nnet – Ops for neural networks¶
-
tensor.nnet.sigmoid(x)¶ - Returns the standard sigmoid nonlinearity applied to x
Parameters: x - symbolic Tensor (or compatible)
Return type: same as x
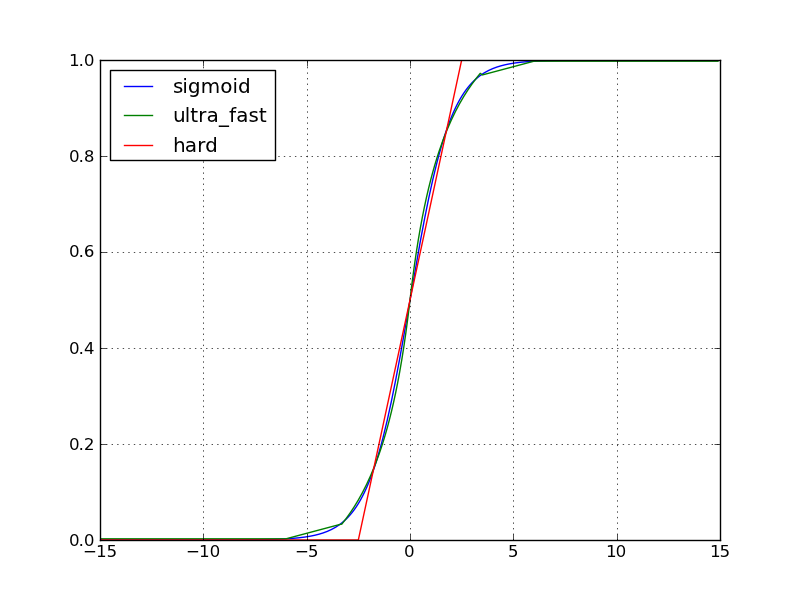
Returns: element-wise sigmoid:
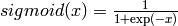 .
.note: see
ultra_fast_sigmoid()orhard_sigmoid()for faster versions. Speed comparison for 100M float64 elements on a Core2 Duo @ 3.16 GHz:- hard_sigmoid: 1.0s
- ultra_fast_sigmoid: 1.3s
- sigmoid (with amdlibm): 2.3s
- sigmoid (without amdlibm): 3.7s
Precision: sigmoid(without or without amdlibm) > ultra_fast_sigmoid > hard_sigmoid.
Example:
import theano.tensor as T x, y, b = T.dvectors('x', 'y', 'b') W = T.dmatrix('W') y = T.nnet.sigmoid(T.dot(W, x) + b)
Note
The underlying code will return an exact 0 or 1 if an element of x is too small or too big.
-
tensor.nnet.ultra_fast_sigmoid(x)¶ - Returns the approximated standard
sigmoid()nonlinearity applied to x. Parameters: x - symbolic Tensor (or compatible) Return type: same as x Returns: approximated element-wise sigmoid: .note: To automatically change all sigmoid()ops to this version, use the Theano optimizationlocal_ultra_fast_sigmoid. This can be done with the Theano flagoptimizer_including=local_ultra_fast_sigmoid. This optimization is done late, so it should not affect stabilization optimization.
Note
The underlying code will return 0.00247262315663 as the minimum value and 0.997527376843 as the maximum value. So it never returns 0 or 1.
Note
Using directly the ultra_fast_sigmoid in the graph will disable stabilization optimization associated with it. But using the optimization to insert them won’t disable the stability optimization.
- Returns the approximated standard
-
tensor.nnet.hard_sigmoid(x)¶ - Returns the approximated standard
sigmoid()nonlinearity applied to x. Parameters: x - symbolic Tensor (or compatible) Return type: same as x Returns: approximated element-wise sigmoid: .note: To automatically change all sigmoid()ops to this version, use the Theano optimizationlocal_hard_sigmoid. This can be done with the Theano flagoptimizer_including=local_hard_sigmoid. This optimization is done late, so it should not affect stabilization optimization.
Note
The underlying code will return an exact 0 or 1 if an element of x is too small or too big.
Note
Using directly the ultra_fast_sigmoid in the graph will disable stabilization optimization associated with it. But using the optimization to insert them won’t disable the stability optimization.
- Returns the approximated standard
-
tensor.nnet.softplus(x)¶ - Returns the softplus nonlinearity applied to x
Parameter: x - symbolic Tensor (or compatible) Return type: same as x Returns: elementwise softplus: 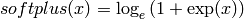 .
.
Note
The underlying code will return an exact 0 if an element of x is too small.
x,y,b = T.dvectors('x','y','b') W = T.dmatrix('W') y = T.nnet.softplus(T.dot(W,x) + b)
-
tensor.nnet.softmax(x)¶ - Returns the softmax function of x:
Parameter: x symbolic 2D Tensor (or compatible). Return type: same as x Returns: a symbolic 2D tensor whose ijth element is 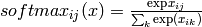 .
.
The softmax function will, when applied to a matrix, compute the softmax values row-wise.
note: this insert a particular op. But this op don’t yet implement the Rop for hessian free. If you want that, implement this equivalent code that have the Rop implemented
exp(x)/exp(x).sum(1, keepdims=True). Theano should optimize this by inserting the softmax op itself. The code of the softmax op is more numeriacaly stable by using this code:e_x = exp(x - x.max(axis=1, keepdims=True)) out = e_x / e_x.sum(axis=1, keepdims=True)
Example of use:
x,y,b = T.dvectors('x','y','b') W = T.dmatrix('W') y = T.nnet.softmax(T.dot(W,x) + b)
-
theano.tensor.nnet.relu(x, alpha=0)¶ Compute the element-wise rectified linear activation function.
Parameters: - x (symbolic tensor) – Tensor to compute the activation function for.
- alpha (scalar or tensor, optional) – Slope for negative input, usually between 0 and 1. The default value of 0 will lead to the standard rectifier, 1 will lead to a linear activation function, and any value in between will give a leaky rectifier. A shared variable (broadcastable against x) will result in a parameterized rectifier with learnable slope(s).
Returns: Element-wise rectifier applied to x.
Return type: symbolic tensor
Notes
This is numerically equivalent to
T.switch(x > 0, x, alpha * x)(orT.maximum(x, alpha * x)foralpha < 1), but uses a faster formulation or an optimized Op, so we encourage to use this function.
-
tensor.nnet.binary_crossentropy(output, target)¶ - Computes the binary cross-entropy between a target and an output:
Parameters: - target - symbolic Tensor (or compatible)
- output - symbolic Tensor (or compatible)
Return type: same as target
Returns: a symbolic tensor, where the following is applied elementwise
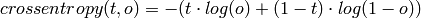 .
.
The following block implements a simple auto-associator with a sigmoid nonlinearity and a reconstruction error which corresponds to the binary cross-entropy (note that this assumes that x will contain values between 0 and 1):
x, y, b, c = T.dvectors('x', 'y', 'b', 'c') W = T.dmatrix('W') V = T.dmatrix('V') h = T.nnet.sigmoid(T.dot(W, x) + b) x_recons = T.nnet.sigmoid(T.dot(V, h) + c) recon_cost = T.nnet.binary_crossentropy(x_recons, x).mean()
-
tensor.nnet.categorical_crossentropy(coding_dist, true_dist)¶ Return the cross-entropy between an approximating distribution and a true distribution. The cross entropy between two probability distributions measures the average number of bits needed to identify an event from a set of possibilities, if a coding scheme is used based on a given probability distribution q, rather than the “true” distribution p. Mathematically, this function computes
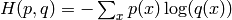 , where
p=true_dist and q=coding_dist.
, where
p=true_dist and q=coding_dist.Parameters: - coding_dist - symbolic 2D Tensor (or compatible). Each row represents a distribution.
- true_dist - symbolic 2D Tensor OR symbolic vector of ints. In the case of an integer vector argument, each element represents the position of the ‘1’ in a 1-of-N encoding (aka “one-hot” encoding)
Return type: tensor of rank one-less-than coding_dist
Note
An application of the scenario where true_dist has a 1-of-N representation is in classification with softmax outputs. If coding_dist is the output of the softmax and true_dist is a vector of correct labels, then the function will compute
y_i = - \log(coding_dist[i, one_of_n[i]]), which corresponds to computing the neg-log-probability of the correct class (which is typically the training criterion in classification settings).y = T.nnet.softmax(T.dot(W, x) + b) cost = T.nnet.categorical_crossentropy(y, o) # o is either the above-mentioned 1-of-N vector or 2D tensor