The clustering features in JBoss AS are built on top of lower level libraries that provide much of the core functionality. Figure 3.1, “The JBoss AS clustering architecture” shows the main pieces:
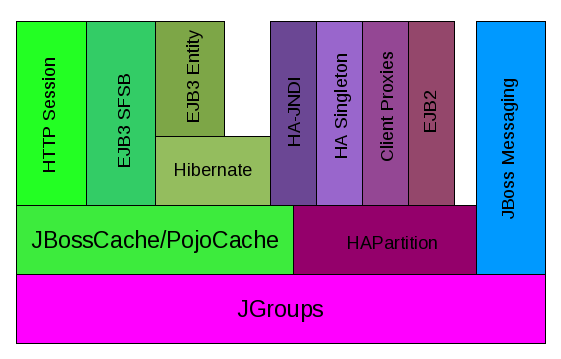
JGroups is a toolkit for reliable point-to-point and point-to-multipoint communication. JGroups is used for all clustering-related communications between nodes in a JBoss AS cluster. See Section 3.1, “Group Communication with JGroups” for more on how JBoss AS uses JGroups.
JBoss Cache is a highly flexible clustered transactional caching library. Many AS clustering services need to cache some state in memory while 1) ensuring for high availability purposes that a backup copy of that state is available on another node if it can't otherwise be recreated (e.g. the contents of a web session) and 2) ensuring that the data cached on each node in the cluster is consistent. JBoss Cache handles these concerns for most JBoss AS clustered services. JBoss Cache uses JGroups to handle its group communication requirements. POJO Cache is an extension of the core JBoss Cache that JBoss AS uses to support fine-grained replication of clustered web session state. See Section 3.2, “Distributed Caching with JBoss Cache” for more on how JBoss AS uses JBoss Cache and POJO Cache.
HAPartition is an adapter on top of a JGroups channel that allows multiple services to use the channel. HAPartition also supports a distributed registry of which HAPartition-based services are running on which cluster members. It provides notifications to interested listeners when the cluster membership changes or the clustered service registry changes. See Section 3.3, “The HAPartition Service” for more details on HAPartition.
The other higher level clustering services make use of JBoss Cache or HAPartition, or, in the case of HA-JNDI, both. The exception to this is JBoss Messaging's clustering features, which interact with JGroups directly.
JGroups provides the underlying group communication support for
JBoss AS clusters. Services deployed on JBoss AS which need group
communication with their peers will obtain a JGroups Channel
and use it to communicate. The Channel handles such
tasks as managing which nodes are members of the group, detecting node failures,
ensuring lossless, first-in-first-out delivery of messages to all group members,
and providing flow control to ensure fast message senders cannot overwhelm
slow message receivers.
The characteristics of a JGroups Channel are determined
by the set of protocols that compose it. Each protocol
handles a single aspect of the overall group communication task; for example
the UDP protocol handles the details of sending and
receiving UDP datagrams. A Channel that uses the
UDP protocol is capable of communicating with UDP unicast and
multicast; alternatively one that uses the TCP protocol
uses TCP unicast for all messages. JGroups supports a wide variety of different
protocols (see Section 10.1, “Configuring a JGroups Channel's Protocol Stack” for details), but
the AS ships with a default set of channel configurations that should meet
most needs.
By default, UDP multicast is used by all JGroups channels used by the AS (except for one TCP-based channel used by JBoss Messaging).
A significant difference in JBoss AS 5 versus previous releases
is that JGroups Channels needed by clustering services (e.g. a channel
used by a distributed HttpSession cache) are no longer configured in
detail as part of the consuming service's configuration, and are no longer
directly instantiated by the consuming service. Instead, a new
ChannelFactory service is used as a registry for named
channel configurations and as a factory for Channel instances.
A service that needs a channel requests the channel from the ChannelFactory,
passing in the name of the desired configuration.
The ChannelFactory service is deployed in the
server/all/deploy/cluster/jgroups-channelfactory.sar.
On startup the ChannelFactory service parses the
server/all/deploy/cluster/jgroups-channelfactory.sar/META-INF/jgroups-channelfactory-stacks.xml
file, which includes various standard JGroups configurations identified
by name (e.g "udp" or "tcp"). Services needing a channel access the channel
factory and ask for a channel with a particular named configuration.
The standard protocol stack configurations that ship with AS 5
are described below. Note that not all of these are actually used;
many are included as a convenience to users who may wish to alter the
default server configuration. The configurations actually used in a
stock AS 5 all config are udp,
jbm-control and jbm-data, with
all clustering services other than JBoss Messaging using udp.
udp
UDP multicast based stack meant to be shared between different channels. Message bundling is disabled, as it can add latency to synchronous group RPCs. Services that only make asynchronous RPCs (e.g. JBoss Cache configured for REPL_ASYNC) and do so in high volume may be able to improve performance by configuring their cache to use the
udp-asyncstack below. Services that only make synchronous RPCs (e.g. JBoss Cache configured for REPL_SYNC or INVALIDATION_SYNC) may be able to improve performance by using theudp-syncstack below, which does not include flow control.udp-async
Same as the default
udpstack above, except message bundling is enabled in the transport protocol (enable_bundling=true). Useful for services that make high-volume asynchronous RPCs (e.g. high volume JBoss Cache instances configured for REPL_ASYNC) where message bundling may improve performance.udp-sync
UDP multicast based stack, without flow control and without message bundling. This can be used instead of
udpif (1) synchronous calls are used and (2) the message volume (rate and size) is not that large. Don't use this configuration if you send messages at a high sustained rate, or you might run out of memory.tcp
TCP based stack, with flow control and message bundling. TCP stacks are usually used when IP multicasting cannot be used in a network (e.g. routers discard multicast).
tcp-sync
TCP based stack, without flow control and without message bundling. TCP stacks are usually used when IP multicasting cannot be used in a network (e.g.routers discard multicast). This configuration should be used instead of
tcpabove when (1) synchronous calls are used and (2) the message volume (rate and size) is not that large. Don't use this configuration if you send messages at a high sustained rate, or you might run out of memory.jbm-control
Stack optimized for the JBoss Messaging Control Channel. By default uses the same UDP transport protocol config as is used for the default 'udp' stack defined above. This allows the JBoss Messaging Control Channel to use the same sockets, network buffers and thread pools as are used by the other standard JBoss AS clustered services (see Section 3.1.2, “The JGroups Shared Transport”.
jbm-data
Stack optimized for the JBoss Messaging Data Channel. TCP-based
You can add a new stack configuration by adding a new stack
element to the server/all/deploy/cluster/jgroups-channelfactory.sar/META-INF/jgroups-channelfactory-stacks.xml
file. You can alter the behavior of an existing configuration by
editing this file. Before doing this though, have a look at the
other standard configurations the AS ships; perhaps one of those
meets your needs. Also, please note that before editing a
configuration you should understand what services are using that
configuration; make sure the change you are making is appropriate
for all affected services. If the change isn't appropriate for a
particular service, perhaps its better to create a new configuration
and change some services to use that new configuration.
It's important to note that if several services request a channel
with the same configuration name from the ChannelFactory, they are not
handed a reference to the same underlying Channel. Each receives its own
Channel, but the channels will have an identical configuration. A logical
question is how those channels avoid forming a group with each other
if each, for example, is using the same multicast address and port.
The answer is that when a consuming service connects its Channel, it
passes a unique-to-that-service cluster_name argument
to the Channel.connect(String cluster_name) method.
The Channel uses that cluster_name as one of the factors
that determine whether a particular message received over the
network is intended for it.
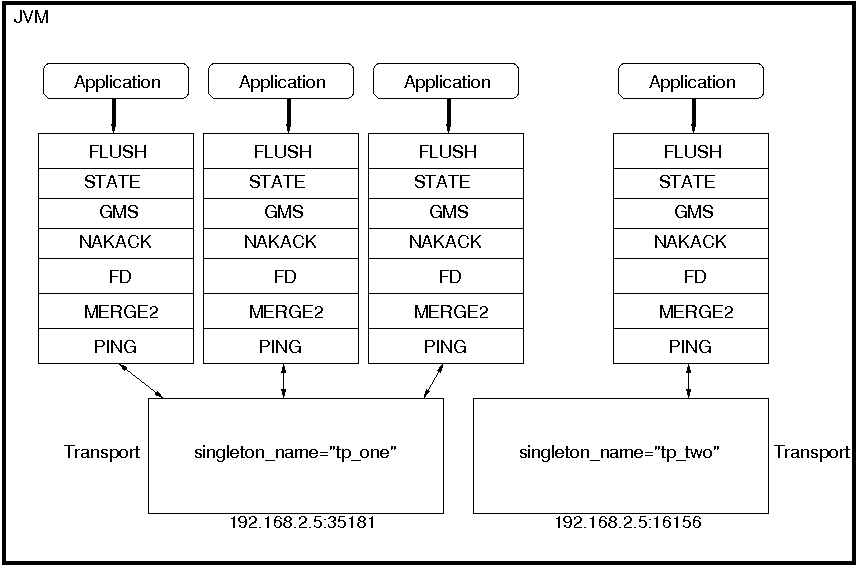
As the number of JGroups-based clustering services running in the AS has risen over the years, the need to share the resources (particularly sockets and threads) used by these channels became a glaring problem. A stock AS 5 all config will connect 4 JGroups channels during startup, and a total of 7 or 8 will be connected if distributable web apps, clustered EJB3 SFSBs and a clustered JPA/Hibernate second level cache are all used. So many channels can consume a lot of resources, and can be a real configuration nightmare if the network environment requires configuration to ensure cluster isolation.
Beginning with AS 5, JGroups supports sharing of transport protocol instances between channels. A JGroups channel is composed of a stack of individual protocols, each of which is responsible for one aspect of the channel's behavior. A transport protocol is a protocol that is responsible for actually sending messages on the network and receiving them from the network. The resources that are most desirable for sharing (sockets and thread pools) are managed by the transport protocol, so sharing a transport protocol between channels efficiently accomplishes JGroups resource sharing.
To configure a transport protocol for sharing, simply add a
singleton_name="someName" attribute to the protocol's
configuration. All channels whose transport protocol config uses the
same singleton_name value will share their transport.
All other protocols in the stack will not be shared. The following
illustrates 4 services running in a VM, each with its own channel.
Three of the services are sharing a transport; the fourth is using
its own transport.
The protocol stack configurations used by the AS 5 ChannelFactory
all have a singleton_name configured. In fact, if you add a stack to the
ChannelFactory that doesn't include a singleton_name,
before creating any channels for that stack, the ChannelFactory will
synthetically create a singleton_name by concatenating
the stack name to the string "unnamed_", e.g. unnamed_customStack.
JBoss Cache is a fully featured distributed cache framework that can be used in any application server environment or standalone. JBoss Cache provides the underlying distributed caching support used by many of the standard clustered services in a JBoss AS cluster, including:
Replication of clustered webapp sessions.
Replication of clustered EJB3 Stateful Session beans.
Clustered caching of JPA and Hibernate entities.
Clustered Single Sign-On.
The HA-JNDI replicated tree.
DistributedStateService
Users can also create their own JBoss Cache and POJO Cache instances for custom use by their applications, see Chapter 11, JBoss Cache Configuration and Deployment for more on this.
Many of the standard clustered services in JBoss AS use JBoss
Cache to maintain consistent state across the cluster. Different
services (e.g. web session clustering or second level caching of
JPA/Hibernate entities) use different JBoss Cache instances, with
each cache configured to meet the needs of the service that uses it.
In AS 4, each of these caches was independently deployed in the
deploy/ directory, which had a number of disadvantages:
Caches that end user applications didn't need were deployed anyway, with each creating an expensive JGroups channel. For example, even if there were no clustered EJB3 SFSBs, a cache to store them was started.
Caches are internal details of the services that use them. They shouldn't be first-class deployments.
Services would find their cache via JMX lookups. Using JMX for purposes other exposing management interfaces is just not the JBoss 5 way.
In JBoss 5, the scattered cache deployments have been replaced
with a new CacheManager service,
deployed via the JBOSS_HOME/server/all/deploy/cluster/jboss-cache-manager.sar.
The CacheManager is a factory and registry for JBoss Cache instances.
It is configured with a set of named JBoss Cache configurations.
Services that need a cache ask the cache manager for the cache by
name; the cache manager creates the cache (if not already created)
and returns it. The cache manager keeps a reference to each cache
it has created, so all services that request the same cache configuration
name will share the same cache. When a service is done with the cache,
it releases it to the cache manager. The cache manager keeps track
of how many services are using each cache, and will stop and destroy
the cache when all services have released it.
The following standard JBoss Cache configurations ship with JBoss AS 5.
You can add others to suit your needs, or edit these configurations
to adjust cache behavior. Additions or changes are done by editing
the deploy/cluster/jboss-cache-manager.sar/META-INF/jboss-cache-manager-jboss-beans.xml
file (see Section 11.2.1, “Deployment Via the CacheManager Service”
for details). Note however that these configurations are specifically
optimized for their intended use, and except as specifically noted
in the documentation chapters for each service in this guide,
it is not advisable to change them.
standard-session-cache
Standard cache used for web sessions.
field-granularity-session-cache
Standard cache used for FIELD granularity web sessions.
sfsb-cache
Standard cache used for EJB3 SFSB caching.
ha-partition
Used by web tier Clustered Single Sign-On, HA-JNDI, Distributed State.
mvcc-entity
A config appropriate for JPA/Hibernate entity/collection caching that uses JBC's MVCC locking (see notes below).
optimistic-entity
A config appropriate for JPA/Hibernate entity/collection caching that uses JBC's optimistic locking (see notes below).
pessimistic-entity
A config appropriate for JPA/Hibernate entity/collection caching that uses JBC's pessimistic locking (see notes below).
mvcc-entity-repeatable
Same as "mvcc-entity" but uses JBC's REPEATABLE_READ isolation level instead of READ_COMMITTED (see notes below).
pessimistic-entity-repeatable
Same as "pessimistic-entity" but uses JBC's REPEATABLE_READ isolation level instead of READ_COMMITTED (see notes below).
local-query
A config appropriate for JPA/Hibernate query result caching. Does not replicate query results. DO NOT store the timestamp data Hibernate uses to verify validity of query results in this cache.
replicated-query
A config appropriate for JPA/Hibernate query result caching. Replicates query results. DO NOT store the timestamp data Hibernate uses to verify validity of query result in this cache.
timestamps-cache
A config appropriate for the timestamp data cached as part of JPA/Hibernate query result caching. A replicated timestamp cache is required if query result caching is used, even if the query results themselves use a non-replicating cache like
local-query.mvcc-shared
A config appropriate for a cache that's shared for JPA/Hibernate entity, collection, query result and timestamp caching. Not an advised configuration, since it requires cache mode REPL_SYNC, which is the least efficient mode. Also requires a full state transfer at startup, which can be expensive. Maintained for backwards compatibility reasons, as a shared cache was the only option in JBoss 4. Uses JBC's MVCC locking.
optimistic-shared
A config appropriate for a cache that's shared for JPA/Hibernate entity, collection, query result and timestamp caching. Not an advised configuration, since it requires cache mode REPL_SYNC, which is the least efficient mode. Also requires a full state transfer at startup, which can be expensive. Maintained for backwards compatibility reasons, as a shared cache was the only option in JBoss 4. Uses JBC's optimistic locking.
pessimistic-shared
A config appropriate for a cache that's shared for JPA/Hibernate entity, collection, query result and timestamp caching. Not an advised configuration, since it requires cache mode REPL_SYNC, which is the least efficient mode. Also requires a full state transfer at startup, which can be expensive. Maintained for backwards compatibility reasons, as a shared cache was the only option in JBoss 4. Uses JBC's pessimistic locking.
mvcc-shared-repeatable
Same as "mvcc-shared" but uses JBC's REPEATABLE_READ isolation level instead of READ_COMMITTED (see notes below).
pessimistic-shared-repeatable
Same as "pessimistic-shared" but uses JBC's REPEATABLE_READ isolation level instead of READ_COMMITTED. (see notes below).
Note
For more on JBoss Cache's locking schemes, see Section 11.1.4, “Concurrent Access”)
Note
For JPA/Hibernate second level caching, REPEATABLE_READ is only useful if the application evicts/clears entities from the EntityManager/Hibernate Session and then expects to repeatably re-read them in the same transaction. Otherwise, the Session's internal cache provides a repeatable-read semantic.
The CacheManager also supports aliasing of caches; i.e. allowing caches registered under one name to be looked up under a different name. Aliasing is useful for sharing caches between services whose configuration may specify different cache config names. It's also useful for supporting legacy EJB3 application configurations ported over from AS 4.
Aliases can be configured by editing the "CacheManager"
bean in the jboss-cache-manager-jboss-beans.xml
file. The following redacted config shows the standard aliases in
AS 5.0.0.GA:
<bean name="CacheManager" class="org.jboss.ha.cachemanager.CacheManager">
. . .
<!-- Aliases for cache names. Allows caches to be shared across
services that may expect different cache config names. -->
<property name="configAliases">
<map keyClass="java.lang.String" valueClass="java.lang.String">
<!-- Use the HAPartition cache for ClusteredSSO caching -->
<entry>
<key>clustered-sso</key>
<value>ha-partition</value>
</entry>
<!-- Handle the legacy name for the EJB3 SFSB cache -->
<entry>
<key>jboss.cache:service=EJB3SFSBClusteredCache</key>
<value>sfsb-cache</value>
</entry>
<!-- Handle the legacy name for the EJB3 Entity cache -->
<entry>
<key>jboss.cache:service=EJB3EntityTreeCache</key>
<value>mvcc-shared</value>
</entry>
</map>
</property>
. . .
</bean>
HAPartition is a general purpose service used for a variety of tasks
in AS clustering. At its core, it is an abstraction built on top of
a JGroups Channel that provides support for making/receiving RPC
invocations on/from one or more cluster members. HAPartition allows
services that use it to share a single Channel and
multiplex RPC invocations over it, eliminating the configuration complexity
and runtime overhead of having each service create its own Channel.
HAPartition also supports a distributed registry of which clustering services are
running on which cluster members. It provides notifications to
interested listeners when the cluster membership changes or the
clustered service registry changes. HAPartition forms the core of many
of the clustering services we'll be discussing in the rest of this
guide, including smart client-side clustered proxies, EJB 2 SFSB
replication and entity cache management, farming, HA-JNDI and HA singletons.
Custom services can also make use of HAPartition.
The following snippet shows the HAPartition service definition packaged with the standard JBoss AS distribution.
This configuration can be found in the server/all/deploy/cluster/hapartition-jboss-beans.xml file.
<bean name="HAPartitionCacheHandler"
class="org.jboss.ha.framework.server.HAPartitionCacheHandlerImpl">
<property name="cacheManager"><inject bean="CacheManager"/></property>
<property name="cacheConfigName">ha-partition</property>
</bean>
<bean name="HAPartition" class="org.jboss.ha.framework.server.ClusterPartition">
<depends>jboss:service=Naming</depends>
<annotation>@org.jboss.aop.microcontainer.aspects.jmx.JMX(...)</annotation>
<!-- ClusterPartition requires a Cache for state management -->
<property name="cacheHandler"><inject bean="HAPartitionCacheHandler"/></property>
<!-- Name of the partition being built -->
<property name="partitionName">${jboss.partition.name:DefaultPartition}</property>
<!-- The address used to determine the node name -->
<property name="nodeAddress">${jboss.bind.address}</property>
<!-- Max time (in ms) to wait for state transfer to complete. -->
<property name="stateTransferTimeout">30000</property>
<!-- Max time (in ms) to wait for RPC calls to complete. -->
<property name="methodCallTimeout">60000</property>
<!-- Optionally provide a thread source to allow async connect of our channel -->
<property name="threadPool">
<inject bean="jboss.system:service=ThreadPool"/>
</property>
<property name="distributedStateImpl">
<bean name="DistributedState"
class="org.jboss.ha.framework.server.DistributedStateImpl">
<annotation>@org.jboss.aop.microcontainer.aspects.jmx.JMX(...)</annotation>
<property name="cacheHandler">
<inject bean="HAPartitionCacheHandler"/>
</property>
</bean>
</property>
</bean>Much of the above is boilerplate; below we'll touch on the key points
relevant to end users. There are two beans defined above, the
HAPartitionCacheHandler and the HAPartition itself.
The HAPartition bean itself exposes the following
configuration properties:
partitionName specifies the name of the cluster. Its default value is
DefaultPartition. Use the-g(a.k.a. --partition) command line switch to set this value at JBoss startup.nodeAddress is unused and can be ignored.
stateTransferTimeout specifies the timeout (in milliseconds) for initial application state transfer. State transfer refers to the process of obtaining a serialized copy of initial application state from other already-running cluster members at service startup. Its default value is
30000.methodCallTimeout specifies the timeout (in milliseconds) for obtaining responses to group RPCs from the other cluster members. Its default value is
60000.
The HAPartitionCacheHandler is a small utility service that
helps the HAPartition integrate with JBoss Cache
(see Section 3.2.1, “The JBoss AS CacheManager Service”). HAPartition exposes
a child service called DistributedState (see Section 3.3.2, “DistributedState Service”)
that uses JBoss Cache; the HAPartitionCacheHandler helps ensure
consistent configuration between the JGroups Channel used by
Distributed State's cache and the one used directly by HAPartition.
cacheConfigName the name of the JBoss Cache configuration to use for the HAPartition-related cache. Indirectly, this also specifies the name of the JGroups protocol stack configuration HAPartition should use. See Section 11.1.5, “JGroups Integration” for more on how the JGroups protocol stack is configured.
In order for nodes to form a cluster, they must have the exact same partitionName
and the HAPartitionCacheHandler's cacheConfigName
must specify an identical JBoss Cache configuration. Changes in either
element on some but not all nodes would prevent proper clustering behavior.
You can view the current cluster information by pointing your browser to the JMX console of any
JBoss instance in the cluster (i.e., http://hostname:8080/jmx-console/) and then
clicking on the jboss:service=HAPartition,partition=DefaultPartition MBean (change the MBean name to reflect your partitionr name if you use the -g startup switch). A list of IP addresses for the current cluster members is shown in the CurrentView field.
Note
While it is technically possible to put a JBoss server instance into multiple HAPartitions at the same time, this practice is generally not recommended, as it increases management complexity.
The DistributedReplicantManager (DRM) service is a component
of the HAPartition service made available to HAPartition
users via the HAPartition.getDistributedReplicantManager()
method. Generally speaking, JBoss AS users will not directly make
use of the DRM; we discuss it here as an aid to those who want a
deeper understanding of how AS clustering internals work.
The DRM is a distributed registry that allows HAPartition users to register objects under a given key, making available to callersthe set of objects registered under that key by the various members of t he cluster. The DRM also provides a notification mechanism so interested listeners can be notified when the contents of the registry changes.
There are two main usages for the DRM in JBoss AS:
Clustered Smart Proxies
Here the keys are the names of the various services that need a clustered smart proxy (see Section 2.2.1, “Client-side interceptor architecture”, e.g. the name of a clustered EJB. The value object each node stores in the DRM is known as a "target". It's something a smart proxy's transport layer can use to contact the node (e.g. an RMI stub, an HTTP URL or a JBoss Remoting
InvokerLocator). The factory that builds clustered smart proxies accesses the DRM to get the set of "targets" that should be injected into the proxy to allow it to communicate with all the nodes in a cluster.HASingleton
Here the keys are the names of the various services that need to function as High Availablity Singletons (see ???). The value object each node stores in the DRM is simply a String that acts as a token to indicate that the node has the service deployed, and thus is a candidate to become the "master" node for the HA singleton service.
In both cases, the key under which objects are registered identifies a particular clustered service. It is useful to understand that every node in a cluster doesn't have to register an object under every key. Only services that are deployed on a particular node will register something under that service's key, and services don't have to be deployed homogeneously across the cluster. The DRM is thus useful as a mechanism for understanding a service's "topology" around the cluster -- which nodes have the service deployed.
The DistributedState service is a legacy component
of the HAPartition service made available to HAPartition
users via the HAPartition.getDistributedState()
method. This service provides coordinated management of arbitary
application state around the cluster. It is supported for backwards
compatibility reasons, but new applications should not use it; they
should use the much more sophisticated JBoss Cache instead.
In JBoss 5 the DistributedState service actually
delegates to an underlying JBoss Cache instance.
Custom services can also use make use of HAPartition to handle
interactions with the cluster. Generally the easiest way to do this
is to extend the org.jboss.ha.framework.server.HAServiceImpl
base class, or the org.jboss.ha.jxm.HAServiceMBeanSupport
class if JMX registration and notification support are desired.