Mesos
Mesos采用两级调度来控制集群中的资源配给。不同于集中式的存储集群中的资源信息,它通过资源提供(resource offers)的概念,让运行的框架通过Master获取Agent节点所提供的资源,从而保持整个系统架构的简洁和可扩展性。
Master的分配模块负责确定哪个应用程序应该接收下一次资源提供,并且依赖主导资源公平(DRF)算法来做出这些决策。本文针对不同的用例使用简单的Mesos框架实现来观察和分析DRF行为。
框架
Mesos框架包括两个主要组件:调度器(Scheduler)和执行器(Executor)。
调度器是一个与Master协商的单实例/进程,负责处理资源提供,任务提交,任务状态更新,框架消息和异常情况,例如从丢失,断开和各种错误。有时高可用性是调度器的一个要求,因此需要某种类型的领导者选举(leader election)或特定逻辑来避免任务提交中的冲突。
执行器是在Agent节点上执行的进程,在Agent节点上接收任务并运行它们。执行器生命周期与调度器绑定,所以当Scheduler完成它的工作时,它也关闭执行器(实际上Mesos Master在框架终止时执行这个例程)。如果执行器是一个JVM进程,它通常有一个线程池用于执行接收的任务。
任务信息使用protobuf进行序列化,它包含关于所需的资源,待运行的执行程序,一些二进制序列化的有效负载(例如Spark任务被序列化并作为Mesos任务中的有效载荷传送)等所有的信息。以下是创建任务的示例代码:
def buildTask(offer: Offer, cpus: Double, memory: Int, executorInfo: ExecutorInfo) = {
val cpuResource = Resource.newBuilder
.setType(SCALAR)
.setName("cpus")
.setScalar(Scalar.newBuilder.setValue(cpus))
.setRole("*")
.build
val memResource = Resource.newBuilder
.setType(SCALAR)
.setName("mem")
.setScalar(Scalar.newBuilder.setValue(memory))
.setRole("*")
.build
TaskInfo.newBuilder()
.setSlaveId(SlaveID.newBuilder().setValue(offer.getSlaveId.getValue).build())
.setTaskId(TaskID.newBuilder().setValue(s"$uuid"))
.setExecutor(executorInfo)
.setName(UUID.randomUUID().toString)
.addResources(cpuResource)
.addResources(memResource)
.build()
}
def buildExecutorInfo(d: SchedulerDriver, prefix: String): ExecutorInfo = {
val scriptPath = System.getProperty("executor.path","/throttle/throttle-executor.sh")
ExecutorInfo.newBuilder()
.setCommand(CommandInfo.newBuilder().setValue("/bin/sh "+scriptPath))
.setExecutorId(ExecutorID.newBuilder().setValue(s"${prefix}_$uuid"))
.build()
}资源提供(Resource Offers)
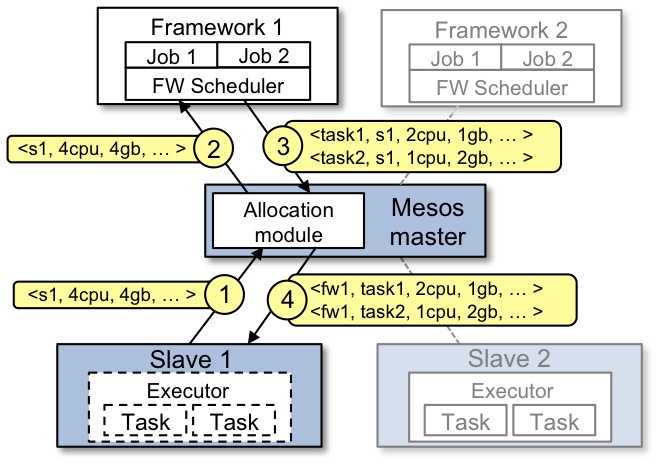
Agent节点定期向Master汇报它们所能提供的资源。
分配模块开始向框架提供资源,并使用主导资源公平算法来决定可以提供资源的候选框架的顺序。接收到资源供给的框架可以根据其需求接受或拒绝。在拒绝的情况下(例如,某些类型的资源不足),分配模块根据DRF将资源提供给下一个框架。
如果供给的资源满足框架的需求,框架会创建任务列表并发送回Master。如果任务资源超出了供应过程中提供的数量,Master可以向框架返回错误信息。
Master向Agent节点上的执行器发送一组任务(如果执行器没有运行,则启动执行器)。
Dominant Resource Fairness (DRF)
DRF解决的主要问题是之前没有解决的多种类型(不仅仅是CPU)的资源的共享,并且在具有异构资源需求的应用之间的资源分配。为了解决这个问题,引入了主导份额和主导资源的概念。
主导资源: 特定类型的资源(cpu,内存,磁盘,端口),它是给定框架在其资源需求队列中最靠前的。此资源被标识为相同类型的所有集群资源的一个份额。
示例1:对于总数为10个CPU和20GB RAM的集群,资源需求是:框架A [4CPU,5GB],框架B [2个CPU,8GB]。同样的需求以总群集资源的份额来表示:框架A [40%CPU,25%RAM],框架B [20%CPU,40%RAM]。因此,对于框架A,CPU是主导资源,而对于框架B,其主导资源则是RAM。
DRF计算分配给框架的主导资源的份额(主导份额),并试图最大化系统中最小的主导份额。在下一轮资源供给过程中,DRF识别框架的主导份额,并将资源首先提供给具有最小主导份额的资源,然后提供给第二最小的一个,依此类推。
示例2:考虑具有总共10个CPU和20GB RAM的集群,资源需求是:框架A [3CPU,2GB],框架B [1CPU,5GB]。同样百分比表示:A [33%CPU,10%RAM],B [10%CPU,25%RAM]。资源计算分配步骤是:
1. (10cpu, 20gb) to A: A(3cpu, 2gb, 33%), B (0cpu, 0gb, 0%)
2. ( 7cpu, 18gb) to B: A(4cpu, 5gb, 40%), B (1cpu, 5gb, 25%)
3. ( 6cpu, 13gb) to B: A(4cpu, 5gb, 40%), B (2cpu, 10gb, 50%)
4. ( 5cpu, 8gb) to A: A(6cpu, 4gb, 66%), B (2cpu, 10gb, 50%)
5. ( 2cpu, 6gb) to B: A(6cpu, 4gb, 66%), B (3cpu, 15gb, 75%)
6. ( 1cpu, 1gb) to A: A(6cpu, 4gb, 66%), B (3cpu, 15gb, 75%)
7. ( 1cpu, 1gb) to B: A(6cpu, 4gb, 66%), B (3cpu, 15gb, 75%)
......直到其中一个框架的任务完成并释放资源。
遍历一下上述过程,首先A得到资源供给(假定A先启动,先到先得),A得到资源供给,它的主导份额变成33%;下一次供给主导份额最低的B优先获得供给(步骤2),B接受资源后,它的主导份额变成25%;B的主导份额低于A,因此,在下一次供给(步骤3),它继续获得供给,其主导份额变为50%;再下一轮(步骤4),A的主导份额开始低于B,A获得资源供给,以此类推。
最后,集群仅剩余1cpu和1gbn内存,整个集群的资源配给分别为CPU90%,内存95%,被充分优化,资源被最大化利用。
可以参考"Dominant Resource Fairness: Fair Allocation of Multiple Resource Types"获取更详细的算法描述。