In this chapter, we take a pragmatic look at developing applications in Scala. We discuss a few language and API features that we haven’t covered before, examine common design patterns and idioms, and revisit traits with an eye towards structuring our code effectively.
Like Java and .NET, Scala supports annotations for adding metadata to declarations. Annotations are used by a variety of tools in typical enterprise and Internet applications. For example, there are annotations that provide directives to the compiler and some Object-Relational Mapping (ORM) frameworks use annotations on types and type members to indicate persistence mapping information. While some uses for annotations in the Java and .NET worlds can be accomplished through other means in Scala, annotations can be essential for interoperating with Java and .NET libraries that rely heavily on them. Fortunately, Java and .NET annotations can be used in Scala code.
The interpretation of Scala annotations depends on the runtime environment. In this section, we will focus on the JDK environment.
In Java, annotations are declared using special conventions, e.g.,
declaring annotations with the @interface keyword instead of the
class or interface keyword. Here is the declaration of an
annotation taken from a toolkit called Contract4J [Contract4J] that
uses annotations to support design by contract programming in Java
(see also the section called “Better Design with Design By Contract” below). Some of the comments
have been removed for clarity.
// code-examples/AppDesign/annotations/Pre.java
package org.contract4j5.contract;
import java.lang.annotation.Documented;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.PARAMETER, ElementType.METHOD, ElementType.CONSTRUCTOR})
public @interface Pre {
/**
* The "value" is the test expression, which must evaluate to true or false.
* It must be a valid expression in the scripting language you are using.
*/
String value() default "";
/**
* An optional message to print with the standard message when the contract
* fails.
*/
String message() default "";
}The @Pre annotation is used to specify “preconditions” that must
be satisfied when entering a method or constructor, or before
using a parameter passed to a method or constructor. The conditions
are specified as a string that is actually a snippet of source code
that evaluates to true or false. The source languages supported
for these snippets are scripting languages like Groovy and JRuby. The
name of the variable for this string, value, is a conventional
name for the most important field in the annotation.
The other field is an optional message to use when reporting
failures.
The declaration has other annotations applied to it, for example the
@Retention annotation with the value RetentionPolicy.RUNTIME means
that when @Pre is used, its information will be retained in the
class file for runtime use.
Here is a Scala example that uses @Pre and shows several ways to
specify the value and message parameters.
// code-examples/AppDesign/annotations/pre-example.scala
import org.contract4j5.contract._
class Person(
@Pre( "name != null && name.length() > 0" )
val name: String,
@Pre{ val value = "age > 0", val message = "You're too young!" }
val age: Int,
@Pre( "ssn != null" )
val ssn: SSN)
class SSN(
@Pre( "valid(ssn)" ) { val message = "Format must be NNN-NN-NNNN." }
val ssn: String) {
private def valid(value: String) =
value.matches("""^\s*\d{3}-\d{2}-\d{4}\s*$""")
}In the Person class, the @Pre annotation on name has a simple
string argument: the “precondition” that users must satisfy when
passing in a name. This value can’t be null and it can’t be of zero length.
As in Java, if a single argument is given to the annotation, it is assigned to the value
field.
A similar @Pre annotation is used for the third argument, the ssn
(social security number). In both cases, the message defaults to the
empty string specified in the definition of Pre.
The @Pre annotation for the age shows one way to specify values for
more than one field. Instead of parentheses, “curly” braces are
used. The syntax for each field looks like a val declaration,
without any type information, since the types can always be inferred!
This syntax allows you to use the shorthand syntax for the value and
still specify values for other fields.
if Person were a Java class, this annotation expression
would look identical, except there would be no val keywords and
parentheses would be used.
The @Pre annotation on the constructor parameter for the SSN class
shows the alternative syntax for specifying values for more than one
field. The value field is specified as before with a one-element
parameter list. The message is initialized in a follow-on block in
curly braces.
Testing this code would require the Contract4J library, build setup, etc. We won’t cover those steps here. Refer to [Contract4J] for more information.
Scala annotations don’t use a special declaration syntax. They are
declared as normal classes. This approach eliminates a “special
case” in the language, but it also means that some of the features
provided by Java annotations aren’t supported, as we will see. Here is
an example annotation from the Scala library, SerialVersionUID
(again with the comments removed for clarity).
package scala class SerialVersionUID(uid: Long) extends StaticAnnotation
The @SerialVersionUID annotation is applied to a class to define a
globally-unique ID as a Long. When the annotation is used, the ID is
specified as a constructor argument. This annotation serves the same
purpose as a static field named serialVersionUID in a Java class.
This is one example of a Scala annotation that maps to a
“non-annotation” construct in Java.
The parent of SerialVersionUID is the trait
scala.StaticAnnotation, which is used as the parent for all
annotations that should be visible to the type checker, even across
compilation units. The parent class of scala.StaticAnnotation is
scala.Annotation, which is the parent of all Scala annotations.
Did you notice that there is no val on uid? Why isn’t uid a
field? The reason is that the annotation’s data is not intended for
use by the program. Recall that it is metadata designed for external
tools to use, such as scalac. This also means that Scala annotations
have no way to define default values in version 2.7.X, as implicit
arguments don’t work. However, the new default arguments feature
in version 2.8.0 may work. (It is not yet implemented at the time of this writing).
I don't know much about annotations but the scala compiler doesn't seem to product and error if val is used with annotation:
scala> class Bar(val x: Long) extends StaticAnnotation
defined class Bar
So is "val" silently ignored? Maybe it can be clarified.
Like Java (and .NET) annotations, a Scala annotation clause applies to the definition it precedes. You can have as many annotation clauses as you want and the order in which they appear is not significant.
Like Java annotations, Scala annotation clauses are written using the
syntax @MyAnnotation, if the annotation constructor takes no
parameters, or @MyAnnotation(arg1, .., argN) if the constructor takes
parameters. The annotation must be a subclass of scala.Annotation.
All the constructor parameters must be constant expressions, including strings, class literals, Java enumerations, numerical expressions and one-dimensional arrays of the same. However, the compiler also allows annotation clauses with other arguments, such as boolean values and maps, as shown in this example.
There is some description on "Did you notice that there is no val on uid?" above while the example below uses vals for annotation. This is a little confusing.
Bug in the following example. Thanks.
I should add that the example compiles fine, but yes, having the keywords is not useful for the reasons discussed previously.
// code-examples/AppDesign/annotations/anno-example.scala
import scala.StaticAnnotation
class Persist(tableName: String, params: Map[String,Any])
extends StaticAnnotation
// Doesn't compile:
//@Persist("ACCOUNTS", Map("dbms" -> "MySql", "writeAutomatically" -> true))
@Persist("ACCOUNTS", Map(("dbms", "MySql"), ("writeAutomatically", true)))
class Account(val balance: Double)Curiously, if you attempt to use the standard Map literal syntax
that is shown in the comments, you get a compilation error that the
-> method doesn’t exist for String. The implicit
conversion to ArrowAssoc that we discussed in the section called “The Predef Object” in
Chapter 7, The Scala Object System isn’t invoked. Instead, you have to
use a list of Tuples, which Map.apply actually expects.
Another child of scala.Annotation that is intended to be a parent of
other annotations is the trait scala.ClassfileAnnotation. It is
supposed to be used for annotations that should have runtime
retention, i.e., the annotations should be visible in the class file
so they are available at runtime. However, actually using it with the
JDK version of Scala results in compiler errors like the following.
...: warning: implementation restriction: subclassing Classfile does not make your annotation visible at runtime. If that is what you want, you must write the annotation class in Java. ...
Hence, if you want runtime visibility, you have to implement the
annotation in Java. This works fine, since you can use any Java
annotation in Scala code. The Scala library currently defines no
annotations derived from ClassfileAnnotation, perhaps for obvious
reasons.
Avoid ClassfileAnnotation. Implement annotations that
require runtime retention in Java instead.
For Scala version 2.7.X, another important limitation to keep in mind is that annotations can’t be nested. This causes problems when using JPA annotations in Scala code, for example, as discussed in [JPAScala]. However, Scala version 2.8 removes this limitation.
Annotations can only be nested in Scala version 2.8.
The following tables describe all the annotations defined in the Scala
library (adapted and expanded from
http://www.scala-lang.org/node/106). We start with the direct children
of Annotation, followed by the children of StaticAnnotation.
Table 13.1. Scala annotations derived from Annotation.
| Name | Java Equivalent | Description |
|---|---|---|
| Annotate with | The parent trait for annotations that should be retained in the class file for runtime access, but it doesn’t actually work on the JDK! |
|
| An annotation for JavaBean types or members that associates a short description (provided as the annotation argument) that will be included when generating bean information. |
|
| An annotation for JavaBean types or members that associates a name (provided as the annotation argument) that will be included when generating bean information. |
|
| A marker that indicates that a |
| N.A. | A marker that indicates that bean information should not be generated for the annotated member. |
| Static fields, | The parent trait of annotations that should be visible across compilation units and define “static” metadata. |
| N.A. | An annotation trait that can be applied to other annotations that define constraints on a type, relying only on information defined within the type itself, as opposed to external context information where the type is defined or used. The compiler can exploit this restriction to rewrite the constraint. There are currently no library annotations that use this trait. |
| N.A. | A marker annotation for the selector in a match statement (e.g., the |
| N.A. | Deprecated, use |
Table 13.2. Scala annotations derived from StaticAnnotation.
| Name | Java Equivalent | Description |
|---|---|---|
| JavaBean convention | A marker for a field (including a constructor argument with the |
|
| A class marker indicating that a class can be cloned. |
| N.A. | (version 2.8) Generate byte code using continuation passing style. |
|
| A marker for any definition indicating that the defined “item” is obsolete. The compiler will issue a warning when the item is used. |
| N.A. | A method marker telling the compiler that it should try “especially hard” to inline the method. |
|
| A method marker indicating the method is implemented as “native” code. The method body will not be generated by the compiler, but usage of the method will be type checked. |
| N.A. | A method marker that prevents the compiler from inlining the method, even when it appears to be safe to do so. |
|
| A class marker indicating that the class can be invoked from a remote JVM. |
|
| A class marker indicating that the class can be serialized. |
|
| Defines a globally-unique ID for serialization purposes. The annotation’s constructor takes a |
| N.A. | (version 2.8) An annotation to be applied to a match expression, e.g., |
| N.A. | (version 2.8) An annotation applied to type parameters in parameterized types and methods. It tells the compiler to generate optimized versions of the type or method for the |
| N.A. | (version 2.8) A method annotation that tells the compiler to verify that the method will be compiled with tail call optimization. If it is present, the compiler will issue an error if the method cannot be optimized into a loop. This happens for example, when the method is not |
|
| Indicates which exceptions are thrown by the annotated method. See the discussion below. |
|
| Marks a method as “transient”. |
| N.A. | A marker for a value that is assumed to be stable even though its type is volatile (i.e., annotated with |
| N.A. | A marker for a type argument that is volatile, when it is used in a parameterized type, to suppress variance checking. |
|
| A marker for an individual field or a whole type, which affects all fields, indicating that the field may be modified by a separate thread. |
The annotations marked with “(version 2.8)” are only available in Scala version 2.8 or later. Consider @tailrec, as used in the following example.
import scala.annotation.tailrec
@tailrec
def fib(i: Int): Int = i match {
case _ if i <= 1 => i
case _ => fib(i-1) + fib(i-2)
}
println(fib(5))Note that fib, which calculates Fibonacci numbers, is recursive, but it isn’t tail-call recursive, because the call to itself is not the very last thing that happens in the second case clause. Rather, after calling itself twice, it does an addition. Hence, a tail-call optimization can’t be performed on this method. When the compiler sees the @tailrec annotation, it throws an error if it can’t apply the tail-call optimization. Attempting to run this script produces the following error.
... 4: error: could not optimize @tailrec annotated method
def fib(i: Int): Int = i match {
^
one error foundWe can also use the same method to demonstrate the new @switch annotation available in version 2.8.
import scala.annotation.switch
def fib(i: Int): Int = (i: @switch) match {
case _ if i <= 1 => i
case _ => fib(i-1) + fib(i-2)
}
println(fib(5))This time we annotate the i in the match statement. This annotation causes the compiler to raise an error if it can’t generate a switch construct in byte code from the cases in the match statement. Switches are generally more efficient than conditional logic. Running this script produces this output.
... 3: error: could not emit switch for @switch annotated match
def fib(i: Int): Int = (i: @switch) match {
^
one error foundConditional blocks have to be generated instead. The reason a switch can’t be generated is because of the condition guard clause we put in the first case clause, if i <= 1.
Let’s look at an example of @unchecked in use (adapted from the Scaladoc entry for @unchecked). Consider the following code fragement.
...
def process(x: Option[int]) = x match {
case Some(value) => ...
}
...If you compile it, you will get the following warning:
...: warning: does not cover case {object None}
def f(x: Option[int]) = x match {
^
one warning foundNormally, you would want to add a case for None. However, if you
want to suppress the warning message in situations like this, change
the method as follows.
...
def process(x: Option[int]) = (x: @unchecked) match {
case Some(value) => ...
}
...With the @unchecked annotation applied to x as shown, the warning
will be suppressed. However, if x is ever None, then a
MatchError will be thrown.
The @specialized annotation is another optimization-related annotation added in version 2.8. It is a pragmatic solution to a tradeoff between space efficiency and performance. In Java and Scala, the implementation of a parameterized type or method is generated at the point of the declaration (as we discussed in the section called “Understanding Parameterized Types” in Chapter 12, The Scala Type System). In contrast, in C++, a template is used to generate an implementation for the actual type parameters where the template is used. The C++ approach has the advantage of allowing optimized implementations to be generated for primitive types, while it has the disadvantage of resulting in code bloat from all the instantiations of templates.
The alternative would be to generate a separate implementation for every AnyVal corresponding to a primitive type, but this would lead to code bloat, especially since it would be rare that an application would use all those implementations. So, we are faced with a dilemma.
The @specialized annotation is a pragmatic compromise. It lets the user tell the compiler that runtime efficiency is more important than space efficiency, so the compiler will generate the separate implementations for each primitive corresponding to an AnyVal. Here is an example of how the annotation is used.
class SpecialCollection[@specialized +T](...) {
...
}At the time of this writing, the implementation in the version 2.8 “nightly” build only supports generation of specialized implementations for Int and Double. For the final version 2.8 library, it is planned that the other AnyVal types will be supported. There are also plans to allow the user to specify the types for which optimized implementations are generated, so that unused implementations for the other AnyVals are avoided. See the final 2.8 Scaladocs for details on the final feature set.
Another planned version 2.8 annotation is @cps, which stands for continuation passing style. It will be a directive interpreted by a compiler plugin that will trigger generation of continuation-based byte code for method invocation, rather than the default stack frame byte code. The annotation will have no effect unless the corresponding scalac plugin is used. Consult the release documentation for more information on this feature, when it becomes available.
To understand the @throws annotation, it’s important to remember
that Scala does not have checked exceptions, in contrast with Java.
There is also no throws clause available for Scala method
declarations. This is not a problem if a Scala method calls a Java
method that is declared to throw a checked exception. The exception is
treated as unchecked in Scala. However, suppose the Scala method in
question doesn’t catch the exception, but lets it pass through. What
if this Scala method is called by other Java code?
Let’s look at an example involving java.io.IOException, which is a
checked exception. The following Scala class prints out the contents
of a java.io.File.
// code-examples/AppDesign/annotations/file-printer.scala
import java.io._
class FilePrinter(val file: File) {
@throws(classOf[IOException])
def print() = {
var reader: LineNumberReader = null
try {
reader = new LineNumberReader(new FileReader(file))
loop(reader)
} finally {
if (reader != null)
reader.close
}
}
private def loop(reader: LineNumberReader): Unit = {
val line = reader.readLine()
if (line != null) {
format("%3d: %s\n", reader.getLineNumber, line)
loop(reader)
}
}
}Note the @throws annotation applied to the print method. The
argument to the annotation constructor is a single
java.lang.Class[Any] object, in this case, classOf[IOException].
The Java IO API methods used by print and the private method loop
might throw this exception.
I'd prefer to see a try/finally with a call reader.close(). Admittedly, it's beside the point of demonstrating @throws, but if this is a concern why show the file reading loop at all?
Good point. We want the code to be "good". I'll add the try/finally clause.
By the way, notice that loop uses functional-style tail recursion,
rather than a loop. No variables were mutated during the production of
this output! (Well, we don’t actually know what’s happening inside the
Java IO classes…)
Here is a Java class that uses FilePrinter. It provides the main routine.
// code-examples/AppDesign/annotations/FilePrinterMain.java
import java.io.*;
public class FilePrinterMain {
public static void main(String[] args) {
for (String fileName: args) {
try {
File file = new File(fileName);
new FilePrinter(file).print();
} catch (IOException ioe) {
System.err.println("IOException for file " + fileName);
System.err.println(ioe.getMessage());
}
}
}
}These classes compile without error. You can try them out with the
following command (which assumes that FilePrinterMain.java is in the
annotations directory, as in the example code distribution).
scala -cp build FilePrinterMain annotations/FilePrinterMain.java
You should get the following output.
1: import java.io.*;
2:
3: public class FilePrinterMain {
4: public static void main(String[] args) {
5: for (String fileName: args) {
6: try {
7: File file = new File(fileName);
8: new FilePrinter(file).print();
9: } catch (IOException ioe) {
10: System.err.println("IOException for file " + fileName);
11: System.err.println(ioe.getMessage());
12: }
13: }
14: }
15: }Now, returning to FilePrinter class above, suppose you comment out the
@throws line. This file will continue to compile, but when you
compile FilePrinterMain.java, you will get the following error.
annotations/FilePrinterMain.java:9: exception java.io.IOException is never
thrown in body of corresponding try statement
} catch (IOException ioe) {
^
1 errorEven though java.io.IOException may get thrown by FilePrinter,
that information isn’t in the byte code generated by scalac, so the
analysis done by javac mistakenly concludes that IOException is
never thrown.
So, the purpose of @throws is to insert the information on thrown
checked exceptions into the byte code that javac will read.
In a mixed Java-Scala environment, consider adding the @throws
annotation for all your Scala methods that can throw Java checked
exceptions. Eventually, some Java code will probably call one of those
methods.
Enumerations are a way of defining a finite set of constant values. They are a lightweight alternative to case classes. You can reference the values directly, iterate through them, index into them with integer indices, etc.
Just as for annotations, Scala’s form of enumerations are class-based, with a particular set of idioms, rather than relying on special keywords for defining them, as is used for enumerations in Java and .NET. However, you can also use enumerations defined in those languages.
Scala enumerations are defined by subclassing the abstract
scala.Enumeration class. There are several ways to construct and use
an enumeration. We’ll demonstrate one idiom that most closely matches
the Java and .NET forms you may already know.
Recall the HTTP methods scripts we wrote in the section called “Sealed Class Hierarchies” in Chapter 7, The Scala Object System. We defined the set of HTTP 1.1 methods using a sealed case class hierarchy.
// code-examples/ObjectSystem/sealed/http-script.scala
sealed abstract class HttpMethod()
case class Connect(body: String) extends HttpMethod
case class Delete (body: String) extends HttpMethod
case class Get (body: String) extends HttpMethod
case class Head (body: String) extends HttpMethod
case class Options(body: String) extends HttpMethod
case class Post (body: String) extends HttpMethod
case class Put (body: String) extends HttpMethod
case class Trace (body: String) extends HttpMethod
def handle (method: HttpMethod) = method match {
case Connect (body) => println("connect: " + body)
case Delete (body) => println("delete: " + body)
case Get (body) => println("get: " + body)
case Head (body) => println("head: " + body)
case Options (body) => println("options: " + body)
case Post (body) => println("post: " + body)
case Put (body) => println("put: " + body)
case Trace (body) => println("trace: " + body)
}
val methods = List(
Connect("connect body..."),
Delete ("delete body..."),
Get ("get body..."),
Head ("head body..."),
Options("options body..."),
Post ("post body..."),
Put ("put body..."),
Trace ("trace body..."))
methods.foreach { method => handle(method) }In that example, each method had a body attribute for the message
body. We’ll assume here that the body is handled through other means
and we only care about identifying the kind of HTTP method. So, here is a Scala Enumeration class for the HTTP 1.1 methods.
// code-examples/AppDesign/enumerations/http-enum-script.scala
object HttpMethod extends Enumeration {
type Method = Value
val Connect, Delete, Get, Head, Options, Post, Put, Trace = Value
}
import HttpMethod._
def handle (method: HttpMethod.Method) = method match {
case Connect => println("Connect: " + method.id)
case Delete => println("Delete: " + method.id)
case Get => println("Get: " + method.id)
case Head => println("Head: " + method.id)
case Options => println("Options: " + method.id)
case Post => println("Post: " + method.id)
case Put => println("Put: " + method.id)
case Trace => println("Trace: " + method.id)
}
HttpMethod foreach { method => handle(method) }
println( HttpMethod )This script produces the following output.
Connect: 0
Delete: 1
Get: 2
Head: 3
Options: 4
Post: 5
Put: 6
Trace: 7
{Main$$anon$1$HttpMethod(0), Main$$anon$1$HttpMethod(1),
Main$$anon$1$HttpMethod(2), Main$$anon$1$HttpMethod(3),
Main$$anon$1$HttpMethod(4), Main$$anon$1$HttpMethod(5),
Main$$anon$1$HttpMethod(6), Main$$anon$1$HttpMethod(7)}(We wrapped the lines for the output between the {…}.) There are
two uses of Value in the definition of HttpMethod. The first usage
is actual a reference to an abstract class, Enumeration.Value, which
encapsulates some useful operations for the “values” in the
enumeration. We define a new type, Method, that functions as an
alias for Value. We see it used in the type of the argument passed
to the handle method, which demonstrates HttpMethod in use.
HttpMethod.Method is a more meaningful name to the reader than the
generic HttpMethod.Value. Note that one of the fields in
Enumeration.Value is id, which we also use in handle.
The second use of Value is actually a call to a method. There is no
namespace collision between these two names. The line val Connect,
Delete, Get, Head, Options, Post, Put, Trace = Value defines the set
of values for the enumeration. The Value method is called for each
one. It creates a new Enumeration.Value for each one and adds it to
the managed set of values.
The first usage is actually
Will fix
In the code below the definition, we import the definitions in
HttpMethod and we define a handle method that pattern matches on
HttpMethod.Method objects. It simply prints a message for each value
along with its id. Note that while the example has no “default”
case clause (e.g. case _ ⇒ …). None is required in this case.
However, the compiler doesn’t actually know that all the possible
values are covered, in contrast to a sealed case class hierarchy. If
you comment out one of the case statements in handle, you will get
no warnings, but you will get a MatchError.
When pattern matching on enumeration values, the compiler can’t tell if the match is “exhaustive”.
You might wonder why we hard-coded strings like “Connect” in the
println statements in the case clauses. Can’t we get the name from
the HttpMethod.Method object itself? And why didn’t the output of
println(HttpMethod) include those names, instead of the ugly
internal object names?
You are probably accustomed to using such names with Java or .NET enumerations.
Unfortunately, we can’t get those names from the
values in the Scala enumeration, at least given the way that we
declared HttpMethod. However, there are two ways we can change the implementation to
get name strings. In the first approach, we pass the name to Value when creating the
fields.
to doing <- using such names
thanks.
// code-examples/AppDesign/enumerations/http-enum2-script.scala
object HttpMethod extends Enumeration {
type Method = Value
val Connect = Value("Connect")
val Delete = Value("Delete")
val Get = Value("Get")
val Head = Value("Head")
val Options = Value("Options")
val Post = Value("Post")
val Put = Value("Put")
val Trace = Value("Trace")
}
import HttpMethod._
def handle (method: HttpMethod.Method) = method match {
case Connect => println(method + ": " + method.id)
case Delete => println(method + ": " + method.id)
case Get => println(method + ": " + method.id)
case Head => println(method + ": " + method.id)
case Options => println(method + ": " + method.id)
case Post => println(method + ": " + method.id)
case Put => println(method + ": " + method.id)
case Trace => println(method + ": " + method.id)
}
HttpMethod foreach { method => handle(method) }
println( HttpMethod )It is a bit redundant to have to use the same word twice in declarations like val Connect = Value("Connect").
to have to use the same word twice
Thanks.
Running this script produces the following nicer output.
Connect: 0
Delete: 1
Get: 2
Head: 3
Options: 4
Post: 5
Put: 6
Trace: 7
{Connect, Delete, Get, Head, Options, Post, Put, Trace}In the second approach, we pass the list of names to the Enumeration constructor.
// code-examples/AppDesign/enumerations/http-enum3-script.scala
object HttpMethod extends Enumeration(
"Connect", "Delete", "Get", "Head", "Options", "Post", "Put", "Trace") {
type Method = Value
val Connect, Delete, Get, Head, Options, Post, Put, Trace = Value
}
import HttpMethod._
def handle (method: HttpMethod.Method) = method match {
case Connect => println(method + ": " + method.id)
case Delete => println(method + ": " + method.id)
case Get => println(method + ": " + method.id)
case Head => println(method + ": " + method.id)
case Options => println(method + ": " + method.id)
case Post => println(method + ": " + method.id)
case Put => println(method + ": " + method.id)
case Trace => println(method + ": " + method.id)
}
HttpMethod foreach { method => handle(method) }
println( HttpMethod )This script produces identical output. Note that we have a redundant list
of name strings and names of the vals.
It is up to you to keep the items in the list and their order consistent with the declared values!
This version has fewer characters, but it is more error prone.
Internally, Enumeration pairs the strings with the corresponding Value
instances as they are created.
The output when printing the whole HttpMethod object is better for
either alternative implementation. When the values have names,
their toString returns the name. In fact, our final two examples have become
quite artificial because we now have identical statements for each
case clause! Of course, in a real implementation, you would handle the
different HTTP methods differently.
For both annotations and enumerations, there are advantages and disadvantages of the Scala approach, where regular class-based mechanisms are used, rather than inventing custom keywords and syntax. The advantages include fewer special cases in the language. Classes and traits are used more or less in the same ways they are used for “normal” code. The disadvantages include the need to understand and use ad hoc conventions which are not always as convenient to use as the custom syntax mechanisms required in Java and .NET. Also, Scala’s implementations are not as full-featured.
So, should the Scala community relent and implement ad hoc, but more full-featured mechanisms for annotations and enumerations? Maybe not. Scala is a more flexible language than most languages. Many of the features provided by Java and .NET annotations and enumerations can be implemented in Scala by other means.
Some “use cases” for the more advanced features of Java annotations can be implemented more elegantly with “normal” Scala code, as we will discuss in the section called “Design Patterns” below. For enumerations, sealed case classes and pattern matching provide a more flexible solution, in many cases.
Let’s revisit the HTTP method script, which uses a sealed case
class hierarchy vs. our the version we wrote previously that uses an Enumeration.
Since the enumeration version doesn’t handle the message body, let’s
write a modified version of the sealed case class version that is
closer to the enumeration version, i.e., it also doesn’t hold the
message body and it has name and id methods.
// code-examples/AppDesign/enumerations/http-case-script.scala
sealed abstract class HttpMethod(val id: Int) {
def name = getClass getSimpleName
override def toString = name
}
case object Connect extends HttpMethod(0)
case object Delete extends HttpMethod(1)
case object Get extends HttpMethod(2)
case object Head extends HttpMethod(3)
case object Options extends HttpMethod(4)
case object Post extends HttpMethod(5)
case object Put extends HttpMethod(6)
case object Trace extends HttpMethod(7)
def handle (method: HttpMethod) = method match {
case Connect => println(method + ": " + method.id)
case Delete => println(method + ": " + method.id)
case Get => println(method + ": " + method.id)
case Head => println(method + ": " + method.id)
case Options => println(method + ": " + method.id)
case Post => println(method + ": " + method.id)
case Put => println(method + ": " + method.id)
case Trace => println(method + ": " + method.id)
}
List(Connect, Delete, Get, Head, Options, Post, Put, Trace) foreach {
method => handle(method)
}Note that we used case object for all the concrete subclasses, to
have a true set of constants. To mimic the enumeration id, we added
a field explicitly, but now it’s up to us to pass in valid, unique
values! The handle methods in the two implementations are nearly
identical.
This script outputs the following.
Main$$anon$1$Connect$: 0 Main$$anon$1$Delete$: 1 Main$$anon$1$Get$: 2 Main$$anon$1$Head$: 3 Main$$anon$1$Options$: 4 Main$$anon$1$Post$: 5 Main$$anon$1$Put$: 6 Main$$anon$1$Trace$: 7
The object names are ugly, but we could parse the string and remove the substring we really care about.
Both approaches support the concept of a finite and fixed set of values, as long as the case class hierarchy is sealed. An additional advantage of a sealed case class hierarchy is the fact that the compiler will warn you if pattern matching statements aren’t exhaustive. Try removing one of the case clauses and you’ll get the usual warning. The compiler can’t do this with enumerations, as we saw.
The enumeration format is more succinct, despite the name duplication we had to use, and it also supports the ability to iterate through the values. We had to do that manually in the case clause implementation.
The case class implementation naturally accommodates other fields,
e.g., the body, as in the original implementation, while
enumerations can only accommodate constant Values with associated
names and id’s.
For cases where you need only a simple list of constants by name or id number, use enumerations. Be careful to follow the usage idioms. For fixed sets of more complex, constant objects, use sealed case objects.
When we introduced Option in the section called “Option, Some, and None: Avoiding nulls” in Chapter 2, Type Less, Do More,
we briefly discussed how it encourages avoiding
null references in your code, which Tony Hoare, who introduced the
concept of null in 1965, called his “billion dollar mistake”
[Hoare2009].
Scala has to support null, because null is supported on both the
JVM and .NET and other libraries use null. In fact, null is used
by some Scala libraries.
What if null were not available? How would that change your designs?
The Map API offers some useful examples. Consider these two Map
methods.
trait Map[A,+B] {
...
def get(key: A) : Option[B]
def getOrElse [B2 >: B](key : A, default : => B2) : B2 = ...
...
}A map may not have a value for a particular key. Both of these methods
avoid returning null in that case. Concrete implementations of get
in subclasses return a None if no value exists for the key.
Otherwise they return a Some wrapping the value. The method
signature tells you that a value might not exist and it forces you to
handle that situation gracefully.
val stateCapitals = Map("Alabama" -> "Montgomery", ...)
...
stateCapitals.get("North Hinterlandia") match {
case None => println ("No such state!")
case Some(x) => println(x)
}Similarly, getOrElse forces you to design defensively. You have to
specify a default value for when a key isn’t in the map. Note that the
default value can actually be an instance of a supertype relative to
the map’s value type.
println(stateCapitals.getOrElse("North Hinterlandia", "No such state!"))A lot of Java and .NET APIs allow null method arguments and can
return null values. You can write Scala wrappers around them to
implement an appropriate strategy for handling nulls.
For example, let’s revisit our previous file printing example in
the section called “Annotations”. We’ll refactor our FilePrinter class and the Java driver
into a combined script. We’ll address two
issues: 1) wrap LineNumberReader.readLine+ with a method that returns
an Option instead of null and 2) wrap checked IOExceptions in
our own unchecked exception, called ScalaIOException.
// code-examples/AppDesign/options-nulls/file-printer-refactored-script.scala
import java.io._
class ScalaIOException(cause: Throwable) extends RuntimeException(cause)
class ScalaLineNumberReader(in: Reader) extends LineNumberReader(in) {
def inputLine() = readLine() match {
case null => None
case line => Some(line)
}
}
object ScalaLineNumberReader {
def apply(file: File) = try {
new ScalaLineNumberReader(new FileReader(file))
} catch {
case ex: IOException => throw new ScalaIOException(ex)
}
}
class FilePrinter(val file: File) {
def print() = {
val reader = ScalaLineNumberReader(file)
try {
loop(reader)
} finally {
if (reader != null)
reader.close
}
}
private def loop(reader: ScalaLineNumberReader): Unit = {
reader.inputLine() match {
case None =>
case Some(line) => {
format("%3d: %s\n", reader.getLineNumber, line)
loop(reader)
}
}
}
}
// Process the command-line arguments (file names):
args.foreach { fileName =>
new FilePrinter(new File(fileName)).print();
}The ScalaLineNumberReader class defines a new method inputLine that
calls LineNumberReader.readLine+ and pattern matches the result. If
null, then None is returned. Otherwise the line is returned
wrapped in a Some[String].
ScalaIOException is a subclass of RuntimeException, so it is
unchecked. We use it to wrap any IOExceptions thrown in
ScalaLineNumberReader.apply.
The refactored FilePrinter class uses ScalaLineNumberReader.apply in
its print method. It uses ScalaLineNumberReader.inputLine in its
loop method. While the original version properly handled the case of
LineNumberReader.readLine returning null, now the user of
ScalaLineNumberReader has no choice but to handle a None return
value.
The script ends with a loop over the input arguments, which are stored
automatically in the args variable. Each argument is treated as a
file name to be printed. The script will print itself with the
following command.
scala file-printer-refactored-script.scala file-printer-refactored-script.scala
There is one other benefit of using Options with for comprehensions, automatic removal of None elements from comprehensions, under most conditions [Pollak2007], [Spiewak2009c]. Consider this first version of a script that uses Options in a for comprehension.
// code-examples/AppDesign/options-nulls/option-for-comp-v1-script.scala
case class User(userName: String, name: String, email: String, bio: String)
val newUserProfiles = List(
Map("userName" -> "twitspam", "name" -> "Twit Spam"),
Map("userName" -> "bucktrends", "name" -> "Buck Trends",
"email" -> "[email protected]", "bio" -> "World's greatest bloviator"),
Map("userName" -> "lonelygurl", "name" -> "Lonely Gurl",
"bio" -> "Obviously fake..."),
Map("userName" -> "deanwampler", "name" -> "Dean Wampler",
"email" -> "[email protected]", "bio" -> "Scala passionista"),
Map("userName" -> "al3x", "name" -> "Alex Payne",
"email" -> "[email protected]", "bio" -> "Twitter API genius"))
// Version #1
var validUsers = for {
user <- newUserProfiles
if (user.contains("userName") && user.contains("name") && // #1
user.contains("email") && user.contains("bio")) // #1
userName <- user get "userName"
name <- user get "name"
email <- user get "email"
bio <- user get "bio" }
yield User(userName, name, email, bio)
validUsers.foreach (user => println(user))Imagine this code is used in some sort of social networking site. New users submit profile data, which are passed to this service in bulk for processing. For example, we hard coded a list of submitted profiles, where each profile data set is a map. The map might have been copied from an HTTP session.
The service filters out incomplete profiles (missing fields), shown with the #1 comments, and creates new user objects from the complete profiles.
Running the script prints out three new users from the five submitted profiles.
User(bucktrends,Buck Trends,[email protected],World's greatest bloviator) User(deanwampler,Dean Wampler,[email protected],Scala passionista) User(al3x,Alex Payne,[email protected],Twitter API genius)
Now, comment out the two lines with the #1 comment.
...
var validUsers = for {
user <- newUserProfiles
userName <- user get "userName"
name <- user get "name"
email <- user get "email"
bio <- user get "bio" }
yield User(userName, name, email, bio)
validUsers.foreach (user => println(user))Before you rerun the script, what do you expect to happen? Will it print 5 lines with some fields empty (or containing other kinds of values)?
It prints the same thing! How did it do the filtering we wanted without the explicit conditional?
The answer lies in the way that for comprehensions are implemented. Here are a couple of simple for comprehensions followed by their translations [ScalaSpec2009]. First, we’ll look at a single generator with a yield.
for (p1 <- e1) yield e2 // for comprehension e1 map ( case p1 => e2 ) // translation
Here’s the translation a single generator followed by an arbitrary expression (which could be several expressions in braces, etc.).
for (p1 <- e1) e2 // for comprehension e1 foreach ( case p1 => e2 ) // translation
With more than one generator, map is replaced with flatMap in the yield expressions, but foreach is unchanged.
for (p1 <- e1; p2 <- e2 ...) yield eN // for comprehension e1 flatMap ( case p1 => for (p2 <- e2 ...) yield eN ) // translation
for (p1 <- e1; p2 <- e2 ...) eN // for comprehension e1 foreach ( case p1 => for (p2 <- e2 ...) eN ) // translation
Note that the second through the Nth generators become nested for comprehensions that need translating.
There are similar translations for conditional statements (which become calls to filter) and val assignments. We won’t show them here, since our primary purpose is to describe just enough of the implementation details so you can understand how Options and for comprehensions work together. The additional details are described in [ScalaSpec2009], with examples.
If you follow this translation process on our example, you get the following expansion.
var validUsers = newUserProfiles flatMap {
case user => user.get("userName") flatMap {
case userName => user.get("name") flatMap {
case name => user.get("email") flatMap {
case email => user.get("bio") map {
case bio => User(name, userName, email, bio) // #1
}
}
}
}
}Note that we have flatMap calls until the most nested case, where map is used (flatMap and map behave equivalently in this case.)
Now we can understand why the big conditional was unnecessary. Recall that user is a Map and user.get("…") returns an Option, either None or Some(value). The key is the behavior of flatMap defined on Option, which lets us treat Options like other collections. Here is the definition of flatMap.
def flatMap[B](f: A => Option[B]): Option[B] = if (isEmpty) None else f(this.get)
If user.get("…") returns None, then flatMap simply returns None and never evaluates the function literal. Hence, the nested iterations simply stop and never get to the line marked with the comment #1, where the User is created.
The outer most flatMap is on the input List, newUserProfiles. On a multi-element collection like this, the behavior of flatMap is similar to map, but it “flattens” the new collection and it doesn’t require the resulting map to have the same number of elements as the original collection, like map does.
Finally, recall from the section called “Partial Functions” in Chapter 8, Functional Programming in Scala that the case user => … statements, for example, cause the compiler to generate a PartialFunction to pass to flatMap and map, so no corresponding foo match {…} style wrappers are necessary.
Using Options with for comprehensions eliminate the need for most “null/empty” checks.
If nulls are the “billion dollar mistake” as we discussed in
the section called “Option, Some, and None: Avoiding nulls” in Chapter 2, Type Less, Do More, then what about exceptions?
You can argue that nulls should never occur and you can design a
language and libraries that never use them. However, exceptions have a
legitimate place, because they separate the concerns of normal
program flow from “exceptional” program flow. The divide isn’t
always clear cut. For example, if a user mistypes his user name, is
that normal or exceptional?
Another question is where should the exception be caught and handled?
Java’s checked exceptions were designed to document for the API user
what exceptions might be thrown by a method. The flaw was it
encouraged handling of the exception in ways that are often
suboptimal. If one method calls another method that might throw a
checked exception, the calling method is forced to either handle the
exception or to declare that it also throws the exception. More often
than not, the calling method is the wrong place to handle the
exception. It is too common for methods to simply “eat” an exception
that should really be passed up the stack and handled in a more
appropriate context. Otherwise, throws declarations are required up
the stack of method calls. This is not only tedious, but it pollutes
the intermediate contexts with exception names that often have no
connection to the local context.
As we have seen, Scala doesn’t have checked exceptions. Any exception can propagate to the point where it is most appropriate to handle it. However, design discipline is required to implement handlers in the appropriate places for all exceptions for which recovery is possible!
Every now and then, an argument erupts among developers in a
particular language community about whether or not it’s okay to use
exceptions as a control-flow mechanism for normal processing.
Sometimes this use of exceptions is seen as a useful longjump or
nonlocal goto mechanism for exiting out of a deeply nested scope.
One reason this debate pops up is that this use of exceptions is
sometimes more efficient than a more “conventional” implementation.
For example, you might implement Iterable.foreach to blindly
traverse a collection and stop when it catches whatever exception
indicates it went past the end of the collection.
When it comes to application design, communicating intent is very
important. Using exceptions as a goto mechanism breaks the
principle of least surprise. It will be rare that the performance
gain will justify the loss of clarity, so we encourage you to use
exceptions only for truly “exceptional” conditions. Note that Ruby
actually provides a nonlocal goto-like mechanism. In Ruby the
keywords throw and catch are actually reserved for this purpose,
while raise and rescue are the keywords for raising an exception
and handling it.
Whatever your view on the proper use of exceptions, when you design
APIs, minimizing the possibility of raising an exception will benefit
your users. This is the flip side of an exception handling strategy,
preventing them in the first place. Option can help.
Consider two methods on Seq, first and firstOption.
trait Seq[+A] {
...
def first : A = ...
def firstOption : Option[A] = ...
...
}The first method throws a Predef.UnsupportedOperationException if
the sequence is empty. Returning null in this case isn’t an option,
because the sequence could have null elements! In contrast, the
firstOption method returns an Option, so it returns None if the
sequence is empty, which is unambiguous.
You could argue that the Seq API would be more robust if it only had
a “first” method that returned an Option. It’s useful to ask
yourself, “how can I prevent the user from ever failing?” When
“failure” can’t be prevented, use Option or a similar construct to
document for the user that a failure mode is possible. Thinking in
terms of valid state transformations, the first method, while
convenient, isn’t really valid for a sequence in an empty state.
Should the “first” methods not exist for this reason? This choice is
probably too draconian, but by returning Option from firstOption,
the API communicates to the user that there are circumstances when the
method can’t satisfy the request and it’s up to the user to recover
gracefully. In this sense, firstOption treats an empty sequence as a
non-exceptional situation.
Recall that we saw another example of this decision tradeoff in
the section called “Option, Some, and None: Avoiding nulls” in Chapter 2, Type Less, Do More. We discussed two methods on Option
for retrieving the value an instance wraps (when the instance is actually a Some).
The get method throws an exception if there is no value, i.e., the Option instance
is actually None. The other method, getOrElse takes a second argument, a default
value to return if the Option is actually None. In this case, no exception is
thrown.
Of course, it is impossible to avoid all exceptions. Part of the original intent of checked vs. unchecked exceptions was to distinguish between potentially-recoverable problems and catastrophic failures, like out-of-memory errors.
However, the alternative methods in Seq and Option show a way to “encourage”
the user of an API to consider the consequences of a possible failure, like asking for
the first element in an empty sequence. The user can specify the contingency in the event that a failure occurs. Minimizing the possibility of exceptions
will improve the robustness of your Scala libraries and the applications that use them.
It has been a goal for some time in our industry to create reusable components. Unfortunately, there is little agreement on the meaning of the term component nor on a related term, module (which some people consider synonymous with component). Proposed definitions usually start with assumptions about the platform, granularity, deployment and configuration scenarios, versioning issues, etc. [Szyperski1998].
We’ll avoid that discussion and use the term component informally to refer to a grouping of types and packages that exposes coherent abstractions (preferably just one) for the services it offers, has minimal coupling to other components, and is internally cohesive.
All languages offer mechanisms for defining components, at least to some degree. Objects are the primary encapsulation mechanism in object-oriented languages. However, objects alone aren’t enough, because we quickly find that objects naturally cluster together into more coarse-grained aggregates, especially as our applications grow. Generally speaking, an object isn’t necessarily a component and a component may contain many objects. Scala and Java offer packages for aggregating types. Ruby modules serve a similar purpose, as do C# and C++ namespaces.
However, these packaging mechanisms still have limitations. A common problem is that they don’t clearly define what is publicly visible outside the component boundary and what is internal to the component. For example, in Java, any public type or public method on a public type is visible outside the package boundary to every other component. You can make types and methods “package private”, but then they are invisible to other packages encapsulated in the component. Java doesn’t have a clear sense of component boundaries.
Scala provides a number of mechanisms that improve this situation. We have seen many of them already.
We saw in the section called “Visibility Rules” in Chapter 5, Basic Object-Oriented Programming in Scala that Scala provides more fine-grained visibility rules than most other languages. You can control the visibility of types and methods outside type and package boundaries.
Consider the following example of a component in package encodedstring.
// code-examples/AppDesign/abstractions/encoded-string.scala
package encodedstring {
trait EncodedString {
protected[encodedstring] val string: String
val separator: EncodedString.Separator.Delimiter
override def toString = string
def toTokens = string.split(separator.toString).toList
}
object EncodedString {
object Separator extends Enumeration {
type Delimiter = Value
val COMMA = Value(",")
val TAB = Value("\t")
}
def apply(s: String, sep: Separator.Delimiter) = sep match {
case Separator.COMMA => impl.CSV(s)
case Separator.TAB => impl.TSV(s)
}
def unapply(es: EncodedString) = Some(Pair(es.string, es.separator))
}
package impl {
private[encodedstring] case class CSV(override val string: String)
extends EncodedString {
override val separator = EncodedString.Separator.COMMA
}
private[encodedstring] case class TSV(override val string: String)
extends EncodedString {
override val separator = EncodedString.Separator.TAB
}
}
}This example encapsulates handling of strings encoding comma-separated values (CSVs) or tab-separated values (TSVs). The encodedstring package exposes a trait EncodedString that is visible to clients. The concrete classes implementing CSVs and TSVs are declared protected[encodedstring] in the encodedstring.impl package. The trait defines two abstract val fields, one to hold the encoded string, which is protected from client access, and the other to hold the separator (e.g., a comma). Recall from Chapter 6, Advanced Object-Oriented Programming In Scala that abstract fields, like abstract types and methods, must be initialized in concrete instances. In this case, string will be defined through a concrete constructor and the separator is defined explicitly in the concrete classes, CSV and TSV.
In the code, the concrete classes implementing CSVs and TSVs are declared private[encodedstring], not protected[encodedstring] as the paragraph states.
The toString method on EncodedString prints the string as a “normal” string. By hiding the string value and the concrete classes, we have complete freedom in how the string is actually stored. For example, for extremely large strings, we might want to split them on the delimiter and store the tokens in a data structure. This could save space if the strings are large enough and we can share tokens between strings. Also, we might find this storage useful for various searching, sorting, and other manipulation tasks. All these implementation issues are transparent to the client.
The package also exposes an object with an Enumeration for the known separators, an apply factory method to construct new encoded strings, and an unapply extractor method to decompose the encoded string into its enclosed string and the delimiter. In this case, the unapply method looks trivial, but if we stored the strings in a different way, this method could transparently reconstitute the original string.
So, clients of this component only know about the EncodedString abstraction and the enumeration representing the supported types of encoded strings. All the actual implementation types and details are private to the encodedstring package. (We put them in the same file for convenience, but normally you would kept them separate.) Hence, the boundary is clear between the exposed abstractions and the internal implementation details.
The following script demonstrates the component in use.
// code-examples/AppDesign/abstractions/encoded-string-script.scala
import encodedstring._
import encodedstring.EncodedString._
def p(s: EncodedString) = {
println("EncodedString: " + s)
s.toTokens foreach (x => println("token: " + x))
}
val csv = EncodedString("Scala,is,great!", Separator.COMMA)
val tsv = EncodedString("Scala\tis\tgreat!", Separator.TAB)
p(csv)
p(tsv)
println( "\nExtraction:" )
List(csv, "ProgrammingScala", tsv, 3.14159) foreach {
case EncodedString(str, delim) =>
println( "EncodedString: \"" + str + "\", delimiter: \"" + delim + "\"" )
case s: String => println( "String: " + s )
case x => println( "Unknown Value: " + x )
}It produces the following output.
EncodedString: Scala,is,great! token: Scala token: is token: great! EncodedString: Scala is great! token: Scala token: is token: great! Extraction: EncodedString: "Scala,is,great!", delimiter: "," String: ProgrammingScala EncodedString: "Scala is great!", delimiter: " " Unknown Value: 3.14159
However, if we try to use the CSV class directly, for example, we get the following error.
scala> import encodedstring._
import encodedstring._
scala> val csv = impl.CSV("comma,separated,values")
<console>:6: error: object CSV cannot be accessed in package encodedstring.impl
val csv = impl.CSV("comma,separated,values")
^
scala>In this simple example, it wasn’t essential to make the concrete types private to the component. However, we have a very minimal interface to clients of the component and we are free to modify the implementation as we see fit with little risk of forcing client code modifications. A common cause of maintenance paralysis in mature applications is the presence of too many dependencies between concrete types, which become difficult to modify since they force changes to client code. So, for larger, more sophisticated components, this clear separation of abstraction from implementation can keep the code maintainable and reusable for a long time.
We saw in Chapter 4, Traits how traits promote mixin composition. A class can focus on its primary domain and other responsibilities can be implemented separately in traits. When instances are constructed, classes and traits can be combined to compose the full range of required behaviors.
For example, in the section called “Overriding Abstract Types” in Chapter 6, Advanced Object-Oriented Programming In Scala, we discussed our second version of the Observer Pattern.
// code-examples/AdvOOP/observer/observer2.scala
package observer
trait AbstractSubject {
type Observer
private var observers = List[Observer]()
def addObserver(observer:Observer) = observers ::= observer
def notifyObservers = observers foreach (notify(_))
def notify(observer: Observer): Unit
}
trait SubjectForReceiveUpdateObservers extends AbstractSubject {
type Observer = { def receiveUpdate(subject: Any) }
def notify(observer: Observer): Unit = observer.receiveUpdate(this)
}
trait SubjectForFunctionalObservers extends AbstractSubject {
type Observer = (AbstractSubject) => Unit
def notify(observer: Observer): Unit = observer(this)
}We used this version to observe button “clicks” in a UI. Let’s revisit this implementation and resolve a few limitations, using our next tool for scalable abstractions, self-type annotations combined with abstract type members.
There are a few things that are unsatisfying about the implementation of AbstractSubject in our second version of the Observer Pattern. The first occurs in SubjectForReceiveUpdateObservers, where the Observer type is defined to be the structural type { def receiveUpdate(subject: Any) }. It would be nice to narrow the type of subject to something more specific than Any.
The second issue, which is really the same problem in a different form, occurs in SubjectForFunctionalObservers, where the Observer type is defined to be the type (AbstractSubject) => Unit. We would like the argument to the function to be something more specific than AbstractSubject. Perhaps this drawback wasn’t so evident before, because our simple examples never needed to access Button state information or methods.
In fact, we expect the actual types of the subject and observer to be specialized covariantly. For example, when we’re observing Buttons, we expect our observers to be specialized for Buttons, so they can access Button state and methods. This covariant specialization is sometimes called family polymorphism [Odersky2005]. Let’s fix our design to support this covariance.
To simplify the example, let’s focus on just the receiveUpdate form of the Observer, which we implemented with SubjectForReceiveUpdateObservers before. Here is a reworking of our pattern, loosely following an example in [Odersky2005]. (Note that the Scala syntax has changed somewhat since that paper was written.)
// code-examples/AppDesign/abstractions/observer3-wont-compile.scala
// WON'T COMPILE
package observer
abstract class SubjectObserver {
type S <: Subject
type O <: Observer
trait Subject {
private var observers = List[O]()
def addObserver(observer: O) = observers ::= observer
def notifyObservers = observers foreach (_.receiveUpdate(this)) // ERROR
}
trait Observer {
def receiveUpdate(subject: S)
}
}We’ll explain the error in a minute. Note how the types S and O are declared. As we saw in the section called “Understanding Parameterized Types” in Chapter 12, The Scala Type System, the expression type S <: Subject defines an abstract type S where the only allowed concrete types will be subtypes of Subject. The declaration of O is similar. To be clear, S and O are “placeholders” at this point, while Subject and Observer are abstract traits defined in SubjectObserver.
By the way, declaring SubjectObserver as an abstract class vs. a trait is somewhat arbitrary. We’ll derive concrete objects from it shortly. We need SubjectObserver primarily so we have a type to “hold” our abstract type members S and O.
However, if you attempt to compile this code as currently written, you get the following error.
... 10: error: type mismatch;
found : SubjectObserver.this.Subject
required: SubjectObserver.this.S
def notifyObservers = observers foreach (_.receiveUpdate(this))
^
one error foundIn the nested Observer trait, receiveUpdate is expecting an instance of type S, but we are passing it this, which is of type Subject. In other words, we are passing an instance of a parent type of the type expected. One solution would be to change the signature to just expect the parent type, Subject. That’s undesirable. We just mentioned that our concrete observers need the more specific type, the actual concrete type we’ll eventually define for S, so they can call methods on it. For example, when observing UI CheckBoxes, the observers will want to read whether or not a box is checked. We don’t want to force the observers to use unsafe casts.
We looked at composition using self-type annotations in the section called “Self Type Annotations” in Chapter 12, The Scala Type System. Let’s use this feature now to solve our current compilation problem. Here is the same code again with a self-type annotation.
// code-examples/AppDesign/abstractions/observer3.scala
package observer
abstract class SubjectObserver {
type S <: Subject
type O <: Observer
trait Subject {
self: S => // #1
private var observers = List[O]()
def addObserver(observer: O) = observers ::= observer
def notifyObservers = observers foreach (_.receiveUpdate(self)) // #2
}
trait Observer {
def receiveUpdate(subject: S)
}
}Comment #1 shows the self-type annotation, self: S =>. We can now use self as an alias for this, but whenever it appears, the type will be assumed to be S, not Subject. It is as if we’re telling Subject to impersonate another type, but in a type-safe way, as we’ll see.
Actually, we could have used this instead of self in the annotation, but self is somewhat conventional. A different name also reminds us that we’re working with a different type.
Are self-type annotations a safe thing to use? When an actual concrete SubjectObserver is defined, S and O will be specified and type checking will be performed to ensure that the concrete S and O are compatible with Subject and Observer. In this case, because we also defined S to be a subtype of Subject and O to be a subtype of Observer, any concrete types derived from Subject and Observer, respectively, will work.
Comment #2 shows that we pass self instead of this to receiveUpdate.
Now that we have a generic implementation of the pattern, let’s specialize it for observing button clicks.
// code-examples/AppDesign/abstractions/button-observer3.scala
package ui
import observer._
object ButtonSubjectObserver extends SubjectObserver {
type S = ObservableButton
type O = ButtonObserver
class ObservableButton(name: String) extends Button(name) with Subject {
override def click() = {
super.click()
notifyObservers
}
}
trait ButtonObserver extends Observer {
def receiveUpdate(button: ObservableButton)
}
}The final piece of the puzzle is to define a concrete observer. As before, we’ll count button clicks. However, to emphasize the value of having the specific type of instance passed to the observer, a Button in this case, we’ll enhance the observer to track clicks for multiple buttons using a hash map with the button labels as the keys. No type casts are required!
// code-examples/AppDesign/abstractions/button-click-observer3.scala
package ui
import observer._
class ButtonClickObserver extends ButtonSubjectObserver.ButtonObserver {
val clicks = new scala.collection.mutable.HashMap[String,Int]()
def receiveUpdate(button: ButtonSubjectObserver.ObservableButton) = {
val count = clicks.getOrElse(button.label, 0) + 1
clicks.update(button.label, count)
}
}Finally, here is a specification that exercises the code.
// code-examples/AppDesign/abstractions/button-observer3-spec.scala
package ui
import org.specs._
import observer._
object ButtonObserver3Spec extends Specification {
"An Observer counting button clicks" should {
"see all clicks" in {
val button1 = new ButtonSubjectObserver.ObservableButton("button1")
val button2 = new ButtonSubjectObserver.ObservableButton("button2")
val button3 = new ButtonSubjectObserver.ObservableButton("button3")
val buttonObserver = new ButtonClickObserver
button1.addObserver(buttonObserver)
button2.addObserver(buttonObserver)
button3.addObserver(buttonObserver)
clickButton(button1, 1)
clickButton(button2, 2)
clickButton(button3, 3)
buttonObserver.clicks("button1") mustEqual 1
buttonObserver.clicks("button2") mustEqual 2
buttonObserver.clicks("button3") mustEqual 3
}
}
def clickButton(button: Button, nClicks: Int) =
for (i <- 1 to nClicks)
button.click()
}We see again how abstract types combined with self-type annotations provide a reusable abstraction that is easy to extend in a type-safe way for particular needs. Even though we defined a general protocol for observing an “event” after it happened, we were able to define subtypes specific to Buttons without resorting to unsafe casts from Subject abstractions.
The Scala compiler itself is implemented using these mechanisms [Odersky2005] to make it modular in useful ways. For example, it is relatively straightforward to implement compiler plugins.
We’ll revisit these idioms in the section called “Dependency Injection in Scala: The Cake Pattern” below.
One of the reasons that many languages (like Java) do not implement multiple inheritance is because of the problems observed with multiple inheritance in C++. One of the those problems is the so-called diamond of death, which is illustrated in Figure 13.1, “Diamond of Death in languages with multiple inheritance.”.
Figure 13.1. Diamond of Death in languages with multiple inheritance.
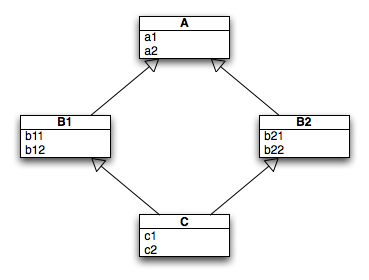
In C++, each constructor for C will invoke a constructor for B1 and a constructor for B2 (explicitly or implicitly). Each constructor for B1 and B2 will invoke a constructor for A. Hence, in a naïve implementation of multiple inheritance, the fields of A, a1 and a2, could be initialized twice and possibly initialized in an inconsistent way or there might be two different A “pieces” in the C instance, one for B1 and one for B2! C++ has mechanisms to clarify what should happen, but it’s up to the developer to understand the details and to do the correct thing.
Scala’s single inheritance and support for traits avoid these problems, while providing the most important benefit of multiple inheritance, mixin composition. The order of construction is unambiguous (see the section called “Linearization of an Object’s Hierarchy” in Chapter 7, The Scala Object System). Traits can’t have constructor argument lists, but Scala ensures that their fields are properly initialized when instances are created, as we saw in the section called “Constructing Traits” and the section called “Overriding Abstract and Concrete Fields in Traits” in Chapter 6, Advanced Object-Oriented Programming In Scala. We saw another example of initializing vals in a trait in the section called “Fine-Grained Visibility Rules” above. There we defined concrete classes that overrode the definitions of the two abstract fields in the EncodedString trait.
So, Scala handles many potential issues that arise when mixing the contributions of different traits into the set of possible states of an instance. Still, it’s important to consider how the contributions of different traits interact with each other.
How are naming conflicts with mixin composition resolved? For example, if both B1 and B2 define (and implement) a method b3? If invoked on C, which would be called? One might expect the first one encountered in the linearized hierarchy. But can C's client also choose a different one? Or will the compiler complain?
When considering the state of an instance, it is useful to consider the instance as possessing a state machine, where events (e.g., method calls and field writes) cause transitions from one state to another. The set of all possible states form a space. You can think of each field as contributing one dimension to this space.
For example, recall our VetoableClicks trait in the section called “Stackable Traits” in Chapter 4, Traits, where button clicks were counted and additional clicks were vetoed after a certain number of clicks occurred. Our simple Button class contributed only a label dimension, while VetoableClicks contributed a count dimension and a maxAllowed constant. Here is a recap of these types, collected together into a single script that also exercises the code.
// code-examples/AppDesign/abstractions/vetoable-clicks1-script.scala
trait Clickable {
def click()
}
class Widget
class Button(val label: String) extends Widget with Clickable {
def click() = println("click!")
}
trait VetoableClicks extends Clickable {
val maxAllowed = 1
private var count = 0
abstract override def click() = {
if (count < maxAllowed) {
count += 1
super.click()
}
}
}
val button1 = new Button("click me!")
println("new Button(...)")
for (i <- 1 to 3 ) button1.click()
val button2 = new Button("click me!") with VetoableClicks
println("new Button(...) with VetoableClicks")
for (i <- 1 to 3 ) button2.click()This script prints the following output.
new Button(...) click! click! click! new Button(...) with VetoableClicks click!
Note that maxAllowed is a constant, but it can be overridden when instantiating each instance. So, two instances could differ only by the value of maxAllowed. Therefore, maxAllowed also contributes a dimension to the state, but with only one value per instance!
In general, a single trait can either be stateless, i.e., it contributes no new dimensions of state to the instance, or it can contribute orthogonal state dimensions to the instance, i.e., dimensions that are independent of the state contributions from other traits and the parent class. In the script, Clickable is trivially stateless (ignoring the button’s label), while VetoableClicks contributes maxAllowed and count. Traits with orthogonal state often have orthogonal methods, too. For example, the observer pattern traits we used in Chapter 4, Traits contained methods for managing their lists of observers.
Independent of whether or not a trait contributes state dimensions, a trait can also modify the possible values for a dimension contributed by a different trait or the parent class. To see an example, let’s refactor the script to move the click count to the Clickable trait.
// code-examples/AppDesign/abstractions/vetoable-clicks2-script.scala
trait Clickable {
private var clicks = 0
def count = clicks
def click() = { clicks += 1 }
}
class Widget
class Button(val label: String) extends Widget with Clickable {
override def click() = {
super.click()
println("click!")
}
}
trait VetoableClicks extends Clickable {
val maxAllowed = 1
abstract override def click() = {
if (count < maxAllowed)
super.click()
}
}
val button1 = new Button("click me!")
println("new Button(...)")
for (i <- 1 to 3 ) button1.click()
val button2 = new Button("click me!") with VetoableClicks
println("new Button(...) with VetoableClicks")
for (i <- 1 to 3 ) button2.click()This script prints the same output as before. Now Clickable contributes one state dimension for count (which is now a method that returns the value of the private clicks field). VetoableClicks modifies this dimension by reducing the number of possible values for count from 0 to infinity down to just 0 and 1. Therefore, one trait affects the behavior of another. We might say that VetoableClicks is invasive, because it changes the behavior of other mixins.
Why is all this important? While the problems of multiple-inheritance are eliminated in Scala’s model of single inheritance plus traits, care is required when mixing state and behavior contributions to create well-behaved applications. For example, if you have a test suite that Button passes, will a Button with VetoableClicks instance pass the same test suite? The suite won’t pass if it assumes that you can click a button as many times as you want. There are different “specifications” for these two kinds of buttons. This difference is expressed by the Liskov Substitution Principle [Martin2003]. An instance of a Button with VetoableClicks won’t be substitutable in every situation where a regular Button instance is used. This is a consequence of the invasive nature of VetoableClicks.
When a trait adds only orthogonal state and behavior, without affecting the rest of the state and behavior of the instance, it makes reuse and composition much easier, as well as reducing the potential for bugs. The observer pattern implementations we have seen are quite reusable. The only requirement for reuse is to provide some “glue” to adapt the generic subject and observer traits to particular circumstances.
This does not mean that invasive mixins are bad, just that they should be used wisely. The “vetoable events” pattern can be very useful.
Design patterns have taken a beating lately. Critics dismiss them as workarounds for missing language features. Indeed, some of the Gang of Four patterns [GOF1995] are not really needed in Scala, as native features provide better substitutes. Other patterns are part of the language itself, so no special coding is needed. Of course, patterns are frequently misused, but that’s not the fault of the patterns themselves.
We think the criticisms often overlook an important point, the distinction between an idea and how it is implemented and used in a particular situation. Design patterns document recurring, widely-useful ideas. These ideas are part of the vocabulary that software developers use to describe their designs.
Some common patterns are native language features in Scala, like singleton objects that eliminate the need for a Singleton Pattern [GOF1995] implementation like you often use in Java code.
The Iterator Pattern [GOF1995] is so pervasive in programming that most languages
include iteration mechanisms for any type that can be treated like a collection.
For example, in Scala you can iterate through the characters in a String with foreach.
"Programming Scala" foreach {c => println(c)}Actually, in this case, an implicit conversation is invoked to convert the java.lang.String to
a RichString, which has the foreach method. That’s an example of the pattern called pimp my library, which we saw in the section called “Implicit Conversions”.
"implicit conversation" should be "implicit conversion"
Other common patterns have better alternatives in Scala. We’ll discuss a better alternative to the Visitor Pattern [GOF1995] in a moment.
Finally, still other patterns can be implemented in Scala and remain very useful. For example, the Observer Pattern that we discussed earlier in this chapter and in Chapter 4, Traits is a very useful pattern for many design problems. It can be implemented very elegantly using mixin composition.
We won’t discuss all the well known patterns, such as those in [GOF1995]. A number of the GOF patterns are discussed at [ScalaWiki:Patterns], along with other patterns that are somewhat specific to Scala. Instead, we’ll discuss a few illustrative examples. We’ll start by discussing a replacement for the Visitor Pattern that uses functional idioms and implicit conversations. Then we’ll discuss a powerful way of implementing Dependency Injection in Scala using the Cake Pattern.
"implicit conversations" should be "implicit conversions"
The Visitor Pattern [GOF1995] solves the problem of adding a new operation to a class hierarchy without editing the source code for the classes in the hierarchy. For a number of practical reasons, it may not be feasible or desirable to edit the hierarchy to support the new operation.
Let’s look at an example of the pattern using the Shape class hierarchy we have
used previously. We’ll start with the case class version from the section called “Case Classes”
in Chapter 6, Advanced Object-Oriented Programming In Scala.
// code-examples/AdvOOP/shapes/shapes-case.scala
package shapes {
case class Point(x: Double, y: Double)
abstract class Shape() {
def draw(): Unit
}
case class Circle(center: Point, radius: Double) extends Shape() {
def draw() = println("Circle.draw: " + this)
}
case class Rectangle(lowerLeft: Point, height: Double, width: Double)
extends Shape() {
def draw() = println("Rectangle.draw: " + this)
}
case class Triangle(point1: Point, point2: Point, point3: Point)
extends Shape() {
def draw() = println("Triangle.draw: " + this)
}
}Suppose we don’t want the draw method in the classes. This is a reasonable design choice, since
the drawing method will be highly dependent on the particular context of use, such as details
of the graphics libraries on the platforms the application will run on. For greater reusability,
we would like drawing to be an operation we decouple from the shapes themselves.
First, we refactor the Shape hierarchy to support the Visitor Pattern, following the example in [GOF1995].
// code-examples/AppDesign/patterns/shapes-visitor.scala
package shapes {
trait ShapeVisitor {
def visit(circle: Circle): Unit
def visit(rect: Rectangle): Unit
def visit(tri: Triangle): Unit
}
case class Point(x: Double, y: Double)
sealed abstract class Shape() {
def accept(visitor: ShapeVisitor): Unit
}
case class Circle(center: Point, radius: Double) extends Shape() {
def accept(visitor: ShapeVisitor) = visitor.visit(this)
}
case class Rectangle(lowerLeft: Point, height: Double, width: Double)
extends Shape() {
def accept(visitor: ShapeVisitor) = visitor.visit(this)
}
case class Triangle(point1: Point, point2: Point, point3: Point)
extends Shape() {
def accept(visitor: ShapeVisitor) = visitor.visit(this)
}
}We define a ShapeVisitor trait, which has one method for each concrete class in the hierarchy,
e.g., visit(circle: Circle). Each such method takes one parameter of the corresponding type to visit.
Concrete derived classes will implement each method to do the appropriate operation for the particular
type passed in.
The visitor pattern requires a one-time modification to the class hierarchy.
An overridden method named "accept" must be added, which takes a Visitor parameter.
This method must be overridden for each class. It calls the corresponding method
defined on the visitor instance, passing this as the argument.
Finally, note that we declared Shape to be sealed. It won’t help us prevent some bugs in
the visitor pattern implementation, but it will prove useful shortly.
Here is a concrete visitor that supports our original draw operation.
// code-examples/AppDesign/patterns/shapes-drawing-visitor.scala
package shapes {
class ShapeDrawingVisitor extends ShapeVisitor {
def visit(circle: Circle): Unit =
println("Circle.draw: " + circle)
def visit(rect: Rectangle): Unit =
println("Rectangle.draw: " + rect)
def visit(tri: Triangle): Unit =
println("Triangle.draw: " + tri)
}
}For each visit method, it “draws” the Shape instance appropriately.
Finally, here is a script that exercises the code.
// code-examples/AppDesign/patterns/shapes-drawing-visitor-script.scala
import shapes._
val p00 = Point(0.0, 0.0)
val p10 = Point(1.0, 0.0)
val p01 = Point(0.0, 1.0)
val list = List(Circle(p00, 5.0),
Rectangle(p00, 2.0, 3.0),
Triangle(p00, p10, p01))
val shapesDrawer = new ShapeDrawingVisitor
list foreach { _.accept(shapesDrawer) }It produces the following output.
Circle.draw: Circle(Point(0.0,0.0),5.0) Rectangle.draw: Rectangle(Point(0.0,0.0),2.0,3.0) Triangle.draw: Triangle(Point(0.0,0.0),Point(1.0,0.0),Point(0.0,1.0))
Visitor has been criticized for being somewhat inelegant and for breaking the
Open-Closed Principle (OCP) [Martin2003], because if the hierarchy changes, you are
forced to edit (and test and redeploy) all the visitors for that hierarchy. Note
that every ShapeVisitor trait has methods that hard-code information about every
Shape derived type. These kinds of changes are also error prone.
In languages with “open types”, like Ruby, an alternative to the visitor pattern is to create a new source file that reopens all the types in the hierarchy and inserts an appropriate method implementation in each one. No modifications to the original source code are required.
Scala does not support open types, of course, but it offers a few alternatives.
The first approach we’ll discuss combines pattern matching with implicit conversions.
Let’s begin by refactoring the ShapeVisitor code to remove the visitor pattern logic.
// code-examples/AppDesign/patterns/shapes.scala
package shapes2 {
case class Point(x: Double, y: Double)
sealed abstract class Shape()
case class Circle(center: Point, radius: Double) extends Shape()
case class Rectangle(lowerLeft: Point, height: Double, width: Double)
extends Shape()
case class Triangle(point1: Point, point2: Point, point3: Point)
extends Shape()
}If we would like to invoke draw as a method on any Shape, then we will have
to use an implicit conversion to a wrapper class with the draw method.
// code-examples/AppDesign/patterns/shapes-drawing-implicit.scala
package shapes2 {
class ShapeDrawer(val shape: Shape) {
def draw = shape match {
case c: Circle => println("Circle.draw: " + c)
case r: Rectangle => println("Rectangle.draw: " + r)
case t: Triangle => println("Triangle.draw: " + t)
}
}
object ShapeDrawer {
implicit def shape2ShapeDrawer(shape: Shape) = new ShapeDrawer(shape)
}
}Instances of ShapeDrawer hold a Shape object. When draw is called,
the shape is pattern matched based on its type to determine the appropriate
way to draw it.
A companion object declares an implicit conversion that wraps a Shape in a
ShapeDrawer.
This script exercises the code.
// code-examples/AppDesign/patterns/shapes-drawing-implicit-script.scala
import shapes2._
val p00 = Point(0.0, 0.0)
val p10 = Point(1.0, 0.0)
val p01 = Point(0.0, 1.0)
val list = List(Circle(p00, 5.0),
Rectangle(p00, 2.0, 3.0),
Triangle(p00, p10, p01))
import shapes2.ShapeDrawer._
list foreach { _.draw }It produces the same output as the example using the visitor pattern.
Technically, the implementation has the same OCP issue as the visitor pattern.
Changing the Shape hierarchy requires a change to the pattern matching expression. However,
the required changes are isolated to one place and they are more succinct. In fact, all the logic
for drawing is now contained in one place, rather than separated into draw methods in each Shape class
and potentially scattered across different files.
Note that because we
sealed the hierarchy, a compilation error in draw will occur if we forget
to change it when the hierarchy changes.
If we don’t like the pattern matching in the draw method, we could implement a
separate “drawer” class and a separate implicit conversion for each Shape class.
That would allow us to keep each shape drawing operation in a separate file, for
modularity, with the drawback of more code and files to manage.
If, on the other hand, we don’t care about using the object-oriented shape.draw syntax, We could
eliminate the implicit conversion and do the same pattern matching that is done
in ShapeDrawer.draw. This approach could be simpler, especially when the extra behavior
can be isolated to one place. Indeed, this approach would be a conventional functional
approach, as illustrated in the following script.
// code-examples/AppDesign/patterns/shapes-drawing-pattern-script.scala
import shapes2._
val p00 = Point(0.0, 0.0)
val p10 = Point(1.0, 0.0)
val p01 = Point(0.0, 1.0)
val list = List(Circle(p00, 5.0),
Rectangle(p00, 2.0, 3.0),
Triangle(p00, p10, p01))
val drawText = (shape:Shape) => shape match {
case circle: Circle => println("Circle.draw: " + circle)
case rect: Rectangle => println("Rectangle.draw: " + rect)
case tri: Triangle => println("Triangle.draw: " + tri)
}
def pointToXML(point: Point) =
"<point><x>%.1f</x><y>%.1f</y></point>".format(point.x, point.y)
val drawXML = (shape:Shape) => shape match {
case circle: Circle => {
println("<circle>")
println(" <center>" + pointToXML(circle.center) + "</center>")
println(" <radius>" + circle.radius + "</radius>")
println("</circle>")
}
case rect: Rectangle => {
println("<rectangle>")
println(" <lower-left>" + pointToXML(rect.lowerLeft) + "</lower-left>")
println(" <height>" + rect.height + "</height>")
println(" <width>" + rect.width + "</width>")
println("</rectangle>")
}
case tri: Triangle => {
println("<triangle>")
println(" <point1>" + pointToXML(tri.point1) + "</point1>")
println(" <point2>" + pointToXML(tri.point2) + "</point2>")
println(" <point3>" + pointToXML(tri.point3) + "</point3>")
println("</triangle>")
}
}
list foreach (drawText)
println("")
list foreach (drawXML)We define two function values and assign them to variables, drawText and drawXML, respectively.
Each drawX function takes an input Shape, pattern matches it to the correct type, and “draws” it appropriately.
We also define a helper method to convert a Point to XML in the format we want.
Finally, we loop through the list of shapes twice. The first time, we pass drawText as the argument
to foreach. The second time, we pass drawXML. Running this script reproduces the previous results
for “text” output, followed by new XML output.
Circle.draw: Circle(Point(0.0,0.0),5.0) Rectangle.draw: Rectangle(Point(0.0,0.0),2.0,3.0) Triangle.draw: Triangle(Point(0.0,0.0),Point(1.0,0.0),Point(0.0,1.0)) <circle> <center><point><x>0.0</x><y>0.0</y></point></center> <radius>5.0</radius> </circle> <rectangle> <lower-left><point><x>0.0</x><y>0.0</y></point></lower-left> <height>2.0</height> <width>3.0</width> </rectangle> <triangle> <point1><point><x>0.0</x><y>0.0</y></point></point1> <point2><point><x>1.0</x><y>0.0</y></point></point2> <point3><point><x>0.0</x><y>1.0</y></point></point3> </triangle>
Any of these idioms provides a powerful way to add additional, special-purpose functionality that may not be needed “everywhere” in the application. It’s a great way to remove methods from objects that don’t absolutely have to be there.
A drawing application should only need to know how to do input and output of shapes in one place, whether it is serializing shapes
to a textual format for storage or rendering shapes to the screen. We can separate the drawing “concern” from the rest of the functionality for shapes and we can isolate the logic for drawing, all without modifying the Shape hierarchy or any of the places where
it is used in the application. The visitor pattern gives us some of this separation and isolation, but we are required to add visitor implementation logic to each Shape.
Let’s conclude with a discussion of one other option that may be applicable in some contexts. If you have complete control over how shapes are constructed, e.g., through a single factory, you can modify the factory to mix in traits that add new behaviors as needed.
// code-examples/AppDesign/patterns/shapes-drawing-factory.scala
package shapes2 {
trait Drawing {
def draw: Unit
}
trait CircleDrawing extends Drawing {
def draw = println("Circle.draw " + this)
}
trait RectangleDrawing extends Drawing {
def draw = println("Rectangle.draw: " + this)
}
trait TriangleDrawing extends Drawing {
def draw = println("Triangle.draw: " + this)
}
object ShapeFactory {
def makeShape(args: Any*) = args(0) match {
case "circle" => {
val center = args(1).asInstanceOf[Point]
val radius = args(2).asInstanceOf[Double]
new Circle(center, radius) with CircleDrawing
}
case "rectangle" => {
val lowerLeft = args(1).asInstanceOf[Point]
val height = args(2).asInstanceOf[Double]
val width = args(3).asInstanceOf[Double]
new Rectangle(lowerLeft, height, width) with RectangleDrawing
}
case "triangle" => {
val p1 = args(1).asInstanceOf[Point]
val p2 = args(2).asInstanceOf[Point]
val p3 = args(3).asInstanceOf[Point]
new Triangle(p1, p2, p3) with TriangleDrawing
}
case x => throw new IllegalArgumentException("unknown: " + x)
}
}
}We define a Drawing trait and concrete derived traits for each Shape class.
Then we define a ShapeFactory object with a makeShape factory method that
takes a variable-length list of arguments. A match is done on the first argument to
determine which shape to make. The trailing arguments are cast to appropriate types
to construct each shape, with the corresponding drawing trait mixed in. A similar
factory could be written for adding draw methods that output XML.
(The variable-length list of Any values, heavy use of casting, and minimal error
checking were done for expediency. A real implementation could minimize these “hacks”.)
The following script exercises the factory.
// code-examples/AppDesign/patterns/shapes-drawing-factory-script.scala
import shapes2._
val p00 = Point(0.0, 0.0)
val p10 = Point(1.0, 0.0)
val p01 = Point(0.0, 1.0)
val list = List(
ShapeFactory.makeShape("circle", p00, 5.0),
ShapeFactory.makeShape("rectangle", p00, 2.0, 3.0),
ShapeFactory.makeShape("triangle", p00, p10, p01))
list foreach { _.draw }Compared to our previous scripts, the list of shapes is now constructed using the factory.
When we want to draw the shapes in the foreach statement, we simply call draw on each
shape. As before, the output is the following.
Circle.draw Circle(Point(0.0,0.0),5.0) Rectangle.draw: Rectangle(Point(0.0,0.0),2.0,3.0) Triangle.draw: Triangle(Point(0.0,0.0),Point(1.0,0.0),Point(0.0,1.0))
There is one subtlety with this approach that we should discuss. Notice that the script
never assigns the result of a ShapeFactory.makeShape call to a Shape variable. If it
did that, it would not be able to call draw on the instance!
In this script, Scala inferred a slightly different common super type for the parameterized
list. You can see that type if you use the :load command to load the script while inside
the interactive scala interpreter, as in the following session.
$ scala -cp ... Welcome to Scala version 2.8.0.final (Java ...). Type in expressions to have them evaluated. Type :help for more information. scala> :load design-patterns/shapes-drawing-factory-script.scala Loading design-patterns/shapes-drawing-factory-script.scala... import shapes2._ p00: shapes2.Point = Point(0.0,0.0) p10: shapes2.Point = Point(1.0,0.0) p01: shapes2.Point = Point(0.0,1.0) list: List[Product with shapes2.Shape with shapes2.Drawing] = List(...) Circle.draw Circle(Point(0.0,0.0),5.0) Rectangle.draw: Rectangle(Point(0.0,0.0),2.0,3.0) Triangle.draw: Triangle(Point(0.0,0.0),Point(1.0,0.0),Point(0.0,1.0)) scala>
Notice the line that begins list: List[Product with shapes2.Shape with shapes2.Drawing].
This line was printed after the list of shapes was parsed.
The inferred common super type is Product with shapes2.Shape with shapes2.Drawing.
Product is a trait mixed into all case classes, such as our concrete subclasses of Shape.
Recall that to avoid case-class inheritance, Shape itself is not a case class.
(see the section called “Case Classes” in Chapter 6, Advanced Object-Oriented Programming In Scala for details on why case
class inheritance should be avoided.)
So, our common super type is an anonymous class that incorporates Shape, Product,
and the Drawing trait.
If you want to assign one of these drawable shapes to a variable and still be able
to invoke draw, use a declaration like the following (shown as a continuation of
the same interactive scala session).
scala> val s: Shape with Drawing = ShapeFactory.makeShape("circle", p00, 5.0)
s: shapes2.Shape with shapes2.Drawing = Circle(Point(0.0,0.0),5.0)
scala> s.draw
Circle.draw Circle(Point(0.0,0.0),5.0)
scala>Dependency Injection (DI), a form of Inversion of Control (IoC), is a powerful technique for resolving dependencies between “components” in larger applications. It supports minimizing the coupling between these components, so it is relatively easy to substitute different components for different circumstances.
It used to be that when a client object needed a database “accessor” object, for example, it would just instantiate the accessor itself. While convenient, this approach makes unit testing very difficult, because you have to test with a real database. It also compromises reuse, for those alternative situations where another persistence mechanism (or none) is required. Inversion of control solves this problem by reversing responsibility for satisfying the dependency between the object and the database connection.
An example of IoC is JNDI. Instead of instantiating an accessor object, the client object asks JDNI to provide one. The client doesn’t care what actual type of accessor is returned. Hence, the client object is no longer coupled to a concrete implementation of the dependency. It only depends on an appropriate abstraction of a persistence accessor, i.e., a Java interface or Scala trait.
Dependency injection takes IoC to its logical conclusion. Now the object does nothing to resolve the dependency. Instead, an external mechanism with system-wide knowledge “injects” the appropriate accessor object using a constructor argument or a setter method. This happens when the client is constructed. DI eliminates dependencies on IoC mechanisms in code (e.g., no more JNDI calls) and keeps objects relatively simple, with minimal coupling to other objects.
Back to unit testing, it is preferable to use a test double for heavyweight dependencies to minimize the overhead and other complications of testing. Our client object with a dependency on a database accessor object is a classic example. While unit testing the client, the overhead and complications of using a real database are prohibitive. Using a lightweight test double with hard-coded sample data provides simpler setup and tear down, faster execution, and predictable behavior from the data accessor dependency.
In Java, DI is usually done using an inversion of control container, like the Spring Framework [SpringFramework], or a Java-API equivalent, like Google’s Guice API [Guice]. These options can be used with Scala code, especially when you are introducing Scala into a mature Java environment.
However, Scala offers some unique options for implementing DI in Scala code, which are discussed by [Bonér2008b]. We’ll discuss one of them, the Cake Pattern, which can replace or complement these other dependency injection mechanisms. We’ll see that it is similar to the implementation of the observer pattern we discussed earlier in this chapter, in the section called “Self-Type Annotations and Abstract Type Members”. The cake pattern was described by [Odersky2005], although it was given that name after that paper was published. [Bonér2008b] also discusses alternatives.
Let’s build a simple component model for an overly-simplified Twitter client. We want a configurable UI, a configurable local cache of past tweets, and a configurable connection to the Twitter service itself. Each of these “components” will be specified separately, along with a client component that will function as the “middleware” that ties the application together. The client component will depend on the other components. When we create a concrete client, we’ll configure in the concrete pieces of the other components that we need.
I've got to reread this, but I wanted to see an example that showed unit testing and "production" configuration of a single trait/component.
This pattern has always seemed a little abstract to me, and I hope this kind of example would ground it.
// code-examples/AppDesign/dep-injection/twitter-client.scala
package twitterclient
import java.util.Date
import java.text.DateFormat
class TwitterUserProfile(val userName: String) {
override def toString = "@" + userName
}
case class Tweet(
val tweeter: TwitterUserProfile,
val message: String,
val time: Date) {
override def toString = "(" +
DateFormat.getDateInstance(DateFormat.FULL).format(time) + ") " +
tweeter + ": " + message
}
trait Tweeter {
def tweet(message: String)
}
trait TwitterClientUIComponent {
val ui: TwitterClientUI
abstract class TwitterClientUI(val client: Tweeter) {
def sendTweet(message: String) = client.tweet(message)
def showTweet(tweet: Tweet): Unit
}
}
trait TwitterLocalCacheComponent {
val localCache: TwitterLocalCache
trait TwitterLocalCache {
def saveTweet(tweet: Tweet): Unit
def history: List[Tweet]
}
}
trait TwitterServiceComponent {
val service: TwitterService
trait TwitterService {
def sendTweet(tweet: Tweet): Boolean
def history: List[Tweet]
}
}
trait TwitterClientComponent {
self: TwitterClientUIComponent with
TwitterLocalCacheComponent with
TwitterServiceComponent =>
val client: TwitterClient
class TwitterClient(val user: TwitterUserProfile) extends Tweeter {
def tweet(msg: String) = {
val twt = new Tweet(user, msg, new Date)
if (service.sendTweet(twt)) {
localCache.saveTweet(twt)
ui.showTweet(twt)
}
}
}
}The first class, TwitterUserProfile, encapsulates a user’s profile, which we limit to the user name. The second class is a case class, Tweet, that encapsulates a single “tweet” (a Twitter message, limited to 140 characters by the Twitter service). Besides the message string, it encapsulates the user who sent the tweet and the date and time when it was sent. We made this class a case class for the convenient support case classes provide for creating objects and pattern matching on them. We didn’t make the profile class a case class, because it is more likely to be used as the parent of more detailed profile classes.
Next is the Tweeter trait that declares one method, tweet. This trait is defined solely to eliminate a potential circular dependency between two components, TwitterClientComponent and TwitterClientUIComponent. All the components are defined next in the file.
There are four “components”. Note that they are implemented as traits.
TwitterClientUIComponent, for the UI.
TwitterLocalCacheComponent, for the local cache of prior tweets.
TwitterServiceComponent, for accessing the Twitter service.
TwitterClientComponent, the client that pulls the pieces together.
They all have a similar structure. Each one declares a nested trait or class that encapsulates the component’s behavior. Each one also declares a val with one instance of the nested type.
Often in Java, packages are informally associated with components. This is common in other languages, too, using their equivalent of a package, e.g., a module or a namespace. Here we define a more precise notion of a component and a trait is the best vehicle for it, because traits are designed for mixin composition.
TwitterClientUIComponent declares a val named ui of the nested type TwitterClientUI. This class has a client field that must be initialized with a Tweeter instance. In fact, this instance will be a TwitterClient (defined in TwitterClientComponent), which extends Tweeter.
TwitterClientUI has two methods. The first is sendTweet, which is defined to call the client object. This method would be used by the UI to call the client when the user sends a new tweet. The second method, showTweet, goes the other direction. It is called whenever a new tweet is to be displayed, e.g., from another user. It is abstract, pending the “decision” of the kind of UI to use.
Similarly, TwitterLocalCacheComponent declares TwitterLocalCache and an instance of it. Instances with this trait save tweets to the local persistent cache when saveTweet is called. You can retrieve the cached tweets with history.
TwitterServiceComponent is very similar. Its nested type has a method, sendTweet, that sends a new tweet to Twitter. It also has a history method that retrieves all the tweets for the current user.
Finally, TwitterClientComponent contains a concrete class, TwitterClient, that integrates the components. Its one tweet method sends new tweets to the Twitter service. If successful, it sends the tweet back to the UI and to the local persistent cache.
TwitterClientComponent also has the following self-type annotation.
self: TwitterClientUIComponent with
TwitterLocalCacheComponent with
TwitterServiceComponent =>The effect of this declaration is to say that any concrete TwitterClientComponent must also behave like these other three components, thereby composing all the components into one client application instance. This composition will be realized by mixing in these components, which are traits, when we create concrete clients, as we will see shortly.
The self-type annotation also means we can reference the vals declared in these components. Notice how TwitterClient.tweet references the service, localCache, and the ui as if they are variables in the scope of this method. In fact, they are in scope, because of the self-type annotation.
Notice also that all the methods that call other components are concrete. Those inter-component relationships are fully specified. The abstractions are directed “outwards”, towards the graphical user interface, a caching mechanism, etc.
Let’s now define a concrete Twitter client that uses a textual (command-line) UI, an in-memory local cache, and fakes the interaction with the Twitter service.
// code-examples/AppDesign/dep-injection/twitter-text-client.scala
package twitterclient
class TextClient(userProfile: TwitterUserProfile)
extends TwitterClientComponent
with TwitterClientUIComponent
with TwitterLocalCacheComponent
with TwitterServiceComponent {
// From TwitterClientComponent:
val client = new TwitterClient(userProfile)
// From TwitterClientUIComponent:
val ui = new TwitterClientUI(client) {
def showTweet(tweet: Tweet) = println(tweet)
}
// From TwitterLocalCacheComponent:
val localCache = new TwitterLocalCache {
private var tweets: List[Tweet] = Nil
def saveTweet(tweet: Tweet) = tweets ::= tweet
def history = tweets
}
// From TwitterServiceComponent
val service = new TwitterService() {
def sendTweet(tweet: Tweet) = {
println("Sending tweet to Twitter HQ")
true
}
def history = List[Tweet]()
}
}Our TextClient concrete class extends TwitterClientComponent and mixes in the three other components. By mixing in the other components, we satisfy the self-type annotations in TwitterClientComponent. In other words, TextClient is also a
TwitterClientUIComponent, a TwitterLocalCacheComponent, and a TwitterServiceComponent, in addition to being a TwitterClientComponent.
The TextClient constructor takes one argument, a user profile, which will be passed onto the nested client class.
TextClient has to define four vals, one from TwitterClientComponent and three from the other mixins. For the client, it simply creates a new TwitterClient, passing it the userProfile.
For the ui, it instantiates an anonymous class derived from TwitterClientUI. It defines showTweet to print out the tweet.
For the localCache, it instantiates an anonymous class derived from TwitterLocalCache. It keeps the history of tweets in a List.
Finally, for the service, it instantiates an anonymous class derived from TwitterService. This “fake” defines sendTweet to print out a message and to return an empty list for the history.
Let’s try our client with the following script.
// code-examples/AppDesign/dep-injection/twitter-text-client-script.scala
import twitterclient._
val client = new TextClient(new TwitterUserProfile("BuckTrends"))
client.ui.sendTweet("My First Tweet. How's this thing work?")
client.ui.sendTweet("Is this thing on?")
client.ui.sendTweet("Heading to the bathroom...")
println("Chat history:")
client.localCache.history.foreach {t => println(t)}We instantiate a TextClient for the user “BuckTrends”. Old Buck sends three insightful tweets through the UI. We finish by reprinting the history of tweets, in reverse order, that are cached locally. Running this script yields output like the following.
Sending tweet to Twitter HQ (Sunday, May 3, 2009) @BuckTrends: My First Tweet. How's this thing work? Sending tweet to Twitter HQ (Sunday, May 3, 2009) @BuckTrends: Is this thing on? Sending tweet to Twitter HQ (Sunday, May 3, 2009) @BuckTrends: Heading to the bathroom... Chat history: (Sunday, May 3, 2009) @BuckTrends: Heading to the bathroom... (Sunday, May 3, 2009) @BuckTrends: Is this thing on? (Sunday, May 3, 2009) @BuckTrends: My First Tweet. How's this thing work?
Your date will vary, of course. Recall that the Sending tweet to Twitter HQ line is printed by the fake service.
To recap, each major component in the Twitter client was declared in its own trait, with a nested type for the component’s fields and methods. The client component declared its dependencies on the other components through a self-type annotation. The concrete client class mixed in those components and defined each component val to be an appropriate subtype of the corresponding abstract classes and traits that were declared in the components.
We get type-safe “wiring” together of components, a flexible component model, and we did it all in Scala code! There are alternatives to the cake pattern for implementing dependency injection in Scala. See [Bonér2008b] for other examples.
We’ll conclude this chapter with a look at an approach to programming called Design by Contract [DesignByContract], which was developed by Bertrand Meyer for the Eiffel language [Eiffel]. (See also [Hunt2000], Chapter 4.). Design by Contract has been around for about twenty years. It has fallen somewhat out of favor, but it is still very useful for thinking about design.
When considering the "contract" of a module, you can specify three types of conditions. First, you can specify the required inputs for a module to successfully perform a service (e.g., when a method is called) These constraints are called preconditions. They can also include system requirements, e.g., global data (which you should normally avoid, of course).
You can also specify the results the module guarantees to deliver, the postconditions, if the preconditions were satisfied.
Finally, you can specify invariants that must be true before and after an invocation of a service.
The specific addition that Design by Contract brings is the idea that these contractual constraints should be specified as executable code, so they can be enforced automatically at runtime, but usually only during testing.
A constraint failure should terminate execution immediately, forcing you to fix the bug. Otherwise, it is very easy to ignore these bugs.
Scala doesn’t provide explicit support for Design by Contract, but
there are several methods in Predef that can be used for this
purpose. The following example shows how to use require and assume
for contract enforcement.
// code-examples/AppDesign/design-by-contract/bank-account.scala
class BankAccount(val balance: Double) {
require(balance >= 0.0)
def debit(amount: Double) = {
require(amount > 0.0, "The debit amount must be > 0.0")
assume(balance - amount > 0.0, "Overdrafts are not permitted")
new BankAccount(balance - amount)
}
def credit(amount: Double) = {
require(amount > 0.0, "The credit amount must be > 0.0")
new BankAccount(balance + amount)
}
}Class BankAccount uses require to ensure that a non-negative
balance is specified for the constructor. Similarly, the debit and
credit methods use require to ensure that a positive amount is
specified.
The following specification confirms that the “contract” is obeyed.
Example 13.1. design-by-contract/bank-account-spec.scala: Testing the contract.
// code-examples/AppDesign/design-by-contract/bank-account-spec.scala
import org.specs._
object BankAccountSpec extends Specification {
"Creating an account with a negative balance" should {
"fail because the initial balance must be positive." in {
new BankAccount(-100.0) must throwAn[IllegalArgumentException]
}
}
"Debiting an account" should {
"fail if the debit amount is < 0" in {
val account = new BankAccount(100.0)
(account.debit(-10.0)) must throwAn[IllegalArgumentException]
}
}
"Debiting an account" should {
"fail if the debit amount is > the balance" in {
val account = new BankAccount(100.0)
(account.debit(110.0)) must throwAn[AssertionError]
}
}
}If we attempt to create a BankAccount with a negative balance, an
IllegalArgumentException is thrown. Similarly, the same kind of
exception is thrown if the debit amount is less than zero. Both
conditions are enforced using require, which throws an
IllegalArgumentException when the condition specified is false.
The assume method, which is used to ensure that overdrafts don’t
occur, is functionally almost identical to require. It throws an
AssertionError instead of an IllegalArgumentException.
Both require and assume come in two forms, one which takes just a
boolean condition and the other which also takes an error message
string.
There is also an assert pair of methods that behave identically to
assume, except for a slight change in the generated failure message.
Pick assert or assume depending on which of these “names”
provides a better conceptual fit in a given context.
Predef also defines an Ensuring class that can be used to
generalize the capabilities of these methods. Ensuring has one
overloaded method, ensure, some versions of which take a function
literal as a “predicate”.
A drawback of using these methods and Ensuring is that you can’t
disable these checks in production. It may not be acceptable to
terminate abruptly if a condition fails, although if the system is
allowed to "limp along" it might crash later and the problem would be
harder to debug. The performance overhead may be another reason to
disable contract checks at runtime.
These days, the goals of Design by Contract are largely met by Test-Driven Development (TDD). However, thinking in terms of Design by Contract will complement the design benefits of TDD. If you decide to use Design by Contract in your code, consider creating a custom module that lets you disable the tests for production code.
We learned a number of pragmatic techniques, patterns and idioms for effective application development using Scala.
Good tools and libraries are important for building applications in any language. The next chapter provides more details about Scala’s command-line tools, describes the state of Scala IDE support, and introduces you to some important Scala libraries.
No comments yet
Add a comment