- MongoDB CRUD Operations >
- MongoDB CRUD Concepts >
- Read Operations >
- Distributed Queries
Distributed Queries¶
Read Operations to Sharded Clusters¶
Sharded clusters allow you to partition a data set among a cluster of mongod instances in a way that is nearly transparent to the application. For an overview of sharded clusters, see the Sharding section of this manual.
For a sharded cluster, applications issue operations to one of the mongos instances associated with the cluster.
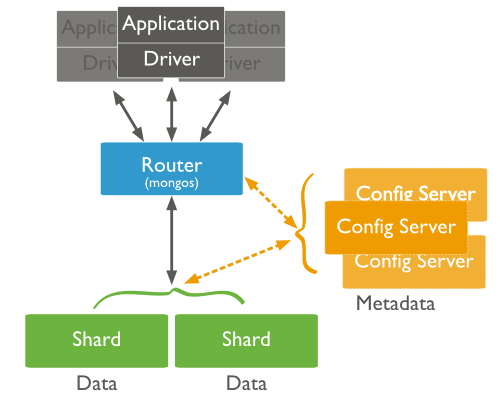
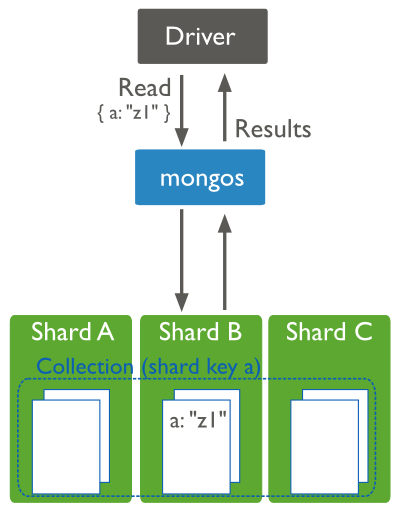
Read operations on sharded clusters are most efficient when directed to a specific shard. Queries to sharded collections should include the collection’s shard key. When a query includes a shard key, the mongos can use cluster metadata from the config database to route the queries to shards.
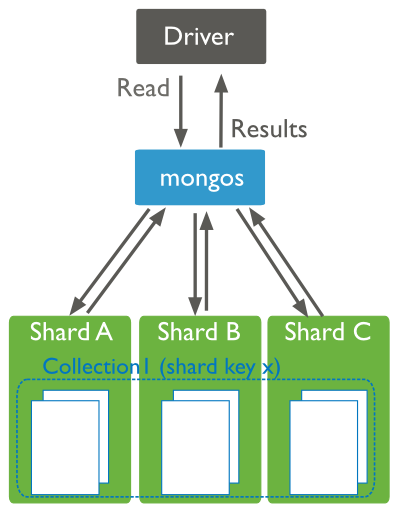
If a query does not include the shard key, the mongos must direct the query to all shards in the cluster. These scatter gather queries can be inefficient. On larger clusters, scatter gather queries are unfeasible for routine operations.
For replica set shards, read operations from secondary members of replica sets may not reflect the current state of the primary. Read preferences that direct read operations to different servers may result in non-monotonic reads.
For more information on read operations in sharded clusters, see the Sharded Cluster Query Routing and Shard Keys sections.
Read Operations to Replica Sets¶
By default, clients reads from a replica set’s primary; however, clients can specify a read preference to direct read operations to other members. For example, clients can configure read preferences to read from secondaries or from nearest member to:
- reduce latency in multi-data-center deployments,
- improve read throughput by distributing high read-volumes (relative to write volume),
- perform backup operations, and/or
- allow reads until a new primary is elected.

Read operations from secondary members of replica sets may not reflect the current state of the primary. Read preferences that direct read operations to different servers may result in non-monotonic reads.
You can configure the read preferece on a per-connection or per-operation basis. For more information on read preference or on the read preference modes, see Read Preference and Read Preference Modes.
Thank you for your feedback!
We're sorry! You can Report a Problem to help us improve this page.