Ice is inherently a multi-threaded platform. There is no such thing as a single-threaded server in Ice. As a result, you must concern yourself with concurrency issues: if a thread reads a data structure while another thread updates the same data structure, havoc will ensue unless you protect the data structure with appropriate locks. In order to build Ice applications that behave correctly, it is important that you understand the threading semantics of the Ice run time. This section discusses Ice’s
thread pool concurrency model and provides guidelines for writing thread-safe Ice applications.
•
The client thread pool services outgoing connections, which primarily involves handling the replies to outgoing requests and includes notifying AMI callback objects. If a connection is used in bidirectional mode (see
Section 36.7), the client thread pool also dispatches incoming callback requests.
•
The server thread pool services incoming connections. It dispatches incoming requests and, for bidirectional connections, processes replies to outgoing requests.
By default, these two thread pools are shared by all of the communicator’s object adapters. If necessary, you can configure individual object adapters to use a private thread pool instead.
If a thread pool is exhausted because all threads are currently dispatching a request, additional incoming requests are transparently delayed until a request completes and relinquishes its thread; that thread is then used to dispatch the next pending request. Ice minimizes thread context switches in a thread pool by using a leader-follower implementation (see
[17]).
A thread pool is dynamic when
name.SizeMax exceeds
name.Size. As the demand for threads increases, the Ice run time adds more threads to the pool, up to the maximum size. Threads are terminated automatically when they have been idle for a while, but a thread pool always contains at least the minimum number of threads.
Setting this property to a value greater than zero forces the thread pool to serialize all messages received over a connection. It is unnecessary to enable serialization for a thread pool whose maximum size is one because such a thread pool is already limited to processing one message at a time. For thread pools with more than one thread, serialization has a negative impact on latency and throughput. If not defined, the default value is zero.
For configuration purposes, the names of the client and server thread pools are Ice.ThreadPool.Client and
Ice.ThreadPool.Server, respectively. As an example, the following properties establish minimum and maximum sizes for these thread pools:
To monitor the thread pool activities of the Ice run time, you can enable the Ice.Trace.ThreadPool property. Setting this property to a non-zero value causes the Ice run time to log a message when it creates a thread pool, as well as each time the size of a thread pool increases or decreases.
The default behavior of an object adapter is to share the thread pools of its communicator and, for many applications, this behavior is entirely sufficient. However, the ability to configure an object adapter with its own thread pool is useful in certain situations:
In a server with multiple object adapters, the configuration of the communicator’s client and server thread pools may be a good match for some object adapters, but others may have different requirements. For example, the servants hosted by one object adapter may not support concurrent access, in which case limiting that object adapter to a single-threaded pool eliminates the need for synchronization in those servants. On the other hand, another object adapter might need a multi-threaded pool for better performance.
An object adapter’s thread pool supports all of the properties described in Section 32.10.2. For configuration purposes, the name of an adapter’s thread pool is
adapter.ThreadPool, where
adapter is the name of the adapter.
These properties have the same semantics as those described earlier except they both have a default value of zero, meaning that an adapter uses the communicator’s thread pools by default.
Improper configuration of a thread pool can have a serious impact on the performance of your application. This section discusses some issues that you should consider when designing and configuring your applications.
It is important to remember that a communicator’s client and server thread pools have a default maximum size of one thread, therefore these limitations also apply to any object adapter that shares the communicator’s thread pools.
Configuring a thread pool to support multiple threads implies that the application is prepared for the Ice run time to dispatch operation invocations or AMI callbacks concurrently. Although greater effort is required to design a thread-safe application, you are rewarded with the ability to improve the application’s scalability and throughput.
Choosing appropriate minimum and maximum sizes for a thread pool requires careful analysis of your application. For example, in compute-bound applications it is best to limit the number of threads to the number of physical processors in the host machine; adding any more threads only increases context switches and reduces performance. Increasing the size of the pool beyond the number of processors can improve responsiveness when threads can become blocked while waiting for the operating system to complete a task, such as a network or file operation. On the other hand, a thread pool configured with too many threads can have the opposite effect and negatively impact performance. Testing your application in a realistic environment is the recommended way of determining the optimum size for a thread pool.
If your application uses nested invocations, it is very important that you evaluate whether it is possible for thread starvation to cause a deadlock. Increasing the size of a thread pool can lessen the chance of a deadlock, but other design solutions are usually preferred.
Section 32.10.5 discusses nested invocations in more detail.
When using a multi-threaded pool, the nondeterministic nature of thread scheduling means that requests from the same connection may not be dispatched in the order they were received. Some applications cannot tolerate this behavior, such as a transaction processing server that must guarantee that requests are executed in order. There are two ways of satisfying this requirement:
At first glance these two options may seem equivalent, but there is a significant difference: a single-threaded pool can only dispatch one request at a time and therefore serializes requests from
all connections, whereas a multi-threaded pool configured for serialization can dispatch requests from different connections concurrently while serializing requests from the same connection.
You can obtain the same behavior from a multi-threaded pool without enabling serialization, but only if you design the clients so that they do not send requests from multiple threads, do not send requests over more than one connection, and only use synchronous twoway invocations. In general, however, it is better to avoid such tight coupling between the implementations of the client and server.
Enabling serialization can improve responsiveness and performance compared to a single-threaded pool, but there is an associated cost. The extra synchronization that the pool must perform to serialize requests adds significant overhead and results in higher latency and reduced throughput.
As you can see, thread pool serialization is not a feature that you should enable without analyzing whether the benefits are worthwhile. For example, it might be an inappropriate choice for a server with long-running operations when the client needs the ability to have several operations in progress simultaneously. If serialization was enabled in this situation, the client would be forced to work around it by opening several connections to the server (see
Section 36.3), which again tightly couples the client and server implementations. If the server must keep track of the order of client requests, a better solution would be to use serialization in conjunction with asynchronous dispatch to queue the incoming requests for execution by other threads.
A nested invocation is one that is made within the context of another Ice operation. For instance, the implementation of an operation in a servant might need to make a nested invocation on some other object, or an AMI callback object might invoke an operation in the course of processing a reply to an asynchronous request. It is also possible for one of these invocations to result in a nested callback to the originating process. The maximum depth of such invocations is determined by the size of the thread pools used by the communicating parties.
Applications that use nested invocations must be carefully designed to avoid the potential for deadlock, which can easily occur when invocations take a circular path. For example,
Figure 32.5 presents a deadlock scenario when using the default thread pool configuration.
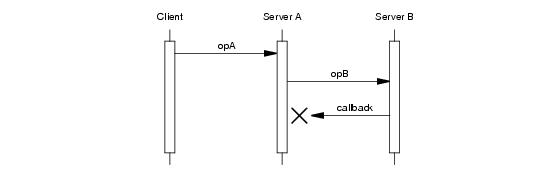
In this diagram, the implementation of opA makes a nested twoway invocation of
opB, but the implementation of
opB causes a deadlock when it tries to make a nested callback. As mentioned in
Section 32.10.1, the communicator’s thread pools have a maximum size of one thread unless explicitly configured otherwise. In Server A, the only thread in the server thread pool is busy waiting for its invocation of
opB to complete, and therefore no threads remain to handle the callback from Server B. The client is now blocked because Server A is blocked, and they remain blocked indefinitely unless timeouts are used.
Configuring the server thread pool in Server A to support more than one thread allows the nested callback to proceed. This is the simplest solution, but it requires that you know in advance how deeply nested the invocations may occur, or that you set the maximum size to a sufficiently large value that exhausting the pool becomes unlikely. For example, setting the maximum size to two avoids a deadlock when a single client is involved, but a deadlock could easily occur again if multiple clients invoke
opA simultaneously. Furthermore, setting the maximum size too large can cause its own set of problems (see
Section 32.10.4).
If Server A called
opB using a oneway invocation, it would no longer need to wait for a response and therefore
opA could complete, making a thread available to handle the callback from Server B. However, we have made a significant change in the semantics of
opA because now there is no guarantee that
opB has completed before
opA returns, and it is still possible for the oneway invocation of
opB to block (see
Section 32.14).
•
Implement opA using asynchronous dispatch and invocation.
By declaring opA as an AMD operation and invoking
opB using AMI, Server A can avoid blocking the thread pool’s thread while it waits for
opB to complete. This technique, known as
asynchronous request chaining, is used extensively in Ice services such as IceGrid and Glacier2 to eliminate the possibility of deadlocks.
As another example, consider a client that makes a nested invocation from an AMI callback object using the default thread pool configuration. The (one and only) thread in the client thread pool receives the reply to the asynchronous request and invokes its callback object. If the callback object in turn makes a nested twoway invocation, a deadlock occurs because no more threads are available in the client thread pool to process the reply to the nested invocation. The solutions are similar to some of those presented for
Figure 32.5: increase the maximum size of the client thread pool, use a oneway invocation, or call the nested invocation using AMI.
•
The thread pool configurations in use by all communicating parties have a significant impact on an application’s ability to use nested invocations. While analyzing the path of circular invocations, you must pay careful attention to the threads involved to determine whether sufficient threads are available to avoid deadlock. This includes not just the threads that dispatch requests, but also the threads that make the requests and process the replies. Enabling the
Ice.Trace.ThreadPool can give you a better understanding of the thread pool behavior in your application.
As you can imagine, tracing the call flow of a distributed application to ensure there is no possibility of deadlock can quickly become a complex and tedious process. In general, it is best to avoid circular invocations if at all possible.
The Ice run time itself is fully thread safe, meaning multiple application threads can safely call methods on objects such as communicators, object adapters, and proxies without synchronization problems. As a developer, you must also be concerned with thread safety because the Ice run time can dispatch multiple invocations concurrently in a server. In fact, it is possible for multiple requests to proceed in parallel within the same servant and within the same operation on that servant. It follows that, if the operation implementation manipulates non-stack storage (such as member variables of the servant or global or static data), you must interlock access to this data to avoid data corruption.
The need for thread safety in an application depends on its configuration. Using the default thread pool configuration typically makes synchronization unnecessary because at most one operation can be dispatched at a time. Thread safety becomes an issue once you increase the maximum size of a thread pool.
Ice uses the native synchronization and threading primitives of each platform. For C++ users, Ice provides a collection of convenient and portable wrapper classes for use by Ice applications (see
Chapter 31).
The marshaling semantics of the Ice run time present a subtle thread safety issue that arises when an operation returns data by reference. In C++, the only relevant case is returning an instance of a Slice class, either directly or nested as a member of another type. In Java, .NET, and Python, Slice structures, sequences, and dictionaries are also affected.
The potential for corruption occurs whenever a servant returns data by reference, yet continues to hold a reference to that data. For example, consider the following Java implementation:
public class GridI extends _GridDisp
{
GridI()
{
_grid = // ...
}
public int[][]
getGrid(Ice.Current curr)
{
return _grid;
}
public void
setValue(int x, int y, int val, Ice.Current curr)
{
_grid[x][y] = val;
}
private int[][] _grid;
}
Suppose that a client invoked the getGrid operation. While the Ice run time marshals the returned array in preparation to send a reply message, it is possible for another thread to dispatch the
setValue operation on the same servant. This race condition can result in several unexpected outcomes, including a failure during marshaling or inconsistent data in the reply to
getGrid. Synchronizing the
getGrid and
setValue operations would not fix the race condition because the Ice run time performs its marshaling outside of this synchronization.
One solution is to implement accessor operations, such as getGrid, so that they return copies of any data that might change. There are several drawbacks to this approach:
Another solution is to make copies of the affected data only when it is modified. In the revised code shown below,
setValue replaces
_grid with a copy that contains the new element, leaving the previous contents of
_grid unchanged:
public class GridI extends _GridDisp
{
...
public synchronized int[][]
getGrid(Ice.Current curr)
{
return _grid;
}
public synchronized void
setValue(int x, int y, int val, Ice.Current curr)
{
int[][] newGrid = // shallow copy...
newGrid[x][y] = val;
_grid = newGrid;
}
...
}
This allows the Ice run time top safely marshal the return value of getGrid because the array is never modified again. For applications where data is read more often than it is written, this solution is more efficient than the previous one because accessor operations do not need to make copies. Furthermore, intelligent use of shallow copying can minimize the overhead in mutating operations.
Finally, a third approach changes accessor operations to use AMD in order to regain control over marshaling. After annotating the
getGrid operation with
amd metadata, we can revise the servant as follows:
public class GridI extends _GridDisp
{
...
public synchronized void
getGrid_async(AMD_Grid_getGrid cb, Ice.Current curr)
{
cb.ice_response(_grid);
}
public synchronized void
setValue(int x, int y, int val, Ice.Current curr)
{
_grid[x][y] = val;
}
...
}
Normally, AMD is used in situations where the servant needs to delay its response to the client without blocking the calling thread. For getGrid, that is not the goal; instead, as a side-effect, AMD provides the desired marshaling behavior. Specifically, the Ice run time marshals the reply to an asynchronous request at the time the servant invokes
ice_response on the AMD callback object. Because
getGrid and
setValue are synchronized, this guarantees that the data remains in a consistent state during marshaling.
On occasion, it is necessary to intercept the creation and destruction of threads created by the Ice run time, for example, to interoperate with libraries that require applications to make thread-specific initialization and finalization calls (such as COM’s
CoInitializeEx and
CoUninitialize). Ice provides callbacks to inform an application when each run-time thread is created and destroyed. For C++, the callback class looks as follows:
1
class ThreadNotification : public IceUtil::Shared {
public:
virtual void start() = 0;
virtual void stop() = 0;
};
typedef IceUtil::Handle<ThreadNotification> ThreadNotificationPtr;
To receive notification of thread creation and destruction, you must derive a class from
ThreadNotification and implement the
start and
stop member functions. These functions will be called by the Ice run by each thread as soon as it is created, and just before it exits. You must install your callback class in the Ice run time when you create a communicator by setting the
threadHook member of the
InitializationData structure (see
Section 32.3).
class MyHook : public virtual Ice::ThreadNotification {
public:
void start()
{
cout << "start: id = " << ThreadControl().id() << endl;
}
void stop()
{
cout << "stop: id = " << ThreadControl().id() << endl;
}
};
int
main(int argc, char* argv[])
{
// ...
Ice::InitializationData id;
id.threadHook = new MyHook;
communicator = Ice::initialize(argc, argv, id);
// ...
}
The implementation of your start and
stop methods can make whatever thread-specific calls are required by your application.
For Java and C#, Ice.ThreadNotification is an interface:
public interface ThreadNotification {
void start();
void stop();
}
To receive the thread creation and destruction callbacks, you must derive a class from this interface that implements the
start and
stop methods, and register an instance of that class when you create the communicator. (The code to do this is analogous to the C++ version.)
class ThreadNotification(object):
def __init__(self):
pass
# def start():
# def stop():
The Ice run time calls the start and
stop methods of the class instance you provide to
Ice.initialize (see
Section 24.3) when it creates and destroys threads.
The thread hook facility described on page 1012 requires that you modify a program’s source code in order to receive callbacks when threads in the Ice run time are created and destroyed. It is also possible to install thread hooks using the Ice plug-in facility (see
Section 32.25), which is useful for adding thread hooks to an existing program that you cannot (or prefer not to) modify.
Ice provides a base class named ThreadHookPlugin for C++, Java, and C# that supplies the necessary functionality. The C++ class definition is shown below:
namespace Ice {
class ThreadHookPlugin : public Ice::Plugin {
public:
ThreadHookPlugin(const CommunicatorPtr& communicator,
const ThreadNotificationPtr&);
virtual void initialize();
virtual void destroy();
};
}
The ThreadHookPlugin constructor installs the given
ThreadNotification object into the specified communicator. The
initialize and
destroy methods are empty, but you can subclass
ThreadHookPlugin and override these methods if necessary.
•
Implement the ThreadNotification object that you will pass to the
ThreadHookPlugin constructor.
To install your plug‑in, use a configuration property like the one shown below:
The first component of the property value represents the plug‑in’s entry point. For C++, this value includes the abbreviated name of the shared library or DLL (
MyHooks) and the name of a factory function (
createPlugin).
If your property value is language-specific and the configuration file containing this property is shared by programs in multiple implementation languages, you can use an alternate syntax that is loaded only by the Ice run time for a certain language. For example, here is the C++-specific version:
Refer to Appendix D for more information on the
Ice.Plugin properties.
By default, operation invocations and AMI callbacks are executed by a thread from a thread pool. This behavior is simple and convenient for applications because they need not concern themselves with thread creation and destruction. However, there are situations where it is necessary to respond to operation invocations or AMI callbacks in a particular thread. For example, in a server, you might need to update a database that does not permit concurrent access from different threads or, in a client, you might need to update a user interface with the results of an invocation. (Many UI frameworks require all UI updates to be made by a specific thread.)
In Ice for C++, Java, and .NET, you can control which thread receives operation invocations and AMI callbacks, so you can ensure that all updates are made by a thread you choose. The implementation techniques vary slightly for each language and are explained in the sections that follow.
To install a dispatcher, you must instantiate a class that derives from Ice::Dispatcher and initialize a communicator with that instance in the
InitializationData structure. All invocations that arrive for this communicator are made via the specified dispatcher. For example:
class MyDispatcher : public Ice::Dispatcher /*, ... */
// ...
};
int
main(int argc, char* argv[])
{
Ice::CommunicatorPtr communicator;
try {
Ice::InitializationData initData;
initData.properties = Ice::createProperties(argc, argv);
initData.dispatcher = new MyDispatcher();
communicator = Ice::initialize(argc, argv, initData);
// ...
} catch (const Ice::Exception& ex) {
// ...
}
// ...
}
The Ice::Dispatcher abstract base class has the following interface:
class Dispatcher : virtual public IceUtil::Shared
{
public:
virtual void dispatch(const DispatcherCallPtr&,
const ConnectionPtr&) = 0;
};
typedef IceUtil::Handle<Dispatcher> DispatcherPtr;
The Ice run time invokes the dispatch method whenever an operation invocation arrives or an AMI invocation completes, passing an instance of
DispatcherCall and the connection via which the invocation arrived. The job of
dispatch is to pass the incoming invocation to an operation implementation. (The connection parameter allows you to decide how to dispatch the operation based on the connection via which it was received.)
You can write dispatch such that it blocks and waits for completion of the invocation because
dispatch is called by a thread in the server-side thread pool (for incoming operation invocations) or the client-side thread pool (for AMI callbacks).
The DispatcherCall instance encapsulates all the details of the incoming call. It is another abstract base class with the following interface:
class DispatcherCall : virtual public IceUtil::Shared
{
public:
virtual ~DispatcherCall() { }
virtual void run() = 0;
};
typedef IceUtil::Handle<DispatcherCall> DispatcherCallPtr;
Your implementation of dispatch is expected to call
run on the
DispatcherCall instance (or, more commonly, to cause
run to be called some time later). When you call
run, the Ice run time processes the invocation in the thread that calls
run.
A very simple way to implement dispatch would be as follows:
class MyDispatcher : public Ice::Dispatcher
public:
virtual void dispatch(const Ice::DispatcherCallPtr& d,
const Ice::ConnectionPtr)
{
d‑>run(); // Does not throw, blocks until op completes.
}
};
Whenever the Ice run time receives an incoming operation invocation or when an AMI invocation completes, it calls
dispatch which, in turn, calls
run on the
DispatcherCall instance.
With this simple example, dispatch immediately calls
run, and
run does not return until the corresponding operation invocation is complete. As a result, this implementation ties up a thread in the thread pool for the duration of the call.
So far, we really have not gained anything because all we have is a callback method that is called by the Ice run time. However, this simple mechanism is sufficient to ensure that we can update a UI from the correct thread.
A common technique to avoid blocking is to use asynchronous method invocation (see
Section 6.15). In response to a UI event (such as the user pressing a “Submit” button), the application initiates an operation invocation from the corresponding UI callback by calling the operation’s
begin_ method. This is guaranteed not to block the caller, so the UI remains responsive. Some time later, when the operation completes, the Ice run time invokes an AMI callback from one of the threads in its thread pool. That callback now has to update the UI, but that can only be done from the UI thread. By using a dispatcher, you can easily delegate the update to the correct thread. For example, here is how you can arrange for AMI callbacks to be passed to the UI thread with MFC:
class MyDialog : public CDialog { ... };
class MyDispatcher : public Ice::Dispatcher {
public:
MyDispatcher(MyDialog* dialog) : _dialog(dialog)
{
}
virtual void
dispatch(const Ice::DispatcherCallPtr& call,
const Ice::ConnectionPtr&)
{
_dialog‑>PostMessage(
WM_AMI_CALLBACK, 0,
reinterpret_cast<LPARAM>(
new Ice::DispatcherCallPtr(call)));
}
private:
MyDialog* _dialog;
};
The MyDispatcher class simply stores the
CDialog handle for the UI and calls
PostMessage, passing the
DispatcherCall instance. In turn, this causes the UI thread to receive an event and invoke the UI callback method that was registered to respond to
WM_AMI_CALLBACK events.
LRESULT
MyDialog::OnAMICallback(WPARAM, LPARAM lParam)
{
try {
Ice::DispatcherCallPtr* call =
reinterpret_cast<Ice::DispatcherCallPtr*>(lParam);
(*call)‑>run();
delete call;
} catch (const Ice::Exception& ex) {
// ...
}
return 0;
}
The Ice run time calls dispatch once the asynchronous operation invocation is complete. In turn, this causes the
OnAMICallback to trigger, which calls
run. Because the operation has completed already,
run does not block, so the UI remains responsive.
Please see the MFC demo in your Ice distribution for a fully-functional UI client that uses this technique.
To install a dispatcher, you must instantiate a class that implements Ice.Dispatcher and initialize a communicator with that instance in the
InitializationData structure. All invocations that arrive for this communicator are made via the specified dispatcher. For example:
public class MyDispatcher implements Ice.Dispatcher
{
// ...
}
public class Server
{
public static void
main(String[] args)
{
Ice.Communicator communicator;
try {
Ice.InitializationData initData =
new Ice.InitializationData();
initData.properties = Ice.Util.createProperties(args);
initData.dispatcher = new MyDispatcher();
communicator = Ice.Util.initialize(args, initData);
// ...
} catch (Ice.LocalException & ex) { {
// ...
}
// ...
}
// ...
}
The Ice.Dispatcher interface looks as follows:
public interface Dispatcher
{
void dispatch(Runnable runnable, Ice.Connection con);
}
The Ice run time invokes the dispatch method whenever an operation invocation arrives, passing a
Runnable and the connection via which the invocation arrived. The job of
dispatch is to pass the incoming invocation to an operation implementation. (The
con parameter allows you to decide how to dispatch the operation based on the connection via which it was received.)
You can write dispatch such that it blocks and waits for completion of the invocation because
dispatch is called by a thread in the server-side thread pool (for incoming operation invocations) or the client-side thread pool (for AMI callbacks).
Your implementation of dispatch is expected to call
run on the
Runnable instance (or, more commonly, to cause
run to be called some time later). When you call
run, the Ice run time processes the invocation in the thread that calls
run.
A very simple way to implement dispatch would be as follows:
public class MyDispatcher implements Ice.Dispatcher
{
public void
dispatch(Runnable runnable, Ice.Connection connection)
{
// Does not throw, blocks until op completes.
runnable.run();
}
}
Whenever the Ice run time receives an incoming operation invocation or when an AMI invocation completes, it calls
dispatch which, in turn, calls
run on the
Runnable instance.
With this simple example, dispatch immediately calls
run, and
run does not return until the corresponding operation invocation is complete. As a result, this implementation ties up a thread in the thread pool for the duration of the call.
So far, we really have not gained anything because all we have is a callback method that is called by the Ice run time. However, this simple mechanism is sufficient to ensure that we can update a UI from the correct thread.
A common technique to avoid blocking is to use asynchronous method invocation (see
Section 10.17). In response to a UI event (such as the user pressing a “Submit” button), the application initiates an operation invocation from the corresponding UI callback by calling the operation’s
begin_ method. This is guaranteed not to block the caller, so the UI remains responsive. Some time later, when the operation completes, the Ice run time invokes an AMI
response callback from one of the threads in its thread pool. That callback now has to update the UI, but that can only be done from the UI thread. By using a dispatcher, you can easily delegate the update to the correct thread. For example, here is how you can arrange for AMI callbacks to be passed to the UI thread with Swing:
public class Client extends JFrame
{
public static void main(final String[] args)
{
SwingUtilities.invokeLater(new Runnable()
{
public void run()
{
try {
new Client(args);
} catch (Ice.LocalException e) {
JOptionPane.showMessageDialog(
null, e.toString(),
"Initialization failed",
JOptionPane.ERROR_MESSAGE);
}
}
});
}
Client(String[] args)
{
Ice.Communicator communicator;
try {
Ice.InitializationData initData =
new Ice.InitializationData();
initData.dispatcher = new Ice.Dispatcher()
{
public void
dispatch(Runnable runnable,
Ice.Connection connection)
{
SwingUtilities.invokeLater(runnable);
}
};
communicator = Ice.Util.initialize(args, initData);
}
catch(Throwable ex)
{
// ...
}
// ...
}
// ...
}
The dispatch method simply delays the call to
run by calling
invokeLater, passing it the
Runnable that is provided by the Ice run time. This causes the Swing UI thread to eventually make the call to
run. Because the Ice run time does not call
dispatch until the asynchronous invocation is complete, that call to
run does not block and the UI remains responsive.
Please see the swing demo in your Ice distribution for a fully-functional UI client that uses this technique.
To install a dispatcher, you must initialize a communicator with a delegate of type Ice.Dispatcher in the
InitializationData structure. All invocations that arrive for this communicator are made via the specified dispatcher. For example:
public class Server
{
public static void Main(string[] args)
{
Ice.Communicator communicator = null;
try {
Ice.InitializationData initData =
new Ice.InitializationData();
initData.dispatcher = new MyDispatcher().dispatch;
communicator =
Ice.Util.initialize(ref args, initData);
// ...
} catch (System.Exception ex) {
// ...
}
// ...
}
// ...
}
The Ice.Dispatcher delegate is defined as follows:
public delegate void Dispatcher(System.Action call,
Connection con);
The Ice run time calls your delegate whenever an operation invocation arrives, passing a
System.Action delegate and the connection via which the invocation arrived. The job of your delegate is to pass the incoming invocation to an operation implementation. (The
con parameter allows you to decide how to dispatch the operation based on the connection via which it was received.)
In this example, the delegate calls a method dispatch on an instance of a
MyDispatcher class. You can write
dispatch such that it blocks and waits for completion of the invocation because
dispatch is called by a thread in the server-side thread pool (for incoming operation invocations) or the client-side thread pool (for AMI callbacks).
Your implementation of dispatch is expected to invoke the
call delegate (or, more commonly, to cause it to be invoked some time later). When you invoke the
call delegate, the Ice run time processes the invocation in the thread that invokes the delegate.
A very simple way to implement dispatch would be as follows:
public class MyDispatcher
{
public void
dispatch(System.Action call, Ice.Connection con)
{
// Does not throw, blocks until op completes.
call();
}
};
Whenever the Ice run time receives an incoming operation invocation or when an AMI invocation completes, it calls
dispatch which, in turn, invokes the
call delegate.
With this simple example, dispatch immediately invokes the delegate, and that call does not return until the corresponding operation invocation is complete. As a result, this implementation ties up a thread in the thread pool for the duration of the call.
So far, we really have not gained anything because all we have is a callback method that is called by the Ice run time. However, this simple mechanism is sufficient to ensure that we can update a UI from the correct thread.
A common technique to avoid blocking is to use asynchronous method invocation (see
Section 14.16). In response to a UI event (such as the user pressing a “Submit” button), the application initiates an operation invocation from the corresponding UI callback by calling the operation’s
begin_ method. This is guaranteed not to block the caller, so the UI remains responsive. Some time later, when the operation completes, the Ice run time invokes an AMI callback from one of the threads in its thread pool. That callback now has to update the UI, but that can only be done from the UI thread. By using a dispatcher, you can easily delegate the update to the correct thread. For example, here is how you can arrange for AMI callbacks to be passed to the UI thread with WPF:
public partial class MyWindow : Window
{
private void Window_Loaded(object sender, EventArgs e)
{
Ice.Communicator communicator = null;
try
{
Ice.InitializationData initData =
new Ice.InitializationData();
initData.dispatcher =
delegate(System.Action action,
Ice.Connection connection)
{
Dispatcher.BeginInvoke(
DispatcherPriority.Normal, action);
};
communicator = Ice.Util.initialize(initData);
}
catch(Ice.LocalException ex)
{
// ...
}
}
// ...
}
The delegate calls Dispatcher.BeginInvoke on the
action delegate. This causes WPF to queue the actual asynchronous invocation of
action for later execution by the UI thread. Because the Ice run time does not invoke your delegate until an asynchronous operation invocation is complete, when the UI thread executes the corresponding call to the
EndInvoke method, that call does not block and the UI remains responsive.
public partical class MyWindow : Window
{
private void someOp_Click(object sender, RoutedEventArgs e)
{
MyIntfPrx p = ...;
// Call remote operation asynchronously.
// Response is processed in UI thread.
p.begin_someOp().whenCompleted(this.opResponse,
this.opException);
}
public void opResponse()
{
// Update UI...
}
public void opException(Ice.Exception ex)
{
// Update UI...
}
}
Please see the wpf demo in your Ice distribution for a fully-functional UI client that uses this technique.
A call to Communicator::destroy will hang indefinitely if there are pending requests that have not yet been dispatched, therefore it is very important for a dispatcher implementation to ensure that all requests are dispatched.


