
As discussed in Batch Domain Language, a
Step is a domain object that encapsulates an
independent, sequential phase of a batch job and contains all of the
information necessary to define and control the actual batch processing.
This is a necessarily vague description because the contents of any given
Step are at the discretion of the developer writing a
Job. A Step can be as simple or complex as the
developer desires. A simple Step might load data from
a file into the database, requiring little or no code. (depending upon the
implementations used) A more complex Step may have
complicated business rules that are applied as part of the
processing.
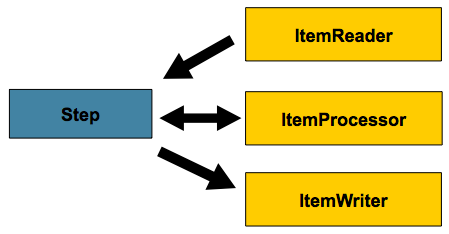
Spring Batch uses a 'Chunk Oriented' processing style within its
most common implementation. Chunk oriented processing refers to reading
the data one at a time, and creating 'chunks' that will be written out,
within a transaction boundary. One item is read in from an
ItemReader, handed to an
ItemWriter, and aggregated. Once the number of
items read equals the commit interval, the entire chunk is written out via
the ItemWriter, and then the transaction is committed.
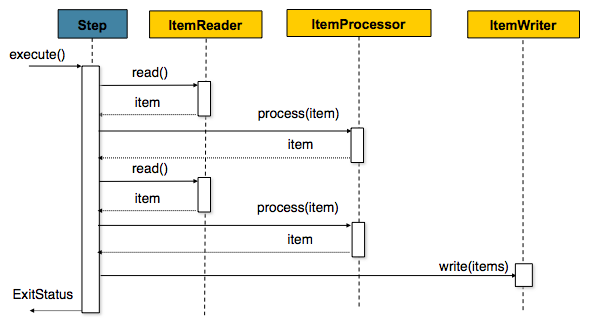
Below is a code representation of the same concepts shown above:
List items = new Arraylist();
for(int i = 0; i < commitInterval; i++){
Object item = itemReader.read()
Object processedItem = itemProcessor.process(item);
items.add(processedItem);
}
itemWriter.write(items);Despite the relatively short list of required dependencies for a
Step, it is an extremely complex class that can
potentially contain many collaborators. In order to ease configuration,
the Spring Batch namespace can be used:
<job id="sampleJob" job-repository="jobRepository">
<step id="step1">
<tasklet transaction-manager="transactionManager">
<chunk reader="itemReader" writer="itemWriter" commit-interval="10"/>
<tasklet>
</step>
</job>The configuration above represents the only required dependencies to create a item-oriented step:
reader - The ItemReader that provides
items for processing.
writer - The ItemWriter that
processes the items provided by the
ItemReader.
transaction-manager - Spring's
PlatformTransactionManager that will be
used to begin and commit transactions during processing.
job-repository - The JobRepository
that will be used to periodically store the
StepExecution and
ExecutionContext during processing (just
before committing). For an in-line <step/> (one defined
within a <job/>) it is an attribute on the <job/>
element; for a standalone step, it is defined as an attribute of
the on the <tasklet/>.
commit-interval - The number of items that will be processed before the transaction is committed.
It should be noted that, job-repository defaults to
"jobRepository" and transaction-manager defaults to "transactionManger".
Furthermore, the ItemProcessor is optional, not
required, since the item could be directly passed from the reader to the
writer.
While steps must exist within a Job to define the flow, it can sometimes be useful to reference a 'standalone' Step. For example, if a Step is used by multiple jobs it can be useful to declare it once and reference it from multiple jobs. This can be achieved with the 'parent' attribute:
<job id="sampleJob" job-repository="jobRepository">
<step id="step1" parent="standaloneStep" />
</job>
<step id="standaloneStep">
<tasklet job-repository="jobRepository" transaction-manager="transactionManager">
<chunk reader="itemReader" writer="itemWriter" commit-interval="10"/>
</tasklet>
</step>It should be noted that the id attribute is still required on the step within the job element. This is for two reasons:
The id will be used as the step name when persisting the StepExecution. If the same standalone step is referenced in more than one step in the job, an error will occur.
When creating job flows, as described later in this chapter, the next attribute should be referring to the step in the flow, not the standalone step.
If a group of Steps share similar
configurations, then it may be helpful to define a "parent"
Step from which the concrete
Steps may inherit properties. Similar to class
inheritance in Java, the "child" Step will
combine its elements and attributes with the parent's. The child will
also override any of the parent's Steps.
In the following example, the Step
"concreteStep1" will inherit from "parentStep". It will be instantiated
with 'itemReader', 'itemProcessor', 'itemWriter', startLimit=5, and
allowStartIfComplete=true. Additionally, the commitInterval will be '5'
since it is overridden by the "concreteStep1":
<step id="parentStep">
<tasklet allow-start-if-complete="true">
<chunk reader="itemReader" writer="itemWriter" commit-interval="10"/>
</tasklet>
</step>
<step id="concreteStep1" parent="parentStep">
<tasklet start-limit="5">
<chunk processor="itemProcessor" commit-interval="5"/>
</tasklet>
</step>Sometimes it may be necessary to define a parent
Step that is not a complete
Step configuration. If, for instance, the
reader, writer, and tasklet attributes are left off of a
Step configuration, then initialization will
fail. If a parent must be defined without these properties, then the
"abstract" attribute should be used. An "abstract"
Step will not be instantiated; it is used only
for extending.
In the following example, the Step
"abstractParentStep" would not instantiate if it were not declared to
be abstract. The Step "concreteStep2" will have
'itemReader', 'itemWriter', and commitInterval=10.
<step id="abstractParentStep" abstract="true">
<tasklet>
<chunk commit-interval="10"/>
</tasklet>
</step>
<step id="concreteStep2" parent="abstractParentStep">
<tasklet>
<chunk reader="itemReader" writer="itemWriter"/>
</tasklet>
</step>Some of the configurable elements on
Steps are lists; the <listeners/>
element, for instance. If both the parent and child
Steps declare a <listeners/> element,
then the child's list will override the parent's. In order to allow a
child to add additional listeners to the list defined by the parent,
every list element has a "merge" attribute. If the element specifies
that merge="true", then the child's list will be combined with the
parent's instead of overriding it.
In the following example, the Step
"concreteStep3" will be created will two listeners:
com.ListenerOne and
com.ListenerTwo:
<step id="listenersParentStep" abstract="true">
<listeners>
<listener class="com.ListenerOne"/>
<listeners>
</step>
<step id="concreteStep3" parent="listenersParentStep">
<tasklet>
<chunk reader="itemReader" writer="itemWriter" commit-interval="5"/>
<listeners merge="true">
<listener class="com.ListenerTwo"/>
<listeners>
</tasklet>
</step>As mentioned above, a step reads in and writes out items,
periodically committing using the supplied
PlatformTransactionManager. With a
commit-interval of 1, it will commit after writing each individual item.
This is less than ideal in many situations, since beginning and
committing a transaction is expensive. Ideally, it is preferable to
process as many items as possible in each transaction, which is
completely dependent upon the type of data being processed and the
resources with which the step is interacting. For this reason, the
number of items that are processed within a commit can be
configured.
<job id="sampleJob">
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="itemWriter" commit-interval="10"/>
</tasklet>
</step>
</job>In the example above, 10 items will be processed within each
transaction. At the beginning of processing a transaction is begun, and
each time read is called on the
ItemReader, a counter is incremented. When it
reaches 10, the list of aggregated items is passed to the
ItemWriter, and the transaction will be
committed.
In Chapter 4, Configuring and Running a Job, restarting a
Job was discussed. Restart has numerous impacts
on steps, and as such may require some specific configuration.
There are many scenarios where you may want to control the
number of times a Step may be started. For
example, a particular Step might need to be
configured so that it only runs once because it invalidates some
resource that must be fixed manually before it can be run again. This
is configurable on the step level, since different steps may have
different requirements. A Step that may only be
executed once can exist as part of the same Job
as a Step that can be run infinitely. Below is
an example start limit configuration:
<step id="step1">
<tasklet start-limit="1">
<chunk reader="itemReader" writer="itemWriter" commit-interval="10"/>
</tasklet>
</step>The simple step above can be run only once. Attempting to run it
again will cause an exception to be thrown. It should be noted that
the default value for the start-limit is
Integer.MAX_VALUE.
In the case of a restartable job, there may be one or more steps
that should always be run, regardless of whether or not they were
successful the first time. An example might be a validation step, or a
Step that cleans up resources before
processing. During normal processing of a restarted job, any step with
a status of 'COMPLETED', meaning it has already been completed
successfully, will be skipped. Setting allow-start-if-complete to
"true" overrides this so that the step will always run:
<step id="step1">
<tasklet allow-start-if-complete="true">
<chunk reader="itemReader" writer="itemWriter" commit-interval="10"/>
</tasklet>
</step><job id="footballJob" restartable="true">
<step id="playerload" next="gameLoad">
<tasklet>
<chunk reader="playerFileItemReader" writer="playerWriter"
commit-interval="10" />
</tasklet>
</step>
<step id="gameLoad" next="playerSummarization">
<tasklet allow-start-if-complete="true">
<chunk reader="gameFileItemReader" writer="gameWriter"
commit-interval="10"/>
</tasklet>
</step>
<step id="playerSummarization">
<tasklet start-limit="3">
<chunk reader="playerSummarizationSource" writer="summaryWriter"
commit-interval="10"/>
</tasklet>
</step>
</job>The above example configuration is for a job that loads in
information about football games and summarizes them. It contains
three steps: playerLoad, gameLoad, and playerSummarization. The
playerLoad Step loads player information from a
flat file, while the gameLoad Step does the
same for games. The final Step,
playerSummarization, then summarizes the statistics for each player
based upon the provided games. It is assumed that the file loaded by
'playerLoad' must be loaded only once, but that 'gameLoad' will load
any games found within a particular directory, deleting them after
they have been successfully loaded into the database. As a result, the
playerLoad Step contains no additional
configuration. It can be started almost limitlessly, and if complete
will be skipped. The 'gameLoad' Step, however,
needs to be run every time in case extra files have been dropped since
it last executed. It has 'allow-start-if-complete' set to 'true' in
order to always be started. (It is assumed that the database tables
games are loaded into has a process indicator on it, to ensure new
games can be properly found by the summarization step). The
summarization Step, which is the most important
in the Job, is configured to have a start limit
of 3. This is useful because if the step continually fails, a new exit
code will be returned to the operators that control job execution, and
it won't be allowed to start again until manual intervention has taken
place.
This job is purely for example purposes and is not the same as the footballJob found in the samples project.
Run 1:
playerLoad is executed and completes successfully, adding 400 players to the 'PLAYERS' table.
gameLoad is executed and processes 11 files worth of game data, loading their contents into the 'GAMES' table.
playerSummarization begins processing and fails after 5 minutes.
Run 2:
playerLoad is not run, since it has already completed successfully, and allow-start-if-complete is 'false' (the default).
gameLoad is executed again and processes another 2 files, loading their contents into the 'GAMES' table as well (with a process indicator indicating they have yet to be processed)
playerSummarization begins processing of all remaining game data (filtering using the process indicator) and fails again after 30 minutes.
Run 3:
playerLoad is not run, since it has already completed successfully, and allow-start-if-complete is 'false' (the default).
gameLoad is executed again and processes another 2 files, loading their contents into the 'GAMES' table as well (with a process indicator indicating they have yet to be processed)
playerSummarization is not start, and the job is immediately
killed, since this is the third execution of playerSummarization,
and its limit is only 2. The limit must either be raised, or the
Job must be executed as a new
JobInstance.
There are many scenarios where errors encountered while processing
should not result in Step failure, but should be
skipped instead. This is usually a decision that must be made by someone
who understands the data itself and what meaning it has. Financial data,
for example, may not be skippable because it results in money being
transferred, which needs to be completely accurate. Loading a list of
vendors, on the other hand, might allow for skips. If a vendor is not
loaded because it was formatted incorrectly or was missing necessary
information, then there probably won't be issues. Usually these bad
records are logged as well, which will be covered later when discussing
listeners.
<step id="step1">
<tasklet>
<chunk reader="flatFileItemReader" writer="itemWriter"
commit-interval="10" skip-limit="10">
<skippable-exception-classes>
org.springframework.batch.item.file.FlatFileParseException
</skippable-exception-classes>
</chunk>
</tasklet>
</step>In this example, a FlatFileItemReader is
used, and if at any point a
FlatFileParseException is thrown, it will be
skipped and counted against the total skip limit of 10. Separate counts
are made of skips on read, process and write inside the step execution,
and the limit applies across all.
One problem with the example above is that any other exception
besides a FlatFileParseException will cause the
Job to fail. In certain scenarios this may be the
correct behavior. However, in other scenarios it may be easier to
identify which exceptions should cause failure and skip everything
else:
<step id="step1">
<tasklet>
<chunk reader="flatFileItemReader" writer="itemWriter"
commit-interval="10" skip-limit="10">
<skippable-exception-classes>
java.lang.Exception
</skippable-exception-classes>
<fatal-exception-classes>
java.io.FileNotFoundException
</fatal-exception-classes>
</chunk>
</tasklet>
</step>By setting the skippable exceptions to
java.lang.Exception, any exception that is thrown
will be skipped. However, the second list, 'fatal-exception-classes',
contains specific exceptions that should be fatal if encountered (i.e.
not skipped).
In most cases you want an exception to cause either a skip or
Step failure. However, not all exceptions are
deterministic. If a FlatFileParseException is
encountered while reading, it will always be thrown for that record;
resetting the ItemReader will not help. However,
for other exceptions, such as a
DeadlockLoserDataAccessException, which indicates
that the current process has attempted to update a record that another
process holds a lock on, waiting and trying again might result in
success. In this case, retry should be configured:
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="itemWriter"
commit-interval="2" retry-limit="3">
<retryable-exception-classes>
org.springframework.dao.DeadlockLoserDataAccessException
</retryable-exception-classes>
</chunk>
</tasklet>
</step>The Step allows a limit for the number of
times an individual item can be retried, and a list of exceptions that
are 'retryable'. More details on how retry works can be found in Chapter 9, Retry
By default, regardless of retry or skip, any exceptions thrown
from the ItemWriter will cause the transaction
controlled by the Step to rollback. If skip is
configured as described above, exceptions thrown from the
ItemReader will not cause a rollback. However,
there are many scenarios in which exceptions thrown from the
ItemWriter should not cause a rollback because no
action has taken place to invalidate the transaction. For this reason,
the Step can be configured with a list of
exceptions that should not cause rollback. The
no-rollback-exception-classes element is a list of transaction
attributes, separated by commas or newlines.
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="itemWriter" commit-interval="2"/>
<no-rollback-exception-classes>
org.springframework.batch.item.validator.ValidationException
</no-rollback-exception-classes>
</tasklet>
</step>The basic contract of the ItemReader is
that it is forward only. The step buffers reader input, so that in the
case of a rollback the items don't need to be re-read from the reader.
However, there are certain scenarios in which the reader is built on
top of a transactional resource, such as a JMS queue. In this case,
since the queue is tied to the transaction that is rolled back, the
messages that have been pulled from the queue will be put back on. For
this reason, the step can be configured to not buffer the
items:
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="itemWriter" commit-interval="2"
is-reader-transactional-queue="true"/>
</tasklet>
</step>Transaction attributes can be used to control the isolation, propagation, and timeout settings. More information on setting transaction attributes can be found in the spring core documentation.
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="itemWriter" commit-interval="2"/>
<transaction-attributes isolation="DEFAULT"
propagation="REQUIRED"
timeout="30"/>
</tasklet>
</step>The step has to take care of ItemStream
callbacks at the necessary points in its lifecycle. (for more
information on the ItemStream interface, please
refer to Section 6.4, “ItemStream”) This is vital if a step fails,
and might need to be restarted, because the
ItemStream interface is where the step gets the
information it needs about persistent state between executions.
If the ItemReader,
ItemProcessor, or
ItemWriter itself implements the
ItemStream interface, then these will be
registered automatically. Any other streams need to be registered
separately. This is often the case where there are indirect dependencies
such as delegates being injected into the reader and writer. A stream
can be registered on the Step through the
'streams' element, as illustrated below:
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="compositeWriter" commit-interval="2">
<streams>
<stream ref="fileItemWriter1"/>
<stream ref="fileItemWriter2"/>
</streams>
</chunk>
</tasklet>
</step>
<beans:bean id="compositeWriter"
class="org.springframework.batch.item.support.CompositeItemWriter">
<beans:property name="delegates">
<beans:list>
<beans:ref bean="fileItemWriter1" />
<beans:ref bean="fileItemWriter2" />
</beans:list>
</beans:property>
</beans:bean>In the example above, the
CompositeItemWriter is not an
ItemStream, but both of its delegates are.
Therefore, both delegate writers must be explicitly registered as
streams in order for the framework to handle them correctly. The
ItemReader does not need to be explicitly
registered as a stream because it is a direct property of the
Step. The step will now be restartable and the
state of the reader and writer will be correctly persisted in the event
of a failure.
Just as with the Job, there are many events
during the execution of a Step where a user may
need to perform some functionality. For example, in order to write out
to a flat file that requires a footer, the
ItemWriter needs to be notified when the
Step has been completed, so that the footer can
written. This can be accomplished with one of many
Step scoped listeners.
Any class that implements the StepListener
interface (or an extension thereof) can be applied to a step via the
listeners element:
<step id="step1">
<tasklet>
<chunk reader="reader" writer="writer" commit-interval="10"/>
<listeners>
<listener ref="stepListener"/>
</listeners>
</tasklet>
</step>An ItemReader, ItemWriter
or ItemProcessor that itself implements
one of the StepListener interfaces will
be registered automatically with the Step
if using the namespace <step> element,
or one of the the *StepFactoryBean
factories. This only applies to components directly injected
into the Step: if the listener is nested
inside another component, it needs to be explicitly registered
(as described above).
In addition to the StepListener interfaces,
annotations are provided to address the same concerns.
StepExecutionListener represents the most
generic listener for Step execution. It allows
for notification before a Step is started and
after it has ends, whether it ended normally or failed:
public interface StepExecutionListener extends StepListener {
void beforeStep(StepExecution stepExecution);
ExitStatus afterStep(StepExecution stepExecution);
}ExitStatus is the return type of
afterStep in order to allow listeners the
chance to modify the exit code that is returned upon completion of a
Step.
The annotations corresponding to this interface are:
@BeforeStep
@AfterStep
A chunk is defined as the items processed within the scope of a
transaction. Committing a transaction, at each commit interval,
commits a 'chunk'. A ChunkListener may be
useful to perform logic before a chunk begins processing or after a
chunk has completed:
public interface ChunkListener extends StepListener {
void beforeChunk();
void afterChunk();
}The beforeChunk method is called after
the transaction is started, but before read
is called on the ItemReader. Conversely,
afterChunk is called after the last call to
write on the
ItemWriter, but before the chunk has been
committed.
The annotations corresponding to this interface are:
@BeforeChunk
@AfterChunk
When discussing skip logic above, it was mentioned that it may
be beneficial to log out skipped records, so that they can be deal
with later. In the case of read errors, this can be done with an
ItemReaderListener:
public interface ItemReadListener<T> extends StepListener {
void beforeRead();
void afterRead(T item);
void onReadError(Exception ex);
}The beforeRead method will be called
before each call to read on the
ItemReader. The
afterRead method will be called after each
successful call to read, and will be passed
the item that was read. If there was an error while reading, the
onReadError method will be called. The
exception encountered will be provided so that it can be
logged.
The annotations corresponding to this interface are:
@BeforeRead
@AfterRead
@OnReadError
Just as with the ItemReadListener, the
processing of an item can be 'listened' to:
public interface ItemProcessListener<T, S> extends StepListener {
void beforeProcess(T item);
void afterProcess(T item, S result);
void onProcessError(T item, Exception e);
}The beforeProcess method will be called
before process on the
ItemProcessor, and is handed the item that will
be processed. The afterProcess method will be
called after the item has been successfully processed. If there was an
error while processing, the onProcessError
method will be called. The exception encountered and the item that was
attempted to be processed will be provided, so that they can be
logged.
The annotations corresponding to this interface are:
@BeforeProcess
@AfterProcess
@OnProcessError
The writing of an item can be 'listened' to with the
ItemWriteListener:
public interface ItemWriteListener<S> extends StepListener {
void beforeWrite(List<? extends S> items);
void afterWrite(List<? extends S> items);
void onWriteError(Exception exception, List<? extends S> items);
}The beforeWrite method will be called
before write on the
ItemWriter, and is handed the item that will be
written. The afterWrite method will be called
after the item has been successfully written. If there was an error
while writing, the onWriteError method will
be called. The exception encountered and the item that was attempted
to be written will be provided, so that they can be logged.
The annotations corresponding to this interface are:
@BeforeWrite
@AfterWrite
@OnWriteError
ItemReadListener,
ItemProcessListener, and
ItemWriteListner all provide mechanisms for
being notified of errors, but none will inform you that a record has
actually been skipped. onWriteError, for
example, will be called even if an item is retried and successful. For
this reason, there is a separate interface for tracking skipped
items:
public interface SkipListener<T,S> extends StepListener {
void onSkipInRead(Throwable t);
void onSkipInProcess(T item, Throwable t);
void onSkipInWrite(S item, Throwable t);
}onSkipInRead will be called whenever an
item is skipped while reading. It should be noted that rollbacks may
cause the same item to be registered as skipped more than once.
onSkipInWrite will be called when an item is
skipped while writing. Because the item has been read successfully
(and not skipped), it is also provided the item itself as an
argument.
The annotations corresponding to this interface are:
@OnSkipInRead
@OnSkipInWrite
@OnSkipInProcess
One of the most common use cases for a
SkipListener is to log out a skipped item, so
that another batch process or even human process can be used to
evaluate and fix the issue leading to the skip. Because there are
many cases in which the original transaction may be rolled back,
Spring Batch makes two guarantees:
The appropriate skip method (depending on when the error happened) will only be called once per item.
The SkipListener will always be
called just before the transaction is committed. This is to
ensure that any transactional resources call by the listener are
not rolled back by a failure within the
ItemWriter.
Chunk-oriented processing is not the only way to process in a
Step. What if a Step must
consist as a simple stored procedure call? You could implement the call as
an ItemReader and return null after the procedure
finishes, but it is a bit unnatural since there would need to be a no-op
ItemWriter. Spring Batch provides the
TaskletStep for this scenario.
The Tasklet is a simple interface that has
one method, execute, which will be a called
repeatedly by the TaskletStep until it either
returns RepeatStatus.FINISHED or throws an exception to
signal a failure. Each call to the Tasklet is
wrapped in a transaction. Tasklet implementors
might call a stored procedure, a script, or a simple SQL update statement.
To create a TaskletStep, the 'ref' attribute of the
<tasket/> element should reference a bean defining a
Tasklet object; no <chunk/> element should be
used within the <tasket/>:
<step id="step1">
<tasklet ref="myTasklet"/>
</step>TaskletStep will automatically register the
tasklet as StepListener if it implements this
interface
As with other adapters for the ItemReader
and ItemWriter interfaces, the
Tasklet interface contains an implementation that
allows for adapting itself to any pre-existing class:
TaskletAdapter. An example where this may be
useful is an existing DAO that is used to update a flag on a set of
records. The TaskletAdapter can be used to call
this class without having to write an adapter for the
Tasklet interface:
<bean id="myTasklet" class="org.springframework.batch.core.step.tasklet.TaskletAdapter">
<property name="targetObject">
<bean class="org.mycompany.FooDao">
</property>
<property name="targetMethod" value="updateFoo" />
</bean>Many batch jobs contain steps that must be done before the main
processing begins in order to set up various resources or after
processing has completed to cleanup those resources. In the case of a
job that works heavily with files, it is often necessary to delete
certain files locally after they have been uploaded successfully to
another location. The example below taken from the Spring Batch samples
project, is a Tasklet implementation with just
such a responsibility:
public class FileDeletingTasklet implements Tasklet, InitializingBean {
private Resource directory;
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
File dir = directory.getFile();
Assert.state(dir.isDirectory());
File[] files = dir.listFiles();
for (int i = 0; i < files.length; i++) {
boolean deleted = files[i].delete();
if (!deleted) {
throw new UnexpectedJobExecutionException("Could not delete file " +
files[i].getPath());
}
}
return RepeatStatus.COMPLETED;
}
public void setDirectoryResource(Resource directory) {
this.directory = directory;
}
public void afterPropertiesSet() throws Exception {
Assert.notNull(directory, "directory must be set");
}
}The above Tasklet implementation will
delete all files within a given directory. It should be noted that the
execute method will only be called once. All
that is left is to reference the Tasklet from the
Step:
<job id="taskletJob">
<step id="deleteFilesInDir">
<tasklet ref="fileDeletingTasklet"/>
</step>
</job>
<beans:bean id="fileDeletingTasklet"
class="org.springframework.batch.sample.tasklet.FileDeletingTasklet">
<beans:property name="directoryResource">
<beans:bean id="directory"
class="org.springframework.core.io.FileSystemResource">
<beans:constructor-arg value="target/test-outputs/test-dir" />
</beans:bean>
</beans:property>
</beans:bean>With the ability to group steps together within an owning job comes
the need to be able to control how the job 'flows' from one step to
another. The failure of a Step doesn't necessarily
mean that the Job should fail. Furthermore, there
may be more than one type of 'success' which determines which
Step should be executed next. Depending upon how a
group of Steps is configured, certain steps may not even be processed at
all.
The simplest flow scenario is a job where all of the steps execute sequentially:
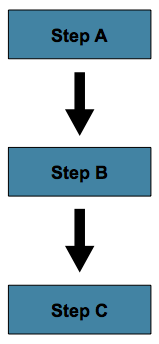
This can be achieved using the 'next' attribute of the step element:
<job id="job">
<step id="stepA" parent="s1" next="stepB" />
<step id="stepB" parent="s2" next="stepC"/>
<step id="stepC" parent="s3" />
</job>In the scenario above, 'step A' will execute
first because it is the first Step listed. If
'step A' completes normally, then 'step B' will execute, and so on.
However, if 'step A' fails, then the entire Job
will fail and 'step B' will not execute.
With the Spring Batch namespace, the first step listed in the
configuration will always be the first step
executed by the Job. The order of the other
step elements does not matter, but the first step must always appear
first in the xml.
In the example above, there are only two possibilities:
The Step is successful and the next
Step should be executed.
The Step failed and thus the
Job should fail.
In many cases, this may be sufficient. However, what about a
scenario in which the failure of a Step should
trigger a different Step, rather than causing
failure?
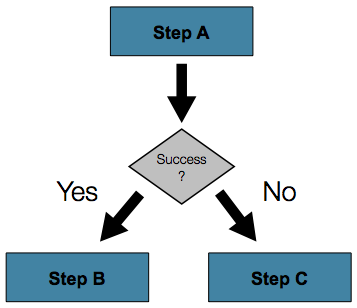
In order to handle more complex scenarios, the
Spring Batch namespace allows transition elements to be defined within
the step element. One such transition is the "next" element. Like the
"next" attribute, the "next" element will tell the
Job which Step to execute
next. However, unlike the attribute, any number of "next" elements are
allowed on a given Step, and there is no default
behavior the case of failure. This means that if transition elements are
used, then all of the behavior for the Step's
transitions must be defined explicitly. Note also that a single step
cannot have both a "next" attribute and a transition element.
The next element specifies a pattern to match and the step to execute next:
<job id="job">
<step id="stepA" parent="s1">
<next on="*" to="stepB" />
<next on="FAILED" to="stepC" />
</step>
<step id="stepB" parent="s2" next="stepC" />
<step id="stepC" parent="s3" />
</job>The "on" attribute of a transition element uses a simple
pattern-matching scheme to match the ExitStatus
that results from the execution of the Step. Only
two special characters are allowed in the pattern:
"*" will zero or more characters
"?" will match exactly one character
For example, "c*t" will match "cat" and "count", while "c?t" will match "cat" but not "count".
While there is no limit to the number of transition elements on a
Step, if the Step's
execution results in an ExitStatus that is not
covered by an element, then the framework will throw an exception and
the Job will fail. It is important to note that
the framework will automatically order transitions from most specific to
least specific. This means that even if the elements were swapped for
"stepA" in the example above, an ExitStatus of
"FAILED" would still go to "stepB".
When configuring a Job for conditional
flow, it is important to understand the difference between
BatchStatus and
ExitStatus. BatchStatus
is an enumeration that is a property of both
JobExecution and
StepExecution and is used by the framework to
record the status of a Job or
Step. It can be one of the following values:
COMPLETED, STARTING, STARTED, STOPPING, STOPPED, FAILED, ABANDONED or
UNKNOWN. Most of them are self explanatory: COMPLETED is the status
set when a step or job has completed successfully, FAILED is set when
it fails, and so on. The example above contains the following 'next'
element:
<next on="FAILED" to="stepB" />
At first glance, it would appear that the 'on' attribute
references the BatchStatus of the
Step to which it belongs. However, it actually
references the ExitStatus of the
Step. As the name implies,
ExitStatus represents the status of a
Step after it finishes execution. More
specifically, the 'next' element above references the exit code of the
ExitStatus. To write it in English, it says:
"go to stepB if the exit code is FAILED". By default, the exit code is
always the same as the BatchStatus for the
Step, which is why the entry above works. However, what if the exit
code needs to be different? A good example comes from the skip sample
job within the samples project:
<step id="step1" parent="s1">
<end on="FAILED" />
<next on="COMPLETED WITH SKIPS" to="errorPrint1" />
<next on="*" to="step2" />
</step>The above step has three possibilities:
The Step failed, in which case the
job should fail.
The Step completed
successfully.
The Step completed successfully, but
with an exit code of 'COMPLETED WITH SKIPS'. In this case, a
different step should be run to handle the errors.
The above configuration will work. However, something needs to change the exit code based on the condition of the execution having skipped records:
public class SkipCheckingListener extends StepExecutionListenerSupport {
public ExitStatus afterStep(StepExecution stepExecution) {
String exitCode = stepExecution.getExitStatus().getExitCode();
if (!exitCode.equals(ExitStatus.FAILED.getExitCode()) &&
stepExecution.getSkipCount() > 0) {
return new ExitStatus("COMPLETED WITH SKIPS");
}
else {
return null;
}
}
}The above code is a StepExecutionListener
that first checks to make sure the Step was
successful, and next if the skip count on the
StepExecution is higher than 0. If both
conditions are met, a new ExitStatus with an
exit code of "COMPLETED WITH SKIPS" is returned.
After the discussion of BatchStatus and
ExitStatus, one might wonder how the
BatchStatus and ExitStatus
are determined for the Job. While these statuses
are determined for the Step by the code that is
executed, the statuses for the Job will be
determined based on the configuration.
So far, all of the job configurations discussed have had at least
one final Step with no transitions. For example,
after the following step executes, the Job will
end:
<step id="stepC" parent="s3"/>
If no transitions are defined for a Step,
then the Job's statuses will be defined as
follows:
If the Step ends with
ExitStatus FAILED, then the
Job's BatchStatus and
ExitStatus will both be FAILED.
Otherwise, the Job's
BatchStatus and
ExitStatus will both be COMPLETED.
While this method of terminating a batch job is sufficient for
some batch jobs, such as a simple sequential step job, custom defined
job-stopping scenarios may be required. For this purpose, Spring Batch
provides three transition elements to stop a Job
(in addition to the "next" element
that we discussed previously). Each of these stopping elements will stop
a Job with a particular
BatchStatus. It is important to note that the
stop transition elements will have no effect on either the
BatchStatus or ExitStatus
of any Steps in the Job:
these elements will only affect the final statuses of the
Job. For example, it is possible for every step
in a job to have a status of FAILED but the job to have a status of
COMPLETED, or vise versa.
The 'end' element instructs a Job to stop
with a BatchStatus of COMPLETED. A
Job that has finished with status COMPLETED
cannot be restarted (the framework will throw a
JobInstanceAlreadyCompleteException). The 'end'
element also allows for an optional 'exit-code' attribute that can be
used to customize the ExitStatus of the
Job. If no 'exit-code' attribute is given, then
the ExitStatus will be "COMPLETED" by default,
to match the BatchStatus.
In the following scenario, if step2 fails, then the
Job will stop with a
BatchStatus of COMPLETED and an
ExitStatus of "COMPLETED" and step3 will not
execute; otherwise, execution will move to step3. Note that if step2
fails, the Job will not be restartable (because
the status is COMPLETED).
<step id="step1" parent="s1" next="step2">
<step id="step2" parent="s2">
<end on="FAILED"/>
<next on="*" to="step3"/>
</step>
<step id="step3" parent="s3">The 'fail' element instructs a Job to
stop with a BatchStatus of FAILED. Unlike the
'end' element, the 'fail' element will not prevent the
Job from being restarted. The 'fail' element
also allows for an optional 'exit-code' attribute that can be used to
customize the ExitStatus of the
Job. If no 'exit-code' attribute is given, then
the ExitStatus will be "FAILED" by default, to
match the BatchStatus.
In the following scenario, if step2 fails, then the
Job will stop with a
BatchStatus of FAILED and an
ExitStatus of "EARLY TERMINATION" and step3
will not execute; otherwise, execution will move to step3.
Additionally, if step2 fails, and the Job is
restarted, then execution will begin again on step2.
<step id="step1" parent="s1" next="step2">
<step id="step2" parent="s2">
<fail on="FAILED" exit-code="EARLY TERMINATION"/>
<next on="*" to="step3"/>
</step>
<step id="step3" parent="s3">The 'stop' element instructs a Job to
stop with a BatchStatus of STOPPED. Stopping a
Job can provide a temporary break in processing
so that the operator can take some action before restarting the
Job. The 'stop' element requires a 'restart'
attribute that specifies the step where execution should pick up when
the Job is restarted.
In the following scenario, if step1 finishes with COMPLETE, then the job will then stop. Once it is restarted, execution will begin on step2.
<step id="step1" parent="s1">
<stop on="COMPLETED" restart="step2"/>
</step>
<step id="step2" parent="s2"/>In some situations, more information than the
ExitStatus may be required to decide which step
to execute next. In this case, a
JobExecutionDecider can be used to assist in the
decision.
public class MyDecider implements JobExecutionDecider {
public String decide(JobExecution jobExecution, StepExecution stepExecution) {
if (someCondition) {
return "FAILED";
}
else {
return "COMPLETED";
}
}
}In the job configuration, a "decision" tag will specify the decider to use as well as all of the transitions.
<job id="job">
<step id="step1" parent="s1" next="decision" />
<decision id="decision" decider="decider">
<next on="FAILED" to="step2" />
<next on="COMPLETED" to="step3" />
</decision>
<step id="step2" parent="s2" next="step3"/>
<step id="step3" parent="s3" />
</job>
<beans:bean id="decider" class="com.MyDecider"/>Every scenario described so far has involved a
Job that executes its
Steps one at a time in a linear fashion. In
addition to this typical style, the Spring Batch namespace also allows
for a job to be configured with parallel flows using the 'split'
element. As is seen below, the 'split' element contains one or more
'flow' elements, where entire separate flows can be defined. A 'split'
element may also contain any of the previously discussed transition
elements such as the 'next' attribute or the 'next', 'end', 'fail', or
'pause' elements.
<split id="split1" next="step4">
<flow>
<step id="step1" parent="s1" next="step2"/>
<step id="step2" parent="s2"/>
</flow>
<flow>
<step id="step3" parent="s3"/>
</flow>
</split>
<step id="step4" parent="s4"/>Both the XML and Flat File examples above use the Spring
Resource abstraction to obtain a file. This works
because Resource has a getFile
method, which returns a java.io.File. Both XML and
Flat File resources can be configured using standard Spring
constructs:
<bean id="flatFileItemReader"
class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource"
value="file://outputs/20070122.testStream.CustomerReportStep.TEMP.txt" />
</bean>The above Resource will load the file from
the file system location specified. Note that absolute locations have to
start with a double slash ("//"). In most spring applications, this
solution is good enough because the names of these are known at compile
time. However, in batch scenarios, the file name may need to be determined
at runtime as a parameter to the job. This could be solved using '-D'
parameters, i.e. a system property:
<bean id="flatFileItemReader"
class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="${input.file.name}" />
</bean>All that would be required for this solution to work would be a
system argument (-Dinput.file.name="file://file.txt"). (Note that although
a PropertyPlaceholderConfigurer can be used here,
it is not necessary if the system property is always set because the
ResourceEditor in Spring already filters and does
placeholder replacement on system properties.)
Often in a batch setting it is preferable to parameterize the file
name in the JobParameters of the
job, instead of through system properties, and access them that way. To
accomplish this, Spring Batch allows for the late binding of various Job
and Step attributes:
<bean id="flatFileItemReader" scope="step"
class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="#{jobParameters[input.file.name]}" />
</bean>Both the JobExecution and
StepExecution level
ExecutionContext can be accessed in the same
way:
<bean id="flatFileItemReader" scope="step"
class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="#{jobExecutionContext[input.file.name]}" />
</bean><bean id="flatFileItemReader" scope="step"
class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="#{stepExecutionContext[input.file.name]}" />
</bean>Any bean that uses late-binding must be declared with scope="step". See for Section 5.4.1, “Step Scope” more information.
All of the late binding examples from above have a scope of "step" declared on the bean definition:
<bean id="flatFileItemReader" scope="step"
class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="#{jobParameters[input.file.name]}" />
</bean>Using a scope of Step is required in order
to use late binding since the bean cannot actually be instantiated until
the Step starts, which allows the attributes to
be found. Because it is not part of the Spring container by default, it
must be added explicitly, either by using the batch
namespace:
<beans:beans xmlns="http://www.springframework.org/schema/beans"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="...">
...
</beans:beans>or by including a bean definition explicitly for
theStep (but not both):
<bean class="org.springframework.batch.core.scope.StepScope" />