
Table of Contents
- 1. Introduction
- 2. Component architecture approach
- 2.1. WS GRAM
- 2.2. Major Protocol Steps
- 2.3. Creation of Job
- 2.4. Optional Staging Credentials
- 2.5. Optional Job Credential
- 2.6. Optional Credential Refresh
- 2.7. Optional Hold of Cleanup for Streaming Output
- 2.8. ManagedJob Destruction
- 2.9. Globus Toolkit Components used by WS GRAM
- 2.10. External Components used by WS GRAM
- 2.11. Internal Components used by WS GRAM
- 3. Security model
- 4. WS GRAM software architecture
- 5. Protocol Variations
- 6. Performance and scalability
The WS GRAM software implements a solution to the job-management problem described in the GT 4.0 WS GRAM Key Concepts document, providing Web services interfaces consistent with the WSRF model. This solution is specific to operating systems following the Unix programming and security model.
WS GRAM combines job-management services and local system adapters with other service components of GT 4.0 in order to support job execution with coordinated file staging.
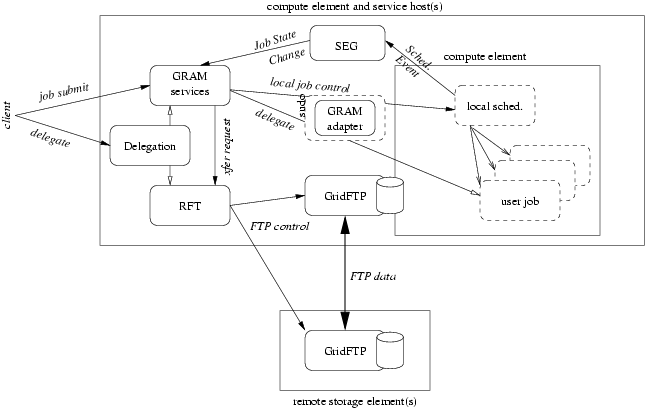
The heart of the WS GRAM service architecture is a set of Web services designed to be hosted in the Globus Toolkit's WSRF core hosting environment. Note, these services, described below, make use of platform-specific callouts to other software components described in the next section.
Table 1. WS GRAM Webservices
| ManagedJob | Each submitted job is exposed as a distinct resource qualifying the generic ManagedJob service. The service provides an interface to monitor the status of the job or to terminate the job (by terminating the ManagedJob resource). The behavior of the service, i.e. the local scheduler adapter implementation, is selected by the specialized type of the resource. |
| ManagedJobFactory | Each compute element, as accessed through a local scheduler, is exposed as a distinct resource qualifying the generic ManagedJobFactory service. The service provides an interface to create ManagedJob resources of the appropriate type in order to perform a job in that local scheduler. |
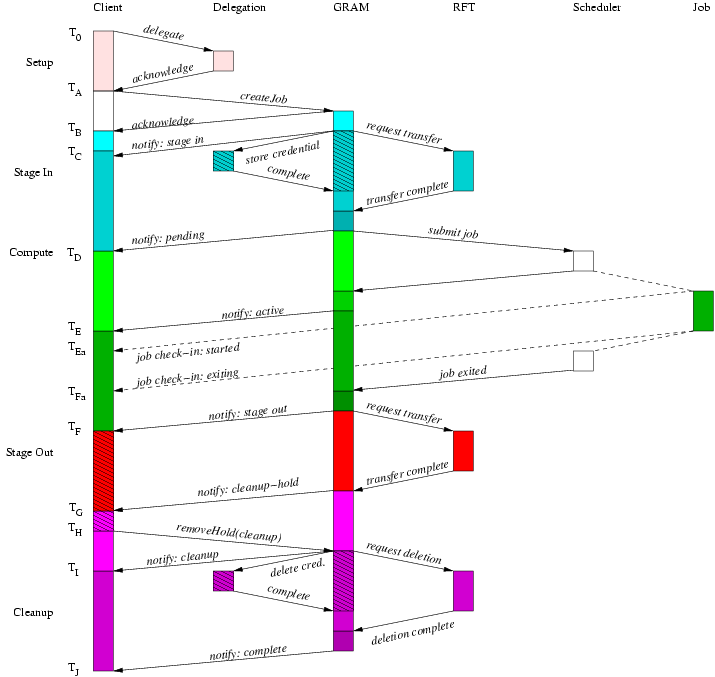
The components in the WS GRAM solution are organized to support a range of optional features that together address different usage scenarios. These scenarios are explored in depth in terms of protocol exchanges in the Protocol Variations section. However, at a high level we can consider the main client activities around a WS GRAM job to be a partially ordered sequence.
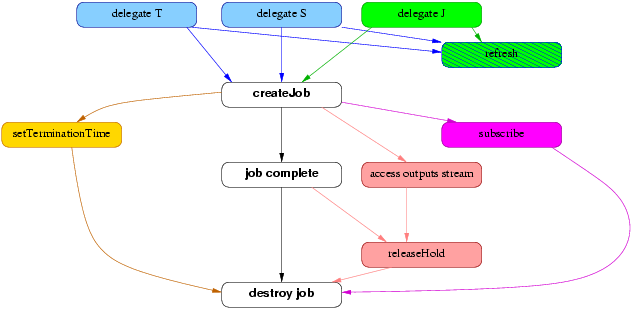
The main component of the WS GRAM service model is the ManagedJob resource created by a ManagedJobFactory::createManagedJob invocation. A meaningful WS GRAM client MUST create a job that will then go through a life cycle where it eventually completes execution and the resource is eventually destroyed (the core black-and-white nodes in the high-level picture).
Optionally, the client MAY request staging activities to occur before or after the job. If these are requested in the create call, suitable delegated credential EPRs MUST be passed in as part of the creation input, meaning that delegation operations MUST be performed sometime before createManagedJob when staging is enabled (the light-blue delegation nodes in the high-level picture). Two credential fields must be initialized: the staging and transfer credentials, which may refer to distinct credentials or may both refer to the same credential. The staging credential gives WS GRAM the right to interact with the RFT service, while the transfer credential gives RFT the right to interact with GridFTP servers.
Optionally, the client MAY request that a credential be stored into the user account for use by the job process. When this is requested in the create call, a suitable delegated credential EPR is passed as part of the creation input. As for staging, the credential MUST have been delegated before the job is created (the green nodes in the picture).
Optionally, credentials delegated for use with staging, transfer, or job processes may be refreshed using the Delegation service interface. This operation may be performed on any valid Delegation EPR (the blue/green striped node in the picture).
If the client wishes to directly access output files written by the job (as opposed to waiting for the stage-out step to transfer files from the job host), the client should request that the file cleanup process be held until released. This gives the client an opportunity to fetch all remaining/buffered data after the job completes but before the output files are deleted. (See the pink nodes in the high-level picture).
The cleanup hold and release are not necessary if the client will not be accessing files that are scheduled for cleanup in the job request, either because the client is not accessing any files or because the files it is accessing will remain on the job host after ManagedJob termination.
Under nearly all circumstances, ManagedJob resources will be eventually destroyed after job cleanup has completed. Clients may hasten this step via an explicit destroy request or by manipulation of the scheduled termination time. Most system administrators will set a default and maximum ManagedJob linger time after which automatic purging of completed ManagedJob resources will occur.
Table 2. Globus Toolkit Components used by WS GRAM
| ReliableFileTransfer |
The ReliableFileTransfer (RFT) service of GT 4.0 is invoked by the WS GRAM services to effect file staging before and after job computations. The integration with RFT provides a much more robust file staging manager than the ad-hoc solution present in previous versions of the GRAM job manager logic. RFT has better support for retry, restart, and fine-grained control of these capabilities. WS GRAM exposes the full flexibility of the RFT request language in the job staging clauses of the job submission language. |
| GridFTP | GridFTP servers are required to access remote storage elements as well as file systems accessible to the local compute elements that may host the job. The ReliableFileTransfer Web service acts as a so-called third-party client to the GridFTP servers in order to manage transfers of data between remote storage elements and the compute element file systems. It is not necessary that GridFTP be deployed on the same host/node as the WS GRAM services, but staging will only be possible to the subset of file systems that are shared by the GridFTP server that is registered with the WS GRAM service. (REF TO DEPLOY/CONFIG HERE) If no such server or shared file systems are registered, staging is disallowed to that WS GRAM compute element. GridFTP is also used to monitor the contents of files written by the job during job execution. The standard GridFTP protocol is used by a slightly unusual client to efficiently and reliably check the status of files and incrementally fetch new content as the file grows. This method supports "streaming" of file content from any file accessible by GridFTP, rather than only the standard output and error files named in the job request--the limitation of previous GRAM solutions. This approach also simplifies failover and restart of streaming to multiple clients. The integration with GridFTP replaces the legacy GASS (Globus Access to Secondary Storage) data transfer protocol. This changeover is advantageous both for greater performance and reliability of data staging as well as to remove redundant software from the GRAM codebase. |
| Delegation |
The Delegation service of GT 4.0 is used by clients to delegate credentials into the correct hosting environment for use by WS GRAM or RFT services. The integration of the Delegation service replaces the implicit, binding-level delegation of previous GRAM solutions with explicit service operations. This change not only reduces the requirements on client tooling for interoperability purposes, but also allows a new separation of the life cycle of jobs and delegated credentials. Credentials can now be shared between multiple short-lived jobs or eliminated entirely on an application-by-application basis to make desired performance and security tradeoffs. Meanwhile, for unique situations WS GRAM retains the ability to refresh credentials for long-lived jobs and gains an ability to designate different delegated credentials for different parts of the job's life cycle. |
Table 3. External Components used by WS GRAM
| Local job scheduler | An optional local job scheduler is required in order to manage the
resources of the compute element. WS GRAM has the ability to spawn
simple time-sharing jobs using standard Unix |
| sudo | The de facto standard Unix The |
Table 4. Internal Components used by WS GRAM
| Scheduler Event Generator | The Scheduler Event Generator component program provides the job monitoring capability for the WS-GRAM service. Plugin modules provide an interface between the Scheduler Event Generator and local schedulers. |
| Fork Starter | The Fork Starter program starts and monitors job processes for WS-GRAM services which do not a local scheduler. The starter executes the user application and then waits for it to terminate. It records the start time, termination time, and exit status of each process it starts. This information is used by a Scheduler Event Generator plugin for triggering job state changes. |
WS GRAM utilizes secure Web service invocation, as provided by the WSRF core of the Globus Toolkit, for all job-management and file-management messages. This security provides for authentication of clients, tamper-resistant messaging, and optional privacy of message content.
User jobs are executed within Unix user accounts. WS GRAM
authentication mechanisms allow the administrator to control to which
local accounts a Grid-based client may submit jobs. WS GRAM uses the
Unix sudo command to access user accounts after determining
that the client has the right to access the account. Additionally, the
administrator may use access and allocation policy controls in the
local scheduler to further restrict the access of specific clients and
Unix users to local computing resources.
A client may optionally delegate some of its rights to WS GRAM and related services in order to facilitate file staging. Additionally, the client may delegate rights for use by the job process itself. If no delegation is performed, staging is disallowed and the job will have no ability to request privileged Grid operations.
WS GRAM provides three types of logging or auditing support:
Table 5. Audit Logging Support
| WSRF core message logging | Detailed logging of the underlying client messages may be logged if such logging is enabled in the container configuration. See WS Core debugging doc |
| WS GRAM custom logging | WS GRAM generates domain-specific logging information about job requests and exceptional conditions. See WS GRAM debugging doc |
| WS GRAM job auditing direct to DB | WS GRAM can be configured to write a job audit record directly to a Database. This can be useful for exposing and integrating GRAM job information with a Grid's existing accounting infrastructure. A case study for TeraGrid can be read here |
| Local scheduler logging | For systems using a local batch scheduler, all of the accounting and logging facilities of that scheduler remain available for the administrator to track jobs whether submitted through WS GRAM or directly to the scheduler by local users. |
| Local system logging | The use of |
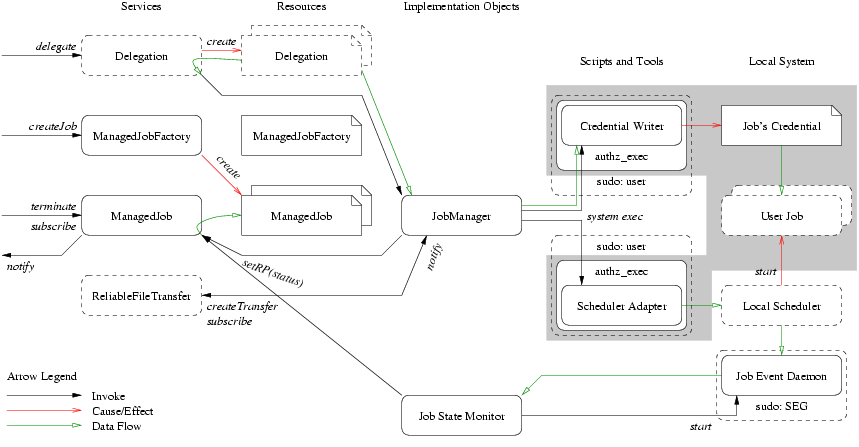
As depicted above, the WS GRAM protocol is centered around the creation of a stateful ManagedJob resource using the ManagedJobFactory createManagedJob() operation. A simple batch job may involve nothing more than this initial client creation step, with all other job life cycle steps occurring automatically in the server. A number of optional protocol elements are available for more complex scenarios.
Table 6. Protocol Overview
| DelegationFactory::requestSecurityToken | This (optional) step allows a client to delegate credentials that will be required for correct operation of WS GRAM, RFT, or the user's job process. Such credentials are only used when referenced in the subsequent job request and under the condition that WS GRAM or RFT is configured to make use of the DelegationFactory, respectively. |
| Delegation::refresh | This (optional) step allows a client to update the credentials already established for use with the previous requestSecurityToken step. |
| ManagedJobFactory::getResourceProperty and getMultipleResourceProperties | These (optional) steps allow a client to retrieve information about the scheduler and the jobs associated with a particular factory resource before or after job creation. The delegationFactoryEndpoint and stagingDelegationFactoryEndpoint resource properties are two examples of information that may need to be obtained before job creation. |
| ManagedJobFactory::createManagedJob | This required step establishes the stateful ManagedJob resource which implements the job processing described in the input request. |
| ManagedJob::release | This (optional) step allows the ManagedJob to continue through a state in its life cycle where it was previously held or scheduled to be held according to details of the original job request. |
| ManagedJob::setTerminationTime | This (optional) step allows the client to reschedule automatic termination to be different than was originally set during creation of the ManagedJob resource. |
| ManagedJob::destroy | This (optional) step allows the client to explicitly abort a job and destroy the ManagedJob resource in the event that the scheduled automatic termination time is not adequate. If the job has already completed (i.e. is in the Done or Failed state), this will simply destroy the resource associated with the job. If the job has not completed, appropriate steps will be taken to purge the job process from the scheduler and perform clean up operations before setting the job state to Failed. |
| ManagedJob::subscribe | This (optional) step allows a client to subscribe for notifications of status (and particularly life cycle status) of the ManagedJob resource. For responsiveness, it is possible to establish an initial subscription in the createManagedJob() operation without an additional round-trip communication to the newly created job. |
| ManagedJob::getResourceProperty and getMultipleResourceProperties | These (optional) steps allow a client to query the status (and particularly life cycle status) of the ManagedJob resource. |
The ManagedJob resource has a complex life cycle. The generic behavior is depicted in the following flowchart as a partially ordered sequence of processes and decision points. The status of the ManagedJob resource, including its "job state" is set as a side-effect of this control flow. The processes in the flowchart do not all directly correspond to client-visible job states.
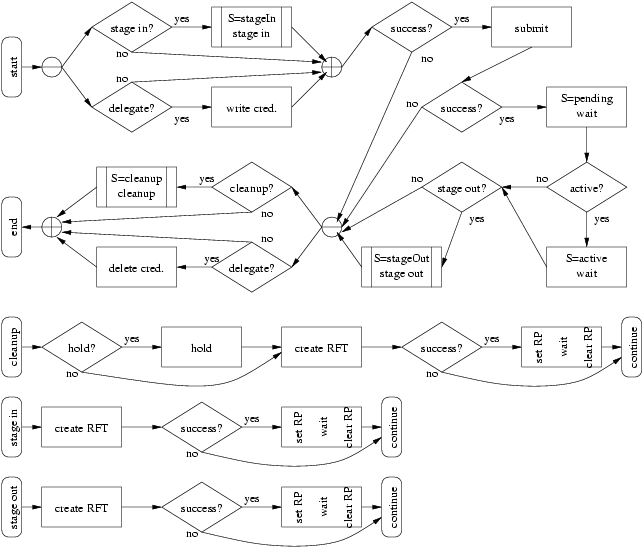
Table 7. Software for local system interaction
| Scheduler adapters | Support to control each local scheduler is provided in the form of adapter scripts in the Perl programming language, following the proprietary GRAM adapter plugin API. These adapters implement the system-specific submission, job exit detection, job cancellation, and (optionally) job exit status determination processes. |
| gridmap_authorize_and_exec | The |
From a protocol perspective, the longest latency WS GRAM submission scenario involves credential delegation, staging before and after the job, and an explicit hold handshake on file cleanup after the job. The credential refresh feature of WS GRAM can be repeated any number of times, so by longest sequence we mean the longest fixed sequence with at most one credential delegation. Explicit termination is not necessary with WS GRAM so we will not consider that case further.
To understand the following figures which illustrate the protocol sequence: the arrows show communication, signalling, or causal links between tiers in the architecture and the vertical span indicates elapsed time (with the start time at the top of the diagram). Due to unpredictable implementation delays, client and job-observed times are not necessarily ordered with respect to the WS GRAM observed times and the WS GRAM generated state notification messages. The diagrams show one possible ordering but applications (and our measurement methods) must tolerate other orderings as well.
The simplest WS GRAM scenario involves a job that requires neither delegated credentials nor staging and that makes use of the automatic termination of resources to avoid an explicit termination request. In this case, we can measure the latency and throughput for job submission and notification alone.
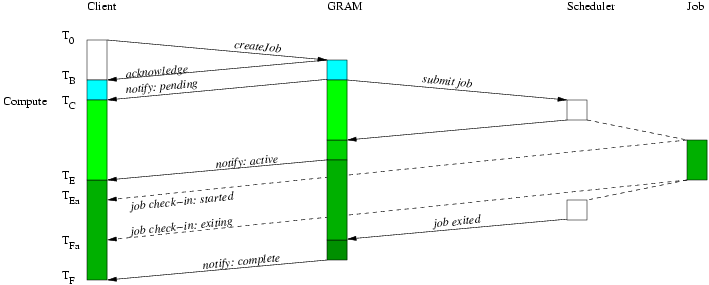
Note: Any difference between this case and the same measurement points in the full scenario must be due to the additional overhead of the delegation and staging services on the front-end node?
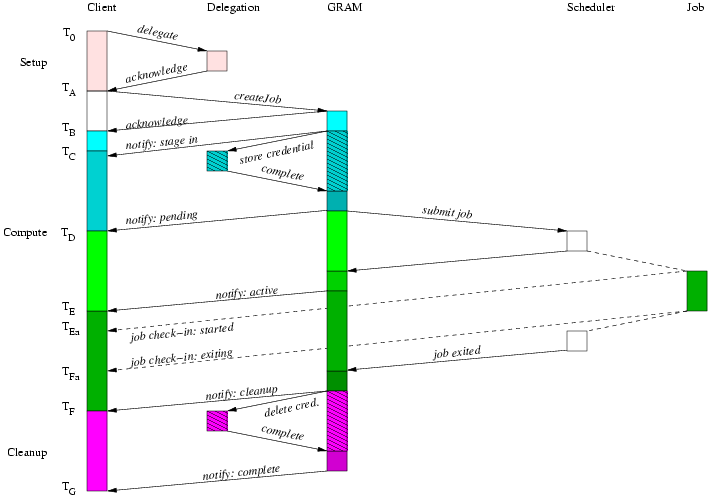
A slightly longer form of job than the minimal sequence is to include credential delegation for use by the job itself, without any staging directives. This sequence is comparable in functionality to previous GRAM releases where delegation was mandatory but staging could be omitted as per the client's request.
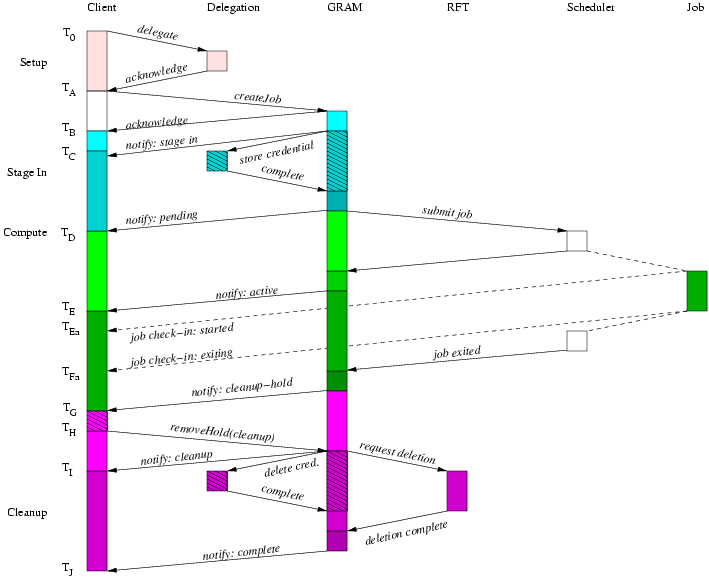
An optional protocol sequence allows the cleanup state to be held in order to allow a client to safely access output files via the GridFTP server after the job has finished writing them and before the cleanup step deletes them. This variant adds the cleanup hold handshake to the previous scenario.
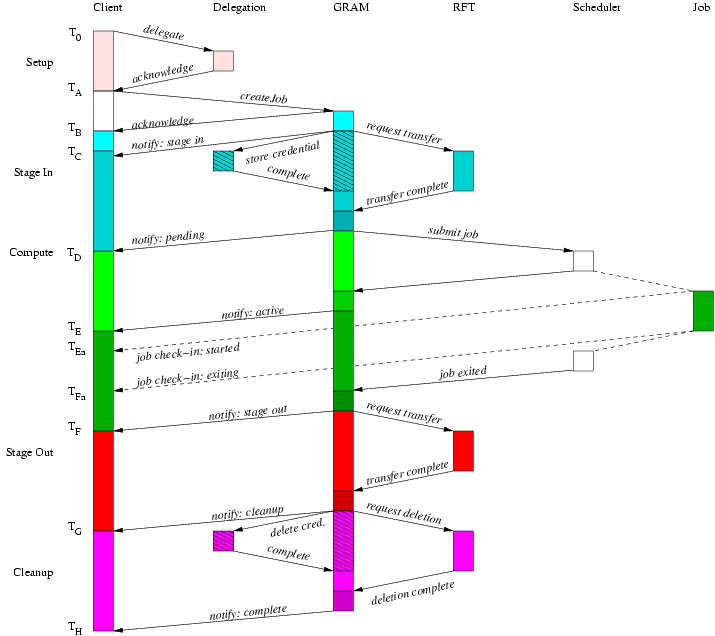
There are several optional parts to the WS GRAM job workflow and protocol. To understand the performance and scalability characteristics of WS GRAM, we must consider variations where different parts of the protocol are used or omitted.
We report average performance for #TRIALS submissions of each of the
three variant sequences described above, using an instrumented version
of the globusrun-ws client command-line tool. Each trial is
an independent run with no other client load on the test WS GRAM
server.
The columns in the figure correspond to the three scenarios described above, and the horizontal bands correspond to the distinct phases of the protocol.
NOTE: these charts currently just illustrate the visualization technique using fictional measurements and do not represent measured data!!
The chart on the left is automatically generated from data files and therefore up to date with any experiments. The chart on the right has been hand-retouched from a snapshot, to color the phases with the same coloring as in the sequence diagrams. Final release documents will include only the retouched chart with consistent coloring.
NOTE: these charts currently just illustrate the visualization technique using fictional measurements and do not represent measured data!!
We use an instrumented version of our command-line client tool to submit one dummy job at a time and log each relevant protocol event with a timestamp. For each of the above scenarios, the protocol events are mapped to the appropriate life cycle boundary for comparison, taking into account the presence or absence of optional protocol sequences in each scenario. The instrumented client measures the initial time by generating a timestamp before issuing the first operation request.
The times from one thousand (1000) independent trials are converted to intervals relative to the initiating protocol event and then these intervals are averaged for all trials. The raw timestamped event logs are preserved in case other analysis methods are preferred in the future.
Table 8. Mapping of protocol events to life cycle boundaries for each testing scenario
| Boundary | Scenario | ||||
|---|---|---|---|---|---|
| Minimal | Delegating | Delegating w/ Hold | Staging | Staging w/ Hold | |
| 0. Sequence Initiated | createManagedJob() invoked | requestSecurityToken() invoked | |||
| 1. Delegation complete | requestSecurityToken() returns | ||||
| 2. Creation complete | createManagedJob() returns | ||||
| 3. Submission complete | Pending state notified | StageIn state notified | |||
| 4. StageIn/Setup complete | Pending state notified | ||||
| 5. Pending/Start complete | Active state notified | ||||
| 6. Execution complete | Done state notified | Cleanup state notified | CleanupHold state notified | StageOut state notified | |
| 7. StageOut complete | Cleanup state notified | CleanupHold state notified | |||
| 8. Hold complete | Cleanup state notified | Cleanup state notified | |||
| 9. Cleanup complete | Done state notified | ||||
For these measurements, we repeat the trials with differing numbers of concurrent (pipelined) submissions from a single client, using a customized test client tool. This leads to a relatively steady-state measurement condition with a parameterized amount of concurrent load on the WS GRAM server.