ArangoDB Graphs
First Steps with Graphs
A Graph consists of vertices and edges. Edges are stored as documents in edge collections. A vertex can be a document of a document collection or of an edge collection (so edges can be used as vertices). Which collections are used within a named graph is defined via edge definitions. A named graph can contain more than one edge definition, at least one is needed. Graphs allow you to structure your models in line with your domain and group them logically in collections and giving you the power to query them in the same graph queries.
Coming from a relational background - what's a graph?
In SQL you commonly have the construct of a relation table to store n:m relations between two data tables.
An edge collection is somewhat similar to these relation tables; vertex collections resemble the data tables with the objects to connect.
While simple graph queries with fixed number of hops via the relation table may be doable in SQL with several nested joins,
graph databases can handle an arbitrary number of these hops over edge collections - this is called traversal.
Also edges in one edge collection may point to several vertex collections.
Its common to have attributes attached to edges, i.e. a label naming this interconnection.
Edges have a direction, with their relations _from and _to pointing from one document to another document stored in vertex collections.
In queries you can define in which directions the edge relations may be followed (OUTBOUND: _from → _to, INBOUND: _from ← _to, ANY: _from ↔ _to).
Named Graphs
Named graphs are completely managed by arangodb, and thus also visible in the webinterface. They use the full spectrum of ArangoDBs graph features. You may access them via several interfaces.
- AQL Graph Operations with several flavors:
- AQL Traversals on both named and anonymous graphs
- AQL Shortest Path on both named and anonymous graph
- JavaScript General Graph implementation, as you may use it in Foxx Services
- Graph Management; creating & manipualating graph definitions; inserting, updating and deleting vertices and edges into graphs
- Graph Functions for working with edges and vertices, to analyze them and their relations
- JavaScript Smart Graph implementation, for scalable graphs
- Smart Graph Management; creating & manipualating SmartGraph definitions; Differences to General Graph
- RESTful General Graph interface used to implement graph management in client drivers
Manipulating collections of named graphs with regular document functions
The underlying collections of the named graphs are still accessible using the standard methods for collections. However the graph module adds an additional layer on top of these collections giving you the following guarantees:
- All modifications are executed transactional
- If you delete a vertex all edges will be deleted, you will never have loose ends
- If you insert an edge it is checked if the edge matches the edge definitions, your edge collections will only contain valid edges
These guarantees are lost if you access the collections in any other way than the graph module or AQL, so if you delete documents from your vertex collections directly, the edges pointing to them will be remain in place.
Anonymous graphs
Sometimes you may not need all the powers of named graphs, but some of its bits may be valuable to you. You may use anonymous graphs in the traversals and in the Working with Edges chapter. Anonymous graphs don't have edge definitions describing which vertex collection is connected by which edge collection. The graph model has to be maintained in the client side code. This gives you more freedom than the strict named graphs.
- AQL Graph Operations are available for both, named and anonymous graphs:
When to choose anonymous or named graphs?
As noted above, named graphs ensure graph integrity, both when inserting or removing edges or vertices. So you won't encounter dangling edges, even if you use the same vertex collection in several named graphs. This involves more operations inside the database which come at a cost. Therefore anonymous graphs may be faster in many operations. So this question may be narrowed down to: 'Can I afford the additional effort or do I need the warranty for integrity?'.
Multiple edge collections vs. FILTERs on edge document attributes
If you want to only traverse edges of a specific type, there are two ways to achieve this. The first would be
an attribute in the edge document - i.e. type, where you specify a differentiator for the edge -
i.e. "friends", "family", "married" or "workmates", so you can later FILTER e.type = "friends"
if you only want to follow the friend edges.
Another way, which may be more efficient in some cases, is to use different edge collections for different
types of edges, so you have friend_eges, family_edges, married_edges and workmate_edges as collection names.
You can then configure several named graphs including a subset of the available edge and vertex collections -
or you use anonymous graph queries, where you specify a list of edge collections to take into account in that query.
To only follow friend edges, you would specify friend_edges as sole edge collection.
Both approaches have advantages and disadvantages. FILTER operations on ede attributes will do comparisons on
each traversed edge, which may become CPU-intense. When not finding the edges in the first place because of the
collection containing them is not traversed at all, there will never be a reason to actualy check for their
type attribute with FILTER.
The multiple edge collections approach is limited by the number of collections that can be used simultaneously in one query. Every collection used in a query requires some resources inside of ArangoDB and the number is therefore limited to cap the resource requirements. You may also have constraints on other edge attributes, such as a hash index with a unique constraint, which requires the documents to be in a single collection for the uniqueness guarantee, and it may thus not be possible to store the different types of edges in multiple edeg collections.
So, if your edges have about a dozen different types, it's okay to choose the collection approach, otherwise
the FILTER approach is preferred. You can still use FILTER operations on edges of course. You can get rid
of a FILTER on the type with the former approach, everything else can stay the same.
Which part of my data is an Edge and which a Vertex?
The main objects in your data model, such as users, groups or articles, are usually considered to be vertices. For each type of object, a document collection (also called vertex collection) should store the individual entities. Entities can be connected by edges to express and classify relations between vertices. It often makes sense to have an edge collection per relation type.
ArangoDB does not require you to store your data in graph structures with edges and vertices, you can also decide
to embed attributes such as which groups a user is part of, or _ids of documents in another document instead of
connecting the documents with edges. It can be a meaningful performance optimization for 1:n relationships, if
your data is not focused on relations and you don't need graph traversal with varying depth. It usually means
to introduce some redundancy and possibly inconsistencies if you embed data, but it can be an acceptable tradeoff.
Vertices
Let's say we have two vertex collections, Users and Groups. Documents in the Groups collection contain the attributes
of the Group, i.e. when it was founded, its subject, an icon URL and so on. Users documents contain the data specific to a
user - like all names, birthdays, Avatar URLs, hobbies...
Edges
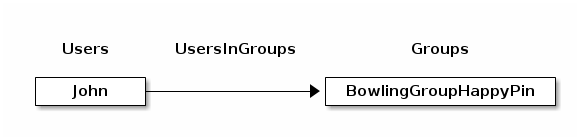
We can use an edge collection to store relations between users and groups. Since multiple users may be in an arbitrary
number of groups, this is an m:n relation. The edge collection can be called UsersInGroups with i.e. one edge
with _from pointing to Users/John and _to pointing to Groups/BowlingGroupHappyPin. This makes the user John
a member of the group Bowling Group Happy Pin. Attributes of this relation may contain qualifiers to this relation,
like the permissions of John in this group, the date when he joined the group etc.
So roughly put, if you use documents and their attributes in a sentence, nouns would typically be vertices, verbs become the edges. You can see this in the knows graph below:
Alice knows Bob, who in term knows Charlie.
Advantages of this approach
Graphs give you the advantage of not just being able to have a fixed number of m:n relations in a row, but an arbitrary number. Edges can be traversed in both directions, so it's easy to determine all groups a user is in, but also to find out which members a certain group has. Users could also be interconnected to create a social network.
Using the graph data model, dealing with data that has lots of relations stays manageable and can be queried in very flexible ways, whereas it would cause headache to handle it in a relational database system.
Backup and restore
For sure you want to have backups of your graph data, you can use Arangodump to create the backup, and Arangorestore to restore a backup into a new ArangoDB. You should however note that:
- you need the system collection
_graphsif you backup named graphs. - you need to backup the complete set of all edge and vertex collections your graph consists of. Partial dump/restore may not work.
Example Graphs
ArangoDB comes with a set of easily graspable graphs that are used to demonstrate the APIs.
You can use the add samples tab in the create graph window in the webinterface, or load the module @arangodb/graph-examples/example-graph in arangosh and use it to create instances of these graphs in your ArangoDB.
Once you've created them, you can inspect them in the webinterface - which was used to create the pictures below.
You can easily look into the innards of this script for reference about howto manage graphs programatically.
The Knows_Graph
A set of persons knowing each other:
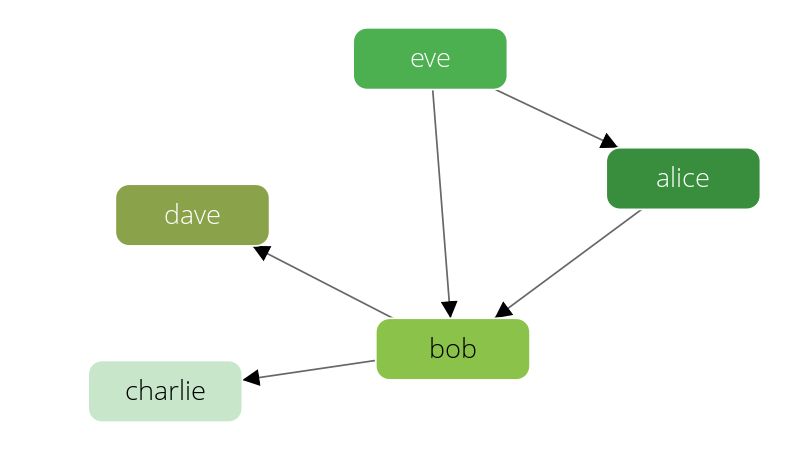
The knows graph consists of one vertex collection persons connected via one edge collection knows.
It will contain five persons Alice, Bob, Charlie, Dave and Eve.
We will have the following directed relations:
- Alice knows Bob
- Bob knows Charlie
- Bob knows Dave
- Eve knows Alice
- Eve knows Bob
This is how we create it, inspect its vertices and edges, and drop it again:
arangosh> var examples = require("@arangodb/graph-examples/example-graph.js");
arangosh> var g = examples.loadGraph("knows_graph");
arangosh> db.persons.toArray()
[
{
"_key" : "bob",
"_id" : "persons/bob",
"_rev" : "_VTxTcb2--_",
"name" : "Bob"
},
{
"_key" : "charlie",
"_id" : "persons/charlie",
"_rev" : "_VTxTcb2--A",
"name" : "Charlie"
},
{
"_key" : "dave",
"_id" : "persons/dave",
"_rev" : "_VTxTcb2--B",
"name" : "Dave"
},
{
"_key" : "eve",
"_id" : "persons/eve",
"_rev" : "_VTxTcb6---",
"name" : "Eve"
},
{
"_key" : "alice",
"_id" : "persons/alice",
"_rev" : "_VTxTcb2---",
"name" : "Alice"
}
]
arangosh> db.knows.toArray();
[
{
"_key" : "33083",
"_id" : "knows/33083",
"_from" : "persons/bob",
"_to" : "persons/charlie",
"_rev" : "_VTxTcc----"
},
{
"_key" : "33089",
"_id" : "knows/33089",
"_from" : "persons/eve",
"_to" : "persons/alice",
"_rev" : "_VTxTccG---"
},
{
"_key" : "33092",
"_id" : "knows/33092",
"_from" : "persons/eve",
"_to" : "persons/bob",
"_rev" : "_VTxTccG--_"
},
{
"_key" : "33086",
"_id" : "knows/33086",
"_from" : "persons/bob",
"_to" : "persons/dave",
"_rev" : "_VTxTccC---"
},
{
"_key" : "33079",
"_id" : "knows/33079",
"_from" : "persons/alice",
"_to" : "persons/bob",
"_rev" : "_VTxTcb6--_"
}
]
arangosh> examples.dropGraph("knows_graph");
true
arangosh> var examples = require("@arangodb/graph-examples/example-graph.js");
arangosh> var g = examples.loadGraph("knows_graph");
arangosh> db.persons.toArray()
arangosh> db.knows.toArray();
arangosh> examples.dropGraph("knows_graph");
The Social Graph
A set of persons and their relations:
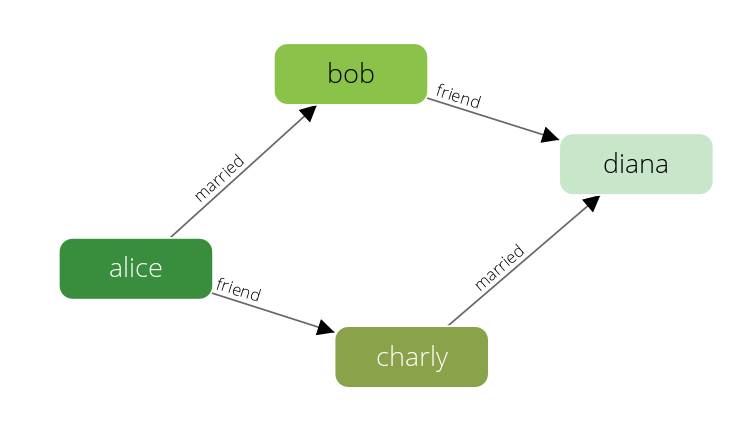
This example has female and male persons as vertices in two vertex collections - female and male. The edges are their connections in the relation edge collection.
This is how we create it, inspect its vertices and edges, and drop it again:
The City Graph
A set of european cities, and their fictional traveling distances as connections:

The example has the cities as vertices in several vertex collections - germanCity and frenchCity. The edges are their interconnections in several edge collections french / german / international Highway. This is how we create it, inspect its edges and vertices, and drop it again:
arangosh> var examples = require("@arangodb/graph-examples/example-graph.js");
arangosh> var g = examples.loadGraph("routeplanner");
arangosh> db.frenchCity.toArray();
[
{
"_key" : "Lyon",
"_id" : "frenchCity/Lyon",
"_rev" : "_VTxTcRS--A",
"population" : 80000,
"isCapital" : false,
"loc" : [
45.76,
4.84
]
},
{
"_key" : "Paris",
"_id" : "frenchCity/Paris",
"_rev" : "_VTxTcRS--B",
"population" : 4000000,
"isCapital" : true,
"loc" : [
48.8567,
2.3508
]
}
]
arangosh> db.germanCity.toArray();
[
{
"_key" : "Cologne",
"_id" : "germanCity/Cologne",
"_rev" : "_VTxTcRS---",
"population" : 1000000,
"isCapital" : false,
"loc" : [
50.9364,
6.9528
]
},
{
"_key" : "Hamburg",
"_id" : "germanCity/Hamburg",
"_rev" : "_VTxTcRS--_",
"population" : 1000000,
"isCapital" : false,
"loc" : [
53.5653,
10.0014
]
},
{
"_key" : "Berlin",
"_id" : "germanCity/Berlin",
"_rev" : "_VTxTcRO---",
"population" : 3000000,
"isCapital" : true,
"loc" : [
52.5167,
13.3833
]
}
]
arangosh> db.germanHighway.toArray();
[
{
"_key" : "32997",
"_id" : "germanHighway/32997",
"_from" : "germanCity/Berlin",
"_to" : "germanCity/Cologne",
"_rev" : "_VTxTcUm---",
"distance" : 850
},
{
"_key" : "33004",
"_id" : "germanHighway/33004",
"_from" : "germanCity/Hamburg",
"_to" : "germanCity/Cologne",
"_rev" : "_VTxTcUm--A",
"distance" : 500
},
{
"_key" : "33001",
"_id" : "germanHighway/33001",
"_from" : "germanCity/Berlin",
"_to" : "germanCity/Hamburg",
"_rev" : "_VTxTcUm--_",
"distance" : 400
}
]
arangosh> db.frenchHighway.toArray();
[
{
"_key" : "33007",
"_id" : "frenchHighway/33007",
"_from" : "frenchCity/Paris",
"_to" : "frenchCity/Lyon",
"_rev" : "_VTxTcUq---",
"distance" : 550
}
]
arangosh> db.internationalHighway.toArray();
[
{
"_key" : "33011",
"_id" : "internationalHighway/33011",
"_from" : "germanCity/Berlin",
"_to" : "frenchCity/Lyon",
"_rev" : "_VTxTcUq--_",
"distance" : 1100
},
{
"_key" : "33021",
"_id" : "internationalHighway/33021",
"_from" : "germanCity/Hamburg",
"_to" : "frenchCity/Lyon",
"_rev" : "_VTxTcUu---",
"distance" : 1300
},
{
"_key" : "33015",
"_id" : "internationalHighway/33015",
"_from" : "germanCity/Berlin",
"_to" : "frenchCity/Paris",
"_rev" : "_VTxTcUq--A",
"distance" : 1200
},
{
"_key" : "33027",
"_id" : "internationalHighway/33027",
"_from" : "germanCity/Cologne",
"_to" : "frenchCity/Paris",
"_rev" : "_VTxTcUu--A",
"distance" : 550
},
{
"_key" : "33024",
"_id" : "internationalHighway/33024",
"_from" : "germanCity/Cologne",
"_to" : "frenchCity/Lyon",
"_rev" : "_VTxTcUu--_",
"distance" : 700
},
{
"_key" : "33018",
"_id" : "internationalHighway/33018",
"_from" : "germanCity/Hamburg",
"_to" : "frenchCity/Paris",
"_rev" : "_VTxTcUq--B",
"distance" : 900
}
]
arangosh> examples.dropGraph("routeplanner");
true
arangosh> var examples = require("@arangodb/graph-examples/example-graph.js");
arangosh> var g = examples.loadGraph("routeplanner");
arangosh> db.frenchCity.toArray();
arangosh> db.germanCity.toArray();
arangosh> db.germanHighway.toArray();
arangosh> db.frenchHighway.toArray();
arangosh> db.internationalHighway.toArray();
arangosh> examples.dropGraph("routeplanner");
The Traversal Graph
This graph was designed to demonstrate filters in traversals. It has some labels to filter on it.
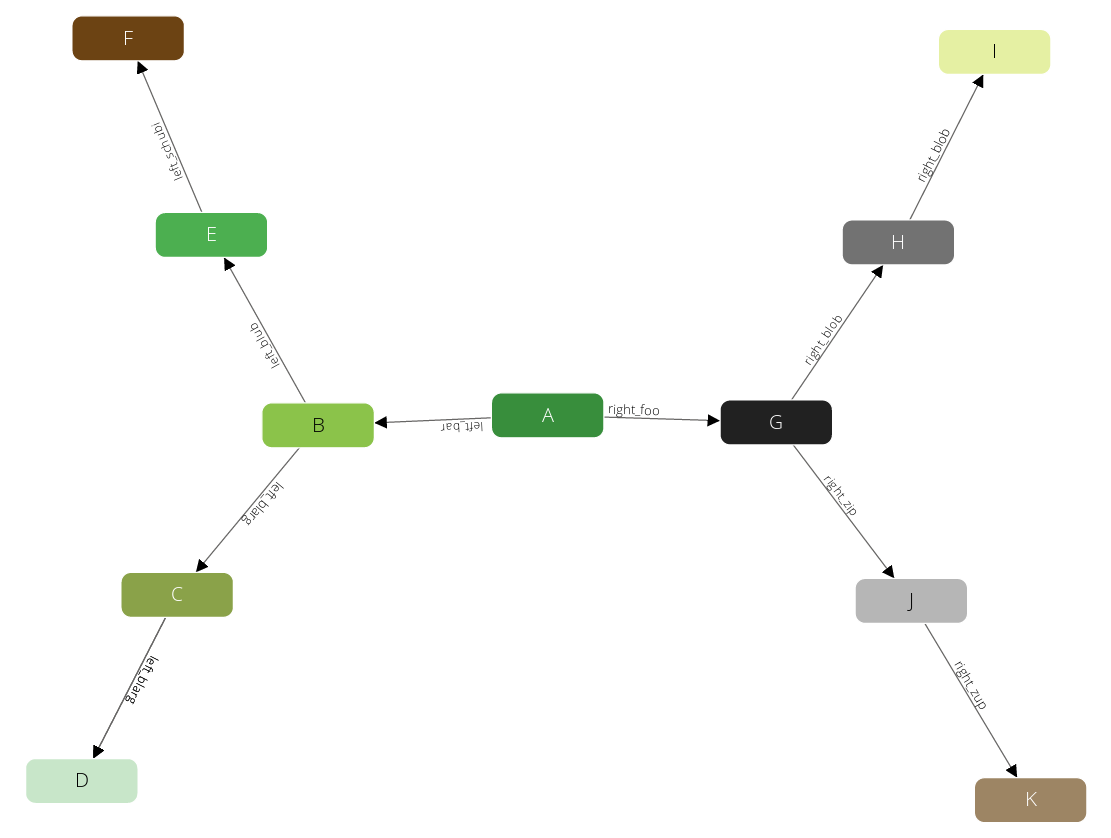
The example has all its vertices in the circles collection, and an edges edge collection to connect them. Circles have unique numeric labels. Edges have two boolean attributes (theFalse always being false, theTruth always being true) and a label sorting B - D to the left side, G - K to the right side. Left and right side split into Paths - at B and G which are each direct neighbours of the root-node A. Starting from A the graph has a depth of 3 on all its paths.
arangosh> var examples = require("@arangodb/graph-examples/example-graph.js");
arangosh> var g = examples.loadGraph("traversalGraph");
arangosh> db.circles.toArray();
[
{
"_key" : "I",
"_id" : "circles/I",
"_rev" : "_VTxTcmG--A",
"label" : "9"
},
{
"_key" : "G",
"_id" : "circles/G",
"_rev" : "_VTxTcmG---",
"label" : "7"
},
{
"_key" : "F",
"_id" : "circles/F",
"_rev" : "_VTxTcmC--C",
"label" : "6"
},
{
"_key" : "A",
"_id" : "circles/A",
"_rev" : "_VTxTcm---_",
"label" : "1"
},
{
"_key" : "E",
"_id" : "circles/E",
"_rev" : "_VTxTcmC--B",
"label" : "5"
},
{
"_key" : "C",
"_id" : "circles/C",
"_rev" : "_VTxTcmC--_",
"label" : "3"
},
{
"_key" : "D",
"_id" : "circles/D",
"_rev" : "_VTxTcmC--A",
"label" : "4"
},
{
"_key" : "J",
"_id" : "circles/J",
"_rev" : "_VTxTcmG--B",
"label" : "10"
},
{
"_key" : "B",
"_id" : "circles/B",
"_rev" : "_VTxTcmC---",
"label" : "2"
},
{
"_key" : "H",
"_id" : "circles/H",
"_rev" : "_VTxTcmG--_",
"label" : "8"
},
{
"_key" : "K",
"_id" : "circles/K",
"_rev" : "_VTxTcmG--C",
"label" : "11"
}
]
arangosh> db.edges.toArray();
[
{
"_key" : "33217",
"_id" : "edges/33217",
"_from" : "circles/G",
"_to" : "circles/J",
"_rev" : "_VTxTcme--_",
"theFalse" : false,
"theTruth" : true,
"label" : "right_zip"
},
{
"_key" : "33192",
"_id" : "edges/33192",
"_from" : "circles/A",
"_to" : "circles/B",
"_rev" : "_VTxTcmK---",
"theFalse" : false,
"theTruth" : true,
"label" : "left_bar"
},
{
"_key" : "33214",
"_id" : "edges/33214",
"_from" : "circles/H",
"_to" : "circles/I",
"_rev" : "_VTxTcme---",
"theFalse" : false,
"theTruth" : true,
"label" : "right_blub"
},
{
"_key" : "33208",
"_id" : "edges/33208",
"_from" : "circles/A",
"_to" : "circles/G",
"_rev" : "_VTxTcma---",
"theFalse" : false,
"theTruth" : true,
"label" : "right_foo"
},
{
"_key" : "33202",
"_id" : "edges/33202",
"_from" : "circles/B",
"_to" : "circles/E",
"_rev" : "_VTxTcmW---",
"theFalse" : false,
"theTruth" : true,
"label" : "left_blub"
},
{
"_key" : "33199",
"_id" : "edges/33199",
"_from" : "circles/C",
"_to" : "circles/D",
"_rev" : "_VTxTcmO---",
"theFalse" : false,
"theTruth" : true,
"label" : "left_blorg"
},
{
"_key" : "33196",
"_id" : "edges/33196",
"_from" : "circles/B",
"_to" : "circles/C",
"_rev" : "_VTxTcmK--_",
"theFalse" : false,
"theTruth" : true,
"label" : "left_blarg"
},
{
"_key" : "33205",
"_id" : "edges/33205",
"_from" : "circles/E",
"_to" : "circles/F",
"_rev" : "_VTxTcmW--_",
"theFalse" : false,
"theTruth" : true,
"label" : "left_schubi"
},
{
"_key" : "33211",
"_id" : "edges/33211",
"_from" : "circles/G",
"_to" : "circles/H",
"_rev" : "_VTxTcma--_",
"theFalse" : false,
"theTruth" : true,
"label" : "right_blob"
},
{
"_key" : "33220",
"_id" : "edges/33220",
"_from" : "circles/J",
"_to" : "circles/K",
"_rev" : "_VTxTcme--A",
"theFalse" : false,
"theTruth" : true,
"label" : "right_zup"
}
]
arangosh> examples.dropGraph("traversalGraph");
true
arangosh> var examples = require("@arangodb/graph-examples/example-graph.js");
arangosh> var g = examples.loadGraph("traversalGraph");
arangosh> db.circles.toArray();
arangosh> db.edges.toArray();
arangosh> examples.dropGraph("traversalGraph");
The World Graph
The world country graph structures its nodes like that: world → continent → country → capital. In some cases edge directions aren't forward (therefore it will be displayed disjunct in the graph viewer). It has two ways of creating it. One using the named graph utilities (worldCountry), one without (worldCountryUnManaged). It is used to demonstrate raw traversal operations.
arangosh> var examples = require("@arangodb/graph-examples/example-graph.js");
arangosh> var g = examples.loadGraph("worldCountry");
arangosh> db.worldVertices.toArray();
[
{
"_key" : "capital-ottawa",
"_id" : "worldVertices/capital-ottawa",
"_rev" : "_VTxTct---_",
"name" : "Ottawa",
"type" : "capital"
},
{
"_key" : "capital-yaounde",
"_id" : "worldVertices/capital-yaounde",
"_rev" : "_VTxTctK--A",
"name" : "Yaounde",
"type" : "capital"
},
{
"_key" : "capital-algiers",
"_id" : "worldVertices/capital-algiers",
"_rev" : "_VTxTcsW---",
"name" : "Algiers",
"type" : "capital"
},
{
"_key" : "continent-south-america",
"_id" : "worldVertices/continent-south-america",
"_rev" : "_VTxTcrm--_",
"name" : "South America",
"type" : "continent"
},
{
"_key" : "capital-andorra-la-vella",
"_id" : "worldVertices/capital-andorra-la-vella",
"_rev" : "_VTxTcsW--_",
"name" : "Andorra la Vella",
"type" : "capital"
},
{
"_key" : "country-people-s-republic-of-china",
"_id" : "worldVertices/country-people-s-republic-of-china",
"_rev" : "_VTxTcsS--C",
"name" : "People's Republic of China",
"type" : "country",
"code" : "CHN"
},
{
"_key" : "capital-tirana",
"_id" : "worldVertices/capital-tirana",
"_rev" : "_VTxTctG--B",
"name" : "Tirana",
"type" : "capital"
},
{
"_key" : "country-cote-d-ivoire",
"_id" : "worldVertices/country-cote-d-ivoire",
"_rev" : "_VTxTcsK--B",
"name" : "Cote d'Ivoire",
"type" : "country",
"code" : "CIV"
},
{
"_key" : "capital-sofia",
"_id" : "worldVertices/capital-sofia",
"_rev" : "_VTxTctG--_",
"name" : "Sofia",
"type" : "capital"
},
{
"_key" : "capital-bridgetown",
"_id" : "worldVertices/capital-bridgetown",
"_rev" : "_VTxTcse---",
"name" : "Bridgetown",
"type" : "capital"
},
{
"_key" : "country-chad",
"_id" : "worldVertices/country-chad",
"_rev" : "_VTxTcsK---",
"name" : "Chad",
"type" : "country",
"code" : "TCD"
},
{
"_key" : "capital-thimphu",
"_id" : "worldVertices/capital-thimphu",
"_rev" : "_VTxTctG--A",
"name" : "Thimphu",
"type" : "capital"
},
{
"_key" : "capital-santiago",
"_id" : "worldVertices/capital-santiago",
"_rev" : "_VTxTctC--B",
"name" : "Santiago",
"type" : "capital"
},
{
"_key" : "capital-manama",
"_id" : "worldVertices/capital-manama",
"_rev" : "_VTxTcs6--B",
"name" : "Manama",
"type" : "capital"
},
{
"_key" : "capital-zagreb",
"_id" : "worldVertices/capital-zagreb",
"_rev" : "_VTxTctK--B",
"name" : "Zagreb",
"type" : "capital"
},
{
"_key" : "country-brazil",
"_id" : "worldVertices/country-brazil",
"_rev" : "_VTxTcsC--_",
"name" : "Brazil",
"type" : "country",
"code" : "BRA"
},
{
"_key" : "country-burundi",
"_id" : "worldVertices/country-burundi",
"_rev" : "_VTxTcsG--_",
"name" : "Burundi",
"type" : "country",
"code" : "BDI"
},
{
"_key" : "capital-la-paz",
"_id" : "worldVertices/capital-la-paz",
"_rev" : "_VTxTcs6--_",
"name" : "La Paz",
"type" : "capital"
},
{
"_key" : "country-germany",
"_id" : "worldVertices/country-germany",
"_rev" : "_VTxTcsS--B",
"name" : "Germany",
"type" : "country",
"code" : "DEU"
},
{
"_key" : "country-botswana",
"_id" : "worldVertices/country-botswana",
"_rev" : "_VTxTcsC---",
"name" : "Botswana",
"type" : "country",
"code" : "BWA"
},
{
"_key" : "capital-phnom-penh",
"_id" : "worldVertices/capital-phnom-penh",
"_rev" : "_VTxTct---C",
"name" : "Phnom Penh",
"type" : "capital"
},
{
"_key" : "country-croatia",
"_id" : "worldVertices/country-croatia",
"_rev" : "_VTxTcsO---",
"name" : "Croatia",
"type" : "country",
"code" : "HRV"
},
{
"_key" : "country-eritrea",
"_id" : "worldVertices/country-eritrea",
"_rev" : "_VTxTcsS---",
"name" : "Eritrea",
"type" : "country",
"code" : "ERI"
},
{
"_key" : "country-angola",
"_id" : "worldVertices/country-angola",
"_rev" : "_VTxTcrq--B",
"name" : "Angola",
"type" : "country",
"code" : "AGO"
},
{
"_key" : "country-bahrain",
"_id" : "worldVertices/country-bahrain",
"_rev" : "_VTxTcry---",
"name" : "Bahrain",
"type" : "country",
"code" : "BHR"
},
{
"_key" : "country-argentina",
"_id" : "worldVertices/country-argentina",
"_rev" : "_VTxTcru--_",
"name" : "Argentina",
"type" : "country",
"code" : "ARG"
},
{
"_key" : "capital-canberra",
"_id" : "worldVertices/capital-canberra",
"_rev" : "_VTxTcsm--B",
"name" : "Canberra",
"type" : "capital"
},
{
"_key" : "capital-bujumbura",
"_id" : "worldVertices/capital-bujumbura",
"_rev" : "_VTxTcsm--_",
"name" : "Bujumbura",
"type" : "capital"
},
{
"_key" : "country-bangladesh",
"_id" : "worldVertices/country-bangladesh",
"_rev" : "_VTxTcry--_",
"name" : "Bangladesh",
"type" : "country",
"code" : "BGD"
},
{
"_key" : "country-ecuador",
"_id" : "worldVertices/country-ecuador",
"_rev" : "_VTxTcsO--B",
"name" : "Ecuador",
"type" : "country",
"code" : "ECU"
},
{
"_key" : "continent-africa",
"_id" : "worldVertices/continent-africa",
"_rev" : "_VTxTcrO--_",
"name" : "Africa",
"type" : "continent"
},
{
"_key" : "country-cambodia",
"_id" : "worldVertices/country-cambodia",
"_rev" : "_VTxTcsG--A",
"name" : "Cambodia",
"type" : "country",
"code" : "KHM"
},
{
"_key" : "country-chile",
"_id" : "worldVertices/country-chile",
"_rev" : "_VTxTcsK--_",
"name" : "Chile",
"type" : "country",
"code" : "CHL"
},
{
"_key" : "country-bolivia",
"_id" : "worldVertices/country-bolivia",
"_rev" : "_VTxTcr6---",
"name" : "Bolivia",
"type" : "country",
"code" : "BOL"
},
{
"_key" : "country-belgium",
"_id" : "worldVertices/country-belgium",
"_rev" : "_VTxTcr2---",
"name" : "Belgium",
"type" : "country",
"code" : "BEL"
},
{
"_key" : "capital-copenhagen",
"_id" : "worldVertices/capital-copenhagen",
"_rev" : "_VTxTcsm--C",
"name" : "Copenhagen",
"type" : "capital"
},
{
"_key" : "country-cameroon",
"_id" : "worldVertices/country-cameroon",
"_rev" : "_VTxTcsG--B",
"name" : "Cameroon",
"type" : "country",
"code" : "CMR"
},
{
"_key" : "capital-gaborone",
"_id" : "worldVertices/capital-gaborone",
"_rev" : "_VTxTcs2---",
"name" : "Gaborone",
"type" : "capital"
},
{
"_key" : "continent-australia",
"_id" : "worldVertices/continent-australia",
"_rev" : "_VTxTcra---",
"name" : "Australia",
"type" : "continent"
},
{
"_key" : "world",
"_id" : "worldVertices/world",
"_rev" : "_VTxTcrO---",
"name" : "World",
"type" : "root"
},
{
"_key" : "capital-yamoussoukro",
"_id" : "worldVertices/capital-yamoussoukro",
"_rev" : "_VTxTctK--_",
"name" : "Yamoussoukro",
"type" : "capital"
},
{
"_key" : "capital-brasilia",
"_id" : "worldVertices/capital-brasilia",
"_rev" : "_VTxTcsa--A",
"name" : "Brasilia",
"type" : "capital"
},
{
"_key" : "country-antigua-and-barbuda",
"_id" : "worldVertices/country-antigua-and-barbuda",
"_rev" : "_VTxTcru---",
"name" : "Antigua and Barbuda",
"type" : "country",
"code" : "ATG"
},
{
"_key" : "capital-bandar-seri-begawan",
"_id" : "worldVertices/capital-bandar-seri-begawan",
"_rev" : "_VTxTcsW--B",
"name" : "Bandar Seri Begawan",
"type" : "capital"
},
{
"_key" : "capital-dhaka",
"_id" : "worldVertices/capital-dhaka",
"_rev" : "_VTxTcsq---",
"name" : "Dhaka",
"type" : "capital"
},
{
"_key" : "capital-saint-john-s",
"_id" : "worldVertices/capital-saint-john-s",
"_rev" : "_VTxTctC--A",
"name" : "Saint John's",
"type" : "capital"
},
{
"_key" : "country-burkina-faso",
"_id" : "worldVertices/country-burkina-faso",
"_rev" : "_VTxTcsG---",
"name" : "Burkina Faso",
"type" : "country",
"code" : "BFA"
},
{
"_key" : "capital-prague",
"_id" : "worldVertices/capital-prague",
"_rev" : "_VTxTctC---",
"name" : "Prague",
"type" : "capital"
},
{
"_key" : "country-czech-republic",
"_id" : "worldVertices/country-czech-republic",
"_rev" : "_VTxTcsO--_",
"name" : "Czech Republic",
"type" : "country",
"code" : "CZE"
},
{
"_key" : "country-egypt",
"_id" : "worldVertices/country-egypt",
"_rev" : "_VTxTcsO--C",
"name" : "Egypt",
"type" : "country",
"code" : "EGY"
},
{
"_key" : "capital-helsinki",
"_id" : "worldVertices/capital-helsinki",
"_rev" : "_VTxTcs2--_",
"name" : "Helsinki",
"type" : "capital"
},
{
"_key" : "country-bhutan",
"_id" : "worldVertices/country-bhutan",
"_rev" : "_VTxTcr2--_",
"name" : "Bhutan",
"type" : "country",
"code" : "BTN"
},
{
"_key" : "country-algeria",
"_id" : "worldVertices/country-algeria",
"_rev" : "_VTxTcrq--_",
"name" : "Algeria",
"type" : "country",
"code" : "DZA"
},
{
"_key" : "country-afghanistan",
"_id" : "worldVertices/country-afghanistan",
"_rev" : "_VTxTcrm--A",
"name" : "Afghanistan",
"type" : "country",
"code" : "AFG"
},
{
"_key" : "capital-paris",
"_id" : "worldVertices/capital-paris",
"_rev" : "_VTxTct---B",
"name" : "Paris",
"type" : "capital"
},
{
"_key" : "country-finland",
"_id" : "worldVertices/country-finland",
"_rev" : "_VTxTcsS--_",
"name" : "Finland",
"type" : "country",
"code" : "FIN"
},
{
"_key" : "country-austria",
"_id" : "worldVertices/country-austria",
"_rev" : "_VTxTcru--B",
"name" : "Austria",
"type" : "country",
"code" : "AUT"
},
{
"_key" : "capital-brussels",
"_id" : "worldVertices/capital-brussels",
"_rev" : "_VTxTcsi---",
"name" : "Brussels",
"type" : "capital"
},
{
"_key" : "country-denmark",
"_id" : "worldVertices/country-denmark",
"_rev" : "_VTxTcsO--A",
"name" : "Denmark",
"type" : "country",
"code" : "DNK"
},
{
"_key" : "country-albania",
"_id" : "worldVertices/country-albania",
"_rev" : "_VTxTcrq---",
"name" : "Albania",
"type" : "country",
"code" : "ALB"
},
{
"_key" : "capital-berlin",
"_id" : "worldVertices/capital-berlin",
"_rev" : "_VTxTcsa---",
"name" : "Berlin",
"type" : "capital"
},
{
"_key" : "capital-buenos-aires",
"_id" : "worldVertices/capital-buenos-aires",
"_rev" : "_VTxTcsm---",
"name" : "Buenos Aires",
"type" : "capital"
},
{
"_key" : "capital-quito",
"_id" : "worldVertices/capital-quito",
"_rev" : "_VTxTctC--_",
"name" : "Quito",
"type" : "capital"
},
{
"_key" : "country-france",
"_id" : "worldVertices/country-france",
"_rev" : "_VTxTcsS--A",
"name" : "France",
"type" : "country",
"code" : "FRA"
},
{
"_key" : "country-colombia",
"_id" : "worldVertices/country-colombia",
"_rev" : "_VTxTcsK--A",
"name" : "Colombia",
"type" : "country",
"code" : "COL"
},
{
"_key" : "country-bulgaria",
"_id" : "worldVertices/country-bulgaria",
"_rev" : "_VTxTcsC--B",
"name" : "Bulgaria",
"type" : "country",
"code" : "BGR"
},
{
"_key" : "continent-north-america",
"_id" : "worldVertices/continent-north-america",
"_rev" : "_VTxTcrm---",
"name" : "North America",
"type" : "continent"
},
{
"_key" : "capital-vienna",
"_id" : "worldVertices/capital-vienna",
"_rev" : "_VTxTctK---",
"name" : "Vienna",
"type" : "capital"
},
{
"_key" : "country-bahamas",
"_id" : "worldVertices/country-bahamas",
"_rev" : "_VTxTcru--C",
"name" : "Bahamas",
"type" : "country",
"code" : "BHS"
},
{
"_key" : "continent-asia",
"_id" : "worldVertices/continent-asia",
"_rev" : "_VTxTcrW---",
"name" : "Asia",
"type" : "continent"
},
{
"_key" : "country-barbados",
"_id" : "worldVertices/country-barbados",
"_rev" : "_VTxTcry--A",
"name" : "Barbados",
"type" : "country",
"code" : "BRB"
},
{
"_key" : "capital-n-djamena",
"_id" : "worldVertices/capital-n-djamena",
"_rev" : "_VTxTct----",
"name" : "N'Djamena",
"type" : "capital"
},
{
"_key" : "capital-ouagadougou",
"_id" : "worldVertices/capital-ouagadougou",
"_rev" : "_VTxTct---A",
"name" : "Ouagadougou",
"type" : "capital"
},
{
"_key" : "capital-bogota",
"_id" : "worldVertices/capital-bogota",
"_rev" : "_VTxTcsa--_",
"name" : "Bogota",
"type" : "capital"
},
{
"_key" : "country-brunei",
"_id" : "worldVertices/country-brunei",
"_rev" : "_VTxTcsC--A",
"name" : "Brunei",
"type" : "country",
"code" : "BRN"
},
{
"_key" : "capital-asmara",
"_id" : "worldVertices/capital-asmara",
"_rev" : "_VTxTcsW--A",
"name" : "Asmara",
"type" : "capital"
},
{
"_key" : "capital-cairo",
"_id" : "worldVertices/capital-cairo",
"_rev" : "_VTxTcsm--A",
"name" : "Cairo",
"type" : "capital"
},
{
"_key" : "capital-kabul",
"_id" : "worldVertices/capital-kabul",
"_rev" : "_VTxTcs6---",
"name" : "Kabul",
"type" : "capital"
},
{
"_key" : "capital-nassau",
"_id" : "worldVertices/capital-nassau",
"_rev" : "_VTxTcs6--C",
"name" : "Nassau",
"type" : "capital"
},
{
"_key" : "capital-beijing",
"_id" : "worldVertices/capital-beijing",
"_rev" : "_VTxTcsW--C",
"name" : "Beijing",
"type" : "capital"
},
{
"_key" : "country-canada",
"_id" : "worldVertices/country-canada",
"_rev" : "_VTxTcsG--C",
"name" : "Canada",
"type" : "country",
"code" : "CAN"
},
{
"_key" : "continent-europe",
"_id" : "worldVertices/continent-europe",
"_rev" : "_VTxTcri---",
"name" : "Europe",
"type" : "continent"
},
{
"_key" : "capital-luanda",
"_id" : "worldVertices/capital-luanda",
"_rev" : "_VTxTcs6--A",
"name" : "Luanda",
"type" : "capital"
},
{
"_key" : "country-australia",
"_id" : "worldVertices/country-australia",
"_rev" : "_VTxTcru--A",
"name" : "Australia",
"type" : "country",
"code" : "AUS"
},
{
"_key" : "capital-sarajevo",
"_id" : "worldVertices/capital-sarajevo",
"_rev" : "_VTxTctG---",
"name" : "Sarajevo",
"type" : "capital"
},
{
"_key" : "country-andorra",
"_id" : "worldVertices/country-andorra",
"_rev" : "_VTxTcrq--A",
"name" : "Andorra",
"type" : "country",
"code" : "AND"
},
{
"_key" : "country-bosnia-and-herzegovina",
"_id" : "worldVertices/country-bosnia-and-herzegovina",
"_rev" : "_VTxTcs----",
"name" : "Bosnia and Herzegovina",
"type" : "country",
"code" : "BIH"
}
]
arangosh> db.worldEdges.toArray();
[
{
"_key" : "33669",
"_id" : "worldEdges/33669",
"_from" : "worldVertices/capital-vienna",
"_to" : "worldVertices/country-austria",
"_rev" : "_VTxTcua---",
"type" : "is-in"
},
{
"_key" : "33456",
"_id" : "worldEdges/33456",
"_from" : "worldVertices/country-antigua-and-barbuda",
"_to" : "worldVertices/continent-north-america",
"_rev" : "_VTxTctW--_",
"type" : "is-in"
},
{
"_key" : "33543",
"_id" : "worldEdges/33543",
"_from" : "worldVertices/country-egypt",
"_to" : "worldVertices/continent-africa",
"_rev" : "_VTxTcty--A",
"type" : "is-in"
},
{
"_key" : "33567",
"_id" : "worldEdges/33567",
"_from" : "worldVertices/capital-asmara",
"_to" : "worldVertices/country-eritrea",
"_rev" : "_VTxTct6--B",
"type" : "is-in"
},
{
"_key" : "33468",
"_id" : "worldEdges/33468",
"_from" : "worldVertices/country-bahamas",
"_to" : "worldVertices/continent-north-america",
"_rev" : "_VTxTcta--_",
"type" : "is-in"
},
{
"_key" : "33621",
"_id" : "worldEdges/33621",
"_from" : "worldVertices/capital-luanda",
"_to" : "worldVertices/country-angola",
"_rev" : "_VTxTcuO---",
"type" : "is-in"
},
{
"_key" : "33426",
"_id" : "worldEdges/33426",
"_from" : "worldVertices/continent-asia",
"_to" : "worldVertices/world",
"_rev" : "_VTxTctO---",
"type" : "is-in"
},
{
"_key" : "33618",
"_id" : "worldEdges/33618",
"_from" : "worldVertices/capital-la-paz",
"_to" : "worldVertices/country-bolivia",
"_rev" : "_VTxTcuK--C",
"type" : "is-in"
},
{
"_key" : "33663",
"_id" : "worldEdges/33663",
"_from" : "worldVertices/capital-thimphu",
"_to" : "worldVertices/country-bhutan",
"_rev" : "_VTxTcuW--B",
"type" : "is-in"
},
{
"_key" : "33579",
"_id" : "worldEdges/33579",
"_from" : "worldVertices/capital-bogota",
"_to" : "worldVertices/country-colombia",
"_rev" : "_VTxTcuC---",
"type" : "is-in"
},
{
"_key" : "33570",
"_id" : "worldEdges/33570",
"_from" : "worldVertices/capital-bandar-seri-begawan",
"_to" : "worldVertices/country-brunei",
"_rev" : "_VTxTcu----",
"type" : "is-in"
},
{
"_key" : "33537",
"_id" : "worldEdges/33537",
"_from" : "worldVertices/country-denmark",
"_to" : "worldVertices/continent-europe",
"_rev" : "_VTxTcty---",
"type" : "is-in"
},
{
"_key" : "33552",
"_id" : "worldEdges/33552",
"_from" : "worldVertices/country-france",
"_to" : "worldVertices/continent-europe",
"_rev" : "_VTxTct2--_",
"type" : "is-in"
},
{
"_key" : "33474",
"_id" : "worldEdges/33474",
"_from" : "worldVertices/country-bangladesh",
"_to" : "worldVertices/continent-asia",
"_rev" : "_VTxTcta--B",
"type" : "is-in"
},
{
"_key" : "33432",
"_id" : "worldEdges/33432",
"_from" : "worldVertices/continent-europe",
"_to" : "worldVertices/world",
"_rev" : "_VTxTctO--A",
"type" : "is-in"
},
{
"_key" : "33549",
"_id" : "worldEdges/33549",
"_from" : "worldVertices/country-finland",
"_to" : "worldVertices/continent-europe",
"_rev" : "_VTxTct2---",
"type" : "is-in"
},
{
"_key" : "33582",
"_id" : "worldEdges/33582",
"_from" : "worldVertices/capital-brasilia",
"_to" : "worldVertices/country-brazil",
"_rev" : "_VTxTcuC--_",
"type" : "is-in"
},
{
"_key" : "33531",
"_id" : "worldEdges/33531",
"_from" : "worldVertices/country-croatia",
"_to" : "worldVertices/continent-europe",
"_rev" : "_VTxTctu--A",
"type" : "is-in"
},
{
"_key" : "33471",
"_id" : "worldEdges/33471",
"_from" : "worldVertices/country-bahrain",
"_to" : "worldVertices/continent-asia",
"_rev" : "_VTxTcta--A",
"type" : "is-in"
},
{
"_key" : "33585",
"_id" : "worldEdges/33585",
"_from" : "worldVertices/capital-bridgetown",
"_to" : "worldVertices/country-barbados",
"_rev" : "_VTxTcuC--A",
"type" : "is-in"
},
{
"_key" : "33519",
"_id" : "worldEdges/33519",
"_from" : "worldVertices/country-chad",
"_to" : "worldVertices/continent-africa",
"_rev" : "_VTxTctq--_",
"type" : "is-in"
},
{
"_key" : "33489",
"_id" : "worldEdges/33489",
"_from" : "worldVertices/country-bosnia-and-herzegovina",
"_to" : "worldVertices/continent-europe",
"_rev" : "_VTxTcte--C",
"type" : "is-in"
},
{
"_key" : "33642",
"_id" : "worldEdges/33642",
"_from" : "worldVertices/capital-phnom-penh",
"_to" : "worldVertices/country-cambodia",
"_rev" : "_VTxTcuS--A",
"type" : "is-in"
},
{
"_key" : "33522",
"_id" : "worldEdges/33522",
"_from" : "worldVertices/country-chile",
"_to" : "worldVertices/continent-south-america",
"_rev" : "_VTxTctq--A",
"type" : "is-in"
},
{
"_key" : "33639",
"_id" : "worldEdges/33639",
"_from" : "worldVertices/capital-paris",
"_to" : "worldVertices/country-france",
"_rev" : "_VTxTcuS--_",
"type" : "is-in"
},
{
"_key" : "33528",
"_id" : "worldEdges/33528",
"_from" : "worldVertices/country-cote-d-ivoire",
"_to" : "worldVertices/continent-africa",
"_rev" : "_VTxTctu--_",
"type" : "is-in"
},
{
"_key" : "33438",
"_id" : "worldEdges/33438",
"_from" : "worldVertices/continent-south-america",
"_to" : "worldVertices/world",
"_rev" : "_VTxTctS---",
"type" : "is-in"
},
{
"_key" : "33513",
"_id" : "worldEdges/33513",
"_from" : "worldVertices/country-cameroon",
"_to" : "worldVertices/continent-africa",
"_rev" : "_VTxTctm--B",
"type" : "is-in"
},
{
"_key" : "33441",
"_id" : "worldEdges/33441",
"_from" : "worldVertices/country-afghanistan",
"_to" : "worldVertices/continent-asia",
"_rev" : "_VTxTctS--_",
"type" : "is-in"
},
{
"_key" : "33609",
"_id" : "worldEdges/33609",
"_from" : "worldVertices/capital-gaborone",
"_to" : "worldVertices/country-botswana",
"_rev" : "_VTxTcuK--_",
"type" : "is-in"
},
{
"_key" : "33651",
"_id" : "worldEdges/33651",
"_from" : "worldVertices/capital-saint-john-s",
"_to" : "worldVertices/country-antigua-and-barbuda",
"_rev" : "_VTxTcuS--D",
"type" : "is-in"
},
{
"_key" : "33657",
"_id" : "worldEdges/33657",
"_from" : "worldVertices/capital-sarajevo",
"_to" : "worldVertices/country-bosnia-and-herzegovina",
"_rev" : "_VTxTcuW--_",
"type" : "is-in"
},
{
"_key" : "33486",
"_id" : "worldEdges/33486",
"_from" : "worldVertices/country-bolivia",
"_to" : "worldVertices/continent-south-america",
"_rev" : "_VTxTcte--B",
"type" : "is-in"
},
{
"_key" : "33654",
"_id" : "worldEdges/33654",
"_from" : "worldVertices/capital-santiago",
"_to" : "worldVertices/country-chile",
"_rev" : "_VTxTcuW---",
"type" : "is-in"
},
{
"_key" : "33645",
"_id" : "worldEdges/33645",
"_from" : "worldVertices/capital-prague",
"_to" : "worldVertices/country-czech-republic",
"_rev" : "_VTxTcuS--B",
"type" : "is-in"
},
{
"_key" : "33600",
"_id" : "worldEdges/33600",
"_from" : "worldVertices/capital-canberra",
"_to" : "worldVertices/country-australia",
"_rev" : "_VTxTcuG--B",
"type" : "is-in"
},
{
"_key" : "33546",
"_id" : "worldEdges/33546",
"_from" : "worldVertices/country-eritrea",
"_to" : "worldVertices/continent-africa",
"_rev" : "_VTxTcty--B",
"type" : "is-in"
},
{
"_key" : "33615",
"_id" : "worldEdges/33615",
"_from" : "worldVertices/capital-kabul",
"_to" : "worldVertices/country-afghanistan",
"_rev" : "_VTxTcuK--B",
"type" : "is-in"
},
{
"_key" : "33636",
"_id" : "worldEdges/33636",
"_from" : "worldVertices/capital-ouagadougou",
"_to" : "worldVertices/country-burkina-faso",
"_rev" : "_VTxTcuS---",
"type" : "is-in"
},
{
"_key" : "33558",
"_id" : "worldEdges/33558",
"_from" : "worldVertices/country-people-s-republic-of-china",
"_to" : "worldVertices/continent-asia",
"_rev" : "_VTxTct6---",
"type" : "is-in"
},
{
"_key" : "33603",
"_id" : "worldEdges/33603",
"_from" : "worldVertices/capital-copenhagen",
"_to" : "worldVertices/country-denmark",
"_rev" : "_VTxTcuG--C",
"type" : "is-in"
},
{
"_key" : "33648",
"_id" : "worldEdges/33648",
"_from" : "worldVertices/capital-quito",
"_to" : "worldVertices/country-ecuador",
"_rev" : "_VTxTcuS--C",
"type" : "is-in"
},
{
"_key" : "33501",
"_id" : "worldEdges/33501",
"_from" : "worldVertices/country-bulgaria",
"_to" : "worldVertices/continent-europe",
"_rev" : "_VTxTcti--B",
"type" : "is-in"
},
{
"_key" : "33612",
"_id" : "worldEdges/33612",
"_from" : "worldVertices/capital-helsinki",
"_to" : "worldVertices/country-finland",
"_rev" : "_VTxTcuK--A",
"type" : "is-in"
},
{
"_key" : "33606",
"_id" : "worldEdges/33606",
"_from" : "worldVertices/capital-dhaka",
"_to" : "worldVertices/country-bangladesh",
"_rev" : "_VTxTcuK---",
"type" : "is-in"
},
{
"_key" : "33660",
"_id" : "worldEdges/33660",
"_from" : "worldVertices/capital-sofia",
"_to" : "worldVertices/country-bulgaria",
"_rev" : "_VTxTcuW--A",
"type" : "is-in"
},
{
"_key" : "33447",
"_id" : "worldEdges/33447",
"_from" : "worldVertices/country-algeria",
"_to" : "worldVertices/continent-africa",
"_rev" : "_VTxTctS--B",
"type" : "is-in"
},
{
"_key" : "33453",
"_id" : "worldEdges/33453",
"_from" : "worldVertices/country-angola",
"_to" : "worldVertices/continent-africa",
"_rev" : "_VTxTctW---",
"type" : "is-in"
},
{
"_key" : "33510",
"_id" : "worldEdges/33510",
"_from" : "worldVertices/country-cambodia",
"_to" : "worldVertices/continent-asia",
"_rev" : "_VTxTctm--A",
"type" : "is-in"
},
{
"_key" : "33507",
"_id" : "worldEdges/33507",
"_from" : "worldVertices/country-burundi",
"_to" : "worldVertices/continent-africa",
"_rev" : "_VTxTctm--_",
"type" : "is-in"
},
{
"_key" : "33588",
"_id" : "worldEdges/33588",
"_from" : "worldVertices/capital-brussels",
"_to" : "worldVertices/country-belgium",
"_rev" : "_VTxTcuC--B",
"type" : "is-in"
},
{
"_key" : "33624",
"_id" : "worldEdges/33624",
"_from" : "worldVertices/capital-manama",
"_to" : "worldVertices/country-bahrain",
"_rev" : "_VTxTcuO--_",
"type" : "is-in"
},
{
"_key" : "33462",
"_id" : "worldEdges/33462",
"_from" : "worldVertices/country-australia",
"_to" : "worldVertices/continent-australia",
"_rev" : "_VTxTctW--B",
"type" : "is-in"
},
{
"_key" : "33498",
"_id" : "worldEdges/33498",
"_from" : "worldVertices/country-brunei",
"_to" : "worldVertices/continent-asia",
"_rev" : "_VTxTcti--A",
"type" : "is-in"
},
{
"_key" : "33534",
"_id" : "worldEdges/33534",
"_from" : "worldVertices/country-czech-republic",
"_to" : "worldVertices/continent-europe",
"_rev" : "_VTxTctu--B",
"type" : "is-in"
},
{
"_key" : "33435",
"_id" : "worldEdges/33435",
"_from" : "worldVertices/continent-north-america",
"_to" : "worldVertices/world",
"_rev" : "_VTxTctO--B",
"type" : "is-in"
},
{
"_key" : "33477",
"_id" : "worldEdges/33477",
"_from" : "worldVertices/country-barbados",
"_to" : "worldVertices/continent-north-america",
"_rev" : "_VTxTcte---",
"type" : "is-in"
},
{
"_key" : "33429",
"_id" : "worldEdges/33429",
"_from" : "worldVertices/continent-australia",
"_to" : "worldVertices/world",
"_rev" : "_VTxTctO--_",
"type" : "is-in"
},
{
"_key" : "33633",
"_id" : "worldEdges/33633",
"_from" : "worldVertices/capital-ottawa",
"_to" : "worldVertices/country-canada",
"_rev" : "_VTxTcuO--C",
"type" : "is-in"
},
{
"_key" : "33675",
"_id" : "worldEdges/33675",
"_from" : "worldVertices/capital-yaounde",
"_to" : "worldVertices/country-cameroon",
"_rev" : "_VTxTcua--A",
"type" : "is-in"
},
{
"_key" : "33480",
"_id" : "worldEdges/33480",
"_from" : "worldVertices/country-belgium",
"_to" : "worldVertices/continent-europe",
"_rev" : "_VTxTcte--_",
"type" : "is-in"
},
{
"_key" : "33459",
"_id" : "worldEdges/33459",
"_from" : "worldVertices/country-argentina",
"_to" : "worldVertices/continent-south-america",
"_rev" : "_VTxTctW--A",
"type" : "is-in"
},
{
"_key" : "33504",
"_id" : "worldEdges/33504",
"_from" : "worldVertices/country-burkina-faso",
"_to" : "worldVertices/continent-africa",
"_rev" : "_VTxTctm---",
"type" : "is-in"
},
{
"_key" : "33422",
"_id" : "worldEdges/33422",
"_from" : "worldVertices/continent-africa",
"_to" : "worldVertices/world",
"_rev" : "_VTxTctK--C",
"type" : "is-in"
},
{
"_key" : "33525",
"_id" : "worldEdges/33525",
"_from" : "worldVertices/country-colombia",
"_to" : "worldVertices/continent-south-america",
"_rev" : "_VTxTctu---",
"type" : "is-in"
},
{
"_key" : "33555",
"_id" : "worldEdges/33555",
"_from" : "worldVertices/country-germany",
"_to" : "worldVertices/continent-europe",
"_rev" : "_VTxTct2--A",
"type" : "is-in"
},
{
"_key" : "33597",
"_id" : "worldEdges/33597",
"_from" : "worldVertices/capital-cairo",
"_to" : "worldVertices/country-egypt",
"_rev" : "_VTxTcuG--A",
"type" : "is-in"
},
{
"_key" : "33627",
"_id" : "worldEdges/33627",
"_from" : "worldVertices/capital-nassau",
"_to" : "worldVertices/country-bahamas",
"_rev" : "_VTxTcuO--A",
"type" : "is-in"
},
{
"_key" : "33492",
"_id" : "worldEdges/33492",
"_from" : "worldVertices/country-botswana",
"_to" : "worldVertices/continent-africa",
"_rev" : "_VTxTcti---",
"type" : "is-in"
},
{
"_key" : "33672",
"_id" : "worldEdges/33672",
"_from" : "worldVertices/capital-yamoussoukro",
"_to" : "worldVertices/country-cote-d-ivoire",
"_rev" : "_VTxTcua--_",
"type" : "is-in"
},
{
"_key" : "33465",
"_id" : "worldEdges/33465",
"_from" : "worldVertices/country-austria",
"_to" : "worldVertices/continent-europe",
"_rev" : "_VTxTcta---",
"type" : "is-in"
},
{
"_key" : "33573",
"_id" : "worldEdges/33573",
"_from" : "worldVertices/capital-beijing",
"_to" : "worldVertices/country-people-s-republic-of-china",
"_rev" : "_VTxTcu---_",
"type" : "is-in"
},
{
"_key" : "33483",
"_id" : "worldEdges/33483",
"_from" : "worldVertices/country-bhutan",
"_to" : "worldVertices/continent-asia",
"_rev" : "_VTxTcte--A",
"type" : "is-in"
},
{
"_key" : "33516",
"_id" : "worldEdges/33516",
"_from" : "worldVertices/country-canada",
"_to" : "worldVertices/continent-north-america",
"_rev" : "_VTxTctq---",
"type" : "is-in"
},
{
"_key" : "33666",
"_id" : "worldEdges/33666",
"_from" : "worldVertices/capital-tirana",
"_to" : "worldVertices/country-albania",
"_rev" : "_VTxTcuW--C",
"type" : "is-in"
},
{
"_key" : "33540",
"_id" : "worldEdges/33540",
"_from" : "worldVertices/country-ecuador",
"_to" : "worldVertices/continent-south-america",
"_rev" : "_VTxTcty--_",
"type" : "is-in"
},
{
"_key" : "33594",
"_id" : "worldEdges/33594",
"_from" : "worldVertices/capital-bujumbura",
"_to" : "worldVertices/country-burundi",
"_rev" : "_VTxTcuG--_",
"type" : "is-in"
},
{
"_key" : "33450",
"_id" : "worldEdges/33450",
"_from" : "worldVertices/country-andorra",
"_to" : "worldVertices/continent-europe",
"_rev" : "_VTxTctS--C",
"type" : "is-in"
},
{
"_key" : "33495",
"_id" : "worldEdges/33495",
"_from" : "worldVertices/country-brazil",
"_to" : "worldVertices/continent-south-america",
"_rev" : "_VTxTcti--_",
"type" : "is-in"
},
{
"_key" : "33576",
"_id" : "worldEdges/33576",
"_from" : "worldVertices/capital-berlin",
"_to" : "worldVertices/country-germany",
"_rev" : "_VTxTcu---A",
"type" : "is-in"
},
{
"_key" : "33591",
"_id" : "worldEdges/33591",
"_from" : "worldVertices/capital-buenos-aires",
"_to" : "worldVertices/country-argentina",
"_rev" : "_VTxTcuG---",
"type" : "is-in"
},
{
"_key" : "33564",
"_id" : "worldEdges/33564",
"_from" : "worldVertices/capital-andorra-la-vella",
"_to" : "worldVertices/country-andorra",
"_rev" : "_VTxTct6--A",
"type" : "is-in"
},
{
"_key" : "33444",
"_id" : "worldEdges/33444",
"_from" : "worldVertices/country-albania",
"_to" : "worldVertices/continent-europe",
"_rev" : "_VTxTctS--A",
"type" : "is-in"
},
{
"_key" : "33678",
"_id" : "worldEdges/33678",
"_from" : "worldVertices/capital-zagreb",
"_to" : "worldVertices/country-croatia",
"_rev" : "_VTxTcua--B",
"type" : "is-in"
},
{
"_key" : "33630",
"_id" : "worldEdges/33630",
"_from" : "worldVertices/capital-n-djamena",
"_to" : "worldVertices/country-chad",
"_rev" : "_VTxTcuO--B",
"type" : "is-in"
},
{
"_key" : "33561",
"_id" : "worldEdges/33561",
"_from" : "worldVertices/capital-algiers",
"_to" : "worldVertices/country-algeria",
"_rev" : "_VTxTct6--_",
"type" : "is-in"
}
]
arangosh> examples.dropGraph("worldCountry");
true
arangosh> var g = examples.loadGraph("worldCountryUnManaged");
arangosh> examples.dropGraph("worldCountryUnManaged");
arangosh> var examples = require("@arangodb/graph-examples/example-graph.js");
arangosh> var g = examples.loadGraph("worldCountry");
arangosh> db.worldVertices.toArray();
arangosh> db.worldEdges.toArray();
arangosh> examples.dropGraph("worldCountry");
arangosh> var g = examples.loadGraph("worldCountryUnManaged");
arangosh> examples.dropGraph("worldCountryUnManaged");
Cookbook examples
The above referenced chapters describe the various APIs of ArangoDBs graph engine with small examples. Our cookbook has some more real life examples:
- Traversing a graph in full depth
- Using an example vertex with the java driver
- Retrieving documents from ArangoDB without knowing the structure
- Using a custom visitor from node.js
- AQL Example Queries on an Actors and Movies Database
Higher volume graph examples
All of the above examples are rather small so they are easier to comprehend and can demonstrate the way the functionality works. There are however several datasets freely available on the web that are a lot bigger. We collected some of them with import scripts so you may play around with them. Another huge graph is the Pokec social network from Slovakia that we used for performance testing on several databases; You will find importing scripts etc. in this blogpost.