Developer Guide¶
Table of Contents
- Code examples
- Configuring a Kafka Streams application
- Writing a Kafka Streams application
- Running a Kafka Streams application
- Data types and serialization
- Security
- Application Reset Tool
Code examples¶
Before we begin the deep-dive into Kafka Streams in the subsequent sections, you might want to take a look at a few examples first.
Streams application examples in Apache Kafka¶
The Apache Kafka project includes a few Kafka Streams code examples, which demonstrate the use of the Kafka Streams DSL and the low-level Processor API; and a juxtaposition of typed vs. untyped examples.
Streams application examples provided by Confluent¶
The Confluent examples repository contains several Kafka Streams examples, which demonstrate the use of Java 8 lambda expressions (which simplify the code significantly), how to read/write Avro data, and how to implement end-to-end integration tests using embedded Kafka clusters.
Simple examples¶
- Java programming language
- With lambda expressions for Java 8+:
- Without lambda expressions for Java 7+:
- Scala programming language
Security examples¶
- Java programming language
- Without lambda expressions for Java 7+:
End-to-end demo applications¶
These demo applications use embedded instances of Kafka, ZooKeeper, and/or Confluent Schema Registry. They are implemented as integration tests.
- Java programming language
- With lambda expressions for Java 8+:
- Without lambda expressions for Java 7+:
- Scala programming language
Configuring a Kafka Streams application¶
Overview¶
The configuration of Kafka Streams is done by specifying parameters in a StreamsConfig instance.
Typically, you create a java.util.Properties instance, set the necessary parameters, and construct a StreamsConfig instance from the Properties instance.
How this StreamsConfig instance is used further (and passed along to other Streams classes) will be explained in the subsequent sections.
import java.util.Properties;
import org.apache.kafka.streams.StreamsConfig;
Properties settings = new Properties();
// Set a few key parameters
settings.put(StreamsConfig.APPLICATION_ID_CONFIG, "my-first-streams-application");
settings.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-broker1:9092");
settings.put(StreamsConfig.ZOOKEEPER_CONNECT_CONFIG, "zookeeper1:2181");
// Any further settings
settings.put(... , ...);
// Create an instance of StreamsConfig from the Properties instance
StreamsConfig config = new StreamsConfig(settings);
Required configuration parameters¶
The table below is a list of required configuration parameters.
| Parameter Name | Description | Default Value |
|---|---|---|
| application.id | An identifier for the stream processing application. Must be unique within the Kafka cluster. | <none> |
| bootstrap.servers | A list of host/port pairs to use for establishing the initial connection to the Kafka cluster | <none> |
| zookeeper.connect | Zookeeper connect string for Kafka topic management | the empty string |
Application Id (application.id):
Each stream processing application must have a unique id. The same id must be given to all instances of the application. It is recommended to use only alphanumeric characters, . (dot), - (hyphen), and _ (underscore).
Examples: "hello_world", "hello_world-v1.0.0"
This id is used in the following places to isolate resources used by the application from others:
- As the default Kafka consumer and producer
client.idprefix - As the Kafka consumer
group.idfor coordination - As the name of the sub-directory in the state directory (cf.
state.dir) - As the prefix of internal Kafka topic names
Attention
When an application is updated, it is recommended to change application.id unless it is safe to let the updated application re-use the existing data in internal topics and state stores.
One pattern could be to embed version information within application.id, e.g., my-app-v1.0.0 vs. my-app-v1.0.2.
Kafka Bootstrap Servers (bootstrap.servers):
This is the same setting that is used by the underlying producer and consumer clients to connect to the Kafka cluster.__
Example: "kafka-broker1:9092,kafka-broker2:9092".
Note
One Kafka cluster only: Currently Kafka Streams applications can only talk to a single Kafka cluster specified by this config value. In the future Kafka Streams will be able to support connecting to different Kafka clusters for reading input streams and/or writing output streams.
ZooKeeper connection (zookeeper.connect):
Currently Kafka Streams needs to access ZooKeeper directly for creating its internal topics.
Internal topics are created when a state store is used, or when a stream is repartitioned for aggregation.
This setting must point to the same ZooKeeper ensemble that your Kafka cluster uses (cf. bootstrap.servers).
Example: "zookeeper1:2181".
Note
ZooKeeper dependency of Kafka Streams and zookeeper.connect: This configuration option is temporary and will be removed after KIP-4 is incorporated, which is planned post 0.10.0.1 release.
Optional configuration parameters¶
The table below is a list of optional configuration parameters. However, users should consider setting the following parameters consciously.
| Parameter Name | Description | Default Value |
|---|---|---|
| buffered.records.per.partition | The maximum number of records to buffer per partition | 1000 |
| client.id | An id string to pass to the server when making requests. (This setting is passed to the consumer/producer clients used internally by Kafka Streams.) | the empty string |
| commit.interval.ms | The frequency with which to save the position (offsets in source topics) of tasks | 30000 (millisecs) |
| key.serde | Default serializer/deserializer class for record keys, implements the Serde interface (see also value.serde) |
Serdes.ByteArraySerde.class.getName() |
| metric.reporters | A list of classes to use as metrics reporters | the empty list |
| metrics.num.samples | The number of samples maintained to compute metrics. | 2 |
| metrics.sample.window.ms | The window of time a metrics sample is computed over. | 30000 (millisecs) |
| num.standby.replicas | The number of standby replicas for each task | 0 |
| num.stream.threads | The number of threads to execute stream processing | 1 |
| partition.grouper | Partition grouper class that implements the PartitionGrouper interface |
see Partition Grouper |
| poll.ms | The amount of time in milliseconds to block waiting for input | 100 (millisecs) |
| replication.factor | The replication factor for changelog topics and repartition topics created by the application | 1 |
| state.cleanup.delay.ms | The amount of time in milliseconds to wait before deleting state when a partition has migrated | 60000 (millisecs) |
| state.dir | Directory location for state stores | /var/lib/kafka-streams |
| timestamp.extractor | Timestamp extractor class that implements the TimestampExtractor interface |
see Timestamp Extractor |
| value.serde | Default serializer/deserializer class for record values, implements the Serde interface (see also key.serde) |
Serdes.ByteArraySerde.class.getName() |
Ser-/Deserialization (key.serde, value.serde): Serialization and deserialization in Kafka Streams happens whenever data needs to be materialized, i.e.,:
- Whenever data is read from or written to a Kafka topic (e.g., via the
KStreamBuilder#stream()andKStream#to()methods). - Whenever data is read from or written to a state store.
We will discuss this in more details later in Data types and serialization.
Number of Standby Replicas (num.standby.replicas): This specifies the number of standby replicas. Standby replicas are shadow copies of local state stores. Kafka Streams attempts to create the specified number of replicas and keep them up to date as long as there are enough instances running. Standby replicas are used to minimize the latency of task failover. A task that was previously running on a failed instance is preferred to restart on an instance that has standby replicas so that the local state store restoration process from its changelog can be minimized. Details about how Kafka Streams makes use of the standby replicas to minimize the cost of resuming tasks on failover can be found in the State section.
Number of Stream Threads (num.stream.threads): This specifies the number of stream threads in an instance of the Kafka Streams application. The stream processing code runs in these threads. Details about Kafka Streams threading model can be found in section Threading Model.
Replication Factor of Internal Topics (replication.factor): This specifies the replication factor of internal topics that Kafka Streams creates when local states are used or a stream is repartitioned for aggregation. Replication is important for fault tolerance. Without replication even a single broker failure may prevent progress of the stream processing application. It is recommended to use a similar replication factor as source topics.
State Directory (state.dir): Kafka Streams persists local states under the state directory. Each application has a subdirectory on its hosting machine, whose name is the application id, directly under the state directory. The state stores associated with the application are created under this subdirectory.
Timestamp Extractor (timestamp.extractor): A timestamp extractor extracts a timestamp from an instance of ConsumerRecord. Timestamps are used to control the progress of streams.
The default extractor is ConsumerRecordTimestampExtractor.
This extractor retrieves built-in timestamps that are automatically embedded into Kafka messages by the Kafka producer client (introduced in Kafka 0.10.0.0, see KIP-32: Add timestamps to Kafka message). Depending on the setting of Kafka’s log.message.timestamp.type parameter, this extractor will provide you with:
- event-time processing semantics if
log.message.timestamp.typeis set toCreateTimeaka “producer time” (which is the default). This represents the time when the Kafka producer sent the original message. - ingestion-time processing semantics if
log.message.timestamp.typeis set toLogAppendTimeaka “broker time”. This represents the time when the Kafka broker received the original message.
Another built-in extractor is WallclockTimestampExtractor. This extractor does not actually “extract” a timestamp from the consumed record but rather returns the current time in milliseconds from the system clock, which effectively means Streams will operate on the basis of the so-called processing-time of events.
You can also provide your own timestamp extractors, for instance to retrieve timestamps embedded in the payload of messages.
Here is an example of a custom TimestampExtractor implementation:
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.streams.processor.TimestampExtractor;
// Extracts the embedded timestamp of a record (giving you "event time" semantics).
public class MyEventTimeExtractor implements TimestampExtractor {
@Override
public long extract(ConsumerRecord<Object, Object> record) {
// `Foo` is your own custom class, which we assume has a method that returns
// the embedded timestamp (in milliseconds).
Foo myPojo = (Foo) record.value();
if (myPojo != null) {
return myPojo.getTimestampInMillis();
}
else {
// Kafka allows `null` as message value. How to handle such message values
// depends on your use case. In this example, we decide to fallback to
// wall-clock time (= processing-time).
return System.currentTimeMillis();
}
}
}
You would then define the custom timestamp extractor in your Streams configuration as follows:
import java.util.Properties;
import org.apache.kafka.streams.StreamsConfig;
Properties settings = new Properties();
settings.put(StreamsConfig.TIMESTAMP_EXTRACTOR_CLASS_CONFIG, MyEventTimeExtractor.class.getName());
Partition Grouper (partition.grouper): A partition grouper is used to create a list of stream tasks given the partitions of source topics, where each created task is assigned with a group of source topic partitions. The default implementation provided by Kafka Streams is DefaultPartitionGrouper, which assigns each task with at most one partition for each of the source topic partitions; therefore, the generated number of tasks is equal to the largest number of partitions among the input topics. Usually an application does not need to customize the partition grouper.
Non-Streams configuration parameters¶
Apart from Kafka Streams’ own configuration parameters (see previous sections) you can also specify parameters for the Kafka consumers and producers that are used internally, depending on the needs of your application. Similar to the Streams settings you define any such consumer and/or producer settings via StreamsConfig:
Properties streamsSettings = new Properties();
// Example of a "normal" setting for Kafka Streams
streamsSettings.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-broker-01:9092");
// Customize the Kafka consumer settings of your Streams application
streamsSettings.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 60000);
StreamsConfig config = new StreamsConfig(streamsSettings);
Note
A future version of Kafka Streams will allow developers to set their own app-specific configuration settings through StreamsConfig as well, which can then be accessed through
ProcessorContext.
Writing a Kafka Streams application¶
Overview¶
Any Java application that makes use of the Kafka Streams library is considered a Kafka Streams application. The computational logic of a Kafka Streams application is defined as a processor topology, which is a graph of stream processors (nodes) and streams (edges).
Currently Kafka Streams provides two sets of APIs to define the processor topology:
- A low-level Processor API that lets you add and connect processors as well as interact directly with state stores.
- A high-level Kafka Streams DSL that provides common data transformation operations in a functional programming style such as
mapandfilteroperations. The DSL is the recommended starting point for developers new to Kafka Streams, and should cover many use cases and stream processing needs.
We describe both of these APIs in the subsequent sections.
Libraries and maven artifacts¶
This section lists the Kafka Streams related libraries that are available for writing your Kafka Streams applications.
The corresponding maven artifacts of these libraries are available in Confluent’s maven repository:
<!-- Example pom.xml snippet when using maven to build your Java applications. -->
<repositories>
<repository>
<id>confluent</id>
<url>http://packages.confluent.io/maven/</url>
</repository>
</repositories>
Depending on your use case you will need to define dependencies on the following libraries for your Kafka Streams applications.
| Group Id | Artifact Id | Version | Description / why needed |
|---|---|---|---|
| org.apache.kafka | kafka-streams | 0.10.0.1-cp1 | Base library for Kafka Streams. Required. |
| org.apache.kafka | kafka-clients | 0.10.0.1-cp1 | Kafka client library. Contains built-in serializers/deserializers. Required. |
| org.apache.avro | avro | 1.7.7 | Apache Avro library. Optional (needed only when using Avro). |
| io.confluent | kafka-avro-serializer | 3.0.1 | Confluent’s Avro serializer/deserializer. Optional (needed only when using Avro). |
Tip
See the section Data types and serialization for more information about serializers/deserializers.
Example pom.xml snippet when using maven:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>0.10.0.1-cp1</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.10.0.1-cp1</version>
</dependency>
<!-- Dependencies below are required/recommended only when using Apache Avro. -->
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-avro-serializer</artifactId>
<version>3.0.1</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>1.7.7</version>
</dependency>
See the Kafka Streams examples in the Confluent examples repository for a full maven/pom setup.
Using Kafka Streams within your application code¶
You can call Kafka Streams from anywhere in your application code. Very commonly though you would do so within the
main() method of your application, or some variant thereof. The most important elements of defining a processing topology within your application are described below.
First, you must create an instance of KafkaStreams.
- The first argument of the
KafkaStreamsconstructor takes a topology builder (eitherKStreamBuilderfor the Kafka Streams DSL, orTopologyBuilderfor the Processor API) that is used to define a topology. - The second argument is an instance of
StreamsConfig, which defines the configuration for this specific topology.
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStreamBuilder;
import org.apache.kafka.streams.processor.TopologyBuilder;
// Use the builders to define the actual processing topology, e.g. to specify
// from which input topics to read, which stream operations (filter, map, etc.)
// should be called, and so on.
KStreamBuilder builder = ...; // when using the Kafka Streams DSL
//
// OR
//
TopologyBuilder builder = ...; // when using the Processor API
// Use the configuration to tell your application where the Kafka cluster is,
// which serializers/deserializers to use by default, to specify security settings,
// and so on.
StreamsConfig config = ...;
KafkaStreams streams = new KafkaStreams(builder, config);
At this point, internal structures are initialized, but the processing is not started yet.
You have to explicitly start the Kafka Streams thread by calling the start() method:
// Start the Kafka Streams threads
streams.start();
If there are other instances of this stream processing application running elsewhere (e.g., on another machine), Kafka Streams transparently re-assigns tasks from the existing instances to the new instance that you just started. See Stream Partitions and Tasks and Threading Model for details.
To catch any unexpected exceptions, you may set an java.lang.Thread.UncaughtExceptionHandler before you start the application. This handler is called whenever a stream thread is terminated by an unexpected exception:
streams.setUncaughtExceptionHandler(new Thread.UncaughtExceptionHandler() {
public uncaughtException(Thread t, throwable e) {
// here you should examine the exception and perform an appropriate action!
}
);
To stop the application instance call the close() method:
// Stop the Kafka Streams threads
streams.close();
So that your application can gracefully shutdown in response to SIGTERM, it is recommended that you add a shutdown hook and call KafkaStreams#close.
Shutdown hook example In Java 8+
// add shutdown hook to stop the Kafka Streams threads Runtime.getRuntime().addShutdownHook(new Thread(streams::close));
Shutdown hook example In Java 7
// add shutdown hook Runtime.getRuntime().addShutdownHook(new Thread(new Runnable() { @Override public void run() { // Stop the Kafka Streams threads streams.close(); } }));
After a particular instance of the application was stopped, Kafka Streams migrates any tasks that had been running in this instance to other running instances (assuming there are any such instances remaining).
In the following sections we describe the two APIs of Kafka Streams in more detail, which is what you will use in combination with KStreamBuilder (Kafka Streams DSL) or TopologyBuilder (Processor API) to define the actual processing topology.
Processor API¶
Note
See also the Kafka Streams Javadocs for a complete list of available API functionality.
Overview¶
As mentioned in the Concepts section, a stream processor is a node in the processor topology that represents a single processing step. With the Processor API users can define arbitrary stream processors that processes one received record at a time, and connect these processors with their associated state stores to compose the processor topology.
Defining a Stream Processor¶
Users can define their customized stream processor by implementing the Processor interface, which provides two main API methods:
process() and punctuate().
process()is called on each of the received record.punctuate()is called periodically based on advanced record timestamps. For example, if processing-time is used as the record timestamp, thenpunctuate()will be triggered every specified period of time.
The Processor interface also has an init() method, which is called by the Kafka Streams library during task construction phase. Processor instances should perform any required initialization in this method. The init() method passes in a ProcessorContext instance, which provides access to the metadata of the currently processed record, including its source Kafka topic and partition, its corresponding message offset, and further such information . This context instance can also be used to schedule the punctuation period (via ProcessorContext#schedule()) for punctuate(), to forward a new record as a key-value pair to the downstream processors (via ProcessorContext#forward()), and to commit the current processing progress (via ProcessorContext#commit()).
The following example Processor implementation defines a simple word-count algorithm:
public class WordCountProcessor implements Processor<String, String> {
private ProcessorContext context;
private KeyValueStore<String, Long> kvStore;
@Override
@SuppressWarnings("unchecked")
public void init(ProcessorContext context) {
// keep the processor context locally because we need it in punctuate() and commit()
this.context = context;
// call this processor's punctuate() method every 1000 time units.
this.context.schedule(1000);
// retrieve the key-value store named "Counts"
kvStore = (KeyValueStore) context.getStateStore("Counts");
}
@Override
public void process(String dummy, String line) {
String[] words = line.toLowerCase().split(" ");
for (String word : words) {
Long oldValue = kvStore.get(word);
if (oldValue == null) {
kvStore.put(word, 1L);
} else {
kvStore.put(word, oldValue + 1L);
}
}
}
@Override
public void punctuate(long timestamp) {
KeyValueIterator<String, Long> iter = this.kvStore.all();
while (iter.hasNext()) {
KeyValue<String, Long> entry = iter.next();
context.forward(entry.key, entry.value.toString());
}
iter.close();
// commit the current processing progress
context.commit();
}
@Override
public void close() {
// close the key-value store
kvStore.close();
}
}
In the above implementation, the following actions are performed:
- In the
init()method, schedule the punctuation every 1000 time units (the time unit is normally milliseconds, which in this example would translate to punctuation every 1 second) and retrieve the local state store by its name “Counts”. - In the
process()method, upon each received record, split the value string into words, and update their counts into the state store (we will talk about this later in this section). - In the
punctuate()method, iterate the local state store and send the aggregated counts to the downstream processor (we will talk about downstream processors later in this section), and commit the current stream state.
Defining a State Store¶
Note that the WordCountProcessor defined above can not only access the currently received record in the process() method,
but also maintain processing states to keep recently arrived records for stateful processing needs such as aggregations and joins.
To take advantage of these states, users can define a state store by implementing the StateStore interface (the Kafka Streams library
also has a few extended interfaces such as KeyValueStore); in practice, though, users usually do not need to customize such a state store from
scratch but can simply use the Stores factory to define a state store by specifying whether it should be persistent, log-backed, etc.
StateStoreSupplier countStore = Stores.create("Counts")
.withKeys(Serdes.String())
.withValues(Serdes.Long())
.persistent()
.build();
In the above example, a persistent key-value store named “Counts” with key type String and value type long is is created.
Connecting Processors and Stores¶
Now that we have defined the processor and the state stores, we can now construct the processor topology by
connecting these processors and state stores together by using the TopologyBuilder instance. In addition, users
can add source processors with the specified Kafka topics to generate input data streams into the topology, and sink processors
with the specified Kafka topics to generate output data streams out of the topology.
TopologyBuilder builder = new TopologyBuilder();
// add the source processor node that takes Kafka topic "source-topic" as input
builder.addSource("Source", "source-topic")
// add the WordCountProcessor node which takes the source processor as its upstream processor
.addProcessor("Process", () -> new WordCountProcessor(), "Source")
// create the countStore associated with the WordCountProcessor processor
.addStateStore(countStore, "Process")
// add the sink processor node that takes Kafka topic "sink-topic" as output
// and the WordCountProcessor node as its upstream processor
.addSink("Sink", "sink-topic", "Process");
There are several steps in the above implementation to build the topology, and here is a quick walk through:
- A source processor node named “Source” is added to the topology using the
addSourcemethod, with one Kafka topic “source-topic” fed to it. - A processor node named “Process” with the pre-defined
WordCountProcessorlogic is then added as the downstream processor of the “Source” node using theaddProcessormethod. - A predefined persistent key-value state store
countStoreis created and associated to the “Process” node. - A sink processor node is then added to complete the topology using the
addSinkmethod, taking the “Process” node as its upstream processor and writing to a separate “sink-topic” Kafka topic.
In this defined topology, the “Process” stream processor node is considered a downstream processor of the “Source” node, and an upstream processor of the “Sink” node.
As a result, whenever the “Source” node forward a newly fetched record from Kafka to its downstream “Process” node, WordCountProcessor#process() method is triggered
to process the record and update the associated state store; and whenever context#forward() is called in the WordCountProcessor#punctuate() method, the aggregate key-value
pair will be sent via the “Sink” processor node to the Kafka topic “sink-topic”. Note that in the WordCountProcessor implementation, users need to refer with the
same store name “Counts” when accessing the key-value store; otherwise an exception will be thrown at runtime indicating that the state store cannot be found;
also if the state store itself is not associated with the processor in the TopologyBuilder code, accessing it in the processor’s
init() method will also throw an exception at runtime indicating the state store is not accessible from this processor.
With the defined processor topology, users can now start running a Kafka Streams application instance. Please read how to run a Kafka Streams application for details.
Kafka Streams DSL¶
Note
See also the Kafka Streams Javadocs for a complete list of available API functionality.
Overview¶
As mentioned in the Concepts section, a stream is an unbounded, continuously updating data set. With the Kafka Streams DSL users can define the processor topology by concatenating multiple transformation operations where each operation transforming one stream into other stream(s); the resulted topology then takes the input streams from source Kafka topics and generates the final output streams throughout its concatenated transformations. However, different streams may have different semantics in their data records:
- In some streams, each record represents a new immutable datum in their unbounded data set; we call these record streams.
- In other streams, each record represents a revision (or update) of their unbounded data set in chronological order; we call these changelog streams.
Both of these two types of streams can be stored as Kafka topics. However, their computational semantics can be quite different. Take the example of an aggregation operation that counts the number of records for the given key. For record streams, each record is a keyed message from a Kafka topic (e.g., a page view stream keyed by user ids):
# Example: a record stream for page view events
# Notation is <record key> => <record value>
1 => {"time":1440557383335, "user_id":1, "url":"/home?user=1"}
5 => {"time":1440557383345, "user_id":5, "url":"/home?user=5"}
2 => {"time":1440557383456, "user_id":2, "url":"/profile?user=2"}
1 => {"time":1440557385365, "user_id":1, "url":"/profile?user=1"}
The counting operation for record streams is trivial to implement: you can maintain a local state store that tracks the latest count for each key, and, upon receiving a new record, update the corresponding key by incrementing its count by one.
For changelog streams, on the other hand, each record is an update of the unbounded data set (e.g., a changelog stream for a user profile table, where the user id serves as both the primary key for the table and as the record key for the stream; here, a new record represents a changed row of the table). In practice you would usually store such streams in Kafka topics where log compaction is enabled.
# Example: a changelog stream for a user profile table
1 => {"last_modified_time":1440557383335, "user_id":1, "email":"[email protected]"}
5 => {"last_modified_time":1440557383345, "user_id":5, "email":"[email protected]"}
2 => {"last_modified_time":1440557383456, "user_id":2, "email":"[email protected]"}
1 => {"last_modified_time":1440557385365, "user_id":1, "email":"[email protected]"}
2 => {"last_modified_time":1440557385395, "user_id":2, "email":null} <-- user has been deleted
As a result the counting operation for changelog streams is no longer monotonically incrementing: you need to also decrement the counts when a delete update record is received on some given key as well. In addition, even for counting aggregations on an record stream, the resulting aggregate is no longer an record stream but a relation / table, which can then be represented as a changelog stream of updates on the table.
Note
The counting operation of a user profile changelog stream is peculiar because it will generate, for a given key, a count
of either 0 (meaning the key does not exist or does not exist anymore) or 1 (the key exists) only.
Multiple records for the same key are considered duplicate, old information of the most recent record, and thus will not
contribute to the count.
For changelog streams developers usually prefer counting a non-primary-key field. We use the example above just for the sake of illustration.
One of the key design principles of the Kafka Streams DSL is to understand and distinguish between record streams and changelog streams and to provide operators with the correct semantics for these two different types of streams. More concretely, in the Kafka Streams DSL we use the KStream interface to represent record streams, and we use a separate KTable interface to represent changelog streams. The Kafka Streams DSL is therefore the recommended API to implement a Kafka Streams application. Compared to the lower-level Processor API, its benefits are:
- More concise and expressive code, particularly when using Java 8+ with lambda expressions.
- Easier to implement stateful transformations such as joins and aggregations.
- Understands the semantic differences of record streams and changelog streams, so that transformations such as aggregations work as expected depending on which type of stream they operate against.
In the subsequent sections we provide a step-by-step guide for writing a stream processing application using the Kafka Streams DSL.
Creating source streams from Kafka¶
Both KStream or KTable objects can be created as a source stream from one or more Kafka topics via KStreamBuilder,
an extended class of TopologyBuilder used in the lower-level Processor API (for KTable you can only create the source stream
from a single topic).
| Interface | How to instantiate |
|---|---|
KStream<K, V> |
KStreamBuilder#stream(...) |
KTable<K, V> |
KStreamBuilder#table(...) |
When creating an instance, you may override the default serdes for record keys (K) and record values (V) used
for reading the data from Kafka topics (see Data types and serdes for more
details); otherwise the default serdes specified through StreamsConfig will be used.
import org.apache.kafka.streams.kstream.KStreamBuilder;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KTable;
KStreamBuilder builder = new KStreamBuilder();
// In this example we assume that the default serdes for keys and values are
// the String serde and the generic Avro serde, respectively.
// Create a stream of page view events from the PageViews topic, where the key of
// a record is assumed to be the user id (String) and the value an Avro GenericRecord
// that represents the full details of the page view event.
KStream<String, GenericRecord> pageViews = builder.stream("PageViews");
// Create a changelog stream for user profiles from the UserProfiles topic,
// where the key of a record is assumed to be the user id (String) and its value
// an Avro GenericRecord.
KTable<String, GenericRecord> userProfiles = builder.table("UserProfiles");
Transform a stream¶
KStream and KTable support a variety of transformation operations.
Each of these operations can be translated into one or more connected processors into the underlying processor topology.
Since KStream and KTable are strongly typed, all these transformation operations are defined as
generics functions where users could specify the input and output data types.
Some KStream transformations may
generate one or more KStream objects (e.g., filter and map on KStream generate another KStream, while
branch on KStream can generate multiple KStream) while some others may generate a KTable object (e.g., aggregation)
interpreted as the changelog stream to the resulted relation. This allows Kafka Streams to continuously update the
computed value upon arrivals of late records after it has already been produced to the downstream transformation operators.
As for KTable, all its transformation operations can only generate another KTable (though the Kafka Streams DSL does provide a special function
to convert a KTable representation into a KStream, which we will describe later).
Nevertheless, all these transformation methods can be chained together to compose a complex processor topology.
We describe these transformation operations in the following subsections, categorizing them as two categories: stateless and stateful transformations.
Stateless transformations¶
Stateless transformations include filter, filterNot, foreach, map, mapValues, selectKey, flatMap, flatMapValues, branch. Most of them can be applied to both KStream and KTable, where users usually pass a customized function to these functions as a parameter; e.g. a Predicate for filter, a KeyValueMapper for map, and so on. Stateless transformations, by definition, do not depend on any state for processing, and hence implementation-wise they do not require a state store associated with the stream processor.
Example of mapValues in Java 8+, using lambda expressions.
KStream<Long, String> uppercased =
nicknameByUserId.mapValues(nickname -> nickname.toUpperCase());
Example of mapValues in Java 7:
KStream<Long, String> uppercased =
nicknameByUserId.mapValues(
new ValueMapper<String>() {
@Override
public String apply(String nickname) {
return nickname.toUpperCase();
}
}
);
The function is applied to each record, and its result will trigger the creation a new record.
Stateful transformations¶
Available stateful transformations include:
- joins (KStream/KTable):
join,leftJoin,outerJoin - aggregations (KStream):
countByKey,reduceByKey,aggregateByKey - aggregations (KTable):
groupBypluscount,reduce,aggregate(viaKGroupedTable) - general transformations (KStream):
process,transform,transformValues
Stateful transformations are transformations where the processing logic requires accessing an associated state for processing and producing outputs. For example, in join and aggregation operations, a windowing state is usually used to store all the records received so far within the defined window boundary. The operators can then access accumulated records in the store and compute based on them (see Windowing a Stream for details).
WordCount example in Java 8+, using lambda expressions (see WordCountLambdaIntegrationTest for the full code):
// We assume message values represent lines of text. For the sake of this example, we ignore
// whatever may be stored in the message keys.
KStream<String, String> textLines = ...;
KStream<String, Long> wordCounts = textLines
// Split each text line, by whitespace, into words. The text lines are the message
// values, i.e. we can ignore whatever data is in the message keys and thus invoke
// `flatMapValues` instead of the more generic `flatMap`.
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
// We will subsequently invoke `countByKey` to count the occurrences of words, so we use
// `map` to ensure the key of each record contains the respective word.
.map((key, word) -> new KeyValue<>(word, word))
// Count the occurrences of each word (record key).
//
// This will change the stream type from `KStream<String, String>` to
// `KTable<String, Long>` (word -> count). We must provide a name for
// the resulting KTable, which will be used to name e.g. its associated
// state store and changelog topic.
.countByKey("Counts")
// Convert the `KTable<String, Long>` into a `KStream<String, Long>`.
.toStream();
WordCount example in Java 7:
// Code below is equivalent to the previous Java 8+ example above.
KStream<String, String> textLines = ...;
KStream<String, Long> wordCounts = textLines
.flatMapValues(new ValueMapper<String, Iterable<String>>() {
@Override
public Iterable<String> apply(String value) {
return Arrays.asList(value.toLowerCase().split("\\W+"));
}
})
.map(new KeyValueMapper<String, String, KeyValue<String, String>>() {
@Override
public KeyValue<String, String> apply(String key, String word) {
return new KeyValue<String, String>(word, word);
}
})
.countByKey("Counts")
.toStream();
Tip
A KTable object can be converted back into a KStream via the KTable#toStream() function.
Windowing a Stream¶
Windowing is a common prerequisite for stateful transformations which group records in a stream, for example, by their timestamps.
A local state store is usually needed for a windowing operation to store recently received records based on the window interval,
while old records in the store are purged after the specified window retention period.
The retention time can be set via Windows#until().
Kafka Streams currently defines the following types of windows:
| Window name | Behavior | Short description |
|---|---|---|
| Tumbling time window | Time-based | Fixed-size, non-overlapping, gap-less windows |
| Hopping time window | Time-based | Fixed-size, overlapping windows |
| Sliding time window | Time-based | Fixed-size, overlapping windows that work on differences between record timestamps |
Tumbling time windows are a special case of hopping time windows and, like the latter, are windows based on time intervals. They model fixed-size, non-overlapping, gap-less windows. A tumbling window is defined by a single property: the window’s size. A tumbling window is a hopping window whose window size is equal to its advance interval. Since tumbling windows never overlap, a data record will belong to one and only one window.
// A tumbling time window with a size 60 seconds (and, by definition, an implicit
// advance interval of 60 seconds).
// The window's name -- the string parameter -- is used to e.g. name the backing state store.
long windowSizeMs = 60 * 1000L;
TimeWindows.of("tumbling-window-example", windowSizeMs);
// The above is equivalent to the following code:
TimeWindows.of("tumbling-window-example", windowSizeMs).advanceBy(windowSizeMs);
Hopping time windows are windows based on time intervals. They model fixed-sized, (possibly) overlapping windows. A hopping window is defined by two properties: the window’s size and its advance interval (aka “hop”). The advance interval specifies by how much a window moves forward relative to the previous one. For example, you can configure a hopping window with a size 5 minutes and an advance interval of 1 minute. Since hopping windows can overlap – and in general they do – a data record may belong to more than one such windows.
// A hopping time window with a size of 5 minutes and an advance interval of 1 minute.
// The window's name -- the string parameter -- is used to e.g. name the backing state store.
long windowSizeMs = 5 * 60 * 1000L;
long advanceMs = 1 * 60 * 1000L;
TimeWindows.of("hopping-window-example", windowSizeMs).advanceBy(advanceMs);
Note
Hopping windows vs. sliding windows: Hopping windows are sometimes called “sliding windows” in other stream processing tools. Kafka Streams follows the terminology in academic literature, where the semantics of sliding windows are different to those of hopping windows.
Pay attention, that tumbling and hopping time windows are aligned to the epoch and that the lower window time interval bound is inclusive, while the upper bound is exclusive.
Aligned to the epoch means, that the first window starts at timestamp zero.
For example, hopping windows with size of 5000ms and advance of 3000ms, have window boundaries [0;5000),[3000;8000),...—
and not [1000;6000),[4000;9000),... or even something “random” like [1452;6452),[4452;9452),...,
which might be the case if windows get initialized depending on system/application start-up time, introducing non-determinism.
Windowed counting example:
KStream<String, GenericRecord> viewsByUser = ...;
KTable<Windowed<String>, Long> userCounts =
// count users, using hopping windows of size 5 minutes that advance every 1 minute
viewsByUser.countByKey(TimeWindows.of("GeoPageViewsWindow", 5 * 60 * 1000L).advanceBy(60 * 1000L));
Unlike non-windowed aggregates that we have seen previously, windowed aggregates return a windowed KTable whose key type is Windowed<K>. This is to differentiate aggregate values with the same key from different windows. The corresponding window instance and the embedded key can be retrieved as Windowed#window() and Windowed#key(), respectively.
Sliding windows are actually quite different from hopping and tumbling windows.
A sliding window models a fixed-size window that slides continuously over the time axis; here, two data records are said to be included in the same window if the difference of their timestamps is within the window size.
Thus, sliding windows are not aligned to the epoch, but on the data record timestamps.
Pay attention, that in contrast to hopping and tumbling windows, lower and upper window time interval bounds are both inclusive.
In Kafka Streams, sliding windows are used only for join operations, and can be specified through the JoinWindows class.
Joining Streams¶
Many stream processing applications can be coded as stream join operations. For example, applications backing an online shop might need to access multiple, updating database tables (e.g. sales prices, inventory, customer information) when processing a new record. These applications can be implemented such that they work on the tables’ changelog streams directly, i.e. without requiring to make a database query over the network for each record. In this example, the KTable concept in Kafka Streams would enable you to track the latest state (think: snapshot) of each table in a local key-value store, thus greatly reducing the processing latency as well as reducing the load of the upstream databases.
In Kafka Streams, you may perform the following join operations:
- Join a
KStreamwith anotherKStreamorKTable. - Join a
KTablewith anotherKTableonly.
We explain each case in more detail below.
- KStream-to-KStream Joins
are always windowed joins, since otherwise the join result size might grow infinitely in size.
Here, a newly received record from one of the streams is joined
with the other stream’s records within the specified window interval to produce one result for each matching pair
based on user-provided
ValueJoiner. A newKStreaminstance representing the result stream of the join is returned from this operator. - KTable-to-KTable Joins
are join operations designed to be consistent with the ones in relational databases.
Here, both changelog streams are materialized into local state stores to represent the latest snapshot
of the their data table duals.
When a new record is received from one of the streams, it is joined with the other stream’s materialized state stores
to produce
one result for each matching pair based on user-provided
ValueJoiner. A newKTableinstance representing the result stream of the join, which is also a changelog stream of the represented table, is returned from this operator. - KStream-to-KTable Joins
allow you to perform table lookups against a changelog stream (KTable) upon receiving a new record
from another record stream (KStream). An example use case would be to enrich a stream of user activities (KStream)
with the latest user profile information (KTable).
Only records received from the record stream will trigger the join and
produce results via
ValueJoiner, not vice versa (i.e., records received from the changelog stream will be used only to update the materialized state store). A newKStreaminstance representing the result stream of the join is returned from this operator.
Depending on the operands the following join operations are supported:
| Join operands | (INNER) JOIN | OUTER JOIN | LEFT JOIN |
|---|---|---|---|
| KStream-to-KStream | Supported | Supported | Supported |
| KTable-to-KTable | Supported | Supported | Supported |
| KStream-to-KTable | N/A | N/A | Supported |
The join semantics are similar to the corresponding operators in relational databases:
- Inner join produces new joined records when the join operator finds some records with the same key in the other stream / materialized store.
- Outer join works like inner join if some records are found in the windowed stream / materialized store. The difference is that outer join still produces a record even when no records are found. It uses null as the value of missing record.
- Left join is like outer join except that for KStream-KStream join it is always driven by record arriving from the primary stream; while for KTable-KTable join it is driven by both streams to make the result consistent with the left join of databases while only permits missing records in the secondary stream. In a KStream-KTable left join, a KStream record will only join a KTable record if the KTable record arrived before the KStream record (and is in the KTable). Otherwise, the join result will be
null.
Note
Since stream joins are performed over the keys of records, it is required that joining streams are co-partitioned by key, i.e., their corresponding Kafka topics must have the same number of partitions and partitioned on the same key so that records with the same keys are delivered to the same processing thread. This is validated by Kafka Streams library at runtime (we talked about the threading model and data parallelism with more details in the Architecture section).
Join example in Java 8+, using lambda expressions.
// Key is user, value is number of clicks by that user
KStream<String, Long> userClicksStream = ...;
// Key is user, value is the geo-region of that user
KTable<String, String> userRegionsTable = ...;
// KStream-KTable join
KStream<String, RegionWithClicks> userClicksWithRegion = userClicksStream
// Null values possible: In general, null values are possible for region (i.e. the value of
// the KTable we are joining against) so we must guard against that (here: by setting the
// fallback region "UNKNOWN").
//
// Also, we need to return a tuple of (region, clicks) for each user. But because Java does
// not support tuples out-of-the-box, we must use a custom class `RegionWithClicks` to
// achieve the same effect. This class two fields -- the region (String) and the number of
// clicks (Long) for that region -- as well as a matching constructor, which we use here.
.leftJoin(userRegionsTable,
(clicks, region) -> new RegionWithClicks(region == null ? "UNKNOWN" : region, clicks));
Join example in Java 7+:
// Key is user, value is number of clicks by that user
KStream<String, Long> userClicksStream = ...;
// Key is user, value is the geo-region of that user
KTable<String, String> userRegionsTable = ...;
// KStream-KTable join
KStream<String, RegionWithClicks> userClicksWithRegion = userClicksStream
// Null values possible: In general, null values are possible for region (i.e. the value of
// the KTable we are joining against) so we must guard against that (here: by setting the
// fallback region "UNKNOWN").
//
// Also, we need to return a tuple of (region, clicks) for each user. But because Java does
// not support tuples out-of-the-box, we must use a custom class `RegionWithClicks` to
// achieve the same effect. This class two fields -- the region (String) and the number of
// clicks (Long) for that region -- as well as a matching constructor, which we use here.
.leftJoin(userRegionsTable, new ValueJoiner<Long, String, RegionWithClicks>() {
@Override
public RegionWithClicks apply(Long clicks, String region) {
return new RegionWithClicks(region == null ? "UNKNOWN" : region, clicks);
}
});
Applying a custom processor¶
Tip
See also the documentation of the low-level Processor API.
Beyond the provided transformation operators, users can also specify any customized processing logic on their stream data
via the KStream#process() method, which takes an implementation of the ProcessorSupplier interface
as its parameter. This is essentially equivalent to the addProcessor() method in the Processor API.
The following example shows how to leverage, via the process() method, a custom processor that sends an email notification whenever a page view count reaches a predefined threshold.
In Java 8+, using lambda expressions:
// Send an email notification when the view count of a page reaches one thousand.
pageViews.countByKey("PageViewCounts")
.filter((PageId pageId, Long viewCount) -> viewCount == 1000)
// PopularPageEmailAlert is your custom processor that implements the
// `Processor` interface, see further down below.
.process(() -> new PopularPageEmailAlert("[email protected]"));
In Java 7:
// Send an email notification when the view count of a page reaches one thousand.
pageViews.countByKey("PageViewCounts")
.filter(
new Predicate<PageId, Long>() {
public boolean test(PageId pageId, Long viewCount) {
return viewCount == 1000;
}
})
.process(
new ProcessorSupplier<PageId, Long>() {
public Processor<PageId, Long> get() {
// PopularPageEmailAlert is your custom processor that implements
// the `Processor` interface, see further down below.
return new PopularPageEmailAlert("[email protected]");
}
});
In the above examples, PopularPageEmailAlert is a custom stream processor that implements the Processor interface:
// A processor that sends an alert message about a popular page to a configurable email address
public class PopularPageEmailAlert implements Processor<PageId, Long> {
private final String emailAddress;
private ProcessorContext;
public PopularPageEmailAlert(String emailAddress) {
this.emailAddress = emailAddress;
}
@Override
public void init(ProcessorContext context) {
this.context = context;
// Here you would perform any additional initializations
// such as setting up an email client.
}
@Override
void process(PageId pageId, Long count) {
// Here would format and send the alert email.
//
// In this specific example, you would be able to include information
// about the page's ID and its view count (because the class implements
// `Processor<PageId, Long>`).
}
@Override
void punctuate(long timestamp) {
// Stays empty. In this use case there would be no need for a periodical
// action of this processor.
}
@Override
void close() {
// Any code for clean up would go here.
// This processor instance will not be used again after this call.
}
}
As mentioned before, a stream processor can access any available state stores by calling ProcessorContext#getStateStore().
Only such state stores are available that have been named in the corresponding KStream#process() method call (note that this is a different method than Processor#process()).
Writing streams back to Kafka¶
Any streams may be (continuously) written back to a Kafka topic via KStream#to() and KTable#to().
Note
Best practice:
It is strongly recommended to manually create output topics ahead of time rather than relying on auto-creation
of topics. First, auto-creation of topics may be disabled in your Kafka cluster. Second, auto-creation will always
apply the default topic settings such as the replicaton factor, and these default settings might not be what you want
for certain output topics (cf. auto.create.topics.enable=true in the
Kafka broker configuration).
// Write the stream userCountByRegion to the output topic 'RegionCountsTopic'
userCountByRegion.to("RegionCountsTopic");
If your application needs to continue reading and processing the records after they have been written
to a topic via to() above, one option is to construct a new stream that reads from the output topic:
// Write to a Kafka topic.
userCountByRegion.to("RegionCountsTopic");
// Read from the same Kafka topic by constructing a new stream from the
// topic RegionCountsTopic, and then begin processing it (here: via `map`)
builder.stream("RegionCountsTopic").map(...)...;
Kafka Streams provides a convenience method called through() that is equivalent to the code above:
// `through` combines write-to-Kafka-topic and read-from-same-Kafka-topic operations
userCountByRegion.through("RegionCountsTopic").map(...)...;
Whenever data is read from or written to a Kafka topic, Streams must know the serdes to be used for the respective data records. By default the to() and through() methods use the default serdes defined in the Streams configuration. You can override these default serdes by passing explicit serdes to the to() and through() methods.
Tip
Besides writing the data back to Kafka, users can also apply a custom processor as mentioned above to write to any other external stores, for example, to materialize a data store, as stream sinks at the end of the processing.
Running a Kafka Streams application¶
Starting a Kafka Streams application¶
A Java application that uses the Kafka Streams library can be run just like any other Java application – there is no special magic or requirement on the side of Kafka Streams.
For example, you can package your Java application as a fat jar file and then start the application via:
# Start the application in class `com.example.MyStreamsApp`
# from the fat jar named `path-to-app-fatjar.jar`.
$ java -cp path-to-app-fatjar.jar com.example.MyStreamsApp
The Kafka Streams examples under https://github.com/confluentinc/examples demonstrate how you can package and start your application in this way. See the README and pom.xml for details.
It is important to understand that, when starting your application as described above, you are actually launching what Kafka Streams considers to be one instance of your application. More than one instance of your application may be running at a time, and in fact the common scenario is that there are indeed multiple instances of your application running in parallel. See Parallelism Model for further information.
Elastic scaling of your application¶
Kafka Streams makes your stream processing applications elastic and scalable: you can add and remove processing capacity dynamically during the runtime of your application, and you can do so without any downtime or data loss. This means that, unlike other stream processing technologies, with Kafka Streams you do not have to completely stop your application, recompile/reconfigure, and then restart. This is great not just for intentionally adding or removing processing capacity, but also for being resilient in the face of failures (e.g. machine crashes, network outages) and for allowing maintenance work (e.g. rolling upgrades).
If you are wondering how this elasticity is actually achieved behind the scenes, you may want to read the Architecture chapter, notably the Parallelism Model section. In a nutshell, Kafka Streams leverages existing functionality in Kafka, notably its group management functionality. This group management, which is built right into the Kafka wire protocol, is the foundation that enables the elasticity of Kafka Streams applications: members of a group will coordinate and collaborate jointly on the consumption and processing of data in Kafka. On top of this foundation Kafka Streams provides some additional functionality, e.g. to enable stateful processing and to allow for fault-tolerante state in environment where application instances may come and go at any time.
Adding capacity to your application (“expand”)¶
If you need more processing capacity for your stream processing application, you can simply start another instance of your stream processing application, e.g. on another machine, in order to scale out. The instances of your application will become aware of each other and automatically begin to share the processing work. More specifically, what will be handed over from the existing instances to the new instances is (some of) the stream tasks that have been run by the existing instances. Moving stream tasks from one instance to another results in moving the processing work plus any internal state of these stream tasks (the state of a stream task will be re-created in the target instance by restoring the state from its corresponding changelog topic).
The various instances of your application each run in their own JVM process, which means that each instance can leverage all the processing capacity that is available to their respective JVM process (minus the capacity that any non-Kafka-Streams part of your application may be using). This explains why running additional instances will grant your application additional processing capacity. The exact capacity you will be adding by running a new instance depends of course on the environment in which the new instance runs: available CPU cores, available main memory and Java heap space, local storage, network bandwidth, and so on. Similarly, if you stop any of the running instances of your application, then you are removing and freeing up the respective processing capacity.
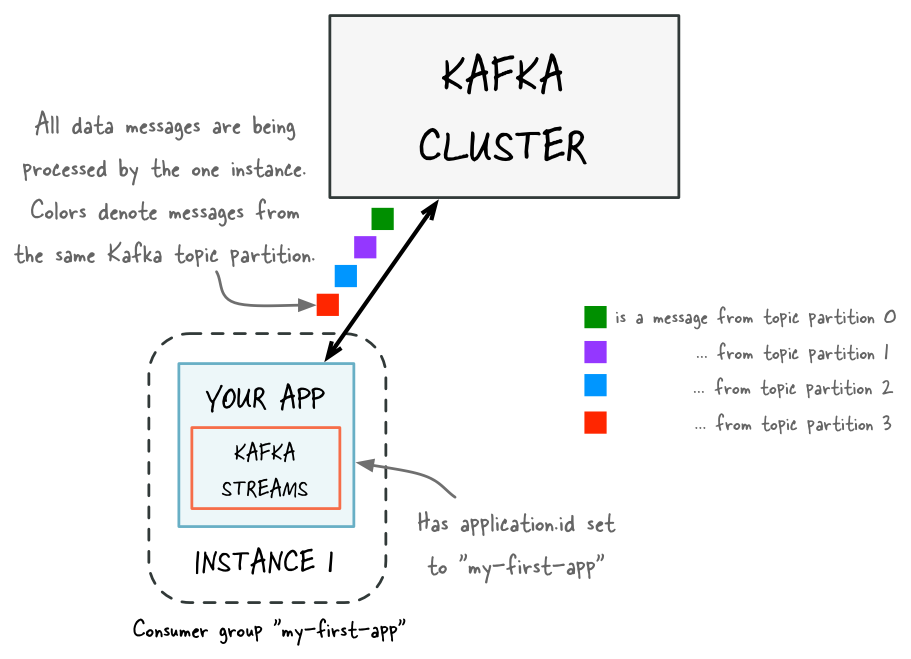
Before adding capacity: only a single instance of your Kafka Streams application is running. At this point the corresponding Kafka consumer group of your application contains only a single member (this instance). All data is being read and processed by this single instance.
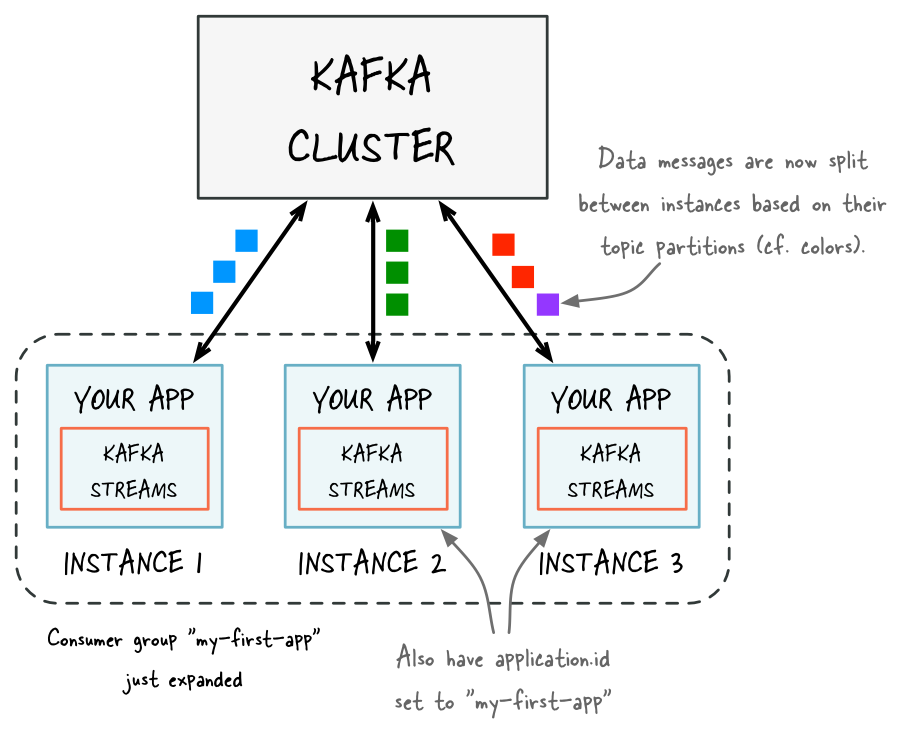
After adding capacity: now two additional instances of your Kafka Streams application are running, and they have automatically joined the application’s Kafka consumer group for a total of three current members. These three instances are automatically splitting the processing work between each other. The splitting is based on the Kafka topic partitions from which data is being read.
Removing capacity from your application (“shrink”)¶
If you need less processing capacity for your stream processing application, you can simply stop one or more running instances of your stream processing application, e.g. shut down 2 of 4 running instances. The remaining instances of your application will become aware that other instances were stopped and automatically take over the processing work of the stopped instances. More specifically, what will be handed over from the stopped instances to the remaining instances is the stream tasks that were run by the stopped instances. Moving stream tasks from one instance to another results in moving the processing work plus any internal state of these stream tasks (the state of a stream task will be re-created in the target instance by restoring the state from its corresponding changelog topic).
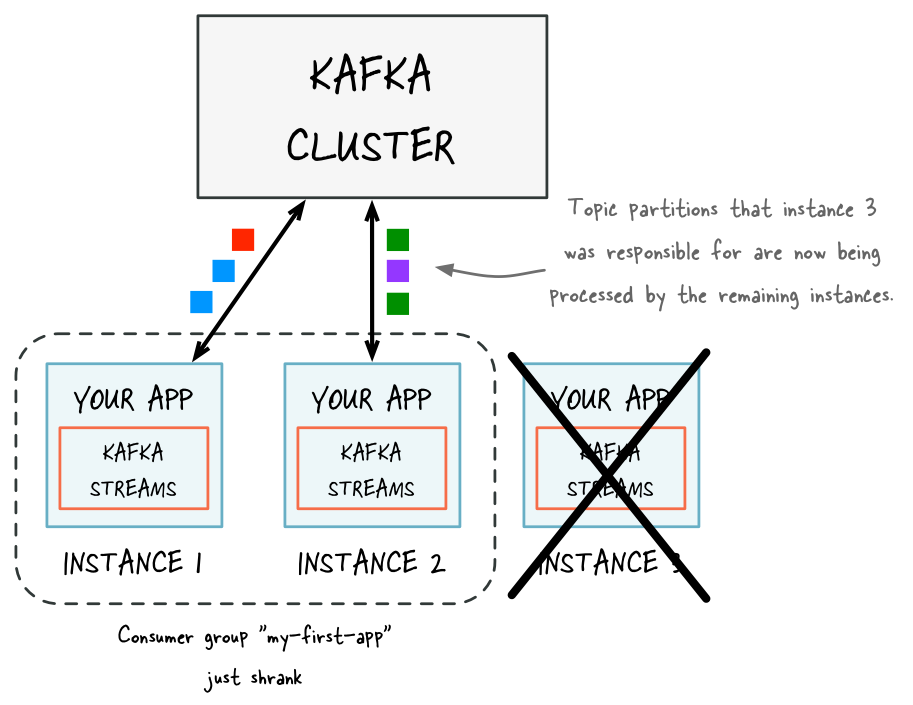
If one of the application instances is stopped (e.g. intentional reduction of capacity, maintenance, machine failure), it will automatically leave the application’s consumer group, which causes the remaining instances to automatically take over the stopped instance’s processing work.
How many application instances to run?¶
How many instances can or should you run for your application? Is there an upper limit for the number of instances and, similarly, for the parallelism of your application? In a nutshell, the parallelism of a Kafka Streams application – similar to the parallelism of Kafka – is primarily determined by the number of partitions of the input topic(s) from which your application is reading. For example, if your application reads from a single topic that has 10 partitions, then you can run up to 10 instances of your applications (note that you can run further instances but these will be idle).
The number of topic partitions is the upper limit for the parallelism of your Kafka Streams application and thus for the number of running instances of your application.
Tip
How to achieve a balanced processing workload across application instances to prevent processing hotpots: The balance of the processing work between application instances depends on factors such as how well data messages are balanced between partitions (think: if you have 2 topic partitions, having 1 million messages in each partition is better than having 2 million messages in the first partition and no messages in the second) and how much processing capacity is required to process the messages (think: if the time to process messages varies heavily, then it is better to spread the processing-intensive messages across partitions rather than storing these messages within the same partition).
If your data happens to be heavily skewed in the way described above, some application instances may become processing hotspots (say, when most messages would end up being stored in only 1 of 10 partitions, then the application instance that is processing this one partition would be performing most of the work while other instances might be idle). You can minimize the likelihood of such hotspots by ensuring better data balancing across partitions (i.e. minimizing data skew at the point in time when data is being written to the input topics in Kafka) and by over-partitioning the input topics (think: use 50 or 100 partitions instead of just 10), which lowers the probability that a small subset of partitions will end up storing most of the topic’s data.
Data types and serialization¶
Overview¶
Every Streams application must provide serializers and deserializers – abbreviated as serdes – for the data types of record keys and record values (e.g. java.lang.String or Avro objects) to materialize the data when necessary. Operations that require such serde information include: stream(), table(), to(), through(), countByKey().
There are two ways to provide these serdes:
- By setting default serdes via a
StreamsConfiginstance. - By specifying explicit serdes when calling the appropriate API methods, thus overriding the defaults.
Configuring default serializers/deserializers (serdes)¶
Serdes specified in the Streams configuration via StreamsConfig are used as the default in your Streams application.
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.StreamsConfig;
Properties settings = new Properties();
// Default serde for keys of data records (here: built-in serde for String type)
settings.put(StreamsConfig.KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
// Default serde for values of data records (here: built-in serde for Long type)
settings.put(StreamsConfig.VALUE_SERDE_CLASS_CONFIG, Serdes.Long().getClass().getName());
StreamsConfig config = new StreamsConfig(settings);
Overriding default serializers/deserializers (serdes)¶
You can also specify serdes explicitly by passing them to the appropriate API methods, which overrides the default serde settings:
import org.apache.kafka.common.serialization.Serde;
import org.apache.kafka.common.serialization.Serdes;
final Serde<String> stringSerde = Serdes.String();
final Serde<Long> longSerde = Serdes.Long();
// The stream userCountByRegion has type `String` for record keys (for region)
// and type `Long` for record values (for user counts).
KStream<String, Long> userCountByRegion = ...;
userCountByRegion.to(stringSerde, longSerde, "RegionCountsTopic");
If you want to override serdes selectively, i.e., keep the defaults for some fields, then pass null whenever you want to leverage the default serde settings:
import org.apache.kafka.common.serialization.Serde;
import org.apache.kafka.common.serialization.Serdes;
// Use the default serializer for record keys (here: region as String) by passing `null`,
// but override the default serializer for record values (here: userCount as Long).
final Serde<Long> longSerde = Serdes.Long();
KStream<String, Long> userCountByRegion = ...;
userCountByRegion.to(null, longSerde, "RegionCountsTopic");
Available serializers/deserializers (serdes)¶
Apache Kafka includes several built-in serde implementations in its kafka-clients maven artifact:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.10.0.1-cp1</version>
</dependency>
This artifact provides the following serde implementations under the package org.apache.kafka.common.serialization, which you can leverage when e.g., defining default serializers in your Streams configuration.
| Data type | Serde |
|---|---|
| byte[] | Serdes.ByteArray(), Serdes.Bytes() (see tip below) |
| ByteBuffer | Serdes.ByteBuffer() |
| Double | Serdes.Double() |
| Integer | Serdes.Integer() |
| Long | Serdes.Long() |
| String | Serdes.String() |
Tip
Bytes is a wrapper for Java’s byte[] (byte array) that supports proper equality and ordering semantics. You may want to consider using Bytes instead of byte[] in your applications.
You would use the built-in serdes as follows, using the example of the String serde:
// When configuring the default serdes of StreamConfig
Properties streamsConfiguration = new Properties();
streamsConfiguration.put(StreamsConfig.KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
streamsConfiguration.put(StreamsConfig.VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
// When you want to override serdes explicitly/selectively
final Serde<String> stringSerde = Serdes.String();
KStreamBuilder builder = new KStreamBuilder();
KStream<String, String> textLines = builder.stream(stringSerde, stringSerde, "TextLinesTopic");
The code examples of Kafka Streams also include a basic serde implementation for JSON:
- JSON example: JsonPOJOSerializer and JsonPOJODeserializer, which you can use to construct a unified JSON serde via
Serdes.serdeFrom(<serializer>, <deserializer>)(see PageViewTypedDemo for a demonstration)
Lastly, the Confluent examples repository includes basic serde implementations for Apache Avro:
- Generic Avro serde: GenericAvroSerde
- Specific Avro serde: SpecificAvroSerde
As well as templated serde implementations:
Windowed<T>serde: WindowedSerde- PriorityQueue serde (example): PriorityQueueSerde
Implementing custom serializers/deserializers (serdes)¶
If you need to implement custom serdes, your best starting point is to take a look at the source code references of existing serdes (see previous section). Typically, your workflow will be similar to:
- Write a serializer for your data type
Tby implementing org.apache.kafka.common.serialization.Serializer. - Write a deserializer for
Tby implementing org.apache.kafka.common.serialization.Deserializer. - Write a serde for
Tby implementing org.apache.kafka.common.serialization.Serde, which you either do manually (see existing serdes in the previous section) or by leveraging helper functions in Serdes such asSerdes.serdeFrom(Serializer<T>, Deserializer<T>).
Security¶
Overview¶
Kafka Streams can help you make your stream processing applications secure, and it achieves this through its native integration with Kafka’s security functionality. In general, Kafka Streams supports all the client-side security features in Kafka. The most important aspect to understand is that Kafka Streams leverages the standard Kafka producer and consumer clients behind the scenes. Hence what you need to do to secure your stream processing applications on the side of Kafka Streams is to configure the appropriate security settings of the corresponding Kafka producer/consumer clients. Once you know which client-side security features you want to use, you simply need to include the corresponding settings in the configuration of your Kafka Streams application.
In this section we will not cover these client-side security features in full detail, so we recommend reading the Kafka Security chapter (see also the Confluent blog post Apache Kafka Security 101) to familiarize yourself with the security features that are currently available in Apache Kafka. That said, let us highlight a couple of important client-side security features:
- Encrypting data-in-transit between Kafka brokers and Kafka clients: You can enable the encryption of the client-server communication between the Kafka brokers and Kafka clients. Kafka clients include stream processing applications built using the Kafka Streams library.
- Example: You can configure your Kafka Streams applications to always use encryption when reading data from Kafka and when writing data to Kafka; this is very important when reading/writing data across security domains (e.g. internal network vs. public Internet or partner network).
- Client authentication: You can enable client authentication for connections from Kafka clients (including Kafka Streams) to Kafka brokers.
- Example: You can define that only some specific Kafka Streams applications are allowed to connect to your production Kafka cluster.
- Client authorization: You can enable client authorization of read/write operations by Kafka clients.
- Example: You can define that only some specific Kafka Streams applications are allowed to read from a Kafka topic that stores sensitive data. Similarly, you can restrict write access to certain Kafka topics to only a few stream processing applications to prevent e.g. data pollution or fraudulent activities.
Note
The aforementioned security features in Apache Kafka are optional, and it is up to you to decide whether to enable or disable any of them. And you can mix and match these security features as needed: both secured and non-secured Kafka clusters are supported, as well as a mix of authenticated, unauthenticated, encrypted and non-encrypted clients. This flexibility allows you to model the security functionality in Kafka to match your specific needs, and to make effective cost vs. benefit (read: security vs. convenience/agility) tradeoffs: tighter security requirements in places where security matters (e.g. production), and relaxed requirements in other situations (e.g. development, testing).
Security example¶
The following example is based on the Confluent blog post Apache Kafka Security 101. What we want to do is to configure a Kafka Streams application to A. enable client authentication and B. encrypt data-in-transit when communicating with its Kafka cluster.
Tip
A complete demo application including step-by-step instructions is available at SecureKafkaStreamsExample.java under https://github.com/confluentinc/examples.
Because we want to focus this example on the side of Kafka Streams, we assume that 1. the security setup of the Kafka brokers in the cluster is already completed, and 2. the necessary SSL certificates are available to the Kafka Streams application in the local filesystem locations specified below (the aforementioned blog post walks you through the steps to generate them); for example, if you are using Docker to containerize your Kafka Streams applications, then you must also include these SSL certificates in the right locations within the Docker image.
Once these two assumptions are met, you must only configure the corresponding settings for the Kafka clients in your Kafka Streams application. The configuration snippet below shows the settings to A. enable client authentication and B. enable SSL encryption for data-in-transit between your Kafka Streams application and the Kafka cluster it is reading from and writing to:
# Essential security settings to enable client authentication and SSL encryption
bootstrap.servers=kafka.example.com:9093
security.protocol=SSL
ssl.truststore.location=/etc/security/tls/kafka.client.truststore.jks
ssl.truststore.password=test1234
ssl.keystore.location=/etc/security/tls/kafka.client.keystore.jks
ssl.keystore.password=test1234
ssl.key.password=test1234
Within a Kafka Streams application, you’d use code such as the following to configure these settings in your StreamsConfig instance (see section Configuring a Kafka Streams application):
// Code of your Java application that uses the Kafka Streams library
Properties settings = new Properties();
settings.put(StreamsConfig.APPLICATION_ID_CONFIG, "secure-kafka-streams-app");
// Where to find secure Kafka brokers. Here, it's on port 9093.
settings.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka.example.com:9093");
//
// ...further non-security related settings may follow here...
//
// Security settings.
// 1. These settings must match the security settings of the secure Kafka cluster.
// 2. The SSL trust store and key store files must be locally accessible to the application.
settings.put(CommonClientConfigs.SECURITY_PROTOCOL_CONFIG, "SSL");
settings.put(SslConfigs.SSL_TRUSTSTORE_LOCATION_CONFIG, "/etc/security/tls/kafka.client.truststore.jks");
settings.put(SslConfigs.SSL_TRUSTSTORE_PASSWORD_CONFIG, "test1234");
settings.put(SslConfigs.SSL_KEYSTORE_LOCATION_CONFIG, "/etc/security/tls/kafka.client.keystore.jks");
settings.put(SslConfigs.SSL_KEYSTORE_PASSWORD_CONFIG, "test1234");
settings.put(SslConfigs.SSL_KEY_PASSWORD_CONFIG, "test1234");
StreamsConfig streamsConfiguration = new StreamsConfig(settings);
With these settings in place your Kafka Streams application will encrypt any data-in-transit that is being read from or written to Kafka, and it will also authenticate itself against the Kafka brokers that it is talking to. (Note that this simple example does not cover client authorization.)
When things go wrong (e.g. wrong password): What would happen if you misconfigured the security settings in your Kafka Streams application? In this case, the application would fail at runtime, typically right after you started it. For example, if you entered an incorrect password for the ssl.keystore.password setting, then error messages similar to the following would be logged, and after that the application would terminate:
# Misconfigured ssl.keystore.password
Exception in thread "main" org.apache.kafka.common.KafkaException: Failed to construct kafka producer
[...snip...]
Caused by: org.apache.kafka.common.KafkaException: org.apache.kafka.common.KafkaException: java.io.IOException: Keystore was tampered with, or password was incorrect
[...snip...]
Caused by: java.security.UnrecoverableKeyException: Password verification failed
Tip
You can monitor the application log files of your Kafka Streams applications for such error messages to spot any misconfigured applications quickly.
Application Reset Tool¶
Overview¶
The Application Reset Tool allows you to quickly reset an application in order to reprocess its data from scratch – think: an application “reset” button.
Scenarios when would you like to reset an application include:
- Development and testing
- Addressing bugs in production
- Demos
However, resetting an application manually is a bit involved. Kafka Streams is designed to hide many details about operator state, fault-tolerance, and internal topic management from the user (especially when using Kafka Streams DSL). In general this hiding of details is very desirable but it also makes manually resetting an application more difficult. The Application Reset Tool fills this gap and allows you to quickly reset an application.
User topics vs. internal topics¶
In Kafka Streams, we distinguish between user topics and internal topics. Both kinds are normal Kafka topics but they are used differently and, in the case of internal topics, follow a specific naming convention.
- User topics (input, output, and intermediate topics)
- Topics that are created and managed manually by the user. These include an application’s input and output topics
as well as any intermediate topics specified via
through(), because such topics are both output and input topics at the same time. - Internal topics
- Topics that are created by Kafka Streams under the hood. For example, the changelog topics for state stores
are considered internal topics. Internal topics currently follow the naming convention
<application.id>-<operatorName>-<suffix>, but this convention is not guaranteed for future releases.
Scope¶
What the application reset tool does:
- For any specified input topics:
- Reset the application’s committed consumer offsets to zero for all partitions (for consumer group
application.id).
- Reset the application’s committed consumer offsets to zero for all partitions (for consumer group
- For any specified intermediate topics:
- Skip to the end of the topic, i.e. set the application’s committed consumer offsets for all partitions to each
partition’s
logSize(for consumer groupapplication.id).
- Skip to the end of the topic, i.e. set the application’s committed consumer offsets for all partitions to each
partition’s
- For any internal topics:
- Reset the application’s committed consumer offsets to zero for all partitions (for consumer group
application.id). - Delete the internal topic.
- Reset the application’s committed consumer offsets to zero for all partitions (for consumer group
What the application reset tool does not:
- Does not reset output topics of an application. If any output (or intermediate) topics are consumed by downstream applications, it is your responsibility to adjust those downstream applications as appropriate when you reset the upstream application.
- Does not reset the local environment of your application instances. It is your responsibility to delete the local state on any machine on which an application instance was run. See the instructions in section Step 2: Reset the local environments of your application instances on how to do this.
Usage¶
Step 1: Run the application reset tool¶
Attention
Use this tool only if the application is fully stopped:
You must use this script only if no instances of your application are running.
Otherwise the application may enter an invalid state, crash, or produce incorrect results.
You can check if the consumer group with ID application.id is still active using bin/kafka-consumer-groups.
Use this tool with care and double-check its parameters:
If you provide wrong parameter values (e.g. typos in application.id) or specify
parameters inconsistently (e.g. specifying the wrong input topics for the application),
this tool might invalidate the application’s state or even impact other applications,
consumer groups, or Kafka topics of your Kafka cluster.
You can call the application reset tool on the command line via bin/kafka-streams-application-reset.
The tool accepts the following parameters:
Option (* = required) Description
--------------------- -----------
* --application-id <id> The Kafka Streams application ID (application.id)
--bootstrap-servers <urls> Comma-separated list of broker urls with format: HOST1:PORT1,HOST2:PORT2
(default: localhost:9092)
--intermediate-topics <list> Comma-separated list of intermediate user topics
--input-topics <list> Comma-separated list of user input topics
--zookeeper <url> Format: HOST:POST
(default: localhost:2181)
You can combine the parameters of the script as needed. For example, if an application should only restart from an
empty internal state but not reprocess previous data, simply omit the parameters --input-topics and
--intermediate-topics.
Tip
On intermediate topics: In general, we recommend to manually delete and re-create any intermediate topics before running the application reset tool. This allows to free disk space in Kafka brokers early on. It is important to first delete and re-create intermediate topics before running the application reset tool.
Not deleting intermediate topics and only using the application reset tool is preferable:
- when there are external downstream consumers for the application’s intermediate topics
- during development, where manually deleting and re-creating intermediate topics might be cumbersome and often unnecessary
Step 2: Reset the local environments of your application instances¶
Running the application reset tool (step 1) ensures that your application’s state – as tracked globally in the application’s configured Kafka cluster – is reset. However, by design the reset tool does not modify or reset the local environment of your application instances, which includes the application’s local state directory.
For a complete application reset you must also delete the application’s local state directory on
any machines on which an application instance was run prior to restarting an application instance on the same
machines. You can either use the API method KafkaStreams#cleanUp() in your application code or manually delete the
corresponding local state directory (default location: /var/lib/kafka-streams/<application.id>, cf.
state.dir configuration parameter).
Example¶
Let’s imagine you are developing and testing an application locally and want to iteratively improve your application via run-reset-modify cycles. You might have code such as the following:
package io.confluent.examples.streams;
import ...;
public class ResetDemo {
public static void main(String[] args) throws Exception {
// Kafka Streams configuration
Properties streamsConfiguration = new Properties();
streamsConfiguration.put(StreamsConfig.APPLICATION_ID_CONFIG, "my-streams-app");
// ...and so on...
// Define the processing topology
KStreamBuilder builder = new KStreamBuilder();
builder.stream("my-input-topic")
.selectKey(...)
.through("rekeyed-topic")
.countByKey("global-count")
.to("my-output-topic");
KafkaStreams app = new KafkaStreams(builder, streamsConfiguration);
// Delete the application's local state.
// Note: In real application you'd call `cleanUp()` only under
// certain conditions. See tip on `cleanUp()` below.
app.cleanUp();
app.start();
// Note: In real applications you would register a shutdown hook
// that would trigger the call to `app.close()` rather than
// using the sleep-then-close example we show here.
Thread.sleep(30 * 1000L);
app.close();
}
}
Tip
Calling cleanUp() is safe but do so judiciously:
It is always safe to call KafkaStreams#cleanUp() because the local state of an application instance can be
recovered from the underlying internal changelog topic(s).
However, to avoid the corresponding recovery overhead it is recommended to not call cleanUp() unconditionally
and every time an application instance is restarted/resumed. A production application would therefore use e.g.
command line arguments to enable/disable the cleanUp() call as needed.
You can then perform run-reset-modify cycles as follows:
# Run your application
$ bin/kafka-run-class io.confluent.examples.streams.ResetDemo
# After stopping all application instances, reset the application
$ bin/kafka-streams-application-reset --application-id my-streams-app \
--input-topics my-input-topic \
--intermediate-topics rekeyed-topic
# Now you can modify/recompile as needed and then re-run the application again.
# You can also experiment, for example, with different input data without
# modifying the application.