|
|
Version: 3.0.2 |


Table of Contents
This section describes how does wxWidgets support Unicode and how can it affect your programs.
Notice that Unicode support has changed radically in wxWidgets 3.0 and a lot of existing material pertaining to the previous versions of the library is not correct any more. Please see Unicode-related Changes for the details of these changes.
You can skip the first two sections if you're already familiar with Unicode and wish to jump directly in the details of its support in the library.
What is Unicode?
Unicode is a standard for character encoding which addresses the shortcomings of the previous standards (e.g. the ASCII standard), by using 8, 16 or 32 bits for encoding each character. This allows enough code points (see below for the definition) sufficient to encode all of the world languages at once. More details about Unicode may be found at http://www.unicode.org/.
From a practical point of view, using Unicode is almost a requirement when writing applications for international audience. Moreover, any application reading files which it didn't produce or receiving data from the network from other services should be ready to deal with Unicode.
Unicode Representations and Terminology
When working with Unicode, it's important to define the meaning of some terms.
A glyph is a particular image (usually part of a font) that represents a character or part of a character. Any character may have one or more glyph associated; e.g. some of the possible glyphs for the capital letter 'A' are:
Unicode assigns each character of almost any existing alphabet/script a number, which is called code point; it's typically indicated in documentation manuals and in the Unicode website as U+xxxx where xxxx is an hexadecimal number.
Note that typically one character is assigned exactly one code point, but there are exceptions; the so-called precomposed characters (see http://en.wikipedia.org/wiki/Precomposed_character) or the ligatures. In these cases a single "character" may be mapped to more than one code point or vice versa more than one character may be mapped to a single code point.
The Unicode standard divides the space of all possible code points in planes; a plane is a range of 65,536 (1000016) contiguous Unicode code points. Planes are numbered from 0 to 16, where the first one is the BMP, or Basic Multilingual Plane. The BMP contains characters for all modern languages, and a large number of special characters. The other planes in fact contain mainly historic scripts, special-purpose characters or are unused.
Code points are represented in computer memory as a sequence of one or more code units, where a code unit is a unit of memory: 8, 16, or 32 bits. More precisely, a code unit is the minimal bit combination that can represent a unit of encoded text for processing or interchange.
The UTF or Unicode Transformation Formats are algorithms mapping the Unicode code points to code unit sequences. The simplest of them is UTF-32 where each code unit is composed by 32 bits (4 bytes) and each code point is always represented by a single code unit (fixed length encoding). (Note that even UTF-32 is still not completely trivial as the mapping is different for little and big-endian architectures). UTF-32 is commonly used under Unix systems for internal representation of Unicode strings.
Another very widespread standard is UTF-16 which is used by Microsoft Windows: it encodes the first (approximately) 64 thousands of Unicode code points (the BMP plane) using 16-bit code units (2 bytes) and uses a pair of 16-bit code units to encode the characters beyond this. These pairs are called surrogate. Thus UTF16 uses a variable number of code units to encode each code point.
Finally, the most widespread encoding used for the external Unicode storage (e.g. files and network protocols) is UTF-8 which is byte-oriented and so avoids the endianness ambiguities of UTF-16 and UTF-32. UTF-8 uses code units of 8 bits (1 byte); code points beyond the usual english alphabet are represented using a variable number of bytes, which makes it less efficient than UTF-32 for internal representation.
As visual aid to understand the differences between the various concepts described so far, look at the different UTF representations of the same code point:
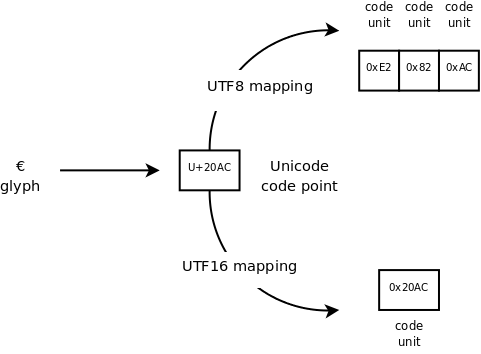
In this particular case UTF8 requires more space than UTF16 (3 bytes instead of 2).
Note that from the C/C++ programmer perspective the situation is further complicated by the fact that the standard type wchar_t which is usually used to represent the Unicode ("wide") strings in C/C++ doesn't have the same size on all platforms. It is 4 bytes under Unix systems, corresponding to the tradition of using UTF-32, but only 2 bytes under Windows which is required by compatibility with the OS which uses UTF-16.
Typically when UTF8 is used, code units are stored into char types, since char are 8bit wide on almost all systems; when using UTF16 typically code units are stored into wchar_t types since wchar_t is at least 16bits on all systems. This is also the approach used by wxString. See wxString Overview for more info.
See also http://unicode.org/glossary/ for the official definitions of the terms reported above.
Unicode Support in wxWidgets
Unicode is Always Used by Default
Since wxWidgets 3.0 Unicode support is always enabled and while building the library without it is still possible, it is not recommended any longer and will cease to be supported in the near future. This means that internally only Unicode strings are used and that, under Microsoft Windows, Unicode system API is used which means that wxWidgets programs require the Microsoft Layer for Unicode to run on Windows 95/98/ME.
However, unlike the Unicode build mode of the previous versions of wxWidgets, this support is mostly transparent: you can still continue to work with the narrow (i.e. current locale-encoded char*) strings even if wide (i.e. UTF16-encoded wchar_t* or UTF8-encoded char*) strings are also supported. Any wxWidgets function accepts arguments of either type as both kinds of strings are implicitly converted to wxString, so both
and the somewhat less usual
work as expected.
Notice that the narrow strings used with wxWidgets are always assumed to be in the current locale encoding, so writing
wouldn't work if the encoding used on the user system is incompatible with ISO-8859-1 (or even if the sources were compiled under different locale in the case of gcc). In particular, the most common encoding used under modern Unix systems is UTF-8 and as the string above is not a valid UTF-8 byte sequence, nothing would be displayed at all in this case. Thus it is important to never use 8-bit (instead of 7-bit) characters directly in the program source but use wide strings or, alternatively, write:
In a similar way, wxString provides access to its contents as either wchar_t or char character buffer. Of course, the latter only works if the string contains data representable in the current locale encoding. This will always be the case if the string had been initially constructed from a narrow string or if it contains only 7-bit ASCII data but otherwise this conversion is not guaranteed to succeed. And as with wxString::FromUTF8() example above, you can always use wxString::ToUTF8() to retrieve the string contents in UTF-8 encoding – this, unlike converting to char* using the current locale, never fails.
For more info about how wxString works, please see the wxString Overview.
To summarize, Unicode support in wxWidgets is mostly transparent for the application and if you use wxString objects for storing all the character data in your program there is really nothing special to do. However you should be aware of the potential problems covered by the following section.
Choosing Unicode Representation
wxWidgets uses the system wchar_t in wxString implementation by default under all systems. Thus, under Microsoft Windows, UCS-2 (simplified version of UTF-16 without support for surrogate characters) is used as wchar_t is 2 bytes on this platform. Under Unix systems, including Mac OS X, UCS-4 (also known as UTF-32) is used by default, however it is also possible to build wxWidgets to use UTF-8 internally by passing –enable-utf8 option to configure.
The interface provided by wxString is the same independently of the format used internally. However different formats have specific advantages and disadvantages. Notably, under Unix, the underlying graphical toolkit (e.g. GTK+) usually uses UTF-8 encoded strings and using the same representations for the strings in wxWidgets allows to avoid conversion from UTF-32 to UTF-8 and vice versa each time a string is shown in the UI or retrieved from it. The overhead of such conversions is usually negligible for small strings but may be important for some programs. If you believe that it would be advantageous to use UTF-8 for the strings in your particular application, you may rebuild wxWidgets to use UTF-8 as explained above (notice that this is currently not supported under Microsoft Windows and arguably doesn't make much sense there as Windows itself uses UTF-16 and not UTF-8) but be sure to be aware of the performance implications (see Performance Implications of Using UTF-8) of using UTF-8 in wxString before doing this!
Generally speaking you should only use non-default UTF-8 build in specific circumstances e.g. building for resource-constrained systems where the overhead of conversions (and also reduced memory usage of UTF-8 compared to UTF-32 for the European languages) can be important. If the environment in which your program is running is under your control – as is quite often the case in such scenarios – consider ensuring that the system always uses UTF-8 locale and use –enable-utf8only configure option to disable support for the other locales and consider all strings to be in UTF-8. This further reduces the code size and removes the need for conversions in more cases.
Unicode Related Preprocessor Symbols
wxUSE_UNICODE is defined as 1 now to indicate Unicode support. It can be explicitly set to 0 in setup.h under MSW or you can use –disable-unicode under Unix but doing this is strongly discouraged. By default, wxUSE_UNICODE_WCHAR is also defined as 1, however in UTF-8 build (described in the previous section), it is set to 0 and wxUSE_UNICODE_UTF8, which is usually 0, is set to 1 instead. In the latter case, wxUSE_UTF8_LOCALE_ONLY can also be set to 1 to indicate that all strings are considered to be in UTF-8.
Potential Unicode Pitfalls
The problems can be separated into three broad classes:
Unicode-Related Compilation Errors
Because of the need to support implicit conversions to both char and wchar_t, wxString implementation is rather involved and many of its operators don't return the types which they could be naively expected to return. For example, the operator[] doesn't return neither a char nor a wchar_t but an object of a helper class wxUniChar or wxUniCharRef which is implicitly convertible to either. Usually you don't need to worry about this as the conversions do their work behind the scenes however in some cases it doesn't work. Here are some examples, using a wxString object s and some integer n:
- Writing doesn't work because the argument of the switch statement must be an integer expression so you need to replaceswitch ( s[n] )
s[n] with. You may also force the conversion tos[n].GetValue()charorwchar_tby using an explicit cast but beware that converting the value to char uses the conversion to current locale and may return 0 if it fails. Finally notice that writingworks both with wxWidgets 3.0 and previous library versions and so should be used for writing code which should be compatible with both 2.8 and 3.0.(wxChar)s[n]
- Similarly, doesn't yield a pointer to char so you may not pass it to functions expecting&s[n]
char*orwchar_t*. Consider using string iterators instead if possible or replace this expression withotherwise.s.c_str() + n
Another class of problems is related to the fact that the value returned by c_str() itself is also not just a pointer to a buffer but a value of helper class wxCStrData which is implicitly convertible to both narrow and wide strings. Again, this mostly will be unnoticeable but can result in some problems:
You shouldn't pass
c_str()result to vararg functions such as standardprintf(). Some compilers (notably g++) warn about this but even if they don't, thisprintf("Hello, %s", s.c_str())is not going to work. It can be corrected in one of the following ways:
- Preferred: (notice the absence ofwxPrintf("Hello, %s", s)
c_str(), it is not needed at all with wxWidgets functions) - Compatible with wxWidgets 2.8: wxPrintf("Hello, %s", s.c_str())
- Using an explicit conversion to narrow, multibyte, string:
- Using a cast to force the issue (listed only for completeness):
- Preferred:
- The result of
c_str()cannot be cast tochar*but only toconstchar*.const_casthere to pass the value to const-incorrect functions. This can be done either using new wxString::char_str() (and matching wchar_str()) method or by writing a double cast:
- One of the unfortunate consequences of the possibility to pass wxString to
wxPrintf()without usingc_str()is that it is now impossible to pass the elements of unnamed enumerations towxPrintf()and other similar vararg functions, i.e.doesn't compile. The easiest workaround is to give a name to the enum.enum { Red, Green, Blue };wxPrintf("Red is %d", Red);
Other unexpected compilation errors may arise but they should happen even more rarely than the above-mentioned ones and the solution should usually be quite simple: just use the explicit methods of wxUniChar and wxCStrData classes instead of relying on their implicit conversions if the compiler can't choose among them.
Data Loss due To Unicode Conversion Errors
wxString API provides implicit conversion of the internal Unicode string contents to narrow, char strings. This can be very convenient and is absolutely necessary for backwards compatibility with the existing code using wxWidgets however it is a rather dangerous operation as it can easily give unexpected results if the string contents isn't convertible to the current locale.
To be precise, the conversion will always succeed if the string was created from a narrow string initially. It will also succeed if the current encoding is UTF-8 as all Unicode strings are representable in this encoding. However initializing the string using wxString::FromUTF8() method and then accessing it as a char string via its wxString::c_str() method is a recipe for disaster as the program may work perfectly well during testing on Unix systems using UTF-8 locale but completely fail under Windows where UTF-8 locales are never used because wxString::c_str() would return an empty string.
The simplest way to ensure that this doesn't happen is to avoid conversions to char* completely by using wxString throughout your program. However if the program never manipulates 8 bit strings internally, using char* pointers is safe as well. So the existing code needs to be reviewed when upgrading to wxWidgets 3.0 and the new code should be used with this in mind and ideally avoiding implicit conversions to char*.
Performance Implications of Using UTF-8
As mentioned above, under Unix systems wxString class can use variable-width UTF-8 encoding for internal representation. In this case it can't guarantee constant-time access to N-th element of the string any longer as to find the position of this character in the string we have to examine all the preceding ones. Usually this doesn't matter much because most algorithms used on the strings examine them sequentially anyhow and because wxString implements a cache for iterating over the string by index but it can have serious consequences for algorithms using random access to string elements as they typically acquire O(N^2) time complexity instead of O(N) where N is the length of the string.
Even despite caching the index, indexed access should be replaced with sequential access using string iterators. For example a typical loop:
should be rewritten as
Another, similar, alternative is to use pointer arithmetic:
however this doesn't work correctly for strings with embedded NUL characters and the use of iterators is generally preferred as they provide some run-time checks (at least in debug build) unlike the raw pointers. But if you do use them, it is better to use wchar_t pointers rather than char ones to avoid the data loss problems due to conversion as discussed in the previous section.
Unicode and the Outside World
Even though wxWidgets always uses Unicode internally, not all the other libraries and programs do and even those that do use Unicode may use a different encoding of it. So you need to be able to convert the data to various representations and the wxString methods wxString::ToAscii(), wxString::ToUTF8() (or its synonym wxString::utf8_str()), wxString::mb_str(), wxString::c_str() and wxString::wc_str() can be used for this.
The first of them should be only used for the string containing 7-bit ASCII characters only, anything else will be replaced by some substitution character. wxString::mb_str() converts the string to the encoding used by the current locale and so can return an empty string if the string contains characters not representable in it as explained in Data Loss due To Unicode Conversion Errors. The same applies to wxString::c_str() if its result is used as a narrow string. Finally, wxString::ToUTF8() and wxString::wc_str() functions never fail and always return a pointer to char string containing the UTF-8 representation of the string or wchar_t string.
wxString also provides two convenience functions: wxString::From8BitData() and wxString::To8BitData(). They can be used to create a wxString from arbitrary binary data without supposing that it is in current locale encoding, and then get it back, again, without any conversion or, rather, undoing the conversion used by wxString::From8BitData(). Because of this you should only use wxString::From8BitData() for the strings created using wxString::To8BitData(). Also notice that in spite of the availability of these functions, wxString is not the ideal class for storing arbitrary binary data as they can take up to 4 times more space than needed (when using wchar_t internal representation on the systems where size of wide characters is 4 bytes) and you should consider using wxMemoryBuffer instead.
Final word of caution: most of these functions may return either directly the pointer to internal string buffer or a temporary wxCharBuffer or wxWCharBuffer object. Such objects are implicitly convertible to char and wchar_t pointers, respectively, and so the result of, for example, wxString::ToUTF8() can always be passed directly to a function taking const char*. However code such as
does not work because the temporary buffer returned by wxString::ToUTF8() is destroyed and p is left pointing nowhere. To correct this you should use
which does work.
Similarly, wxWX2WCbuf can be used for the return type of wxString::wc_str(). But, once again, none of these cryptic types is really needed if you just pass the return value of any of the functions mentioned in this section to another function directly.