Contents
- Day 9, 09:00 to 11:00, 11:15 to 12:30
- Review Associate Introduction to Object Storage
- Review Associate Features and Benefits
- Review Associate Administration Tasks
- Object Storage Capabilities
- Object Storage Building Blocks
- Swift Ring Builder
- More Swift Concepts
- Swift Cluster Architecture
- Swift Account Reaper
- Swift Replication
OpenStack Object Storage (code-named Swift) is open source software for creating redundant, scalable data storage using clusters of standardized servers to store petabytes of accessible data. It is a long-term storage system for large amounts of static data that can be retrieved, leveraged, and updated. Object Storage uses a distributed architecture with no central point of control, providing greater scalability, redundancy and permanence. Objects are written to multiple hardware devices, with the OpenStack software responsible for ensuring data replication and integrity across the cluster. Storage clusters scale horizontally by adding new nodes. Should a node fail, OpenStack works to replicate its content from other active nodes. Because OpenStack uses software logic to ensure data replication and distribution across different devices, inexpensive commodity hard drives and servers can be used in lieu of more expensive equipment.
Object Storage is ideal for cost effective, scale-out storage. It provides a fully distributed, API-accessible storage platform that can be integrated directly into applications or used for backup, archiving and data retention. Block Storage allows block devices to be exposed and connected to compute instances for expanded storage, better performance and integration with enterprise storage platforms, such as NetApp, Nexenta and SolidFire.
| Features | Benefits |
|---|---|
| Leverages commodity hardware | No lock-in, lower price/GB |
| HDD/node failure agnostic | Self healingReliability, data redundancy protecting from failures |
| Unlimited storage | Huge & flat namespace, highly scalable read/write accessAbility to serve content directly from storage system |
| Multi-dimensional scalability (scale out architecture)Scale vertically and horizontally-distributed storage | Backup and archive large amounts of data with linear performance |
| Account/Container/Object structureNo nesting, not a traditional file system | Optimized for scaleScales to multiple petabytes, billions of objects |
| Built-in replication3x+ data redundancy compared to 2x on RAID | Configurable number of accounts, container and object copies for high availability |
| Easily add capacity unlike RAID resize | Elastic data scaling with ease |
| No central database | Higher performance, no bottlenecks |
| RAID not required | Handle lots of small, random reads and writes efficiently |
| Built-in management utilities | Account Management: Create, add, verify, delete usersContainer Management: Upload, download, verifyMonitoring: Capacity, host, network, log trawling, cluster health |
| Drive auditing | Detect drive failures preempting data corruption |
| Expiring objects | Users can set an expiration time or a TTL on an object to control access |
| Direct object access | Enable direct browser access to content, such as for a control panel |
| Realtime visibility into client requests | Know what users are requesting |
| Supports S3 API | Utilize tools that were designed for the popular S3 API |
| Restrict containers per account | Limit access to control usage by user |
| Support for NetApp, Nexenta, SolidFire | Unified support for block volumes using a variety of storage systems |
| Snapshot and backup API for block volumes | Data protection and recovery for VM data |
| Standalone volume API available | Separate endpoint and API for integration with other compute systems |
| Integration with Compute | Fully integrated to Compute for attaching block volumes and reporting on usage |
OpenStack provides redundant, scalable object storage using clusters of standardized servers capable of storing petabytes of data
Object Storage is not a traditional file system, but rather a distributed storage system for static data such as virtual machine images, photo storage, email storage, backups and archives. Having no central "brain" or master point of control provides greater scalability, redundancy and durability.
Objects and files are written to multiple disk drives spread throughout servers in the data center, with the OpenStack software responsible for ensuring data replication and integrity across the cluster.
Storage clusters scale horizontally simply by adding new servers. Should a server or hard drive fail, OpenStack replicates its content from other active nodes to new locations in the cluster. Because OpenStack uses software logic to ensure data replication and distribution across different devices, inexpensive commodity hard drives and servers can be used in lieu of more expensive equipment.
Swift Characteristics
The key characteristics of Swift include:
All objects stored in Swift have a URL
All objects stored are replicated 3x in as-unique-as-possible zones, which can be defined as a group of drives, a node, a rack etc.
All objects have their own metadata
Developers interact with the object storage system through a RESTful HTTP API
Object data can be located anywhere in the cluster
The cluster scales by adding additional nodes -- without sacrificing performance, which allows a more cost-effective linear storage expansion vs. fork-lift upgrades
Data doesn’t have to be migrated to an entirely new storage system
New nodes can be added to the cluster without downtime
Failed nodes and disks can be swapped out with no downtime
Runs on industry-standard hardware, such as Dell, HP, Supermicro etc.

Developers can either write directly to the Swift API or use one of the many client libraries that exist for all popular programming languages, such as Java, Python, Ruby and C#. Amazon S3 and RackSpace Cloud Files users should feel very familiar with Swift. For users who have not used an object storage system before, it will require a different approach and mindset than using a traditional filesystem.
The components that enable Swift to deliver high availability, high durability and high concurrency are:
Proxy Servers:Handles all incoming API requests.
Rings:Maps logical names of data to locations on particular disks.
Zones:Each Zone isolates data from other Zones. A failure in one Zone doesn’t impact the rest of the cluster because data is replicated across the Zones.
Accounts & Containers:Each Account and Container are individual databases that are distributed across the cluster. An Account database contains the list of Containers in that Account. A Container database contains the list of Objects in that Container
Objects:The data itself.
Partitions:A Partition stores Objects, Account databases and Container databases. It’s an intermediate 'bucket' that helps manage locations where data lives in the cluster.

Proxy Servers
The Proxy Servers are the public face of Swift and
handle all incoming API requests. Once a Proxy Server
receive a request, it will determine the storage node
based on the URL of the object, such as
https://swift.example.com/v1/account/container/object
. The Proxy Servers also coordinates responses,
handles failures and coordinates timestamps.
Proxy servers use a shared-nothing architecture and can be scaled as needed based on projected workloads. A minimum of two Proxy Servers should be deployed for redundancy. Should one proxy server fail, the others will take over.
The Ring
A ring represents a mapping between the names of entities stored on disk and their physical location. There are separate rings for accounts, containers, and objects. When other components need to perform any operation on an object, container, or account, they need to interact with the appropriate ring to determine its location in the cluster.
The Ring maintains this mapping using zones, devices, partitions, and replicas. Each partition in the ring is replicated, by default, 3 times across the cluster, and the locations for a partition are stored in the mapping maintained by the ring. The ring is also responsible for determining which devices are used for hand off in failure scenarios.
Data can be isolated with the concept of zones in the ring. Each replica of a partition is guaranteed to reside in a different zone. A zone could represent a drive, a server, a cabinet, a switch, or even a data center.
The partitions of the ring are equally divided among all the devices in the OpenStack Object Storage installation. When partitions need to be moved around, such as when a device is added to the cluster, the ring ensures that a minimum number of partitions are moved at a time, and only one replica of a partition is moved at a time.
Weights can be used to balance the distribution of partitions on drives across the cluster. This can be useful, for example, when different sized drives are used in a cluster.
The ring is used by the Proxy server and several background processes (like replication).
The Ring maps Partitions to physical locations on disk. When other components need to perform any operation on an object, container, or account, they need to interact with the Ring to determine its location in the cluster.
The Ring maintains this mapping using zones, devices, partitions, and replicas. Each partition in the Ring is replicated three times by default across the cluster, and the locations for a partition are stored in the mapping maintained by the Ring. The Ring is also responsible for determining which devices are used for handoff should a failure occur.

The Ring maps partitions to physical locations on disk.
The rings determine where data should reside in the cluster. There is a separate ring for account databases, container databases, and individual objects but each ring works in the same way. These rings are externally managed, in that the server processes themselves do not modify the rings, they are instead given new rings modified by other tools.
The ring uses a configurable number of bits from a path’s MD5 hash as a partition index that designates a device. The number of bits kept from the hash is known as the partition power, and 2 to the partition power indicates the partition count. Partitioning the full MD5 hash ring allows other parts of the cluster to work in batches of items at once which ends up either more efficient or at least less complex than working with each item separately or the entire cluster all at once.
Another configurable value is the replica count, which indicates how many of the partition->device assignments comprise a single ring. For a given partition number, each replica’s device will not be in the same zone as any other replica's device. Zones can be used to group devices based on physical locations, power separations, network separations, or any other attribute that would lessen multiple replicas being unavailable at the same time.
Zones: Failure Boundaries
Swift allows zones to be configured to isolate failure boundaries. Each replica of the data resides in a separate zone, if possible. At the smallest level, a zone could be a single drive or a grouping of a few drives. If there were five object storage servers, then each server would represent its own zone. Larger deployments would have an entire rack (or multiple racks) of object servers, each representing a zone. The goal of zones is to allow the cluster to tolerate significant outages of storage servers without losing all replicas of the data.
As we learned earlier, everything in Swift is stored, by default, three times. Swift will place each replica "as-uniquely-as-possible" to ensure both high availability and high durability. This means that when choosing a replica location, Swift will choose a server in an unused zone before an unused server in a zone that already has a replica of the data.
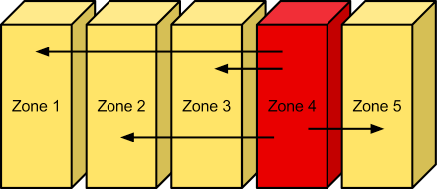
When a disk fails, replica data is automatically distributed to the other zones to ensure there are three copies of the data
Accounts & Containers
Each account and container is an individual SQLite database that is distributed across the cluster. An account database contains the list of containers in that account. A container database contains the list of objects in that container.

To keep track of object data location, each account in the system has a database that references all its containers, and each container database references each object
Partitions
A Partition is a collection of stored data, including Account databases, Container databases, and objects. Partitions are core to the replication system.
Think of a Partition as a bin moving throughout a fulfillment center warehouse. Individual orders get thrown into the bin. The system treats that bin as a cohesive entity as it moves throughout the system. A bin full of things is easier to deal with than lots of little things. It makes for fewer moving parts throughout the system.
The system replicators and object uploads/downloads operate on Partitions. As the system scales up, behavior continues to be predictable as the number of Partitions is a fixed number.
The implementation of a Partition is conceptually simple -- a partition is just a directory sitting on a disk with a corresponding hash table of what it contains.

*Swift partitions contain all data in the system.
Replication
In order to ensure that there are three copies of the data everywhere, replicators continuously examine each Partition. For each local Partition, the replicator compares it against the replicated copies in the other Zones to see if there are any differences.
How does the replicator know if replication needs to take place? It does this by examining hashes. A hash file is created for each Partition, which contains hashes of each directory in the Partition. Each of the three hash files is compared. For a given Partition, the hash files for each of the Partition's copies are compared. If the hashes are different, then it is time to replicate and the directory that needs to be replicated is copied over.
This is where the Partitions come in handy. With fewer "things" in the system, larger chunks of data are transferred around (rather than lots of little TCP connections, which is inefficient) and there are a consistent number of hashes to compare.
The cluster has eventually consistent behavior where the newest data wins.

*If a zone goes down, one of the nodes containing a replica notices and proactively copies data to a handoff location.
To describe how these pieces all come together, let's walk through a few scenarios and introduce the components.
Bird-eye View
Upload
A client uses the REST API to make a HTTP request to PUT an object into an existing Container. The cluster receives the request. First, the system must figure out where the data is going to go. To do this, the Account name, Container name and Object name are all used to determine the Partition where this object should live.
Then a lookup in the Ring figures out which storage nodes contain the Partitions in question.
The data then is sent to each storage node where it is placed in the appropriate Partition. A quorum is required -- at least two of the three writes must be successful before the client is notified that the upload was successful.
Next, the Container database is updated asynchronously to reflect that there is a new object in it.

Download
A request comes in for an Account/Container/object. Using the same consistent hashing, the Partition name is generated. A lookup in the Ring reveals which storage nodes contain that Partition. A request is made to one of the storage nodes to fetch the object and if that fails, requests are made to the other nodes.
The rings are built and managed manually by a utility called the ring-builder. The ring-builder assigns partitions to devices and writes an optimized Python structure to a gzipped, serialized file on disk for shipping out to the servers. The server processes just check the modification time of the file occasionally and reload their in-memory copies of the ring structure as needed. Because of how the ring-builder manages changes to the ring, using a slightly older ring usually just means one of the three replicas for a subset of the partitions will be incorrect, which can be easily worked around.
The ring-builder also keeps its own builder file with the ring information and additional data required to build future rings. It is very important to keep multiple backup copies of these builder files. One option is to copy the builder files out to every server while copying the ring files themselves. Another is to upload the builder files into the cluster itself. Complete loss of a builder file will mean creating a new ring from scratch, nearly all partitions will end up assigned to different devices, and therefore nearly all data stored will have to be replicated to new locations. So, recovery from a builder file loss is possible, but data will definitely be unreachable for an extended time.
Ring Data Structure
The ring data structure consists of three top level fields: a list of devices in the cluster, a list of lists of device ids indicating partition to device assignments, and an integer indicating the number of bits to shift an MD5 hash to calculate the partition for the hash.
Partition Assignment List
This is a list of array(‘H’) of devices ids. The outermost list contains an array(‘H’) for each replica. Each array(‘H’) has a length equal to the partition count for the ring. Each integer in the array(‘H’) is an index into the above list of devices. The partition list is known internally to the Ring class as _replica2part2dev_id.
So, to create a list of device dictionaries assigned to a partition, the Python code would look like: devices = [self.devs[part2dev_id[partition]] for part2dev_id in self._replica2part2dev_id]
That code is a little simplistic, as it does not account for the removal of duplicate devices. If a ring has more replicas than devices, then a partition will have more than one replica on one device; that’s simply the pigeonhole principle at work.
array(‘H’) is used for memory conservation as there may be millions of partitions.
Fractional Replicas
A ring is not restricted to having an integer number of replicas. In order to support the gradual changing of replica counts, the ring is able to have a real number of replicas.
When the number of replicas is not an integer, then the last element of _replica2part2dev_id will have a length that is less than the partition count for the ring. This means that some partitions will have more replicas than others. For example, if a ring has 3.25 replicas, then 25% of its partitions will have four replicas, while the remaining 75% will have just three.
Partition Shift Value
The partition shift value is known internally to the Ring class as _part_shift. This value used to shift an MD5 hash to calculate the partition on which the data for that hash should reside. Only the top four bytes of the hash is used in this process. For example, to compute the partition for the path /account/container/object the Python code might look like: partition = unpack_from('>I', md5('/account/container/object').digest())[0] >> self._part_shift
For a ring generated with part_power P, the partition shift value is 32 - P.
Building the Ring
The initial building of the ring first calculates the number of partitions that should ideally be assigned to each device based the device’s weight. For example, given a partition power of 20, the ring will have 1,048,576 partitions. If there are 1,000 devices of equal weight they will each desire 1,048.576 partitions. The devices are then sorted by the number of partitions they desire and kept in order throughout the initialization process.
Note: each device is also assigned a random tiebreaker value that is used when two devices desire the same number of partitions. This tiebreaker is not stored on disk anywhere, and so two different rings created with the same parameters will have different partition assignments. For repeatable partition assignments, RingBuilder.rebalance() takes an optional seed value that will be used to seed Python’s pseudo-random number generator.
Then, the ring builder assigns each replica of each partition to the device that desires the most partitions at that point while keeping it as far away as possible from other replicas. The ring builder prefers to assign a replica to a device in a regions that has no replicas already; should there be no such region available, the ring builder will try to find a device in a different zone; if not possible, it will look on a different server; failing that, it will just look for a device that has no replicas; finally, if all other options are exhausted, the ring builder will assign the replica to the device that has the fewest replicas already assigned. Note that assignment of multiple replicas to one device will only happen if the ring has fewer devices than it has replicas.
When building a new ring based on an old ring, the desired number of partitions each device wants is recalculated. Next the partitions to be reassigned are gathered up. Any removed devices have all their assigned partitions unassigned and added to the gathered list. Any partition replicas that (due to the addition of new devices) can be spread out for better durability are unassigned and added to the gathered list. Any devices that have more partitions than they now desire have random partitions unassigned from them and added to the gathered list. Lastly, the gathered partitions are then reassigned to devices using a similar method as in the initial assignment described above.
Whenever a partition has a replica reassigned, the time of the reassignment is recorded. This is taken into account when gathering partitions to reassign so that no partition is moved twice in a configurable amount of time. This configurable amount of time is known internally to the RingBuilder class as min_part_hours. This restriction is ignored for replicas of partitions on devices that have been removed, as removing a device only happens on device failure and there’s no choice but to make a reassignment.
The above processes don’t always perfectly rebalance a ring due to the random nature of gathering partitions for reassignment. To help reach a more balanced ring, the rebalance process is repeated until near perfect (less 1% off) or when the balance doesn’t improve by at least 1% (indicating we probably can’t get perfect balance due to wildly imbalanced zones or too many partitions recently moved).
Containers and Objects
A container is a storage compartment for your data and provides a way for you to organize your data. You can think of a container as a folder in Windows or a directory in UNIX. The primary difference between a container and these other file system concepts is that containers cannot be nested. You can, however, create an unlimited number of containers within your account. Data must be stored in a container so you must have at least one container defined in your account prior to uploading data.
The only restrictions on container names is that they cannot contain a forward slash (/) or an ascii null (%00) and must be less than 257 bytes in length. Please note that the length restriction applies to the name after it has been URL encoded. For example, a container name of Course Docs would be URL encoded as Course%20Docs and therefore be 13 bytes in length rather than the expected 11.
An object is the basic storage entity and any optional metadata that represents the files you store in the OpenStack Object Storage system. When you upload data to OpenStack Object Storage, the data is stored as-is (no compression or encryption) and consists of a location (container), the object's name, and any metadata consisting of key/value pairs. For instance, you may chose to store a backup of your digital photos and organize them into albums. In this case, each object could be tagged with metadata such as Album : Caribbean Cruise or Album : Aspen Ski Trip.
The only restriction on object names is that they must be less than 1024 bytes in length after URL encoding. For example, an object name of C++final(v2).txt should be URL encoded as C%2B%2Bfinal%28v2%29.txt and therefore be 24 bytes in length rather than the expected 16.
The maximum allowable size for a storage object upon upload is 5 GB and the minimum is zero bytes. You can use the built-in large object support and the swift utility to retrieve objects larger than 5 GB.
For metadata, you should not exceed 90 individual key/value pairs for any one object and the total byte length of all key/value pairs should not exceed 4 KB (4096 bytes).
Language-Specific API Bindings
A set of supported API bindings in several popular languages are available from the Rackspace Cloud Files product, which uses OpenStack Object Storage code for its implementation. These bindings provide a layer of abstraction on top of the base REST API, allowing programmers to work with a container and object model instead of working directly with HTTP requests and responses. These bindings are free (as in beer and as in speech) to download, use, and modify. They are all licensed under the MIT License as described in the COPYING file packaged with each binding. If you do make any improvements to an API, you are encouraged (but not required) to submit those changes back to us.
The API bindings for Rackspace Cloud Files are hosted athttp://github.com/rackspacehttp://github.com/rackspace. Feel free to coordinate your changes through github or, if you prefer, send your changes to [email protected]. Just make sure to indicate which language and version you modified and send a unified diff.
Each binding includes its own documentation (either HTML, PDF, or CHM). They also include code snippets and examples to help you get started. The currently supported API binding for OpenStack Object Storage are:
PHP (requires 5.x and the modules: cURL, FileInfo, mbstring)
Python (requires 2.4 or newer)
Java (requires JRE v1.5 or newer)
C#/.NET (requires .NET Framework v3.5)
Ruby (requires 1.8 or newer and mime-tools module)
There are no other supported language-specific bindings at this time. You are welcome to create your own language API bindings and we can help answer any questions during development, host your code if you like, and give you full credit for your work.
Proxy Server
The Proxy Server is responsible for tying together the rest of the OpenStack Object Storage architecture. For each request, it will look up the location of the account, container, or object in the ring (see below) and route the request accordingly. The public API is also exposed through the Proxy Server.
A large number of failures are also handled in the Proxy Server. For example, if a server is unavailable for an object PUT, it will ask the ring for a hand-off server and route there instead.
When objects are streamed to or from an object server, they are streamed directly through the proxy server to or from the user – the proxy server does not spool them.
You can use a proxy server with account management enabled by configuring it in the proxy server configuration file.
Object Server
The Object Server is a very simple blob storage server that can store, retrieve and delete objects stored on local devices. Objects are stored as binary files on the filesystem with metadata stored in the file’s extended attributes (xattrs). This requires that the underlying filesystem choice for object servers support xattrs on files. Some filesystems, like ext3, have xattrs turned off by default.
Each object is stored using a path derived from the object name’s hash and the operation’s timestamp. Last write always wins, and ensures that the latest object version will be served. A deletion is also treated as a version of the file (a 0 byte file ending with “.ts”, which stands for tombstone). This ensures that deleted files are replicated correctly and older versions don’t magically reappear due to failure scenarios.
Container Server
The Container Server’s primary job is to handle listings of objects. It does not know where those objects are, just what objects are in a specific container. The listings are stored as SQLite database files, and replicated across the cluster similar to how objects are. Statistics are also tracked that include the total number of objects, and total storage usage for that container.
Account Server
The Account Server is very similar to the Container Server, excepting that it is responsible for listings of containers rather than objects.
Replication
Replication is designed to keep the system in a consistent state in the face of temporary error conditions like network outages or drive failures.
The replication processes compare local data with each remote copy to ensure they all contain the latest version. Object replication uses a hash list to quickly compare subsections of each partition, and container and account replication use a combination of hashes and shared high water marks.
Replication updates are push based. For object replication, updating is just a matter of rsyncing files to the peer. Account and container replication push missing records over HTTP or rsync whole database files.
The replicator also ensures that data is removed from the system. When an item (object, container, or account) is deleted, a tombstone is set as the latest version of the item. The replicator will see the tombstone and ensure that the item is removed from the entire system.
To separate the cluster-internal replication traffic from client traffic, separate replication servers can be used. These replication servers are based on the standard storage servers, but they listen on the replication IP and only respond to REPLICATE requests. Storage servers can serve REPLICATE requests, so an operator can transition to using a separate replication network with no cluster downtime.
Replication IP and port information is stored in the ring on a per-node basis. These parameters will be used if they are present, but they are not required. If this information does not exist or is empty for a particular node, the node's standard IP and port will be used for replication.
Updaters
There are times when container or account data can not be immediately updated. This usually occurs during failure scenarios or periods of high load. If an update fails, the update is queued locally on the file system, and the updater will process the failed updates. This is where an eventual consistency window will most likely come in to play. For example, suppose a container server is under load and a new object is put in to the system. The object will be immediately available for reads as soon as the proxy server responds to the client with success. However, the container server did not update the object listing, and so the update would be queued for a later update. Container listings, therefore, may not immediately contain the object.
In practice, the consistency window is only as large as the frequency at which the updater runs and may not even be noticed as the proxy server will route listing requests to the first container server which responds. The server under load may not be the one that serves subsequent listing requests – one of the other two replicas may handle the listing.
Auditors
Auditors crawl the local server checking the integrity of the objects, containers, and accounts. If corruption is found (in the case of bit rot, for example), the file is quarantined, and replication will replace the bad file from another replica. If other errors are found they are logged. For example, an object’s listing cannot be found on any container server it should be.
Access Tier

Large-scale deployments segment off an "Access Tier". This tier is the “Grand Central” of the Object Storage system. It fields incoming API requests from clients and moves data in and out of the system. This tier is composed of front-end load balancers, ssl- terminators, authentication services, and it runs the (distributed) brain of the Object Storage system — the proxy server processes.
Having the access servers in their own tier enables read/write access to be scaled out independently of storage capacity. For example, if the cluster is on the public Internet and requires SSL-termination and has high demand for data access, many access servers can be provisioned. However, if the cluster is on a private network and it is being used primarily for archival purposes, fewer access servers are needed.
A load balancer can be incorporated into the access tier, because this is an HTTP addressable storage service.
Typically, this tier comprises a collection of 1U servers. These machines use a moderate amount of RAM and are network I/O intensive. It is wise to provision them with two high-throughput (10GbE) interfaces, because these systems field each incoming API request. One interface is used for 'front-end' incoming requests and the other for 'back-end' access to the Object Storage nodes to put and fetch data.
Factors to consider
For most publicly facing deployments as well as private deployments available across a wide-reaching corporate network, SSL is used to encrypt traffic to the client. SSL adds significant processing load to establish sessions between clients; it adds more capacity to the access layer that will need to be provisioned. SSL may not be required for private deployments on trusted networks.
Storage Nodes
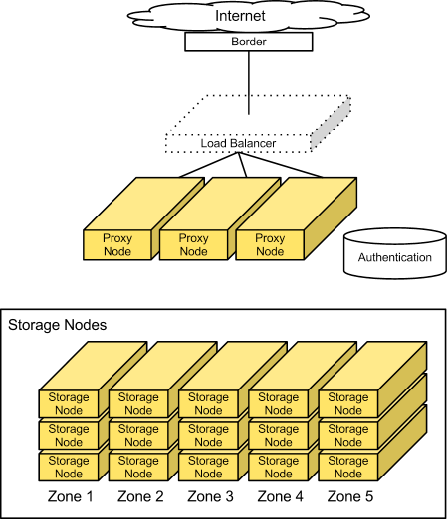
The next component is the storage servers themselves. Generally, most configurations should provide each of the five Zones with an equal amount of storage capacity. Storage nodes use a reasonable amount of memory and CPU. Metadata needs to be readily available to quickly return objects. The object stores run services not only to field incoming requests from the Access Tier, but to also run replicators, auditors, and reapers. Object stores can be provisioned with a single gigabit or a 10-gigabit network interface depending on expected workload and desired performance.
Currently, a 2 TB or 3 TB SATA disk delivers good performance for the price. Desktop-grade drives can be used where there are responsive remote hands in the datacenter, and enterprise-grade drives can be used where this is not the case.
Factors to Consider
Desired I/O performance for single-threaded requests should be kept in mind. This system does not use RAID, so each request for an object is handled by a single disk. Disk performance impacts single-threaded response rates.
To achieve apparent higher throughput, the object storage system is designed with concurrent uploads/downloads in mind. The network I/O capacity (1GbE, bonded 1GbE pair, or 10GbE) should match your desired concurrent throughput needs for reads and writes.
The Account Reaper removes data from deleted accounts in the background.
An account is marked for deletion by a reseller issuing a DELETE request on the account’s storage URL. This simply puts the value DELETED into the status column of the account_stat table in the account database (and replicas), indicating the data for the account should be deleted later.
There is normally no set retention time and no undelete; it is assumed the reseller will implement such features and only call DELETE on the account once it is truly desired the account’s data be removed. However, in order to protect the Swift cluster accounts from an improper or mistaken delete request, you can set a delay_reaping value in the [account-reaper] section of the account-server.conf to delay the actual deletion of data. At this time, there is no utility to undelete an account; one would have to update the account database replicas directly, setting the status column to an empty string and updating the put_timestamp to be greater than the delete_timestamp. (On the TODO list is writing a utility to perform this task, preferably through a ReST call.)
The account reaper runs on each account server and scans the server occasionally for account databases marked for deletion. It will only trigger on accounts that server is the primary node for, so that multiple account servers aren’t all trying to do the same work at the same time. Using multiple servers to delete one account might improve deletion speed, but requires coordination so they aren’t duplicating efforts. Speed really isn’t as much of a concern with data deletion and large accounts aren’t deleted that often.
The deletion process for an account itself is pretty straightforward. For each container in the account, each object is deleted and then the container is deleted. Any deletion requests that fail won’t stop the overall process, but will cause the overall process to fail eventually (for example, if an object delete times out, the container won’t be able to be deleted later and therefore the account won’t be deleted either). The overall process continues even on a failure so that it doesn’t get hung up reclaiming cluster space because of one troublesome spot. The account reaper will keep trying to delete an account until it eventually becomes empty, at which point the database reclaim process within the db_replicator will eventually remove the database files.
Sometimes a persistent error state can prevent some object or container from being deleted. If this happens, you will see a message such as “Account <name> has not been reaped since <date>” in the log. You can control when this is logged with the reap_warn_after value in the [account-reaper] section of the account-server.conf file. By default this is 30 days.
Because each replica in swift functions independently, and clients generally require only a simple majority of nodes responding to consider an operation successful, transient failures like network partitions can quickly cause replicas to diverge. These differences are eventually reconciled by asynchronous, peer-to-peer replicator processes. The replicator processes traverse their local filesystems, concurrently performing operations in a manner that balances load across physical disks.
Replication uses a push model, with records and files generally only being copied from local to remote replicas. This is important because data on the node may not belong there (as in the case of handoffs and ring changes), and a replicator can’t know what data exists elsewhere in the cluster that it should pull in. It’s the duty of any node that contains data to ensure that data gets to where it belongs. Replica placement is handled by the ring.
Every deleted record or file in the system is marked by a tombstone, so that deletions can be replicated alongside creations. The replication process cleans up tombstones after a time period known as the consistency window. The consistency window encompasses replication duration and how long transient failure can remove a node from the cluster. Tombstone cleanup must be tied to replication to reach replica convergence.
If a replicator detects that a remote drive has failed, the replicator uses the get_more_nodes interface for the ring to choose an alternate node with which to synchronize. The replicator can maintain desired levels of replication in the face of disk failures, though some replicas may not be in an immediately usable location. Note that the replicator doesn’t maintain desired levels of replication when other failures, such as entire node failures occur, because most failure are transient.
Replication is an area of active development, and likely rife with potential improvements to speed and accuracy.
There are two major classes of replicator - the db replicator, which replicates accounts and containers, and the object replicator, which replicates object data.
DB Replication
The first step performed by db replication is a low-cost hash comparison to determine whether two replicas already match. Under normal operation, this check is able to verify that most databases in the system are already synchronized very quickly. If the hashes differ, the replicator brings the databases in sync by sharing records added since the last sync point.
This sync point is a high water mark noting the last record at which two databases were known to be in sync, and is stored in each database as a tuple of the remote database id and record id. Database ids are unique amongst all replicas of the database, and record ids are monotonically increasing integers. After all new records have been pushed to the remote database, the entire sync table of the local database is pushed, so the remote database can guarantee that it is in sync with everything with which the local database has previously synchronized.
If a replica is found to be missing entirely, the whole local database file is transmitted to the peer using rsync(1) and vested with a new unique id.
In practice, DB replication can process hundreds of databases per concurrency setting per second (up to the number of available CPUs or disks) and is bound by the number of DB transactions that must be performed.
Object Replication
The initial implementation of object replication simply performed an rsync to push data from a local partition to all remote servers it was expected to exist on. While this performed adequately at small scale, replication times skyrocketed once directory structures could no longer be held in RAM. We now use a modification of this scheme in which a hash of the contents for each suffix directory is saved to a per-partition hashes file. The hash for a suffix directory is invalidated when the contents of that suffix directory are modified.
The object replication process reads in these hash files, calculating any invalidated hashes. It then transmits the hashes to each remote server that should hold the partition, and only suffix directories with differing hashes on the remote server are rsynced. After pushing files to the remote server, the replication process notifies it to recalculate hashes for the rsynced suffix directories.
Performance of object replication is generally bound by the number of uncached directories it has to traverse, usually as a result of invalidated suffix directory hashes. Using write volume and partition counts from our running systems, it was designed so that around 2% of the hash space on a normal node will be invalidated per day, which has experimentally given us acceptable replication speeds.