|
| |||
|
MetaBoss Testing Framework Guide.Regression Testing.OverviewA regression test is used to answer questions like "Has system behaviour changed since a certain time in the past?" and if it has then "What are these changes ?". Due to the very nature of the regression testing (i.e. because it measures regression) it can not exist without a system test facility. In fact regression testing can be thought of as "comparing results of two system test runs". This is why the preparation and running of the regression tests is built on top of all the steps necessary to execute a standard system test. We only need to set up one additional parameter - the reference to the specimen log file containing the results of prior test run.
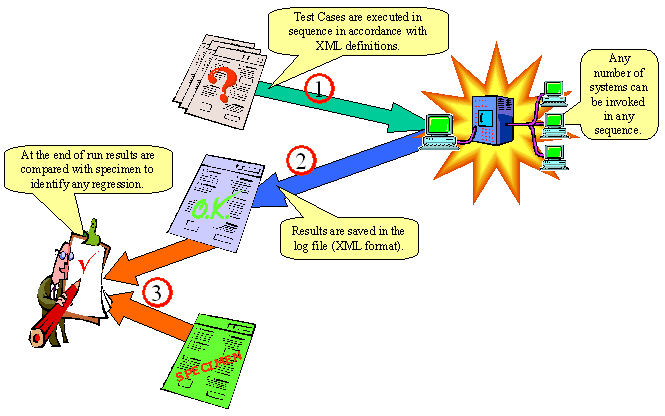
As it is shown on the picture above, the execution of a regression test run always consists of three parts:
Please note that it is imperative that the regression testing run starts from known data base state. Whereas it is theoretically possible (albeit it requires more work) to prepare a set of system tests which can run irrespective of the database state, with regression testing this is not possible. This is because the regression test compares 100% of data contained in the specimen file with the data contained in the test scenario log, so even small and innocent diferences in the data will lead to regression test failure. The suggested approach here is to clean up and reinitialise the database prior to every test run and then have a "Populate Data" test case, which can be run as a first test case. The advantage of this approach is that the data population services themselves are also tested every time. Specimen file descriptionAs was mentioned above, the specimen file is a file which contains the historical log record of the trusted test run. The trusted test run is simply some successful previous run of the same system test scenario. In order not to cause many failure alarms when comparing volatile elements, the regression test comparison has the following features:
Based on these features of the comparison process, to convert the log file from trusted test run into a specimen file one has to do the following:
The reliability and quality of the regression test very much depends on the quality of the specimen file and we suggest that the specimen file candidate be reviewed by testers, developers and designers prior to promoting the candidate specimen file to the final specimen. Questions which should be answered by this review are:
|
|
|
Copyright © 2000-2005 Softaris Pty.Ltd. All Rights Reserved.
MetaBoss is the registered trademark of Softaris Pty.Ltd. Java, Enterprise JavaBeans, JDBC, JNDI, JTA, JTS, JCA and other Java related APIs are trademarks or registered trademarks of Sun Microsystems, Inc. MDA, UML, MOF, CORBA and IIOP are trademarks or registered trademarks of the Object Management Group. Microsoft, .NET and C# are trademarks or registered trademarks of the Microsoft Corporation. All other product names mentioned herein are trademarks of their respective owners. |