
The Spring Batch 2.0 release has six major themes:
Java 5
Non Sequential Step Execution
Chunk oriented processing
Meta Data enhancements
Scalability
Configuration
The 1.x releases of Spring Batch were all based on Java 1.4. This
prevented the framework from using many enhancements provided in Java 5
such as generics, parameterized types, etc. The entire framework has been
updated to utilize these features. As a result, Java
1.4 is no longer supported. Most of the interfaces developers
work with have been updated to support generic types. As an example, the
ItemReader interface from 1.1 is below:
public interface ItemReader {
Object read() throws Exception;
void mark() throws MarkFailedException;
void reset() throws ResetFailedException;
}As you can see, the read method returns an
Object. The 2.0 version is below:
public interface ItemReader<T> {
T read() throws Exception, UnexpectedInputException, ParseException;
}As you can see, ItemReader now supports the
generic type, T, which is returned from read. You
may also notice that mark and
reset have been removed. This is due to step
processing strategy changes, which are discussed below. Many other
interfaces have been similarly updated.
Previously, the default processing strategy provided by Spring Batch was item-oriented processing:
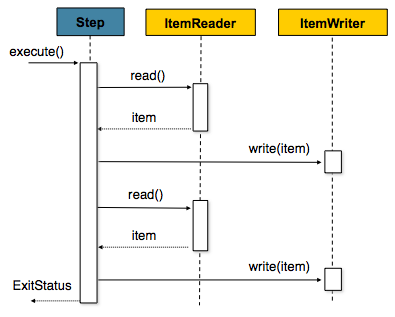 |
In item-oriented processing, the ItemReader
returns one Object (the 'item') which is then
handed to the ItemWriter, periodically committing
when the number of items hits the commit interval. For example, if the
commit interval is 5, ItemReader and
ItemWriter will each be called 5 times. This is
illustrated in a simplified code example below:
for(int i = 0; i < commitInterval; i++){
Object item = itemReader.read();
itemWriter.write(item);
}Both the ItemReader and
ItemWriter interfaces were completely geared toward
this approach:
public interface ItemReader {
Object read() throws Exception;
void mark() throws MarkFailedException;
void reset() throws ResetFailedException;
}public interface ItemWriter {
void write(Object item) throws Exception;
void flush() throws FlushFailedException;
void clear() throws ClearFailedException;
}Because the 'scope' of the processing was one item, supporting
rollback scenarios required additional methods, which is what
mark, reset,
flush, and clear
provided. If, after successfully reading and writing 2 items, the third
has an error while writing, the transaction would need to be rolled back.
In this case, the clear method on the writer
would be called, indicating that it should clear
its buffer, and reset would be called on the
ItemReader, indicating that it should return back
to the last position it was at when mark was
called. (Both mark and
flush are called on commit)
In 2.0, this strategy has been changed to a chunk-oriented approach:
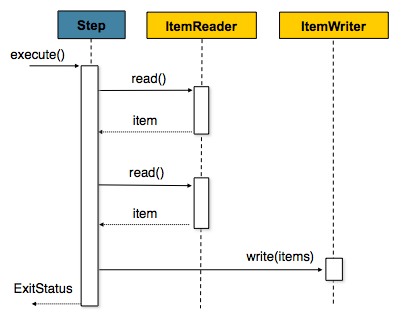 |
Using the same example from above, if the commit interval is five, read will be called 5 times, and write once. The items read will be aggregated into a list, that will ultimately be written out, as the simplified example below illustrates:
List items = new Arraylist();
for(int i = 0; i < commitInterval; i++){
items.add(itemReader.read());
}
itemWriter.write(items);This approach not only allows for much simpler processing and
scalability approaches, it also makes the
ItemReader and ItemWriter
interfaces much cleaner:
public interface ItemReader<T> {
T read() throws Exception, UnexpectedInputException, ParseException;
}public interface ItemWriter<T> {
void write(List<? extends T> items) throws Exception;
}As you can see, the interfaces no longer contain the
mark, reset,
flush, and clear
methods. This makes the creation of readers and writers much more
straightforward for developers. In the case of
ItemReader, the interface is now forward-only. The
framework will buffer read items for developers in the case of rollback
(though there are exceptions if the underlying resource is transactional
see: Section 5.1.9.1, “Transactional Readers”).
ItemWriter is also simplified, since it gets the
entire 'chunk' of items at once, rather than one at a time, it can decide
to flush any resources (such as a file or hibernate session) before
returning control to the Step. More detailed
information on chunk-oriented processing can be found in Section 5.1, “Chunk-Oriented Processing”. Reader and writer implementation
information can be found in Chapter 6, ItemReaders and ItemWriters.
Previously, Steps had only two
dependencies, ItemReader and
ItemWriter:
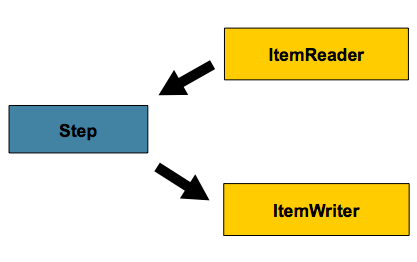
The basic configuration above is fairly robust. However, there are many cases where the item needs to be transformed before writing. In 1.x this can be achieved using the composite pattern:
This approach works. However, it requires an extra layer between
either the reader or the writer and the Step.
Furthermore, the ItemWriter would need to be
registered separately as an ItemStream with the
Step. For this reason, the
ItemTransfomer was renamed to
ItemProcessor and moved up to the same level as
ItemReader and
ItemWriter:
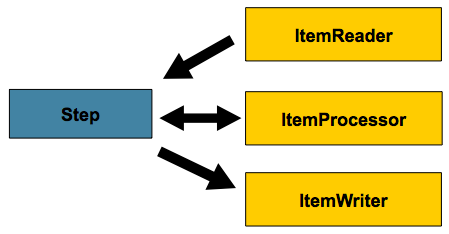
Until 2.0, the only option for configuring batch jobs has been normal spring bean configuration. However, in 2.0 there is a new namespace for configuration. For example, in 1.1, configuring a job looked like the following:
<bean id="footballJob"
class="org.springframework.batch.core.job.SimpleJob">
<property name="steps">
<list>
<!-- Step bean details ommitted for clarity -->
<bean id="playerload"/>
<bean id="gameLoad"/>
<bean id="playerSummarization"/>
</list>
</property>
<property name="jobRepository" ref="jobRepository" />
</bean>In 2.0, the equivalent would be:
<job id="footballJob">
<!-- Step bean details ommitted for clarity -->
<step id="playerload" next="gameLoad"/>
<step id="gameLoad" next="playerSummarization"/>
<step id="playerSummarization"/>
</job>More information on how to configure Jobs and Steps with the new namespace can be found in Chapter 4, Configuring and Running a Job, and Chapter 5, Configuring a Step.
The JobRepository interface represents basic
CRUD operations with Job meta-data. However, it may
also be useful to query the meta-data. For that reason, the
JobExplorer and JobOperator
interfaces have been created:
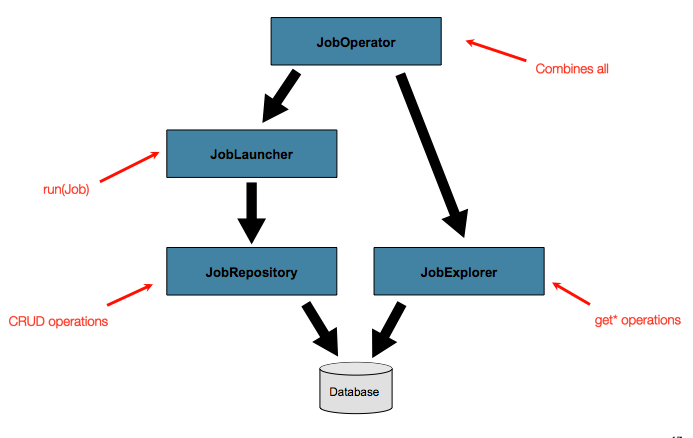
More information on the new meta data features can be found in Section 4.5, “Advanced Meta-Data Usage”. It is also worth noting that Jobs can now
be stopped via the database, removing the requirement to maintain a handle
to the JobExecution on the JVM the job was launched
in.
2.0 has also seen improvements in how steps can be configured. Rather than requiring that they solely be sequential:
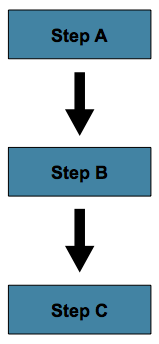
They may now be conditional:
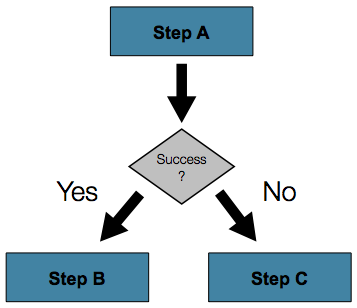
This new 'conditional flow' support is made easy to configure via the new namespace:
<job id="job">
<step id="stepA">
<next on="FAILED" to="stepB" />
<next on="*" to="stepC" />
</step>
<step id="stepB" next="stepC" />
<step id="stepC" />
</job>More details on how to configure non sequential steps can be found in Section 5.3, “Controlling Step Flow”.
Spring Batch 1.x was always intended as a single VM, possibly multi-threaded model, but many features were built into it that support parallel execution in multiple processes. Many projects have successfully implemented a scalable solution relying on the quality of service features of Spring Batch to ensure that processing only happens in the correct sequence. In 2.0 those features have been exposed more explicitly. There are two approaches to scalability: remote chunking, and partitioning.
Remote chunking is a technique for dividing up the work of a step without any explicit knowledge of the structure of the data. Any input source can be split up dynamically by reading it in a single process (as per normal in 1.x) and sending the items as a chunk to a remote worker process. The remote process implements a listener pattern, responding to the request, processing the data and sending an asynchronous reply. The transport for the request and reply has to be durable with guaranteed delivery and a single consumer, and those features are readily available with any JMS implementation. But Spring Batch is building the remote chunking feature on top of Spring Integration, therefore it is agnostic to the actual implementation of the message middleware. More details can be found in Section 7.3, “Remote Chunking”
Partitioning is an alternative approach which in contrast depends on having some knowledge of the structure of the input data, like a range of primary keys, or the name of a file to process. The advantage of this model is that the processors of each element in a partition can act as if they are a single step in a normal Spring Batch job. They don't have to implement any special or new patterns, which makes them easy to configure and test. Partitioning in principle is more scalable than remote chunking because there is no serialization bottleneck arising from reading all the input data in one place.
In Spring Batch 2.0 partitioning is supported by two interfaces:
PartitionHandler and
StepExecutionSplitter. The
PartitionHandler is the one that knows about the
execution fabric - it has to transmit requests to remote steps and
collect the results using whatever grid or remoting technology is
available. PartitionHandler is an SPI, and Spring
Batch provides one implementation out of the box for local execution
through a TaskExecutor. This will be useful
immediately when parallel processing of heavily IO bound tasks is
required, since in those cases remote execution only complicates the
deployment and doesn't necessarily help much with the performance. Other
implementations will be specific to the execution fabric. (e.g. one of
the grid providers such as IBM, Oracle, Terracotta, Appistry etc.),
Spring Batch makes no preference for any of grid provider over another.
More details can be found in Section 7.4, “Partitioning”