A clustered singleton service (also known as an HA singleton) is a service that is deployed on multiple nodes in a cluster, but is providing its service on only one of the nodes. The node running the singleton service is typically called the master node. When the master fails or is shut down, another master is selected from the remaining nodes and the service is restarted on the new master. Thus, other than a brief interval when one master has stopped and another has yet to take over, the service is always being provided by one but only one node.
The JBoss Application Server (AS) provides support for a number of
strategies for helping you deploy clustered singleton services. In
this section we will explore the different strategies. All of the
strategies are built on top of the HAPartition service described
in the introduction. They rely on the HAPartition
to provide notifications when different nodes in the cluster start
and stop; based on those notifications each node in the cluster
can independently (but consistently) determine if it is now the
master node and needs to begin providing a service.
The simplest and most commonly used strategy for deploying an HA
singleton is to take an ordinary deployment (war, ear, jar,
whatever you would normally put in deploy) and deploy it in the
$JBOSS_HOME/server/all/deploy-hasingleton
directory instead of in deploy. The
deploy-hasingleton directory does not lie under
deploy nor farm directories,
so its contents are not automatically deployed
when an AS instance starts. Instead, deploying the contents of this
directory is the responsibility of a special service, the
HASingletonDeployer bean
(which itself is deployed via the
deploy/deploy-hasingleton-jboss-beans.xml file.) The
HASingletonDeployer service is itself an HA Singleton, one whose
provided service, when it becomes master, is to deploy the
contents of deploy-hasingleton; and whose service, when it stops
being the master (typically at server shutdown), is to undeploy
the contents of deploy-hasingleton.
So, by placing your deployments in deploy-hasingleton
you know that they will be deployed only on the master node in
the cluster. If the master node cleanly shuts down, they will be
cleanly undeployed as part of shutdown. If the master node fails
or is shut down, they will be deployed on whatever node takes
over as master.
Using deploy-hasingleton is very simple, but it does have two drawbacks:
There is no hot-deployment feature for services in
deploy-hasingleton. Redeploying a service that has been deployed todeploy-hasingletonrequires a server restart.If the master node fails and another node takes over as master, your singleton service needs to go through the entire deployment process before it will be providing services. Depending on the complexity of your service's deployment, and the extent of startup activity in which it engages, this could take a while, during which time the service is not being provided.
If your service is a POJO (i.e., not a J2EE deployment like an ear or war or jar), you can deploy it along with a service called an HASingletonController in order to turn it into an HA singleton. It is the job of the HASingletonController to work with the HAPartition service to monitor the cluster and determine if it is now the master node for its service. If it determines it has become the master node, it invokes a method on your service telling it to begin providing service. If it determines it is no longer the master node, it invokes a method on your service telling it to stop providing service. Let's walk through an illustration.
First, we have a POJO that we want to make an HA singleton. The only thing special about it is it needs to expose a public method that can be called when it should begin providing service, and another that can be called when it should stop providing service:
public interface HASingletonExampleMBean
{
boolean isMasterNode();
}
public class HASingletonExample implements HASingletonExampleMBean
{
private boolean isMasterNode = false;
public boolean isMasterNode()
{
return isMasterNode;
}
public void startSingleton()
{
isMasterNode = true;
}
public void stopSingleton()
{
isMasterNode = false;
}
}
We used startSingleton and stopSingleton
in the above example, but you could name the methods anything.
Next, we deploy our service, along with an HASingletonController
to control it, most likely packaged in a .sar file, with the
following META-INF/jboss-beans.xml:
<deployment xmlns="urn:jboss:bean-deployer:2.0">
<!-- This bean is an example of a clustered singleton -->
<bean name="HASingletonExample" class="org.jboss.ha.examples.HASingletonExample">
<annotation>@org.jboss.aop.microcontainer.aspects.jmx.JMX(...)</annotation>
</bean>
<bean name="ExampleHASingletonController" class="org.jboss.ha.singleton.HASingletonController">
<annotation>@org.jboss.aop.microcontainer.aspects.jmx.JMX(...)</annotation>
<property name="HAPartition"><inject bean="HAPartition"/></property>
<property name="target"><inject bean="HASingletonExample"/></property>
<property name="targetStartMethod">startSingleton</property>
<property name="targetStopMethod">stopSingleton</property>
</bean>
</deployment>Voila! A clustered singleton service.
The primary advantage of this approach over deploy-ha-singleton.
is that the above example can be placed in
deploy or farm
and thus can be hot deployed and farmed deployed. Also, if our
example service had complex, time-consuming startup
requirements, those could potentially be implemented in create()
or start() methods. JBoss will invoke create() and start() as
soon as the service is deployed; it doesn't wait until the node
becomes the master node. So, the service could be primed and
ready to go, just waiting for the controller to implement
startSingleton() at which point it can immediately provide
service.
Although not demonstrated in the example above, the HASingletonController
can support an optional argument for either or both of the
target start and stop methods.
These are specified using the targetStartMethodArgument and
TargetStopMethodArgument properties, respectively.
Currently, only string values are supported.
Services deployed normally inside deploy or farm that want to be started/stopped whenever the content of deploy-hasingleton gets deployed/undeployed, (i.e., whenever the current node becomes the master), need only specify a dependency on the Barrier service:
<depends>HASingletonDeployerBarrierController</depends>
The way it works is that a BarrierController is deployed along with the HASingletonDeployer and listens for JMX notifications from it. A BarrierController is a relatively simple Mbean that can subscribe to receive any JMX notification in the system. It uses the received notifications to control the lifecycle of a dynamically created Mbean called the Barrier. The Barrier is instantiated, registered and brought to the CREATE state when the BarrierController is deployed. After that, the BarrierController starts and stops the Barrier when matching JMX notifications are received. Thus, other services need only depend on the Barrier bean using the usual <depends> tag, and they will be started and stopped in tandem with the Barrier. When the BarrierController is undeployed the Barrier is also destroyed.
This provides an alternative to the deploy-hasingleton approach in that we can use farming to distribute the service, while content in deploy-hasingleton must be copied manually on all nodes.
On the other hand, the barrier-dependent service will be instantiated/created (i.e., any create() method invoked) on all nodes, but only started on the master node. This is different with the deploy-hasingleton approach that will only deploy (instantiate/create/start) the contents of the deploy-hasingleton directory on one of the nodes.
So services depending on the barrier will need to make sure they do minimal or no work inside their create() step, rather they should use start() to do the work.
Note
The Barrier controls the start/stop of dependent services, but not their destruction,
which happens only when the BarrierController is itself destroyed/undeployed.
Thus using the Barrier to control services that need to be "destroyed" as part of their normal “undeploy” operation (like, for example, an EJBContainer) will not have the desired effect.
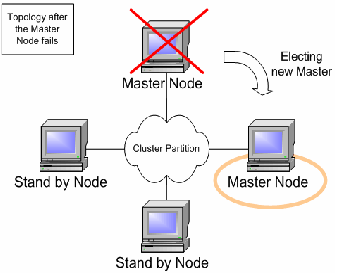
The various clustered singleton management strategies all depend on the fact that each node in the cluster can independently react to changes in cluster membership and correctly decide whether it is now the “master node”. How is this done?
For each member of the cluster, the HAPartition service maintains an attribute called the CurrentView, which is basically an ordered list of the current members of the cluster.
As nodes join and leave the cluster, JGroups ensures that each surviving member of the cluster gets an updated view.
You can see the current view by going into the JMX console, and looking at the CurrentView attribute in the jboss:service=DefaultPartition mbean.
Every member of the cluster will have the same view, with the members in the same order.
Let's say, for example, that we have a 4 node cluster, nodes A through D, and the current view can be expressed as {A, B, C, D}. Generally speaking, the order of nodes in the view will reflect the order in which they joined the cluster (although this is not always the case, and should not be assumed to be the case).
To further our example, let's say there is a singleton service (i.e. an HASingletonController) named Foo that's deployed around the cluster, except, for whatever reason, on B.
The HAPartition service maintains across the cluster a registry of what services are deployed where, in view order.
So, on every node in the cluster, the HAPartition service knows that the view with respect to the Foo service is {A, C, D} (no B).
Whenever there is a change in the cluster topology of the Foo service, the HAPartition service invokes a callback on Foo notifying it of the new topology.
So, for example, when Foo started on D, the Foo service running on A, C and D all got callbacks telling them the new view for Foo was {A, C, D}.
That callback gives each node enough information to independently decide if it is now the master.
The Foo service on each node uses the HAPartition's HASingletonElectionPolicy to determine if they are the master, as explained in the next section.
If A were to fail or shutdown, Foo on C and D would get a callback with a new view for Foo of {C, D}. C would then become the master. If A restarted, A, C and D would get a callback with a new view for Foo of {C, D, A}. C would remain the master – there's nothing magic about A that would cause it to become the master again just because it was before.
The HASingletonElectionPolicy object is responsible for electing a master node from a list of available nodes, on behalf of an HA singleton, following a change in cluster topology.
public interface HASingletonElectionPolicy
{
ClusterNode elect(List<ClusterNode> nodes);
}JBoss ships with 2 election policies:
HASingletonElectionPolicySimpleThis policy selects a master node based relative age. The desired age is configured via the
positionproperty, which corresponds to the index in the list of available nodes.position = 0, the default, refers to the oldest node;position = 1, refers to the 2nd oldest; etc.positioncan also be negative to indicate youngness; imagine the list of available nodes as a circular linked list.position = -1, refers to the youngest node;position = -2, refers to the 2nd youngest node; etc.<bean class="org.jboss.ha.singleton.HASingletonElectionPolicySimple"> <property name="position">-1</property> </bean>
PreferredMasterElectionPolicyThis policy extends
HASingletonElectionPolicySimple, allowing the configuration of a preferred node. ThepreferredMasterproperty, specified as host:port or address:port, identifies a specific node that should become master, if available. If the preferred node is not available, the election policy will behave as described above.<bean class="org.jboss.ha.singleton.PreferredMasterElectionPolicy"> <property name="preferredMaster">server1:12345</property> </bean>
The easiest way to deploy an application into the cluster is to use the farming service.
Using the farming service, you can deploy an application (e.g. EAR, WAR, or SAR; either an archive file or in exploded form) to the
all/farm/ directory of any cluster member and the application will be automatically duplicate across all nodes in the same cluster.
If a node joins the cluster later, it will pull in all farm deployed applications in the cluster and deploy them locally at start-up time.
If you delete the application from a running clustered server node's farm/ directory,
the application will be undeployed locally and then removed from all other clustered server nodes' farm/ directories (triggering undeployment).
Note
The farming service was not available in JBoss AS 5.0.0 and 5.0.1. This section is only relevant to releases 5.1.0 and later.
Farming is enabled by default in the all configuration in JBoss AS and thus requires no manual setup.
The required farm-deployment-jboss-beans.xml and timestamps-jboss-beans.xml configuration files are located in the deploy/cluster directory.
If you want to enable farming in a custom configuration, simply copy these files to the corresponding JBoss deploy directory $JBOSS_HOME/server/your_own_config/deploy/cluster.
Make sure that your custom configuration has clustering enabled.
While there is little need to customize the farming service, it can be customized via the FarmProfileRepositoryClusteringHandler bean, whose properties and default values are listed below:
<bean name="FarmProfileRepositoryClusteringHandler"
class="org.jboss.profileservice.cluster.repository.DefaultRepositoryClusteringHandler">
<property name="partition"><inject bean="HAPartition"/></property>
<property name="profileDomain">default</property>
<property name="profileServer">default</property>
<property name="profileName">farm</property>
<property name="immutable">false</property>
<property name="lockTimeout">60000</property><!-- 1 minute -->
<property name="methodCallTimeout">60000</property><!-- 1 minute -->
<property name="synchronizationPolicy">
<inject bean="FarmProfileSynchronizationPolicy"/>
</property>
</bean>partition is a required attribute to inject the HAPartition service that the farm service uses for intra-cluster communication.
profile[Domain|Server|Name] are all used to identify the profile for which this handler is intended.
immutable indicates whether or not this handler allows a node to push content changes to the cluster. A value of
trueis equivalent to settingsynchronizationPolicyto theorg.jboss.system.server.profileservice.repository.clustered.syncpackage'sImmutableSynchronizationPolicy.lockTimeout defines the number of milliseconds to wait for cluster-wide lock acquisition.
methodCallTimeout defines the number of milliseconds to wait for invocations on remote cluster nodes.
synchronizationPolicy decides how to handle content additions, reincarnations, updates, or removals from nodes attempting to join the cluster or from cluster merges. The policy is consulted on the "authoritative" node, i.e. the master node for the service on the cluster. Reincarnation refers to the phenomenon where a newly started node may contain an application in its
farmdirectory that was previously removed by the farming service but might still exist on the starting node if it was not running when the removal took place. The default synchronization policy is defined as follows:<bean name="FarmProfileSynchronizationPolicy" class="org.jboss.profileservice.cluster.repository.DefaultSynchronizationPolicy"> <property name="allowJoinAdditions"><null/></property> <property name="allowJoinReincarnations"><null/></property> <property name="allowJoinUpdates"><null/></property> <property name="allowJoinRemovals"><null/></property> <property name="allowMergeAdditions"><null/></property> <property name="allowMergeReincarnations"><null/></property> <property name="allowMergeUpdates"><null/></property> <property name="allowMergeRemovals"><null/></property> <property name="developerMode">false</property> <property name="removalTrackingTime">2592000000</property><!-- 30 days --> <property name="timestampService"> <inject bean="TimestampDiscrepancyService"/> </property> </bean>allow[Join|Merge][Additions|Reincarnations|Updates|Removals] define fixed responses to requests to allow additions, reincarnations, updates, or removals from joined or merged nodes.
developerMode enables a lenient synchronization policy that allows all changes. Enabling developer mode is equivalent to setting each of the above properties to
trueand is intended for development environments.removalTrackingTime defines the number of milliseconds for which this policy should remembered removed items, for use in detecting reincarnations.
timestampService estimates and tracks discrepancies in system clocks for current and past members of the cluster. Default implementation is defined in
timestamps-jboss-beans.xml.