# oc get pods -n openshift-infra NAME READY STATUS RESTARTS AGE hawkular-cassandra-1-l5y4g 1/1 Running 0 17h hawkular-metrics-1t9so 1/1 Running 0 17h heapster-febru 1/1 Running 0 17h
Enabling Cluster Metrics
- Overview
- Before You Begin
- Metrics Project
- Metrics Data Storage
- Metrics Ansible Role
- Deploying the Metric Components
- Setting the Metrics Public URL
- Accessing Hawkular Metrics Directly
- Accessing Heapster Directly
- Scaling OpenShift Origin Cluster Metrics Pods
- Integration with Aggregated Logging
- Cleanup
- Prometheus on OpenShift Origin
Overview
As an OpenShift Origin administrator, you can view a cluster’s metrics from all containers and components in one user interface. These metrics are also used by horizontal pod autoscalers in order to determine when and how to scale.
This topic describes using Hawkular Metrics as a metrics engine which stores the data persistently in a Cassandra database. When this is configured, CPU, memory and network-based metrics are viewable from the OpenShift Origin web console and are available for use by horizontal pod autoscalers.
Heapster retrieves a list of all nodes from the master server, then contacts
each node individually through the /stats endpoint. From there, Heapster
scrapes the metrics for CPU, memory and network usage, then exports them into
Hawkular Metrics.
The storage volume metrics available on the kubelet are not available through
the /stats endpoint, but are available through the /metrics endpoint. See
OpenShift Origin via Prometheus for detailed information.
Browsing individual pods in the web console displays separate sparkline charts for memory and CPU. The time range displayed is selectable, and these charts automatically update every 30 seconds. If there are multiple containers on the pod, then you can select a specific container to display its metrics.
If resource limits are
defined for your project, then you can also see a donut chart for each pod. The
donut chart displays usage against the resource limit. For example: 145
Available of 200 MiB, with the donut chart showing 55 MiB Used.
For more information about the metrics integration, please refer to the Origin Metrics GitHub project.
Before You Begin
|
If your OpenShift Origin installation was originally performed on a version previous to v1.0.8, even if it has since been updated to a newer version, follow the instructions for node certificates outlined in Updating Master and Node Certificates. If the node certificate does not contain the IP address of the node, then Heapster fails to retrieve any metrics. |
An Ansible playbook is available to deploy and upgrade cluster metrics. You should familiarize yourself with the Advanced Installation section. This provides information for preparing to use Ansible and includes information about configuration. Parameters are added to the Ansible inventory file to configure various areas of cluster metrics.
The following describe the various areas and the parameters that can be added to the Ansible inventory file in order to modify the defaults:
Metrics Project
The components for cluster metrics must be deployed to the openshift-infra
project in order for autoscaling to work.
Horizontal pod
autoscalers specifically use this project to discover the Heapster service and
use it to retrieve metrics. The metrics project can be changed by adding
openshift_metrics_project to the inventory file.
Metrics Data Storage
You can store the metrics data to either persistent storage or to a temporary pod volume.
Persistent Storage
Running OpenShift Origin cluster metrics with persistent storage means that your metrics are stored to a persistent volume and are able to survive a pod being restarted or recreated. This is ideal if you require your metrics data to be guarded from data loss. For production environments it is highly recommended to configure persistent storage for your metrics pods.
The size requirement of the Cassandra storage is dependent on the number of
pods. It is the administrator’s responsibility to ensure that the size
requirements are sufficient for their setup and to monitor usage to ensure that
the disk does not become full. The size of the persisted volume claim is
specified with the openshift_metrics_cassandra_pvc_size
ansible
variable which is set to 10 GB by default.
If you would like to use dynamically provisioned persistent volumes set the openshift_metrics_cassandra_storage_type
variable
to dynamic in the inventory file.
Capacity Planning for Cluster Metrics
After running the openshift_metrics Ansible role, the output of oc get pods
should resemble the following:
OpenShift Origin metrics are stored using the Cassandra database, which is
deployed with settings of openshift_metrics_cassandra_limits_memory: 2G; this
value could be adjusted further based upon the available memory as determined by
the Cassandra start script. This value should cover most OpenShift Origin metrics
installations, but using environment variables you can modify the MAX_HEAP_SIZE
along with heap new generation size, HEAP_NEWSIZE, in the
Cassandra Dockerfile
prior to deploying cluster metrics.
By default, metrics data is stored for seven days. After seven days, Cassandra begins to purge the oldest metrics data. Metrics data for deleted pods and projects is not automatically purged; it is only removed once the data is more than seven days old.
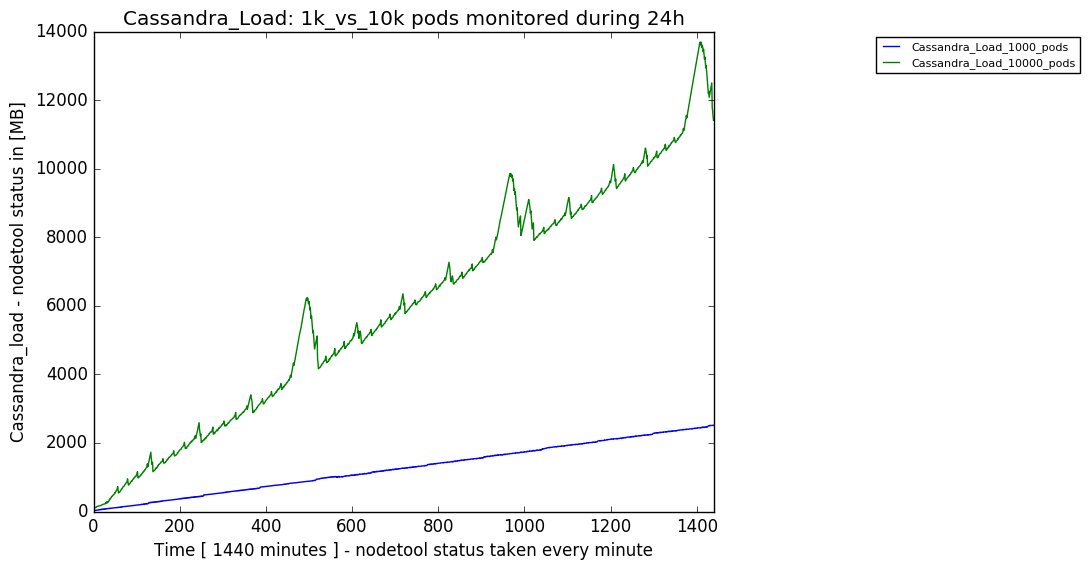
Example 1. Data Accumulated by 10 Nodes and 1000 Pods
In a test scenario including 10 nodes and 1000 pods, a 24 hour period accumulated 2.5 GB of metrics data. Therefore, the capacity planning formula for metrics data in this scenario is:
(((2.5 × 109) ÷ 1000) ÷ 24) ÷ 106 = ~0.125 MB/hour per pod.
Example 2. Data Accumulated by 120 Nodes and 10000 Pods
In a test scenario including 120 nodes and 10000 pods, a 24 hour period accumulated 25 GB of metrics data. Therefore, the capacity planning formula for metrics data in this scenario is:
(((11.410 × 109) ÷ 1000) ÷ 24) ÷ 106 = 0.475 MB/hour
| 1000 pods | 10000 pods | |
|---|---|---|
Cassandra storage data accumulated over 24 hours (default metrics parameters) |
2.5 GB |
11.4 GB |
These two test cases are presented on the following graph:
If the default value of 7 days for openshift_metrics_duration and 10 seconds for
openshift_metrics_resolution are preserved, then weekly storage requirements for the Cassandra pod would be:
| 1000 pods | 10000 pods | |
|---|---|---|
Cassandra storage data accumulated over seven days (default metrics parameters) |
20 GB |
90 GB |
In the previous table, an additional 10 percent was added to the expected storage space as a buffer for unexpected monitored pod usage.
|
If the Cassandra persisted volume runs out of sufficient space, then data loss occurs. |
For cluster metrics to work with persistent storage, ensure that the persistent volume has the ReadWriteOnce access mode. If this mode is not active, then the persistent volume claim cannot locate the persistent volume, and Cassandra fails to start.
To use persistent storage with the metric components, ensure that a
persistent volume of
sufficient size is available. The creation of
persistent volume claims is handled by
the OpenShift Ansible openshift_metrics role.
OpenShift Origin metrics also supports dynamically-provisioned persistent volumes.
To use this feature with OpenShift Origin metrics, it is necessary to set the value
of openshift_metrics_cassandra_storage_type to dynamic.
You can use EBS, GCE, and Cinder storage back-ends to
dynamically provision persistent volumes.
For information on configuring the performance and scaling the cluster metrics pods, see the Scaling Cluster Metrics topic.
Known Issues and Limitations
Testing found that the heapster metrics component is capable of handling up to
25,000 pods. If the amount of pods exceed that number, Heapster begins to fall
behind in metrics processing, resulting in the possibility of metrics graphs no
longer appearing. Work is ongoing to increase the number of pods that Heapster
can gather metrics on, as well as upstream development of alternate
metrics-gathering solutions.
Non-Persistent Storage
Running OpenShift Origin cluster metrics with non-persistent storage means that any stored metrics are deleted when the pod is deleted. While it is much easier to run cluster metrics with non-persistent data, running with non-persistent data does come with the risk of permanent data loss. However, metrics can still survive a container being restarted.
In order to use non-persistent storage, you must set the
openshift_metrics_cassandra_storage_type
variable
to emptyDir in the inventory file.
|
When using non-persistent storage, metrics data is written to /var/lib/origin/openshift.local.volumes/pods on the node where the Cassandra pod runs Ensure /var has enough free space to accommodate metrics storage. |
Metrics Ansible Role
The OpenShift Origin Ansible openshift_metrics role configures and deploys all of the
metrics components using the variables from the
Configuring
Ansible inventory file.
Specifying Metrics Ansible Variables
The openshift_metrics role included with OpenShift Ansible defines the tasks
to deploy cluster metrics. The following is a list of role variables that can be
added to your inventory file if it is necessary to override them.
| Variable | Description |
|---|---|
|
Deploy metrics if |
|
Start the metrics cluster after deploying the components. |
|
The prefix for the component images. With
|
|
The version for the component images. For example, with
|
|
The time, in seconds, to wait until Hawkular Metrics and Heapster start up before attempting a restart. |
|
The number of days to store metrics before they are purged. |
|
The frequency that metrics are gathered. Defined as a number and time identifier: seconds (s), minutes (m), hours (h). |
|
The persistent volume claim prefix created for Cassandra. A serial number is appended to the prefix starting from 1. |
|
The persistent volume claim size for each of the Cassandra nodes. |
|
Use |
|
The number of Cassandra nodes for the metrics stack. This value dictates the number of Cassandra replication controllers. |
|
The memory limit for the Cassandra pod. For example, a value of |
|
The CPU limit for the Cassandra pod. For example, a value of |
|
The number of replicas for Cassandra. |
|
The amount of memory to request for Cassandra pod. For example, a value of
|
|
The CPU request for the Cassandra pod. For example, a value of |
|
The supplemental storage group to use for Cassandra. |
|
Set to the desired, existing
node selector to ensure that
pods are placed onto nodes with specific labels. For example,
|
|
An optional certificate authority (CA) file used to sign the Hawkular certificate. |
|
The certificate file used for re-encrypting the route to Hawkular metrics. The certificate must contain the host name used by the route. If unspecified, the default router certificate is used. |
|
The key file used with the Hawkular certificate. |
|
The amount of memory to limit the Hawkular pod. For example, a value of |
|
The CPU limit for the Hawkular pod. For example, a value of |
|
The number of replicas for Hawkular metrics. |
|
The amount of memory to request for the Hawkular pod. For example, a value of
|
|
The CPU request for the Hawkular pod. For example, a value of |
|
Set to the desired, existing
node selector to ensure that
pods are placed onto nodes with specific labels. For example,
|
|
A comma-separated list of CN to accept. By default, this is set to allow the
OpenShift service proxy to connect. Add |
|
The amount of memory to limit the Heapster pod. For example, a value of |
|
The CPU limit for the Heapster pod. For example, a value of |
|
The amount of memory to request for Heapster pod. For example, a value of |
|
The CPU request for the Heapster pod. For example, a value of |
|
Deploy only Heapster, without the Hawkular Metrics and Cassandra components. |
|
Set to the desired, existing
node selector to ensure that
pods are placed onto nodes with specific labels. For example,
|
|
Set to |
|
The Hawkular OpenShift Origin Agent on OpenShift Origin is a Technology Preview feature only. |
See Compute Resources for further discussion on how to specify requests and limits.
The only required variable is openshift_metrics_hawkular_hostname. This value is
required when executing the openshift_metrics Ansible role because it uses the host name for the
Hawkular Metrics route. This
value should correspond to a fully qualified domain name. You must know
the value of openshift_metrics_hawkular_hostname when
configuring the console for metrics access.
If you are using
persistent
storage with Cassandra, it is the administrator’s responsibility to set a
sufficient disk size for the cluster using the openshift_metrics_cassandra_pvc_size variable.
It is also the administrator’s responsibility to monitor disk usage to make sure
that it does not become full.
|
Data loss results if the Cassandra persisted volume runs out of sufficient space. |
All of the other variables are optional and allow for greater customization.
For instance, if you have a custom install in which the Kubernetes master is not
available under https://kubernetes.default.svc:443 you can specify the value
to use instead with the openshift_metrics_master_url parameter. To deploy a specific version
of the metrics components, modify the openshift_metrics_image_version variable.
|
It is highly recommended to not use latest for the openshift_metrics_image_version. The latest version corresponds to the very latest version available and can cause issues if it brings in a newer version not meant to function on the version of OpenShift Origin you are currently running. |
Using Secrets
The OpenShift Origin Ansible openshift_metrics role auto-generates self-signed certificates for use between its
components and generates a
re-encrypting route to expose
the Hawkular Metrics service. This route is what allows the web console to access the Hawkular Metrics
service.
In order for the browser running the web console to trust the connection through
this route, it must trust the route’s certificate. This can be accomplished by
providing your own certificates signed by
a trusted Certificate Authority. The openshift_metrics role allows you to
specify your own certificates, which it then uses when creating the route.
The router’s default certificate are used if you do not provide your own.
Providing Your Own Certificates
To provide your own certificate, which is used by the
re-encrypting
route, you can set the openshift_metrics_hawkular_cert,
openshift_metrics_hawkular_key, and openshift_metrics_hawkular_ca
variables
in your inventory file.
The hawkular-metrics.pem value needs to contain the certificate in its .pem
format. You may also need to provide the certificate for the Certificate Authority
which signed this pem file via the hawkular-metrics-ca.cert secret.
For more information, please see the re-encryption route documentation.
Deploying the Metric Components
Because deploying and configuring all the metric components is handled with OpenShift Origin Ansible, you can deploy everything in one step.
The following examples show you how to deploy metrics with and without persistent storage using the default parameters.
Example 3. Deploying with Persistent Storage
The following command sets the Hawkular Metrics route to use hawkular-metrics.example.com and is deployed using persistent storage.
You must have a persistent volume of sufficient size available.
$ ansible-playbook [-i </path/to/inventory>] <OPENSHIFT_ANSIBLE_DIR>/playbooks/openshift-metrics/config.yml \ -e openshift_metrics_install_metrics=True \ -e openshift_metrics_hawkular_hostname=hawkular-metrics.example.com \ -e openshift_metrics_cassandra_storage_type=pv
Example 4. Deploying without Persistent Storage
The following command sets the Hawkular Metrics route to use hawkular-metrics.example.com and deploy without persistent storage.
$ ansible-playbook [-i </path/to/inventory>] <OPENSHIFT_ANSIBLE_DIR>/playbooks/openshift-metrics/config.yml \ -e openshift_metrics_install_metrics=True \ -e openshift_metrics_hawkular_hostname=hawkular-metrics.example.com
|
Because this is being deployed without persistent storage, metric data loss can occur. |
Setting the Metrics Public URL
The OpenShift Origin web console uses the data coming from the Hawkular Metrics
service to display its graphs. The URL for accessing the Hawkular Metrics
service must be configured with the metricsPublicURL option in the
master
configuration file (/etc/origin/master/master-config.yaml). This URL
corresponds to the route created with the openshift_metrics_hawkular_hostname
inventory variable used during the
deployment
of the metrics components.
|
You must be able to resolve the |
For example, if your openshift_metrics_hawkular_hostname corresponds to
hawkular-metrics.example.com, then you must make the following change in the
master-config.yaml file:
assetConfig:
...
metricsPublicURL: "https://hawkular-metrics.example.com/hawkular/metrics"Once you have updated and saved the master-config.yaml file, you must restart your OpenShift Origin instance.
When your OpenShift Origin server is back up and running, metrics are displayed on the pod overview pages.
|
If you are using self-signed certificates, remember that the Hawkular Metrics
service is hosted under a different host name and uses different certificates
than the console. You may need to explicitly open a browser tab to the value
specified in To avoid this issue, use certificates which are configured to be acceptable by your browser. |
Accessing Hawkular Metrics Directly
To access and manage metrics more directly, use the Hawkular Metrics API.
|
When accessing Hawkular Metrics from the API, you are only able to perform
reads. Writing metrics is disabled by default. If you want individual
users to also be able to write metrics, you must set the
However, it is recommended to use the default configuration and only have metrics enter the system via Heapster. If write access is enabled, any user can write metrics to the system, which can affect performance and cause Cassandra disk usage to unpredictably increase. |
The Hawkular Metrics documentation covers how to use the API, but there are a few differences when dealing with the version of Hawkular Metrics configured for use on OpenShift Origin:
OpenShift Origin Projects and Hawkular Tenants
Hawkular Metrics is a multi-tenanted application. It is configured so that a project in OpenShift Origin corresponds to a tenant in Hawkular Metrics.
As such, when accessing metrics for a project named MyProject you must set the Hawkular-Tenant header to MyProject.
There is also a special tenant named _system which contains system level metrics. This requires either a cluster-reader or cluster-admin level privileges to access.
Authorization
The Hawkular Metrics service authenticates the user against OpenShift Origin to determine if the user has access to the project it is trying to access.
Hawkular Metrics accepts a bearer token from the client and verifies that token with the OpenShift Origin server using a SubjectAccessReview. If the user has proper read privileges for the project, they are allowed to read the metrics for that project. For the _system tenant, the user requesting to read from this tenant must have cluster-reader permission.
When accessing the Hawkular Metrics API, you must pass a bearer token in the Authorization header.
Accessing Heapster Directly
Heapster is configured to only be accessible via the API proxy. Accessing Heapster requires either a cluster-reader or cluster-admin privileges.
For example, to access the Heapster validate page, you need to access it using something similar to:
$ curl -H "Authorization: Bearer XXXXXXXXXXXXXXXXX" \
-X GET https://${KUBERNETES_MASTER}/api/v1/proxy/namespaces/openshift-infra/services/https:heapster:/validate
For more information about Heapster and how to access its APIs, please refer the Heapster project.
Scaling OpenShift Origin Cluster Metrics Pods
Information about scaling cluster metrics capabilities is available in the Scaling and Performance Guide.
Integration with Aggregated Logging
Hawkular Alerts must be connected to the Aggregated Logging’s Elasticsearch to
react on log events. By default, Hawkular tries to find Elasticsearch on its
default place (namespace logging, pod logging-es) at every boot. If
Aggregated Logging is installed after Hawkular, the Hawkular Metrics pod might
need to be restarted in order to recognize the new Elasticsearch server. The
Hawkular boot log provides a clear indication if the integration could not be
properly configured, with messages like:
Failed to import the logging certificate into the store. Continuing, but the logging integration might fail.
or
Could not get the logging secret! Status code: 000. The Hawkular Alerts integration with Logging might not work properly.
This feature is available from version v1.7. You can confirm if logging is available by checking the log for an entry like:
Retrieving the Logging's CA and adding to the trust store, if Logging is available.
Cleanup
You can remove everything deployed by the OpenShift Origin Ansible openshift_metrics role
by performing the following steps:
$ ansible-playbook [-i </path/to/inventory>] <OPENSHIFT_ANSIBLE_DIR>/playbooks/openshift-metrics/config.yml \ -e openshift_metrics_install_metrics=False
Prometheus on OpenShift Origin
Prometheus is a stand-alone, open source systems monitoring and alerting toolkit. You can use Prometheus to visualize metrics and alerts for OpenShift Origin system resources.
|
Prometheus on OpenShift Origin is a Technology Preview feature only. |
Setting Prometheus Role Variables
The Prometheus role creates:
-
The
openshift-metricsnamespace. -
Prometheus
clusterrolebindingand service account. -
Prometheus pod with Prometheus behind OAuth proxy, Alertmanager, and Alert Buffer as a stateful set.
-
Prometheus and
prometheus-alertsConfigMaps. -
Prometheus and Prometheus Alerts services and direct routes.
Prometheus deployment is disabled by default, enable it by setting
openshift_hosted_prometheus_deploy to true. For example:
# openshift_hosted_prometheus_deploy=true
Set the following role variables to install and configure Prometheus.
| Variable | Description |
|---|---|
|
Project namespace where the components are deployed. Default set to
|
|
Selector for the nodes on which Prometheus is deployed. |
|
Set to create PV for Prometheus. For example,
|
|
Set to create PV for Alertmanager. For example,
|
|
Set to create PV for Alert Buffer. For example,
|
|
Set to create PVC for Prometheus. For example,
|
|
Set to create PVC for Alertmanager. For example,
|
|
Set to create PVC for Alert Buffer. For example,
|
|
Additional Prometheus rules file. Set to |
Deploying Prometheus Using Ansible Installer
The Ansible Installer is the default method of deploying Prometheus.
Add label to your node:
# Inventory file
openshift_prometheus_namespace=openshift-metrics
openshift_prometheus_node_selector={"region":"infra"}
Run the playbook:
$ ansible-playbook -vvv -i ${INVENTORY_FILE} playbooks/openshift-prometheus/config.yml
Additional Methods for Deploying Prometheus
Deploy Using Node-Selector
Label the node on which you want to deploy Prometheus:
# oadm label node/$NODE ${KEY}=${VALUE}
Deploy Prometheus with Ansible and container resources:
# Inventory file
openshift_prometheus_namespace=openshift-metrics
# Set node selector for prometheus
openshift_prometheus_node_selector={"${KEY}":"${VALUE}"}
Run the playbook:
$ ansible-playbook -vvv -i ${INVENTORY_FILE} playbooks/openshift-prometheus/config.yml
Deploy Using a Non-default Namespace
Identify your namespace:
# Inventory file
openshift_prometheus_node_selector={"region":"infra"}
# Set non-default openshift_prometheus_namespace
openshift_prometheus_namespace=${USER_PROJECT}
Run the playbook:
$ ansible-playbook -vvv -i ${INVENTORY_FILE} playbooks/openshift-prometheus/config.yml
Accessing the Prometheus Web UI
The Prometheus server automatically exposes a Web UI at localhost:9090. You
can access the Prometheus Web UI with the view role.
Configuring Prometheus for OpenShift Origin
Prometheus Storage Related Variables
With each Prometheus component (including Prometheus, Alertmanager, Alert Buffer, and OAuth proxy) you can set the PV claim by setting corresponding role variable, for example:
openshift_prometheus_storage_type: pvc openshift_prometheus_alertmanager_pvc_name: alertmanager openshift_prometheus_alertbuffer_pvc_size: 10G openshift_prometheus_pvc_access_modes: [ReadWriteOnce]
Prometheus Alert Rules File Variable
You can add an external file with alert rules by setting the path to an additional rules variable:
openshift_prometheus_additional_rules_file: <PATH>
The file content should be in Prometheus Alert rules format. The following example sets a rule to send an alert when one of the cluster nodes is down:
groups:
- name: example-rules
interval: 30s # defaults to global interval
rules:
- alert: Node Down
expr: up{job="kubernetes-nodes"} == 0
annotations:
miqTarget: "ContainerNode"
severity: "HIGH"
message: "{{ '{{' }}{{ '$labels.instance' }}{{ '}}' }} is down"
Prometheus Variables to Control Resource Limits
With each Prometheus component (including Prometheus, Alertmanager, Alert Buffer, and OAuth proxy) you can specify CPU, memory limits, and requests by setting the corresponding role variable, for example:
openshift_prometheus_alertmanager_limits_memory: 1Gi openshift_prometheus_oauth_proxy_cpu_requests: 100m
For more detailed information, see OpenShift Prometheus.
|
Once |
OpenShift Origin Metrics via Prometheus
The state of a system can be gauged by the metrics that it emits. This section describes current and proposed metrics that identify the health of the storage subsystem and cluster.
Current Metrics
This section describes the metrics currently emitted from Kubernetes’s storage subsystem.
Cloud Provider API Call Metrics
This metric reports the time and count of success and failures of all
cloudprovider API calls. These metrics include aws_attach_time and
aws_detach_time. The type of emitted metrics is a histogram, and hence,
Prometheus also generates sum, count, and bucket metrics for these metrics.
Example summary of cloudprovider metrics from GCE:
cloudprovider_gce_api_request_duration_seconds { request = "instance_list"}
cloudprovider_gce_api_request_duration_seconds { request = "disk_insert"}
cloudprovider_gce_api_request_duration_seconds { request = "disk_delete"}
cloudprovider_gce_api_request_duration_seconds { request = "attach_disk"}
cloudprovider_gce_api_request_duration_seconds { request = "detach_disk"}
cloudprovider_gce_api_request_duration_seconds { request = "list_disk"}
Example summary of cloudprovider metrics from AWS:
cloudprovider_aws_api_request_duration_seconds { request = "attach_volume"}
cloudprovider_aws_api_request_duration_seconds { request = "detach_volume"}
cloudprovider_aws_api_request_duration_seconds { request = "create_tags"}
cloudprovider_aws_api_request_duration_seconds { request = "create_volume"}
cloudprovider_aws_api_request_duration_seconds { request = "delete_volume"}
cloudprovider_aws_api_request_duration_seconds { request = "describe_instance"}
cloudprovider_aws_api_request_duration_seconds { request = "describe_volume"}
See Cloud Provider (specifically GCE and AWS) metrics for Storage API calls for more information.
Volume Operation Metrics
These metrics report time taken by a storage operation once started. These
metrics keep track of operation time at the plug-in level, but do not include
time taken by goroutine to run or operation to be picked up from the internal
queue. These metrics are a type of histogram.
Example summary of available volume operation metrics
storage_operation_duration_seconds { volume_plugin = "aws-ebs", operation_name = "volume_attach" }
storage_operation_duration_seconds { volume_plugin = "aws-ebs", operation_name = "volume_detach" }
storage_operation_duration_seconds { volume_plugin = "glusterfs", operation_name = "volume_provision" }
storage_operation_duration_seconds { volume_plugin = "gce-pd", operation_name = "volume_delete" }
storage_operation_duration_seconds { volume_plugin = "vsphere", operation_name = "volume_mount" }
storage_operation_duration_seconds { volume_plugin = "iscsi" , operation_name = "volume_unmount" }
storage_operation_duration_seconds { volume_plugin = "aws-ebs", operation_name = "unmount_device" }
storage_operation_duration_seconds { volume_plugin = "cinder" , operation_name = "verify_volumes_are_attached" }
storage_operation_duration_seconds { volume_plugin = "<n/a>" , operation_name = "verify_volumes_are_attached_per_node" }
See Volume operation metrics for more information.
Volume Stats Metrics
These metrics typically report usage stats of PVC (such as used space vs available space). The type of metrics emitted is gauge.
| Metric | Type | Labels/tags |
|---|---|---|
volume_stats_capacityBytes |
Gauge |
namespace,persistentvolumeclaim,persistentvolume= |
volume_stats_usedBytes |
Gauge |
namespace=<persistentvolumeclaim-namespace> persistentvolumeclaim=<persistentvolumeclaim-name> persistentvolume=<persistentvolume-name> |
volume_stats_availableBytes |
Gauge |
namespace=<persistentvolumeclaim-namespace> persistentvolumeclaim=<persistentvolumeclaim-name> persistentvolume= |
volume_stats_InodesFree |
Gauge |
namespace=<persistentvolumeclaim-namespace> persistentvolumeclaim=<persistentvolumeclaim-name> persistentvolume=<persistentvolume-name> |
volume_stats_Inodes |
Gauge |
namespace=<persistentvolumeclaim-namespace> persistentvolumeclaim=<persistentvolumeclaim-name> persistentvolume=<persistentvolume-name> |
volume_stats_InodesUsed |
Gauge |
namespace=<persistentvolumeclaim-namespace> persistentvolumeclaim=<persistentvolumeclaim-name> persistentvolume=<persistentvolume-name> |