Placement Groups¶
A Placement Group (PG) aggregates a series of objects into a group, and maps the group to a series of OSDs. Tracking object placement and object metadata on a per-object basis is computationally expensive–i.e., a system with millions of objects cannot realistically track placement on a per-object basis. Placement groups address this barrier to performance and scalability. Additionally, placement groups reduce the number of processes and the amount of per-object metadata Ceph must track when storing and retrieving data.
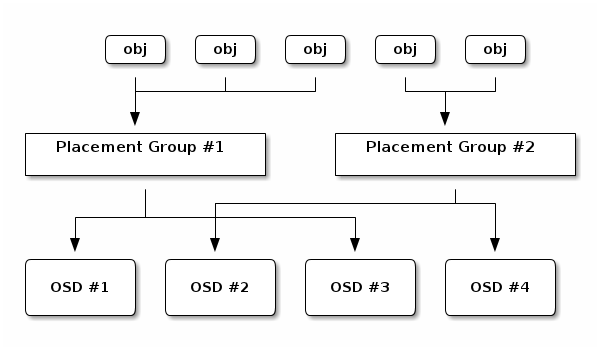
Each placement group requires some amount of system resources:
- Directly: Each PG requires some amount of memory and CPU.
- Indirectly: The total number of PGs increases the peering count.
Increasing the number of placement groups reduces the variance in per-OSD load across your cluster. We recommend approximately 50-100 placement groups per OSD to balance out memory and CPU requirements and per-OSD load. For a single pool of objects, you can use the following formula:
(OSDs * 100)
Total PGs = ------------
Replicas
The result should be rounded up to the nearest power of two. Rounding up is optional, but recommended if you want to ensure that all placement groups are roughly the same size.
As an example, for a cluster with 200 OSDs and a pool size of 3 replicas, you would estimate your number of PGs as follows:
(200 * 100)
----------- = 6667. Nearest power of 2: 8192
3
When using multiple data pools for storing objects, you need to ensure that you balance the number of placement groups per pool with the number of placement groups per OSD so that you arrive at a reasonable total number of placement groups that provides reasonably low variance per OSD without taxing system resources or making the peering process too slow.
Set the Number of Placement Groups¶
To set the number of placement groups in a pool, you must specify the number of placement groups at the time you create the pool. See Create a Pool for details. Once you’ve set placement groups for a pool, you may increase the number of placement groups (but you cannot decrease the number of placement groups). To increase the number of placement groups, execute the following:
ceph osd pool set {pool-name} pg_num {pg_num}
Once you increase the number of placement groups, you must also increase the number of placement groups for placement (pgp_num) before your cluster will rebalance. The pgp_num should be equal to the pg_num. To increase the number of placement groups for placement, execute the following:
ceph osd pool set {pool-name} pgp_num {pgp_num}
Get the Number of Placement Groups¶
To get the number of placement groups in a pool, execute the following:
ceph osd pool get {pool-name} pg_num
Get a Cluster’s PG Statistics¶
To get the statistics for the placement groups in your cluster, execute the following:
ceph pg dump [--format {format}]
Valid formats are plain (default) and json.
Get Statistics for Stuck PGs¶
To get the statistics for all placement groups stuck in a specified state, execute the following:
ceph pg dump_stuck inactive|unclean|stale [--format <format>] [-t|--threshold <seconds>]
Inactive Placement groups cannot process reads or writes because they are waiting for an OSD with the most up-to-date data to come up and in.
Unclean Placement groups contain objects that are not replicated the desired number of times. They should be recovering.
Stale Placement groups are in an unknown state - the OSDs that host them have not reported to the monitor cluster in a while (configured by mon_osd_report_timeout).
Valid formats are plain (default) and json. The threshold defines the minimum number of seconds the placement group is stuck before including it in the returned statistics (default 300 seconds).
Get a PG Map¶
To get the placement group map for a particular placement group, execute the following:
ceph pg map {pg-id}
For example:
ceph pg map 1.6c
Ceph will return the placement group map, the placement group, and the OSD status:
osdmap e13 pg 1.6c (1.6c) -> up [1,0] acting [1,0]
Get a PGs Statistics¶
To retrieve statistics for a particular placement group, execute the following:
ceph pg {pg-id} query
Scrub a Placement Group¶
To scrub a placement group, execute the following:
ceph pg scrub {pg-id}
Ceph checks the primary and any replica nodes, generates a catalog of all objects in the placement group and compares them to ensure that no objects are missing or mismatched, and their contents are consistent. Assuming the replicas all match, a final semantic sweep ensures that all of the snapshot-related object metadata is consistent. Errors are reported via logs.
Revert Lost¶
If the cluster has lost one or more objects, and you have decided to abandon the search for the lost data, you must mark the unfound objects as lost.
If all possible locations have been queried and objects are still lost, you may have to give up on the lost objects. This is possible given unusual combinations of failures that allow the cluster to learn about writes that were performed before the writes themselves are recovered.
Currently the only supported option is “revert”, which will either roll back to a previous version of the object or (if it was a new object) forget about it entirely. To mark the “unfound” objects as “lost”, execute the following:
ceph pg {pg-id} mark_unfound_lost revert
Important
Use this feature with caution, because it may confuse applications that expect the object(s) to exist.
![]()
Table Of Contents
- Intro to Ceph
- Installation (Quick)
- Installation (Manual)
- Ceph Storage Cluster
- Configuration
- Deployment
- Operations
- Operating a Cluster
- Monitoring a Cluster
- Monitoring OSDs and PGs
- Authentication Overview
- Cephx Authentication
- Data Placement Overview
- Pools
- Placement Groups
- CRUSH Maps
- Adding/Removing OSDs
- Adding/Removing Monitors
- Command Reference
- The Ceph Community
- Troubleshooting Monitors
- Troubleshooting OSDs
- Troubleshooting PGs
- Logging and Debugging
- CPU Profiling
- Memory Profiling
- Man Pages
- Troubleshooting
- APIs
- Ceph Filesystem
- Ceph Block Device
- Ceph Object Gateway
- API Documentation
- Architecture
- Development
- Release Notes
- Glossary