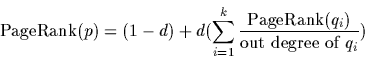
| Ronny Lempel | Aya Soffer | |
| Department of Computer Science | IBM Research Lab in Haifa | |
| The Technion | Matam | |
| Haifa 32000, Israel | Haifa 31905, Israel | |
| [email protected] | [email protected] |
Copyright is held by the author/owner(s).
WWW10, May 1-5, 2001, Hong Kong.
ACM 1-58113-348-0/01/0005.
Keywords: Image Retrieval; Link Structure Analysis; Hubs and Authorities; Image Hubs; PicASHOW.





|






|

 
 

|

 
 

|
![$[M_R]_{i,j} \stackrel{\triangle}{=}m_{i,j} \sqrt{r_t(i)}$](img40.gif) .
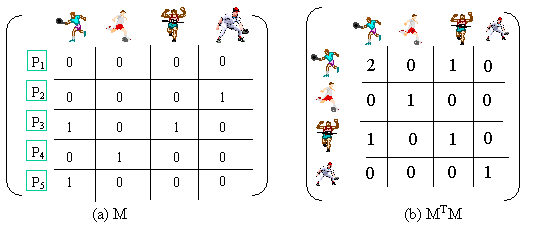
By examining
the t-relevance image co-citation matrix MRTMR, we note
that when M
is unweighted (a binary adjacency matrix),
[MRTMR]i,j
sums the relevance weight of all pages which co-display images
i and j:
.
By examining
the t-relevance image co-citation matrix MRTMR, we note
that when M
is unweighted (a binary adjacency matrix),
[MRTMR]i,j
sums the relevance weight of all pages which co-display images
i and j:
![\begin{eqnarray*}[M_R^T M_R]_{i,j}&=&
\sum_{\{ k:k\leadsto i,k\leadsto j \}}[M_...
...rt{r_t(k)})^2 =
\sum_{\{ k:k\leadsto i,k\leadsto j \}}r_t(k)\\
\end{eqnarray*}](img41.gif)




|





|






|





|

|

|

|

|
|

|

|

|

|

|







|
| URLs of PicASHOW's "Michael Jordan" images |
|
http://views.vcu.edu/~absiddiq/jordan01.gif http://www.geocities.com/Colosseum/Sideline/1534/jordan01.gif http://scnc.sps.k12.mi.us/~powers/jordan01.gif http://www.eng.fsu.edu/~toliver/jordanmovie.gif http://www2.gvsu.edu/%7Ejirtlee/Bettermovingdunk.gif http://sesd.sk.ca/scp/images/AIR_JORDAN.gif (animated gif) |
|
http://www.geocities.com/Colosseum/Sideline/1534/jumper.jpg http://scnc.sps.k12.mi.us/~powers/jumper.jpg http://icdweb.cc.purdue.edu/~fultona/MJ11.jpg |
| http://www.engin.umd.umich.edu/~jafreema/mj/mjpics/jordan5-e.gif |
|
http://www.angelfire.com/ny/Aaronskickasspage/images/1-11.JPG http://homepages.eu.rmit.edu.au/dskiba/mjsmile.jpg http://scnc.sps.k12.mi.us/~woolwor1/jordan.jpg http://www.fidelweb.com/graphic/jordan4.jpg |
| http://www.engin.umd.umich.edu/~jafreema/mj/mjpics/jordan10-e.jpg |
|
http://www.engin.umd.umich.edu/~jafreema/pictures/1991.gif http://metal.chungnam.ac.kr/~myoungho/1991.gif (animated gif) |
| URLs of Scour's "Michael Jordan" images |
| http://www.geocities.com/SunsetStrip/2546/mjjuwan.jpg |
| http://www.geocities.com/SunsetStrip/2546/jordanmvp2.jpg |
| http://www.unc.edu/~lbrooks2/jordan2.jpg |
| http://www.geocities.com/Colosseum/Track/7823/JORDAN_ALLSTAR_1.JPG |
| http://www.big.du.se/~joke/f1-96/pics/car/jordan96_car.jpg |
| http://www.unc.edu/~lbrooks2/mjbugs.jpg |
| URLs of PicASHOW's Van Gogh images |
|
http://www.vangoghgallery.com/images/small/0612.jpg http://vangoghgallery.com/images/small/0612.jpg http://www-scf.usc.edu/~wrivera/vangogh.jpg http://www.openface.ca/~vangogh/images/small/0612.jpg |
|
http://www.vangoghgallery.com/images/small/0627.jpg http://vangoghgallery.com/images/small/0627.jpg http://www.sd104.s-cook.k12.il.us/rhauser/vangoghsel.jpg http://www.openface.ca/~vangogh/images/small/0627.jpg |
|
http://www.vangoghgallery.com/images/intro/1530.jpg http://vangoghgallery.com/images/intro/1530.jpg http://www.openface.ca/~vangogh/images/intro/1530.jpg |
| http://www.bc.edu/bc_org/avp/cas/fnart/art/19th/vangogh/vangoghself3.jpg |
|
http://sunsite.unc.edu/wm/paint/auth/gogh/entrance.jpg http://www.ibiblio.org/wm/paint/auth/gogh/entrance.jpg http://www.southern.com/wm/paint/auth/gogh/entrance.jpg |
|
http://www.bc.edu/bc_org/avp/cas/fnart/art/19th/vangogh/vangogh_starry1.jpg |
| URLs of AltaVista's Vincent Van Gogh images |
| http://www.ElectronicPostcards.com/pc/pics/van12b.jpg |
| http://www.ElectronicPostcards.com/pc/pics/van5b.jpg |
| http://www.ElectronicPostcards.com/pc/pics/van1b.jpg |
| http://www.culturekiosque.com/images5/van.jpg |
| http://www.ElectronicPostcards.com/pc/pics/van6b.jpg |
| http://www.ElectronicPostcards.com/pc/pics/van2b.jpg |
| URLs of PicASHOW's Kilimanjaro images |
|
http://www.calle.com/~carl/brett.kili.jpg http://www.premier.org.uk/graphics/programmes/kili001.jpg |
|
http://www.sfusd.edu/cj/kibo.jpg http://nisus.sfusd.k12.ca.us/cj/kibo.jpg |
| http://www.geocities.com/Yosemite/1015/kili1.jpg |
| http://seclab.cs.ucdavis.edu/~wee/images/kili-summit.gif |
| http://www.geocities.com/Yosemite/1015/kili2.jpg |
| http://www.picton-castle.com/jpg/Kilimanjaro_masai_T.jpg |
| http://www.adventure.co.za/1STPAGEOFKIBO.jpg |
| URLs of PicASHOW's Solar System images |
|
http://oposite.stsci.edu/pubinfo/jpeg/M16Full.jpg http://www.geosci.unc.edu/classes/Geo120/SNsmall.gif http://www.geosci.unc.edu/classes/Geo15/SNsmall.gif 5 |
| http://nssdc.gsfc.nasa.gov/image/planetary/solar_system/family_portraits.jpg |
|
http://www.seds.org/nineplanets/nineplanets/gif/SmallWorlds.gif http://www4.netease.com/~chwu/images/solar_system/nineplanets/SmallWorlds.gif http://www.physics.louisville.edu/tnp/gif/SmallWorlds.gif http://img.iln.net/images/main/astronomy/gif/SmallWorlds.gif http://www-hpcc.astro.washington.edu/mirrors/nineplanets/gif/SmallWorlds.gif http://seds.lpl.arizona.edu/nineplanets/nineplanets/gif/SmallWorlds.gif |
|
http://www.seds.org/nineplanets/nineplanets/NinePlanets.jpg http://kiss.uni-lj.si/~k4fg0152/devetplanetov/xslike/9planetov_x.jpg http://www.physics.louisville.edu/tnp/NinePlanets.jpg http://img.iln.net/images/main/astronomy/NinePlanets.jpg http://www-hpcc.astro.washington.edu/mirrors/nineplanets/NinePlanets.jpg http://seds.lpl.arizona.edu/nineplanets/nineplanets/NinePlanets.jpg |
| http://www.solarviews.com/images/rocketvision.gif (animated gif) |
| http://nssdc.gsfc.nasa.gov/image/planetary/solar_system/solar_family.jpg |
| URLs of Ditto's Solar System images |
| http://www.festivale.webcentral.com.au/shopping/art_com/SYST.jpg |
| http://www.coseti.org/images/12358.jpg |
| http://www.greenbuilder.com/sourcebook/SourcebookGifs/HeatCoolSolar.2.GIF |
| http://www.astro.ufl.edu/aac/icons/solsyt.gif |
| http://connect.ccsn.edu/edu/shs/grant/solar_system.gif |
| http://www.bonus.com/bonus/card/solarsystembrowser/solarsystembrowser.jpg |
| URLs of PicASHOW's Jaguar car images |
| http://www.classicar.com/museums/welshjag/outside.gif |
| http://www.ferrari-transmissions.co.uk/home2.jpg 6 |
| http://www.jtc-nj.com/Doylestowncrowd.jpg |
| http://www.jaguar-association.de/images/verkaufsbilder/12-00-tesch/ss100s-lg.jpg |
| http://www.j-c-c.org.uk/images/drive.jpg |
| http://www.seattlejagclub.org/IMAGES/picyzk.jpg |
| URLs of the Lycos Jaguar car images |
| http://www.auto.com/art/reviews/98_jaguar_xjr/98_Jaguar_XJR_Interior.jpg |
| http://highway-one.com/Images/Photos/Jaguar/LaGrassaJaguar4.jpg |
| http://highway-one.com/Images/Photos/Jaguar/LaGrassaJaguar2.jpg |
| http://highway-one.com/Images/Photos/Jaguar/LaGrassaJaguar.jpg |
| http://highway-one.com/Images/Photos/Jaguar/LaGrassaJaguar3.jpg |