 |
Cody Kwok
Oren Etzioni
Daniel S. Weld
{ctkwok, etzioni, weld}@cs.washington.edu
University of Washington, Seattle, WA, USA
November 13, 2000
Copyright is held by the author/owner.
WWW10, May 1-5, 2001, Hong Kong.
ACM 1-58113-348-0/01/0005.
The wealth of information on the web makes it an attractive resource for seeking quick answers to simple, factual questions such as ``who was the first American in space?'' or ``what is the second tallest mountain in the world?'' Yet today's most advanced web search services (e.g., Google and AskJeeves) make it surprisingly tedious to locate answers to such questions. In this paper, we extend question-answering techniques, first studied in the information retrieval literature, to the web and experimentally evaluate their performance.
First we introduce MULDER, which we believe to be the first general-purpose, fully-automated question-answering system available on the web. Second, we describe MULDER's architecture, which relies on multiple search-engine queries, natural-language parsing, and a novel voting procedure to yield reliable answers coupled with high recall. Finally, we compare MULDER's performance to that of Google and AskJeeves on questions drawn from the TREC-8 question track. We find that MULDER's recall is more than a factor of three higher than that of AskJeeves. In addition, we find that Google requires 6.6 times as much user effort to achieve the same level of recall as MULDER.
While web search engines and directories have made important strides in recent years, the problem of efficiently locating information on the web is far from solved. This paper empirically investigates the problem of scaling question-answering techniques, studied in the information retrieval and information extraction literature [1,16], to the web. Can these techniques, previously explored in the context of much smaller and more carefully structured corpora, be extended to the web? Will a question-answering system yield benefit when compared to cutting-edge commercial search engines such as Google1?
Our focus is on factual questions such as ``what is the second tallest mountain in the world?'' or ``who was the first American in space?'' While this species of questions represents only a limited subset of the queries posed to web search engines, it presents the opportunity to substantially reduce the amount of user effort required to find the answer. Instead of forcing the user to sift through a list search engine ``snippets'' and read through multiple web pages potentially containing the answer, our goal is to develop a system that concisely answers ``K-2'' or ``Alan Shepard'' (along with the appropriate justification) in response to the above questions.
As a step towards this goal, this paper introduces the MULDER web question-answering system. We believe that MULDER is the first general-purpose, fully-automated question-answering system available on the web.2 The commercial search engine known as AskJeeves3 responds to natural-language questions but its recall is very limited (see Section 4) suggesting that it is not fully automated.
To achieve its broad scope, MULDER automatically submits multiple queries on the user's behalf to a search engine (Google) and extracts its answers from the engine's output. Thus, MULDER is an information carnivore in the sense described in [13]. MULDER utilizes several natural-language parsers and heuristics in order to return high-quality answers.
The remainder of this paper is organized as follows. Section 2 provides background information on question-answering systems and considers the requirements for scaling this class of systems to the web. Section 3 describes MULDER and its architecture. Section 4 compares MULDER's performance experimentally with that of AskJeeves and Google, and also analyzes the contribution of each of MULDER's key components to its performance. We conclude with a discussion of related and future work.
A question answering (QA) system provides direct answers to user questions by consulting its knowledge base. Since the early days of artificial intelligence in the 60's, researchers have been fascinated with answering natural language questions. However, the difficulty of natural language processing (NLP) has limited the scope of QA to domain-specific expert systems.
In recent years, the combination of web growth, improvements in information technology, and the explosive demand for better information access has reignited the interest in QA systems. The availability of huge document collections (e.g., the web itself), combined with improvements in information retrieval (IR) and NLP techniques, has attracted the development of a special class of QA systems that answers natural language questions by consulting a repository of documents [16]. The Holy Grail for these systems is, of course, answering questions over the web. A QA system utilizing this resource has the potential to answer questions of a wide variety of topics, and will constantly be kept up-to-date with the web itself. Therefore, it makes sense to build QA systems that can scale up to the web.
In the following sections, we look at the anatomy of QA systems, and what challenges the web poses for them. We then define what is required of a web-based QA system.
An automated QA system based on a document collection typically has three main components. The first is a retrieval engine that sits on top of the document collection and handles retrieval requests. In the context of web, this is a search engine that indexes web pages. The second is a query formulation mechanism that translates natural-language questions into queries for the IR engine in order to retrieve relevant documents from the collection, i.e., documents that can potentially answer the question. The third component, answer extraction, analyzes these documents and extracts answers from them.
Although the web is full of information, finding the facts sometimes resembles picking needles from a haystack. The following are specific challenges of the web to an automated QA system:
In the next section, we describe a fully implemented prototype web QA system, MULDER, which takes these factors into consideration.
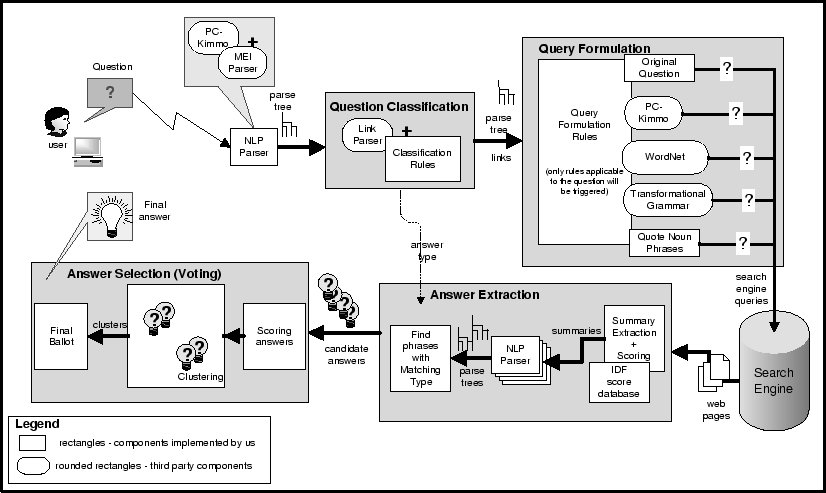
Figure 1 shows the architecture of MULDER. The user begins by asking the question in natural language from MULDER's web interface. MULDER then parses the question using a natural language parser (section 3.1), which constructs a tree of the question's phrasal structure. The parse tree is given to the classifier (section 3.2) which determines the type of answer to expect. Next, the query formulator (section 3.3) uses the parse tree to translate the question into a series of search engine queries. These queries are issued in parallel to the search engine (section 3.4), which fetches web pages for each query. The answer extraction module (section 3.5) extracts relevant snippets called summaries from the web pages, and generates a list of possible candidate answers from these snippets. These candidates are given to the answer selector (section 3.6) for scoring and ranking; the sorted list of answers (presented in the context of their respective summaries) is displayed to the user.
The following sections describe each component in detail.
In contrast to traditional search engines which treat queries as a set of keywords, MULDER parses the user's question to determine its syntactic structure. As we shall see, knowing the structure of the question allows MULDER to formulate the question into several different keyword queries which are submitted to the search engine in parallel, thus increasing recall. Furthermore, MULDER uses the question's syntactic structure to better extract plausible answers from the pages returned by the search engine.
Natural language parsing is a mature field with a decades-long history, so we chose to adopt the best existing parsing technology rather than roll our own. Today's best parsers employ statistical techniques [12,8]. These parsers are trained on a tagged corpus, and they use learned probabilities of word relationships to guide the search for the best parse. The Maximum Entropy-Inspired (MEI) parser [9] is one of the best of this breed, and so we integrated it into MULDER. The parser was trained on the Penn Wall Street Journal tree-bank [21] sections 2-21.
Our overall experience with the parser has been positive, but initially we discovered two problems. First, due to its limited training set the parser has a restricted vocabulary. Second, when the parser does not know a word, it attempts to make educated guesses for the word's part-of-speech. This increases its search space, and slows down parsing.4 In addition, the guesses can be quite bad. In one instance, the parser tagged the word ``tungsten'' as a cardinal number. To remedy both of these problems, we integrated a lexical analyzer called PC-KIMMO [3] into the MEI parser. Lexical analysis allows MULDER to tag previously unseen words. For example, MULDER does not know the word ``neurological'', but by breaking down the word into the root ``neurology'' and the suffix ``-al'', it knows the word is an adjective. When the MEI parser does not know a word, MULDER uses PC-KIMMO to recognize and tag the part-of-speech of the word. If PC-KIMMO also does not know the word either, we adopt the heuristic of tagging the word as a proper noun.
MULDER's combination of MEI/PC-KIMMO and noun defaulting is able to parse all TREC-8 questions correctly.
Question classification allows MULDER to narrow the number of candidate answers during the extraction phase. Our classifier recognizes three types of questions: nominal, numerical and temporal, which correspond to noun phrase, number, and date answers. This simple hierarchy makes classification an easy task and offers the potential of very high accuracy. It also avoids the difficult process of designing a complete question ontology with manually-tuned answer recognizers.
Most natural questions contain a wh-phrase, which consists
of the interrogative word and the subsequent words associated with it.
The MEI parser distinguishes four main types of wh-phrases, and
MULDER makes use of this type information to classify the question.
Wh-adjective phrases, such as ``how many'' and ``how tall'', contain
an adjective in addition to the question words. These questions
inquire about the degree of something or some event, and MULDER classifies them as numerical. Wh-adverb phrases begin with single
question words such as ``where'' or ``when''. We use the
interrogative word to find the question type, e.g., ``when'' is
temporal and ``where'' is nominal. Wh-noun phrases usually begin with
``what'', and the questions can look for any type of answer. For
example, ``what height'' looks for a number, ``what year'' a date, and
``what car'' a noun. We use the object of the verb in the question to
determine the type. To find the object of the verb, MULDER uses the Link
parser [14]. The Link parser is different from the MEI
parser in that it outputs the sentence parse in the form of the
relationships between words (called links) instead of a tree
structure. MULDER uses the verb-object links to find the object in the
question. MULDER then consults WordNet [22] to determine
the type of the object. WordNet is a semantic network containing
words grouped into sets called synsets. Synsets are linked to
each other by different relations, such as synonyms, hypernyms and
meronyms5 To classify the object word, we traverse the
hypernyms of the object until we find the synsets of ``measure'' or
``time''. In the former case, we classify the question as numerical,
and in the latter case temporal. Sometimes a word can have multiple
senses, and each sense may lead to a different classification, e.g.,
``capital'' can be a city or a sum of money. In such cases we assume
the question is nominal. Finally, if the question does not contain a
wh-phrase (e.g., ``Name a film that has won the Golden Bear award
![]() ''), we classify it as nominal.
''), we classify it as nominal.
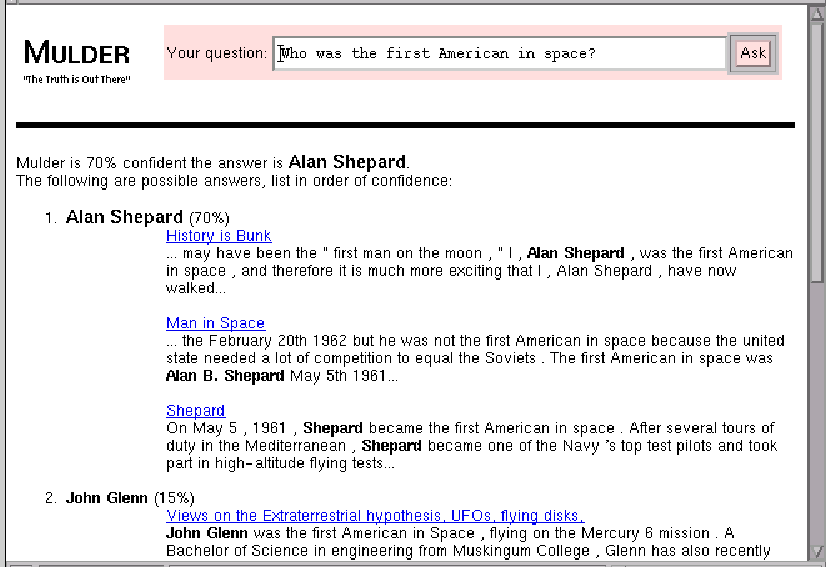
The query formulation module converts the question into a set of keyword queries that will be sent to the search engine for parallel evaluation. MULDER has a good chance of success if it can guess how the answer may appear in a target sentence, i.e. a sentence that contains the answer. We believe this strategy works especially well for questions related to common facts, because these facts are replicated across the web on many different sites, which makes it highly probable that some web page will contain our formulated phrase. To illustrate, one can find the answer to our American-in-space question by issuing the phrase query `` "The first American in space was"''.6 When given this query, Google returns 34 pages, and most of them say ``The first American in space was Alan Shepard,'' with variations of Shepard's name.
A second insight behind MULDER's query formulation method is the idea of varying the specificity of the query. The most general query contains only the most important keywords from the user's question, while the most specific queries are quoted partial sentences. Longer phrases place additional constraints on the the query, increasing precision, but reducing the number of pages returned. If the constraint is too great, then no pages will be returned at all. A priori it is difficult to know the optimal point on the generality/specificity tradeoff, hence our decision to try multiple points in parallel; if a long phrase query fails to return, MULDER can fall back on the more relaxed queries. MULDER currently implements the following reformulation strategies, in order of general to specific:
The actual rules are slightly more complicated in order to handle complex sentences, but the essence is the same.
Since only a subset of these techniques is applicable to each question, for each user question MULDER's query formulation module issues approximately 4 search engine queries on average. We think this is a reasonable load on the search engine. Section 4.4 details experiments that show that reformulation significantly improves MULDER's performance.
Since MULDER depends on the web as its knowledge base, the choice of search engine essentially determines our scope of knowledge, and the method of retrieving that knowledge. The idiosyncrasies of the search engine also affect more than just the syntax of the queries. For example, with Boolean search engines one could issue a query A AND ( B OR C ), but for search engines which do not support disjunction, one must decompose the original query into two, A B and A C, in order to get the same set of pages.
We considered a few search engine candidates, but eventually chose Google. Google has two overwhelming advantages over others: it has the widest coverage among search engines (as of October 2000, Google has indexed 1.2 billion web pages), and its page ranking function is unrivaled. Wider coverage means that MULDER has a larger knowledge base and access to more information. Moreover, with a larger collection we have a higher probability of finding target sentences. Google's ranking function helps MULDER in two ways. First, Google's ranking function is based on the PAGERANK [17] and the HITS algorithms [19], which use random walk and link analysis techniques respectively to determine sites with higher information value. This provides MULDER with a selection of higher quality pages. Second, Google's ranking function is also based on the proximity of words, i.e., if the document has keywords closer together, it will be ranked higher. While this has no effect on queries with long phrases, it helps significantly in cases when we have to rely on keywords.
The answer extraction module is responsible for acquiring candidate answers from the retrieved web pages. In MULDER, answer extraction is a two-step process. First, we extract snippets of text that are likely to contain the answer from the pages. These snippets are called summaries; MULDER ranks them and selects the N best. Next MULDER parses the summaries using the MEI parser and obtains phrases of the expected answer type. For example, after MULDER has retrieved pages from the American-in-space queries, the summary extractor obtains the snippet ``The first American in space was Alan B. Shepard. He made a 15 minute suborbital flight in the Mercury capsule Freedom 7 on May 5, 1961.'' When MULDER parses this snippet, it obtains the following noun phrases, which become candidate answers: ``The first American'', ``Alan B. Shepard'', ``suborbital flight'' and ``Mercury capsule Freedom 7''.
We implemented a summary mechanism instead of extracting answers directly from the web page because the latter is very expensive. The MEI parser takes between a half second for short sentences to three or more for longer sentences, making it impractical to parse every sentence on every web page retrieved. Moreover, regions that are not close to any query keywords are unlikely to contain the answer.
MULDER's summary extractor operates by locating textual regions containing keywords from the search engine queries. In order to bound subsequent parser time and improve efficiency, these regions are limited to at most 40 words and are delimited by sentence boundaries whenever possible. We tried limiting summaries to a single sentence, but this heuristic reduced recall significantly. The following snippet illustrates why multiple sentences are often useful: ``Many people ask who was the first American in space. The answer is Alan Shepard whose suborbital flight made history in 1961.''
After MULDER has extracted summaries from each web page, it scores and ranks
them. The scoring function prefers summaries that contain more important
keywords which are close to each other. To determine the importance of a
keyword, we use a common IR metric known as inverse document
frequency (IDF), which is defined by ![]() ,
where N is the size of a document collection and df
is the number of documents containing the word. The idea is that
unimportant words, such as ``the'' and ``is'', are in almost all documents
while important words occur sparingly. To obtain IDF scores for words, we
collected about 100,000 documents from various online encyclopedias and
computed the IDF score of every word in this collection. For unknown words,
we assume df is 1. To measure how close keywords are to each other, MULDER
calculates the square-root-mean of the distances between keywords. For example,
suppose
,
where N is the size of a document collection and df
is the number of documents containing the word. The idea is that
unimportant words, such as ``the'' and ``is'', are in almost all documents
while important words occur sparingly. To obtain IDF scores for words, we
collected about 100,000 documents from various online encyclopedias and
computed the IDF score of every word in this collection. For unknown words,
we assume df is 1. To measure how close keywords are to each other, MULDER
calculates the square-root-mean of the distances between keywords. For example,
suppose
![]() are the distances between the n keywords in summary s,
then the distance is
are the distances between the n keywords in summary s,
then the distance is
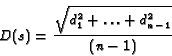
If s has n keywords, each with weight wi, then its score is given by:
MULDER selects the best N summaries and parses them using the MEI parser. To reduce the overall parse time, MULDER runs many instances of the MEI parser on different machines so that parsing can be done in parallel. We also created a quality switch for the parser, so that MULDER can trade quality for time. The parse results are then scanned for the expected answer type (noun phrases, numbers, or dates), and the candidate answers are collected.
The answer selection module picks the best answer among the candidates with a voting procedure. MULDER first ranks the candidates according to how close they are to keywords. It then performs clustering to group similar answers together, and a final ballot is cast for all clusters; the one with the highest score wins. The final answer is chosen from the top candidate in this cluster. For instance, suppose we have 3 answer candidates, ``Alan B. Shepard'', ``Shepard'', and ``John Glenn'', each with scores 2, 1 and 2 respectively. The clustering will result in two groups, one with ``Alan B. Shepard'' and ``Shepard'' and the other with ``John Glenn''. The former is scored 3 and the latter 2, thus MULDER would pick the Shepard cluster as the winner and select ``Alan B. Shepard'' as the final answer.
MULDER scores a candidate answer by its distance from the keywords in
the neighborhood, weighted by how important those keywords are. Let
ki represent a keyword, ai an answer word and ci a word that
does not belong to either category. Furthermore, let wi be the weight
of keyword ki. Suppose we have a string of consecutive keywords
on the left side of the answer candidate beginning at a1, separated by
m unrelated words, i.e.,
![]() ,
MULDER scores the answer by
,
MULDER scores the answer by
After we have assigned scores to each candidate answer, we cluster them into groups. This procedure effects several corrections:
Our clustering mechanism is a simplified version of suffix tree clustering [31]. MULDER simply assigns answers that share the same words into the same cluster. While a complete implementation of suffix tree clustering that handles phrases may give better performance than our simple algorithm, our experience shows word-based clustering works reasonably well.
After the clusters are created, they are ranked according to the sum of the scores of their member answers. The member answer with the highest individual score is chosen as the representative of each cluster.
The sorted list of ranked clusters and their representatives are displayed as the final results to the user. Figure 2 shows MULDER's response to the American-in-space question.
In this section, we evaluate the performance of MULDER by comparing it with two popular and highly-regarded web services, Google (the web's premier search engine) and AskJeeves (the web's premier QA system). In addition, we evaluate how different components contribute to MULDER's performance. Specifically, we study the effectiveness of query formulation, answer extraction and the voting selection mechanism.
AskJeeves allows users to ask questions in natural language. It looks up the user's question in its own database and returns a list of matching questions which it knows how to answer. The user selects the most appropriate entry in the list, and is taken to a web page where the answer will be found. Its database of questions appears to be constructed manually, therefore the corresponding web pages reliably provide the desired answer. We also compare MULDER with Google. Google supplies the web pages that MULDER uses in our current implementation and provides a useful baseline for comparison.
We begin by defining various metrics of our experiment in section 4.1, then in section 4.2 we describe our test question set. In section 4.3, we compare the performance of MULDER with the two web services on the TREC-8 question set. Finally, in section 4.4 we investigate the efficacy of various system components.
The main goal of our experiments is to quantitatively assess MULDER's
performance relative to the baseline provided by Google and AskJeeves.
Traditional information retrieval systems use recall and
precision to measure system performance. Suppose we have a document
collection D, there is a subset R of this collection that is
relevant to a query Q. The retrieval system fetches a subset F of D
for Q. Recall is defined as
![]() and precision
and precision
![]() .
In other words, recall
measures how thorough the system is in locating R. Precision, on the
other hand, measures how many relevant retrieved documents are among
the retrieved set, which can be viewed as a measure of the effort the
user has to expend to find the relevant documents. For example, if
precision is high then, all other things being equal, the user spends
less time sifting through the irrelevant documents to find relevant
ones.
.
In other words, recall
measures how thorough the system is in locating R. Precision, on the
other hand, measures how many relevant retrieved documents are among
the retrieved set, which can be viewed as a measure of the effort the
user has to expend to find the relevant documents. For example, if
precision is high then, all other things being equal, the user spends
less time sifting through the irrelevant documents to find relevant
ones.
In question answering, we can define recall as the percentage of questions answered correctly from the test set. Precision, on the other hand, is inappropriate to measure in this context because a question is answered either correctly or incorrectly.8 Nonetheless, we would still like to measure how much user effort is required to find the answer, not merely what fraction of the time an answer is available.
To measure user effort objectively across the different systems, we need a metric that captures or approximates how much work it takes for the user to reach an answer while reading through the results presented by each system. While the true ``cognitive load'' for each user is difficult to capture, a natural candidate for measuring user effort is time; the longer it takes the user to reach the answer, the more effort is expended on the user's part. However, reading time depends on numerous factors, such as how fast a person reads, how well the web pages are laid out, how experienced the user is with the subject, etc. In addition, obtaining data for reading time would require an extensive user study. Thus, in our first investigation of the feasibility of web QA systems, we chose to measure user effort by the number of words the user has to read from the start of each system's result page until they locate the first correct answer.
Naturally, our measure of user effort is approximate. It does not take into account page layout, users' ability to skip text instead of reading it sequentially, differences in word length, etc. However, it has two important advantages. First, the metric can be computed automatically without requiring an expensive user study. Second, it provides a common way to measure user effort across multiple systems with very different user interfaces.
We now define our metric formally. The word distance metric counts
how many words it takes an idealized user to reach the first correct answer
starting from the top of the system's result page and reading sequentially
towards the bottom. Suppose
![]() are the summary entries
in the results page returned by the system, and di is the web
page linked to by si. We define |t| to be the number of words in the text
t before the answer. If t does not have the answer, then |t| is the
total number of words in t. Finally, let a be the index
of the entry with the answer, thus sa and da are the
first snippet and document containing the answer respectively.
are the summary entries
in the results page returned by the system, and di is the web
page linked to by si. We define |t| to be the number of words in the text
t before the answer. If t does not have the answer, then |t| is the
total number of words in t. Finally, let a be the index
of the entry with the answer, thus sa and da are the
first snippet and document containing the answer respectively.
![]() if the answer is found in sa, since we do not need to view
da if sa already contains the answer.
if the answer is found in sa, since we do not need to view
da if sa already contains the answer.
We now define W(C,P), the word distance of the first correct answer C on a results page P, as follows:
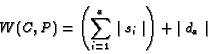
Note that our word distance metric favors Google and AskJeeves by assuming
that the user is able to determine which document di contains the answer
by reading snippets exclusively, allowing her to skip
![]() .
On the other hand, it does assume that people read snippets and
pages sequentially without skipping or employing any kind of ``speed
reading'' techniques. Overall, we feel that this a fair, though
approximate, metric for comparing user effort across the three systems
investigated.
.
On the other hand, it does assume that people read snippets and
pages sequentially without skipping or employing any kind of ``speed
reading'' techniques. Overall, we feel that this a fair, though
approximate, metric for comparing user effort across the three systems
investigated.
It is interesting to note that an average person reads 280 words per minute [27], thus we can use word distance to provide a rough estimate of the time it takes to find the answer.
For our test set, we use the TREC-8 question track which consists of 200 questions of varying type, topic, complexity and difficulty. Some example questions are shown in Table 1.
|
In the original question track, each system is provided with approximately 500,000 documents from the TREC-8 document collection as its knowledge base, and is required to supply a ranked list of candidate answers for each question. The score given to each participant is based on where answers occur in its lists of candidates. The scoring procedure is done by trained individuals. All the questions are guaranteed to have an answer in the collection.
We chose TREC-8 as our test set because its questions are very well-selected, and it allows our work to be put into context with other systems which participated in the track. However, our experiments differ from the TREC-8 question track in four ways. First, MULDER is a QA system based on the web, therefore we do not use the TREC-8 document collection as our knowledge base. Second, because we do not use the original document collection, it is possible that some questions will not have answers. For example, we spent about 30 minutes with Google looking for the answer to ``How much did Mercury spend on advertising in 1993?'' and could not find an answer. Third, since we do not have the resources to score all of our test runs manually, we constructed a list of answers based on TREC-8's relevance judgment file9 and our manual effort. Furthermore, some of TREC-8's answers had to be slightly modified or updated. For example, ``How tall is Mt. Everest?'' can be answered either in meters or feet; ``Donald Kennedy'' was TREC-8's answer to ``Who is the president of Stanford University'', but it is Gerhard Casper at the time of writing.10 Finally, whereas TREC-8 participants are allowed to return a snippet of fixed length text as the answer, MULDER returns the most precise answer whenever possible.
In our first experiment, we compare the user effort required to find the answers in TREC-8 by using MULDER, Google and AskJeeves. User effort is measured using word distance as defined in section 4.1. At each word distance level, we compute the recall for each system. The maximum user effort is bounded at 5000, which represents more than 15 minutes of reading by a normal person. To compare the systems quantitatively, we compute total effort at recall r% by summing up the user effort required from 0% recall up to r%. Figure 3 shows the result of this experiment.
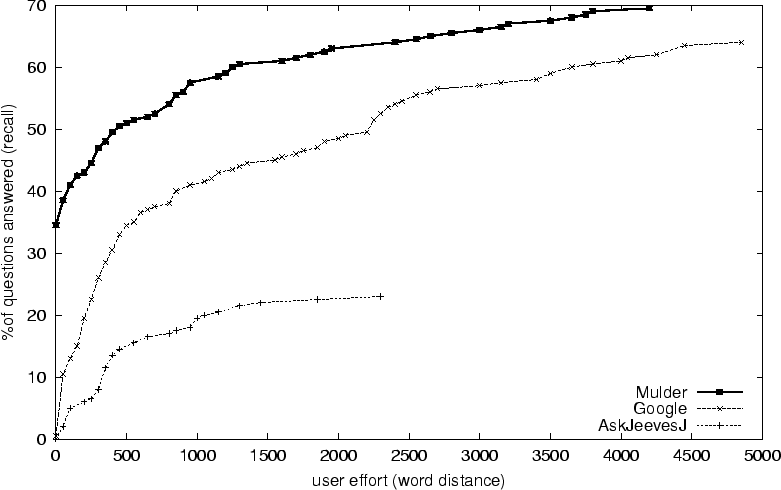 |
The experiment shows that MULDER outperforms both AskJeeves and Google. MULDER consistently requires less user effort to reach an answer than either system at every level of recall. AskJeeves has the lowest level of recall; its maximum is roughly 20%. Google requires 6.6 times more total effort than MULDER at 64.5% recall (Google's maximum recall).
MULDER displayed an impressive ability to answer questions effectively. As figure 3 shows, 34% of the questions have the correct answer as their top-ranked result (as compared with only 1% for Google.) MULDER's recall rises to about 60% at 1000 words. After this point, MULDER's recall per unit effort grows linearly at a rate similar to Google. The questions in this region are harder to answer, and some of the formulated queries from transformations do not retrieve any documents, hence MULDER's performance is similar to that of Google. MULDER still has an edge over Google, however, due to phrased queries and answer extraction. The latter filters out irrelevant text so that users can find answers with MULDER while reading far less text than they would using Google. Finally, MULDER's curve extends beyond this graph to about 10,000 words, ending at 75%. Based on our limited testing, we speculate that of the 25% unanswered questions, about 10% cannot be answered with pages indexed by Google at the time of writing, and the remaining 15% require more sophisticated search strategies.
From our results, we can also see the limited recall of AskJeeves. This suggests that a search engine with a good ranking function and wide coverage is better than a non-automated QA system in answering questions.
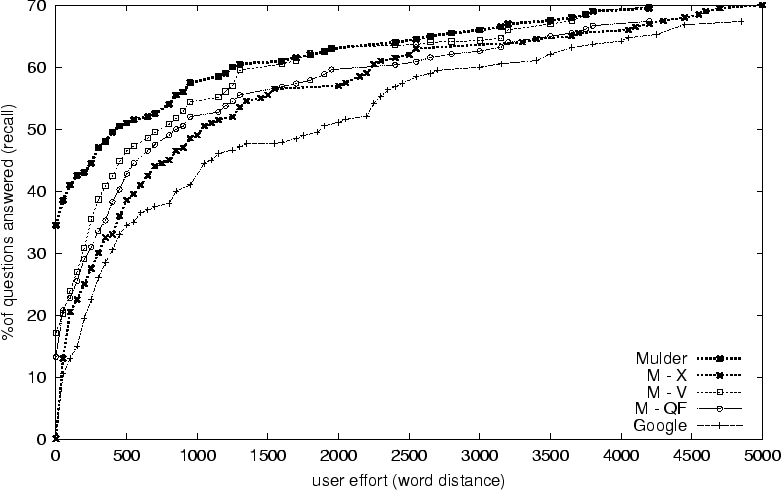 |
Our second experiment investigates the contribution of each component of MULDER to its performance. We compare MULDER to three different variants of itself, each with a single missing component:
In addition, we included Google as a baseline for comparison. As in the first experiment, we compare the systems' performance on recall and user effort. Figure 4 illustrates the results.
|
Figure 4 shows that at all recall levels, systems with missing components perform worse than MULDER, but better than Google. Among them, M-V appears to perform better than M-QF, and M-X trails both. Table 2 shows total user effort for each system as a multiple of MULDER's at 64.5% recall, Google's maximum. The numbers suggest that answer extraction is the most important, followed by query formulation, and voting least. Answer extraction plays a major role in distilling text which saves users a lot of time. Query formulation helps in two ways: first, by forming queries with alternative words that improve the chance of finding answers; second, by getting to the relevant pages sooner. The positive effects of query formulation can also be seen with the improvement in M-X over Google; we expect this effect to be much more pronounced with other less impressive search engines, such as AltaVista11 and Inktomi.12 Finally, voting is the last element that enhances answer extraction. Without voting, M-V only reaches 17% recall at effort 0; with voting, the number is doubled. It is, however, less effective after 1500 words, because it becomes difficult to find any correct answer at that point.
Although question answering systems have a long history in Artificial Intelligence, previous systems have used processed or highly-edited knowledge bases (e.g., subject-relation-object tuples [18], edited lists of frequently asked questions [6], sets of newspaper articles [16], and an encyclopedia [20]) as their foundation. As far as we know, MULDER is the first automated question-answering system that uses the full web as its knowledge base. AskJeeves13 is a commercial service that provides a natural language question interface to the web, but it relies on hundreds of human editors to map between question templates and authoritative sites. The Webclopedia project14 appears to be attacking the same problem as MULDER, but we are unable to find any publications for this system, and from the absence of a functioning web interface, it appears to be still in active development.
START [18] is one of the first QA systems with a web interface, having been available since 1993. Focussed on questions about geography and the MIT InfoLab, START uses a precompiled knowledge base in the form of subject-relation-object tuples, and retrieves these tuples at run time to answer questions. Our experience with the system suggests that its knowledge is rather limited, e.g., it fails on simple queries such as ``What is the third highest mountain in the world?''
The seminal MURAX [20] uses an encyclopedia as a knowledge base in order to answer trivia-type questions. MURAX combines a Boolean search engine with a shallow parser to retrieve relevant sections of the encyclopedia and to extract potential answers. The final answer is determined by investigating the phrasal relationships between words that appear in the question. According to its author MURAX's weak performance stems from the fact that the vector space model of retrieval is insufficient for QA, at least when applied to a large corpus like an encyclopedia.
Recently Usenet FAQ files (collections of frequently asked questions and answers, constructed by human experts) have become a popular choice of knowledge base, because they are small, cover a wide variety of topics, and have high content-to-noise ratio. Auto-FAQ [30] was an early system, limited to a few FAQ files. FAQFinder [6] is a more comprehensive system which uses a vector-space IR engine to retrieve a list of relevant FAQ files from the question. After the user selects a FAQ file from the list, the system proceeds to use question keywords to find a question-answer pair in the FAQ file that best matches the user's question. Question matching is improved by using WordNet [22] hypernyms to expand the possible keywords. Another system [25] uses priority keyword matching to improve retrieval performance. Keywords are divided into different classes depending on their importance and are scored differently. Various morphological and lexical transformations are also applied to words to improve matching. MULDER uses a similar idea by applying IDF scores to estimate the importance of words.
There are also many new QA systems spawning from the TREC-8 QA competition [28], the 1999 AAAI Fall Symposium on Question Answering [10] and the Message Understanding Conferences [1]. Since the TREC-8 competition provides a relatively controlled corpus for information extraction, the objectives and techniques used by these systems are somewhat different from those of MULDER. Indeed, most TREC-8 systems use simple, keyword-based retrieval mechanisms, instead focussing on techniques to improve the accuracy of answer extraction. While effective in TREC-8, such mechanisms do not scale well to the web. Furthermore, these systems have not addressed the problems of noise or incorrect information which plague the web. A lot of common techniques are shared among the TREC-8 systems, most notably a question classification mechanism and name-entity tagging.
Question classification methods analyze a question in order to determine what type of information is being requested so that the system may better recognize an answer. Many systems define a hierarchy of answer types, and use the first few words of the question to determine what type of answer it expects (such as [23,26]). However, building a complete question taxonomy requires excessive manual effort and will not cover all possible cases. For instance, what questions can be associated with many noun subjects, such as what height, what currency and what members. These subjects can also occur in many positions in the question. In contrast, MULDER uses a simple question wh-phrase matching mechanism with combined lexical and semantic processing to classify the subject of the question with high accuracy.
Name-entity (NE) tagging associates a phrase or a word with its semantics. For example, ``Africa'' is associated with ``country'', ``John'' with ``person'' and ``1.2 inches'' with ``length''. Most of the NE taggers are trained on a tagged corpus using statistical language processing techniques, and report relatively high accuracy [4]. QA systems use the NE tagger to tag phrases in the question as well as the retrieved documents. The number of candidate answers can be greatly reduced if the system only selects answers that have the required tag type. Many systems report favorable results with NE tagging, e.g. [26]. We believe a NE tagger would be a useful addition to MULDER, but we also believe a QA system should not rely too heavily on NE tagging, as the number of new terms changes and grows rapidly on the web.
Relationships between words can be a powerful mechanism to recover answers. As mentioned previously, the START system uses subject-relation-object relationships. CL Research's QA system [24] parses all sentences from retrieved documents and forms semantic relation triples which consist of a discourse entity, a semantic relation that characterizes the entity's role in the sentence, and a governing word to which the entity stands in the semantic relation. Another system, described by Harabagiu [15], achieves respectable results for TREC-8 by reasoning with linkages between words, which are obtained from its dependency-based statistical parser [12]. Harabagiu's system first parses the question and the retrieved documents into word linkages. It then transforms these linkages into logical forms. The answer is selected using an inference procedure, supplemented by an external knowledge base. We believe mechanisms of this type would be very useful in reducing the number of answer candidates in MULDER.
Clearly, we need substantially more experimental evaluation to validate MULDER's strong performance in our initial experiments. We plan to compare MULDER against additional search services, and against traditional encyclopedias. In addition, we plan to evaluate MULDER using additional question sets and additional performance metrics. We plan to conduct controlled user studies to gauge the utility of MULDER to web users. Finally, as we have done with previous research prototypes, we plan to gather data on the performance of the deployed version of MULDER in practice.
Many challenges remain ahead of MULDER. Our current implementation utilizes little of the semantic and syntactic information available during answer extraction. We believe our recall will be much higher if these factors are taken into consideration.
There are many elements that can determine the truth of an answer. For example, the last-modified information from web pages can tell us how recent the page and its answer is. The authority of a page is also important, since authoritative sites are likely to have better contents and more accurate answers. In future versions of MULDER we may incorporate these elements into our answer selection mechanism.
We are also implementing our own search engine, and plan to integrate MULDER with its index. We expect that an evaluation of the best data structures and integrated algorithms will provide many challenges. There are many advantages to a local search engine, the most obvious being reduced network latencies for querying and retrieving web pages. We may also improve the efficiency and accuracy for QA with analyses of a large document collection. One disadvantage of a home-grown search engine is our smaller coverage, since we do not have the resources of a commercial search engine. However, with focussed web crawling techniques [7], we may be able to obtain a very high quality QA knowledge base with our limited resources.
In this paper we set out to investigate whether the question-answering techniques studied in classical information retrieval can be scaled to the web. While additional work is necessary to optimize the system so that it can support high workloads with fast response, our initial experiments (reported in Section 4) are encouraging. Our central contributions are the following:
Our work is a step towards the ultimate goal of using the web as a comprehensive, self-updating knowledge repository that can be automatically mined to answer a wide range of questions with much less effort than is required from users interacting with today's search engines.
We thank David Ko and Sam Revitch for their contributions to the project. We also thank Erik Sneiders, Tessa Lau and Yasuro Kawata for their helpful comments. This research was funded in part by Office of Naval Research Grant 98-1-0177, Office of Naval Research Grant N00014-98-1-0147, and by National Science Foundation Grant DL-9874759.