Base Roll: Users Guide: 
| ||
|---|---|---|
| Prev | Chapter 4. Customizing your Rocks Installation | Next |
The default root partition is 16 GB, the default swap partition is 1 GB, and the default /var partition is 4 GB. The remainder of the root disk is setup as the partition /state/partition1.
Only the root disk (the first discovered disk) is partitioned by default. To partition all disks connected to a compute node, see the section Forcing the Default Partitioning Scheme for All Disks on a Compute Node.
Table 4-1. Compute Node -- Default Root Disk Partition
| Partition Name | Size |
|---|---|
| / | 16 GB |
| swap | 1 GB |
| /var | 4 GB |
| /state/partition1 | remainder of root disk |
 | After the initial installation, all data in the file systems labeled /state/partitionX will be preserved over reinstallations. |
In Rocks, to supply custom partitioning to a node, one must write code in a <pre> section and the code must create a file named /tmp/user_partition_info. Red Hat kickstart partitioning directives should be placed inside /tmp/user_partition_info. This allows users to fully program their cluster nodes' partitions. In the examples below, we'll explore what this means.
Create a new XML node file that will replace the current partition.xml XML node file:
# cd /export/rocks/install/site-profiles/5.1/nodes/ # cp skeleton.xml replace-partition.xml |
Inside replace-partition.xml, add the following section right after the <main> </main> section:
<main> <!-- kickstart 'main' commands go here --> </main> <pre> echo "clearpart --all --initlabel --drives=hda part / --size 8000 --ondisk hda part swap --size 1000 --ondisk hda part /mydata --size 1 --grow --ondisk hda" > /tmp/user_partition_info </pre> |
The above example uses a bash script to populate /tmp/user_partition_info. This will set up an 16 GB root partition, a 1 GB swap partition, and the remainder of the drive will be set up as /mydata. Additional drives on your compute nodes can be setup in a similar manner by changing the --ondisk parameter.
In the above example, the syntax of the data in /tmp/user_partition_info follows directly from Red Hat's kickstart. For more information on the part keyword, see Red Hat Enterprise Linux 5 Installation Guide : Kickstart Options.
 | User-specified partition mountpoint names (e.g., /mydata) cannot be longer than 15 characters. |
Then apply this configuration to the distribution by executing:
# cd /export/rocks/install # rocks create distro |
To reformat compute node compute-0-0 to your specification above, you'll need to first remove the partition info for compute-0-0 from the database:
# rocks remove host partition compute-0-0 |
Then you'll need to remove the file .rocks-release from the first partition of each disk on the compute node. Here's an example script:
for i in `df | awk '{print $6}'`
do
if [ -f $i/.rocks-release ]
then
rm -f $i/.rocks-release
fi
done |
Save the above script as /share/apps/nukeit.sh and then execute:
# ssh compute-0-0 'sh /share/apps/nukeit.sh' |
Then, reinstall the node:
# ssh compute-0-0 '/boot/kickstart/cluster-kickstart' |
If you would like to use software RAID on your compute nodes, inside replace-partition.xml add a section that looks like:
<pre> echo "clearpart --all --initlabel --drives=hda,hdb part / --size 8000 --ondisk hda part swap --size 1000 --ondisk hda part raid.00 --size=10000 --ondisk hda part raid.01 --size=10000 --ondisk hdb raid /mydata --level=1 --device=md0 raid.00 raid.01" > /tmp/user_partition_info </pre> |
Then apply this configuration to the distribution by executing:
# cd /export/rocks/install # rocks create distro |
To reformat compute node compute-0-0 to your specification above, you'll need to first remove the partition info for compute-0-0 from the database:
# rocks remove host partition compute-0-0 |
Then you'll need to remove the file .rocks-release from the first partition of each disk on the compute node. Here's an example script:
for i in `df | awk '{print $6}'`
do
if [ -f $i/.rocks-release ]
then
rm -f $i/.rocks-release
fi
done |
Save the above script as /share/apps/nukeit.sh and then execute:
# ssh compute-0-0 'sh /share/apps/nukeit.sh' |
Then, reinstall the node:
# ssh compute-0-0 '/boot/kickstart/cluster-kickstart' |
Some issues with the above two examples are that 1) you must know the name of the disk device (e.g., hda) and, 2) the partitioning will be applied to all nodes. We can avoid these issues by writing a python program that emits node-specific partitioning directives.
In the next example, we'll use some Rocks partitioning library code to dynamically determine the name of the boot disk.
<pre arg="--interpreter /opt/rocks/bin/python">
import rocks_partition
membership = '<var name='Node_Membership'/>'
nodename = '<var name="Node_Hostname"/>'
def doDisk(file, disk):
file.write('clearpart --all --initlabel --drives=%s\n' % disk)
file.write('part / --size=6000 --fstype=ext3 --ondisk=%s\n' % disk)
file.write('part /var --size=2000 --fstype=ext3 --ondisk=%s\n' % disk)
file.write('part swap --size=2000 --ondisk=%s\n' % disk)
file.write('part /mydata --size=1 --grow --fstype=ext3 --ondisk=%s\n'
% disk)
#
# main
#
p = rocks_partition.RocksPartition()
disks = p.getDisks()
if len(disks) == 1:
file = open('/tmp/user_partition_info', 'w')
doDisk(file, disks[0])
file.close()
</pre> |
The function getDisks() returns a list of discovered disks. In the code sample above, if only one disk is discovered on the node, then the function doDisk is called which outputs partitioning directives for a single disk. This code segment will work for nodes with IDE or SCSI controllers. For example, a node with a IDE controller will name its disks hdX and a node with SCSI controllers will name its disks sdX. But, the code segment above doesn't care how the node names its drives, it only cares if one drive is discovered.
The next example shows how a node can automatically configure a node for software raid when it discovers 2 disks. But, if the node only discovers 1 disk, it will output partitioning info appropriate for a single-disk system.
<pre arg="--interpreter /opt/rocks/bin/python">
import rocks_partition
membership = '<var name='Node_Membership'/>'
nodename = '<var name="Node_Hostname"/>'
def doRaid(file, disks):
file.write('clearpart --all --initlabel --drives=%s\n'
% ','.join(disks))
raidparts = []
for disk in disks:
if disk == disks[0]:
part = 'part / --size=6000 --fstype=ext3 ' + \
'--ondisk=%s\n' % disk
file.write(part)
part = 'part /var --size=2000 --fstype=ext3 ' + \
'--ondisk=%s\n' % disk
file.write(part)
part = 'part raid.%s --size=5000 --ondisk=%s\n' % (disk, disk)
file.write(part)
raidparts.append('raid.%s' % disk)
raid = 'raid /bigdisk --fstype=ext3 --device=md0 --level=1 %s\n' \
% ' '.join(raidparts)
file.write(raid)
def doDisk(file, disk):
file.write('clearpart --all --initlabel --drives=%s\n' % disk)
file.write('part / --size=6000 --fstype=ext3 --ondisk=%s\n' % disk)
file.write('part /var --size=2000 --fstype=ext3 --ondisk=%s\n' % disk)
file.write('part swap --size=2000 --ondisk=%s\n' % disk)
file.write('part /mydata --size=1 --grow --fstype=ext3 --ondisk=%s\n'
% disk)
#
# main
#
p = rocks_partition.RocksPartition()
disks = p.getDisks()
file = open('/tmp/user_partition_info', 'w')
if len(disks) == 2:
doRaid(file, disks)
elif len(disks) == 1:
doDisk(file, disks[0])
file.close()
</pre> |
If the node has 2 disks (if len(disks) == 2:), then call doRaid() to configure a software raid 1 over the 2 disks. If the node has 1 disk then call doDisk() and output partitioning directives for a single disk.
In the next example, we show how to output user-specified partitioning info for only one specific node (compute-0-0). All other nodes that execute this pre section will get the default Rocks partitioning.
<pre arg="--interpreter /opt/rocks/bin/python">
import rocks_partition
membership = '<var name='Node_Membership'/>'
nodename = '<var name="Node_Hostname"/>'
def doRaid(file, disks):
file.write('clearpart --all --initlabel --drives=%s\n'
% ','.join(disks))
raidparts = []
for disk in disks:
if disk == disks[0]:
part = 'part / --size=6000 --fstype=ext3 ' + \
'--ondisk=%s\n' % disk
file.write(part)
part = 'part /var --size=2000 --fstype=ext3 ' + \
'--ondisk=%s\n' % disk
file.write(part)
part = 'part raid.%s --size=5000 --ondisk=%s\n' % (disk, disk)
file.write(part)
raidparts.append('raid.%s' % disk)
raid = 'raid /bigdisk --fstype=ext3 --device=md0 --level=1 %s\n' \
% ' '.join(raidparts)
file.write(raid)
def doDisk(file, disk):
file.write('clearpart --all --initlabel --drives=%s\n' % disk)
file.write('part / --size=6000 --fstype=ext3 --ondisk=%s\n' % disk)
file.write('part /var --size=2000 --fstype=ext3 --ondisk=%s\n' % disk)
file.write('part swap --size=2000 --ondisk=%s\n' % disk)
file.write('part /mydata --size=1 --grow --fstype=ext3 --ondisk=%s\n'
% disk)
#
# main
#
p = rocks_partition.RocksPartition()
disks = p.getDisks()
if nodename in [ 'compute-0-0' ]:
file = open('/tmp/user_partition_info', 'w')
if len(disks) == 2:
doRaid(file, disks)
elif len(disks) == 1:
doDisk(file, disks[0])
file.close()
</pre> |
This procedure describes how to force all the disks connected to a compute node back to the default Rocks partitioning scheme regardless of the current state of the disk drive on the compute node. the Rocks compute node default partitioning scheme.
The root disk will be partitioned as described in Default Partitioning and all remaining disk drives will have one partition with the name /state/partition2, /state/partition3, ...
For example, the following table describes the default partitioning for a compute node with 3 SCSI drives.
Table 4-2. A Compute Node with 3 SCSI Drives
| Device Name | Mountpoint | Size |
|---|---|---|
| /dev/sda1 | / | 16 GB |
| /dev/sda2 | swap | 1 GB |
| /dev/sda3 | /var | 4 GB |
| /dev/sda4 | /state/partition1 | remainder of root disk |
| /dev/sdb1 | /state/partition2 | size of disk |
| /dev/sdc1 | /state/partition3 | size of disk |
Create a new XML configuration file that will replace the current partition.xml configuration file:
# cd /export/rocks/install/site-profiles/5.1/nodes/ # cp skeleton.xml replace-partition.xml |
Inside replace-partition.xml, add the following section:
<pre> echo "rocks force-default" > /tmp/user_partition_info </pre> |
Then apply this configuration to the distribution by executing:
# cd /export/rocks/install # rocks create distro |
To reformat compute node compute-0-0 to your specification above, you'll need to first remove the partition info for compute-0-0 from the database:
# rocks remove host partition compute-0-0 |
Then you'll need to remove the file .rocks-release from the first partition of each disk on the compute node. Here's an example script:
for i in `df | awk '{print $6}'`
do
if [ -f $i/.rocks-release ]
then
rm -f $i/.rocks-release
fi
done |
Save the above script as /share/apps/nukeit.sh and then execute:
# ssh compute-0-0 'sh /share/apps/nukeit.sh' |
Then, reinstall the node:
# ssh compute-0-0 '/boot/kickstart/cluster-kickstart' |
After you have returned all the compute nodes to the default partitioning scheme, then you'll want to remove replace-partition.xml in order to allow Rocks to preserve all non-root partition data.
# rm /export/rocks/install/site-profiles/5.1/nodes/replace-partition.xml |
Then apply this update to the distribution by executing:
# cd /export/rocks/install # rocks create distro |
This procedure describes how to force a compute node to always display the manual partitioning screen during install. This is useful when you want full and explicit control over a node's partitioning.
Create a new XML configuration file that will replace the current partition.xml configuration file:
# cd /export/rocks/install/site-profiles/5.1/nodes/ # cp skeleton.xml replace-partition.xml |
Inside replace-partition.xml, add the following section:
<pre> echo "rocks manual" > /tmp/user_partition_info </pre> |
Then apply this configuration to the distribution by executing:
# cd /export/rocks/install # rocks create distro |
The next time you install a compute node, you will see the screen:
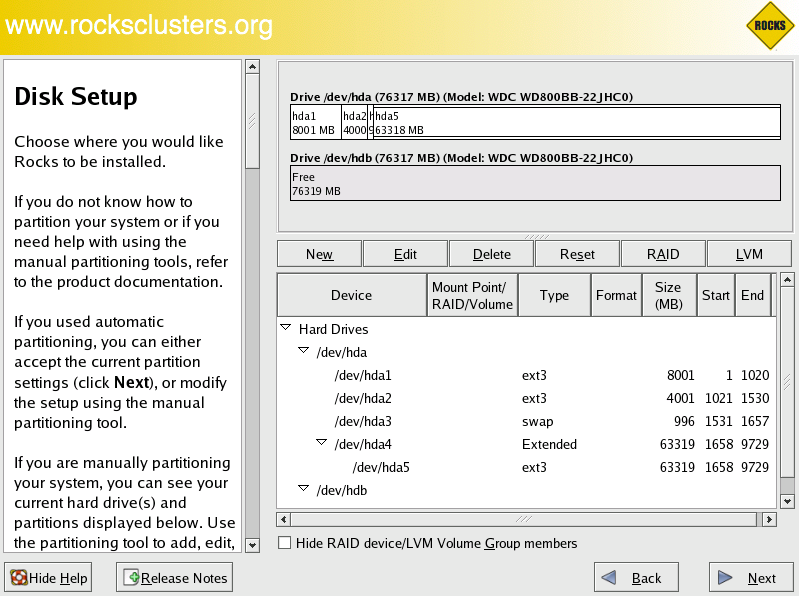
To interact with the above screen, from the frontend execute the command:
# rocks-console compute-0-0 |