Zero Downtime Deployment and Scaling in CF
Page last updated: December 15, 2015
To increase the capacity and availability of the Cloud Foundry platform, and to decrease the chances of downtime, you can scale a deployment up using the strategies described below.
This topic also describes the requirements for a zero downtime deployment. A zero downtime deployment ensures that if individual components go down, your deployment continues to run.
For more information regarding zero downtime deployment, see the Scaling Instances in Resource Config for Elastic Runtime topic.
Zero Downtime Deployment
This section describes the required configurations for achieving a zero downtime deployment.
Application Instances
Deploy at least two instances of every application.
Components
Scale your components as described in the Scaling Platform Availability section below. Components should be distributed across two or more availability zones (AZs).
Space
Ensure that you allocate and maintain enough of the following:
- Free space on DEAs so that apps expected to deploy can successfully be staged and run.
- Disk space and memory in your deployment such that if your max_in_flight number of DEAs is down, all instances of apps can be placed on the remaining DEAs.
- Free space to handle one AZ going down if deploying in multiple AZs.
Resource pools
Configure your resource pools according to the requirements of your deployment.
Scaling Platform Capacity
You can scale platform capacity vertically by adding memory and disk, or horizontally by adding more VMs running instances of Cloud Foundry components.
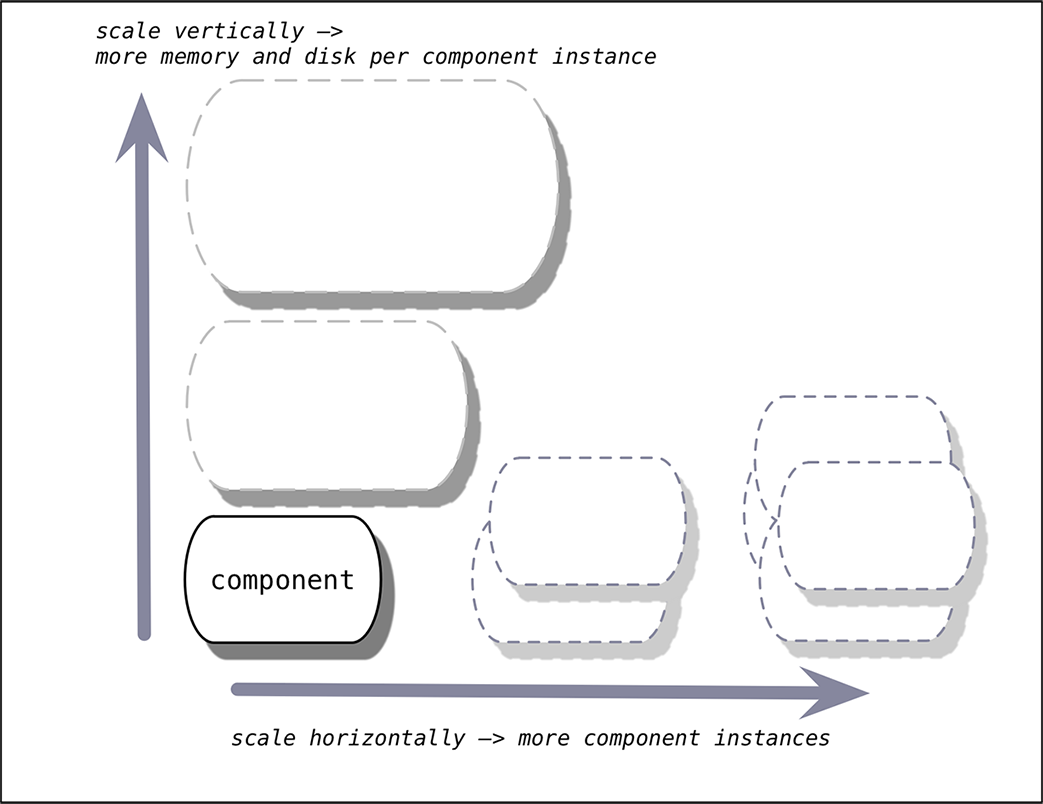
Trade-offs and Benefits
The nature of a particular application should determine whether you scale vertically or horizontally.
DEAs:
The optimal sizing and CPU/memory balance depends on the performance characteristics of the apps that will run on the DEA.
- The more DEAs are horizontally scaled, the higher the number of NATS messages the DEAs generate. There are no known limits to the number of DEA nodes in a platform.
- The denser the DEAs (the more vertically scaled they are), the larger the NATS message volume per DEA, as each message includes details of each app instance running on the DEA.
- Larger DEAs also make for larger points of failure: the system takes longer to rebalance 100 app instances than to rebalance 20 app instances.
Router:
Scale the router with the number of incoming requests. In general, this load is much less than the load on DEA nodes.
Health Manager:
The Health Manager works as a failover set, meaning that only one Health Manager is active at a time. For this reason, you only need to scale the Health Manager to deal with instance failures, not increased deployment size.
Cloud Controller:
Scale the Cloud Controller with the number of requests to the API and with the number of apps in the system.
Scaling Platform Availability
To scale the Cloud Foundry platform for high availability, the actions you take fall into three categories.
- For components that support multiple instances, increase the number of instances to achieve redundancy.
- For components that do not support multiple instances, choose a strategy for dealing with events that degrade availability.
- For database services, plan for and configure backup and restore where possible.
Note: Data services may have single points of failure depending on their configuration.
Scalable Processes
You can think of components that support multiple instances as scalable processes. If you are already scaling the number of instances of such components to increase platform capacity, you need to scale further to achieve the redundancy required for high availability.
If you are using DEAs:
| Job | Number | Notes |
|---|---|---|
| Load Balancer | 1 | |
| MySQL Server | ≥ 3 | Set this to an odd number to support cluster quorum. For more information about cluster quorum, see Cluster Scaling, Node Failure, and Quorum. |
| MySQL Proxy | ≥ 2 | |
| NATS Server | ≥ 2 | If you lack the network bandwidth, CPU utilization, or other resources to deploy two stable NATS servers, Pivotal recommends that you use one NATS server. |
| HM9000 | ≥ 2 | |
| Cloud Controller | ≥ 2 | More Cloud Controllers help with API request volume. |
| Gorouter | ≥ 2 | Additional Gorouters help bring more available bandwidth to ingress and egress. |
| Collector | 1 | |
| UAA | ≥ 2 | |
| DEA | ≥ 3 | More DEAs add application capacity. |
| Doppler Server (formerly Loggregator Server) | ≥ 2 | Deploying additional Doppler servers splits traffic across them. Pivotal recommends you have at least two per Availability Zone. |
| Loggregator Traffic Controller | ≥ 2 | Deploying additional Loggregator Traffic Controllers allows you to direct traffic to them in a round-robin manner. Pivotal recommends you have at least two per Availability Zone. |
| etcd | ≥ 3 | Must be set to an odd number. |
If you are using DIEGO:
| Job | Number | Notes |
|---|---|---|
| Diego Cell | ≥ 3 | |
| Diego Brain | ≥ 2 | |
| Diego BBS | ≥ 3 | This must be set to an odd number. |
| DEA | 0 | |
| Consul | ≥ 3 | This must be set to an odd number. |
| MySQL Server | ≥ 3 | This must be set to an odd number. |
| MySQL Proxy | ≥ 2 | |
| NATS Server | ≥ 2 | If you lack the network bandwidth, CPU utilization, or other resources to deploy two stable NATS servers, Pivotal recommends that you use one NATS server. |
| Cloud Controller | ≥ 2 | Cloud Controllers help with API request volume. |
| Router | ≥ 2 | Additional Gorouters help bring more available bandwidth to ingress and egress. |
| UAA | ≥ 2 | |
| Doppler Server | ≥ 2 | Deploying additional Doppler servers splits traffic across them. Pivotal recommends to have at least two per Availability Zone. |
| Loggregator TC | ≥ 2 | Deploying additional Loggregator Traffic Controllers allows you to direct traffic to them in a round-robin manner. Pivotal recommends to have at least two per Availability Zone. |
| etcd | ≥ 3 | This must be set to an odd number. |
| Health Manager | 0 |
For more information regarding zero downtime deployment, see the Scaling Instances in Resource Config for Elastic Runtime topic.
Single-node Processes
You can think of components that do not support multiple instances as single-node processes. Since you cannot increase the number of instances of these components, you should choose a different strategy for dealing with events that degrade availability.
First, consider the components whose availability affects the platform as a whole.
HAProxy:
Cloud Foundry deploys with a single instance of HAProxy for use in lab and test environments. Production environments should use your own highly-available load balancing solution.
NATS:
You might run NATS as a single-node process if you lack the resources to deploy two stable NATS servers.
Cloud Foundry continues to run any apps that are already running even when NATS is unavailable for short periods of time. The components publishing messages to and consuming messages from NATS are resilient to NATS failures. As soon as NATS recovers, operations such as health management and router updates resume and the whole Cloud Foundry system recovers.
Because NATS is deployed by BOSH, the BOSH resurrector will recover the VM if it becomes non-responsive.
NFS Server:
For some deployments, an appropriate strategy would be to use your infrastructure’s high availability features to immediately recover the VM where the NFS Server runs. In others, it would be preferable to run a scalable and redundant blobstore service. Contact Pivotal PSO if you need help.
Collector:
This component is not in the critical path for any operation.
Compilation:
This component is active only during platform installation and upgrades.
Databases
For database services deployed outside Cloud Foundry, plan to leverage your infrastructure’s high availability features and to configure backup and restore where possible.
Contact Pivotal PSO if you require replicated databases or any assistance.