
")

If it is acceptable for your application to have the database as a single point of failure, you can deploy a broker cluster using the JDBC master/slave failover pattern. Conceptually, this approach is somewhat similar to the shared file system master/slave pattern, as it is also based on lock acquisition. Brokers automatically configure themselves to operate in master mode or slave mode, depending on whether or not they manage to grab a mutex lock on an underlying database table. There is no replication of data in this scenario (unless this is provided by the database).
It is also necessary to access the database without enabling high speed journaling. This inevitably has a significant impact on performance and has to be kept in mind when comparing with other failover approaches.
In the JDBC master/slave pattern, there is nothing special to distinguish a master broker from the slave brokers. Membership of a particular failover cluster is defined by the fact that all of the brokers in the cluster use the same JDBC persistence layer (without journaling) and store their data in the same database tables. The brokers in the cluster therefore compete to grab the mutex lock on the database table. The first broker to grab the lock is the master and all of the other brokers in the cluster are the slaves (there can be any number of brokers in a failover cluster). The master and the slaves now behave as follows:
The master retains the lock on the database table, preventing the other brokers from accessing the data. The master starts up its transport connectors and network connectors, enabling other messaging clients and message brokers to connect to it.
The slaves keep attempting to grab the lock on the database table, but they do not succeed as long as the master is running. The slaves do not start up any transport connectors or network connectors and are thus inaccessible to messaging clients and brokers.
The only condition that brokers in a cluster must satisfy is that they all use the same non-journaling JDBC persistence layer with the broker data stored in the same underlying database tables.
For example, to store the shared broker data in an Oracle database, you could configure the non-journaled JDBC persistence layer, for all brokers in the cluster, as follows:
Example 4.7. JDBC master/slave broker configuration
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:amq="http://activemq.apache.org/schema/core"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.0.xsd
http://activemq.apache.org/schema/core
http://activemq.apache.org/schema/core/activemq-core-5.3.1.xsd">
<broker xmlns="http://activemq.apache.org/schema/core"
brokerName="brokerA">
...
<persistenceAdapter>
<jdbcPersistenceAdapter dataSource="#oracle-ds"/>
</persistenceAdapter>
...
</broker>
<bean id="oracle-ds"
class="org.apache.commons.dbcp.BasicDataSource"
destroy-method="close">
<property name="driverClassName" value="oracle.jdbc.driver.OracleDriver"/>
<property name="url" value="jdbc:oracle:thin:@localhost:1521:AMQDB"/>
<property name="username" value="scott"/>
<property name="password" value="tiger"/>
<property name="poolPreparedStatements" value="true"/>
</bean>
</beans>The persistence adapter is configured as a direct JDBC persistence layer,
using the jdbcPersistenceAdapter element. You must
not use the journaled persistence adapter (configurable
using the journalPersistenceAdapter element) in this
scenario.
Clients of the failover cluster must be configured with a failover URL that
lists the URLs for all of the brokers in the cluster. For example, assuming that
there are three brokers in the cluster, deployed on the hosts,
broker1, broker2, and broker3, and
all listening on IP port 61616, you could use the following
failover URL for the clients:
failover:(tcp://broker1:61616,tcp://broker2:61616,tcp://broker3:61616)
In this case, it does not matter in which order the clients attempt to connect to the brokers, because the identity of the master broker is determined by chance: that is, by whichever broker is the first to grab the mutex lock on the relevant database table.
Figure 4.6 shows the initial state of a JDBC master/slave cluster. When all of the brokers in the cluster are started, one of them grabs the mutex lock on the database table, thus becoming the master. All of the other brokers in the clusters remain slaves and pause while waiting for the lock to be freed up. Only the master starts its transport connectors, so all of the clients connect to it.
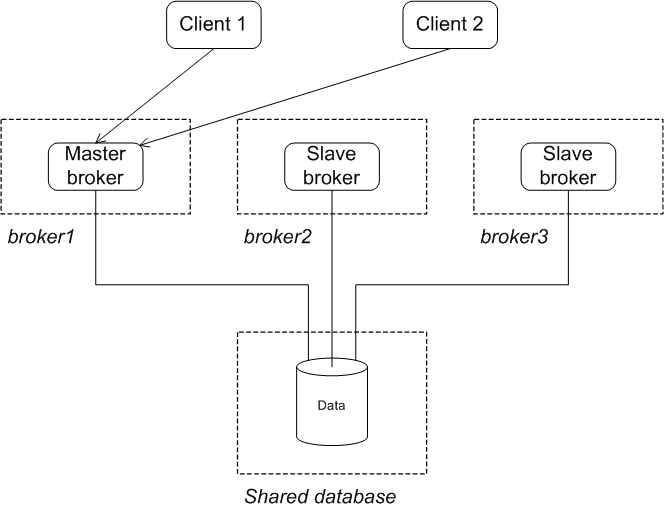
Figure 4.7 shows the state of the
cluster after the original master has shut down or failed. As soon as the master
gives up the lock (or after a suitable timeout, if the master crashes), the lock
on the database table frees up and another broker in the cluster grabs the lock
and gets promoted to master (broker2 in the figure).
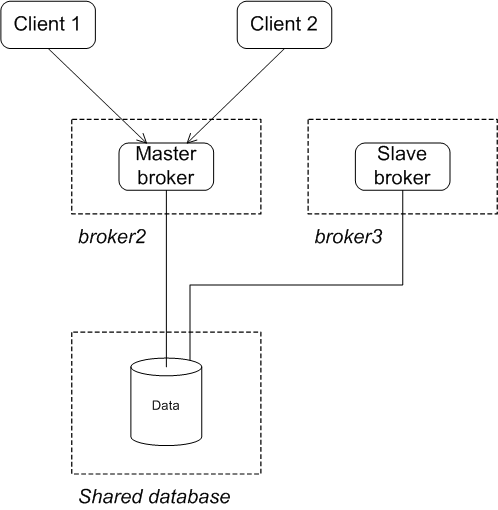
After the clients lose their connection to the original master, they automatically try all of the other brokers listed in the failover URL. This enables them to find and connect to the new master.
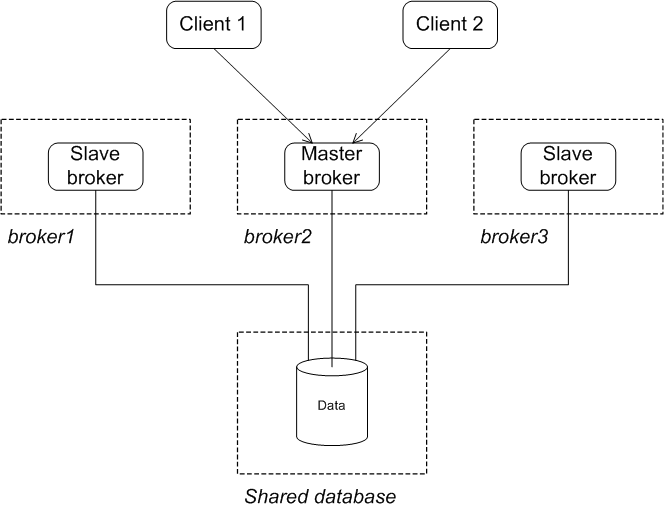
You can restart the failed master at any time and it will rejoin the cluster. Initially, however, it will have the status of a slave broker, because one of the other brokers already owns the mutex lock on the database table, as shown in Figure 4.8.
 |  |  |
 |
