

![[Index]](../../../../a_stock/images/btn_index.gif)
![]()
![[Previous]](../../../../a_stock/images/btn_prev_top.gif)
![[Next]](../../../../a_stock/images/btn_next_top.gif)
|
|
|
|
|
|
||
|
|
3.2 Batch INSERT, UPDATE, and DELETE Operations Using TEMP Tables
3.6 Put Smaller and Frequently Accessed Columns at the Beginning of Tables
3.7 Consider Storing Large BLOBs Separately from the Database
3.9 Create Indexes Automatically Using PRIMARY KEY and UNIQUE
3.11 Use Small Positive Integers for INTEGER PRIMARY KEY or RowID
3.12 Used Indexed Column Names, not Expressions, in WHERE Clauses
3.20 Resolve Indexing Ambiguities Using the Unary “+” Operator
3.30 Avoid Tables and Indexes with an Excessive Number of Columns
|
|
This document describes techniques for making more efficient use of Symbian’s SQL relational database component. Anyone writing software using Symbian SQL who wants to make their software as fast and memory efficient as possible will benefit from the study of this document.
Section 2 of this document provides background information on the internal workings of SQLite, the database engine used by Symbian SQL. This background information is important for understanding the material of the following section. Readers are advised to study this carefully before proceeding.
Section 3 is an unordered collection of rules of thumb for making efficient use of SQLite. Each rule describes a technique for increasing the speed and efficiency of SQLite. Each entry in this collection strives to stand on its own and be independent of the others. Hence, you can read bits and pieces here and there as your needs and interests dictate.
The document assumes that the reader is already familiar with the SQL query language and with the Symbian SQL API.
|
|
The figure below shows the major modules within SQLite. SQL statements that are to be processed are sent to the SQL Compiler module which does a syntactic and semantic analysis of the SQL statements and generates bytecode for carrying out the work of each statement. The generated bytecode is then handed over to a Virtual Machine for evaluation.
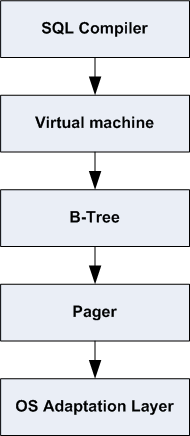
Simplified SQLite Architecture
The Virtual Machine considers the database to be a set of B-Trees, one B-Tree for each table and one B-Tree for each index. The logic for creating, reading, writing, updating, balancing and destroying B-Trees is contained in the B-Tree module.
The B-Tree module uses the Pager module to access individual pages of the database file. The Pager module abstracts the database file into zero or more fixed-sized pages with atomic commit and rollback semantics.
All interaction with the underlying filesystem and operating system occurs through the OS Adaptation Layer.
A key to understanding the operation of SQLite, or any other SQL relational database engine, is to recognize that each statement of SQL is really a small computer program.
Users of SQL database engines sometimes fail to grasp this simple truth because SQL is a peculiar programming language. In most other computer languages the programmer must specify exactly how a computation is to take place. But in SQL the programmer specifies what results are needed and lets the SQL Compiler worry about how to achieve them.
All SQL database engines contain a SQL Compiler of some kind. The job of this compiler is to convert SQL statements into procedural programs for obtaining the desired result. Most SQL database engines translate SQL statements into tree structures. The Virtual Machine modules of these databases then walk these tree structures to evaluate the SQL statements. A few SQL database engines translate SQL statements into native machine code.
SQLite takes an intermediate approach and translates SQL statements into small programs written in a bytecode language. The SQLite bytecode is similar in concept to Java bytecode, the parrot bytecode of Perl, or to the p-code of the UCSD Pascal implementation. SQLite bytecode consists of operators that work with values contained in registers or on a stack. Typical bytecode operators do things like:
Push a literal value onto the stack
Pop two numbers off of the stack, add them together and push the result back onto the stack
Move the top element of the stack into a specific memory register
Jump to a specific instruction if the top element of the stack is zero
The SQLite bytecode supports about 125 different opcodes. There is a remarkable resemblance between SQLite bytecode and assembly language. The major difference is that SQLite bytecode contains a few specialized opcodes designed to facilitate database operations that commonly occur in SQL.
Just as you do not need to understand the details of x86 or ARM7 assembly language in order to make effective use of C++, so also you do not need to know any of the details of SQLite bytecode in order to make the best use of SQLite. The reader need only recognize that the bytecode is there and is being used behind the scenes.
Those who are interested can peruse the definitions of the bytecodes in the SQLite documentation. But the details of the various bytecodes are not important to making optimal use of SQLite and so no further details on the bytecodes will be provided in this document.
A SQLite database file consists of one or more b-trees. Each table and each index is a separate b-tree.
A b-tree is a data structure discovered in 1970 by Rudolf Bayer and Edward McCreight and is widely used in the implementation of databases. B-trees provide an efficient means of organizing data stored on an external storage device with fixed-sized blocks, such as a disk drive or a flash memory card. Each entry in a b-tree has a unique key and arbitrary data. The entries are ordered by their key which permits efficient lookup using a binary search. The b-tree algorithm guarantees worst-case insert, update, and access times of O(log N) where N is the number of entries.
In SQLite, each table is a separate b-tree and each row of the table is a separate entry. The b-tree key is the RowID or INTEGER PRIMARY KEY for the row and other columns in the row are stored in the data for the b-tree entry. Tables use a variant of the b-tree algorithm call b+trees in which all data is stored on the leaves of the tree.
Indexes are also stored as b-trees with one entry in the b-tree for each row of the table being indexed. The b-tree key is composed of the values for the columns being indexed followed by the RowID of the corresponding row in the table. Indexes do not use the data part of the b-tree entry. Indexes use the original Bayer and McCreight b-tree algorithm, not b+trees as tables do.
The number of pages in a b-tree can grow and shrink as information is inserted and removed. When new information is inserted and the b-tree needs to grow, the B-Tree Module may reuse pages in the database that have fallen into disuse or it may ask the Pager module to allocate new pages at the end of the database file to accommodate this growth. When a b-tree shrinks and pages are no longer needed, the surplus pages are added to a free-list to be reused by future page requests. The B-Tree module takes care of managing this free-list of unused pages.
The Pager module (also called simply “the pager”) manages the reading and writing of raw data from the database file such that reads are always consistent and isolated and so that writes are atomic.
The pager treats the database file as a sequence of zero or more fixed-size pages. A typical page size might be 1024 bytes. Within a single database all pages are the same size. The first page of a database file is called page 1. The second is page 2. There is no page 0. SQLite uses a page number of 0 internally to mean “no such page”.
When the B-Tree module needs a page of data from the database file, it asks for the page by number from the pager. The pager then returns a pointer to the requested data. The pager keeps a cache of recently accessed database pages so in many cases no disk I/O has to occur to fulfil a page request.
The B-Tree module notifies the pager before making any changes to a page and the pager then saves a copy of the original page content in a rollback journal file. The rollback journal is used to restore the database to its original state if a ROLLBACK occurs.
After making changes to one or more pages, the B-Tree Module may ask the pager to commit those changes. The pager then goes through a carefully designed sequence of steps that ensure that changes to the database are atomic. If the update process is interrupted by a program crash, a system crash, or even a power failure, the next time the database is accessed it will appear that either all the changes were made or else none of them.
A SQLite database file consists of one or more fixed-sized pages. The first page contains a 100-byte header that identifies the file as a SQLite database and which contains operating parameters such as the page size, a file format version number, the first page of the free-list, flags indicating whether or not autovacuum is enabled, and so forth.
The content of the database is stored in one or more b-trees. Each b-tree has root page which never moves. If the table or index is small enough to fit entirely on the root page, then that one page contains everything there is to know about the table or index. But most tables and indexes require more space and additional pages must be allocated.
The root page contains pointers (actually page numbers) to the other pages in the b-tree. So given the root page of a b-tree that implements a table or index, the B-Tree module is able to follow pointers to locate any entry in the b-tree and thus any row in the corresponding table or index.
Note that auxiliary pages of a b-tree can be allocated from anywhere within the database file and so the pages numbers of auxiliary pages will change as information is added and removed from the b-tree. But the root page never moves. When a new table or index is created, its root page is assigned and remains unchanged for the lifetime of the table or index.
Every SQLite database contains a master table which stores the database schema. Each row of the master table holds information about a single table, index, view or trigger, including the original CREATE statement that created that table, index, view or trigger. Rows that define tables and indexes also record the root page number for the b-tree that stores the table or index. The root page of the master table is always page 1 of the database file, so SQLite always knows how to locate it. And from the master table it can learn the root page of every other table and index in the database and thus locate any information in the database.
This is what happens inside SQLite during a typical usage scenario: When the SQL server instructs SQLite to open a database, the SQLite library allocates a data structure to hold everything it will ever need to know about that database connection. It also asks the pager to open the database file, but does not immediately try to read anything or even verify that the file is a valid database.
The first time you actually try to access the database, SQLite will look at the 100-byte header of the database file to verify that the file is a SQLite database and to extract operating parameters such as the database page size.
After checking the header SQLite opens and reads the entire master table. Recall that the master table contains entries for every table, index, view and trigger in the database and that each entry includes the complete text of the CREATE statement that originally created the table, index, view or trigger.
SQLite parses these CREATE statements in order to rebuild an internal symbol table holding the names and properties of all tables, indexes, triggers and views in the database schema.
Among the values stored in the header of the database is a 32-bit schema cookie. The schema cookie is changed whenever the database schema is modified by creating or dropping a table, index, trigger, or view.
When SQLite parses the database schema into its internal symbol table, it remembers the schema cookie. Thereafter, whenever SQLite goes to access the database file, it first compares the schema cookie that it read when it parsed the schema to the current schema cookie value.
If they match, everything continues normally, but if the schema cookie has changed that means that some other thread or process may have modified the database schema. When that happens, SQLite has to throw out its internal symbol table and reread and reparse the entire database schema in order to figure out what might have changed.
RSqlStatement’s
RSqlStatement::Prepare() API is used to interface with
SQLite’s SQL Compiler. The Prepare() API triggers
tokenizing, parsing, and compilation of a SQL statement into the internal
bytecode representation that is used by the Virtual Machine. The generated
bytecode is stored in an object returned by SQLite often referred to as a
prepared statement.
After compiling a SQL statement into a prepared statement you can
pass it to the Virtual Machine to be run. This is the job of
RSqlStatement’s
RSqlStatement::Next() and
RSqlStatement::Exec() APIs. These interfaces cause the
bytecode contained in the prepared statement to be run until it either
completes or until it hits a breakpoint.
A breakpoint is hit whenever a SELECT statement generates a row of result that needs to be returned. When a breakpoint is hit SQLite returns control to the caller.
The bytecode in a prepared statement object is such that whenever a breakpoint occurs, a single row of the result of a SELECT statement is contained on the stack of the Virtual Machine. At this point column accessor functions can be used to retrieve individual column values.
RSqlStatement:: Reset() can be called on a
prepared statement at any time. This rewinds the program counter of the Virtual
Machine back to the beginning and clears the stack, thus leaving the prepared
statement in a state where it is ready to start over again from the beginning.
RSqlStatement’s
RSqlStatement::Close() API is merely a destructor for the
prepared statement object. It calls Reset() to clear the virtual
machine stack if necessary, deallocates the generated bytecode, and frees the
container object.
Similarly, RSqlDatabase’s
Close() API is just a destructor for a server-side object created
by SQLite when the database was opened. SQLite asks the pager module to close
the database file, clears the symbol table, and deallocates all associated
memory.
Sections 2.1 to 2.5 provide a terse overview of how SQLite is constructed and how it operates. The SQLite library is complex and in such a brief treatment it is necessary, of course, to omit many details.
However, most of the essential points are covered and these are all that is really required to understand how to use SQLite to its full potential.
|
|
The remainder of this document describes features of the underlying SQLite database in more depth and explains how to exploit them to achieve optimal performance.
The sections that follow are mostly independent of one another and can be read in any order. However, it is important to have read the preceding section in order to understand the underlying principles of operation.
A programmer migrating to this database engine might write a test program to see how many INSERT statements per second it can do. They create an empty database with a single empty table. Then they write a loop that runs a few thousand times and does a single INSERT statement on each iteration. Upon timing this program they find that it appears to only be doing a couple of dozen INSERTs per second.
“Everybody I talked to says SQLite is suppose to be really fast”, the new programmer will typically complain, “But I'm only getting 20 or 30 INSERTs per second!”
In reality, SQLite can achieve around 50000 or more INSERTs per second on a modern workstation, although less on a typical embedded platform. But the characteristics of the underlying storage medium and the fact that the database engine guarantees atomic updates to the database mean that it can only achieve a few dozen COMMIT operations per second.
Unless you take specific action to tell SQLite to do otherwise, it will automatically insert a COMMIT operation after every insert. So the programmers described above are really measuring the number of transactions per second, not the number of INSERTs. This is a very important distinction.
Why is COMMIT so much slower than INSERT? SQLite guarantees that changes to a database are ACID – Atomic, Consistent, Isolated, and Durable. The Atomic and Durable parts are what take the time.
In order to be Atomic, the database engine has to go through an elaborate protocol with the underlying file system, which ultimately means that every modified page of the database file must be written twice.
In order to be durable, the COMMIT operation must not return until all content has been safely written to nonvolatile media. At least two consecutive non-concurrent writes to flash memory must occur in order to COMMIT.
An atomic and durable COMMIT is a very powerful feature that can help you to build a system that is resilient, even in the face of unplanned system crashes or power failures. But the price of this resilience is that COMMIT is a relatively slow operation. Hence if performance is a priority you should strive to minimize the number of COMMITs.
If you need to do more than one INSERT or UPDATE or DELETE operation, you are advised to put them all inside a single explicit transaction by running the BEGIN statement prior to the first changes and executing COMMIT once all changes have finished. In this way, all your changes occur within a single transaction and only a single time-consuming COMMIT operation must occur.
If you omit the explicit BEGIN...COMMIT, then SQLite automatically inserts an implicit BEGIN...COMMIT around each of your INSERT, UPDATE, and DELETE statements, which means you end of doing many COMMITs which will always be much slower than doing just one.
As described in section 3.1, when you have many changes to make to a database, you are advised to make all those changes within a single explicit transaction by preceding the first change with a BEGIN statement and concluding the changes with a COMMIT statement.
The problem with BEGIN...COMMIT is that BEGIN acquires an exclusive lock on the database file which is not released until the COMMIT completes. That means that only a single connection to the database can be in the middle of a BEGIN...COMMIT at one time. If another thread or process tries to start a BEGIN...COMMIT while the first is busy, the second has to wait. To avoid holding up other threads and processes, therefore, every BEGIN should be followed by a COMMIT as quickly as possible.
But sometimes you run into a situation where you have to make periodic INSERTs or UPDATEs to a database based on timed or external events. For example, you may want to do an INSERT into an event log table once every 250 milliseconds or so. You could do a separate INSERT for each event, but that would mean doing a separate COMMIT four times per second, which is perhaps more overhead than you desire. On the other hand, if you did a BEGIN and accumulated several seconds worth of INSERTs you could avoid doing a COMMIT except for every 10th second or so. The trouble there is that other threads and processes are unable to write to the database while the event log is holding its transaction open.
The usual method for avoiding this dilemma is to store all of the INSERTs in a separate TEMP table, then periodically flush the content of the TEMP table into the main database with a single operation.
A TEMP table works just like a regular database table except that a TEMP table is only visible to the database connection that creates it, and the TEMP table is automatically dropped when the database connection is closed. You create a TEMP table by inserting the “TEMP” or “TEMPORARY” keyword in between “CREATE” and “TABLE”, like this:
CREATE TEMP TABLE event_accumulator(
eventId INTEGER,
eventArg TEXT
);Because TEMP tables are ephemeral (meaning that they do not persist after the database connection closes) SQLite does not need to worry about making writes to a TEMP table atomic or durable. Hence a COMMIT to a TEMP table is very quick.
A process can do multiple INSERTs into a TEMP table without having to enclose those INSERTs within an explicit BEGIN...COMMIT for efficiency. Writes to a TEMP table are always efficient regardless of whether or not they are enclosed in an explicit transaction.
So as events arrive, they can be written into the TEMP table using isolated INSERT statements. But because the TEMP table is ephemeral, one must take care to periodically flush the contents of the TEMP table into the main database where they will persist. So every 10 seconds or so (depending on the application requirements) you can run code like this:
BEGIN;
INSERT INTO event_log SELECT * FROM event_accumulator;
DELETE FROM event_accumulator;
COMMIT;These statements transfer the content of the ephemeral event_accumulator table over to the persistent event_log table as a single atomic operation. Since this transfer occurs relatively infrequently, minimal database overhead is incurred.
Suppose you have a descriptor, nameDes, and you want to insert that value into the namelist table of a database. One way to proceed is to construct an appropriate INSERT statement that contains the desired string value as a SQL string literal, then run that INSERT statement. Pseudo-code for this approach follows:
_LIT(KSql, “INSERT INTO namelist VALUES('%S')”);
sqlBuf.Format(KSql, nameDes);
sqlDatabase.Execute(sql);
The INSERT statement is constructed by the call to
Format() on the second line of the example above. The first
argument is a template for the SQL statement. The value of the nameDes
descriptor is inserted where the %S occurs in the template. Notice that the %S
is surrounded by single quotes so that the string will be properly contained in
SQL standard quotes.
This approach works as long as the value in nameDes does not contain any single-quote characters. If nameDes does contain one or more single-quotes, then the string literal in the INSERT statement will not be well-formed and a syntax error might occur. Or worse, if a hostile user is able to control the content of nameDes, they might be able to put text in nameDes that looked something like this:
hi'); DELETE FROM critical_table; SELECT 'hiThis would result in the sqlBuf variable holding
INSERT INTO namelist VALUES('hi'); DELETE FROM critical_table; SELECT 'hi'Your adversary has managed to convert your single INSERT statement into three separate SQL statements, one of which does things that you probably do not want to happen. This is called an “SQL Injection Attack”. You want to be very, very careful to avoid SQL injection attacks as they can seriously compromise the security of your application.
SQLite allows you to specify parameters in SQL statements and then substitute values for those parameters prior to running the SQL. Parameters can take several forms, including:
?
?NNN
:AAA
@AAA
$AAAIn the above, NNN means any sequence of digits and AAA means any sequence of alphanumeric characters and underscores. In this example we will stick with the first and simplest form – the question mark. The operation above would be rewritten as shown below. (Error checking is omitted from this example for brevity.)
_LIT(KSql, “INSERT INTO namelist VALUES(?)”);
RSqlStatement s;
s.PrepareL(db, KSql);
s.BindText(1, nameDes);
s.Exec();
s.Close();
PrepareL() compiles the SQL statement held in the
literal KSql. This statement contains a single parameter. The value for this
parameter is initially NULL.
The BindText() sets the value of this parameter to the
content of the nameDes descriptor and then Exec()
executes the SQL statement with the bound parameter value.
There are variations of BindXxx() to bind other kinds of
values such as integers, floating point numbers, and binary large objects
(BLOBs). The key point to observe is that none of these values need to be
quoted or escaped in any way. And there is no possibility of being vulnerable
to an SQL injection attack.
Besides reducing your vulnerability to SQL injection attacks, the use of bound parameters also happens to be more efficient that constructing SQL statements from scratch, especially when inserting large strings or BLOBs.
Using RSqlStatement is a two-step process.
Firstly the statement must be compiled using Prepare(). Then the
resulting prepared statement is run using either Exec() or
Next().
The relative amount of time spent doing each of these steps depends on the nature of the SQL statement. SELECT statements that return a large result set or UPDATE or DELETE statements that touch many rows of a table will normally spend most of their time in the Virtual Machine module and relatively little time being compiled. But simple INSERT statements on the other hand, can take twice as long to compile as they take to run in the virtual machine.
A simple way to reduce the CPU load of an application that uses SQLite is to cache the prepared statements and reuse them. Of course, one rarely needs to run the exact same SQL statement more than once. But if a statement contains one or more bound parameters, you can bind new values to the parameters prior to each run and thus accomplish something different with each invocation.
This technique is especially effective when doing multiple INSERTs into the same table. Instead of preparing a separate insert for each row, create a single generic insert statement like this:
INSERT INTO important_table VALUES(?,?,?,?,?)
Then for each row to be inserted, use one or more of the
BindXxx() interfaces to bind values to the parameters in the
insert statement, and call Exec() to do the insert, then call
Reset() to rewind the program counter of the internal bytecode in
preparation for the next run.
For INSERT statements, reusing a single prepared statement in this way will typically make your code run two or three times faster.
You can manually manage a cache of prepared statements, keeping
around only those prepared statements that you know will be needed again and
closing prepared statements using Close() when you are done with
them or when they are about to fall out of scope. But depending on the
application, it can be more convenient to create a wrapper class around the SQL
interface that manages the cache automatically.
A wrapper class can keep around the 5 or 10 most recently used
prepared statements and reuse those statements if the same SQL is requested.
Handling the prepared statement cache automatically in a wrapper has the
advantage that it frees you to focus more mental energy on writing a great
application and less effort on operating the database interface. It also makes
the programming task less error prone since with an automatic class, there is
no chance of accidentally omitting a call to Close() and leaking
prepared statements.
The downside is that a cache wrapper will not have the foresight of a human programmer and will often cache prepared statements that are no longer needed, thus using excess memory, or sometimes discard prepared statements just before they are needed again.
This is a classic ease-of-programming versus performance trade-off. For applications that are intended for a high-power workstation, it can be best to go with a wrapper class that handles the cache automatically. But when designing an application for a resource constrained devices where performance is critical and engineering design talent is plentiful, it may be better to manage the cache manually.
Regardless of whether or not the prepared statement cache is managed manually or automatically using a wrapper class, reusing prepared statements is always a good thing, and can in some cases double or triple the performance of the application.
In order to translate a SQL statement into bytecode,
Prepare() needs to know the database schema. For any given SQL
statement there are typically many different ways of implementing the statement
in bytecode. The compiler (or a particular part of the compiler that is
commonly referred to as the optimizer) tries to pick the most
efficient implementation based on what is known about the content of the
various tables and what indexes are available. The bytecode depends so much on
the database schema that the slightest change to the schema can cause totally
different bytecode to be generated for the same SQL statement.
When Prepare() runs, it uses the database schema as of
the last time the database was accessed when preparing the bytecode. So if the
database schema has been changed by another program, or if the schema is
changed after Prepare() completes but before Exec()
or Next() is run, the schema of the database will not match the
schema used to prepare the bytecode.
To guard against any problems, the first few instructions of bytecode
in a prepared statement read the current schema cookie for the database and
check to see that it is the same as it was when Prepare() was run.
If the schema cookie has changed, then Exec() and
Next() terminate with the error
KSqlErrSchema.
When this occurs, a new prepared statement should be created by
calling Prepare() again with the same SQL and the original
prepared statement should be discarded.
It is important to recognize that a
KSqlErrSchema error can occur on any call to
Exec() or Next(). A common programming error with is
to omit the necessary error handling or to do it incorrectly. The error is,
unfortunately, often overlooked during testing because the usual cause of an
KSqlErrSchema error is an external program making a schema
change at just the wrong moment, and external programs are not normally running
during testing.
SQLite stores a row of a table by gathering the data for all columns in that row and packing the data together in column order into as few bytes as possible. Column order means that the data for the first declared column of the table – the column that appears first in the CREATE TABLE statement – is packed into the bundle first. The data for the second column is packed into the bundle second. And so forth.
SQLite goes to some trouble to use as few bytes as possible when storing data. A text string that is 5 bytes long, for example, is stored using just 5 bytes. The '\00' terminator on the end is omitted. No padding bytes or overhead are added even if the column specifies a larger string such as VARCHAR(1000).
Small integers (between -127 and +127) are stored as a single byte. As the magnitude of the integer increases, additional bytes of storage are added as necessary up to 8 bytes. Floating point numbers are normally stored as 8-byte IEEE floats, but if the floating point number can be represented as a smaller integer without loss of information, it is converted and stored that way to save space. BLOBs are also stored using the minimum number of bytes necessary.
These efforts to save space both help to keep SQLite database files small and also improve perfomance since the smaller each record is the more information will fit in the same amount of space and the less disk I/O needs to occur.
The downside of using compressed storage is that data in each column is an unpredictable size. So within each row, we do not know in advance where one column ends and the next column begins. To extract the data from the N-th column of a row, SQLite has to decode the data from the N-1 prior columns first. Thus, for example, if you have a query that reads just the fourth column of a table, the bytecode that implements the query has to read and discard the data from the first, second, and third columns in order to find where the data for the fourth column begins in order to read it out.
For this reason, it is best to put smaller and more frequently accessed columns of a table early in the CREATE TABLE statement and put large CLOBs and BLOBs and infrequently accessed information toward the end.
SQLite does not place arbitrary constraints on the size of BLOBs and CLOBs that it will store. The only real restriction is that the entire BLOB or CLOB must fit in memory all at once. But just because you can do this does not mean you should.
Although SQLite is able to handle really big BLOBs, it is not optimized for that case. If performance and storage efficiency is a concern, you will be better served to store large BLOBs and CLOBs in separate disk files then store the name of the file in the database in place of the actual content.
When SQLite encounters a large table row – e.g. because it contains one or more large BLOBs – it tries to store as much of the row as it can on a single page of the database. The tail of the row that will not fit on a single page is spilled into overflow pages. If more than one overflow page is required, then the overflow pages form a linked list.
To store a 1MiB BLOB in a database with a 1KiB page size will require the BLOB to be broken into a list of over a thousand links, each of which gets stored separately. Whenever you want to read the BLOB out of the database, SQLite has to walk this thousand-member linked list in order to reassemble the BLOB again. This works and is reliable, but it is not especially efficient.
Another problem with large BLOBs and CLOBs is that they can be neither read nor written incrementally. The entire BLOB or CLOB must be read or written all at once. So, for example, to append 10 bytes to the end of a 10MiB BLOB, one has to read the entire BLOB, append the 10 bytes, then write the new BLOB back out again. With a disk file, on the other hand, you can append 10 bytes quickly and efficiently without having to access the other 10 million bytes of the original file.
If you absolutely need to store large BLOBs and CLOBs in your database (perhaps so that changes to these data elements will be atomic and durable) then at least consider storing the BLOBs and CLOBs in separate tables that contain only an INTEGER PRIMARY KEY and the content of the BLOB or CLOB. So, instead of writing your schema this way:
CREATE TABLE image(
imageId INTEGER PRIMARY KEY,
imageTitle TEXT,
imageWidth INTEGER,
imageHeight INTEGER,
imageRefCnt INTEGER,
imageBlob BLOB
);Factor out the large BLOB into a separate table so that your schema looks more like this:
CREATE TABLE image(
imageId INTEGER PRIMARY KEY,
imageTitle TEXT,
imageWidth INTEGER,
imageHeight INTEGER,
imageRefCnt INTEGER
);
CREATE TABLE imagedata(
imageId INTEGER PRIMARY KEY,
imageBlob BLOB
);Keeping all of the small columns in a separate table increases locality of reference and allows queries that do not use the large BLOB to run much faster. You can still write single queries that return both the smaller fields and the BLOB by using a simple (and very efficient) join on the INTEGER PRIMARY KEY.
Suppose you have a table like this:
CREATE TABLE demo5(
id INTEGER,
content BLOB
);Further suppose that this table contains thousands or millions of rows and you want to access a single row with a particular ID:
SELECT content FROM demo5 WHERE id=?The only want that SQLite can perform this query, and be certain to get every row with the chosen ID, is to examine every single row, check the ID of that row, and return the content if the ID matches. Examining every single row this way is called a full table scan.
Reading and checking every row of a large table can be very slow, so you want to avoid full table scans. The usual way to do this is to create an index on the column you are searching against. In the example above, an appropriate index would be this:
CREATE INDEX demo5_idx1 ON demo5(id);With an index on the ID column, SQLite is able to use a binary search to locate entries that contain a particular value of ID. So if the table contains a million rows, the query can be satisfied with about 20 accesses rather than 1000000 accesses. This is a huge performance improvement.
One of the features of the SQL language is that you do not have to figure out what indexes you may need in advance of coding your application. It is perfectly acceptable, even preferable, to write the code for your application using a database without any indexes. Then once the application is running and you can make speed measurements, add whatever indexes are needed in order to make it run faster.
When you add indexes, the query optimizer within the SQL compiler is able to find new more efficient bytecode procedures for carrying out the operations that your SQL statements specify. In other words, by adding indexes late in the development cycle you have the power to completely reorganize your data access patterns without changing a single line of code.
Any column of a table that is declared to be the PRIMARY KEY or that is declared UNIQUE will be indexed automatically. There is no need to create a separate index on that column using the CREATE INDEX statement. So, for example, this table declaration:
CREATE TABLE demo39a(
id INTEGER,
content BLOB
);
CREATE INDEX demo39_idx1 ON demo39a(id);Is roughly equivalent to the following:
CREATE TABLE demo39b(
id INTEGER UNIQUE,
content BLOB
);The two examples above are “roughly” equivalent, but not exactly equivalent. Both tables have an index on the ID column. In the first case, the index is created explicitly. In the second case, the index is implied by the UNIQUE keyword in the type declaration of the ID column. Both table designs use exactly the same amount of disk space, and both will run queries such as
SELECT content FROM demo39 WHERE id=?using exactly the same bytecode. The only difference is that table demo39a lets you insert multiple rows with the same ID whereas table demo39b will raise an exception if you try to insert a new row with the same ID as an existing row.
If you use the UNIQUE keyword in the CREATE INDEX statement of demo39a, like this:
CREATE UNIQUE INDEX demo39_idx1 ON demo39a(id);Then both table designs really would be exactly the same in every way. In fact, whenever SQLite sees the UNIQUE keyword on a column type declaration, all it does is create an automatic unique index on that column.
The PRIMARY KEY modifier on a column type declaration works like UNIQUE; it causes a unique index to be created automatically. The main difference is that you are only allowed to have a single PRIMARY KEY. This restriction of only allowing a single PRIMARY KEY is part of the official SQL language definition.
The idea is that a PRIMARY KEY is used to order the rows on disk. Some SQL database engines actually implement PRIMARY KEYs this way. But with SQLite, a PRIMARY KEY is like any other UNIQUE column, with only one exception: INTEGER PRIMARY KEY is a special case which is handled differently, as described in the next section.
Every row of every SQLite table has a signed 64-bit integer RowID. This RowID is the key for the b-tree that holds the table content. The RowID must be unique over all other rows in the same table. When you go to find, insert, or remove a row from a table in SQLite, the row is first located by search for its RowID. Searching by RowID is very fast. Everything in SQLite tables centres around RowIDs.
In the CREATE TABLE statement that defines a table, if you declare a column to be of type INTEGER PRIMARY KEY, then that column becomes an alias for the RowID. It is generally a good idea to create such a column whenever it is practical.
Looking up information by RowID or INTEGER PRIMARY KEY is usually about twice as fast as any other search method in SQLite. So for example, if we have an indexed table like this:
CREATE TABLE demo1(
id1 INTEGER PRIMARY KEY,
id2 INTEGER UNIQUE,
content BLOB
);Then queries against the INTEGER PRIMARY KEY, e.g. of the form:
SELECT content FROM demo1 WHERE id1=?;will be about twice as fast as queries like this:
SELECT content FROM demo1 WHERE id2=?;Note that the following two queries are identical in SQLite – not just equivalent but identical. They generate exactly the same bytecode:
SELECT content FROM demo1 WHERE id1=?;
SELECT content FROM demo1 WHERE RowID=?;But for stylistic and portability reasons, the first form of the query is preferred.
Also observe that in order for the INTEGER PRIMARY KEY to truly be an alias for the RowID, the declared type must be exactly “INTEGER PRIMARY KEY”.
Variations such as “INT PRIMARY KEY” or “UNSIGNED INTEGER PRIMARY KEY” or “SHORTINT PRIMARY KEY” become independent columns instead of aliases for the RowID.
So be careful to always spell INTEGER PRIMARY KEY correctly in your CREATE TABLE statements.
As explained in section 3.10, every table row has a key which is a signed 64-bit integer: the RowID or INTEGER PRIMARY KEY. This same RowID also occurs in every index entry and is used to refer the index entry back to the original table row.
When writing the RowID to disk, SQLite encodes the 64-bit integer value using a Huffman code over a fixed probability distribution. The resulting encoding requires between 1 and 9 bytes of storage space, depending on the magnitude of the integer. Small, non-negative integers require less space than larger or negative integers. Table 3.1 shows the storage requirements:
| RowID Magnitude | Bytes Of Storage |
|---|---|
|
0 to 127 |
1 |
|
128 to 16383 |
2 |
|
16384 to 2097151 |
3 |
|
2097152 to 268435455 |
4 |
|
268435456 to 34359738367 |
5 |
|
34359738368 to 4398046511103 |
6 |
|
4398046511104 to 562949953421311 |
7 |
|
562949953421312 to 72057594037927935 |
8 |
|
Less than 0 or greater than 72057594037927935 |
9 |
Table 3.1: Storage requirements for RowIDs of different magnitudes
This chart makes it clear that the best way to keep reduce the number of bytes of disk space devoted to storing RowIDs is to keep RowIDs small non-negative integers. The database will continue to work fine with large or negative RowIDs, but the database files will take up more space.
SQLite normally works by assigning RowIDs automatically. An automatically generated RowID will normally be the smallest positive integer that is not already used as a RowID in the same table. The first RowID assigned will be 1, the second 2, and so forth. So the automatic RowID assignment algorithm begins by using 1-byte RowIDs, then moves to 2-byte RowIDs as the number of rows increased, then 3-byte RowIDs, and so forth. In other words, the automatic RowID assignment algorithm does a good job of selecting RowIDs that minimize storage requirements.
If a table contains an INTEGER PRIMARY KEY column, that column becomes an alias for the RowID. If you then specify a particular RowID when doing an INSERT, the RowID you specify overrides the default choice made by SQLite itself. For example, if your table is this:
CREATE TABLE demo311(
id INTEGER PRIMARY KEY,
content VARCHAR(100)
);Then if you insert like this:
INSERT INTO demo311(id,content) VALUES(-17,'Hello');The value -17 is used as the RowID which requires 9 bytes of space in the disk file because it is negative. If instead of specifying the id value you had just left it blank:
INSERT INTO demo311(content) VALUES('Hello');Or if you had specified a NULL as the INTEGER PRIMARY KEY value:
INSERT INTO demo311(id,content) VALUES(NULL,'Hello');Then in either case, SQLite would have automatically selected a RowID value that was the smallest positive integer not already in use, thus minimizing the amount of disk space required.
Therefore unless you have specific requirements to the contrary, it generally works best to let SQLite pick its own RowID and INTEGER PRIMARY KEY values.
Suppose you have a table with an indexed column you want to search against, like this:
CREATE TABLE demo312(
id INTEGER PRIMARY KEY,
name TEXT
);When you use the demo312.id column in a query, it is important that the column name appear by itself on one side of the comparison operation and that it not be part of an expression. So the following query works very efficiently:
SELECT name FROM demo312 WHERE id=?;But the following variations, although logically equivalent, result in a full table scan:
SELECT name FROM demo312 WHERE id-?=0;
SELECT name FROM demo312 WHERE id*1=?;
SELECT name FROM demo312 WHERE +id=?;In other words, you want to make sure that the indexed column name appears by itself on one side or the other of the comparison operator, and not inside an expression of some kind. Even a degenerate expression such as a single unary “+” operator will disable the optimizer and cause a full table scan.
Some variation in terms of the WHERE clause is permitted. The column name can be enclosed in parentheses, it can be qualified with the name of its table, and it can occur on either side of the comparison operator. So all of the following forms are efficient, and will in fact generate identical bytecode:
SELECT name FROM demo312 WHERE id=?;
SELECT name FROM demo312 WHERE demo312.id=?;
SELECT name FROM demo312 WHERE ?=id;
SELECT name FROM demo312 WHERE (id)=?;
SELECT name FROM demo312 WHERE (((demo321.id))=?);The previous examples have all shown SELECT statements. But the same rules apply for the WHERE clause in DELETE and UPDATE statements:
UPDATE demo312 SET name=? WHERE id=?;
DELETE FROM demo312 WHERE id=?;SQLite works best when the expression in a WHERE clause is a list of terms connected by the conjunction (AND) operator. Furthermore, each term should consist of a single comparison operator against an indexed column. The same rule also applies to ON clauses in a join and to a HAVING clause.
SQLite is able to optimize queries such as this:
SELECT * FROM demo313 WHERE a=5 AND b IN ('on','off') AND c>15.5;The WHERE clause in the example above consists of three terms connected by the AND operator and each term contains a single comparison operator with a column as one operand. The three terms are:
a=5
b IN ('on','off')
c>15.5The SQLite query optimizer is able to break the WHERE clause down and analyze each of the terms separately, and possibly use one or more of those terms with indexes to generate bytecode that runs faster. But consider the following similar query:
SELECT * FROM demo313 WHERE (a=5 AND b IN ('on','off') AND c>15.5) OR d=0;In this case, the WHERE clause consist of two terms connected by an OR. The query optimizer is not able to break this expression up for analysis. As a result, this query will be implemented as a full table scan in which the complete WHERE clause expression will be evaluated for each row.
In this case, refactoring the WHERE clause does not help much:
SELECT * FROM demo313 WHERE (a=5 OR d=0) AND (b IN ('on','off') OR d==0)
AND (c>15.5 OR d=0)The WHERE clause is now a conjunctive expression but its terms are not simple comparison operators against table columns. The query optimizer will be able to break the WHERE expression into three smaller subexpressions for analysis, but because each subexpression is a disjunction, no indexes will be usable and a full table scan will result.
If you know in advance that all rows in the result set are unique (or if that is what you want anyway) then the following query can be used for an efficient implementation:
SELECT * FROM demo313 WHERE a=5 AND b IN ('on','off') AND c>15.5
UNION
SELECT * FROM demo313 WHERE d=0In this form, the two queries are evaluated separately and their results are merged to get the final result. The WHERE clause on both queries is a conjunction of simple comparison operators so both queries could potentially be optimized to use indexes.
If the result set could potentially contain two or more identical rows, then you can run the above query efficiently as follows:
SELECT * FROM demo313 WHERE RowID IN (
SELECT RowID FROM demo313 WHERE a=5 AND b IN('on','off') AND c>15.5
UNION ALL
SELECT RowID FROM demo313 WHERE d=0
)The subquery computes a set containing the RowID of every row that should be in the result set. Then the outer query retrieves the desired rows. When a WHERE clause contains OR terms at the top level, most enterprise-class SQL database engines such as PostgreSQL or Oracle will automatically convert the query to a form similar to the above. But in order to keep minimize the complexity and size of SQLite, such advanced optimizations are omitted. In the rare cases where such queries are required, than can be optimized manually by the programmer by recasting the query statements as shown above.
SQLite is able to make use of multi-column indexes. The rule is that if an index is over columns X 0 , X 1 , X 2 , ..., X n of some table, then the index can be used if the WHERE clause contains equality constraints for some prefix of those columns X 0 , X 1 , X 2 , ..., X i where i is less than n.
As an example, suppose you have a table and index declared as follows:
CREATE TABLE demo314(a,b,c,d,e,f,g);
CREATE INDEX demo314_idx ON demo314(a,b,c,d,e,f);Then the index might be used to help with a query that contained a WHERE clause like this:
... WHERE a=1 AND b='Smith' AND c=1All three terms of the WHERE clause would be used together with the index in order to narrow the search. But the index could not be used if there WHERE clause said:
... WHERE b='Smith' AND c=1The second WHERE clause does not contain equality terms for a prefix of the columns in the index because it omits a term for the “a” column.
In a case like this:
... WHERE a=1 AND c=1Only the “a=1” term in the WHERE clause could be used to help narrow the search. The “c=1” term is not part of the prefix of terms in the index which have equality constraints because there is no equality constraint on the “b” column.
SQLite only allows a single index to be used per table within a simple SQL statement. For UPDATE and DELETE statements, this means that only a single index can ever be used, since those statements can only operate on a single table at a time.
In a simple SELECT statement multiple indexes can be used if the SELECT statement is a join – one index per table in the join. In a compound SELECT statement (two or more SELECT statements connected by UNION or INTERSECT or EXCEPT) each SELECT statement is treated separately and can have its own indexes. Likewise, SELECT statements that appear in subexpressions are treated separately.
Some other SQL database engines (for example PostgreSQL) allow multiple indexes to be used for each table in a SELECT. For example, if you had a table and index in PostgreSQL like this:
CREATE TABLE pg1(a INT, b INT, c INT, d INT);
CREATE INDEX pg1_ix1 ON pg1(a);
CREATE INDEX pg1_ix2 ON pg1(b);
CREATE INDEX pg1_ix3 ON pg1(c);And if you were to run a query like the following:
SELECT d FROM pg1 WHERE a=5 AND b=11 AND c=99;Then PostgreSQL might attempt to optimize the query by using all three indexes, one for each term of the WHERE clause.
SQLite does not work this way. SQLite is compelled to select a single index to use in the query. It might select any of the three indexes shown, depending on which one the optimizer things will give the best speedup. But in every case it will only select a single index and only a single term of the WHERE clause will be used.
SQLite prefers to use a multi-column index such as this:
CREATE INDEX pg1_ix_all ON pg1(a,b,c);If the pg1_ix_all index is available for use when the SELECT statement above is prepared, SQLite will likely choose it over any of the single-column indexes because the multi-column index is able to make use of all 3 terms of the WHERE clause.
You can trick SQLite into using multiple indexes on the same table by rewriting the query. Instead of the SELECT statement shown above, if you rewrite it as this:
SELECT d FROM pg1 WHERE RowID IN (
SELECT RowID FROM pg1 WHERE a=5
INTERSECT
SELECT RowID FROM pg1 WHERE b=11
INTERSECT
SELECT RowID FROM pg1 WHERE c=99
)Then each of the individual SELECT statements will using a different single-column index and their results will be combined by the outer SELECT statement to give the correct result. The other SQL database engines like PostgreSQL that are able to make use of multiple indexes per table do so by treating the simpler SELECT statement shown first as if they where the more complicated SELECT statement shown here.
Terms in the WHERE clause of a query or UPDATE or DELETE statement are mostly likely to trigger the use of an index if they are an equality constraint – in other words if the term consists of the name of an indexed column, an equal sign (“=”), and an expression.
So, for example, if you have a table and index that look like this:
CREATE TABLE demo315(a,b,c,d);
CREATE INDEX demo315_idx1 ON demo315(a,b,c);And a query like this:
SELECT d FROM demo315 WHERE a=512;The single “a=512” term of the WHERE clause qualifies as an equality constraint and is likely to provoke the use of the demo315_idx1 index.
SQLite supports two other kinds of equality constraints. One is the IN operator:
SELECT d FROM demo315 WHERE a IN (512,1024);
SELECT d FROM demo315 WHERE a IN (SELECT x FROM someothertable);There other is the IS NULL constraint:
SELECT d FROM demo315 WHERE a IS NULL;SQLite allows at most one term of an index to be constrained by an inequalty such as less than “<”, greater than “>”, less than or equal to “<=”, or greater than or equal to “>=”.
The column that the inequality constrains will be the right-most term of the index that is used. So, for example, in this query:
SELECT d FROM demo315 WHERE a=5 AND b>11 AND c=1;Only the first two terms of the WHERE clause will be used with the demo315_idx1 index. The third term, the “c=1” constraint, cannot be used because the “c” column occurs to the right of the “b” column in the index and the “b” column is constrained by an inequality.
SQLite allows up to two inequalities on the same column as long as the two inequalities provide an upper and lower bound on the column. For example, in this query:
SELECT d FROM demo315 WHERE a=5 AND b>11 AND b<23;All three terms of the WHERE clause will be used because the two inequalities on the “b” column provide an upper and lower bound on the value of “b”.
SQLite will only use the four inequalities mentioned above to help constrain a search: “<”, “>”, “<=”, and “>=”. Other inequality operators such as not equal to (“!=” or “<>”) and NOT NULL are not helpful to the query optimizer and will never be used to control an index and help make the query run faster.
The default method for evaluating an ORDER BY clause in a SELECT statement is to first evaluate the SELECT statement and store the results in a temporary tables, then sort the temporary table according to the ORDER BY clause and scan the sorted temporary table to generate the final output.
This method always works, but it requires three passes over the data (one pass to generate the result set, a second pass to sort the result set, and a third pass to output the results) and it requires a temporary storage space sufficiently large to contain the entire results set.
Where possible, SQLite will avoid storing and sorting the result set by using an index that causes the results to emerge from the query in sorted order in the first place.
The way to get SQLite to use an index for sorting is to provide an index that covers the same columns specified in the ORDER BY clause. For example, if the table and index are like this:
CREATE TABLE demo316(a,b,c,data);
CREATE INDEX idx316 ON demo316(a,b,c);And you do a query like this:
SELECT data FROM demo316 ORDER BY a,b,c;SQLite will use the idx316 index to implement the ORDER BY clause, obviating the need for temporary storage space and a separate sorting pass.
An index can be used to satisfy the search constraints of a WHERE clause and to impose the ORDER BY ordering of outputs all at once. The trick is for the ORDER BY clause terms to occur immediately after the WHERE clause terms in the index. For example, one can write:
SELECT data FROM demo316 WHERE a=5 ORDER BY b,c;The “a” column is used in the WHERE clause and the immediately following terms of the index, “b” and “c” are used in the ORDER BY clause. So in this case the idx316 index would be used both to speed up the search and to satisfy the ORDER BY clause.
This query also uses the idx316 index because, once again, the ORDER BY clause term “c” immediate follows the WHERE clause terms “a” and “b” in the index:
SELECT data FROM demo316 WHERE a=5 AND b=17 ORDER BY c;But now consider this:
SELECT data FROM demo316 WHERE a=5 ORDER BY c;Here there is a gap between the ORDER BY term “c” and the WHERE clause term “a”. So the idx316 index cannot be used to satisfy both the WHERE clause and the ORDER BY clause. The index will be used on the WHERE clause and a separate sorting pass will occur to put the results in the correct order.
Queries will sometimes run faster if their result columns appear in the right-most entries of an index. Consider the following example:
CREATE TABLE demo317(a,b,c,data);
CREATE INDEX idx317 ON demo316(a,b,c);A query where all result column terms appears in the index, such as
SELECT c FROM demo317 WHERE a=5 ORDER BY b;will typically run about twice as fast or faster than a query that uses columns that are not in the index, e.g.
SELECT data FROM demo317 WHERE a=5 ORDER BY b;The reason for this is that when all information is contained within the index entry only a single search has to be made for each row of output. But when some of the information is in the index and other parts are in the table, first there must be a search for the appropriate index entry then a separate search is made for the appropriate table row based on the RowID found in the index entry. Twice as much searching has to be done for each row of output generated.
The extra query speed does not come for free, however. Adding additional columns to an index makes the database file larger. So when developing an application, the programmer will need to make a space versus time trade-off to determine whether the extra columns should be added to the index or not.
Note that if any column of the result must be obtained from the original table, then the table row will have to be searched for anyhow. There will be no speed advantage, so you might as well omit the extra columns from the end of the index and save on storage space. The speed-up described in this section can only be realized when every column in a table is obtainable from the index.
Taking into account the results of the previous few sections, the best set of columns to put in an index can be described as follows:
The first columns in the index should be columns that have equality constraints in the WHERE clause of the query.
The second group of columns should match the columns specified in the ORDER BY clause.
Add additional columns to the end of the index that are used in the result set of the query.
A big part of the job of the SQL compiler is to choose which of many implementation options should be used for a particular SQL statement.
Often a table will have two or more indexes and the optimizer will need to choose which one of those indexes to use. Or the optimizer will have to decide between using an index to implement the WHERE clause or the ORDER BY clause. For a join, the optimizer has to pick an appropriate order for the table in the join. And so forth.
By default, the only information the optimizer has to go on when trying to choose between two or more indexes is the database schema. In many cases the schema alone is not sufficient to make a wise choice. Suppose, for example, you have a table with two indexes:
CREATE TABLE demo318(a,b,c,data);
CREATE INDEX idx318a ON demo381(a);
CREATE INDEX idx318b ON demo381(b);And further suppose SQLite is trying to compile a statement such as the following:
SELECT data FROM demo318 WHERE a=0 AND b=11;The optimizer has to decide whether it should use idx318a with the “a=5” term of the WHERE clause or if it should use idx318b with the “b=11” term.
Without additional information, the two approaches are equivalent and so the choice is arbitrary. But the choice of indexes might have a big impact on performance.
Suppose that the demo318 table contains one million rows of which 55% have a=0, 40% have a=1, and the rest have a=2 or a=3. If the idx381a index is chosen, it will only narrow down the set of candidate rows by half. In this situation you are unlikely to notice any performance gain at all. In fact, in this extreme case, using the index is likely to make the query slower!
On the other hand, let us assume that there are never more than 2 or 3 rows with the same value for column b. In this case using index idx381b allows us to reduce the set of candidate rows from one million to 2 or 3 which will yield a huge speed improvement.
So clearly, in this example we hope that the optimizer chooses index idx318b. But without knowledge of the table contents and the statistical distributions of values for the “a” and “b” columns, the optimizer has no way of knowing which of the idx318a and idx318b indexes will work better.
The ANALYZE command is used to provide the query optimizer with statistical information about the distribution of values in a database so that it can make better decisions about which indexes to use.
When you run the ANALYZE command, SQLite creates a special table named SQLITE_STAT1. It then reads the entire database, gathers statistics and puts those statistics in the SQLITE_STAT1 table so that the optimizer can find them. ANALYZE is a relatively slow operation, since it has to read every single row of every single table in your database.
The statistical information generated by ANALYZE is not kept up-to-date by subsequent changes to the database. But many databases have a relatively constant statistical profile so running ANALYZE once and using the same statistical profile forever thereafter is often sufficient.
For embedded applications, you can often get by without ever having to run ANALYZE on a real database on the embedded device. Instead, generate a template database that contains typical data for your application and then run ANALYZE on that database on a developer workstation. Then just copy the content of the resulting SQLITE_STAT1 table over to the embedded device.
The SQLITE_STAT1 table is special in that you cannot CREATE or DROP it, but you can still SELECT, DELETE, and UPDATE the SQLITE_STAT1 table. So to create the SQLITE_STAT1 table on the embedded device, just run ANALYZE when the database is empty. That will take virtually no time and will leave you with an empty SQLITE_STAT1 table. Then copy the content of the SQLITE_STAT1 table that was created on the developer workstation into the database on the embedded device and the optimizer will begin using it just as if it had been created locally.
There is one entry in the SQLITE_STAT1 table for each index in your schema. Each entry contains the name of the table being indexed, the name of the index itself, and a string composed of two or more integers separated by spaces. These integers are the statistics that the ANALYZE command collects for each index.
The first integer is the total number of entries in the table. The second integer is the average number of rows in a result from a query that had an equality constraint on the first term of the index. The third integer (if there is one) is the average number of rows that would result if the index were used with equality constraints on the first two terms of the index. And so forth for as many terms as there are in the index.
The smaller the second and subsequent integers are, the more selective an index is. And the more selective the index is, the fewer rows have to be processed when using that index. So the optimizer tries to use indexes with small second and subsequent numbers.
The details are complex and do not really add any understanding to what is going on. The key point is that the second and subsequent integers in the SQLITE_STAT1 table are a measure of the selectivity of an index and that smaller numbers are better.
The statistics gathered by the ANALYZE command reflect the state of the database at a single point in time. While making the final performance tweaks on an application, some developers may want to adjust these statistics manually to better reflect the kinds of data they expect to encounter in the field. This is easy to do. The SQLITE_STAT1 table is readable and writable using ordinary SQL statements. You are free to adjust or modify the statistics in anyway that seems to performance benefit.
The SQLite query optimizer will attempt to reorder the tables in a join in order to find the most efficient way to evaluate the join. The optimizer usually does this job well, but occasionally it will make a bad choice. When that happens, it might be necessary to override the optimizer's choice by explicitly specifying the order of tables in the SELECT statement.
To illustrate the problem, consider the following schema:
CREATE TABLE node(
id INTEGER PRIMARY KEY,
name TEXT
);
CREATE INDEX node_idx ON node(name);
CREATE TABLE edge(
orig INTEGER REFERENCES node,
dest INTEGER REFERENCES node,
PRIMARY KEY(orig, dest)
);
CREATE INDEX edge_idx ON edge(dest,orig);This schema defines a directed graph with the ability to store a name on each node of the graph. Similar designs (though usually more complicated) arise frequently in application development. Now consider a three-way join against the above schema:
SELECT e.*
FROM edge AS e,
node AS n1,
node AS n2
WHERE n1.name = 'alice'
AND n2.name = 'bob'
AND e.orig = n1.id
AND e.dest = n2.id;This query asks for information about all edges that go from nodes labelled “alice” over to nodes labelled “bob”.
There are many ways that the optimizer might choose to implement this query, but they all boil down to two basic designs. The first option looks for edges between all pairs of nodes. The following pseudocode illustrates:
foreach n1 where n1.name='alice' do:
foreach n2 where n2.name='bob' do:
foreach e where e.orig=n1.id and e.dest=n2.id do:
return e.*
end
end
endThe second design is to loop over all 'alice' nodes and follow edges off of those nodes looking for nodes named 'bob'. (The roles of 'alice' and 'bob' might be reversed here without changing the fundamental character or the algorithm):
foreach n1 where n1.name='alice' do:
foreach e where e.orig=n1.id do:
foreach n2 where n2.id=e.dest and n2.name='bob' do:
return e.*
end
end
endThe first algorithm above corresponds to a join order of n1-n2-e. The second algorithm corresponds to a join order of n1-e-n2.
The question the optimizer has to answer is which of these two algorithms is likely to give the fastest result, and it turns out that the answer depends on the nature of the data stored in the database.
Let the number of alice nodes be M and the number of bob nodes be N. Consider two scenarios: In the first scenario, M and N are both 2 but there are thousands of edges on each node. In this case, the first algorithm is preferred. With the first algorithm, the inner loop checks for the existence of an edge between a pair of nodes and outputs the result if found. But because there are only 2 alice and bob nodes each, the inner loop only has to run 4 times and the query is very quick.
The second algorithm would take much longer here. The outer loop of the second algorithm only executes twice, but because there are a large number of edges leaving each 'alice' node, the middle loop has to iterate many thousands of times. So in the first scenario, we prefer to use the first algorithm.
Now consider the case where M and N are both 3500. But suppose each of these nodes is connected by only one or two edges. In this case, the second algorithm is preferred.
With the second algorithm, the outer loop still has to run 3500 times, but the middle loop only runs once or twice for each outer loop and the inner loop will only run once for each middle loop, if at all. So the total number of iterations of the inner loop is around 7000.
The first algorithm, on the other hand, has to run both its outer loop and its middle loop 3500 times each, resulting in 12 million iterations of the middle loop. Thus in the second scenario, second algorithm is nearly 2000 times faster than the first.
In this particular example, if you run ANALYZE on your database to collect statistics on the tables, the optimizer will be able to figure out the best algorithm to use. But if you do not want to run ANALYZE or if you do not want to waste database space storing the SQLITE_STAT1 statistics table that ANALYZE generates, you can manually override the decision of the optimizer by specifying a particular order for tables in a join. You do this by substituting the keyword phrase “CROSS JOIN” in place of commas in the FROM clause.
The “CROSS JOIN” phrase forces the table to the left to be used before the table to the right. For example, to force the first algorithm, write the query this way:
SELECT *
FROM node AS n1 CROSS JOIN
node AS n2 CROSS JOIN
edge AS e
WHERE n1.name = 'alice'
AND n2.name = 'bob'
AND e.orig = n1.id
AND e.dest = n2.id;And to force the second algorithm, write the query like this:
SELECT *
FROM node AS n1 CROSS JOIN
edge AS e CROSS JOIN
node AS n2
WHERE n1.name = 'alice'
AND n2.name = 'bob'
AND e.orig = n1.id
AND e.dest = n2.id;The CROSS JOIN keyword phrase is perfectly valid SQL syntax according to the SQL standard, but it is syntax that is rarely if ever used in real-world SQL statements. Because it is so rarely used otherwise, SQLite has appropriated the phrase as a means to override the table reordering decisions of the query optimizer.
The CROSS JOIN connector is rarely needed and should probably never be used prior to the final performance tuning phase of application development. Even then, SQLite usually gets the order of tables in a join right without any extra help. But on those rare occasions when SQLite gets it wrong, the CROSS JOIN connector is an invaluable way of tweaking the optimizer to do what you want.
The SQLite query optimizer usually does a good job of choosing the best index to use for a particular query, especially if ANALYZE has been run to provide it with index performance statistics. But occasions do arise where it is useful to give the optimizer hints.
One of the easiest ways to control the operation of the optimizer is to disqualify terms in the WHERE clause or ORDER BY clause as candidates for optimization by using the unary “+” operator.
In SQLite, a unary “+” operator is a no-op. It makes no change to its operand, even if the operand is something other than a number. So you can always prefix a “+” to an expression in without changing the meaning of the expression. As the optimizer will only use terms in WHERE, HAVING, or ON clauses that have an index column name on one side of a comparison operator, you can prevent such a term from being used by the optimizer by prefixing the column name with a “+”.
For example, suppose you have a database with a schema like this:
CREATE TABLE demo321(a,b,c,data);
CREATE INDEX idx321a ON demo321(a);
CREATE INDEX idx321b ON demo321(b);If you issue a query such as this:
SELECT data FROM demo321 WHERE a=5 AND b=11;The query optimizer might use the “a=5” term with idx321a or it might use the “b=11” term with the idx321b index. But if you want to force the use of the idx321a index you can accomplish that by disqualifying the second term of the WHERE clause as a candidate for optimization using a unary “+” like this:
SELECT data FROM demo321 WHERE a=5 AND +b=11;The “+” in front of the “b=11” turns the left-hand side of the equals comparison operator into an expression instead of an indexed column name. The optimizer will then not recognize that the second term can be used with an index and so the optimizer is compelled to use the first “a=5” term.
The unary “+” operator can also be used to disable ORDER BY clause optimizations. Consider this query:
SELECT data FROM demo321 WHERE a=5 ORDER BY b;The optimizer has the choice of using the “a=5” term of the WHERE clause with idx321a to restrict the search. Or it might choose to use do a full table scan with idx321b to satisfy the ORDER BY clause and thus avoid a separate sorting pass. You can force one choice or the other using a unary “+”.
To force the use of idx321a on the WHERE clause, add the unary “+” in from of the “b” in the ORDER BY clause:
SELECT data FROM demo321 WHERE a=5 ORDER BY +b;To go the other way and force the idx321b index to be used to satisfy the ORDER BY clause, disqualify the WHERE term by prefixing with a unary “+”:
SELECT data FROM demo321 WHERE +a=5 ORDER BY b;The reader is cautioned not to overuse the unary “+” operator. The SQLite query optimizer usually picks the best index without any outside help. Premature use of unary “+” can confuse the optimizer and cause less than optimal performance. But in some cases it is useful to be able override the decisions of the optimizer, and the unary “+” operator is an excellent way to do this when it becomes necessary.
SQLite stores indexes as b-trees. Each b-tree node uses one page of the database file. In order to maintain an acceptable fan-out, the b-tree module within SQLite requires that at least 4 entries must fit on each page of a b-tree. There is also some overhead associated with each b-tree page. So at the most there is about 250 bytes of space available on the main b-tree page for each index entry.
If an index entry exceeds this allotment of approximately 250 bytes excess bytes are spilled to overflow pages. There is no arbitrary limit on the number of overflow pages or on the length of a b-tree entry, but for maximum efficiency it is best to avoid overflow pages, especially in indexes. This means that you should strive to keep the number of bytes in each index entry below 250.
If you keep the size of indexes significantly smaller than 250 bytes, then the b-tree fan-out is increased and the binary search algorithm used to search for entries in an index has fewer pages to examine and therefore runs faster. So the fewer bytes used in each index entry the better, at least from a performance perspective.
For these reasons, it is recommended that you avoid indexing large BLOBs and CLOBs. SQLite will continue to work when large BLOBs and CLOBs are indexed, but there will be a performance impact.
On the other hand, if you need to lookup entries using a large BLOB or CLOB as the key, then by all means use an index. An index on a large BLOB or CLOB is not as fast as an index using more compact data types such as integers, but it is still many order of magnitude faster than doing a full table scan. So to be more precise, the advice of this section is that you should design your applications so that you do not need to lookup entries using a large BLOB or CLOB as the key. Try to arrange to have compact keys consisting of short strings or integers.
Note that many other SQL database engines disallow the indexing of BLOBs and CLOBs in the first place. You simple cannot do it. SQLite is more flexible that most in that it does allow BLOBs and CLOBs to be indexed and it will use those indexes when appropriate. But for maximum performance, it is best to use smaller search keys.
Some developers approach SQL-based application development with the attitude that indexes never hurt and that the more indexes you have, the faster your application will run. This is definitely not the case. There is a costs associated with each new index you create:
Each new index takes up additional space in the database file. The more indexes you have, the larger your database files will become for the same amount of data.
Every INSERT and UPDATE statement modifies both the original table and all indexes on that table. So the performance of INSERT and UPDATE decreases linearly with the number of indexes.
Compiling new SQL statements using Prepare() takes
longer when there are more indexes for the optimizer to choose between.
Surplus indexes give the optimizer more opportunities to make a bad choice.
Your policy on indexes should be to avoid them wherever you can. Indexes are powerful medicine and can work wonders to improve the performance of a program. But just as too many drugs can be worse than none at all, so also can too many indexes cause more harm than good.
When building a new application, a good approach is to omit all explicitly declared indexes in the beginning and only add indexes as needed to address specific performance problems.
Take care to avoid redundant indexes. For example, consider this schema:
CREATE TABLE demo323a(a,b,c);
CREATE INDEX idx323a1 ON demo323(a);
CREATE INDEX idx323a2 ON demo323(a,b);The idx323a1 index is redundant and can be eliminated. Anything that the idx323a1 index can do the idx323a2 index can do better.
Other redundancies are not quite as apparent as the above. Recall that any column or columns that are declared UNIQUE or PRIMARY KEY (except for the special case of INTEGER PRIMARY KEY) are automatically indexed. So in the following schema:
CREATE TABLE demo323b(x TEXT PRIMARY KEY, y INTEGER UNIQUE);
CREATE INDEX idx323b1 ON demo323b(x);
CREATE INDEX idx323b2 ON demo323b(y);Both indexes are redundant and can be eliminated with no loss in query performance. Occasionally one sees a novice SQL programmer use both UNIQUE and PRIMARY KEY on the same column:
CREATE TABLE demo323c(p TEXT UNIQUE PRIMARY KEY, q);This has the effect of creating two indexes on the “p” column – one for the UNIQUE keywords and another for the PRIMARY KEY keyword. Both indexes are identical so clearly one can be omitted. A PRIMARY KEY is guaranteed to always be unique so the UNIQUE keyword can be removed from the demo323c table definition with no ambiguity or loss of functionality.
It is not a fatal error to create too many indexes or redundant indexes. SQLite will continue to generate the correct answers but it may take longer to produce those answers and the resulting database files might be a little larger. So for best results, keep the number of indexes to a minimum.
In an earlier section we described how the optimizer would only make use of an index if one of the columns being indexed occurred on one side of certain equality and comparison operators (“=”, “IN”, “<”, “>”, “<=”, “>=”, and sometimes “IS NULL”).
While this is technically true, prior to the stage of the analysis where the optimizer is looking for these kinds of expressions, it may have first modified the WHERE clause (or the ON or HAVING clause) from what was originally entered by the programmer.
The next few paragraphs will describe some of these rewriting rules.
The query optimizer always rewrites the BETWEEN operator as a pair of inequalities. So, for example, if the input SQL is this:
SELECT * FROM demo324 WHERE x BETWEEN 7 AND 23;What the query optimizer ultimately sees is this:
SELECT * FROM demo324 WHERE x>=7 AND x<=23;In this revised form, the optimizer might be able to use an index on the “x” column to speed the operation of the query.
Another rewriting rule is that a disjunction of two or more equality tests against the same column is changed into a single IN operator. So if you write:
SELECT * FROM demo324 WHERE x=7 OR x=23 OR x=47;The WHERE clause will be rewritten into the following form:
SELECT * FROM demo324 WHERE x IN (7,23,47);The original format was not a candidate for use of indexes. But after the disjunction is converted into a single IN operator the usual index processing logic applies and the query can be made much faster.
In order for this rewriting rule to be applied, however, all terms of the disjunction must be equality comparisons against the same column. It will not work to have a disjunction involving two or more columns or involving expressions. So, for instance, the following statements will not be optimized:
SELECT * FROM demo324 WHERE x=7 OR y=23;
SELECT * FROM demo324 WHERE x=7 OR +x=23;The query parser and compiler in SQLite are designed to be small, fast, and lean. A consequence of this design is that SQLite does not do much in the way of constant folding or common subexpression elimination. SQLite evaluates SQL expressions mostly as written.
One way to work around the lack of constant folding in SQLite is to enclose constant subexpressions within a subquery. SQLite does optimize constant subqueries – it evaluates them once, remembers the result, and then reuses that result repeatedly.
An example will help clarify how this works. Suppose you have a table that contains a timestamp recorded as the fractional julian day number:
CREATE TABLE demo325(tm DATE, data BLOB);A query against this table to find all entries after November 8, 2006 might look like the following:
SELECT data FROM demo325 WHERE tm>julianday('2006-11-08');This query works fine. The problem is that the “julianday('2006-11-08')” function gets called repeatedly, once for each row tested, even though the function returns the same value each time. It is much more efficient to call the function one time only and reuse the result over and over. You can accomplish this by moving the function call inside a subquery as follows:
SELECT data FROM demo325 WHERE tm>(SELECT julianday('2006-11-08'));There are, of course, some cases where multiple evaluations of a function in the WHERE clause is desirable. For example, suppose you want to return roughly one out of every eight records, chosen at random. A suitable query would be:
SELECT data FROM demo325 WHERE (random()&7)==0;In this case, moving the function evaluation into a subquery would not work as desired:
SELECT data FROM demo325 WHERE (SELECT random()&7)==0;
In this last example, the result would be either all of the records
in the table (probability 12.5%) or none of them (probability 87.5%). The
difference here, of course, is that the random() function is not
constant whereas the julianday() function is.
The SQL compiler does not have any way of knowing this so it always
assumes the worst: that every function works like random() and can
potentially return a different answer even with the same inputs. Use a subquery
if you truly want to make a subexpression constant.
SQLite includes some special case optimizations for the
MIN() and MAX() aggregate functions. The normal way
of evaluating a MIN() or MAX() aggregate function is
to run the entire query, examine every row of the result set, and pick the
largest or smallest value. Hence, the following two queries take roughly same
amount of work:
SELECT x FROM demo326 WHERE y>11.5;
SELECT min(x) FROM demo326 WHERE y>11.5;The only difference in the above two SELECT statements is that the first returns every possible value for “x” whereas the second only returns the smallest. Both require about the same amount of time to run.
But there are some special cases where MIN() and
MAX() are very fast. If the result set of a SELECT consists of
only the MIN() function or the MAX() function and the
argument to that function is an indexed column or the RowID and there is no
WHERE or HAVING or GROUP BY clause then the query runs in logarithmic time. So
these two queries are very quick:
SELECT min(x) FROM demo326;
SELECT max(x) FROm demo326;Note that the result set must contain a single column. The following query is much slower:
SELECT min(x), max(x) FROM demo326;If you need the results from this last query quickly, you can rewrite it as follows:
SELECT (SELECT min(x) FROM demo326), (SELECT max(x) FROM dem326);In other words, break the query up into two subqueries both of which can be optimized using the MIN/MAX optimization.
Note also that the result set must not be an expression on
MIN() or MAX() - it needs to be a plain
MIN() or MAX() and nothing else. So the following
query is slower:
SELECT max(x)+1 FROM demo326;As before, achieve the same result quickly using a subquery:
SELECT (SELECT max(x) FROM demo326)+1;SQLite, in accordance with the SQL standard, allows two or more SELECT statements to be combined using operators UNION, UNION ALL, INTERSECT, or EXCEPT. The first two, UNION and UNION ALL, are the subject of this section.
The UNION and UNION ALL operators do very nearly the same thing, but with one important difference. Both operators return the union of all rows from their left and right queries. The difference is that the UNION operator removes duplicates whereas the UNION ALL operator does not. To look it another way, the following two queries are equivalent:
SELECT * FROM tableA UNION SELECT * FROM tableB;
SELECT DISTINCT * FROM (SELECT * FROM tableA UNION ALL SELECT * FROM tableB);When you look at it this way, you should clearly see that UNION is just UNION ALL with some extra work to compute the DISTINCT operation. You should also see that UNION ALL is noticeably faster than UNION and uses less temporary storage space too.
If you need uniqueness of output values then by all means use UNION. It is there for you and it works. But if you know in advance that your results will be unique or if you do not care, UNION ALL will almost always run faster.
A common design pattern is to show the results of a large query result in a scrolling window. The query result might contain hundreds or thousands of rows, but only a handful are shown to the user at one time. The user clicks the “Up” or “Down” buttons or drags a scrollbar to move up and down the list.
A common example of this is in media players where a user has requested to see all “albums” of a particular “genre”. There might be 200 such albums stored on the device, but the display window is only large enough to show 5 at a time. So the first 5 albums are displayed initially. When the user clicks the Down button the display scrolls down to the next 5 albums. When the user presses the Up button the display scrolls back up to the previous 5 albums.
The naïve approach for implementing this behaviour is to keep the index of the topmost album currently displayed. When the user presses Up or Down this index is decremented or incremented by 5 and a query like this is run to refill the display:
SELECT title FROM album WHERE genre='classical' ORDER BY title LIMIT 5 OFFSET ?The bound parameter on the offset field would be filled in with the index of the topmost album to be displayed and the query is run to generate five album titles. Presumably the album table is indexed in such a way that both the WHERE clause and the ORDER BY clause can be satisfied using the index so that no accumulation of results and sorting is required. Perhaps the index looks like this:
CREATE INDEX album_idx1 ON album(genre, title);This approach works find as long as the offset value is small. But the time needed to evaluate this query grows linearly with the offset. So as the user scrolls down towards the bottom of the list, the response time for each click becomes longer and longer.
A better approach is to remember the top and bottom title currently being displayed. (The application probably has to do this already in order be able to display the titles). To scroll down, run this query:
SELECT title FROM album WHERE genre='classical' AND title>:bottom
ORDER BY title ASC LIMIT 5;And to scroll back up, use this query:
SELECT title FROM album WHERE genre='classical' AND title<:top
ORDER BY title DESC LIMIT 5;For the scrolling down case the addition of the “title>:bottom” term (where :bottom is a parameter which is bound to the title of the bottom element currently displayed) causes SQLite to jump immediately to the first entry past the current display. There is no longer a need for an OFFSET clause in the query, though we still include “LIMIT 5”. The same index will still work to optimize both the WHERE clause and the ORDER BY clause.
The scrolling up case is very similar, although in this case we are looking for titles that are less than the current top element. We have also added the “DESC” tag to the ORDER BY clause so that titles will come out in “descending” order. (The sort order is descending, but the order is ascending if you are talking about the order in which the titles are displayed in the scrolling window). As before, the same album_idx1 index is able handle both terms of the WHERE clause and the descending ORDER BY clause.
Both of these queries should be much faster than using OFFSET, especially when the OFFSET is large. OFFSET is convenient for use in ad hoc queries entered on a workstation, but it is rarely helpful in an embedded application. An indexing scheme such as described here is only slightly more complex to implement but is much faster from user's perspective.
SQLite's efforts to make sure that all database changes are atomic and durable result in the following irony: You cannot delete information from a database that is located on a full filesystem. SQLite requires some temporary disk space in order to do a delete.
The temporary disk space is needed to hold the rollback journal that SQLite creates as part of its COMMIT processing. Before making any changes to the original database file, SQLite copies the original content of the pages to be changed over into the separate rollback journal file. Once the original content is preserved in the rollback journal, modifications can be made to the original database. Once the original file is updated, the rollback journal is deleted and the transaction commits.
The purpose of the rollback journal is to provide a means of recovering the database if a power failure or other unexpected failure occurs. Whenever a database is opened, a check is made to see if a rollback journal exists for that database. The presence of a rollback journal indicates that a previous update failed to complete. The original database content stored in the rollback journal is copied back into the database file thus reverting the database back to its state prior to the start of the failed transaction.
Since the rollback journal stores the original content of pages that are changing, the size of the rollback journal depends on how many pages are changing in the transaction. The more records that are modified, the larger the rollback journal will become.
A consequence of this is that any change to a database requires temporary disk space that is roughly proportional to the size of change. Any delete requires some temporary space and a large delete requires correspondingly more temporary disk space than a small delete.
Designers of applications for embedded systems should therefore takes steps to make sure that filesystem space is never completely exhausted. And when filesystem space is low, large updates and deletes should be broken up into smaller transactions to avoid creating excessively large rollback journals.
SQLite stores the original text of all CREATE statements in a system table of the database. When a database session is opened or when the database schema is changed, SQLite has to read and parse all of these CREATE statements in order to reconstruct its internal symbol tables.
The parser and symbol table builder inside SQLite are very fast, but they still take time which is proportional to the size of the schema. To minimize the computational overhead associated with parsing the schema:
Keep the number and size of CREATE statements in the schema to a minimum.
Avoid unnecessary calls to
RSqlDatabase::Open(). Reuse the same database session
where possible.
Avoid changing the database schema while other threads or processes might be using the database.
Whenever the schema is reparsed, all statements that were prepared
using the old schema are invalidated. A call Next() or
Exec() on a RSqlStatement object that was
prepared prior to the schema reparse will return
KSqlErrSchema to let you know that the cause of the error
was a schema change. Thus any prepared statements that were cached will have to
be discarded and re-prepared following a schema change. Refilling the prepared
statement cache can be as computationally expensive as parsing the schema in
the first place.
Prepared statements can be invalidated for reasons other than schema
changes including executing Attach() or Detach().
Avoid this if you have a large cache of prepared statements. The best strategy
is to attach all associated databases as soon as a new database session is
opened and before any statements are prepared.
SQLite places no arbitrary limits on the number of columns in a table or index. There are known commercial applications using SQLite that construct tables with tens of thousands of columns each. And these applications actually work.
However the database engine is optimized for the common case of tables with no more than a few dozen columns. For best performance you should try to stay in the optimized region. Furthermore, we note that relational databases with a large number of columns are usually not well normalized. So even apart from performance considerations, if you find your design has tables with more than a dozen or so columns, you really need to rethink how you are building your application.
There are a number of places in Prepare() that run in
time O(N2) where N is the number of columns in the
table. The constant of proportionality is small in these cases so you should
not have any problems for N of less than one hundred but for N on the order of
a thousand, the time to run Prepare() can start to become
noticeable.
When the bytecode is running and it needs to access the i-th column of a table, the values of the previous i-1 columns must be accessed first. So if you have a large number of columns, accessing the last column can be an expensive operation. This fact also argues for putting smaller and more frequently accessed columns early in the table.
There are certain optimizations that will only work if the table has 30 or fewer columns. The optimization that extracts all necessary information from an index and never refers to the underlying table works this way. So in some cases, keeping the number of columns in a table at or below 30 can result in a 2-fold speed improvement.
Indexes will only be used if they contain 30 or fewer columns. You can put as many columns in an index as you want, but if the number is greater than 30, the index will never improve performance and will never do anything but take up space in your database file.
One of the key benefits of using an atomic and durable database engine is that you can be responsibly confident that the database will not be corrupted by application crashes or power failures. SQLite is very resistant to database corruption but it is possible to corrupt a database. This section will describe all of the known techniques for corrupting a SQLite database so that you can make sure you avoid them.
A SQLite database is just an ordinary file in the filesystem. If the database is placed in a publicly accessible location then any process can open that file and write nonsense into the middle of it, corrupting the database. Similarly, an operating system malfunction or a hardware fault can cause invalid data to be written into the database file. Both of these issues are beyond the control of SQLite or of application developers. We only mention them here for completeness.
After a power loss or system crash and subsequent system reboot, a rollback journal file will be found in the same directory as the original database. The presence of this rollback journal file is the signal to subsequent users that the database is in an inconsistent state and needs to be restored (by playing back the journal) before it is used. A rollback journal file that is left over after a crash is called a “hot journal”.
If after a post-crash reboot some kind application recovery occurs which deletes, renames, or moves a hot journal, then SQLite will have no way of knowing that a hot journal existed. It will not know that the database is in an inconsistent state and will have no way to restore it. Deleting or renaming a hot journal will result in a corrupted database nearly every time.
The name of the hot journal is related to the name of the original database file. If the database file is renamed this means that SQLite will not see the hot journal based on the original name, no database recovery will be undertaken and the database will become corrupt.
These are all of the known ways for corrupting a SQLite database file, and as you can see, none of these ways are easy to achieve. SQLite databases have proven to be remarkably reliable and trouble-free. By avoiding the above situations you can ensure that your databases will be safe and intact even after system crashes and untimely power failures.
Complex queries sometimes require SQLite to compute intermediate results that are stored in transient tables. Transient tables are nameless entities that exist for the duration of a single SQL statement and are automatically deleted at the conclusion of the statement.
We use the term transient to describe these tables rather than temporary to avoid confusion with TEMP tables. TEMP tables are tables that are private to a particular database connection and which persist for the duration of that database connection. TEMP tables have names and work like regular tables with the exceptions that they are only visible to the current database connection and are automatically deleted when the connection is closed. Transient tables, in contrast, are invisible internal holding areas for intermediate results that exist only until the end of the current SQL statement.
Transient tables will be stored either in RAM or on disk depending on device configuration. The Symbian default configuration is to store transient tables on disk although downstream device manufacturers may alter this.
When configured to store transient tables on disk, in reality a combination of memory and file space is used to hold the table. Transient tables go through the same page cache mechanism that regular database files go through. So as long as the transient tables do not grow too large, they will always be held in memory in the page cache rather than being written to disk. Information is only written to disk when the cache overflows.
When transient tables are configured to be stored in memory rather than in a file, the cache is considered infinitely large and will never overflow and thus nothing will ever be written out to the filesystem. Storing transient tables in memory rather than in files avoids the overhead of file I/O but requires potentially unbounded amounts of memory. Using file-based transient tables puts an upper bound on the amount of memory required but adds file I/O overhead.
One strategy for dealing with transient tables is to avoid them all together. If you never use transient tables then it does not really matter if they are stored in memory or on disk. The remainder of this section will enumerate all of the things that might provoke SQLite to create a transient table. If you avoid all of these things in your code, then you never need to worry about where your transient tables are stored.
A transient table is created whenever you use the DISTINCT keyword in a query:
SELECT DISTINCT name FROM artist;The DISTINCT keyword guarantees that each row of the result set will be different from all other rows. In order to enforce this SQLite creates a transient table that stores all prior output rows from the query. If a new row can be found in the transient table then the new row is skipped. The same situation occurs when DISTINCT is used within an aggregate function:
SELECT avg(DISTINCT cnt) FROM playlist;In this context the DISTINCT keyword means that the aggregate function is only applied to distinct elements of the result. As before, a transient table is used to record prior values of the result so that SQLite can tell if new results have been seen before.
The UNION, INTERSECT, and EXCEPT operators used to create compound queries always generate a distinct set of rows. Even though the DISTINCT keyword does not appear, it is implied for these connectors, and a transient table is used to enforce the distinctness. In contrast, the UNION ALL operator does not require a transient table.
A transient table might be used to implement an ORDER BY or GROUP BY clause. SQLite always tries to use an index to satisfy an ORDER BY or GROUP BY clause if it can. But if no indexes are available which can satisfy the ORDER BY or GROUP BY, then the entire results set is loaded into a transient table and sorted there.
Subqueries on the right-hand side of the IN operator use a transient table. Consider an example:
SELECT * FROM ex334a WHERE id IN (SELECT id FROM ex334b WHERE amt>7);The results of the (SELECT id FROM ex334b WHERE amt>7) subquery are stored in a transient table. Then the value of the id column is checked against this table for each row of the outer query to determine if that row should be included in the result set.
Sometimes subqueries in the FROM clause of a query will result in a transient table. This is not always the case because SQLite tries very hard to convert subqueries in the FROM clause into a join that does not use subqueries. SQLite uses the term flattening to describe the conversion of FROM clause subqueries into joins. Flattening is an optimization that makes queries run faster. But in some cases, flattening cannot occur. When the flattening optimization is inhibited, the results of the subqueries are stored in transient tables and then a separate query is run against those transient tables to generate the final results.
Consider the following schema and query:
CREATE TABLE t1(a,b,c);
CREATE TABLE t2(x,y,z);
SELECT * FROM t1 JOIN (SELECT x,y FROM t2);The subquery in the FROM clause is plainly visible in the SELECT statement above. But if the subquery were disguised as a view, it might be less noticeable. A view is really just a macro that serves as a place-holder for a subquery. So the SELECT statement above is equivalent to the following:
CREATE VIEW v2 AS SELECT x, y FROM t2;
SELECT * FROM t1 JOIN v2;In either case above, whether the subquery is stated explicitly or is implied by the use of a view, flattening occurs and the query is converted into this:
SELECT a,b,c,x,y FROM t1 JOIN t2;Had flattening not occurred, it would have been necessary to evaluate the v2 view or the subquery into a transient table then execute the outer query using the transient table as one of the two tables in the join. SQLite prefers to flatten the query because a flattened query generally uses fewer resources and is better able to take advantage of indexes. The rules for determining when flattening occurs and when it does not are complex. Flattening occurs if all of the following conditions in the outer query and in the subquery are satisfied:
The subquery and the outer query do not both use aggregates.
The subquery is not an aggregate or the outer query is not a join.
The subquery is not the right operand of a left outer join, or the subquery is not itself a join.
The subquery is not DISTINCT or the outer query is not a join.
The subquery is not DISTINCT or the outer query does not use aggregates.
The subquery does not use aggregates or the outer query is not DISTINCT.
The subquery has a FROM clause.
The subquery does not use LIMIT or the outer query is not a join.
The subquery does not use LIMIT or the outer query does not use aggregates.
The subquery does not use aggregates or the outer query does not use LIMIT.
The subquery and the outer query do not both have ORDER BY clauses.
The subquery is not the right term of a LEFT OUTER JOIN or the subquery has no WHERE clause.
The subquery and outer query do not both use LIMIT
The subquery does not use OFFSET
Nobody really expects a programmer to memorize or even understand the above set of flattening rules. As a short-cut, perhaps it is best to remember that a complicated subquery or view in the FROM clause of a complicated query might defeat the flattening optimization and thus require the use of transient tables.
One other obscure use of transient tables is when there is an INSTEAD OF DELETE or INSTEAD OF UPDATE trigger on a view. When such triggers exists and a DELETE or an UPDATE is executed against that view then a transient table is created which stores copies of the rows to be deleted or updated. Since it is unusual to have INSTEAD OF triggers in the first place this case rarely arises.
In summary, transient tables are used to implement the following features:
The DISTINCT keyword or other situations where distinct results are required such as compound queries using UNION, INTERSECT, or EXCEPT.
ORDER BY or GROUP BY clauses that cannot be satisfied by indexes.
Subqueries on the right-hand side of the IN operator.
Subqueries or views in the FROM clause of a query that cannot be flattened.
DELETE or UPDATE against a view with INSTEAD OF triggers.
The resource-limited nature of the environment, where file I/O is expensive and memory is scarce, means you will be well served to avoid these constructs and thus avoid the need for transient tables.
The largest user of memory in SQLite is the page cache which sits
between the b-tree layer and the file system. It keeps copies of every page
that is currently in use as well as copies of recently used pages that might be
reused again in the near future. It does this for the main database file, for
each Attach()ed database, and for the various temporary files used
to implement TEMP and transient tables.
Generally speaking, a larger page cache gives better performance since a larger cache generally reduces the need for file I/O. The pager uses only as much memory as it really needs and so if you are working with a small database or with simple queries, the amount of memory used by the pager is typically much smaller than the maximum.
Note that a separate pager is used for the main database file, the
database file used to hold TEMP tables, each Attach()ed database,
and each transient table. So a good way to hold down the amount of memory used
by the pager is to avoid using TEMP tables, Attach()ed databases,
and transient tables. TEMP tables and Attach()ed databases are
easy to control since they are specified explicitly. Transient tables, on the
other hand, are implicit and so controlling their use is more subtle.
Techniques for limiting the use of transient tables are discussed in section
3.32.
Another big user of memory is the symbol table. When a database session is created, the database schema is parsed into internal data structures that are accessible to the SQL compiler. This symbol table exists for the lifetime of the database connection. The size of the symbol table is roughly proportional to the size of the database schema. For a typical schema, the symbol table size will be less than 20KiB – sometimes much less. But for a really complex schema, the size of the symbol table can be much larger. So it is often best to keep the complexity of the database schema to a minimum. Keeping the schema as simple has the added benefit of making it easier to parse and thus speeding database session setup.
Each prepared statement uses memory that is roughly proportional to
the complexity of the SQL statement it implements. Most prepared statements use
less than 1KiB of memory when they are not running. All the associated memory
is freed when the prepared statement is closed. Prepared statements use some
additional memory when they are running. The additional memory is freed when
the statement is reset using Reset().
Most internal values used during SQL statement execution are stored in pre-allocated space inside the prepared statement. However, additional memory is allocated to store large strings and BLOBs. This additional memory is freed when the use of the string or BLOB ends, and efforts are made to make sure that no unnecessary copies of the string or BLOB are made during processing. But while they are held in memory, strings and BLOBs use memory space proportional to their size.
SQLite does not implement incremental I/O for large strings or BLOBs. The entire string or BLOB must be read or written to the database file all at once. This means that if you have a string or BLOB that is 1MB in size, you must have 1MB of free memory available to read or write the string or BLOB. This argues for storing large strings and BLOBs as separate files in the filesystem and then recording the filename in the database rather than the complete content of the string or BLOB.
SQLite implements the DELETE command using a two-pass algorithm. The first pass determines the RowIDs for all rows in the table that are to be deleted and stores these in memory. The second pass does the actual deleting. Because the first pass of DELETE stores RowIDs to be deleted in memory the DELETE operation uses memory that is proportional to the number of rows to be deleted. This is not normally a problem as each RowID fits in only 8 bytes. But if tens of thousands of rows are being deleted from a table, even 8 bytes per row can be more memory than a mobile device has available. A reasonable workaround is to do the DELETE in two or more smaller chunks.
If you are deleting all rows in a table and the DELETE statement has no WHERE clause, then SQLite uses a special optimization that deletes the entire table all at once without having to loop through and delete each row separately. When this optimization is employed, no memory is used to hold RowIDs. Thus the statement:
DELETE FROM ex335;Is much faster and uses less memory than this statement:
DELETE FROM ex335 WHERE 1;The last memory user in SQLite that is worth mentioning is the page bitmask used by the transaction logic in the pager. Whenever a new transaction is started, the pager has to allocate a chunk of memory that contains 2 bits for every page in the entire database file. On mobile devices, this bitmask is not normally large. A 10MiB database file with 4KiB pages only requires 640 bytes for the bitmask.
|
Copyright © 2005-2008 Symbian Software Ltd. |
|
![[Previous]](../../../../a_stock/images/btn_prev.gif)
![[Top]](../../../../a_stock/images/btn_top.gif)
![[Next]](../../../../a_stock/images/btn_next.gif)