What's new in Grafana v2.6
Release highlights
The release includes a new Table panel, a new InfluxDB query editor, support for Elasticsearch Pipeline Metrics and support for multiple Cloudwatch credentials.
Table Panel
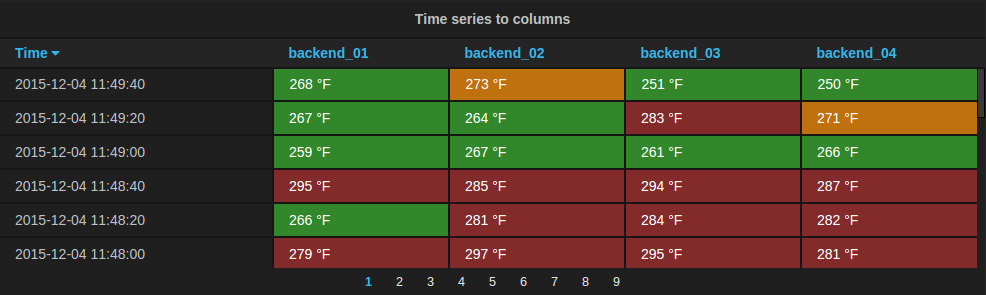
The new table panel is very flexible, supporting both multiple modes for time series as well as for table, annotation and raw JSON data. It also provides date formating and value formating and coloring options.
Time series to rows
In the most simple mode you can turn time series to rows. This means you get a Time, Metric and a Value column.
Where Metric is the name of the time series.
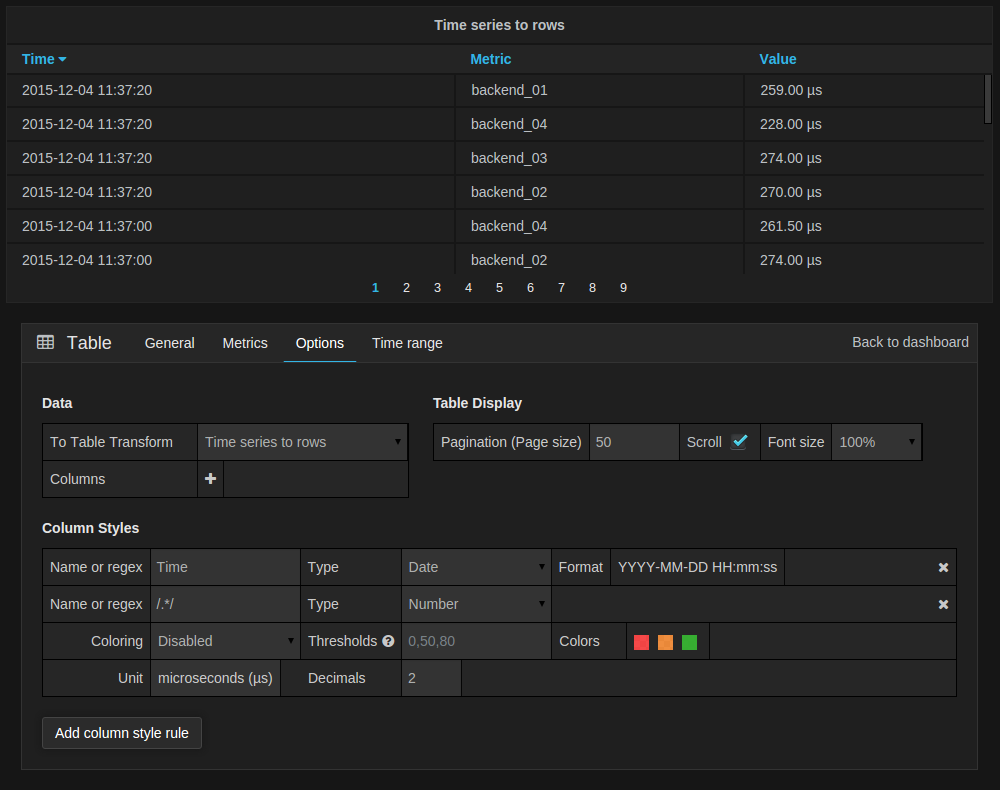
Table Transform
Above you see the options tab for the Table Panel. The most important option is the To Table Transform.
This option controls how the result of the metric/data query is turned into a table.
Column Styles
The column styles allow you control how dates and numbers are formatted.
Time series to columns
This transform allows you to take multiple time series and group them by time. Which will result in a Time column
and a column for each time series.
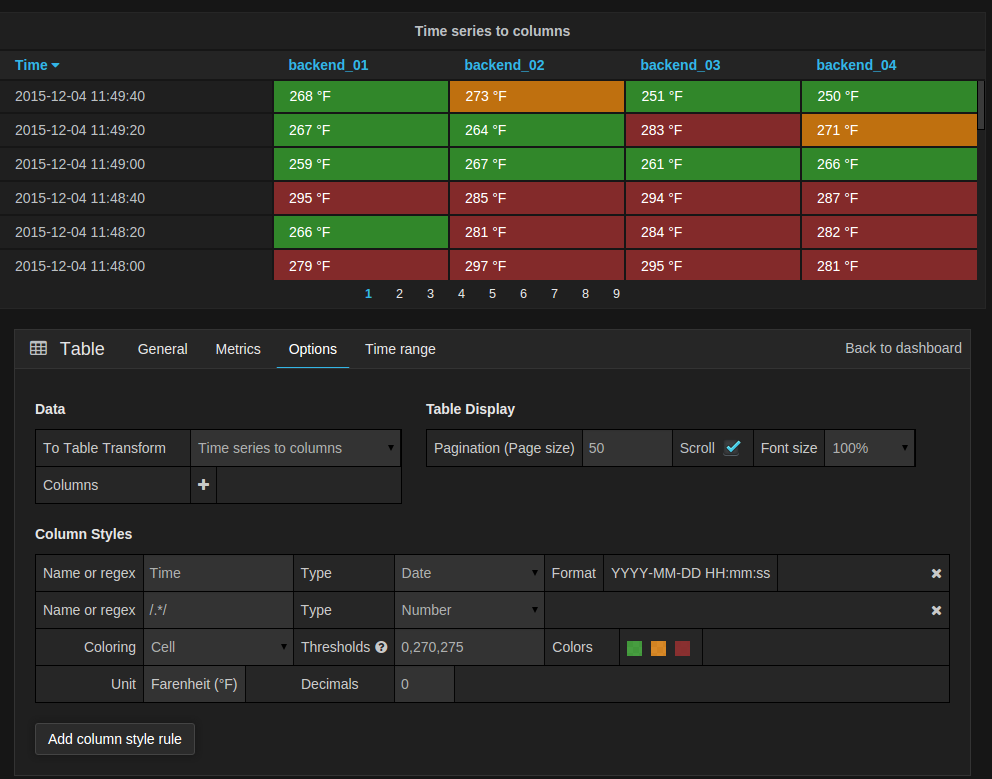
In the screenshot above you can see how the same time series query as in the previous example can be transformed into
a different table by changing the To Table Transform to Time series to columns.
Time series to aggregations
This transform works very similar to the legend values in the Graph panel. Each series gets its own row. In the Options tab you can select which aggregations you want using the plus button the Columns section.

You have to think about how accurate the aggregations will be. It depends on what aggregation is used in the time series query, how many data points are fetched, etc. The time series aggregations are calculated by Grafana after aggregation is performed by the time series database.
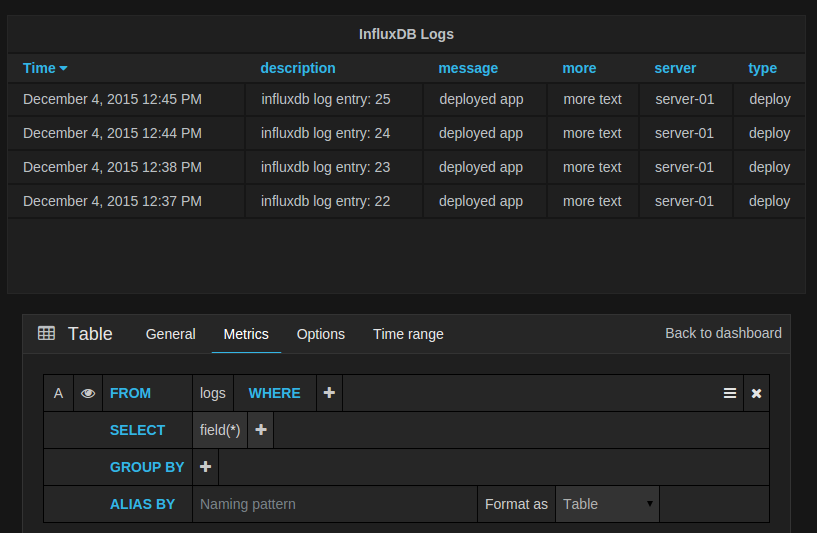
Raw logs queries
If you want to show documents from Elasticsearch pick Raw Document as the first metric.

This in combination with the JSON Data table transform will allow you to pick which fields in the document
you want to show in the table.

Elasticsearch aggregations
You can also make Elasticsearch aggregation queries without a Date Histogram. This allows you to
use Elasticsearch metric aggregations to get accurate aggregations for the selected time range.

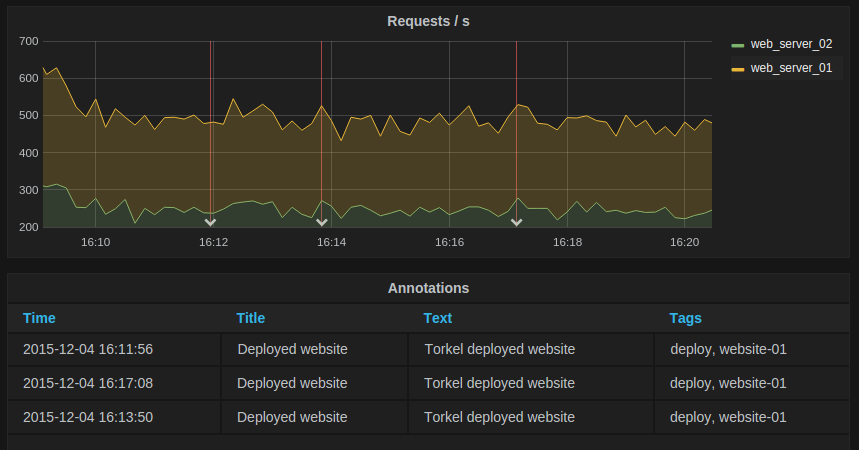
Annotations
The table can also show any annotations you have enabled in the dashboard.
The New InfluxDB Editor
The new InfluxDB editor is a lot more flexible and powerful. It supports nested functions, like derivative.
It also uses the same technique as the Graphite query editor in that it presents nested functions as chain of function
transformations. It tries to simplify and unify the complicated nature of InfluxDB's query language.

In the SELECT row you can specify what fields and functions you want to use. If you have a
group by time you need an aggregation function. Some functions like derivative require an aggregation function.
The editor tries simplify and unify this part of the query. For example:

The above will generate the following InfluxDB SELECT clause:
SELECT derivative(mean("value"), 10s) /10 AS "REQ/s" FROM ....
Select multiple fields
Use the plus button and select Field > field to add another SELECT clause. You can also
specify an asterix * to select all fields.
Group By
To group by a tag click the plus icon at the end of the GROUP BY row. Pick a tag from the dropdown that appears.
You can remove the group by by clicking on the tag and then click on the x icon.
The new editor also allows you to remove group by time and select raw table data. Which is very useful
in combination with the new Table panel to show raw log data stored in InfluxDB.
Pipeline metrics
If you have Elasticsearch 2.x and Grafana 2.6 or above then you can use pipeline metric aggregations like Moving Average and Derivative. Elasticsearch pipeline metrics require another metric to be based on. Use the eye icon next to the metric to hide metrics from appearing in the graph.

Changelog
For a detailed list and link to github issues for everything included in the 2.6 release please view the CHANGELOG.md file.