Squid has evolved in many ways with additional features to enhance the neighbour selection algorithm described above. Most of these features have been suggested by the user community. In this section we describe the configuration file directives that are relevant to hierarchical caching and the neighbour selection algorithm.
After each option we indicate in parentheses the Squid version where it first appeared. As of late August 1997 the most recent Squid release is version 1.1.15.
In most situations, there will be some set of servers which are ``local'' to the Web cache. Because these servers are nearby, we should contact them directly instead of forwarding the request to another cache. Squid allows you to configure local servers by domain name to avoid sending their requests up the cache hierarchy. For example:
local_domain sample.com
Squid checks the hostname part of requested URLs. If the hostname
ends with sample.com, Squid forwards the request directly
to the origin server. All of these URLs would match the above
specification:
http://www.sample.com/
http://ftp.uk.sample.com/
http://sample.com/foo
However, these URLs would not match:
http://www.freesample.com/
http://www.nlanr.net/stats/sample.com/
Also note that if the URL had the IP address for sample.com instead
of the domain name, it would NOT match. The local_ip option, described below,
can be used for this latter case.
You may specify multiple domains on one configuration line, or multiple configuration lines:
local_domain foo1.com foo2.com foo3.com
local_domain bar1.com
local_domain bar2.com
local_domain bar3.com
Cache administrators often do not want to cache the objects from local servers. The local_domain directive does not prevent this caching; you need to use the cache_stoplist directive instead.
In some situations it might be easier to specify local servers by IP address instead of domain name, which Squid supports with the local_ip directive. local_ip works for both IP addresses and domain names in requested URLs.
One drawback to local_ip is that Squid must look up the IP address before deciding if a given request is local or not, which adds the DNS lookup delay to the request processing. Thus we must recommend the use of the local_domain directive whenever possible. Of course, if you really need need to catch the case when the URL in question uses an IP address, then you should use local_ip as well. These two directives may be used together; not just one or the other.
There are three basic ways to specify IP address values. First, zeros can be used to indicate the wildcard octets of a network. For example:
local_ip 10.0.0.0
local_ip 172.16.0.0
local_ip 192.1.2.0
local_ip 10.7.7.0
local_ip 172.16.1.1
Note that we do not assume classful IP addresses. If all
octets are nonzero, then it specifies a single IP address.
The second way is with CIDR prefix notation. For example,
the above lines may be equivalently written as:
local_ip 10.0.0.0/8
local_ip 172.16.0.0/16
local_ip 192.1.2.0/24
local_ip 10.7.7.0/24
local_ip 172.16.1.1/32
Of course the CIDR notation allows more flexibility, because you can
specify any prefix length, not just 8, 16, 24 or 32.
Finally, the more traditional netmask notation is accepted as well:
local_ip 10.0.0.0/255.0.0.0
local_ip 172.16.0.0/255.255.0.0
local_ip 192.1.2.0/255.255.255.0
local_ip 10.7.7.0/255.255.255.0
local_ip 172.16.1.1/255.255.255.255
The local_ip addresses can be preceded with a `!' to negate the meaning. For example,
local_ip 10.0.0.0/8
means that any address in the 10.0.0.0 network is local, and
local_ip !10.0.0.0/8
means that every address is local, EXCEPT those in the 10.0.0.0
network. This is most often useful when a more-specific subset of a
network is not local. Such as:
local_ip !172.16.4.4 172.16.0.0
Often, it will be necessary to restrict the requests sent to neighbour caches. In other words, we want to force some requests to certain neighbours, and/or prevent requests to certain other neighbours. One motivation might be to distribute load among a set of neighbours. We can specify which domains a given cache can handle with the cache_host_domain directive. This directive is not required, so by default Squid assumes that a neighbour cache can handle all requests.
As an example, consider four cooperating
caches, which we will abbreviate as cache1 through cache4
(Normally we would use fully qualified domain names).
These caches are dedicated to caching URLs in the .au top-level
domain, but rather than all caches holding all objects, they have
been partitioned.
cache1 holds net.au URLs,
cache2 holds com.au URLs,
cache3 holds edu.au URLs,
and cache4 holds all the other URLs in the .au domain.
Now, if we need to configure a cache that will act as a child of this cluster of four, we would specify the partitioning as follows:
cache_host_domain cache1 net.au
cache_host_domain cache2 com.au
cache_host_domain cache3 edu.au
cache_host_domain cache4 !net.au !com.au !edu.au au
Note that we can either list the domains in a positive or negative manner. Preceding a domain with `!' means that the querying cache can NOT use the specified cache for the corresponding domain.
Squid searches the domain list in the order give, and stops searching as soon as it finds a match, or reaches the end of the list. For this reason, you must list more-specific domains before less-specific ones.
In some cases, simple domain-based restrictions may not be sufficient For example, what if you wanted to send HTTP requests to one neighbour and FTP requests to another?
You can also restrict neighbour caches based on Squid's general access control features. To accomplish the example above, we could specify it thusly in the config file:
acl FTP proto FTP
acl HTTP proto HTTP
cache_host_acl cache1 FTP
cache_host_acl cache2 HTTP
This configuration would cause Squid to send only FTP requests to
cache1 and only HTTP requests to cache2.
As with cache_host_domain, you can negate ACL elements:
cache_host_acl cache2.foo.net !FTP
which would send everything except FTP requests to cache2.
Note that use of the ACLs might cause additional delays. Some of the ACL types require forward or reverse DNS lookups.
Routing by domain name suffers from a couple of problems:
These reasons motivated the query_icmp feature in Squid and ICP. Each cache keeps a table of ICMP round trip time (RTT) measurements to the origin servers. The measured values can be returned in the ICP reply messages. Squid uses the RTT values to select the neighbour which is ``closest'' to the origin server. If the local cache itself is closest, then the request is forwarded directly to the origin server.
This feature is not enabled by default and requires the cooperation of both parties in a peering relationship. First of all, your neighbour caches need to be configured to make ICMP measurements. They will return these measurements in their ICP replies to your cache. Your cache will use the measurements to select the best neighbour.
To get Squid to make the ICMP measurements, Squid must be compiled with a special option. The USE_ICMP option must be enabled in src/Makefile, and then Squid recompiled. After Squid has been built, the pinger program must be installed with root privileges. pinger is responsible for sending and receiving the ICMP messages and relaying them to Squid. Unix systems require root privileges to send and receive ICMP, so we use an external process rather than make all of Squid run with superuser privileges. The commands below indicate the sequence of events required to enable this feature and install the pinger program. The Squid FAQ has more details on this procedure.
% vi src/Makefile
% make clean all
% make install
% su
# make install-pinger
Now that we have your neighbours collecting ICMP measurements, we must tell them to send them to you. To do this, enable the query_icmp option in your configuration file.
query_icmp on
There are two ways to see how this is working. You should see some requests logged as CLOSEST_PARENT_MISS in the access.log file. Also, if your Squid program is compiled with the USE_ICMP option, then you can view the Network Probe Database from the cache manager interface. This database will include both the measured ICMP RTTs from your cache and your neighbour caches.
When your Squid cache is making ICMP measurements, you can configure it to forward directly to origin servers which are estimated to be some small number of router-hops away. The minimum_direct_hops directive sets this value. Note that the hop-count estimation is not always perfect, but it should be safe to set this parameter to 4 or 5.
The proxy-only option appears on a cache_host line, and specifies that Squid should not save a local copy of any object retrieved from that cache. This feature is often useful in a cluster of sibling caches to prevent each cache from holding every object. When the caches are close to each other (e.g. on the same ethernet segment), then it costs relatively little to transfer an object from one to the other. Specify this option with:
cache_host cache1 sibling 3128 3130 proxy-only
cache_host cache2 sibling 3128 3130 proxy-only
There is no requirement that one use proxy-only exclusively with sibling caches; it also works fine for a parent cache.
Note that the proxy-only feature can generate some confusing error messages for some versions of Squid. When Squid initiates a transfer from a neighbour with the proxy-only option set, Squid puts the object into ``delete behind'' mode. That is, Squid deletes the data as it is delivered to the client. If the user aborts the transfer before it completes, Squid will log the error message:
ERR_NO_CLIENT_BIG_OBJ: http://www.nlanr.net/
As of Squid v1.1.11, this error message will no longer appear
for proxy-only requests.
The description for proxy-only above alludes to creating a larger, distributed cache from a cluster of caches with sibling relationships. The proxy-only option makes sure that an object is stored in only one of the caches. However, its not quite that simple.
Recall that an ICP_HIT reply indicates that a subsequent HTTP request from the querying cache would result in a cache hit. This feature is critical for siblings because if the HTTP request turns out to be a cache miss, we would be violating the sibling relationship. For this reason, we only return ICP_HIT if the object is cached and fresh. In fact, to be safe, we require that the object be fresh for the next 30 seconds. If the object will be stale soon, we return an ICP_MISS instead.
This procedure implies that the distributed cache idea will not work as we would like. Once an object becomes stale in one of the caches, a sibling cache will never be able to refresh the object because an ICP_MISS reply must be returned. This situation is unfortunate, since the distributed cache model was a primary early motivation for the sibling relationship. To have the distributed cache concept work, siblings must return ICP_HIT replies even for stale objects. Squid supports the capability with the icp_hit_stale configuration option:
icp_hit_stale on
Enabling this option allows your your sibling caches to refresh stale objects through your cache. In fact, it changes the peering relationship to be something between the strict sibling and parent definitions. If icp_hit_stale is enabled, you must NOT also use the miss_access feature.
The no-query option appears on a cache_host line and prevents Squid from sending ICP queries to a specified neighbour cache. It is most useful with the default or round-robin options, described below. An example configuration is:
cache_host cache1 parent 3128 3130 no-query default
Recall that in the basic neighbour selection algorithm, Squid uses a parent only if the parent sends it an ICP reply. This limits Squid in at least two situations:
The default option designates a parent cache as a default choice in the absence of other indications (such as ICP replies). For example:
cache_host cache1 parent 3128 3130 default
And if we did NOT want to use ICP at all, we would use:
cache_host cache1 parent 3128 3130 default no-query
Note that when searching for a default parent, the cache_host_domain restrictions still apply. Thus, it is not unreasonable to have multiple default parents, but it makes little sense to have a default sibling. Squid searches the neighbour caches in the order given in the configuration file, and uses the first parent with the default designation (if it passes the cache_host_domain restrictions).
The round-robin option is similar to default, except that Squid forwards the request to the parent with the lowest use count. The cache_host_domain restrictions still apply, of course. A typical configuration might look like:
cache_host cache1 parent 3128 3130 round-robin no-query
cache_host cache2 parent 3128 3130 round-robin no-query
cache_host cache3 parent 3128 3130 round-robin no-query
Squid treats all round-robin parents equally. It is not currently possible to, e.g., forward 25% of the requests to one parent and 75% to another.
Recall that the basic neighbour selection algorithm selects the FIRST_PARENT_MISS reply in the absence of any ICP_HIT replies. So with two parents, one close (low RTT), and the other far away (high RTT), Squid will typically use the close parent, although in certain situations this choice may not actually be optimal.
Squid allows you to balance this out a little bit by specifying weighting values for each parent. It does not make any sense to assign weights to a sibling (Do you know why?). Squid calculates the round-trip time between sending an ICP query and receiving the corresponding reply, and divides this RTT by the weighting factor. A higher weight will artificially lower the calculated RTT between peers, thereby favoring it in the selection algorithm. You specify weights as follows:
cache_host cache1 parent 3128 3130 weight=10
cache_host cache2 parent 3128 3130 weight=4
cache_host cache3 parent 3128 3130 weight=1
When all your parent caches have similar (unweighted) round-trip times, this feature gives you the ability to increase the chance of selecting one peer over the others, simply by giving it a higher weight. Some people use this option to configure a primary parent and a backup parent.
In describing the basic neighbour selection algorithm we referred to a two second timeout. The actual value is configurable with the neighbour_timeout directive. If you have a high latency link and want to use ICP across it, you may want to increase this value. However, in that case we would probably recommend NOT using ICP at all. To increase the timeout to four seconds, you would write:
neighbour_timeout 4
Firewalls present some interesting problems for Web caches. The cache must be able to figure out if a given server is inside or outside of the firewall. Squid has two options to configure this. inside_firewall is a list of DNS domains which are inside of the firewall (and can be contacted directly if needed). All other domains are assumed to be outside of the firewall and therefore only reachable by forwarding the request to a parent cache.
As with the cache_host_domain directive, the `!' negation operator may precede a domain name, and more-specific domains should be specified first.
Please keep in mind that this directive is used for caches behind a firewall. If the cache is on the firewall then it should be able to directly connect to external systems, and firewall configuration lines should be unnecessary.
A sample configuration is:
inside firewall !extern.sample.com sample.com
Why do we need to specify extern.sample.com? Because otherwise
Squid will think it is inside the firewall and able to
connect to it directly. Squid assumes that any domain not matching the
inside_firewall list is outside the firewall.
The special keyword none can be used in place of a domain name:
inside_firewall none
means that all hosts are outside of the firewall and must be requested
via a neighbour cache.
People will often make use of the inside_firewall directive when there is really not a firewall in place. They want to force all requests to go through a parent cache, and never to make direct connections to origin servers. To make matters worse, Squid has not been designed to be very persistent in forwarding requests. Squid likes to choose a single, best server to send the request to, and it will try that server only once. If the connection or request fails for some reason, Squid returns an error message.
This behavior can be particularly frustrating with firewall configurations. If Squid thinks all of its neighbours are down, or fails to receive any ICP replies, it will return a message saying that it is unable to satisfy the request. When the administrator goes to check things out, it usually works just fine, thereby increasing the frustration. We are addressing this significant deficiency for the upcoming version of Squid.
It is also possible to specify a set of IP addresses inside the firewall with the firewall_ip option. As with the local_ip option, this normally requires an IP address lookup before forwarding the request, so inside_firewall is preferred. The IP address specifications here are exactly the same as for local_ip, including the ability to precede an address with `!' to indicate it is outside the firewall.
Note that the firewall_ip list must be exhaustive. That is, if a given address matches the firewall_ip list, then it is inside the firewall, otherwise it is outside.
The hierarchy_stoplist allows you to specify URLs that Squid should never forward to neighbour caches, if possible (the firewall directives take precedence). It is somewhat similar in function to local_domain, however, it applies to the URL as a whole. The hierarchy_stoplist is simply a list of strings which we check for in URLs.
It makes sense that we should only use the cache hierarchy for requests likely to result in cache hits. To reduce the load placed on parent caches, if we can identify requests that we know will not result in a cache hit, we should prevent forwarding them to parents.
The default Squid configuration file sets the hierarchy_stoplist to
hierarchy_stoplist cgi-bin ?
That is, cgi-bin and query requests (indicated by the question mark)
are unlikely to ever result in a cache hit. Some may want to change
cgi-bin to simply cgi to catch even more of those nasty CGI
programs.
Normally the parent or sibling relationship applies to the neighbour cache as a whole. However, some hierarchical configurations need to define the relationship at a finer granularity. Consider, for example, a top-level cache for the country of Germany, intended as a service to two groups:
.de domain, since any .de request can be
forwarded to it.
In addition to accepting all .de requests from external caches,
the German cache is also willing to serve any cache hits (but not misses)
to anyone. This latter description defines the sibling relationship.
What we need, therefore,
is the ability to have a parent relationship for some requests,
and a sibling relationship for others.
The neighbour_type_domain directive fills this need:
cache_host sibling cache.foonet.de 3128 3130
neighbour_type_domain cache.foonet.de parent de
Now we will treat cache.foonet.de as a sibling for most requests,
and as a parent for .de requests. You probably only need to
specify the domains when the relationship is the opposite of
the default. Of course it is also possible to have a
parent relationship by default, and a sibling relationship
for specific domains:
cache_host parent cache.sample.com 3128 3130
neighbour_type_domain cache.sample.com sibling .com .net
neighbour_type_domain cache.sample.com sibling .au .de
The effect here is that when we receive an ICP_MISS from
cache.sample.com, we would never forward the request there
if the origin server is in the
com,
net,
au,
or de domains. However, we can forward requests
for URLs in any other domains to cache.sample.com because
it would be considered a parent cache.
Note that an ICP query does not include any parent or sibling designation, so the receiver really has no indication of how the peer cache is configured to use it. This issue becomes important when a cache is willing to serve cache hits to anyone, but only handle cache misses for its own customers. In other words, whether to allow the request or not depends on if the result is a hit or a miss. By default Squid does not deny the request based on the hit/miss status. We added the miss_access directive to support this type of access control.
In addition to being a somewhat awkward to implement, miss access brings its own complication: it requires that the ICP reply be an extremely accurate prediction of the result of a subsequent HTTP request. This prediction is challenging because the ICP query cannot convey the full HTTP request. Additionally, there are more types of HTTP request results than there are for ICP. The ICP reply will either be a hit or miss, but an HTTP request might result in a Not Modified reply from the origin server. Such a reply is not strictly a hit since the peer needed to forward a conditional request to the source. At the same time, its not strictly a miss either since the local object data is still valid, and the Not Modified reply from the origin server is quite small.
To use the miss_access feature, you first must define a set of ACL elements, and then combine them on the miss_access lines with allow or deny designations:
acl Browsers src 10.0.0.0/8
acl Kids 172.16.0.0/16
miss_access allow Browsers
miss_access allow Kids
miss_access deny all
In this simple example, all of our end users (Browsers) are
on one network (10.0.0.0), and we also have some child caches
on another network (172.16.0.0). Of course we allow end users
to make any request, since the cache is really for them.
Similarly, child caches are all allowed to make any request,
including cache misses. However, no one else may request
cache misses.
Note that you only need to use miss_access if some other cache is using yours as a sibling. Any request to your cache must first pass the normal http_access controls, and unless you are someone's sibling, there is absolutely no reason to allow cache hits and deny cache misses. If Squid denies a request for failure to pass the miss_access controls, the end user is shown an error message.
A rather serious problem arises when sibling caches use miss_access and have differing refresh_pattern rules. Again, the fundamental problem is that an ICP query cannot fully express the HTTP request, specifically the Cache-Control parameters. Without those parameters, we cannot accurately predict the hit/miss status in the ICP reply. Occasionally a sibling cache will return ICP_HIT, but the following HTTP request will be a cache miss due to the Cache-Control headers. If miss_access is enabled, Squid generates the miss_access error message, which will make no sense to either the cache administrator or the end user. If miss_access is NOT used, then the sibling cache will forward the request on, which strictly speaking, is a violation of the sibling relationship. How frequently this violation occurs depends on the extent to which the refresh rules differ.
For reasons of backward compatibility, we have not changed the ICP message format to fix this problem. We feel that the best solution to this problem is to configure both siblings with identical refresh parameters. Otherwise, we would recommend against the use of miss_access.
Squid also allows the origin server to be included in the selection algorithm. This is accomplished by sending an ICP_SECHO message to the echo service of the origin server. The SECHO reply is treated like an ICP_HIT in the selection algorithm. Thus, when the origin server is closer than any of the neighbour caches, the SECHO reply will be received first, and the request will be forwarded there directly.
Unfortunately, this feature is often unusable because system administrators have disabled their UDP echo service, or even worse, they log the echo packets, track down the source, and interrogate the responsible party. This became a real problem after CERT issued some warnings regarding denial-of-service attacks to the UDP echo port. Nonetheless, this feature remains available, and to enable it, the configuration file should include:
source_ping on
An alternative to UDP echo is to use ICMP instead. When Squid is compiled with USE_ICMP (described above for query_icmp), then ICMP will be used for source ping messages. The only change is that we sneak these messages in as ICMP where they are less likely to be noticed.
This option skips the ICP query when the only neighbour to which a request could be forwarded is a parent cache. It is very likely that the ICP reply will be either ICP_HIT or ICP_MISS, both of which would result in selecting that parent. If there are sibling caches involved, then the single_parent_bypass setting does not come into effect. The functionality of this option has been superseded by the no-query and default options, so it is rarely used. To enable this option:
single_parent_bypass on
Squid allows non-ICP caches (e.g. CERN) to be included in the basic neighbour selection algorithm. Rather than sending ICP query messages, we instead send the special ICP_DECHO message to the UDP echo port of the neighbour cache. The DECHO reply is treated as an ICP_MISS in the selection algorithm.
There are three problems with this feature. First, we must treat the reply as a miss because the neighbour cache does not support ICP. The reply is primarily used to indicate the state of the path between the pair of caches. Second, we are sending to the host's echo service. This really only tells us that the host is up, and not that the cache application is necessarily running. Finally, as described above, paranoid system administrators often disable UDP echo on their hosts, making this technique unusable.
To use this feature, simply specify the ICP port as 7 in a cache_host line:
cache_host cache.sample.com parent 8080 7
Note that it does not make any sense to have a non-ICP sibling cache.
(Do you know why?)
Recent versions of Squid support sending ICP queries via multicast. This feature also requires the cooperation of both you and your neighbour cache administrators. You must configure your cache to send multicast queries and your neighbour must configure theirs to receive them.
Multicast, although it sounds promising, may not be a good idea for everyone. First of all, you need multicast connectivity to your peers, typically meaning an Mbone tunnel to your site. The best way to test your mbone connectivity is with the mtrace program, which is available from the Xerox PARC FTP site.
The primary advantage to multicast is that it can reduce the number of times an ICP packet traverses a single path. The primary disadvantage is that the Mbone infrastructure is sometimes unstable. If a tunnel goes down, you may find that your neighbour caches are not being utilized.
You should be a little bit careful when selecting a multicast group address and TTL parameters. Note that there are no special privileges required to join a multicast group, so anyone can join and ``snoop'' on your ICP messages. Also, multicast packets are routed based on address, not port number. This means that if you happen to choose an address already in use by a different application, your ICP packets will be sent to the hosts running the other application, and their packets will be sent to your host. There are two good ways to limit the scope of multicast traffic. The simplest is with TTLs, and the other is known as administrative scoping. The multicast TTL scheme is too complex to go into here, but mtrace can tell you the minimum required TTL needed between a source and destination. We also recommend you use administrative scoping if possible. For details see the mrouted manual page, or your router (probably Cisco) documentation. Also, NLANR has been delegated a block of multicast address for use exclusively by Web caching applications. If you would like to use one of these addresses, just let us know.
To configure Squid to send ICP queries to a multicast address, you need to create another neighbour cache entry specified as multicast. For example:
cache_host 224.9.9.9 multicast 3128 3130 ttl=64
224.9.9.9 is a sample multicast group address; DNS names may be used
here as well if available. multicast indicates that this
is a special type of neighbour. The HTTP-port argument (3128)
is ignored for multicast peers, but the ICP-port (3130) is
very important. The final argument, ttl=64
specifies the multicast TTL value for queries sent to this
address.
It is probably a good
idea to increment the minimum TTL by a few to provide a margin
for error and changing conditions.
Your neighbours will need to be configured to receive your multicast queries. To accomplish this, they must listen for packets on the multicast group address by using the mcast_groups configuration directive.
mcast_groups 224.9.9.9
You must also specify which of your neighbours will respond to your multicast queries, since it would be a bad idea to implicitly trust any ICP reply from an unknown address. Note that ICP replies are sent back to unicast addresses; they are NOT multicast, so Squid has no indication whether a reply is from a regular query or a multicast query. To configure your multicast group neighbours, use the cache_host directive and the multicast-responder option:
cache_host cache1 sibling 3128 3130 multicast-responder
cache_host cache2 sibling 3128 3130 multicast-responder
Here all fields are relevant. The ICP port number (3130)
must be the same as in the cache_host line defining the
multicast peer above. The third field must either be
parent or sibling to indicate how Squid should treat replies.
With the multicast-responder flag set for a peer,
Squid will NOT send ICP queries to it directly (i.e. unicast).
Recall that in the basic neighbour selection algorithm, Squid waits for all ICP replies to arrive before forwarding the request. This characteristic in problematic for multicast since we send only one query and receive numerous replies. If Squid overestimates the number of replies it will receive, then it will often suffer the two second timeout. If Squid underestimates the number of replies, then it will underutilize its neighbours.
Squid periodically (every 15 minutes) sends out a bogus ICP query to its multicast peers, and tallies the number of replies received before the two second timeout. Squid averages the number of replies with a decay factor so that it adjusts fairly quickly to changing conditions. When waiting for replies to arrive after a normal query, Squid always rounds down the average to the nearest integer value. This counting process is logged in cache.log with lines like:
97/08/07 13:59:36| Group nlanr.mcast.ircache.net: 6 replies, 6.0 average 97/08/07 14:14:36| Group nlanr.mcast.ircache.net: 5 replies, 5.5 average 97/08/07 14:29:36| Group nlanr.mcast.ircache.net: 4 replies, 5.0 average
The ICP_HIT_OBJ feature was added as another way to reduce latency in cache transfers. Many Web objects are relatively small. For the NLANR caches, the median object size is approximately 3750 bytes. It's an appealing thought to just piggyback such small documents on ICP_HIT replies, thereby avoiding the need for a subsequent TCP connection and HTTP request. We were initially very excited about this feature, but then some problems began to appear.
The fundamental problem is that the ICP query does not convey as much information as an HTTP request. Certain important headers, such as If-Modified-Since and Max-Age, are not present in the ICP query, which may lead to an ICP_HIT_OBJ reply returning stale data. The ICP query also will not include authentication or identification (i.e. ``cookie'') headers, which may affect the reply. For these reasons we generally do not recommend use of ICP_HIT_OBJ, and Squid disables it by default.
Prior to Squid v1.0.13, ICP_HIT_OBJ was always enabled. To enable receipt of ICP_HIT_OBJ replies in later versions, use the udp_hit_obj configuration option:
udp_hit_obj on
By default, Squid will send an ICP_HIT_OBJ reply, including the requested object content, if the object will fit into the single UDP reply packet. For most systems the maximum UDP packet size is 12 Kbytes or larger, so an ICP_HIT_OBJ reply can occasionally result in some fairly large UDP packets, which may be undesirable. If the cache administrator prefers the limit the size of the of the ICP_HIT_OBJ message (i.e. the UDP packet), he can specify the maximum allowed ICP packet size with the udp_hit_obj_size directive (added in v1.1.4). Remember that the ICP message also includes the 20-octet ICP header and a NULL-terminated URL string. To limit ICP_HIT_OBJ messages to 4 Kbytes, for example:
udp_hit_obj_size 4096
If you wanted to never send any ICP_HIT_OBJ messages, you could
specify a very low, but non-zero value here, for example:
udp_hit_obj_size 1
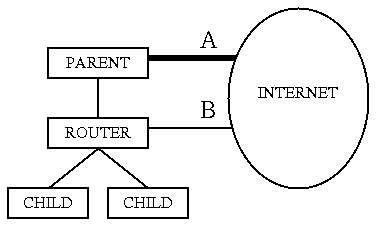
UDP transport allows ICP to gracefully accommodate network failures, albeit only for failures between a pair of peers. Network failures have also been known to occur between the parent and the rest of the Internet. Consider figure 1 which shows a pair of child caches which have two ways to reach the global Internet, via either link A, or link B. Assume that link A is faster and therefore preferred over B. To make use of link A, the child caches are configured to use a parent cache which routes its traffic over that link.
What happens when link A goes down? The child caches still have good connectivity to the parent, and will therefore receive ICP_HIT or ICP_MISS replies as usual. However, the parent cache will be unable to satisfy any miss requests because its path to the Internet is down. The users of the child caches will get many ``connection failed'' error messages, even though they have an alternate way of reaching the Internet.
Squid keeps track of its failed requests to cope with this problem. When the ratio of failed to successful requests exceeds a threshold (i.e. 1) then Squid returns ICP_MISS_NOFETCH instead of ICP_MISS replies. This feature allows a parent cache to continue serving hits, but take itself out of the peer selection process for misses.