problem is detected. To verify if a device is blocked, run the following command:
cat /sys/block/device/device/state
blocked if the device is blocked. If the device is operating normally, this command will return running.
cat /sys/class/fc_remote_port/rport-H:B:R/port_state
Blocked when the remote port (along with devices accessed through it) are blocked. If the remote port is operating normally, the command will return Online.
dev_loss_tmo seconds, the rport and devices will be unblocked and all I/O running on that device (along with any new I/O sent to that device) will be failed.
dev_loss_tmodev_loss_tmo value, echo in the desired value to the file. For example, to set dev_loss_tmo to 30 seconds, run:
echo 30 > /sys/class/fc_remote_port/rport-H:B:R/dev_loss_tmo
dev_loss_tmo, refer to Section 21.1.1, “Fibre Channel API”.
/dev/sdx will remain /dev/sdx. This is because the dev_loss_tmo expired. If the link problem is fixed at a later time, operations will continue using the same SCSI device and device node name.
remove_on_dev_lossdev_loss_tmo seconds), you can use the scsi_transport_fc module parameter remove_on_dev_loss. When a device is removed at the SCSI layer while remove_on_dev_loss is in effect, the device will be added back once all transport problems are corrected.
remove_on_dev_loss is not recommended, as removing a device at the SCSI layer does not automatically unmount any file systems from that device. When file systems from a removed device are left mounted, the device may not be properly removed from multipath or RAID devices.
dm-multipathdm-multipath is implemented, it is advisable to set iSCSI timers to immediately defer commands to the multipath layer. To configure this, nest the following line under device { in /etc/multipath.conf:
features "1 queue_if_no_path"
dm-multipath layer.
replacement_timeout, which are discussed in the following sections.
dm-multipath is being used, the SCSI layer will fail those running commands and defer them to the multipath layer. The multipath layer then retries those commands on another path. If dm-multipath is not being used, those commands are retried five times before failing altogether.
/etc/iscsi/iscsid.conf and edit the following line:
node.conn[0].timeo.noop_out_interval = [interval value][interval value] seconds.
/etc/iscsi/iscsid.conf and edit the following line:
node.conn[0].timeo.noop_out_timeout = [timeout value][timeout value] seconds.
replacement_timeout seconds. For more information about replacement_timeout, refer to Section 21.16.2.2, “replacement_timeout”.
iscsiadm -m session -P 3
replacement_timeoutreplacement_timeout controls how long the iSCSI layer should wait for a timed-out path/session to reestablish itself before failing any commands on it. The default replacement_timeout value is 120 seconds.
replacement_timeout, open /etc/iscsi/iscsid.conf and edit the following line:
node.session.timeo.replacement_timeout = [replacement_timeout]1 queue_if_no_path option in /etc/multipath.conf sets iSCSI timers to immediately defer commands to the multipath layer (refer to Section 21.16.2, “iSCSI Settings With dm-multipath”). This setting prevents I/O errors from propagating to the application; because of this, you can set replacement_timeout to 15-20 seconds.
replacement_timeout, I/O is quickly sent to a new path and executed (in the event of a NOP-Out timeout) while the iSCSI layer attempts to re-establish the failed path/session. If all paths time out, then the multipath and device mapper layer will internally queue I/O based on the settings in /etc/multipath.conf instead of /etc/iscsi/iscsid.conf.
replacement_timeout will depend on other factors. These factors include the network, target, and system workload. As such, it is recommended that you thoroughly test any new configurations to replacements_timeout before applying it to a mission-critical system.
dm-multipath is implemented.
/etc/iscsi/iscsid.conf and edit as follows:
node.conn[0].timeo.noop_out_interval = 0 node.conn[0].timeo.noop_out_timeout = 0
replacement_timeout should be set to a high number. This will instruct the system to wait a long time for a path/session to reestablish itself. To adjust replacement_timeout, open /etc/iscsi/iscsid.conf and edit the following line:
node.session.timeo.replacement_timeout = replacement_timeout/etc/iscsi/iscsid.conf, you must perform a re-discovery of the affected storage. This will allow the system to load and use any new values in /etc/iscsi/iscsid.conf. For more information on how to discover iSCSI devices, refer to Section 21.12, “
Scanning iSCSI Interconnects”.
/etc/iscsi/iscsid.conf). To do so, run the following command (replace the variables accordingly):
iscsiadm -m node -T target_name -p target_IP:port -o update -n node.session.timeo.replacement_timeout -v $timeout_value
dm-multipath), refer to Section 21.16.2, “iSCSI Settings With dm-multipath”.
offline state. When this occurs, all I/O to that device will be failed, until the problem is corrected and the user sets the device to running.
rport is blocked. In such cases, the drivers wait for several seconds for the rport to become online again before activating the error handler. This prevents devices from becoming offline due to temporary transport problems.
lvm commands will hang indefinitely when dm-multipath is used, as the logical unit has now become stale.
mpath link entries in /etc/lvm/cache/.cache are specific to the stale logical unit. To do this, run the following command:
ls -l /dev/mpath | grep stale-logical-unit
stale-logical-unitlrwxrwxrwx 1 root root 7 Aug 2 10:33 /3600d0230003414f30000203a7bc41a00 -> ../dm-4 lrwxrwxrwx 1 root root 7 Aug 2 10:33 /3600d0230003414f30000203a7bc41a00p1 -> ../dm-5
mpath links: dm-4 and dm-5.
/etc/lvm/cache/.cache. Delete all lines containing stale-logical-unitmpath links that stale-logical-unit/dev/dm-4 /dev/dm-5 /dev/mapper/3600d0230003414f30000203a7bc41a00 /dev/mapper/3600d0230003414f30000203a7bc41a00p1 /dev/mpath/3600d0230003414f30000203a7bc41a00 /dev/mpath/3600d0230003414f30000203a7bc41a00p1
[7]
The target_IPport
[8]
For details on different types of discovery, refer to the DISCOVERY TYPES section of man iscsiadm.
[9]
Refer to Section 21.12, “
Scanning iSCSI Interconnects” for information on proper_target_name
[10] For information on how to retrieve a session's SID value, refer to Section 21.2.1, “iSCSI API”.
[11] This is a single command split into multiple lines, to accommodate printed and PDF versions of this document. All concatenated lines — preceded by the backslash (\) — should be treated as one command, sans backslashes.
[12] Prior to Red Hat Enterprise Linux 5.4, the default NOP-Out requests time out was 15 seconds.
libvirt to manage virtual instances. The libvirt utility uses the concept of storage pools to manage storage for virtualized guests. A storage pool is storage that can be divided up into smaller volumes or allocated directly to a guest. Volumes of a storage pool can be allocated to virtualized guests. There are two categories of storage pools available:
| Revision History | |||
|---|---|---|---|
| Revision 1.0 | Thu Jul 09 2009 | ||
| |||
See Also Metadata Journaling.