User Guide¶
Kafka Connect is a tool for copying data between Kafka and a variety of other systems, ranging from relational databases, to logs and metrics, to Hadoop and data warehouses, to NoSQL data stores, to search indexes, and more. Kafka Connect makes it easy to integrate all your data via Kafka, making it available as realtime streams. For example, you can use Kafka Connect to:
- Stream changes from a relational database to make events available with low latency for stream processing applications.
- Import realtime logs and metrics into Kafka and process them to detect anomalies.
- Import data from a primary data store and data stores and feed a collection of secondary indexes such as search and caches.
- Design an ETL pipeline by loading data into Kafka from your primary data storage systems, performing filtering, transformations, and enrichment with a stream processing framework, and deliver the prepared data to HDFS or your data warehouse. As an additional benefit, all your data is made available for stream processing by application developers.
Getting Started¶
The quickstart describes how to get started in standalone mode. It demonstrates an end-to-end job, importing data from one “system” (the filesystem) into Kafka, then exporting that same data from the Kafka topic to another “system” the console. Each of the following sections will cover the following in more detail:
- Kafka Connect concepts and running in standalone and distributed modes
- Configuring connectors
- Configuring workers
- Interacting with Kafka Connect via the REST API
Connectors, Tasks, and Workers¶
Kafka Connect’s core concept that users interact with is a connector. Connectors (or a connector instance) is a logical job that is responsible for managing the copying of data between Kafka and another system. Each connector can instantiate a set of tasks that actually copy the data. By allowing the connector to break a single job into many tasks, Kafka Connect provides built-in support for parallelism and scalable data copying with very little configuration. Connector plugins are jars that add the classes that implement a connector. Sometimes we refer to both connector instances and connector plugins as simply “connectors”, but it should always be clear from the context which is being referred to (e.g., “install a connector” refers to the plugin, and “check the status of a connector” refers to a connector instance).
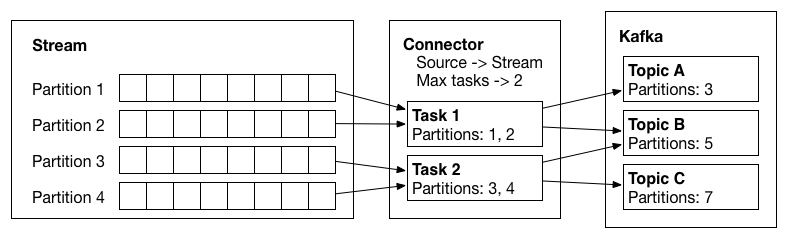
Logical view of an input stream, a source connector, the tasks it creates, and the data flow from the source system into Kafka.
Offsets¶
As connectors run, Kafka Connect tracks offsets for each one so that connectors can resume from their previous
position in the event of failures or graceful restarts for maintenance. These offsets are similar to Kafka’s offsets
in that they track the current position in the stream of data being copied and because each connector may need to
track many offsets for different partitions of the stream. However, they are different because the format of the offset
is defined by the system data is being loaded from and therefore may not simply be a long as they are for Kafka
topics. For example, when loading data from a database, the offset might be a transaction ID that identifies a position
in the database changelog.
Users generally do not need to worry about the format of offsets, especially since they differ from connector to connector. However, Kafka Connect does require persistent storage for offset data to ensure it can recover from faults, and users will need to configure this storage. These settings, which depend on the way you decide to run Kafka Connect, are discussed in the next section.
Workers¶
Connectors and tasks are logical units of work and must be scheduled to execute in a process. Kafka Connect calls these processes workers and has to types of workers: standalone and distributed.
Standalone Mode¶
Standalone mode is the simplest mode, where a single process is responsible for executing all connectors and tasks. Since it is a single process, it requires minimal configuration. To execute a worker in standalone mode, run the following command:
$ bin/connect-standalone worker.properties connector1.properties [connector2.properties connector3.properties ...]
The first parameter is always a configuration file for the worker. Described below in the section on configuring workers, this configuration gives you control over settings such as the Kafka cluster to use and the serialization format. All additional parameters should be connector configuration files. Each file contains a single connector configuration.
If you run multiple standalone instances on the same host, there are a couple of settings that must differ between each instance:
offset.storage.file.filename- storage for connector offsets, which are stored on the local filesystem in standalone mode; using the same file will lead to offset data being deleted or overwritten with different valuesrest.port- the port the REST interface listens on for HTTP requests
Distributed Mode¶
Standalone mode is convenient for getting started, during development, and in certain situations where only one process makes sense, such as collecting logs from a host. However, because there is only a single process, it also has more limited functionality: scalability is limited to the single process and there is no fault tolerance beyond any monitoring you add to the single process.
Distributed mode provides scalability and automatic fault tolerance for Kafka Connect. In distributed mode,
you start many worker processes using the same group.id and they automatically coordinate to schedule execution of
connectors and tasks across all available workers. If you add a worker, shut down a worker, or a worker fails
unexpectedly, the rest of the workers detect this and automatically coordinate to redistribute connectors and tasks
across the updated set of available workers.
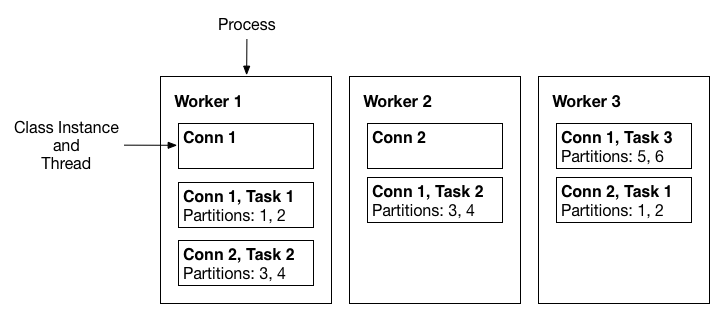
A three-node Kafka Connect distributed mode cluster. Connectors (monitoring the source or sink system for changes that require reconfiguring tasks) and tasks (copying a subset of a connector’s data) are automatically balanced across the active workers. The division of work between tasks is shown by the partitions that each task is assigned.
Unlike standalone mode where connector configurations are generally passed in via the command line, interaction with a distributed-mode cluster is via REST APIs. To create a connector, you start the workers and then make a REST request to create a connector (see the REST API section for details). Unlike many other systems, all nodes in Kafka Connect can respond to REST requests, including creating, listing, modifying, and destroying connectors.
In distributed mode, the workers need to be able to discover each other and have shared storage for connector configuration and offset data. In addition to the usual worker settings, you’ll want to ensure you’ve configured the following for this cluster:
group.id- an ID that uniquely identifies the Kafka Connect cluster these workers belong to. Ensure this is unique for all groups that work with a Kafka cluster.config.storage.topic- the Kafka topic to store connector and task configuration state in. Although this topic can be auto-created if your cluster has auto topic creation enabled, it is highly recommended that you create it before starting the Kafka Connect cluster. This topic should always have a single partition and be highly replicated (3x or more).offset.storage.topic- the Kafka topic to store connector offset state in. Although this topic can be auto-created if your cluster has auto topic creation enabled, it is highly recommended that you create it before starting the Kafka Connect cluster. To support large Kafka Connect clusters, this topic should have a large number of partitions (e.g. 25 or 50, just like Kafka’s built-in__offsetstopic) and highly replicated (3x or more).status.storage.topic- the Kafka topic to store status updates for connectors and tasks. Although this topic can be auto-created if your cluster has auto topic creation enabled, it is highly recommended that you create it before starting the Kafka Connect cluster. This topic can have multiple partitions and should be highly replicated (3x or more).
To start a distributed worker, create a worker configuration just as you would with standalone mode, but also setting the above config options. Then, simply start the worker process with that configuration:
$ bin/connect-distributed worker.properties
Distributed mode does not have any additional command line parameters. New workers will either start a new group or join an existing one, if other instances are already running, and then wait for work to do. You can use the REST API to manage the connectors running in the cluster. See the REST API section for more details, but here is a simple example that creates a connector that reads from stdin and produces each line as a message to the topic connect-test:
$ curl -X POST -H "Content-Type: application/json" --data '{"name": "local-console-source", "config": {"connector.class":"org.apache.kafka.connect.file.FileStreamSourceConnector", "tasks.max":"1", "topic":"connect-test" }}' http://localhost:8083/connectors
# Or, to use a file containing the JSON-formatted configuration
# curl -X POST -H "Content-Type: application/json" --data @config.json http://localhost:8083/connectors
In distributed mode, if you run more than one worker per host (for example, if you are testing distributed mode locally during development), the following settings must have different values for each instance:
rest.port- the port the REST interface listens on for HTTP requests
Configuring Connectors¶
Connector configurations are key-value mappings. For standalone mode these are defined in a properties file and passed to the Connect process on the command line. In distributed mode, they will be included in the JSON payload for the request that creates (or modifies) the connector. Most configurations are connector dependent, but there are a few settings common to all connectors:
name- Unique name for the connector. Attempting to register again with the same name will fail.connector.class- The Java class for the connectortasks.max- The maximum number of tasks that should be created for this connector. The connector may create fewer tasks if it cannot achieve this level of parallelism.
Sink connectors also have one additional option to control their input:
topics- A list of topics to use as input for this connector
For other options, consult the documentation for individual connectors.
Configuring Workers¶
Whether you’re running standalone or distributed mode, Kafka Connect workers are configured by passing a properties
file containing any required or overridden options as the first parameter to the worker process. Some example
configuration files are included with the Confluent Platform to help you get started. We recommend using the files
etc/schema-registry/connect-avro-[standalone|distributed].properties as a starting point because they include the
necessary configuration to use Confluent Platform’s Avro converters that integrate with the Schema Registry. They are
configured to work well with Kafka and Schema Registry services running locally, making it easy to test Kafka Connect
locally; using them with production deployments should only require adjusting the hostnames for Kafka and Schema Registry.
An exhaustive listing of options is provided below, broken into several sections. The first lists options that can be set in either standalone or distributed mode. These control basic functionality like which Kafka cluster to communicate with and what format data you’re working with. The next two sections list settings specific to standalone or distributed mode. Finally, although it should not usually be required, the final section describes how to override the settings for the producers and consumers that are created internally by Kafka Connect.
Common Worker Configs¶
bootstrap.serversA list of host/port pairs to use for establishing the initial connection to the Kafka cluster. The client will make use of all servers irrespective of which servers are specified here for bootstrapping—this list only impacts the initial hosts used to discover the full set of servers. This list should be in the form <code>host1:port1,host2:port2,...</code>. Since these servers are just used for the initial connection to discover the full cluster membership (which may change dynamically), this list need not contain the full set of servers (you may want more than one, though, in case a server is down).
- Type: list
- Default: [localhost:9092]
- Importance: high
key.converterConverter class for key Connect data. This controls the format of the data that will be written to Kafka for source connectors or read from Kafka for sink connectors. Popular formats include Avro and JSON.
- Type: class
- Default:
- Importance: high
value.converterConverter class for value Connect data. This controls the format of the data that will be written to Kafka for source connectors or read from Kafka for sink connectors. Popular formats include Avro and JSON.
- Type: class
- Default:
- Importance: high
internal.key.converterConverter class for internal key Connect data that implements the <code>Converter</code> interface. Used for converting data like offsets and configs.
- Type: class
- Default:
- Importance: low
internal.value.converterConverter class for offset value Connect data that implements the <code>Converter</code> interface. Used for converting data like offsets and configs.
- Type: class
- Default:
- Importance: low
offset.flush.interval.msInterval at which to try committing offsets for tasks.
- Type: long
- Default: 60000
- Importance: low
offset.flush.timeout.msMaximum number of milliseconds to wait for records to flush and partition offset data to be committed to offset storage before cancelling the process and restoring the offset data to be committed in a future attempt.
- Type: long
- Default: 5000
- Importance: low
rest.advertised.host.nameIf this is set, this is the hostname that will be given out to other workers to connect to.
- Type: string
- Importance: low
rest.advertised.portIf this is set, this is the port that will be given out to other workers to connect to.
- Type: int
- Importance: low
rest.host.nameHostname for the REST API. If this is set, it will only bind to this interface.
- Type: string
- Importance: low
rest.portPort for the REST API to listen on.
- Type: int
- Default: 8083
- Importance: low
task.shutdown.graceful.timeout.msAmount of time to wait for tasks to shutdown gracefully. This is the total amount of time, not per task. All task have shutdown triggered, then they are waited on sequentially.
- Type: long
- Default: 5000
- Importance: low
Standalone Worker Configuration¶
In addition to the common worker configuration options, the following are available in standalone mode.
offset.storage.file.filenameThe file to store connector offsets in. By storing offsets on disk, a standalone process can be stopped and started on a single node and resume where it previously left off.
- Type: string
- Default: “”
- Importance: high
Distributed Worker Configuration¶
In addition to the common worker configuration options, the following are available in distributed mode.
group.idA unique string that identifies the Connect cluster group this worker belongs to.
- Type: string
- Default: “”
- Importance: high
config.storage.topicThe topic to store connector and task configuration data in. This must be the same for all workers with the same
group.id- Type: string
- Default: “”
- Importance: high
offset.storage.topicThe topic to store offset data for connectors in. This must be the same for all workers with the same
group.id- Type: string
- Default: “”
- Importance: high
heartbeat.interval.msThe expected time between heartbeats to the group coordinator when using Kafka’s group management facilities. Heartbeats are used to ensure that the worker’s session stays active and to facilitate rebalancing when new members join or leave the group. The value must be set lower than <code>session.timeout.ms</code>, but typically should be set no higher than 1/3 of that value. It can be adjusted even lower to control the expected time for normal rebalances.
- Type: int
- Default: 3000
- Importance: high
session.timeout.msThe timeout used to detect failures when using Kafka’s group management facilities.
- Type: int
- Default: 30000
- Importance: high
ssl.key.passwordThe password of the private key in the key store file. This is optional for client.
- Type: password
- Importance: high
ssl.keystore.locationThe location of the key store file. This is optional for client and can be used for two-way authentication for client.
- Type: string
- Importance: high
ssl.keystore.passwordThe store password for the key store file.This is optional for client and only needed if ssl.keystore.location is configured.
- Type: password
- Importance: high
ssl.truststore.locationThe location of the trust store file.
- Type: string
- Importance: high
ssl.truststore.passwordThe password for the trust store file.
- Type: password
- Importance: high
connections.max.idle.msClose idle connections after the number of milliseconds specified by this config.
- Type: long
- Default: 540000
- Importance: medium
receive.buffer.bytesThe size of the TCP receive buffer (SO_RCVBUF) to use when reading data.
- Type: int
- Default: 32768
- Importance: medium
request.timeout.msThe configuration controls the maximum amount of time the client will wait for the response of a request. If the response is not received before the timeout elapses the client will resend the request if necessary or fail the request if retries are exhausted.
- Type: int
- Default: 40000
- Importance: medium
sasl.kerberos.service.nameThe Kerberos principal name that Kafka runs as. This can be defined either in Kafka’s JAAS config or in Kafka’s config.
- Type: string
- Importance: medium
security.protocolProtocol used to communicate with brokers. Currently only PLAINTEXT and SSL are supported.
- Type: string
- Default: “PLAINTEXT”
- Importance: medium
send.buffer.bytesThe size of the TCP send buffer (SO_SNDBUF) to use when sending data.
- Type: int
- Default: 131072
- Importance: medium
ssl.enabled.protocolsThe list of protocols enabled for SSL connections. TLSv1.2, TLSv1.1 and TLSv1 are enabled by default.
- Type: list
- Default: [TLSv1.2, TLSv1.1, TLSv1]
- Importance: medium
ssl.keystore.typeThe file format of the key store file. This is optional for client. Default value is JKS
- Type: string
- Default: “JKS”
- Importance: medium
ssl.protocolThe SSL protocol used to generate the SSLContext. Default setting is TLS, which is fine for most cases. Allowed values in recent JVMs are TLS, TLSv1.1 and TLSv1.2. SSL, SSLv2 and SSLv3 may be supported in older JVMs, but their usage is discouraged due to known security vulnerabilities.
- Type: string
- Default: “TLS”
- Importance: medium
ssl.providerThe name of the security provider used for SSL connections. Default value is the default security provider of the JVM.
- Type: string
- Importance: medium
ssl.truststore.typeThe file format of the trust store file. Default value is JKS.
- Type: string
- Default: “JKS”
- Importance: medium
worker.sync.timeout.msWhen the worker is out of sync with other workers and needs to resynchronize configurations, wait up to this amount of time before giving up, leaving the group, and waiting a backoff period before rejoining.
- Type: int
- Default: 3000
- Importance: medium
worker.unsync.backoff.msWhen the worker is out of sync with other workers and fails to catch up within worker.sync.timeout.ms, leave the Connect cluster for this long before rejoining.
- Type: int
- Default: 300000
- Importance: medium
client.idAn id string to pass to the server when making requests. The purpose of this is to be able to track the source of requests beyond just ip/port by allowing a logical application name to be included in server-side request logging.
- Type: string
- Default: “”
- Importance: low
metadata.max.age.msThe period of time in milliseconds after which we force a refresh of metadata even if we haven’t seen any partition leadership changes to proactively discover any new brokers or partitions.
- Type: long
- Default: 300000
- Importance: low
metric.reportersA list of classes to use as metrics reporters. Implementing the <code>MetricReporter</code> interface allows plugging in classes that will be notified of new metric creation. The JmxReporter is always included to register JMX statistics.
- Type: list
- Default: []
- Importance: low
metrics.num.samplesThe number of samples maintained to compute metrics.
- Type: int
- Default: 2
- Importance: low
metrics.sample.window.msThe number of samples maintained to compute metrics.
- Type: long
- Default: 30000
- Importance: low
reconnect.backoff.msThe amount of time to wait before attempting to reconnect to a given host. This avoids repeatedly connecting to a host in a tight loop. This backoff applies to all requests sent by the consumer to the broker.
- Type: long
- Default: 50
- Importance: low
retry.backoff.msThe amount of time to wait before attempting to retry a failed fetch request to a given topic partition. This avoids repeated fetching-and-failing in a tight loop.
- Type: long
- Default: 100
- Importance: low
sasl.kerberos.kinit.cmdKerberos kinit command path. Default is /usr/bin/kinit
- Type: string
- Default: “/usr/bin/kinit”
- Importance: low
sasl.kerberos.min.time.before.reloginLogin thread sleep time between refresh attempts.
- Type: long
- Default: 60000
- Importance: low
sasl.kerberos.ticket.renew.jitterPercentage of random jitter added to the renewal time.
- Type: double
- Default: 0.05
- Importance: low
sasl.kerberos.ticket.renew.window.factorLogin thread will sleep until the specified window factor of time from last refresh to ticket’s expiry has been reached, at which time it will try to renew the ticket.
- Type: double
- Default: 0.8
- Importance: low
ssl.cipher.suitesA list of cipher suites. This is a named combination of authentication, encryption, MAC and key exchange algorithm used to negotiate the security settings for a network connection using TLS or SSL network protocol.By default all the available cipher suites are supported.
- Type: list
- Importance: low
ssl.endpoint.identification.algorithmThe endpoint identification algorithm to validate server hostname using server certificate.
- Type: string
- Importance: low
ssl.keymanager.algorithmThe algorithm used by key manager factory for SSL connections. Default value is the key manager factory algorithm configured for the Java Virtual Machine.
- Type: string
- Default: “SunX509”
- Importance: low
ssl.trustmanager.algorithmThe algorithm used by trust manager factory for SSL connections. Default value is the trust manager factory algorithm configured for the Java Virtual Machine.
- Type: string
- Default: “PKIX”
- Importance: low
Overriding Producer & Consumer Settings¶
Internally, Kafka Connect uses the standard Java producer and consumers to communicate with Kafka. Kafka Connect configures these producer and consumer instances with good defaults. Most importantly, it is configured with important settings that ensure data from sources will be delivered to Kafka in order and without any loss. The most critical site-specific options, such as the Kafka bootstrap servers, are already exposed via the standard worker configuration.
Occasionally, you may have an application that needs to adjust the default settings. One example is a standalone process that runs a log file connector. For the logs being collected, you might prefer low-latency, best-effort delivery – minor loss in the case of connectivity issues might be acceptable for this application in order to avoid any data buffering on the client, keeping the log collection as lean as possible.
All new producer configs and
new consumer configs can be overridden by prefixing
them with producer. or consumer., respectively. For example:
producer.retries=1
consumer.max.partition.fetch.bytes=10485760
would override the producers to only retry sending messages once and increase the default amount of data fetched from a partition per request to 10 MB.
Note that these configuration changes are applied to all connectors running on the worker. You should be especially careful making any changes to these settings when running distributed mode workers.
Connect Administration¶
Kafka Connect’s Rest API enables administration of the cluster. This includes APIs to view the configuration of connectors and the status of their tasks, as well as to alter their current behavior (e.g. changing configuration and restarting tasks).
When a connector is first submitted to the cluster, the workers rebalance the full set of connectors in the cluster and their tasks so that each worker has approximately the same amount of work. This same rebalancing procedure is also used when connectors increase or decrease the number of tasks they require, or when a connector’s configuration is changed. You can use the REST API to view the current status of a connector and its tasks, including the id of the worker to which each was assigned.
Connectors and their tasks publish status updates to a shared topic (configured with
status.storage.topic) which all workers in the cluster monitor. Because the workers consume
this topic asynchronously, there is typically a short delay before a state change is visible
through the status API. The following states are possible for a connector or one of its tasks:
UNASSIGNED: The connector/task has not yet been assigned to a worker.RUNNING: The connector/task is running.PAUSED: The connector/task has been administratively paused.FAILED:The connector/task has failed (usually by raising an exception, which is reported in the status output).
In most cases, connector and task states will match, though they may be different for short periods
of time when changes are occurring or if tasks have failed. For example, when a connector is first
started, there may be a noticeable delay before the connector and its tasks have all transitioned to
the RUNNING state. States will also diverge when tasks fail since Connect does not automatically
restart failed tasks. To restart a connector/task manually, you can use the restart APIs listed
above. Note that if you try to restart a task while a rebalance is taking place, Connect will
return a 409 (Conflict) status code. You can retry after the rebalance completes, but it might
not be necessary since rebalances effectively restart all the connectors and tasks in the cluster.
It’s sometimes useful to temporarily stop the message processing of a connector. For example,
if the remote system is undergoing maintenance, it would be preferable for source connectors to
stop polling it for new data instead of filling logs with exception spam. For this use case,
Connect offers a pause/resume API. While a source connector is paused, Connect will stop polling it
for additional records. While a sink connector is paused, Connect will stop pushing new messages to
it. The pause state is persistent, so even if you restart the cluster, the connector will not begin
message processing again until the task has been resumed. Note that there may be a delay before all
of a connector’s tasks have transitioned to the PAUSED state since it may take time for them to
finish whatever processing they were in the middle of when being paused. Additionally, failed tasks
will not transition to the PAUSED state until they have been restarted.
REST Interface¶
Since Kafka Connect is intended to be run as a service, it also supports a REST API for managing connectors.
By default this service runs on port 8083. When executed in distributed mode, the REST API will be the primary
interface to the cluster. You can make requests to any cluster member; the REST API automatically forwards requests if
required.
Although you can use the standalone mode just by submitting a connector on the command line, it also runs the REST interface. This is useful for getting status information, adding and removing connectors without stopping the process, and more.
Currently the top level resources are connector and connector-plugins. The sub-resources for connector
lists configuration settings and tasks and the sub-resource for connector-plugins provides configuration
validation and recommendation.
Note that if you try to modify, update or delete a resource under connector which may require the request
to be forwarded to the leader, Connect will return status code 409 while the worker group rebalance is in process
as the leader may change during rebalance.
Content Types¶
Currently the REST API only supports application/json as both the request and response entity content type. Your
requests should specify the expected content type of the response via the HTTP Accept header:
Accept: application/json
and should specify the content type of the request entity (if one is included) via the Content-Type header:
Content-Type: application/json
Statuses & Errors¶
The REST API will return standards-compliant HTTP statuses. Clients should check the HTTP status, especially before attempting to parse and use response entities. Currently the API does not use redirects (statuses in the 300 range), but the use of these codes is reserved for future use so clients should handle them.
When possible, all endpoints will use a standard error message format for all errors (status codes in the 400 or 500 range). For example, a request entity that omits a required field may generate the following response:
HTTP/1.1 422 Unprocessable Entity Content-Type: application/json { "error_code": 422, "message": "config may not be empty" }
Connectors¶
-
GET/connectors¶ Get a list of active connectors
Request JSON Object: - connectors (array) – List of connector names
Example request:
GET /connectors HTTP/1.1 Host: connect.example.com Accept: application/json
Example response:
HTTP/1.1 200 OK Content-Type: application/json ["my-jdbc-source", "my-hdfs-sink"]
-
POST/connectors¶ Create a new connector, returning the current connector info if successful. Return
409 (Conflict)if rebalance is in process.Request JSON Object: - name (string) – Name of the connector to create
- config (map) – Configuration parameters for the connector. All values should be strings.
Response JSON Object: - name (string) – Name of the created connector
- config (map) – Configuration parameters for the connector.
- tasks (array) – List of active tasks generated by the connector
- tasks[i].connector (string) – The name of the connector the task belongs to
- tasks[i].task (int) – Task ID within the connector.
Example request:
POST /connectors HTTP/1.1 Host: connect.example.com Content-Type: application/json Accept: application/json { "name": "hdfs-sink-connector", "config": { "connector.class": "io.confluent.connect.hdfs.HdfsSinkConnector", "tasks.max": "10", "topics": "test-topic", "hdfs.url": "hdfs://fakehost:9000", "hadoop.conf.dir": "/opt/hadoop/conf", "hadoop.home": "/opt/hadoop", "flush.size": "100", "rotate.interval.ms": "1000" } }
Example response:
HTTP/1.1 201 Created Content-Type: application/json { "name": "hdfs-sink-connector", "config": { "connector.class": "io.confluent.connect.hdfs.HdfsSinkConnector", "tasks.max": "10", "topics": "test-topic", "hdfs.url": "hdfs://fakehost:9000", "hadoop.conf.dir": "/opt/hadoop/conf", "hadoop.home": "/opt/hadoop", "flush.size": "100", "rotate.interval.ms": "1000" }, "tasks": [ { "connector": "hdfs-sink-connector", "task": 1 }, { "connector": "hdfs-sink-connector", "task": 2 }, { "connector": "hdfs-sink-connector", "task": 3 } ] }
-
GET/connectors/(string: name)¶ Get information about the connector.
Response JSON Object: - name (string) – Name of the created connector
- config (map) – Configuration parameters for the connector.
- tasks (array) – List of active tasks generated by the connector
- tasks[i].connector (string) – The name of the connector the task belongs to
- tasks[i].task (int) – Task ID within the connector.
Example request:
GET /connectors/hdfs-sink-connector HTTP/1.1 Host: connect.example.com Accept: application/json
Example response:
HTTP/1.1 200 OK Content-Type: application/json { "name": "hdfs-sink-connector", "config": { "connector.class": "io.confluent.connect.hdfs.HdfsSinkConnector", "tasks.max": "10", "topics": "test-topic", "hdfs.url": "hdfs://fakehost:9000", "hadoop.conf.dir": "/opt/hadoop/conf", "hadoop.home": "/opt/hadoop", "flush.size": "100", "rotate.interval.ms": "1000" }, "tasks": [ { "connector": "hdfs-sink-connector", "task": 1 }, { "connector": "hdfs-sink-connector", "task": 2 }, { "connector": "hdfs-sink-connector", "task": 3 } ] }
-
GET/connectors/(string: name)/config¶ Get the configuration for the connector.
Response JSON Object: - config (map) – Configuration parameters for the connector.
Example request:
GET /connectors/hdfs-sink-connector/config HTTP/1.1 Host: connect.example.com Accept: application/json
Example response:
HTTP/1.1 200 OK Content-Type: application/json { "connector.class": "io.confluent.connect.hdfs.HdfsSinkConnector", "tasks.max": "10", "topics": "test-topic", "hdfs.url": "hdfs://fakehost:9000", "hadoop.conf.dir": "/opt/hadoop/conf", "hadoop.home": "/opt/hadoop", "flush.size": "100", "rotate.interval.ms": "1000" }
-
PUT/connectors/(string: name)/config¶ Create a new connector using the given configuration, or update the configuration for an existing connector. Returns information about the connector after the change has been made. Return
409 (Conflict)if rebalance is in process.Request JSON Object: - config (map) – Configuration parameters for the connector. All values should be strings.
Response JSON Object: - name (string) – Name of the created connector
- config (map) – Configuration parameters for the connector.
- tasks (array) – List of active tasks generated by the connector
- tasks[i].connector (string) – The name of the connector the task belongs to
- tasks[i].task (int) – Task ID within the connector.
Example request:
PUT /connectors/hdfs-sink-connector/config HTTP/1.1 Host: connect.example.com Accept: application/json { "connector.class": "io.confluent.connect.hdfs.HdfsSinkConnector", "tasks.max": "10", "topics": "test-topic", "hdfs.url": "hdfs://fakehost:9000", "hadoop.conf.dir": "/opt/hadoop/conf", "hadoop.home": "/opt/hadoop", "flush.size": "100", "rotate.interval.ms": "1000" }
Example response:
HTTP/1.1 201 Created Content-Type: application/json { "name": "hdfs-sink-connector", "config": { "connector.class": "io.confluent.connect.hdfs.HdfsSinkConnector", "tasks.max": "10", "topics": "test-topic", "hdfs.url": "hdfs://fakehost:9000", "hadoop.conf.dir": "/opt/hadoop/conf", "hadoop.home": "/opt/hadoop", "flush.size": "100", "rotate.interval.ms": "1000" }, "tasks": [ { "connector": "hdfs-sink-connector", "task": 1 }, { "connector": "hdfs-sink-connector", "task": 2 }, { "connector": "hdfs-sink-connector", "task": 3 } ] }
Note that in this example the return status indicates that the connector was
Created. In the case of a configuration update the status would have been200 OK.
-
GET/connectors/(string: name)/tasks¶ Get a list of tasks currently running for the connector.
Response JSON Object: - tasks (array) – List of active task configs that have been created by the connector
- tasks[i].id (string) – The ID of task
- tasks[i].id.connector (string) – The name of the connector the task belongs to
- tasks[i].id.task (int) – Task ID within the connector.
- tasks[i].config (map) – Configuration parameters for the task
Example request:
GET /connectors/hdfs-sink-connector/tasks HTTP/1.1 Host: connect.example.com
Example response:
HTTP/1.1 200 OK [ { "task.class": "io.confluent.connect.hdfs.HdfsSinkTask", "topics": "test-topic", "hdfs.url": "hdfs://fakehost:9000", "hadoop.conf.dir": "/opt/hadoop/conf", "hadoop.home": "/opt/hadoop", "flush.size": "100", "rotate.interval.ms": "1000" }, { "task.class": "io.confluent.connect.hdfs.HdfsSinkTask", "topics": "test-topic", "hdfs.url": "hdfs://fakehost:9000", "hadoop.conf.dir": "/opt/hadoop/conf", "hadoop.home": "/opt/hadoop", "flush.size": "100", "rotate.interval.ms": "1000" } ]
-
DELETE/connectors/(string: name)/¶ Delete a connector, halting all tasks and deleting its configuration. Return
409 (Conflict)if rebalance is in process.Example request:
DELETE /connectors/hdfs-sink-connector HTTP/1.1 Host: connect.example.com
Example response:
HTTP/1.1 204 No Content
-
GET/connectors/(string: name)/status¶ Get current status of the connector, including whether it is running, failed or paused, which worker it is assigned to, error information if it has failed, and the state of all its tasks.
Response JSON Object: - name (string) – The name of the connector.
- connector (map) – The map containing connector status.
- tasks[i] (map) – The map containing the task status.
Example request:
GET /connectors/hdfs-sink-connector/status HTTP/1.1 Host: connect.example.com
Example response:
HTTP/1.1 200 OK { "name": "hdfs-sink-connector", "connector": { "state": "RUNNING", "worker_id": "fakehost:8083" }, "tasks": [ { "id": 0, "state": "RUNNING", "worker_id": "fakehost:8083" }, { "id": 1, "state": "FAILED", "worker_id": "fakehost:8083", "trace": "org.apache.kafka.common.errors.RecordTooLargeException\n" } ] }
-
POST/connectors/(string: name)/restart¶ Restart the connector and its tasks. Return
409 (Conflict)if rebalance is in process.Example request:
POST /connectors/hdfs-sink-connector/restart HTTP/1.1 Host: connect.example.com
Example response:
HTTP/1.1 200 OK
-
PUT/connectors/(string: name)/pause¶ Pause the connector and its tasks, which stops message processing until the connector is resumed. This call asynchronous and the tasks will not transition to
PAUSEDstate at the same time.Example request:
PUT /connectors/hdfs-sink-connector/pause HTTP/1.1 Host: connect.example.com
Example response:
HTTP/1.1 202 Accepted
-
PUT/connectors/(string: name)/resume¶ Resume a paused connector or do nothing if the connector is not paused. This call asynchronous and the tasks will not transition to
RUNNINGstate at the same time.Example request:
PUT /connectors/hdfs-sink-connector/resume HTTP/1.1 Host: connect.example.com
Example response:
HTTP/1.1 202 Accepted
Connector Plugins¶
-
GET/connector-plugins/¶ Return a list of connector plugins installed in the Kafka Connect cluster. Note that the API only checks for connectors on the worker that handles the request, which means it is possible to see inconsistent results, especially during a rolling upgrade if you add new connector jars.
Response JSON Object: - class (string) – The connector class name.
Example request:
GET /connector-plugins/ HTTP/1.1 Host: connect.example.com
Example response:
HTTP/1.1 200 OK { "class": "io.confluent.connect.hdfs.HdfsSinkConnector", "class": "io.confluent.connect.jdbc.JdbcSourceConnector" }
-
PUT/connector-plugins/(string: name)/config/validate¶ Validate the provided configuration values against the configuration definition. This API performs per config validation, returns suggested values and error messages during validation.
Request JSON Object: - config (map) – Configuration parameters for the connector. All values should be strings.
Response JSON Object: - name (string) – The class name of the connector plugin.
- error_count (int) – The total number of errors encountered during configuration validation.
- groups (array) – The list of groups used in configuration definitions.
- configs[i].definition (map) – The definition for a config in the connector plugin, which includes the name, type, importance, etc.
- configs[i].value (map) – The current value for a config, which includes the name, value, recommended values, etc.
Example request:
PUT /connector-plugins/FileStreamSinkConnector/config/validate/ HTTP/1.1 Host: connect.example.com Accept: application/json { "connector.class": "org.apache.kafka.connect.file.FileStreamSinkConnector", "tasks.max": "1", "topics": "test-topic" }
Example response:
HTTP/1.1 200 OK { "name": "FileStreamSinkConnector", "error_count": 1, "groups": [ "Common" ], "configs": [ { "definition": { "name": "topics", "type": "LIST", "required": false, "default_value": "", "importance": "HIGH", "documentation": "", "group": "Common", "width": "LONG", "display_name": "Topics", "dependents": [], "order": 4 }, "value": { "name": "topics", "value": "test-topic", "recommended_values": [], "errors": [], "visible": true } }, { "definition": { "name": "file", "type": "STRING", "required": true, "default_value": "", "importance": "HIGH", "documentation": "Destination filename.", "group": null, "width": "NONE", "display_name": "file", "dependents": [], "order": -1 }, "value": { "name": "file", "value": null, "recommended_values": [], "errors": [ "Missing required configuration \"file\" which has no default value." ], "visible": true } }, { "definition": { "name": "name", "type": "STRING", "required": true, "default_value": "", "importance": "HIGH", "documentation": "Globally unique name to use for this connector.", "group": "Common", "width": "MEDIUM", "display_name": "Connector name", "dependents": [], "order": 1 }, "value": { "name": "name", "value": "test", "recommended_values": [], "errors": [], "visible": true } }, { "definition": { "name": "tasks.max", "type": "INT", "required": false, "default_value": "1", "importance": "HIGH", "documentation": "Maximum number of tasks to use for this connector.", "group": "Common", "width": "SHORT", "display_name": "Tasks max", "dependents": [], "order": 3 }, "value": { "name": "tasks.max", "value": "1", "recommended_values": [], "errors": [], "visible": true } }, { "definition": { "name": "connector.class", "type": "STRING", "required": true, "default_value": "", "importance": "HIGH", "documentation": "Name or alias of the class for this connector. Must be a subclass of org.apache.kafka.connect.connector.Connector. If the connector is org.apache.kafka.connect.file.FileStreamSinkConnector, you can either specify this full name, or use \"FileStreamSink\" or \"FileStreamSinkConnector\" to make the configuration a bit shorter", "group": "Common", "width": "LONG", "display_name": "Connector class", "dependents": [], "order": 2 }, "value": { "name": "connector.class", "value": "org.apache.kafka.connect.file.FileStreamSinkConnector", "recommended_values": [], "errors": [], "visible": true } } ] }
Installing Connector Plugins¶
Confluent Platform ships with commonly used connector plugins that have been tested with the rest of the platform. However, Kafka Connect is designed to be extensible so that it is easy for other developers to create new connectors and for users to run them with minimal effort.
All that is required to install a new plugin is to place it in the CLASSPATH of the Kafka Connect process. All the
scripts for running Kafka Connect will use the CLASSPATH environment variable if it is set when they are invoked,
making it easy to run with additional connector plugins:
$ export CLASSPATH=/path/to/my/connectors/*
$ bin/connect-standalone standalone.properties new-custom-connector.properties