This chapter discusses some of the more advanced concepts of JGroups with respect to using it and setting it up correctly.
When using a fully virtual synchronous protocol stack, the performance may not be great because of the larger number of protocols present. For certain applications, however, throughput is more important than ordering, e.g. for video/audio streams or airplane tracking. In the latter case, it is important that airplanes are handed over between control domains correctly, but if there are a (small) number of radar tracking messages (which determine the exact location of the plane) missing, it is not a problem. The first type of messages do not occur very often (typically a number of messages per hour), whereas the second type of messages would be sent at a rate of 10-30 messages/second. The same applies for a distributed whiteboard: messages that represent a video or audio stream have to be delivered as quick as possible, whereas messages that represent figures drawn on the whiteboard, or new participants joining the whiteboard have to be delivered according to a certain order.
The requirements for such applications can be solved by using two separate stacks: one for control messages such as group membership, floor control etc and the other one for data messages such as video/audio streams (actually one might consider using one channel for audio and one for video). The control channel might use virtual synchrony, which is relatively slow, but enforces ordering and retransmission, and the data channel might use a simple UDP channel, possibly including a fragmentation layer, but no retransmission layer (losing packets is preferred to costly retransmission).
The Draw2Channels demo program (in the org.jgroups.demos package) demonstrates how to use two different channels.
In JBoss we have multiple JGroups channels, one for each application (e.g. JBossCache, ClusterPartition etc).
The goal of the Multiplexer is to combine all stacks with the same configuration into one, and have multiple services on top of that same channel.
To do this, we have to introduce multiplexing and demultiplexing functionality, ie. each service will have to have a unique service ID (a string), and when sending a message, the message has to be tagged with that ID. When receiving a message, it will be dispatched to the right destination service based on the ID attached to the message. We require special handling for VIEW and SUSPECT messages: those need to be dispatched to *all* services. State transfer also needs to be handled specially, here we probably have to use thread locals, or change the API (TBD).
When deployed into JBoss, the Multiplexer will be exposed as an MBean, and all services that depend on it will be deployed with dependency injection on the Multiplexer. Of course, the old configuration will still be supported.
The config of the Multiplexer is done via a config file, which lists a number of stacks, each keyed by a name, e.g. "udp", "tcp", "tcp-nio" etc. See ./conf/stacks.xml for an example. An app is configured with the name of a stack, e.g. "udp", and a reference to the Multiplexer MBean. It will get a proxy channel through which all of its communication will take place. The proxy channel (MuxChannel) will mux/demux messages to the real JGroups channel.
The advantage of the Multiplexer is that we can reduce N channels into M where M < N. This means fewer threads, therefore fewer context switches, less memory consumption and easier configuration and better support.
The Multiplexer is actually a JChannelFactory, which is configured with a reference to an XML configuration file, and has a few additional methods to get a Channel. The channel returned is actually an instance of MuxChannel, which transparently forwards all invocations to the underlying JChannel, and performs multiplexing and demultiplexing. Multiple MuxChannels can share the same underlying JChannel, and each message sent by a service over the MuxChannel will add the services's ID to the message (as a header). That ID is then used to demultiplex the message to the correct MuxChannel when received.
The methods of the JChannelFactory are:
public Channel createMultiplexerChannel(String stack_name, String id) throws Exception;
public Channel createMultiplexerChannel(String stack_name, String id, boolean register_for_state_transfer, String substate_id) throws Exception;
The stack_name parameter refers to a channel configuration defined in a separate file (see below).
The id parameter is the service ID and has to be unique for all services sitting on the same channel. If an ID is used more than once, when trying to call createMultiplexerChannel(), an exception will be thrown.
the register_for_state_transfer and substate_id parameters are discussed below (in Section 5.2.1.1, “Batching state transfers”).
The stack_name parameter is a reference to a stack, for example defined in stacks.xml. A shortened version of stacks.xml is shown below:
<protocol_stacks>
<stack name="fc-fast-minimalthreads" description="Flow control, no up or down threads">
<config>
<UDP mcast_port="45566"
enable_bundling="true"/>
...
<pbcast.STATE_TRANSFER down_thread="false" up_thread="false"/>
</config>
</stack>
<stack name="sequencer" description="Totally ordered multicast using a sequencer">
<config>
// config
</config>
</stack>
<stack name="tcp" description="Using TCP as transport">
<config>
<TCP start_port="7800" loopback="true" send_buf_size="100000" recv_buf_size="200000"/>
<TCPPING timeout="3000" initial_hosts="localhost[7800]" port_range="3" num_initial_members="3"/>
<FD timeout="2000" max_tries="4"/>
<VERIFY_SUSPECT timeout="1500" down_thread="false" up_thread="false"/>
<pbcast.NAKACK gc_lag="100" retransmit_timeout="600,1200,2400,4800"/>
<pbcast.STABLE stability_delay="1000" desired_avg_gossip="20000" down_thread="false" max_bytes="0" up_thread="false"/>
<VIEW_SYNC avg_send_interval="60000" down_thread="false" up_thread="false" />
<pbcast.GMS print_local_addr="true" join_timeout="5000" shun="true"/>
</config>
</stack>
<stack name="discovery" description="Simple UDP-only stack for discovery">
<config>
<UDP mcast_port="7609"
use_incoming_packet_handler="false"
mcast_addr="228.15.15.15"
use_outgoing_packet_handler="false"
ip_ttl="32"/>
</config>
</stack>
</protocol_stacks>
This file defines 4 configurations: fc-fast-minimalthreads, sequencer, tcp and discovery. The first service to call JChannelFactory.createMultiplexerChannel() with a stack_name of "tcp" will create the JChannel with the "tcp" configuration, all subsequent method calls for the same stack_name ("tcp") will simply get a MuxChannel which has a reference to the same underlying JChannel. When a service closes a MuxChannel, the underlying JChannel will only be closed when there are no more MuxChannels referring to it.
For more information on Multiplexing refer to JGroups/doc/design/Multiplexer.txt
Note that this feature is currently not used in JBoss, because JBoss doesn't call all create() methods of all dependent beans first, and then all start() methods. The call sequence is indeterministic unless all dependent beans are defined in the same XML file, which is unrealistic. We're looking into using a barrier service to provide the guarantee that all create() methods are called before all start() methods, possibly in JBoss 5.
When multiple services are sharing a JChannel, and each of the services requires state transfer at a different time, then we need FLUSH (see ./doc/design/PartialStateTransfer.txt for a description of the problem). FLUSH is also called the stop-the-world model, and essentially stops everyone in a group from sending messages until the state has been transferred, and then everyone can resume again.
Note
The 2.3 release of JGroups will not have the FLUSH protocol integrated, so state transfer for the Multiplexer might be incorrect. 2.4 will have FLUSH, so that situation will be corrected. The main reason for putting Multiplexing into 2.3 is that people can start programming against the API, and then use it when FLUSH is available.When multiple services share one JChannel, then we have to run the FLUSH protocol for every service which requires state, so if we have services A, B, C, D and E running on top of a JChannel J, and B,C and E require state, then the FLUSH protocol has to be run 3 times, which slows down startup (e.g.) of JBoss.
To remedy this, we can batch state transfers, so that we suspend everyone from sending messages, then fetch the states for B, C and E at once, and then resume everyone. Thus, the FLUSH protocol has to be run only once.
To do this, a service has to register with the JChannelFactory when creating the MuxChannel, and know that getState() will be a no-op until the last registered application has called getState(). This works as follows:
- B, C and D register for state transfer
- B calls MuxChannel.getState(). Nothing happens.
- D calls MuxChannel.getState(). Nothing happens.
- E calls MuxChannel.getState(). Now everyone who registered has called getState() and therefore we transfer the state for B, C and E (using partial state transfer).
- At this point B, C and D's setState() will be called, so that they can set the state.
The code below (a snipper from MultiplexerTest) shows how services can register for state transfers. In an MBean (JBoss) environment, the registration could be done in the create() callback, and the actual getState() call in start().
public void testStateTransferWithRegistration() throws Exception {
final String STACK_NAME="fc-fast-minimalthreads";
Channel ch1, ch2;
ch1=factory.createMultiplexerChannel(STACK_NAME, "c1", true, null); // register for (entire) state transfer
ch1.connect("bla"); // will create a new JChannel
ch2=factory.createMultiplexerChannel(STACK_NAME, "c2", true, null); // register for (entire) state transfer
ch2.connect("bla"); // will share the JChannel created above (same STACK_NAME)
boolean rc=ch1.getState(null, 5000); // this will *not* trigger the state transfer protocol
rc=ch2.getState(null, 5000); // only *this* will trigger the state transfer
}
The example above shows that 2 services ("c1" and "c2") share a common JChannel because they use the same stack_name (STACK_NAME). It also shows that only the second getState() invocation will actually transfer the 2 states (for "c1" and "c2").
When we have multiple service running on the same channel, then some services might get redeployed or stopped independently from the other services. So we might have a situation where we have services S1, S2 and S3 running on host H1, but on host H2, only services S2 and S3 are running.
The cluster view is {H1, H2}, but the service views are:
- S1: {H1}
- S2: {H1, H2}
- S3: {H1, H2}
This can also be seen as ordered by hosts:
- H1: {S1, S2, S3}
- H2: {S2, S3}
So here we host H1 running services S1, S2 and S3, whereas H2 is only running S2 and S3. S1 might be in the process of being redeployed on H2, or is simply not running.
A service view is essentially a list of nodes of a cluster on which a given service S is currently running. Service views are always subsets of cluster views. Here's a reason we need service views: consider the example above. Let's say service S1 on H1 wants to make a cluster-wide method invocation on all instances of S1 running on any host. Now, S1 is only running on H1, therefore we have to make the invocation only on S1. However, if we took the cluster view rather than the service view, the invocation would be across H1 and H2, and we'd be waiting for a response from the (non-existent) service S1 on H2 forever !
So, by default, calling MuxChannel.getView() will return the service view rather than the cluster view. The cluster view can be retrieved calling MuxChannel.getClusterView().
There are example unit tests in MultiplexerTest and MultiplexerViewTest. The latter tests service views versus cluster views.
To save resources (threads, sockets and CPU cycles), transports of channels residing within the same JVM can be shared. If we have 4 channels inside of a JVM (as is the case in an application server such as JBoss), then we have 4 separate thread pools and sockets (1 per transport, and there are 4 transports (1 per channel)).
If those transport happen to be the same (all 4 channels use UDP, for example), then we can share them and only create 1 instance of UDP. That transport instance is created and started only once, when the first channel is created, and is deleted when the last channel is closed.
Each channel created over a shared transport has to join a different cluster. An exception will be thrown if a channel sharing a transport tries to connect to a cluster to which another channel over the same transport is already connected.
When we have 3 channels (C1 connected to "cluster-1", C2 connected to "cluster-2" and C3 connected to "cluster-3") sending messages over the same shared transport, the cluster name with which the channel connected is used to multiplex messages over the shared transport: a header with the cluster name ("cluster-1") is added when C1 sends a message.
When a message with a header of "cluster-1" is received by the shared transport, it is used to demultiplex the message and dispatch it to the right channel (C1 in this example) for processing.
How channels can share a single transport is shown in Figure 5.1, “A shared transport”.
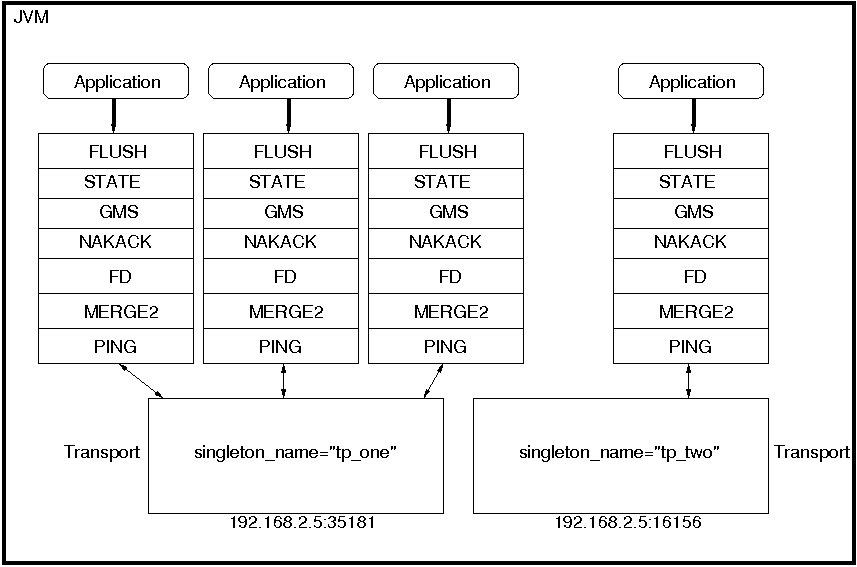
Here we see 4 channels which share 2 transports. Note that first 3 channels which share transport "tp_one" have the same protocols on top of the shared transport. This is not required; the protocols above "tp_one" could be different for each of the 3 channels as long as all applications residing on the same shared transport have the same requirements for the transport's configuration.
To use shared transports, all we need to do is to add a property "singleton_name" to the transport configuration. All channels with the same singleton name will be shared.
A transport protocol refers to the protocol at the bottom of the protocol stack which is responsible for sending and receiving messages to/from the network. There are a number of transport protocols in JGroups. They are discussed in the following sections.
A typical protocol stack configuration using UDP is:
<config>
<UDP
mcast_addr="${jgroups.udp.mcast_addr:228.10.10.10}"
mcast_port="${jgroups.udp.mcast_port:45588}"
discard_incompatible_packets="true"
max_bundle_size="60000"
max_bundle_timeout="30"
ip_ttl="${jgroups.udp.ip_ttl:2}"
enable_bundling="true"
use_concurrent_stack="true"
thread_pool.enabled="true"
thread_pool.min_threads="1"
thread_pool.max_threads="25"
thread_pool.keep_alive_time="5000"
thread_pool.queue_enabled="false"
thread_pool.queue_max_size="100"
thread_pool.rejection_policy="Run"
oob_thread_pool.enabled="true"
oob_thread_pool.min_threads="1"
oob_thread_pool.max_threads="8"
oob_thread_pool.keep_alive_time="5000"
oob_thread_pool.queue_enabled="false"
oob_thread_pool.queue_max_size="100"
oob_thread_pool.rejection_policy="Run"/>
<PING timeout="2000"
num_initial_members="3"/>
<MERGE2 max_interval="30000"
min_interval="10000"/>
<FD_SOCK/>
<FD timeout="10000" max_tries="5" shun="true"/>
<VERIFY_SUSPECT timeout="1500" />
<pbcast.NAKACK
use_mcast_xmit="false" gc_lag="0"
retransmit_timeout="300,600,1200,2400,4800"
discard_delivered_msgs="true"/>
<UNICAST timeout="300,600,1200,2400,3600"/>
<pbcast.STABLE stability_delay="1000" desired_avg_gossip="50000"
max_bytes="400000"/>
<pbcast.GMS print_local_addr="true" join_timeout="3000"
shun="false"
view_bundling="true"/>
<FC max_credits="20000000"
min_threshold="0.10"/>
<FRAG2 frag_size="60000" />
<pbcast.STATE_TRANSFER />
</config>
In a nutshell the properties of the protocols are:
- UDP
This is the transport protocol. It uses IP multicasting to send messages to the entire cluster, or individual nodes. Other transports include TCP, TCP_NIO and TUNNEL.
- PING
Uses IP multicast (by default) to find initial members. Once found, the current coordinator can be determined and a unicast JOIN request will be sent to it in order to join the cluster.
- MERGE2
Will merge subgroups back into one group, kicks in after a cluster partition.
- FD_SOCK
Failure detection based on sockets (in a ring form between members). Generates notification if a member fails
- FD
Failure detection based on heartbeats and are-you-alive messages (in a ring form between members). Generates notification if a member fails
- VERIFY_SUSPECT
Double-checks whether a suspected member is really dead, otherwise the suspicion generated from protocol below is discarded
- pbcast.NAKACK
Ensures (a) message reliability and (b) FIFO. Message reliability guarantees that a message will be received. If not, the receiver(s) will request retransmission. FIFO guarantees that all messages from sender P will be received in the order P sent them
- UNICAST
Same as NAKACK for unicast messages: messages from sender P will not be lost (retransmission if necessary) and will be in FIFO order (conceptually the same as TCP in TCP/IP)
- pbcast.STABLE
Deletes messages that have been seen by all members (distributed message garbage collection)
- pbcast.GMS
Membership protocol. Responsible for joining/leaving members and installing new views.
- FRAG2
Fragments large messages into smaller ones and reassembles them back at the receiver side. For both multicast and unicast messages
- STATE_TRANSFER
Ensures that state is correctly transferred from an existing member (usually the coordinator) to a new member.
UDP uses IP multicast for sending messages to all members of a group and UDP datagrams for unicast messages (sent to a single member). When started, it opens a unicast and multicast socket: the unicast socket is used to send/receive unicast messages, whereas the multicast socket sends/receives multicast messages. The channel's address will be the address and port number of the unicast socket.
A protocol stack with UDP as transport protocol is typically used with groups whose members run on the same host or are distributed across a LAN. Before running such a stack a programmer has to ensure that IP multicast is enabled across subnets. It is often the case that IP multicast is not enabled across subnets. Refer to section Section 2.8, “It doesn't work !” for running a test program that determines whether members can reach each other via IP multicast. If this does not work, the protocol stack cannot use UDP with IP multicast as transport. In this case, the stack has to either use UDP without IP multicasting or other transports such as TCP.
The protocol stack with UDP and PING as the bottom protocols use IP multicasting by default to send messages to all members (UDP) and for discovery of the initial members (PING). However, if multicasting cannot be used, the UDP and PING protocols can be configured to send multiple unicast messages instead of one multicast message [6] (UDP) and to access a well-known server ( GossipRouter ) for initial membership information (PING).
To configure UDP to use multiple unicast messages to send a group message instead of using IP multicasting, the ip_mcast property has to be set to false .
To configure PING to access a GossipRouter instead of using IP multicast the following properties have to be set:
- gossip_host
The name of the host on which GossipRouter is started
- gossip_port
The port on which GossipRouter is listening
- gossip_refresh
The number of milliseconds to wait until refreshing our address entry with the GossipRouter
Before any members are started the GossipRouter has to be started, e.g.
java org.jgroups.stack.GossipRouter -port 5555 -bindaddress localhost
This starts the GossipRouter on the local host on port 5555. The GossipRouter is essentially a lookup service for groups and members. It is a process that runs on a well-known host and port and accepts GET(group) and REGISTER(group, member) requests. The REGISTER request registers a member's address and group with the GossipRouter. The GET request retrieves all member addresses given a group name. Each member has to periodically ( gossip_refresh ) re-register their address with the GossipRouter, otherwise the entry for that member will be removed (accommodating for crashed members).
The following example shows how to disable the use of IP multicasting and use a GossipRouter instead. Only the bottom two protocols are shown, the rest of the stack is the same as in the previous example:
<UDP ip_mcast="false" mcast_addr="224.0.0.35" mcast_port="45566" ip_ttl="32"
mcast_send_buf_size="150000" mcast_recv_buf_size="80000"/>
<PING gossip_host="localhost" gossip_port="5555" gossip_refresh="15000"
timeout="2000" num_initial_members="3"/>
The property ip_mcast is set to false in UDP and the gossip properties in PING define the GossipRouter to be on the local host at port 5555 with a refresh rate of 15 seconds. If PING is parameterized with the GossipRouter's address and port, then gossiping is enabled, otherwise it is disabled. If only one parameter is given, gossiping will be disabled .
Make sure to run the GossipRouter before starting any members, otherwise the members will not find each other and each member will form its own group [7] .
TCP is a replacement of UDP as bottom layer in cases where IP Multicast based on UDP is not desired. This may be the case when operating over a WAN, where routers will discard IP MCAST. As a rule of thumb UDP is used as transport for LANs, whereas TCP is used for WANs.
The properties for a typical stack based on TCP might look like this (edited/protocols removed for brevity):
<TCP start_port="7800" />
<TCPPING timeout="3000"
initial_hosts="${jgroups.tcpping.initial_hosts:localhost[7800],localhost[7801]}"
port_range="1"
num_initial_members="3"/>
<VERIFY_SUSPECT timeout="1500" />
<pbcast.NAKACK
use_mcast_xmit="false" gc_lag="0"
retransmit_timeout="300,600,1200,2400,4800"
discard_delivered_msgs="true"/>
<pbcast.STABLE stability_delay="1000" desired_avg_gossip="50000"
max_bytes="400000"/>
<pbcast.GMS print_local_addr="true" join_timeout="3000"
shun="true"
view_bundling="true"/>
- TCP
The transport protocol, uses TCP (from TCP/IP) to send unicast and multicast messages. In the latter case, it sends multiple unicast messages.
- TCPPING
Discovers the initial membership to determine coordinator. Join request will then be sent to coordinator.
- VERIFY_SUSPECT
Double checks that a suspected member is really dead
- pbcast.NAKACK
Reliable and FIFO message delivery
- pbcast.STABLE
Distributed garbage collection of messages seen by all members
- pbcast.GMS
Membership services. Takes care of joining and removing new/old members, emits view changes
Since TCP already offers some of the reliability guarantees that UDP doesn't, some protocols (e.g. FRAG and UNICAST) are not needed on top of TCP.
When using TCP, each message to the group is sent as multiple unicast messages (one to each member). Due to the fact that IP multicasting cannot be used to discover the initial members, another mechanism has to be used to find the initial membership. There are a number of alternatives:
PING with GossipRouter: same solution as described in Section 5.4.1.2, “Using UDP without IP multicasting” . The ip_mcast property has to be set to false . GossipRouter has to be started before the first member is started.
TCPPING: uses a list of well-known group members that it solicits for initial membership
TCPGOSSIP: essentially the same as the above PING [8] . The only difference is that TCPGOSSIP allows for multiple GossipRouters instead of only one.
The next two section illustrate the use of TCP with both TCPPING and TCPGOSSIP.
A protocol stack using TCP and TCPPING looks like this (other protocols omitted):
<TCP start_port="7800" /> +
<TCPPING initial_hosts="HostA[7800],HostB[7800]" port_range="5"
timeout="3000" num_initial_members="3" />
The concept behind TCPPING is that no external daemon such as GossipRouter is needed. Instead some selected group members assume the role of well-known hosts from which initial membership information can be retrieved. In the example HostA and HostB are designated members that will be used by TCPPING to lookup the initial membership. The property start_port in TCP means that each member should try to assign port 7800 for itself. If this is not possible it will try the next higher port ( 7801 ) and so on, until it finds an unused port.
TCPPING will try to contact both HostA and HostB , starting at port 7800 and ending at port 7800 + port_range , in the above example ports 7800 - 7804 . Assuming that at least one of HostA or HostB is up, a response will be received. To be absolutely sure to receive a response all the hosts on which members of the group will be running can be added to the configuration string.
As mentioned before TCPGOSSIP is essentially the same as PING with properties gossip_host , gossip_port and gossip_refresh set. However, in TCPGOSSIP these properties are called differently as shown below (only the bottom two protocols are shown):
<TCP />
<TCPGOSSIP initial_hosts="localhost[5555],localhost[5556]" gossip_refresh_rate="10000"
num_initial_members="3" />
The initial_hosts properties combines both the host and port of a GossipRouter, and it is possible to specify more than one GossipRouter. In the example there are two GossipRouters at ports 5555 and 5556 on the local host. Also, gossip_refresh_rate defines how many milliseconds to wait between refreshing the entry with the GossipRouters.
The advantage of having multiple GossipRouters is that, as long as at least one is running, new members will always be able to retrieve the initial membership. Note that the GossipRouter should be started before any of the members.
Firewalls are usually placed at the connection to the internet. They shield local networks from outside attacks by screening incoming traffic and rejecting connection attempts to host inside the firewalls by outside machines. Most firewall systems allow hosts inside the firewall to connect to hosts outside it (outgoing traffic), however, incoming traffic is most often disabled entirely.
Tunnels are host protocols which encapsulate other protocols by multiplexing them at one end and demultiplexing them at the other end. Any protocol can be tunneled by a tunnel protocol.
The most restrictive setups of firewalls usually disable all incoming traffic, and only enable a few selected ports for outgoing traffic. In the solution below, it is assumed that one TCP port is enabled for outgoing connections to the GossipRouter.
JGroups has a mechanism that allows a programmer to tunnel a firewall. The solution involves a GossipRouter, which has to be outside of the firewall, so other members (possibly also behind firewalls) can access it.
The solution works as follows. A channel inside a firewall has to use protocol TUNNEL instead of UDP as bottommost layer in the stack, plus either PING or TCPGOSSIP, as shown below (only the bottom two protocols shown):
<TUNNEL router_host="localhost" router_port="12001" />
<TCPGOSSIP initial_hosts="localhost[12001]" gossip_refresh_rate="10000"
num_initial_members="3" />
TCPGOSSIP uses the GossipRouter (outside the firewall) at port 12001 to register its address (periodically) and to retrieve the initial membership for its group.
TUNNEL establishes a TCP connection to the GossipRouter process (also outside the firewall) that accepts messages from members and passes them on to other members. This connection is initiated by the host inside the firewall and persists as long as the channel is connected to a group. GossipRouter will use the same connection to send incoming messages to the channel that initiated the connection. This is perfectly legal, as TCP connections are fully duplex. Note that, if GossipRouter tried to establish its own TCP connection to the channel behind the firewall, it would fail. But it is okay to reuse the existing TCP connection, established by the channel.
Note that TUNNEL has to be given the hostname and port of the GossipRouter process. This example assumes a GossipRouter is running on the local host at port 12001. Both TUNNEL and TCPGOSSIP (or PING) access the same GossipRouter.
Any time a message has to be sent, TUNNEL forwards the message to GossipRouter, which distributes it to its destination: if the message's destination field is null (send to all group members), then GossipRouter looks up the members that belong to that group and forwards the message to all of them via the TCP connection they established when connecting to GossipRouter. If the destination is a valid member address, then that member's TCP connection is looked up, and the message is forwarded to it [9] .
To tunnel a firewall using JGroups, the following steps have to be taken:
Check that a TCP port (e.g. 12001) is enabled in the firewall for outgoing traffic
Start the GossipRouter:
start org.jgroups.stack.GossipRouter -port 12001Configure the TUNNEL protocol layer as instructed above.
Create a channel
The general setup is shown in Figure 5.2, “Tunneling a firewall” .
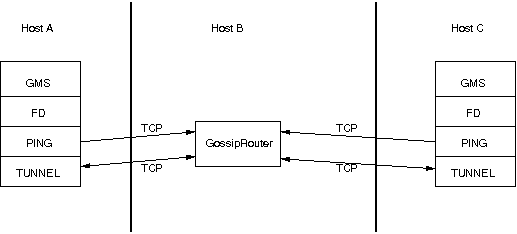
First, the GossipRouter process is created on host B. Note that host B should be outside the firewall, and all channels in the same group should use the same GossipRouter process. When a channel on host A is created, its TCPGOSSIP protocol will register its address with the GossipRouter and retrieve the initial membership (assume this is C). Now, a TCP connection with the GossipRouter is established by A; this will persist until A crashes or voluntarily leaves the group. When A multicasts a message to the group, GossipRouter looks up all group members (in this case, A and C) and forwards the message to all members, using their TCP connections. In the example, A would receive its own copy of the multicast message it sent, and another copy would be sent to C.
This scheme allows for example Java applets , which are only allowed to connect back to the host from which they were downloaded, to use JGroups: the HTTP server would be located on host B and the gossip and GossipRouter daemon would also run on that host. An applet downloaded to either A or C would be allowed to make a TCP connection to B. Also, applications behind a firewall would be able to talk to each other, joining a group.
However, there are several drawbacks: first, the central GossipRouter process constitute a single point of failure (if host B crashes) [10] , second, having to maintain a TCP connection for the duration of the connection might use up resources in the host system (e.g. in the GossipRouter), leading to scalability problems, third, this scheme is inappropriate when only a few channels are located behind firewalls, and the vast majority can indeed use IP multicast to communicate, and finally, it is not always possible to enable outgoing traffic on 2 ports in a firewall, e.g. when a user does not 'own' the firewall.
Note
There will be a major overhaul of GossipRouter/TUNNEL in 2.6, where we'll streamline the connection table and possibly introduce new functionality such as connecting to multiple GossipRouters, connecting to both IP multicasting and TCP based clients etc.The concurrent stack (introduced in 2.5) provides a number of improvements over previous releases, which has some deficiencies:
- Large number of threads: each protocol had by default 2 threads, one for the up and one for the down queue. They could be disabled per protocol by setting up_thread or down_thread to false. In the new model, these threads have been removed.
- Sequential delivery of messages: JGroups used to have a single queue for incoming messages, processed by one thread. Therefore, messages from different senders were still processed in FIFO order. In 2.5 these messages can be processed in parallel.
- Out-of-band messages: when an application doesn't care about the ordering properties of a message, the OOB flag can be set and JGroups will deliver this particular message without regard for any ordering.
The architecture of the concurrent stack is shown in Figure 5.3, “The concurrent stack”. The changes were made entirely inside of the transport protocol (TP, with subclasses UDP, TCP and TCP_NIO). Therefore, to configure the concurrent stack, the user has to modify the config for (e.g.) UDP in the XML file.
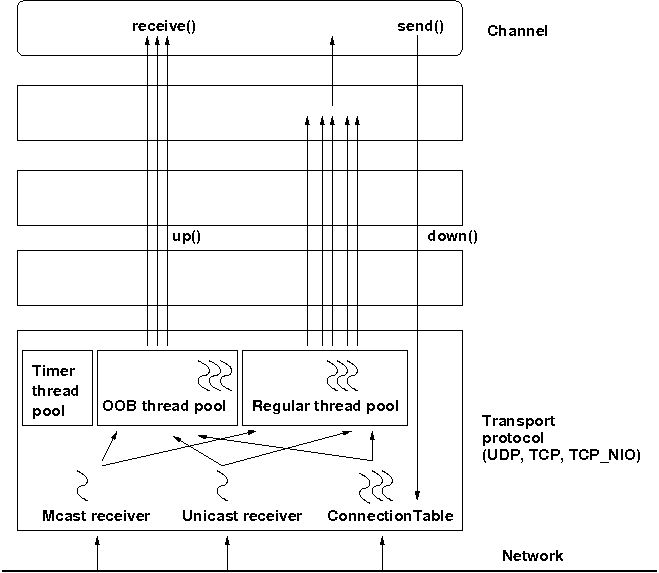
The concurrent stack consists of 2 thread pools (java.util.concurrent.Executor): the out-of-band (OOB) thread pool and the regular thread pool. Packets are received by multicast or unicast receiver threads (UDP) or a ConnectionTable (TCP, TCP_NIO). Packets marked as OOB (with Message.setFlag(Message.OOB)) are dispatched to the OOB thread pool, and all other packets are dispatched to the regular thread pool.
When a thread pool is disabled, then we use the thread of the caller (e.g. multicast or unicast receiver threads or the ConnectionTable) to send the message up the stack and into the application. Otherwise, the packet will be processed by a thread from the thread pool, which sends the message up the stack. When all current threads are busy, another thread might be created, up to the maximum number of threads defined. Alternatively, the packet might get queued up until a thread becomes available.
The point of using a thread pool is that the receiver threads should only receive the packets and forward them to the thread pools for processing, because unmarshalling and processing is slower than simply receiving the message and can benefit from parallelization.
Note that this is preliminary and names or properties might change
We are thinking of exposing the thread pools programmatically, meaning that a developer might be able to set both threads pools programmatically, e.g. using something like TP.setOOBThreadPool(Executor executor).
Here's an example of the new configuration:
<UDP
mcast_addr="228.10.10.10"
mcast_port="45588"
use_concurrent_stack="true"
thread_pool.enabled="true"
thread_pool.min_threads="1"
thread_pool.max_threads="100"
thread_pool.keep_alive_time="20000"
thread_pool.queue_enabled="false"
thread_pool.queue_max_size="10"
thread_pool.rejection_policy="Run"
oob_thread_pool.enabled="true"
oob_thread_pool.min_threads="1"
oob_thread_pool.max_threads="4"
oob_thread_pool.keep_alive_time="30000"
oob_thread_pool.queue_enabled="true"
oob_thread_pool.queue_max_size="10"
oob_thread_pool.rejection_policy="Run"/>
The concurrent stack can be completely eliminated by setting use_concurrent_stack to false. (Note that this attribute might be removed in a future release).
The attributes for the 2 thread pools are prefixed with thread_pool and oob_thread_pool respectively.
The attributes are listed below. The roughly correspond to the options of a java.util.concurrent.ThreadPoolExecutor in JDK 5.
Table 5.1. Attributes of thread pools
| Name | Description |
|---|---|
| enabled | Whether of not to use a thread pool. If set to false, the caller's thread is used. |
| min_threads | The minimum number of threads to use. |
| max_threads | The maximum number of threads to use. |
| keep_alive_time | Number of milliseconds until an idle thread is removed from the pool |
| queue_enabled | Whether of not to use a (bounded) queue. If enabled, when all minimum threads are busy, work items are added to the queue. When the queue is full, additional threads are created, up to max_threads. When max_threads have been reached, the rejection policy is consulted. |
| max_size | The maximum number of elements in the queue. Ignored if the queue is disabled |
| rejection_policy | Determines what happens when the thread pool (and queue, if enabled) is full. The default is to run on the caller's thread. "Abort" throws an runtime exception. "Discard" discards the message, "DiscardOldest" discards the oldest entry in the queue. Note that these values might change, for example a "Wait" value might get added in the future. |
| thread_naming_pattern | Determines how threads are named that are running from thread pools in concurrent stack. Valid values include any combination of "cl" letters, where "c" includes the cluster name and "l" includes local address of the channel. The default is "cl" |
By removing the 2 queues/protocol and the associated 2 threads, we effectively reduce the number of threads needed to handle a message, and thus context switching overhead. We also get clear and unambiguous semantics for Channel.send(): now, all messages are sent down the stack on the caller's thread and the send() call only returns once the message has been put on the network. In addition, an exception will only be propagated back to the caller if the message has not yet been placed in a retransmit buffer. Otherwise, JGroups simply logs the error message but keeps retransmitting the message. Therefore, if the caller gets an exception, the message should be re-sent.
On the receiving side, a message is handled by a thread pool, either the regular or OOB thread pool. Both thread pools can be completely eliminated, so that we can save even more threads and thus further reduce context switching. The point is that the developer is now able to control the threading behavior almost completely.
Up to version 2.5, all messages received were processed by a single thread, even if the messages were sent by different senders. For instance, if sender A sent messages 1,2 and 3, and B sent message 34 and 45, and if A's messages were all received first, then B's messages 34 and 35 could only be processed after messages 1-3 from A were processed !
Now, we can process messages from different senders in parallel, e.g. messages 1, 2 and 3 from A can be processed by one thread from the thread pool and messages 34 and 35 from B can be processed on a different thread.
As a result, we get a speedup of almost N for a cluster of N if every node is sending messages and we configure the thread pool to have at least N threads. There is actually a unit test (ConcurrentStackTest.java) which demonstrates this.
OOB messages completely ignore any ordering constraints the stack might have. Any message marked as OOB will be processed by the OOB thread pool. This is necessary in cases where we don't want the message processing to wait until all other messages from the same sender have been processed, e.g. in the heartbeat case: if sender P sends 5 messages and then a response to a heartbeat request received from some other node, then the time taken to process P's 5 messages might take longer than the heartbeat timeout, so that P might get falsely suspected ! However, if the heartbeat response is marked as OOB, then it will get processed by the OOB thread pool and therefore might be concurrent to its previously sent 5 messages and not trigger a false suspicion.
The 2 unit tests UNICAST_OOB_Test and NAKACK_OOB_Test demonstrate how OOB messages influence the ordering, for both unicast and multicast messages.
In 2.7, there are 3 thread pools and 4 thread factories in TP:
Table 5.2. Thread pools and factories in TP
| Name | Description |
|---|---|
| Default thread pool | This is the pools for handling incoming messages. It can be fetched using getDefaultThreadPool() and replaced using setDefaultThreadPool(). When setting a thread pool, the old thread pool (if any) will be shutdown and all of it tasks cancelled first |
| OOB thread pool | This is the pool for handling incoming OOB messages. Methods to get and set it are getOOBThreadPool() and setOOBThreadPool() |
| Timer thread pool | This is the thread pool for the timer. The max number of threads is set through the timer.num_threads property. The timer thread pool cannot be set, it can only be retrieved using getTimer(). However, the thread factory of the timer can be replaced (see below) |
| Default thread factory | This is the thread factory (org.jgroups.util.ThreadFactory) of the default thread pool, which handles incoming messages. A thread pool factory is used to name threads and possibly make them daemons. It can be accessed using getDefaultThreadPoolThreadFactory() and setDefaultThreadPoolThreadFactory() |
| OOB thread factory | This is the thread factory for the OOB thread pool. It can be retrieved using getOOBThreadPoolThreadFactory() and set using method setOOBThreadPoolThreadFactory() |
| Timer thread factory | This is the thread factory for the timer thread pool. It can be accessed using getTimerThreadFactory() and setTimerThreadFactory() |
| Global thread factory | The global thread factory can get used (e.g. by protocols) to create threads which don't live in the transport, e.g. the FD_SOCK server socket handler thread. Each protocol has a method getTransport(). Once the TP is obtained, getThreadFactory() can be called to get the global thread factory. The global thread factory can be replaced with setThreadFactory() |
In 2.7, the default and OOB thread pools can be shared between instances running inside the same JVM. The advantage here is that multiple channels running within the same JVM can pool (and therefore save) threads. The disadvantage is that thread naming will not show to which channel instance an incoming thread belongs to.
Note that we can not just shared thread pools between JChannels within the same JVM, but we can also share entire transports. For details see Section 5.3, “Sharing a transport between multiple channels in a JVM”.
channel.setOpt(Channel.AUTO_RECONNECT, Boolean.TRUE);
To enable shunning, set FD.shun and GMS.shun to true.
Let's look at a more detailed example. Say member D is overloaded, and doesn't respond to are-you-alive messages (done by the failure detection (FD) protocol). It is therefore suspected and excluded. The new view for A, B and C will be {A,B,C}, however for D the view is still {A,B,C,D}. So when D comes back and sends messages to the group, or any individiual member, those messages will be discarded, because A,B and C don't see D in their view. D is shunned when A,B or C receive an are-you-alive message from D, or D shuns itself when it receives a view which doesn't include D. So shunning is always a unilateral decision. However, things may be different if all members exclude each other from the group. For example, say we have a switch connecting A, B, C and D. If someone pulls all plugs on the switch, or powers the switch down, then A, B, C and D will all form singleton groups, that is, each member thinks it's the only member in the group. When the switch goes back to normal, then each member will shun everybody else (a real shun fest :-)). This is clearly not desirable, so in this case shunning should be turned off:
<FD timeout="2000" max_tries="3" shun="false"/> ... <pbcast.GMS join_timeout="3000" shun="false"/>
Network partitions can be caused by switch, router or network interface crashes, among other things. If we have a cluster {A,B,C,D,E} spread across 2 subnets {A,B,C} and {D,E} and the switch to which D and E are connected crashes, then we end up with a network partition, with subclusters {A,B,C} and {D,E}.
A, B and C can ping each other, but not D or E, and vice versa. We now have 2 coordinators, A and D. Both subclusters operate independently, for example, if we maintain a shared state, subcluster {A,B,C} replicate changes to A, B and C.
This means, that if during the partition, some clients access {A,B,C}, and others {D,E}, then we end up with different states in both subclusters. When a partition heals, the merge protocol (e.g. MERGE2) will notify A and D that there were 2 subclusters and merge them back into {A,B,C,D,E}, with A being the new coordinator and D ceasing to be coordinator.
The question is what happens with the 2 diverged substates ?
There are 2 solutions to merging substates: first we can attempt to create a new state from the 2 substates, and secondly we can shut down all members of the non primary partition, such that they have to re-join and possibly reacquire the state from a member in the primary partition.
In both cases, the application has to handle a MergeView (subclass of View), as shown in the code below:
public void viewAccepted(View view) {
if(view instanceof MergeView) {
MergeView tmp=(MergeView)view;
Vector<View> subgroups=tmp.getSubgroups();
// merge state or determine primary partition
// run this in a separate thread !
}
}
It is essential that the merge view handling code run on a separate thread if it needs more than a few milliseconds, or else it would block the calling thread.
The MergeView contains a list of views, each view represents a subgroups and has the list of members which formed this group.
The application has to merge the substates from the various subgroups ({A,B,C} and {D,E}) back into one single state for {A,B,C,D,E}. This task has to be done by the application because JGroups knows nothing about the application state, other than it is a byte buffer.
If the in-memory state is backed by a database, then the solution is easy: simply discard the in-memory state and fetch it (eagerly or lazily) from the DB again. This of course assumes that the members of the 2 subgroups were able to write their changes to the DB. However, this is often not the case, as connectivity to the DB might have been severed by the network partition.
Another solution could involve tagging the state with time stamps. On merging, we could compare the time stamps for the substates and let the substate with the more recent time stamps win.
Yet another solution could increase a counter for a state each time the state has been modified. The state with the highest counter wins.
Again, the merging of state can only be done by the application. Whatever algorithm is picked to merge state, it has to be deterministic.
The primary partition approach is simple: on merging, one subgroup is designated as the primary partition and all others as non-primary partitions. The members in the primary partition don't do anything, whereas the members in the non-primary partitions need to drop their state and re-initialize their state from fresh state obtained from a member of the primary partition.
The code to find the primary partition needs to be deterministic, so that all members pick the same primary partition. This could be for example the first view in the MergeView, or we could sort all members of the new MergeView and pick the subgroup which contained the new coordinator (the one from the consolidated MergeView). Another possible solution could be to pick the largest subgroup, and, if there is a tie, sort the tied views lexicographically (all Addresses have a compareTo() method) and pick the subgroup with the lowest ranked member.
Here's code which picks as primary partition the first view in the MergeView, then re-acquires the state from the new coordinator of the combined view:
public static void main(String[] args) throws Exception {
final JChannel ch=new JChannel("/home/bela/udp.xml");
ch.setReceiver(new ExtendedReceiverAdapter() {
public void viewAccepted(View new_view) {
handleView(ch, new_view);
}
});
ch.connect("x");
while(ch.isConnected())
Util.sleep(5000);
}
private static void handleView(JChannel ch, View new_view) {
if(new_view instanceof MergeView) {
ViewHandler handler=new ViewHandler(ch, (MergeView)new_view);
handler.start(); // requires separate thread as we don't want to block JGroups
}
}
private static class ViewHandler extends Thread {
JChannel ch;
MergeView view;
private ViewHandler(JChannel ch, MergeView view) {
this.ch=ch;
this.view=view;
}
public void run() {
Vector<View> subgroups=view.getSubgroups();
View tmp_view=subgroups.firstElement(); // picks the first
Address local_addr=ch.getLocalAddress();
if(!tmp_view.getMembers().contains(local_addr)) {
System.out.println("I (" + local_addr + ") am not member of the new primary partition (" + tmp_view +
"), will re-acquire the state");
try {
ch.getState(null, 30000);
}
catch(Exception ex) {
}
}
else {
System.out.println("I (" + local_addr + ") am member of the new primary partition (" + tmp_view +
"), will do nothing");
}
}
}
The handleView() method is called from viewAccepted(), which is called whenever there is a new view. It spawns a new thread which gets the subgroups from the MergeView, and picks the first subgroup to be the primary partition. Then, if it was a member of the primary partition, it does nothing, and if not, it reaqcuires the state from the coordinator of the primary partition (A).
The downside to the primary partition approach is that work (= state changes) on the non-primary partition is discarded on merging. However, that's only problematic if the data was purely in-memory data, and not backed by persistent storage. If the latter's the case, use state merging discussed above.
It would be simpler to shut down the non-primary partition as soon as the network partition is detected, but that a non trivial problem, as we don't know whether {D,E} simply crashed, or whether they're still alive, but were partitioned away by the crash of a switch. This is called a split brain syndrome, and means that none of the members has enough information to determine whether it is in the primary or non-primary partition, by simply exchanging messages.
In certain situations, we can avoid having multiple subgroups where every subgroup is able to make progress, and on merging having to discard state of the non-primary partitions.
If we have a fixed membership, e.g. the cluster always consists of 5 nodes, then we can run code on a view reception that determines the primary partition. This code
- assumes that the primary partition has to have at least 3 nodes
- any cluster which has less than 3 nodes doesn't accept modfications. This could be done for shared state for example, by simply making the {D,E} partition read-only. Clients can access the {D,E} partition and read state, but not modify it.
- As an alternative, clusters without at least 3 members could shut down, so in this case D and E would leave the cluster.
The algorithm is shown in pseudo code below:
On initialization:
- Mark the node as read-only
On view change V:
- If V has >= N members:
- If not read-write: get state from coordinator and switch to read-write
- Else: switch to read-only
Of course, the above mechanism requires that at least 3 nodes are up at any given time, so upgrades have to be done in a staggered way, taking only one node down at a time. In the worst case, however, this mechanism leaves the cluster read-only and notifies a system admin, who can fix the issue. This is still better than shutting the entire cluster down.
To change this, we can turn on virtual synchrony (by adding FLUSH to the top of the stack), which guarantees that
- A message M sent in V1 will be delivered in V1. So, in the example above, M1 would get delivered in view V1; by A, B and C, but not by D.
- The set of messages seen by members in V1 is the same for all members before a new view V2 is installed. This is important, as it ensures that all members in a given view see the same messages. For example, in a group {A,B,C}, C sends 5 messages. A receives all 5 messages, but B doesn't. Now C crashes before it can retransmit the messages to B. FLUSH will now ensure, that before installing V2={A,B} (excluding C), B gets C's 5 messages. This is done through the flush protocol, which has all members reconcile their messages before a new view is installed. In this case, A will send C's 5 messages to B.
Sometimes it is important to know that every node in the cluster received all messages up to a certain point, even if there is no new view being installed. To do this (initiate a manual flush), an application programmer can call Channel.startFlush() to start a flush and Channel.stopFlush() to terminate it.
Channel.startFlush() flushes all pending messages out of the system. This stops all senders (calling Channel.down() during a flush will block until the flush has completed)[11]. When startFlush() returns, the caller knows that (a) no messages will get sent anymore until stopFlush() is called and (b) all members have received all messages sent before startFlush() was called.
Channel.stopFlush() terminates the flush protocol, no blocked senders can resume sending messages.
Note that the FLUSH protocol has to be present on top of the stack, or else the flush will fail.
[6] Although not as efficient (and using more bandwidth), it is sometimes the only possibility to reach group members.
[7] This can actually be used to test the MERGE2 protocol: start two members (forming two singleton groups because they don't find each other), then start the GossipRouter. After some time, the two members will merge into one group
[8] PING and TCPGOSSIP will be merged in the future.
[9] To do so, GossipRouter has to maintain a table between groups, member addresses and TCP connections.
[10] Although multiple GossipRouters could be started
[11] Note that block() will be called in a Receiver when the flush is about to start and unblock() will be called when it ends