We have already seen from the preceding discussion that the Vortex language satisfies requirements (a) through (g).
Turning to requirement (h), the ``attribute-centric'' nature of Decision Flows makes possible reports about how or why decisions were made are conceptually close to the Decision Flow specification. In particular, reports such as in Figure 3 can be created using some or all of the attributes derived by the Decision Flow. Given a family of decisions, a user can inspect this report (either manually or using automated techniques such as regression analysis or data mining) to see whether the various attributes and criteria are given appropriate emphasis. If anomalies are found, then it is relatively easy to find the corresponding places in the Decision Flow that should be modified. Furthermore, we expect that this close correspondence between reports and Decision Flow structure will facilitate the development of self-learning tools that will work on top of Vortex.
Decision Flows reveal the key factors involved in making a decision or evaluation, and hide a substantial amount of detail about the execution. In contrast, when specifying an equivalent decision using a conventional flowchart or Petri Net formalism, the key factors and logic are obscured by the plumbing. In Decision Flows different ways of executing rules can co-exist; this contrasts with logic programming languages and conventional expert systems, which have a single execution semantics, and force the use of awkward simulations if rules are to be combined in a different way. It is these considerations along with the correspondence between reports and the structure of Decision Flows that lead us to believe that Vortex satisfies requirement (h).
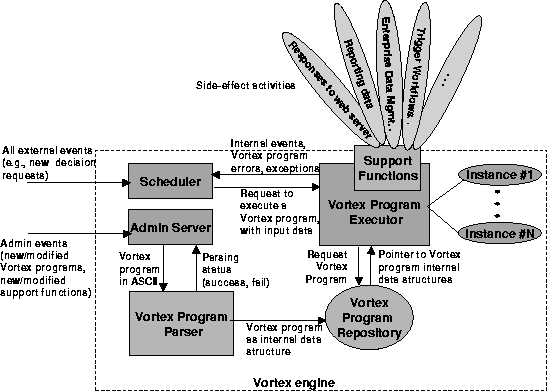
We turn now to requirement (j). Figure 5 shows a high-level architecture of the Vortex engine. Vortex programs are input into the Administrative Server, which invokes a parser. This checks that the program is well-formed and compiles it into an internal data structure. When the program is to be executed, i.e., when a decision is to be made based on given input parameters, a copy of the data structure is created, and that copy is then interpreted. As a result, the Vortex program can be modified, parsed, and complied into a (new) internal data structure. The new data structure can then be used for subsequent decisions. In this way, Vortex programs can be modified without bringing the engine down. For efficiency, the Vortex engine has been implemented in C++. Furthermore, many of the specific operations of a Vortex program (e.g., arithmetic comparisons, list manipulations, external functions) are performed by ``support functions'', which are compiled. Additional support functions can be added to the engine without bringing it down.
With regards to requirement (k), a prototype GUI has been implemented to support specification of Vortex programs. A visual palette is provided for the Decision Flow constructs; this has appearance similar to the images of Figures 2 and 4. Wizards are provided for building up flowchart nodes, rules, attribute modules, database queries, etc.
The example MIHU Decision Flow described earlier is relatively simple, in terms of the size of the Decision Flow and the nature of the data being evaluated. We have developed richer Decision Flows that involve many modules and over 50 attributes.