


Next: Impact of the model
Up: Experimental Evaluation
Previous: Performance Results
To experimentally determine the impact of the model size on the quality
of the prediction, we selectively varied the number of items to be used
for similarity computation from 25 to 200 in an increment of 25. A model
size of l means that we only considered l best similarity values
for model building and later on used k of them for the prediction
generation process, where k<l.
Using the train data set we precomputed the item similarity using
different model sizes and then used only the weighted sum prediction generation
technique to provide the predictions. We then used the test data set to compute
MAE and plotted the values. To compare with the full model size (i.e.,
model size = no. of items) we also ran the same test considering all
similarity values and picked best k for prediction generation. We repeated
the entire process for three different x values (train/test ratios). Figure 7
shows the plots at different x values. It can be observed from the plots
that the MAE values get better as we increase the model size and the improvements
are drastic at the beginning, but gradually slows down as we increase the model
size. The most important observation from these plots is the high
accuracy can be achieved using only a fraction of items. For example,
at x=0.3 the full item-item scheme provided an MAE of 0.7873, but
using a model size of only 25, we were able to achieve an MAE value
of 0.842. At x=0.8 these numbers are even more appealing-for the
full item-item we had an MAE of 0.726 but using a model size of only
25 we were able to obtain an MAE of 0.754, and using a model size
of 50 the MAE was 0.738. In other words, at x=0.8 we were within
 and
and 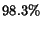 of the full item-item scheme's accuracy using
only
of the full item-item scheme's accuracy using
only  and
and  of the items respectively!
of the items respectively!
Figure 7:
Sensitivity of the model size on item-based collaborative filtering algorithm
 |
This model size sensitivity has important performance implications. It appears
from the plots that it is useful to precompute the item similarities using
only a fraction of items and yet possible to obtain reasonably good prediction
quality.
Next: Impact of the model
Up: Experimental Evaluation
Previous: Performance Results
Badrul M. Sarwar
2001-02-19