Data recovery from remote clusters
Data recovery from remote clusters requires an XDCR environment and adequate amount of memory and disk space to support the workload and recovered data.
If more nodes fail in a cluster than the number of replicas, data partitions in that cluster will no longer be available. For instance, if you have a four node cluster with one replica per node and two nodes fail, some data partitions will no longer be available. There are two solutions for this scenario:
- Recover data from disk. If you plan on recovering from disk, you may not be able to do so if the disk completely fails.
- Recover partitions from a remote cluster. You can use this second option when you have XDCR set up to replicate data to the second cluster. The requirement for using cbrecovery is that you need to set up a second cluster that will contain backup data.
The following shows a scenario where replica vBuckets are lost from a cluster due to multi-node failure:
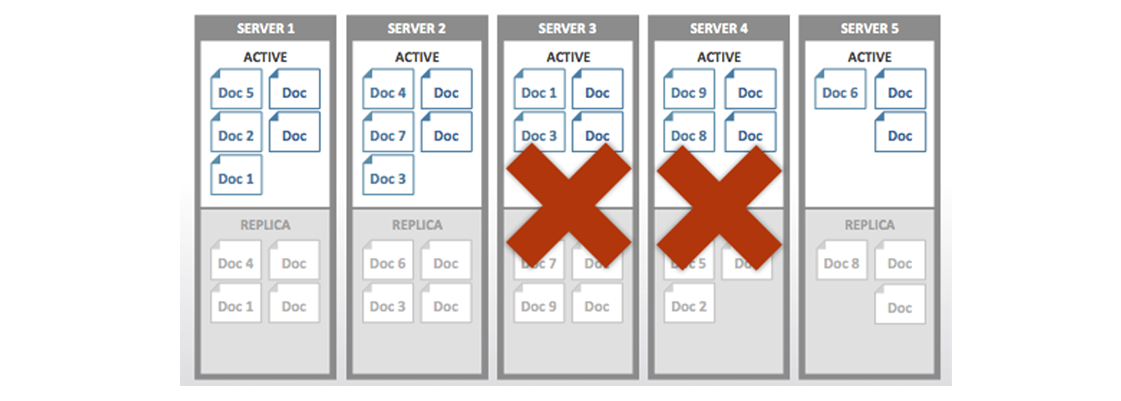
Before you perform a recovery, make sure that your main cluster has an adequate amount of memory and disk space to support the workload as well as the data you recover. This means that even though you can recover data to a cluster with failed nodes, you should investigate what caused the node failures and also make sure your cluster has adequate capacity before you recover data. If you do add nodes be certain to rebalance only after you have
When you use cbrecovery it compares the data partitions from a main cluster with a backup cluster, then sends missing data partitions detected. If it fails, once you successfully restart cbrecovery, it will do a delta between clusters again and determine any missing partitions since the failure then resume restoring these partitions.
Failure Scenarios
Imagine the following happens when you have a four node cluster with one replica. Each node has 256 active and 256 replica vBuckets which total 1024 active and 1024 replica vBuckets:
- When one node fails, some active and some replica vBuckets are no longer available in the cluster.
- After you fail over this node, the corresponding replica vBuckets on other nodes will be put into an active state. At this point you have a full set of active vBuckets and a partial set of replica vBuckets in the cluster.
- A second node fails. More active vBuckets will not be accessible.
- You fail over the second node. At this point any missing active vBuckets that do not have corresponding replica vBuckets will be lost.
In this type of scenario you can use cbrecovery to get the missing vBuckets from your backup cluster. If you have multi-node failure on both your main and backup clusters you will experience data loss.
Recovery Scenarios for cbrecovery
The following describes some different cluster setups so that you can better understand whether or not this approach will work in your failure scenario:
- Multiple Node Failure in Cluster. If multiple nodes fail in a cluster then some vBuckets may be unavailable. In this case if you have already setup XDCR with another cluster, you can recover those unavailable vBuckets from the other cluster.
- Bucket with Inadequate Replicas.
Single Bucket. In this case where we have only one bucket with zero replicas on all the nodes in a cluster. In this case when a node goes down in the cluster some of the partitions for that node will be unavailable. If we have XDCR set up for this cluster we can recover the missing partitions with cbrecovery.
Multi-Bucket. In this case, nodes in a cluster have multiple buckets and some buckets might have replicas and some do not. In the image below we have a cluster and all nodes have two buckets, Bucket1 and Bucket2. Bucket 1 has replicas but Bucket2 does not. In this case if one of the nodes goes down, since Bucket 1 has replicas, when we failover the node the replicas on other nodes will be activated. But for the bucket with no replicas some partitions will be unavailable and will require cbrecovery to recover data. In this same example if multiple nodes fail in the cluster, we need to perform vBucket recovery both buckets since both will have missing partitions.
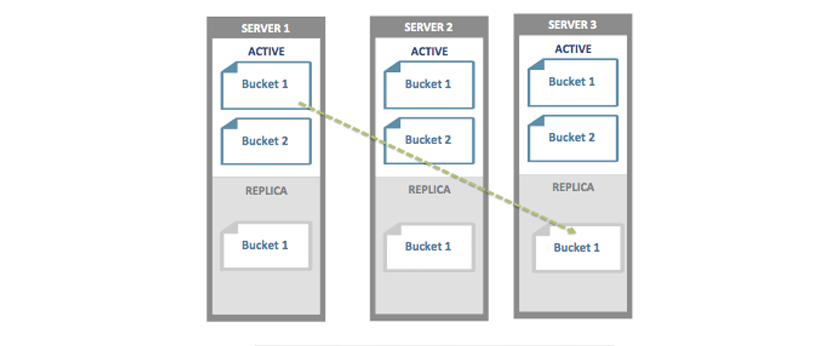
Handling the Recovery
Should you encounter node failure and have unavailable vBuckets, you should follow this process:
- For each failed node, Click Fail Over under the Server Nodes tab in Web Console.
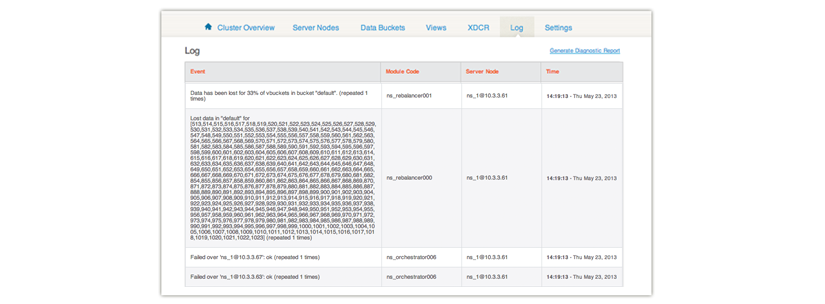
After you click Fail Over, under Web Console | Log tab you will see whether data is unavailable and which vBuckets are unavailable. If you do not have enough replicas for the number of failed over nodes, some vBuckets will no longer be available:
- Add new functioning nodes to replace the failed nodes.
Do not rebalance after you add new nodes to the cluster. Typically you do this after adding nodes to a cluster, but in this scenario the rebalance will destroy information about the missing vBuckets and you cannot recover them.
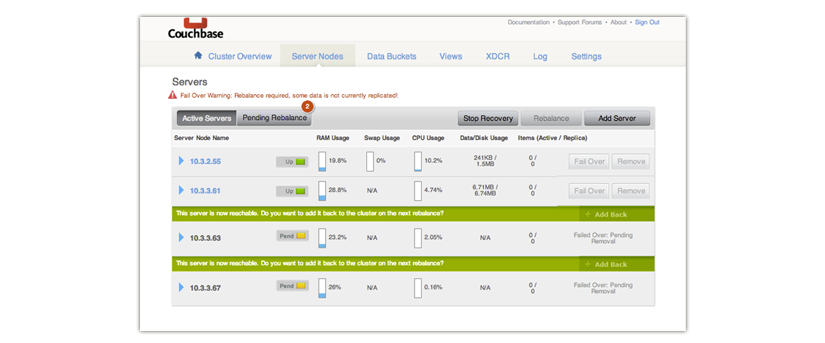
In this example we have two nodes that failed in a three-node cluster and we add a new node 10.3.3.61.
If you are certain your cluster can easily handle the workload and recovered data, you may choose to skip this step.
- Run cbrecovery to recover data from your backup cluster. In the Server
Panel, a Stop Recovery button appears.
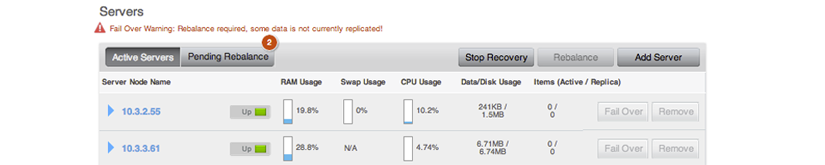
After the recovery completes, this button disappears.
- Rebalance your cluster.
Once the recovery is done, you can rebalance your cluster, which will recreate replica vBuckets and evenly redistribute them across the cluster.

Recovery ‘Dry-Run’
Before you recover vBuckets, you may want to preview a list of buckets no longer available in the cluster. Use this command and options:
shell> ./cbrecovery http://Administrator:[email protected]:8091 http://Administrator:[email protected]:8091 -n
Here we provide administrative credentials for the node in the cluster as well as the option -n. This will return a list of vBuckets in the remote secondary cluster which are no longer in the your first cluster. If there are any unavailable buckets in the cluster with failed nodes, you see output as follows:
2013-04-29 18:16:54,384: MainThread Missing vbuckets to be recovered:[{"node": "[email protected]",
"vbuckets": [513, 514, 515, 516, 517, 518, 519, 520, 521, 522, 523, 524, 525, 526,, 528, 529,
530, 531, 532, 533, 534, 535, 536, 537, 538, 539, 540, 541, 542, 543, 544, 545,, 547, 548,
549, 550, 551, 552, 553, 554, 555, 556, 557, 558, 559, 560, 561, 562, 563, 564, 565, 566, 567,
568, 569, 570, 571, 572,....
Where the vbuckets array contains all the vBuckets that are no longer available in the cluster. These are the bucket you can recover from the remotes cluster. To recover the vBuckets:
shell> ./cbrecovery http://Administrator:password@<From_IP>:8091 \
http://Administrator:password@<To_IP>:8091 -B bucket_name
You can run the command on either the cluster with unavailable vBuckets or on the remote cluster, as long as you provide the hostname, port, and credentials for remote cluster and the cluster with missing vBuckets in that order. If you do not provide the parameter -B the tool assumes you will recover unavailable vBuckets for the default bucket.
Monitoring the Recovery Process
You can monitor the progress of recovery under the Data Buckets tab of Couchbase Web Console:
- Click on the Data Buckets tab.
- Select the data bucket you are recovering in the Data Buckets drop-down.
- Click on the Summary drop-down to see more details about this data bucket. You see an
increased number in the items level during recovery:

- You can also see the number of active vBuckets increase as they are recovered until you
reach 1024 vBuckets. Click on the vBucket Resources drop-down:

As this tool runs from the command line you can stop it at any time as you would any other command-line tool.
- A Stop Recovery button appears in the Servers panels. If you click this
button, you will stop the recovery process between clusters. Once the recovery process
completes, this button will no longer appear and you will need to rebalance the cluster. If you
are in Couchbase Web Console, you can also stop it in this panel:
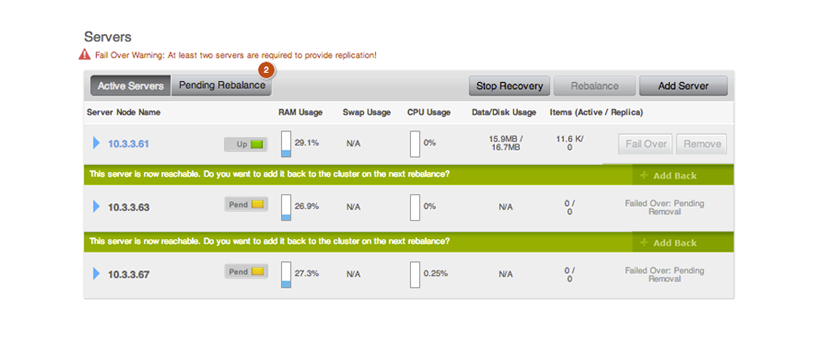
- After recovery completes, click on the Server Nodes tab then Rebalance to rebalance your cluster.
When cbrecovery finishes it will output a report in the console:
Recovery : Total | Per sec
batch : 0000 | 14.5
byte : 0000 | 156.0
msg : 0000 | 15.6
4 vbuckets recovered with elapsed time 10.90 seconds
In this report batch is a group of internal operations performed by cbrecovery, byte indicates the total number of bytes recovered and msg is the number of documents recovered.