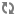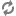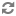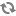You can configure OpenStack Compute to use any SQLAlchemy-compatible
database. The database name is nova and entries to it are mostly written
by the nova-scheduler service, although all the services need to be able
to update entries in the database. Use these settings to configure the
connection string for the nova database.
| Configuration option=Default value | (Type) Description |
| db_backend=sqlalchemy | (StrOpt)The backend to use for db |
| db_backend=sqlalchemy | (StrOpt)The backend to use for bare-metal database |
| db_check_interval=60 | (IntOpt)Seconds between getting fresh cell info from db. |
| db_driver=nova.db | (StrOpt)driver to use for database access |
| dbapi_use_tpool=False | (BoolOpt)Enable the experimental use of thread pooling for all DB API calls |
| sql_connection=sqlite:////home/fifieldt/temp/nova/nova/openstack/common/db/$sqlite_db | (StrOpt)The SQLAlchemy connection string used to connect to the database |
| sql_connection=sqlite:///$state_path/baremetal_$sqlite_db | (StrOpt)The SQLAlchemy connection string used to connect to the bare-metal database |
| sql_connection_debug=0 | (IntOpt)Verbosity of SQL debugging information. 0=None, 100=Everything |
| sql_connection_trace=False | (BoolOpt)Add python stack traces to SQL as comment strings |
| sql_idle_timeout=3600 | (IntOpt)timeout before idle sql connections are reaped |
| sql_max_overflow=None | (IntOpt)If set, use this value for max_overflow with sqlalchemy |
| sql_max_pool_size=5 | (IntOpt)Maximum number of SQL connections to keep open in a pool |
| sql_max_retries=10 | (IntOpt)maximum db connection retries during startup. (setting -1 implies an infinite retry count) |
| sql_min_pool_size=1 | (IntOpt)Minimum number of SQL connections to keep open in a pool |
| sql_retry_interval=10 | (IntOpt)interval between retries of opening a sql connection |
| sqlite_db=nova.sqlite | (StrOpt)the filename to use with sqlite |
| sqlite_synchronous=True | (BoolOpt)If passed, use synchronous mode for sqlite |