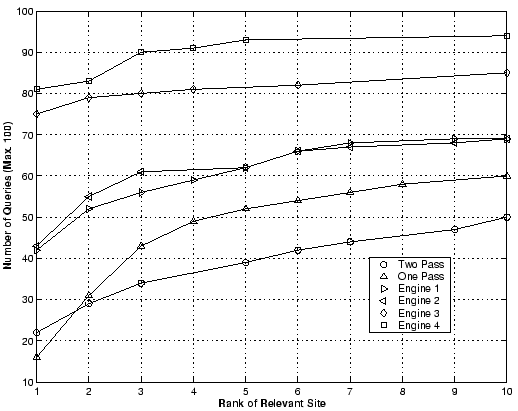
Figure 1 shows the results of our experiments. The
x-axis of Figure 1 shows the rank at which the desired
site was retrieved by a system. The y-axis shows the cumulative number
of queries for which the desired site was retrieved at or before the
corresponding rank on the x-axis. For example, a point ![]() 6,82
6,82![]() on
the plot indicates that the corresponding search engine retrieved the
desired site at rank 6 or better for 82 out of the 100 queries. The
higher the plot, the better the engine is. For example, the best
engine (Engine 4) retrieves the relevant page at rank 1 for 81 out of
the 100 queries. Whereas our two-pass TREC algorithm retrieves the
relevant page at rank 1 for only 22 out of the 100 queries.
on
the plot indicates that the corresponding search engine retrieved the
desired site at rank 6 or better for 82 out of the 100 queries. The
higher the plot, the better the engine is. For example, the best
engine (Engine 4) retrieves the relevant page at rank 1 for 81 out of
the 100 queries. Whereas our two-pass TREC algorithm retrieves the
relevant page at rank 1 for only 22 out of the 100 queries.
We would like to emphasize that for the TREC algorithms, any page that resides on the same host as the relevant page is counted as relevant. We assume that it should be fairly simple to do the host based grouping and present the root page for the host. This assumption might not always be true and the results presented in Figure 1 for the TREC algorithms are, in some sense, best-case. Despite the best-case scenario for the TREC algorithms, Figure 1 shows that the TREC algorithms are far behind these four commercial web search engines for the kind of queries used in this study. The best commercial engine finds the relevant page in top 10 for 94/100 queries whereas the better performing (one-pass) TREC algorithm finds the relevant page for only 60 of the 100 queries. In short, the performance analysis presented in Figure 1 shows that the results from the TREC algorithms are consistently and notably below even the poorest of the commercial web search engines used in our study. This indicates that best TREC ad-hoc algorithms are by no means state-of-the-art for web search if our objective is to find a specific web site. These results contradict the results presented in [5,6,7]. However, we should say that these previous studies do not use the type of queries used in our study.
An even more surprising result is that adding a more complex query-expansion second pass does not improve the results, instead it makes the results somewhat worse. Using query expansion and doing two-pass retrieval we only find the relevant page for 50/100 queries in top 10 results as opposed to 60 pages for the one-pass algorithm. This result is in direct contradiction to the results obtained by TREC participants for the TREC ad-hoc benchmark tasks. In those results, it has been widely shown that in terms of average precision, which is how results are measured at TREC, a two-pass algorithm is almost always notably better than using just the first pass.