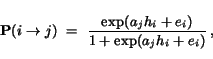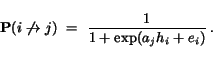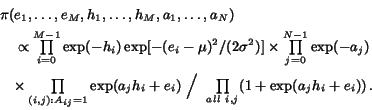WWW10, May 1-5, 2001, Hong Kong. 2001 1-58113-348-0/01/0005
Allan Borodin, Department of Computer Science, University of Toronto, Toronto, Ontario, Canada M5S 3G4, and Gammasite, Hertzilya, Israel. E-mail:
[email protected] Web: http://www.cs.utoronto.ca/DCS/People/Faculty/bor.htmlGareth O. Roberts, Department of Mathematics and Statistics, Lancaster University, Lancaster, U.K. LA1 4YF. E-mail:
[email protected] Web: http://www.maths.lancs.ac.uk/dept/people/robertsg.htmlJeffrey S. Rosenthal, Department of Statistics, University of Toronto, Toronto, Ontario, Canada M5S 3G3. Supported in part by NSERC of Canada. E-mail:
[email protected] Web: http://markov.utstat.toronto.edu/jeffPanayiotis Tsaparas, Department of Computer Science, University of Toronto, Toronto, Ontario, Canada M5S 3G4. E-mail:
[email protected] Web: http://www.cs.toronto.edu/~tsap
Recently, there have been a number of algorithms proposed for analyzing hypertext link structure so as to determine the best "authorities" for a given topic or query. While such analysis is usually combined with content analysis, there is a sense in which some algorithms are deemed to be "more balanced" and others "more focused". We undertake a comparative study of hypertext link analysis algorithms. Guided by some experimental queries, we propose some formal criteria for evaluating and comparing link analysis algorithms.
Keywords: link analysis, web searching, hubs, authorities, SALSA, Kleinberg's algorithm, threshold, Bayesian
In recent years, a number of papers [3,8,11,9,4] have considered the use of hypertext links to determine the value of different web pages. In particular, these papers consider the extent to which hypertext links between World Wide Web documents can be used to determine the relative authority values of these documents for various search queries.
We consider some of the previously published algorithms as well as introducing some new alternatives. One of our new algorithms is based on a Bayesian statistical approach as opposed to the more common algebraic/graph theoretic approach. While link analysis by itself cannot be expected to always provide reliable rankings, it is interesting to study various link analysis strategies in an attempt to understand inherent limitations, basic properties and "similarities" between the various methods. To this end, we offer definitions for several intuitive concepts relating to (link analysis) ranking algorithms and begin a study of these concepts.
We also provide some new (comparative) experimental studies of the performance of the various ranking algorithms. It can be seen that no method is completely safe from "topic drift", but some methods do seem to be more resistant than others. We shall see that certain methods have surprisingly similar rankings as observed in our experimental studies, however they cannot be said to be similar with regard to our formalization.
One of the earliest and most commercially successful of the efforts to use hypertext link structures in web searching is the PageRank algorithm used by Brin and Page [3] in the Google search engine [7].
The page rank of a given web page ![]() , denoted
, denoted ![]() , is defined recursively according to the equation
, is defined recursively according to the equation
![begin{displaymath}PR(i) = d D(i) + (1-d) sum_{j to i} [ PR(j) / N(j) ] ,end{displaymath}](img5.gif)
where the sum is taken over all pages ![]() which have a link to page
which have a link to page ![]() ,
, ![]() is the total number of links originating from page
is the total number of links originating from page ![]() ,
, ![]() is a number between 0 and 1, and
is a number between 0 and 1, and ![]() is a probability distribution (e.g. uniform) over all web pages.
is a probability distribution (e.g. uniform) over all web pages.
Brin and Page [3] note that the value of ![]() is equivalent to the limiting fraction of time spent on page
is equivalent to the limiting fraction of time spent on page ![]() by a random walk which proceeds at each step as follows: With probability
by a random walk which proceeds at each step as follows: With probability ![]() it jumps to a sample from the distribution
it jumps to a sample from the distribution ![]() , and with probability
, and with probability ![]() it jumps uniformly at random to one of the pages linked from the current page. This idea is also used by Rafiei and Mendelzon [11] for computing the "reputation" of a page. Intuitively, the value of
it jumps uniformly at random to one of the pages linked from the current page. This idea is also used by Rafiei and Mendelzon [11] for computing the "reputation" of a page. Intuitively, the value of ![]() is a measure of the importance or authority of the web page
is a measure of the importance or authority of the web page ![]() . This ranking is used as one component of the Google search engine, to help determine how to order the pages returned by a web search query.
. This ranking is used as one component of the Google search engine, to help determine how to order the pages returned by a web search query.
Independent of Brin and Page, Kleinberg [8] proposed a more refined notion for the importance of web pages. He suggested that web page importance should depend on the search query being performed. Furthermore, each page should have a separate "authority" rating (based on the links going to the page) and "hub" rating (based on the links going from the page). Kleinberg proposed first using a text-based web search engine (such as AltaVista [1]) to get a "Root Set" consisting of a short list of web pages relevant to a given query. Second, the Root Set is augmented by pages which link to pages in the Root Set, and also pages which are linked to pages in the Root Set, to obtain a larger `Base Set" of web pages. If ![]() is the number of pages in the final Base Set, then the data for Kleinberg's algorithm consists of an
is the number of pages in the final Base Set, then the data for Kleinberg's algorithm consists of an ![]() adjacency matrix
adjacency matrix ![]() , where
, where ![]() if there are one or more hypertext links from page
if there are one or more hypertext links from page ![]() to page
to page ![]() , otherwise
, otherwise ![]() .
.
Kleinberg's algorithm assigns to each page ![]() an authority weight
an authority weight ![]() and a hub weight
and a hub weight ![]() . Let
. Let ![]()
![]() denote the vector of all authority weights, and
denote the vector of all authority weights, and ![]()
![]() the vector of all hub weights. Initially both authority and hub vectors are set to
the vector of all hub weights. Initially both authority and hub vectors are set to ![]()
![]() . At each iteration the operations
. At each iteration the operations ![]() ("in") and
("in") and ![]() ("out") are performed. The operation
("out") are performed. The operation ![]() sets the authority vector to
sets the authority vector to ![]()
![]()
![]() . The operation
. The operation ![]() sets the hub vector to
sets the hub vector to ![]()
![]()
![]() . A normalization step is then applied, so that the vectors
. A normalization step is then applied, so that the vectors ![]() and
and ![]() become unit vectors in some norm. Kleinberg proves that after a sufficient number of iterations the vectors
become unit vectors in some norm. Kleinberg proves that after a sufficient number of iterations the vectors ![]() and
and ![]() converge to the principal eigenvectors of the matrices
converge to the principal eigenvectors of the matrices ![]() and
and ![]() , respectively. The above normalization step may be performed in various ways. Indeed, ratios such as
, respectively. The above normalization step may be performed in various ways. Indeed, ratios such as ![]() will converge to the same value no matter how (or if) normalization is performed.
will converge to the same value no matter how (or if) normalization is performed.
Kleinberg's Algorithm (and some of the other algorithms we are considering) converge naturally to their principal eigenvector, i.e. to the eigenvector of their transition matrix which corresponds to the largest eigenvalue. Kleinberg [8] makes an interesting (though non-precise) claim that the subsequent non-principal eigenvectors (or their positive and negative components) are sometimes representative of "sub-communities" of web pages. It is easy to construct simple examples which show that subsequent eigenvectors sometimes are, but sometimes are not, indicative of sub-communities; we present a few indicative such examples in the full version of this paper. The significance of non-principal eigenvectors is an important topic that we intend to pursue further.
An alternative algorithm, SALSA, was proposed by Lempel and Moran [9]. Like Kleinberg's algorithm, SALSA starts with a similarly constructed Base Set. It then performs a random walk by alternately (a) going uniformly to one of the pages which links to the current page, and (b) going uniformly to one of the pages linked to by the current page. The authority weights are defined to be the stationary distribution of the two-step chain doing first step (a) and then (b), while the hub weights are defined to be the stationary distribution of the two-step chain doing first step (b) and then (a).
Formally, let ![]() denote the set of all nodes that point to
denote the set of all nodes that point to ![]() , that is, the nodes we can reach from
, that is, the nodes we can reach from ![]() by following a link backwards, and let
by following a link backwards, and let ![]() denote the set of all nodes that we can reach from
denote the set of all nodes that we can reach from ![]() by following a forward link. The Markov Chain for the authorities has transition probabilities
by following a forward link. The Markov Chain for the authorities has transition probabilities
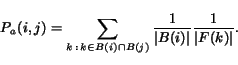
Assume for a moment that the Markov Chain is irreducible, that is, the underlying graph consists of a single connected component. The authors prove that the stationary distribution ![]()
![]()
![]() of the Markov Chain satisfies
of the Markov Chain satisfies ![]() , where
, where ![]() is the set of all (backward) links. Similarly, the Markov Chain for the hubs has transition probabilities
is the set of all (backward) links. Similarly, the Markov Chain for the hubs has transition probabilities
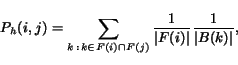
and the stationary distribution ![]()
![]() satisfies
satisfies ![]() , where
, where ![]() is the set of all (forward) links.
is the set of all (forward) links.
SALSA does not really have the same "mutually reinforcing structure" that Kleinberg's algorithm does. Indeed, since ![]() , the relative authority of site
, the relative authority of site ![]() within a connected component is determined from local links, not from the structure of the component. (See also the discussion of locality in Section 7.) We also note that in the special case of a single component, SALSA can be viewed as a one-step truncated version of Kleinberg's algorithm. That is, in the first iteration of Kleinberg's algorithm, if we perform the
within a connected component is determined from local links, not from the structure of the component. (See also the discussion of locality in Section 7.) We also note that in the special case of a single component, SALSA can be viewed as a one-step truncated version of Kleinberg's algorithm. That is, in the first iteration of Kleinberg's algorithm, if we perform the ![]() operation first, the authority weights are set to
operation first, the authority weights are set to ![]()
![]()
![]() , where
, where ![]() is the vector of all ones. If we normalize in the
is the vector of all ones. If we normalize in the ![]() norm, then
norm, then ![]() , which is the stationary distribution of the SALSA algorithm. A similar observation can be made for the hub weights.
, which is the stationary distribution of the SALSA algorithm. A similar observation can be made for the hub weights.
If the underlying graph of the Base Set consists of more than one component, then the SALSA algorithm selects a starting point uniformly at random, and performs a random walk within the connected component that contains that node. Formally, let ![]() be a component that contains node
be a component that contains node ![]() , let
, let ![]() denote the number of nodes in the component, and
denote the number of nodes in the component, and ![]() the set of (backward) links in component
the set of (backward) links in component ![]() . Then, the authority weight of node
. Then, the authority weight of node ![]() is
is
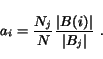
Led astray by the simplifying assumption of a single component, we considered a simplified version of the SALSA algorithm where the authority weight of a node is the ratio ![]() . This corresponds to the case that the starting point for the random walk is chosen with probability proportional to the "popularity" of the node, that is, the number of links that point to this node. We will refer to this variation of the SALSA algorithm as pSALSA (popularity SALSA)
. This corresponds to the case that the starting point for the random walk is chosen with probability proportional to the "popularity" of the node, that is, the number of links that point to this node. We will refer to this variation of the SALSA algorithm as pSALSA (popularity SALSA)![]() . We will consider the original SALSA algorithm as defined in [9] in the full version of our paper.
. We will consider the original SALSA algorithm as defined in [9] in the full version of our paper.
An interesting generalization of the SALSA algorithm is considered by Rafiei and Mendelzon [11]. They propose an algorithm for computing reputations that is a hybrid of the SALSA algorithm, and the PageRank algorithm. At each step, with probability ![]() , the Rafiei and Mendelzon algorithm jumps to a page of the collection chosen uniformly at random, and with probability
, the Rafiei and Mendelzon algorithm jumps to a page of the collection chosen uniformly at random, and with probability ![]() it performs a SALSA step.
it performs a SALSA step.
Cohn and Chang [4] propose a statistical hubs and authorities algorithm, which they call the PHITS Algorithm. They propose a probabilistic model in which a citation ![]() of a document
of a document ![]() is caused by a latent "factor" or "topic",
is caused by a latent "factor" or "topic", ![]() . It is postulated that there are conditional distributions
. It is postulated that there are conditional distributions ![]() of a citation
of a citation ![]() given a factor
given a factor ![]() , and also conditional distributions
, and also conditional distributions ![]() of a factor
of a factor ![]() given a document
given a document ![]() . In terms of these conditional distributions, they produce a likelihood function.
. In terms of these conditional distributions, they produce a likelihood function.
Cohn and Chang then propose using the EM Algorithm of Dempster et al. [5] to assign the unknown conditional probabilities so as to maximize this likelihood function ![]() , and thus best "explain" the proposed data. Their algorithm requires specifying in advance the number of factors
, and thus best "explain" the proposed data. Their algorithm requires specifying in advance the number of factors ![]() to be considered. Furthermore, it is possible that their EM Algorithm could get "stuck" in a local maximum, without converging to the true global maximum.
to be considered. Furthermore, it is possible that their EM Algorithm could get "stuck" in a local maximum, without converging to the true global maximum.
The fact that the output of the first (half) step of the Kleinberg algorithm can be seen as the stationary distribution of a certain random walk on the underlying graph, poses the natural question of whether other intermediary results of Kleinberg's algorithm (and ultimately the output of the algorithm itself) can also be seen as the stationary distribution of a random walk. We show that this is indeed the case.
While Kleinberg's algorithm has some very desirable properties, it also has its limitations. One potential problem is the possibility of severe "topic drift". Roughly, Kleinberg's algorithm converges to the most "tightly-knit" community within the Base Set. It is possible that this tightly-knit community will have little or nothing to do with the proposed query topic.
A striking example of this phenomenon is provided by Cohn and Chang ([4], p. 6). They use Kleinberg's Algorithm with the search term "jaguar" (an example query suggested by Kleinberg [8]), and converge to a collection of sites about the city of Cincinnati! They determine that the cause of this is a large number of on-line newspaper articles in the Cincinnati Enquirer which discuss the Jacksonville Jaguars football team, and all link to the same standard Cincinnati Enquirer service pages. Interestingly, in a preliminary experiment with the query term "abortion" (another example query suggested by Kleinberg [8]), we also found the Kleinberg Algorithm converging to a collection of web pages about the city of Cincinnati!
Now, in both these cases, we believe it is possible to eliminate such errant behavior through more careful selection of the Base Set, and more careful elimination of intra-domain hypertext links. Nevertheless, we do feel that these examples point to a certain "instability" of Kleinberg's Algorithm.
We propose here a small modification of Kleinberg's algorithm to help remedy the above-mentioned instability. For motivation, consider the following. Suppose there are ![]() authority pages, and
authority pages, and ![]() hub pages, with
hub pages, with ![]() large. The first
large. The first ![]() hubs link only to the first authority, while the final hub links to all
hubs link only to the first authority, while the final hub links to all ![]() authorities. In such a set-up, we would expect the first authority to be considered much more authoritative than all the others, and Kleinberg's algorithm does indeed do this. On the other hand, it seems that the final hub should be worse than the others, since in addition to linking to a good authority (the first authority), it also links to many bad authorities. However, according to Kleinberg's algorithm, it is the best hub, 5pt because linking to more things can only improve your hub rating.
authorities. In such a set-up, we would expect the first authority to be considered much more authoritative than all the others, and Kleinberg's algorithm does indeed do this. On the other hand, it seems that the final hub should be worse than the others, since in addition to linking to a good authority (the first authority), it also links to many bad authorities. However, according to Kleinberg's algorithm, it is the best hub, 5pt because linking to more things can only improve your hub rating.
Inspired by such considerations, we propose an algorithm which is a "hybrid" of the Kleinberg and SALSA algorithms. Namely, it does the authority rating updates ![]() just like Kleinberg (i.e., giving each authority a rating equal to the sum of the hub ratings of all the pages that link to it), but does the hub rating updates
just like Kleinberg (i.e., giving each authority a rating equal to the sum of the hub ratings of all the pages that link to it), but does the hub rating updates ![]() by instead giving each hub a rating equal to the average of the authority ratings of all the pages that it links to. With this modified "Hub-Averaging" algorithm, a hub is better if it links to only good authorities, rather than linking to both good and bad authorities.
by instead giving each hub a rating equal to the average of the authority ratings of all the pages that it links to. With this modified "Hub-Averaging" algorithm, a hub is better if it links to only good authorities, rather than linking to both good and bad authorities.
We propose two different "threshold" modifications to Kleinberg's Algorithm. The first modification, Hub-Threshold, is applied to the in-step ![]() . When computing the authority weight of the
. When computing the authority weight of the ![]() page, this algorithm does not take into account all hubs that point to page
page, this algorithm does not take into account all hubs that point to page ![]() . It only counts those hubs whose hub weight is at least the average hub weight over all the hubs that point to page
. It only counts those hubs whose hub weight is at least the average hub weight over all the hubs that point to page ![]() , computed using the current hub weights for the nodes. This corresponds to saying that a site should not be considered a good authority simply because a lot of very poor hubs point to it.
, computed using the current hub weights for the nodes. This corresponds to saying that a site should not be considered a good authority simply because a lot of very poor hubs point to it.
The second modification, Authority-Threshold, is applied to the out-step ![]() . When computing the hub weight of the
. When computing the hub weight of the ![]() page, this algorithm does not take into account all authorities pointed to by page
page, this algorithm does not take into account all authorities pointed to by page ![]() . It only counts those authorities which are among the top
. It only counts those authorities which are among the top ![]() authorities, judging by current authority values. The value of
authorities, judging by current authority values. The value of ![]() is passed as a parameter to the algorithm. This corresponds to saying that a site should not be considered a good hub simply because it points to a number of "acceptable" authorities; rather, to be considered a good hub the site must point to some of the best authorities. This is inspired partially by the fact that, in most web searches, a user only visits the top few authorities.
is passed as a parameter to the algorithm. This corresponds to saying that a site should not be considered a good hub simply because it points to a number of "acceptable" authorities; rather, to be considered a good hub the site must point to some of the best authorities. This is inspired partially by the fact that, in most web searches, a user only visits the top few authorities.
We also consider a Full-Threshold algorithm, which makes both the Hub-Threshold and Authority-Threshold modifications to Kleinberg's Algorithm.
When the pSALSA algorithm computes the authority weight of a page, it takes into account only the popularity of this page within its immediate neighborhood, disregarding the rest of the graph. On the other hand, the Kleinberg algorithm considers the whole graph, taking into account more the structure of the graph around the node, than the popularity of that node in the graph. Specifically, after ![]() steps, the authority weight of the
steps, the authority weight of the ![]() authority is
authority is ![]() , where
, where ![]() is the number of
is the number of ![]() paths that leave node
paths that leave node ![]() . Another way to think of this is that the contribution of a node
. Another way to think of this is that the contribution of a node ![]() to the weight of
to the weight of ![]() is equal to the number of
is equal to the number of ![]() paths that go from
paths that go from ![]() to
to ![]() . Therefore, if a small bipartite component intercepts the path between node
. Therefore, if a small bipartite component intercepts the path between node ![]() and
and ![]() , the contribution of node
, the contribution of node ![]() will increase exponentially fast. This may not always be desirable, especially if the bipartite component is not representative of the query.
will increase exponentially fast. This may not always be desirable, especially if the bipartite component is not representative of the query.
We propose the Breadth-First-Search (BFS) algorithm, as a generalization of the pSALSA algorithm, and a restriction of the Kleinberg algorithm. The BFS algorithm extends the idea of popularity that appears in pSALSA from a one link neighborhood to an ![]() -link neighborhood. However, instead of considering the number of
-link neighborhood. However, instead of considering the number of ![]() paths that leave
paths that leave ![]() , it considers the number of
, it considers the number of ![]() neighbors of node
neighbors of node ![]() . We let
. We let ![]() denote the set of nodes that can be reached from
denote the set of nodes that can be reached from ![]() by following a
by following a ![]() path. The contribution of node
path. The contribution of node ![]() to the weight of node
to the weight of node ![]() depends on the distance of the node
depends on the distance of the node ![]() from
from ![]() . We adopt an exponentially decreasing weighting scheme. Therefore, the weight of node
. We adopt an exponentially decreasing weighting scheme. Therefore, the weight of node ![]() is determined as follows:
is determined as follows:
The algorithm starts from node ![]() , and visits its neighbors in BFS order. At each iteration it takes a Backward or a Forward step (depending on whether it is an odd, or an even iteration), and it includes the new nodes it encounters. The weight factors are updated accordingly. Note that each node is considered only once, when it is first encountered by the algorithm.
, and visits its neighbors in BFS order. At each iteration it takes a Backward or a Forward step (depending on whether it is an odd, or an even iteration), and it includes the new nodes it encounters. The weight factors are updated accordingly. Note that each node is considered only once, when it is first encountered by the algorithm.
A different type of algorithm is given by a fully Bayesian statistical approach to authorities and hubs. Suppose there are ![]() hubs and
hubs and ![]() authorities (which could be the same set). We suppose that each hub
authorities (which could be the same set). We suppose that each hub ![]() has an (unknown) real parameter
has an (unknown) real parameter ![]() , corresponding to its "general tendency to have hypertext links", and also an (unknown) non-negative parameter
, corresponding to its "general tendency to have hypertext links", and also an (unknown) non-negative parameter ![]() , corresponding to its "tendency to have intelligent hypertext links to authoritative sites". We further suppose that each authority
, corresponding to its "tendency to have intelligent hypertext links to authoritative sites". We further suppose that each authority ![]() has an (unknown) non-negative parameter
has an (unknown) non-negative parameter ![]() , corresponding to its level of authority.
, corresponding to its level of authority.
Our statistical model is as follows. The a priori probability of a link from hub ![]() to authority
to authority ![]() is given by
is given by
with the probability of no link from ![]() to
to ![]() given by
given by
This reflects the idea that a link is more likely if ![]() is large (in which case hub
is large (in which case hub ![]() has large tendency to link to any site), or if both
has large tendency to link to any site), or if both ![]() and
and ![]() are large (in which case
are large (in which case ![]() is an intelligent hub, and
is an intelligent hub, and ![]() is a high-quality authority).
is a high-quality authority).
To complete the specification of the statistical model from a Bayesian point of view (see, e.g., Bernardo and Smith [2]), we must assign prior distributions to the ![]() unknown parameters
unknown parameters ![]() ,
, ![]() , and
, and ![]() . (These priors should be general and uninformative, and should not depend on the observed data. For large graphs, the choice of priors should have only a small impact on the results.) To do this, we let
. (These priors should be general and uninformative, and should not depend on the observed data. For large graphs, the choice of priors should have only a small impact on the results.) To do this, we let ![]() and
and ![]() be fixed parameters, and let each
be fixed parameters, and let each ![]() have prior distribution
have prior distribution ![]() , a normal distribution with mean
, a normal distribution with mean ![]() and variance
and variance ![]() . We further let each
. We further let each ![]() and
and ![]() have prior distribution
have prior distribution ![]() (since they have to be non-negative), meaning that for
(since they have to be non-negative), meaning that for ![]() ,
, ![]() .
.
The (standard) Bayesian inference method then proceeds from this fully-specified statistical model, by conditioning on the observed data, which in this case is the matrix ![]() of actual observed hypertext links in the Base Set. Specifically, when we condition on the data
of actual observed hypertext links in the Base Set. Specifically, when we condition on the data ![]() we obtain a posterior density
we obtain a posterior density ![]() for the parameters
for the parameters ![]() . This density is defined so that
. This density is defined so that
for any (measurable) subset ![]() , and also
, and also
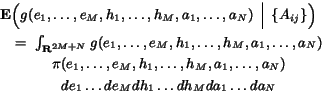
for any (measurable) function ![]() . An easy computation gives the following.
. An easy computation gives the following.
Our Bayesian algorithm then reports the conditional means of the ![]() parameters, according to the posterior density
parameters, according to the posterior density ![]() . That is, it reports final values
. That is, it reports final values ![]() ,
, ![]() , and
, and ![]() , where, for example
, where, for example
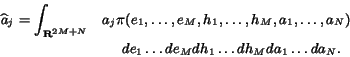
To actually compute these conditional means is non-trivial. To accomplish this, we used a Metropolis Algorithm. (The Metropolis algorithm is an example of a Markov chain Monte Carlo Algorithm; for background see, e.g., Smith and Roberts [13]; Tierney [14]; Gilks et al. [6]; Roberts and Rosenthal [12]).
There is, of course, some arbitrariness in the specification of this Bayesian algorithm, e.g., in the form of the prior distributions and in the precise formula for the probability of a link from ![]() to
to ![]() . However, the model appears to work well in practice, as our experiments show. We note that it is possible that the priors for a new search query could instead depend on the performance of hub
. However, the model appears to work well in practice, as our experiments show. We note that it is possible that the priors for a new search query could instead depend on the performance of hub ![]() on different previous searches, though we do not pursue that here.
on different previous searches, though we do not pursue that here.
This Bayesian algorithm is similar in spirit to the PHITS algorithm of Cohn and Chang [4] described earlier, in that both use statistical modeling, and both use an iterative algorithm to converge to an answer. However, the algorithms differ substantially in their details. Firstly, they use substantially different statistical models. Secondly, the PHITS algorithm uses a non-Bayesian (i.e. "classical" or "frequentist") statistical framework, as opposed to the Bayesian framework adopted here.
It is possible to simplify the above Bayesian model, by replacing equation (2) with ![]() and correspondingly replace equation (3) with
and correspondingly replace equation (3) with ![]() . This eliminates the parameters
. This eliminates the parameters ![]() entirely, so that we no longer need the prior values
entirely, so that we no longer need the prior values ![]() and
and ![]() .
.
This leads to a slightly modified posterior density ![]() , now given by
, now given by ![]() where
where
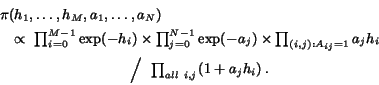
This Simplified Bayesian algorithm was designed to be to similar to the original Bayesian algorithm. Surprisingly, we will see that experimentally it often performs very similarly to the pSALSA algorithm.
We have implemented the algorithms presented here on various queries. Because of space limitations we only report here (see Appendix A) a representative subset of results; all of our results (including the queries "death penalty", "computational complexity" and "gun control" which are not reported here) can be obtained at
http://www.cs.toronto.edu/![]() tsap/experiments. The reader may find it easier to follow the discussion in the next section by accessing the full set of results. For the generation of the Base Set of pages, we follow the specifications of Kleinberg [8] described earlier. For each of the queries, we begin by generating a Root Set that consists of the first 200 pages returned by AltaVista on the same query. The Root Set is then expanded to the Base Set by including nodes that point to, or are pointed to, by the pages in the Root Set. In order to keep the size of the Base Set manageable, for every page in the Root Set, we only include the first 50 pages returned from AltaVista that point to this page. We then construct the graph induced by nodes in the Base Set, by discovering all links among the pages in the Base Set, eliminating those that are between pages of the same domain
tsap/experiments. The reader may find it easier to follow the discussion in the next section by accessing the full set of results. For the generation of the Base Set of pages, we follow the specifications of Kleinberg [8] described earlier. For each of the queries, we begin by generating a Root Set that consists of the first 200 pages returned by AltaVista on the same query. The Root Set is then expanded to the Base Set by including nodes that point to, or are pointed to, by the pages in the Root Set. In order to keep the size of the Base Set manageable, for every page in the Root Set, we only include the first 50 pages returned from AltaVista that point to this page. We then construct the graph induced by nodes in the Base Set, by discovering all links among the pages in the Base Set, eliminating those that are between pages of the same domain![]() .
.
For each query, we tested nine different algorithms on the same Base Set. We present the top ten authority sites returned by each of the algorithms. For evaluation purposes, we also include a list of the URL and title (possibly abbreviated) of each site which appears in the top five of one or more of the algorithms. For each page we also note the popularity of the page (denoted pop in the tables), that is, the number of different algorithms that rank it in the top ten sites. The pages that seem (to us) to be generally unrelated with the topic in hand appear bold-faced. We also present an "intersection table" which provides, for each pair of algorithms, the number of sites which were in the top ten according to both algorithms (maximum 10, minimum 0).
In the tables, SBayesian denotes the Simplified Bayesian algorithm, HubAvg denotes the Hub-Averaging Kleinberg algorithm, AThresh denotes the Authority-Threshold algorithm, HThresh denotes the Hub-Threshold algorithm, and FThresh denotes the Full-Threshold algorithm. For the
Authority-Threshold and Full-Threshold algorithms, we (arbitrarily) set the threshold ![]() .
.
We observe from the experiments that different algorithms emerge as the "best" for different queries, while there are queries for which no algorithm seems to perform well. One prominent such case is the query on "net censorship" (also on "computational complexity") where only a few of the top ten pages returned by any of the algorithms can possibly be considered as authoritative on the subject. One possible explanation is that in these cases the topic is not well represented on the web, or there is no strong interconnected community. This reinforces a common belief that any commercial search engine cannot rely solely on link information, but rather must also examine the text content of sites to prevent such difficulties as "topic drift". On the other hand, in cases such as "death penalty" (not shown here), all algorithms converge to almost the same top ten pages, which are both relevant and authoritative. In these cases the community is well represented, and strongly interconnected.
The experiments also indicate the difference between the behavior of the Kleinberg algorithm and pSALSA, first observed for the SALSA algorithm in the original paper of Lempel and Moran [9]. Specifically, when computing the top authorities, the Kleinberg algorithm tends to concentrate on a "tightly knit community" of nodes (the TKC effect), while pSALSA, like SALSA, tends to mix the authorities of different communities in the top authorities. The TKC effect becomes clear in the "genetic" query, where the Kleinberg algorithm only reports pages on biology in the top ten while pSALSA mixes these pages with pages on genetic algorithms. It also becomes poignantly clear in the "movies" query (and also in the "gun control" and the "abortion" query), where the top ten pages reported by the Kleinberg algorithm are dominated by an irrelevant cluster of nodes from the about.com community. A more elaborate algorithm for detecting intra-domain links could help alleviate this problem. However, these examples seem indicative of the topic drift potential of the principal eigenvector in the Kleinberg algorithm.
On the other hand, the limitations of the pSALSA algorithm become obvious in the "computational geometry" query, where three out of the top ten pages belong to the unrelated w3.com community. They appear in the top positions because they are pointed to by a large collection of pages by ACM, which point to nothing else. A similar phenomenon explains the appearance of the "Yahoo!" page in the "genetic" query. We thus see that the simple heuristic of counting the in-degree as the authority weight is also imperfect.
We identify two types of characteristic behavior: the Kleinberg behavior, and the pSALSA behavior. The former ranks the authorities based on the structure of the entire graph, and tends to favor the authorities of tightly knit communities. The latter ranks the authorities based on their popularity in their immediate neighborhood, and favors various authorities from different communities. To see how the rest of the algorithms fit within these two types of behaviors, we compare the behavior of algorithms on a pairwise basis, using the number of intersections in their respective top ten authorities as an indication of agreement.
The first striking observation is that the Simplified Bayesian algorithm is almost identical to the pSALSA algorithm. The pSALSA algorithm and the Simplified Bayesian have at least ![]() overlap on all queries. One possible explanation for this is that both algorithms place great importance on the in-degree of a node when determining the authority weight of a node. For the pSALSA algorithm we know that it is "local" in nature, that is, the authority weight assigned to a node depends only on the links that point to this node, and not on the structure of the whole graph. The Simplified Bayesian seems to possess a similar, yet weaker property; we explore the locality issue further in the next section. On the other hand, the Bayesian algorithm appears to resemble both the Kleinberg and the pSALSA behavior, leaning more towards the first. Indeed, although the Bayesian algorithm avoids the severe topic drift in the "movies" and the "gun control" queries (but not in the "abortion" case), it usually has higher intersection numbers with Kleinberg than with pSALSA. One possible explanation for this observation is the presence of the
overlap on all queries. One possible explanation for this is that both algorithms place great importance on the in-degree of a node when determining the authority weight of a node. For the pSALSA algorithm we know that it is "local" in nature, that is, the authority weight assigned to a node depends only on the links that point to this node, and not on the structure of the whole graph. The Simplified Bayesian seems to possess a similar, yet weaker property; we explore the locality issue further in the next section. On the other hand, the Bayesian algorithm appears to resemble both the Kleinberg and the pSALSA behavior, leaning more towards the first. Indeed, although the Bayesian algorithm avoids the severe topic drift in the "movies" and the "gun control" queries (but not in the "abortion" case), it usually has higher intersection numbers with Kleinberg than with pSALSA. One possible explanation for this observation is the presence of the ![]() parameters in the Bayesian algorithm (but not the Simplified Bayesian algorithm), which "absorb" some of the effect of many links pointing to a node, thus causing the authority weight of a node to be less dependent on its in-degree.
parameters in the Bayesian algorithm (but not the Simplified Bayesian algorithm), which "absorb" some of the effect of many links pointing to a node, thus causing the authority weight of a node to be less dependent on its in-degree.
Another algorithm that seems to combine characteristics of both the pSALSA and the Kleinberg behavior is the Hub-Averaging algorithm. The Hub-Averaging algorithm is by construction a hybrid of the two since it alternates between one step of each algorithm. It shares certain behavior characteristics with the Kleinberg algorithm: if we consider a full bipartite graph, then the weights of the authorities increase exponentially fast for Hub-Averaging (the rate of increase, however, is the square root of that of the Kleinberg algorithm). However, if the component becomes infiltrated, by making one of the hubs point to a node outside the component, then the weights of the authorities in the component drop. This prevents the Hub-Averaging algorithm from completely following the drifting behavior of the Kleinberg algorithm in the "movies" query. Nevertheless, in the "genetic" query, Hub-Averaging agrees strongly with Kleinberg, focusing on sites of a single community, instead of mixing communities as does pSALSA![]() . On the other hand, Hub-Averaging and pSALSA share a common characteristic, since the Hub-Averaging algorithm tends to favor nodes with high in-degree: if we consider an isolated component of one authority with high in-degree, the authority weight of this node will increase exponentially fast. This explains the fact that the top three authorities for "computational geometry" are the w3.com pages that are also ranked highly by pSALSA (with Hub-Averaging giving a very high weight to all three authorities).
. On the other hand, Hub-Averaging and pSALSA share a common characteristic, since the Hub-Averaging algorithm tends to favor nodes with high in-degree: if we consider an isolated component of one authority with high in-degree, the authority weight of this node will increase exponentially fast. This explains the fact that the top three authorities for "computational geometry" are the w3.com pages that are also ranked highly by pSALSA (with Hub-Averaging giving a very high weight to all three authorities).
For the threshold algorithms, since they are modifications of the Kleinberg Algorithm, they are usually closer to the Kleinberg behavior. This is especially true for the Hub-Threshold algorithm. However, the benefit of eliminating unimportant hubs when computing authorities becomes obvious in the "abortion" query. If one looks further than the first ten pages returned by Kleinberg, one observes that after the first nine pages, which belong to the amazon.com community, the rest of the pages are on topic. The Hub-Threshold algorithm escapes this cluster, and moves directly to the relevant pages. The intersection between the top ten pages of Hub-Threshold, and the set of pages in the positions 10 to 20 in the Kleinberg algorithm is ![]() .
.
The Authority-Threshold often appears to be most similar with the Hub-Averaging algorithm. This makes sense since these two algorithms have a similar underlying motivation. The best moment for Authority-Threshold is the "movies" query, where it reports the most relevant top ten pages among all algorithms. The Full-Threshold algorithm combines elements of both the Threshold algorithms; however, usually it reports in the top ten a mixture of the results of the two algorithms, rather than the best of the two.
Finally, the BFS algorithm is designed to be a generalization of the pSALSA algorithm, that combines some elements of the Kleinberg algorithm. Its behavior resembles both pSALSA and Kleinberg, with a tendency to favor pSALSA. In the "genetic" and "abortion" queries it demonstrates some mixing, but to a lesser extent than that of pSALSA. The most successful moments for BFS are the "abortion" and the "gun control" queries where it reports a set of top ten pages that are all on topic. An interesting question to investigate is how the behavior of the BFS algorithm is altered if we change the weighting scheme of the neighbors.
The experimental results of the previous section suggest that certain algorithms seem to share similar properties and ranking behavior. In this section, we initiate a (preliminary) formal study of fundamental properties and comparisons between ranking algorithms. For the purpose of following analysis we need some basic definitions and notation. Let ![]() be a collection of graphs of size
be a collection of graphs of size ![]() . One special case is to let
. One special case is to let ![]() be the set of all graphs of size
be the set of all graphs of size ![]() , hereafter denoted
, hereafter denoted ![]() . We define a link analysis algorithm
. We define a link analysis algorithm ![]() as a function that maps a graph
as a function that maps a graph ![]() to an
to an ![]() -dimensional vector. We call the vector
-dimensional vector. We call the vector ![]() the weight vector of algorithm
the weight vector of algorithm ![]() on graph
on graph ![]() . The value of the entry
. The value of the entry ![]() of vector
of vector ![]() denotes the authority weight assigned by the algorithm
denotes the authority weight assigned by the algorithm ![]() to the page
to the page ![]() .
.
We can normalize the weight vector ![]() under some chosen norm. The choice of normalization affects the definition of some of the properties of the algorithms, so we discriminate between algorithms that use different norms. For any norm
under some chosen norm. The choice of normalization affects the definition of some of the properties of the algorithms, so we discriminate between algorithms that use different norms. For any norm ![]() , we define the
, we define the ![]() -algorithm
-algorithm ![]() to be the algorithm
to be the algorithm ![]() , where the weight vector of
, where the weight vector of ![]() is normalized under
is normalized under ![]() . We also examine unnormalized algorithms, where no normalization is performed at any stage of the algorithm. For example, the unnormalized pSALSA algorithm assigns a weight to page
. We also examine unnormalized algorithms, where no normalization is performed at any stage of the algorithm. For example, the unnormalized pSALSA algorithm assigns a weight to page ![]() equal to the in-degree of page
equal to the in-degree of page ![]() . For the following discussion, when not stated explicitly, we will assume that the weight vectors of the algorithms are normalized under the
. For the following discussion, when not stated explicitly, we will assume that the weight vectors of the algorithms are normalized under the ![]() norm (i.e. each weight is divided by the maximum weight); this gives weight 1 to the top authority, with other weights given as a fraction of the top weight. Due to space constraints, many proofs have been omitted in the following sections.
norm (i.e. each weight is divided by the maximum weight); this gives weight 1 to the top authority, with other weights given as a fraction of the top weight. Due to space constraints, many proofs have been omitted in the following sections.
![]()
Monotonicity appears to be a "reasonable" property that any sensible link-analysis algorithm should satisfy.
Let ![]() and
and ![]() be two algorithms on
be two algorithms on ![]() . We shall consider the distance
. We shall consider the distance ![]() between the weight vectors of
between the weight vectors of ![]() and
and ![]() , for
, for ![]() , where
, where ![]() is some function that maps the weight vectors
is some function that maps the weight vectors ![]() and
and ![]() to a real number
to a real number ![]() . We shall consider the Manhattan distance
. We shall consider the Manhattan distance ![]() , that is, the
, that is, the ![]() norm of the difference of the weight vectors, given by
norm of the difference of the weight vectors, given by ![]() .
.
For this distance function, we now define the similarity between two ![]() -algorithms as follows
-algorithms as follows![]() .
.
![]()
We also consider another distance function that attempts to capture the similarity between the ordinal rankings of two algorithms. The motivation behind this definition is that the ordinal ranking is the usual end-product seen by the user. Let ![]() and
and ![]() be the weight vectors of two algorithms
be the weight vectors of two algorithms ![]() and
and ![]() . We define the indicator function
. We define the indicator function ![]() as follows
as follows
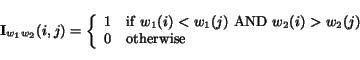
We note that ![]() if and only if
if and only if ![]() .
. ![]() becomes one for each pair of nodes that are ranked differently. We define the "ranking distance" function
becomes one for each pair of nodes that are ranked differently. We define the "ranking distance" function ![]() as follows.
as follows.
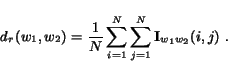
Note that, unlike ![]() , the distance between two weight vectors under
, the distance between two weight vectors under ![]() does not depend upon the choice of normalization.
does not depend upon the choice of normalization.
![]()
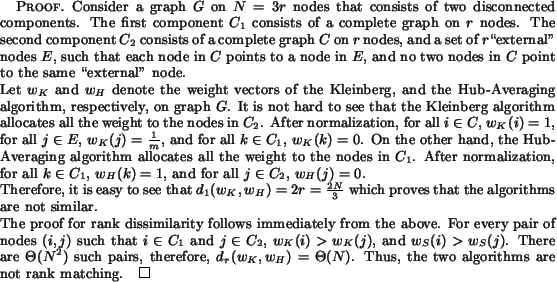
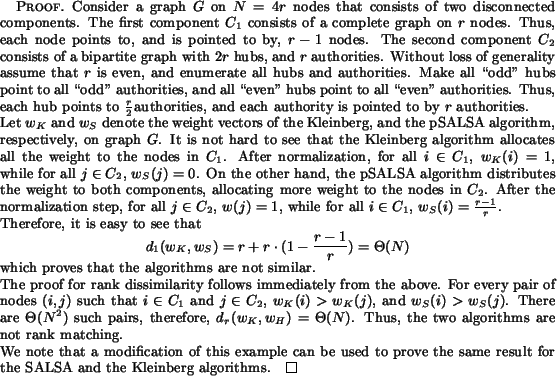

On the other hand, we have the following.
![]()
Let ![]() be the set of all size-
be the set of all size-![]() nested graphs. (Of course,
nested graphs. (Of course, ![]() is a rather restricted set of size-
is a rather restricted set of size-![]() graphs.)
graphs.)
In the previous section we examined the similarity of two different algorithms on the same graph ![]() . In this section we are interested on how the output of a fixed algorithm changes, as we alter the graph. We would like small changes in the graph to have a small effect on the weight vector of the algorithm. We capture this requirement by the definition of stability. For the following, let
. In this section we are interested on how the output of a fixed algorithm changes, as we alter the graph. We would like small changes in the graph to have a small effect on the weight vector of the algorithm. We capture this requirement by the definition of stability. For the following, let ![]() denote the set of all edges (i.e. links) in the graph
denote the set of all edges (i.e. links) in the graph ![]() . We assume that
. We assume that ![]() , otherwise all properties that we discuss below are trivial. The following definition applies to unnormalized, and
, otherwise all properties that we discuss below are trivial. The following definition applies to unnormalized, and ![]() -algorithms
-algorithms![]() .
.
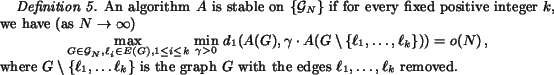

Stability may be a desirable property. Indeed, the algorithms all act on a base set which is generated using some other search engine (e.g. AltaVista [1]) and the associated hypertext links. Presumably with a "very good" base set, all the algorithms would perform well. However, if an algorithm is not stable, then slight changes in the base set (or its link structure) may lead to large changes in the rankings given by the algorithm. Thus, stability may provide "protection" from poor base sets. We note that the parameter ![]() used in the definition of stability allows for an arbitrary scaling of the second weight vector, thus eliminating instability which is caused solely by different normalization factors.
used in the definition of stability allows for an arbitrary scaling of the second weight vector, thus eliminating instability which is caused solely by different normalization factors.
We now introduce the idea of "locality". The idea behind locality is that a change in the in-links of a node should have only a small effect on the weights of the rest of the nodes.
![]()
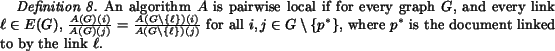
![]()
We note that locality depends on the normalization used, but pairwise locality and rank locality do not. The following lemmas are direct consequences of the definitions.
We have the following.

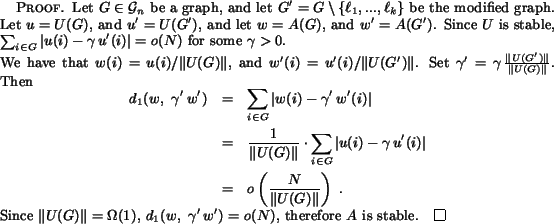
We originally thought that the Bayesian and Simplified Bayesian Algorithms were also local. However, it turns out that they are neither local nor pairwise local. Indeed, it is true that conditional on the values of ![]() ,
, ![]() , and
, and ![]() , the conditional distribution of
, the conditional distribution of ![]() for
for ![]() is unchanged upon removing a link from
is unchanged upon removing a link from ![]() to
to ![]() . However, the unconditional marginal distribution of
. However, the unconditional marginal distribution of ![]() , and hence also its posterior mean
, and hence also its posterior mean ![]() (or even ratios
(or even ratios ![]() for
for ![]() ), may still be changed upon removing a link from
), may still be changed upon removing a link from ![]() to
to ![]() . (Indeed, we have computed experimentally that
. (Indeed, we have computed experimentally that ![]() may change upon removing a link from 1 to 2, even for a simple example with just four nodes.) Hence, neither the Bayesian nor the Simplified Bayesian Algorithm is local or pairwise local.
may change upon removing a link from 1 to 2, even for a simple example with just four nodes.) Hence, neither the Bayesian nor the Simplified Bayesian Algorithm is local or pairwise local.
Finally, we use locality and "label-independence" to prove a uniqueness property of the pSALSA algorithm.
![]()
All of our algorithms are clearly label-independent, and we would expect this property of any reasonable algorithm. We have the following.

![]()
We have by inspection:
We have considered a number of known and some new algorithms which use the hypertext link structure of World Wide Web pages to extract information about the relative ranking of these pages. In particular, we have introduced two algorithms based on Bayesian statistical approach as well as a number of algorithms which are modifications of Kleinberg's seminal hubs and authority algorithm. Based on 8 different queries (5 presented here), we discuss some observed properties of each algorithm as well as relationships between the algorithms. We found (experimentally) that certain algorithms appear to be more "balanced", while others more "focused". The latter tend to be sensitive to the existence of tightly interconnected clusters, which may cause them to drift. The intersections between the lists of the top-ten results of the algorithms suggest that certain algorithms exhibit similar behavior and properties.
Motivated by the experimental observations, we introduced a theoretical framework for the study and comparison of link-analysis ranking algorithms. We formally defined (and gave some preliminary results for) the concepts of monotonicity and locality, as well as various concepts of distance and similarity between ranking algorithms.
Our work leaves a number of interesting open questions. The two Bayesian algorithms open the door to the use of other statistical and machine learning techniques for ranking of hyper-linked documents. Furthermore, the framework we defined suggests a number of interesting directions for the theoretical study of ranking algorithms, which we have just begun to explore in this work.
|
|
Kleinberg |
pSALSA |
HubAvg |
AThresh |
HThresh |
FThresh |
BFS |
SBayesian |
Bayesian |
|
1. |
P-1165 |
P-717 |
P-1165 |
P-1165 |
P-717 |
P-1165 |
P-717 |
P-717 |
P-717 |
|
2. |
P-1184 |
P-1461 |
P-1184 |
P-1184 |
P-1461 |
P-1184 |
P-719 |
P-1461 |
P-1192 |
|
3. |
P-1193 |
P-719 |
P-1193 |
P-1193 |
P-1769 |
P-1193 |
P-1769 |
P-1191 |
P-1165 |
|
4. |
P-1187 |
P-1165 |
P-1187 |
P-1187 |
P-719 |
P-1461 |
P-1461 |
P-719 |
P-1191 |
|
5. |
P-1188 |
P-1184 |
P-1188 |
P-1188 |
P-1 |
P-719 |
P-962 |
P-1184 |
P-1193 |
|
6. |
P-1189 |
P-1193 |
P-1189 |
P-1189 |
P-718 |
P-717 |
P-0 |
P-1165 |
P-1184 |
|
7. |
P-1190 |
P-1187 |
P-1190 |
P-1190 |
P-0 |
P-1 |
P-2 |
P-1192 |
P-1189 |
|
8. |
P-1191 |
P-1188 |
P-1191 |
P-1191 |
P-115 |
P-0 |
P-718 |
P-1193 |
P-1188 |
|
9. |
P-1192 |
P-1189 |
P-1192 |
P-1192 |
P-2515 |
P-115 |
P-1325 |
P-1188 |
P-1187 |
|
10. |
P-717 |
P-1190 |
P-1948 |
P-1948 |
P-962 |
P-607 |
P-1522 |
P-1187 |
P-1190 |
|
Index |
pop |
URL |
Title |
|
P-0 |
3 |
www.gynpages.com |
Abortion Clinics OnLine |
|
P-1 |
2 |
www.prochoice.org |
NAF - The Voice of Abortion Providers |
|
P-2 |
1 |
www.cais.com/agm/main |
The Abortion Rights Activist Home Page |
|
P-115 |
2 |
www.ms4c.org |
Medical Students for Choice |
|
P-607 |
1 |
www.feministcampus.org |
Feminist Campus Activism Online: Welcome |
|
P-717 |
7 |
www.nrlc.org |
National Right to Life Organization |
|
P-718 |
2 |
www.hli.org |
Human Life International (HLI) |
|
P-719 |
5 |
www.naral.org |
NARAL: Abortion and Reproductive Rights: ... |
|
P-962 |
2 |
www.prolife.org/ultimate |
Empty title field |
|
P-1165 |
7 |
www5.dimeclicks.com |
DimeClicks.com - Web and Marketing Solutions |
|
P-1184 |
7 |
www.amazon.com/...../youdebatecom |
Amazon.com-Earth's Biggest Selection |
|
P-1187 |
6 |
www.amazon.com/...../top-sellers.html |
Amazon.com-Earth's Biggest Selection |
|
P-1188 |
6 |
www.amazon.com/.../software/home.html |
Amazon.com Software |
|
P-1189 |
5 |
www.amazon.com/.../hot-100-music.html |
Amazon.com-Earth's Biggest Selection |
|
P-1190 |
5 |
www.amazon.com/.../gifts.html |
Amazon.com-Earth's Biggest Selection |
|
P-1191 |
5 |
www.amazon.com/.....top-100-dvd.html |
Amazon.com-Earth's Biggest Selection |
|
P-1192 |
5 |
www.amazon.com/...top-100-video.html |
Amazon.com-Earth's Biggest Selection |
|
P-1193 |
7 |
rd1.hitbox.com/....... |
HitBox.com - hitbox web site ....... |
|
P-1325 |
1 |
www.serve.com/fem4life |
Feminists For Life of America |
|
P-1461 |
5 |
www.plannedparenthood.org |
Planned Parenthood Federation of America |
|
P-1522 |
1 |
www.naralny.org |
NARAL/NY |
|
P-1769 |
2 |
www.priestsforlife.org |
Priests for Life Index |
|
P-1948 |
2 |
www.politics1.com/issues.htm |
Politics1: Hot Political Debates & Issues |
|
P-2515 |
1 |
www.ohiolife.org |
Ohio Right To Life |
|
|
Kleinberg |
pSALSA |
HubAvg |
AThresh |
HThresh |
FThresh |
BFS |
SBayesian |
Bayesian |
|
Kleinberg |
10 |
8 |
9 |
9 |
1 |
4 |
1 |
8 |
10 |
|
pSALSA |
8 |
10 |
7 |
7 |
3 |
6 |
3 |
8 |
8 |
|
HubAvg |
9 |
7 |
10 |
10 |
0 |
3 |
0 |
7 |
9 |
|
AThresh |
9 |
7 |
10 |
10 |
0 |
3 |
0 |
7 |
9 |
|
HThresh |
1 |
3 |
0 |
0 |
10 |
6 |
7 |
3 |
1 |
|
FThresh |
4 |
6 |
3 |
3 |
6 |
10 |
4 |
6 |
4 |
|
BFS |
1 |
3 |
0 |
0 |
7 |
4 |
10 |
3 |
1 |
|
SBayesian |
8 |
8 |
7 |
7 |
3 |
6 |
3 |
10 |
8 |
|
Bayesian |
10 |
8 |
9 |
9 |
1 |
4 |
1 |
8 |
10 |
|
|
Kleinberg |
pSALSA |
HubAvg |
AThresh |
HThresh |
FThresh |
BFS |
SBayesian |
Bayesian |
|
1. |
P-375 |
P-371 |
P-371 |
P-371 |
P-375 |
P-375 |
P-371 |
P-371 |
P-375 |
|
2. |
P-3163 |
P-1440 |
P-2874 |
P-375 |
P-1344 |
P-371 |
P-375 |
P-1440 |
P-371 |
|
3. |
P-3180 |
P-375 |
P-2871 |
P-2871 |
P-3132 |
P-1344 |
P-1299 |
P-375 |
P-3180 |
|
4. |
P-3177 |
P-2874 |
P-2873 |
P-2874 |
P-3163 |
P-3130 |
P-1440 |
P-2874 |
P-3177 |
|
5. |
P-3173 |
P-2871 |
P-2659 |
P-3536 |
P-3166 |
P-3131 |
P-2871 |
P-1299 |
P-3163 |
|
6. |
P-3172 |
P-1299 |
P-375 |
P-2873 |
P-3167 |
P-3132 |
P-2874 |
P-2871 |
P-3173 |
|
7. |
P-3132 |
P-3536 |
P-3536 |
P-2659 |
P-3168 |
P-3133 |
P-3536 |
P-3536 |
P-3166 |
|
8. |
P-3193 |
P-1712 |
P-2639 |
P-2639 |
P-3170 |
P-3135 |
P-1802 |
P-1712 |
P-3193 |
|
9. |
P-3170 |
P-268 |
P-1440 |
P-1440 |
P-3171 |
P-3161 |
P-2639 |
P-268 |
P-3168 |
|
10. |
P-3166 |
P-1445 |
P-2867 |
P-3180 |
P-3172 |
P-3162 |
P-452 |
P-1445 |
P-3132 |
|
Index |
pop |
URL |
Title |
|
P-268 |
2 |
www.epic.org |
Electronic Privacy Information Center |
|
P-371 |
7 |
www.yahoo.com |
Yahoo! |
|
P-375 |
9 |
www.cnn.com |
CNN.com |
|
P-452 |
1 |
www.mediachannel.org |
MediaChannel.org - A Global Network ........ |
|
P-1299 |
3 |
www.eff.org/blueribbon.html |
EFF Blue Ribbon Campaign |
|
P-1344 |
2 |
www.igc.apc.org/peacenet |
PeaceNet Home |
|
P-1440 |
5 |
www.eff.org |
EFF ... - the Electronic Frontier Foundation |
|
P-1445 |
2 |
www.cdt.org |
The Center for Democracy and Technology |
|
P-1712 |
2 |
www.aclu.org |
ACLU: American Civil Liberties Union |
|
P-1802 |
1 |
ukonlineshop.about.com |
Online Shopping: UK |
|
P-2639 |
3 |
www.imdb.com |
The Internet Movie Database (IMDb). |
|
P-2659 |
2 |
www.altavista.com |
AltaVista - Welcome |
|
P-2867 |
1 |
home.netscape.com |
Empty title field |
|
P-2871 |
5 |
www.excite.com |
My Excite Start Page |
|
P-2873 |
2 |
www.mckinley.com |
Welcome to Magellan! |
|
P-2874 |
5 |
www.lycos.com |
Lycos |
|
P-3130 |
1 |
www.city.net/countries/kyrgyzstan |
Excite Travel |
|
P-3131 |
1 |
www.bishkek.su/krg/Contry.html |
ElCat. 404: Not Found. |
|
P-3132 |
4 |
www.pitt.edu/~cjp/rees.html |
REESWeb: Programs: |
|
P-3133 |
1 |
www.ripn.net |
RIPN |
|
P-3135 |
1 |
www.yahoo.com/.../Kyrgyzstan |
Yahoo! Regional Countries Kyrgyzstan |
|
P-3161 |
1 |
151.121.3.140/fas/fas-publications/... |
Error 404 Redirector |
|
P-3162 |
1 |
www.rferl.org/BD/KY |
RFE/RL Kyrgyz Service : News |
|
P-3163 |
3 |
www.usa.ft.com |
Empty title field |
|
P-3166 |
3 |
www.pathfinder.com/time/daily |
TIME.COM |
|
P-3167 |
1 |
travel.state.gov |
US State Department - Services - Consular Affairs |
|
P-3168 |
2 |
www.yahoo.com/News |
Yahoo! News and Media |
|
P-3170 |
2 |
www.financenet.gov |
...FinanceNet is the government's official home... |
|
P-3171 |
1 |
www.securities.com |
ISI Emerging Markets |
|
P-3172 |
2 |
www.oecd.org |
OECD Online |
|
P-3173 |
2 |
www.worldbank.org |
The World Bank Group |
|
P-3177 |
2 |
www.envirolink.org |
EnviroLink Network |
|
P-3180 |
3 |
www.lib.utexas.edu/.../Map_collection |
PCL Map Collection |
|
P-3193 |
2 |
www.wiesenthal.com |
Simon Wiesenthal Center |
|
P-3536 |
5 |
www.shareware.com |
CNET.com - Shareware.com |
|
|
Kleinberg |
pSALSA |
HubAvg |
AThresh |
HThresh |
FThresh |
BFS |
SBayesian |
Bayesian |
|
Kleinberg |
10 |
1 |
1 |
2 |
6 |
2 |
1 |
1 |
8 |
|
pSALSA |
1 |
10 |
6 |
6 |
1 |
2 |
7 |
10 |
2 |
|
HubAvg |
1 |
6 |
10 |
9 |
1 |
2 |
7 |
6 |
2 |
|
AThresh |
2 |
6 |
9 |
10 |
1 |
2 |
7 |
6 |
3 |
|
HThresh |
6 |
1 |
1 |
1 |
10 |
3 |
1 |
1 |
5 |
|
FThresh |
2 |
2 |
2 |
2 |
3 |
10 |
2 |
2 |
3 |
|
BFS |
1 |
7 |
7 |
7 |
1 |
2 |
10 |
7 |
2 |
|
SBayesian |
1 |
10 |
6 |
6 |
1 |
2 |
7 |
10 |
2 |
|
Bayesian |
8 |
2 |
2 |
3 |
5 |
3 |
2 |
2 |
10 |
|
|
Kleinberg |
pSALSA |
HubAvg |
AThresh |
HThresh |
FThresh |
BFS |
SBayesian |
Bayesian |
|
1. |
P-678 |
P-999 |
P-999 |
P-999 |
P-678 |
P-999 |
P-999 |
P-999 |
P-999 |
|
2. |
P-2268 |
P-2832 |
P-2832 |
P-2832 |
P-2266 |
P-2832 |
P-2832 |
P-2832 |
P-2832 |
|
3. |
P-2304 |
P-6359 |
P-803 |
P-6359 |
P-2268 |
P-1989 |
P-2827 |
P-6359 |
P-2827 |
|
4. |
P-2305 |
P-2827 |
P-1539 |
P-2827 |
P-999 |
P-1911 |
P-2803 |
P-2827 |
P-6359 |
|
5. |
P-2306 |
P-2120 |
P-2101 |
P-2838 |
P-2832 |
P-1980 |
P-5470 |
P-1374 |
P-678 |
|
6. |
P-2308 |
P-1374 |
P-1178 |
P-6446 |
P-2263 |
P-1983 |
P-2120 |
P-2120 |
P-2838 |
|
7. |
P-2310 |
P-803 |
P-6359 |
P-5 |
P-2264 |
P-1984 |
P-4577 |
P-803 |
P-2266 |
|
8. |
P-2266 |
P-1539 |
P-1082 |
P-2803 |
P-2265 |
P-1986 |
P-5 |
P-6446 |
P-2268 |
|
9. |
P-2325 |
P-6446 |
P-2827 |
P-2839 |
P-2280 |
P-1987 |
P-2838 |
P-1539 |
P-2308 |
|
10. |
P-2299 |
P-2838 |
P-6446 |
P-2840 |
P-2304 |
P-1993 |
P-4534 |
P-2838 |
P-2330 |
|
Index |
pop |
Title |
URL |
|
P-5 |
2 |
www.movies.com |
Movies.com |
|
P-678 |
3 |
chatting.about.com |
Empty title field |
|
P-803 |
3 |
www.google.com |
|
|
P-999 |
8 |
www.moviedatabase.com |
The Internet Movie Database (IMDb). |
|
P-1082 |
1 |
www.amazon.com/ |
Amazon.com-Earth's Biggest Selection |
|
P-1178 |
1 |
www.booksfordummies.com |
Empty title field |
|
P-1374 |
2 |
www.onwisconsin.com |
On Wisconsin |
|
P-1539 |
3 |
206.132.25.51 |
Washingtonpost.com - News Front |
|
P-1911 |
1 |
people2people.com/...nytoday |
People2People.com - Search |
|
P-1980 |
1 |
newyork.urbanbaby.com/nytoday |
Kids & Family |
|
P-1983 |
1 |
tunerc1.va.everstream.com/nytoday/ |
Empty title field |
|
P-1984 |
1 |
nytoday.opentable.com/ |
OpenTable |
|
P-1986 |
1 |
www.nytimes.com/.../jobmarket |
The New York Times: Job Market |
|
P-1987 |
1 |
www.cars.com/nytimes |
New York Today cars.com - new and used car ... |
|
P-1989 |
1 |
www.nytodayshopping.com |
New York Today Shopping - Shop for computers, ... |
|
P-1993 |
1 |
www.nytimes.com/.../nytodaymediakit |
New York Today - Online Media Kit |
|
P-2101 |
1 |
www2.ebay.com/aw/announce.shtml |
eBay Announcement Board |
|
P-2120 |
3 |
www.mylifesaver.com |
welcome to mylifesaver.com |
|
P-2263 |
1 |
clicks.about.com/...nationalinterbank |
Banking Center |
|
P-2264 |
1 |
clicks.about.com/ |
Credit Report, Free Trial Offer |
|
P-2265 |
1 |
membership.about.com/... |
Member Center |
|
P-2266 |
3 |
home.about.com/movies |
About - Movies |
|
P-2268 |
3 |
a-zlist.about.com |
About.com A-Z |
|
P-2280 |
1 |
sprinks.about.com |
Sprinks : About Sprinks |
|
P-2299 |
1 |
home.about.com/aboutaus |
About Australia |
|
P-2304 |
2 |
home.about.com/arts |
About - Arts/Humanities |
|
P-2305 |
1 |
home.about.com/autos |
About - Autos |
|
P-2306 |
1 |
home.about.com/citiestowns |
About - Cities/Towns |
|
P-2308 |
2 |
home.about.com/compute |
About - Computing/Technology |
|
P-2310 |
1 |
home.about.com/education |
About - Education |
|
P-2325 |
1 |
home.about.com/musicperform |
About - Music/Performance |
|
P-2330 |
1 |
home.about.com/recreation |
About - Recreation/Outdoors |
|
P-2803 |
2 |
www.allmovie.com |
All Movie Guide |
|
P-2827 |
6 |
www.film.com |
Film.com Movie Reviews, News, Trailers... |
|
P-2832 |
8 |
www.hollywood.com |
Hollywood.com - Your entertainment source... |
|
P-2838 |
5 |
www.mca.com |
Universal Studios |
|
P-2839 |
1 |
www.mgmua.com |
MGM - Home Page |
|
P-2840 |
1 |
www.miramax.com |
Welcome to the Miramax Cafe |
|
P-4534 |
1 |
www.aint-it-cool-news.com |
Ain't It Cool News |
|
P-4577 |
1 |
go.com |
GO.com |
|
P-5470 |
1 |
www.doubleaction.net |
Double Action - Stand. Point. Laugh. |
|
P-6359 |
5 |
www.paramount.com |
Paramount Pictures - Home Page |
|
P-6446 |
4 |
www.disney.com |
Disney.com - Where the Magic Lives Online! |
|
|
Kleinberg |
pSALSA |
HubAvg |
AThresh |
HThresh |
FThresh |
BFS |
SBayesian |
Bayesian |
|
Kleinberg |
10 |
0 |
0 |
0 |
4 |
0 |
0 |
0 |
4 |
|
pSALSA |
0 |
10 |
7 |
6 |
2 |
2 |
5 |
10 |
5 |
|
HubAvg |
0 |
7 |
10 |
5 |
2 |
2 |
3 |
7 |
4 |
|
AThresh |
0 |
6 |
5 |
10 |
2 |
2 |
6 |
6 |
5 |
|
HThresh |
4 |
2 |
2 |
2 |
10 |
2 |
2 |
2 |
5 |
|
FThresh |
0 |
2 |
2 |
2 |
2 |
10 |
2 |
2 |
2 |
|
BFS |
0 |
5 |
3 |
6 |
2 |
2 |
10 |
5 |
4 |
|
SBayesian |
0 |
10 |
7 |
6 |
2 |
2 |
5 |
10 |
5 |
|
Bayesian |
4 |
5 |
4 |
5 |
5 |
2 |
4 |
5 |
10 |
|
|
Kleinberg |
pSALSA |
HubAvg |
AThresh |
HThresh |
FThresh |
BFS |
SBayesian |
Bayesian |
|
1. |
P-2187 |
P-2187 |
P-2187 |
P-2187 |
P-2187 |
P-2187 |
P-2187 |
P-2187 |
P-2187 |
|
2. |
P-1057 |
P-258 |
P-1057 |
P-1057 |
P-1057 |
P-1057 |
P-3932 |
P-258 |
P-1057 |
|
3. |
P-2168 |
P-1057 |
P-3932 |
P-2168 |
P-2168 |
P-2168 |
P-1538 |
P-1057 |
P-2168 |
|
4. |
P-2200 |
P-3932 |
P-2095 |
P-2200 |
P-2200 |
P-2200 |
P-1057 |
P-3932 |
P-2095 |
|
5. |
P-2219 |
P-2095 |
P-2168 |
P-2219 |
P-2219 |
P-2219 |
P-2095 |
P-2095 |
P-2200 |
|
6. |
P-2199 |
P-1538 |
P-2186 |
P-2095 |
P-2199 |
P-2095 |
P-258 |
P-1538 |
P-2219 |
|
7. |
P-2095 |
P-2 |
P-941 |
P-3932 |
P-2186 |
P-3932 |
P-2168 |
P-2 |
P-3932 |
|
8. |
P-2186 |
P-2168 |
P-0 |
P-2199 |
P-2095 |
P-2199 |
P-2200 |
P-2168 |
P-2199 |
|
9. |
P-2193 |
P-941 |
P-2200 |
P-2186 |
P-2193 |
P-2186 |
P-2 |
P-941 |
P-2186 |
|
10. |
P-3932 |
P-23 |
P-2199 |
P-2193 |
P-3932 |
P-2193 |
P-2199 |
P-2200 |
P-2193 |
|
Index |
pop |
URL |
Title |
|
P-0 |
1 |
www.geneticalliance.org |
Genetic Alliance, Washington, DC |
|
P-2 |
3 |
www.genetic-programming.org |
genetic-programming.org-Home-Page |
|
P-23 |
1 |
www.geneticprogramming.com |
The Genetic Programming Notebook |
|
P-258 |
3 |
www.aic.nrl.navy.mil/galist |
The Genetic Algorithms Archive |
|
P-941 |
3 |
www3.ncbi.nlm.nih.gov/Omim |
OMIM Home Page - Online Mendelian Inheritance in Man |
|
P-1057 |
9 |
gdbwww.gdb.org |
The Genome Database |
|
P-1538 |
3 |
www.yahoo.com |
Yahoo! |
|
P-2095 |
9 |
www.nhgri.nih.gov |
National Human Genome Research Institute (NHGRI) |
|
P-2168 |
9 |
www-genome.wi.mit.edu |
Welcome To the ..... Center for Genome Research |
|
P-2186 |
6 |
www.ebi.ac.uk |
EBI, the European Bioinformatics Institute ........ |
|
P-2187 |
9 |
www.ncbi.nlm.nih.gov |
NCBI HomePage |
|
P-2193 |
5 |
www.genome.ad.jp |
GenomeNet WWW server |
|
P-2199 |
7 |
www.hgmp.mrc.ac.uk |
UK MRC HGMP-RC |
|
P-2200 |
8 |
www.tigr.org |
The Institute for Genomic Research |
|
P-2219 |
5 |
www.sanger.ac.uk |
The Sanger Centre Web Server |
|
P-3932 |
9 |
www.nih.gov |
National Institutes of Health (NIH) |
|
|
Kleinberg |
pSALSA |
HubAvg |
AThresh |
HThresh |
FThresh |
BFS |
SBayesian |
Bayesian |
|
Kleinberg |
10 |
5 |
8 |
10 |
10 |
10 |
7 |
6 |
10 |
|
pSALSA |
5 |
10 |
6 |
5 |
5 |
5 |
8 |
9 |
5 |
|
HubAvg |
8 |
6 |
10 |
8 |
8 |
8 |
7 |
7 |
8 |
|
AThresh |
10 |
5 |
8 |
10 |
10 |
10 |
7 |
6 |
10 |
|
HThresh |
10 |
5 |
8 |
10 |
10 |
10 |
7 |
6 |
10 |
|
FThresh |
10 |
5 |
8 |
10 |
10 |
10 |
7 |
6 |
10 |
|
BFS |
7 |
8 |
7 |
7 |
7 |
7 |
10 |
9 |
7 |
|
SBayesian |
6 |
9 |
7 |
6 |
6 |
6 |
9 |
10 |
6 |
|
Bayesian |
10 |
5 |
8 |
10 |
10 |
10 |
7 |
6 |
10 |
|
|
Kleinberg |
pSALSA |
HubAvg |
AThresh |
HThresh |
FThresh |
BFS |
SBayesian |
Bayesian |
|
1. |
P-161 |
P-161 |
P-634 |
P-161 |
P-0 |
P-161 |
P-0 |
P-161 |
P-161 |
|
2. |
P-0 |
P-1 |
P-632 |
P-0 |
P-161 |
P-0 |
P-161 |
P-1 |
P-0 |
|
3. |
P-1 |
P-0 |
P-633 |
P-1 |
P-1 |
P-1 |
P-1 |
P-0 |
P-1 |
|
4. |
P-162 |
P-3 |
P-161 |
P-162 |
P-162 |
P-162 |
P-300 |
P-3 |
P-162 |
|
5. |
P-3 |
P-280 |
P-1 |
P-3 |
P-280 |
P-280 |
P-299 |
P-280 |
P-3 |
|
6. |
P-280 |
P-634 |
P-1406 |
P-280 |
P-3 |
P-3 |
P-162 |
P-634 |
P-280 |
|
7. |
P-275 |
P-162 |
P-0 |
P-275 |
P-275 |
P-275 |
P-3 |
P-162 |
P-275 |
|
8. |
P-299 |
P-2 |
P-3 |
P-299 |
P-299 |
P-299 |
P-280 |
P-2 |
P-299 |
|
9. |
P-300 |
P-632 |
P-162 |
P-300 |
P-300 |
P-848 |
P-375 |
P-633 |
P-300 |
|
10. |
P-848 |
P-633 |
P-280 |
P-848 |
P-848 |
P-300 |
P-551 |
P-632 |
P-848 |
|
Index |
pop |
URL |
Title |
|
P-0 |
9 |
www.geom.umn.edu/software/cglist |
Directory of Computational Geometry Software |
|
P-1 |
9 |
www.cs.uu.nl/CGAL |
The former CGAL home page |
|
P-2 |
2 |
link.springer.de/link/service/journals/00454 |
LINK: Peak-time overload |
|
P-3 |
9 |
www.scs.carleton.ca/~csgs/resources/cg.html |
Computational Geometry Resources |
|
P-161 |
9 |
www.ics.uci.edu/~eppstein/geom.html |
Geometry in Action |
|
P-162 |
9 |
www.ics.uci.edu/~eppstein/junkyard |
The Geometry Junkyard |
|
P-275 |
5 |
www.ics.uci.edu/~eppstein |
David Eppstein |
|
P-280 |
9 |
www.geom.umn.edu |
The Geometry Center Welcome Page |
|
P-299 |
6 |
www.mpi-sb.mpg.de/LEDA/leda.html |
LEDA - Main Page of LEDA Research |
|
P-300 |
6 |
www.cs.sunysb.edu/~algorith |
The Stony Brook Algorithm Repository |
|
P-375 |
1 |
graphics.lcs.mit.edu/~seth |
Seth Teller |
|
P-551 |
1 |
www.cs.sunysb.edu/~skiena |
Steven Skiena |
|
P-632 |
3 |
www.w3.org/Style/CSS/Buttons |
CSS button |
|
P-633 |
3 |
jigsaw.w3.org/css-validator |
W3C CSS Validation Service |
|
P-634 |
3 |
validator.w3.org |
W3C HTML Validation Service |
|
P-848 |
5 |
www.inria.fr/prisme/....../cgt |
CG Tribune |
|
P-1406 |
1 |
www.informatik.rwth-aachen.de/..... |
Department of Computer Science, Aachen |
|
|
Kleinberg |
pSALSA |
HubAvg |
AThresh |
HThresh |
FThresh |
BFS |
SBayesian |
Bayesian |
|
Kleinberg |
10 |
6 |
6 |
10 |
10 |
10 |
8 |
6 |
10 |
|
pSALSA |
6 |
10 |
9 |
6 |
6 |
6 |
6 |
10 |
6 |
|
HubAvg |
6 |
9 |
10 |
6 |
6 |
6 |
6 |
9 |
6 |
|
AThresh |
10 |
6 |
6 |
10 |
10 |
10 |
8 |
6 |
10 |
|
HThresh |
10 |
6 |
6 |
10 |
10 |
10 |
8 |
6 |
10 |
|
FThresh |
10 |
6 |
6 |
10 |
10 |
10 |
8 |
6 |
10 |
|
BFS |
8 |
6 |
6 |
8 |
8 |
8 |
10 |
6 |
8 |
|
SBayesian |
6 |
10 |
9 |
6 |
6 |
6 |
6 |
10 |
6 |
|
Bayesian |
10 |
6 |
6 |
10 |
10 |
10 |
8 |
6 |
10 |