Modeling for AndroMDA
AndroMDA is an automatic tool with a medium amount of
intelligence built into it. Such a tool always has to rely upon
some clearly defined preconditions; in the case of AndroMDA,
these preconditions are
modeling conventions. This means
that a UML model for use with AndroMDA cannot be structured
arbitrarily but has to adhere to a certain structure that can
be interpreted by AndroMDA.
On the other hand, not too many constraints should
be imposed on the modeler - after all, a model should represent
the conceptual reality of the customer's requirements and the
structure of the application domain.
To sum up it all up, we've tried to keep the number of
rules low in order to keep your freedom of modeling high.
Keep in mind: modeling standards/requirements will
ultimately be dependantant on the implementation(s) of the cartridge(s)
you employ at build time. Each cartridge has required properties and modeling
conventions that must be followed. See
Cartridges for
more information. In general, there are rules to follow (seen below) when you start
sketching a design model and you want AndroMDA to generate your
components smoothly.
General Modeling Rules
Stereotypes drive code generation!:
UML Stereotypes are a kind of "label" that you
attach to modeling elements in order to classify them.
Please note that AndroMDA can now also generate code from templates
based on properties of any model element found in the XMI, so
theoretically it is possible to generate code without even using
stereotypes.
Example: You tag a CustomerService class
with a
<<Service>> stereotype.
AndroMDA sees this stereotype, looks into its internal
dictionary of available code generation components (called
"cartridges") and finds the EJB cartridge. In the EJB
cartridge, two templates correspond to the
<<Service>>
stereotype: SessionBean.vsl and SessionBeanImpl.vsl. AndroMDA uses the
internal representation of CustomerService loaded from the model,
calls the processing engine twice, and two output files are generated:
CustomerServiceBean.java and CustomerServiceBeanImpl.java.
A small model, containing an element tagged with the
<<Service>> stereotype,
can be seen in this picture:
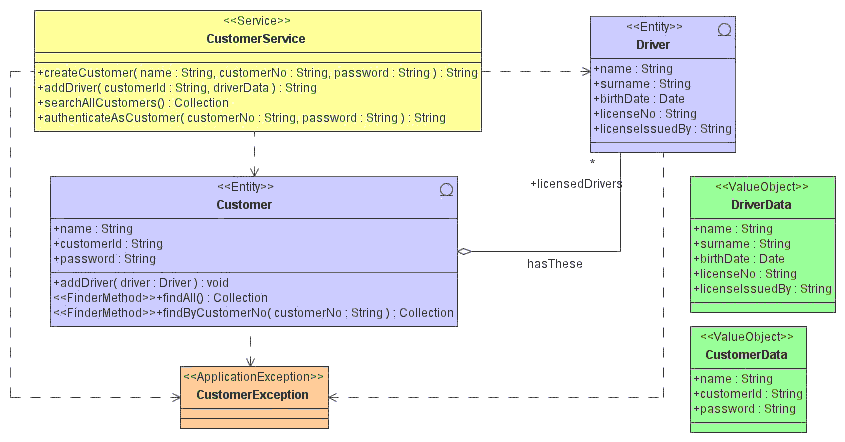
Even though modeling will depend primarily on how the
cartridge is implemented. There are some standard ways of
modeling which MUST be followed to ensure
the model is syntactically and semantically
complete, meaning the cartridge performing generation
has enough information on which to generate from.
These are listed here.
-
Names:
the general rule for all the names is to capitalize the
first letter of each concatenated word (i.e
exampleOfCapitalizationOfConcatenatedWords). This applies
to all model element names (methods, operations,
attributes, associations, association ends, etc.).
-
Specify the type of ALL attributes and operation
parameters. Some tools with allow you to
specify an attribute or operation without making you
specify it's type, but make sure you specify this, as a
cartridge performing generation will expect this
information.
-
Specify visibility where visibiliy counts.
Attributes on generated output are ALWAYS
private, however, the accessor and mutator of each attribute will
have the visibilty that you define in the model. For example:
if you define the name attribute on your Person
element to have a visibility of public,
then the accessor and mutator for that element will be
public as well, if you define the name
attribute's visibility as private, then the
accessor and mutator for attribute will be generated with a
private visibility.
-
Specify the multiplicities of both ends of ALL associations.
Cartridges use and require all multiplicity information.
-
Make sure names of association ends making up an
association are UNIQUE within the association.
If more than one association end of the same association is
the same name, there will be conflicts from the generated
output.
-
Do not leave unused elements dangling in your model.
One of the biggest causes of syntatic incompleteness is
the existence in the model of partially defined elements that are
undetected by the modeler because they do not reside in any
model diagram. Its easy to make the mistake of deleting the
element from the diagram but then forgetting to delete it
from the model as well.
-
If an element CANNOT exist without another element, define the
association end of the owning element as composite aggregation.
An association between a house and a room is a good
example of composite aggregation. Destruction of the house
implies destruction of all rooms that the house contains.
Therefore the association end of the house to a room would be
defined as composite aggregation (i.e. a black diamond).
-
Specify ordering where ordering matters.
When using multivalued attributes and association ends you
should be able to specify whether or not these are ordered in
the modeling tool. Make sure you specify this if ordering does matter
for these multivalued properties since cartridges need to
be able to take advantage of this specification. For
example, if an association end was defined as ordered, a
cartridge generating to Java may specify the type as a
java.util.Set instead of a
java.util.Collection (if it was left
unspecified or defined as unordered).
-
Do NOT add getter and setter operations for attributes.
The cartridge will generate any required accessor and mutator operations needed at
generation time.
-
Do NOT add getter and setter methods for association ends.
The cartridge will generate any required accessor and mutator operations
needed at generation time.
-
Define and use Datatypes for simple types.
Use UML Datatypes for simple types such as String,
Collection, Set, etc. instead of using the language
specific types which the tool may implement by default
(i.e. java.lang.String). You want to keep the model as
language independent as possible. Cartridges use mapping
files at generation time to map Datatypes to specific
language types (i.e. for Java, these could be: Collection -->
java.util.Collection, Blob --> java.sql.Blob, etc.)
